In Partea 1 din această serie, am prezentat o soluție care a folosit Embeddings multimodale Amazon Titan model pentru a converti diapozitive individuale dintr-un pachet de diapozitive în înglobare. Am stocat înglobările într-o bază de date vectorială și apoi am folosit Asistent mare pentru limbaj și viziune (LLaVA 1.5-7b) model pentru a genera răspunsuri text la întrebările utilizatorului pe baza celui mai asemănător diapozitiv preluat din baza de date vectorială. Am folosit servicii AWS inclusiv Amazon Bedrock, Amazon SageMaker, și Amazon OpenSearch Serverless in aceasta solutie.
În această postare, demonstrăm o abordare diferită. Noi folosim Sonetul antropic Claude 3 model pentru a genera descrieri de text pentru fiecare diapozitiv din pachetul de diapozitive. Aceste descrieri sunt apoi convertite în înglobări de text folosind Încorporare text Amazon Titan model și stocat într-o bază de date vectorială. Apoi folosim modelul Claude 3 Sonnet pentru a genera răspunsuri la întrebările utilizatorilor pe baza celei mai relevante descrieri de text preluate din baza de date vectorială.
Puteți testa ambele abordări pentru setul de date și puteți evalua rezultatele pentru a vedea care abordare vă oferă cele mai bune rezultate. În partea 3 a acestei serii, evaluăm rezultatele ambelor metode.
Prezentare generală a soluțiilor
Soluția oferă o implementare pentru răspunsul la întrebări folosind informațiile conținute în text și elementele vizuale ale unui pachet de diapozitive. Designul se bazează pe conceptul de Retrieval Augmented Generation (RAG). În mod tradițional, RAG a fost asociat cu date textuale care pot fi procesate de modele de limbaj mari (LLM). În această serie, extindem RAG pentru a include și imagini. Aceasta oferă o capacitate puternică de căutare pentru a extrage conținut relevant din punct de vedere contextual din elemente vizuale precum tabele și grafice împreună cu text.
Această soluție include următoarele componente:
- Amazon Titan Text Embeddings este un model de încorporare a textului care convertește textul în limbaj natural, inclusiv cuvinte, fraze sau chiar documente mari, în reprezentări numerice care pot fi folosite pentru a alimenta cazuri de utilizare, cum ar fi căutarea, personalizarea și gruparea pe baza similitudinii semantice.
- Claude 3 Sonnet este următoarea generație de modele de ultimă generație de la Anthropic. Sonnet este un instrument versatil care poate gestiona o gamă largă de sarcini, de la raționament și analiză complexe până la rezultate rapide, precum și căutare și regăsire eficientă a unor cantități mari de informații.
- OpenSearch Serverless este o configurație la cerere fără server pentru Amazon OpenSearch Service. Folosim OpenSearch Serverless ca bază de date vectorială pentru stocarea înglobărilor generate de modelul Amazon Titan Text Embeddings. Un index creat în colecția OpenSearch Serverless servește drept magazin de vectori pentru soluția noastră RAG.
- Ingestie Amazon OpenSearch (OSI) este un colector de date complet gestionat, fără server, care furnizează date către domeniile OpenSearch Service și colecțiile OpenSearch Serverless. În această postare, folosim un API pipeline OSI pentru a livra date către magazinul de vectori OpenSearch Serverless.
Proiectarea soluției constă din două părți: asimilare și interacțiune cu utilizatorul. În timpul ingerării, procesăm pachetul de diapozitive de intrare transformând fiecare diapozitiv într-o imagine, generând descrieri și încorporare de text pentru fiecare imagine. Apoi populam depozitul de date vectoriale cu înglobările și descrierea textului pentru fiecare diapozitiv. Acești pași sunt finalizați înainte de pașii de interacțiune cu utilizatorul.
În faza de interacțiune cu utilizatorul, o întrebare a utilizatorului este convertită în încorporare de text. Se execută o căutare de similaritate în baza de date vectorială pentru a găsi o descriere text corespunzătoare unui diapozitiv care ar putea conține răspunsuri la întrebarea utilizatorului. Apoi oferim descrierea diapozitivului și întrebarea utilizatorului modelului Claude 3 Sonnet pentru a genera un răspuns la interogare. Tot codul pentru această postare este disponibil în GitHub odihnă.
Următoarea diagramă ilustrează arhitectura de asimilare.

Fluxul de lucru constă din următorii pași:
- Diapozitivele sunt convertite în fișiere imagine (unul per diapozitiv) în format JPG și trecute la modelul Claude 3 Sonnet pentru a genera descrierea textului.
- Datele sunt trimise la modelul Amazon Titan Text Embeddings pentru a genera înglobări. În această serie, folosim slide-ul Antrenați și implementați Stable Diffusion folosind AWS Trainium și AWS Inferentia de la summitul AWS de la Toronto, iunie 2023, pentru a demonstra soluția. Pachetul de mostre are 31 de diapozitive, prin urmare generăm 31 de seturi de înglobări vectoriale, fiecare cu 1536 de dimensiuni. Adăugăm câmpuri de metadate suplimentare pentru a efectua interogări de căutare bogate folosind capabilitățile puternice de căutare ale OpenSearch.
- Înglobările sunt ingerate într-o conductă OSI folosind un apel API.
- Conducta OSI ingerează datele ca documente într-un index OpenSearch Serverless. Indexul este configurat ca receptor pentru această conductă și este creat ca parte a colecției OpenSearch Serverless.
Următoarea diagramă ilustrează arhitectura de interacțiune cu utilizatorul.

Fluxul de lucru constă din următorii pași:
- Un utilizator trimite o întrebare legată de pachetul de diapozitive care a fost ingerat.
- Intrarea utilizatorului este convertită în înglobări folosind modelul Amazon Titan Text Embeddings accesat folosind Amazon Bedrock. O căutare vectorială a Serviciului OpenSearch este efectuată folosind aceste înglobări. Efectuăm o căutare k-nearest neighbor (k-NN) pentru a regăsi cele mai relevante înglobări care se potrivesc cu interogarea utilizatorului.
- Metadatele răspunsului de la OpenSearch Serverless conțin o cale către imagine și descrierea corespunzătoare celui mai relevant diapozitiv.
- Un prompt este creat combinând întrebarea utilizatorului și descrierea imaginii. Solicitarea este furnizată lui Claude 3 Sonnet găzduit pe Amazon Bedrock.
- Rezultatul acestei inferențe este returnat utilizatorului.
Discutăm pașii pentru ambele etape în secțiunile următoare și includem detalii despre rezultat.
Cerințe preliminare
Pentru a implementa soluția oferită în această postare, ar trebui să aveți un Cont AWS și familiaritatea cu FM, Amazon Bedrock, SageMaker și OpenSearch Service.
Această soluție folosește modelele Claude 3 Sonnet și Amazon Titan Text Embeddings găzduite pe Amazon Bedrock. Asigurați-vă că aceste modele sunt activate pentru utilizare navigând la Acces model pagina de pe consola Amazon Bedrock.
Dacă modelele sunt activate, Starea accesului va afirma Acces permis.

Dacă modelele nu sunt disponibile, permiteți accesul alegând Gestionați accesul la model, selectând modelele și alegând Solicitați acces la model. Modelele sunt activate pentru utilizare imediat.
Utilizați AWS CloudFormation pentru a crea stiva de soluții
Puteți utiliza AWS CloudFormation pentru a crea stiva de soluții. Dacă ați creat soluția pentru partea 1 în același cont AWS, asigurați-vă că o ștergeți înainte de a crea această stivă.
| Regiunea AWS | Link |
|---|---|
us-east-1 |
|
us-west-2 |
După ce stiva este creată cu succes, navigați la fila Ieșiri a stivei din consola AWS CloudFormation și notați valorile pentru MultimodalCollectionEndpoint și OpenSearchPipelineEndpoint. Le folosiți în pașii următori.
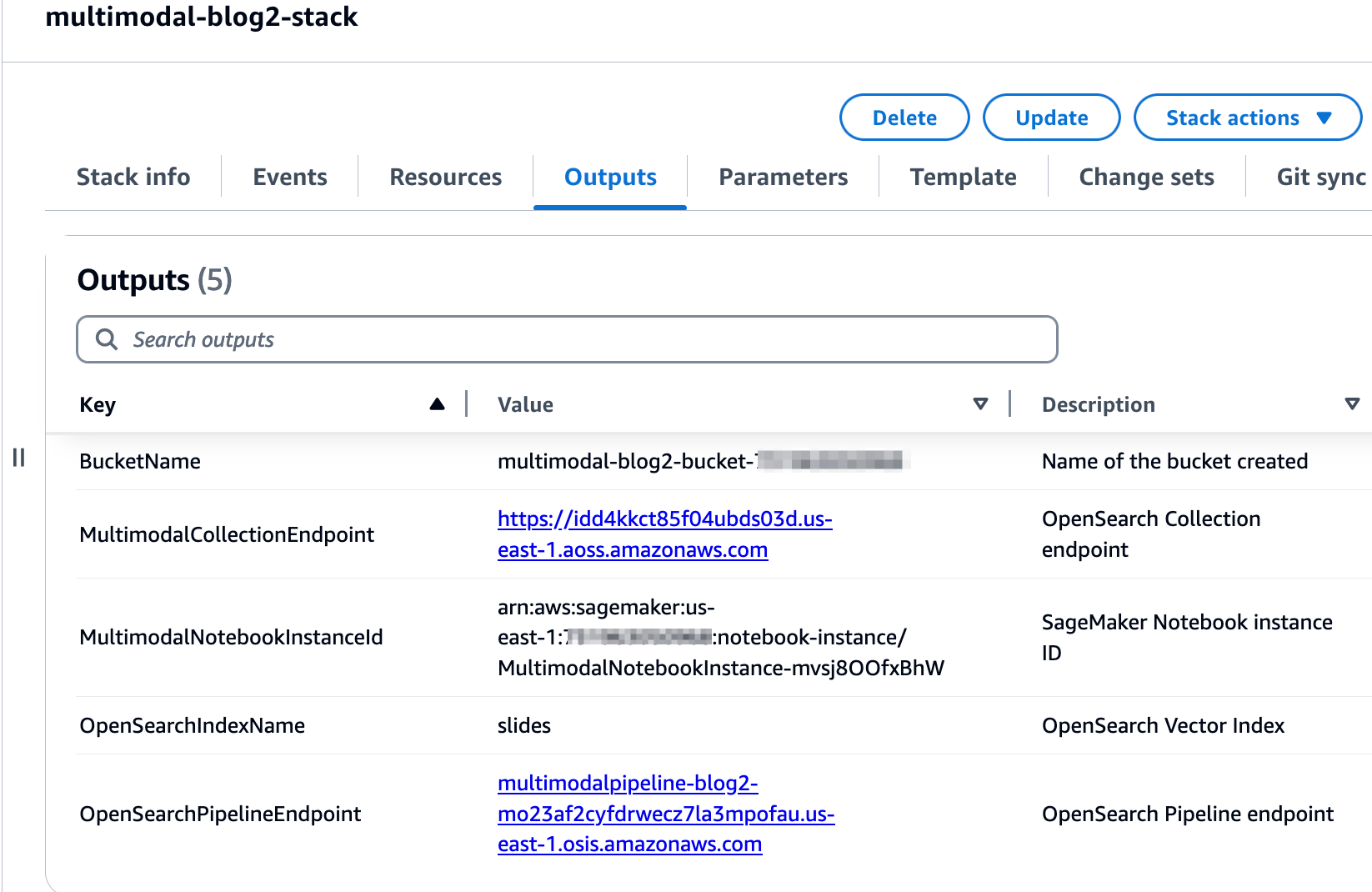
Șablonul CloudFormation creează următoarele resurse:
- Roluri IAM - Următoarele Gestionarea identității și accesului AWS (IAM) sunt create. Actualizați aceste roluri pentru a aplica permisiunile cu cel mai mic privilegiu, așa cum se discută în Cele mai bune practici de securitate.
SMExecutionRolecu Serviciul Amazon de stocare simplă (Amazon S3), SageMaker, OpenSearch Service și Amazon Bedrock acces complet.OSPipelineExecutionRolecu acces la bucket-ul S3 și la acțiunile OSI.
- Caietul SageMaker – Tot codul pentru această postare este rulat folosind acest notebook.
- Colecție OpenSearch Serverless – Aceasta este baza de date vectorială pentru stocarea și preluarea înglobărilor.
- Conducta OSI – Acesta este canalul pentru ingerarea datelor în OpenSearch Serverless.
- Găleată S3 – Toate datele pentru această postare sunt stocate în această găleată.
Șablonul CloudFormation stabilește configurația conductei necesară pentru a configura conducta OSI cu HTTP ca sursă și indexul OpenSearch Serverless ca receptor. Caietul SageMaker 2_data_ingestion.ipynb afișează cum să ingerați date în conductă folosind Cereri Bibliotecă HTTP.
De asemenea, șablonul CloudFormation creează reţea, criptare și accesul la date politicile necesare pentru colecția dvs. OpenSearch Serverless. Actualizați aceste politici pentru a aplica permisiunile cu cel mai mic privilegiu.
Numele șablonului CloudFormation și numele indexului OpenSearch Service sunt menționate în blocnotesul SageMaker 3_rag_inference.ipynb. Dacă modificați numele implicite, asigurați-vă că le actualizați în blocnotes.
Testați soluția
După ce ați creat stiva CloudFormation, puteți testa soluția. Parcurgeți următorii pași:
- Pe consola SageMaker, alegeți notebook-uri în panoul de navigare.
- Selectați
MultimodalNotebookInstanceȘi alegeți Deschideți JupyterLab.
- In Browser de fișiere, treceți la folderul caiete pentru a vedea caietele și fișierele suport.
Caietele sunt numerotate în ordinea în care rulează. Instrucțiunile și comentariile din fiecare caiet descriu acțiunile efectuate de acel caiet. Rulăm aceste caiete unul câte unul.
- Alege
1_data_prep.ipynbpentru a-l deschide în JupyterLab. - Pe Alerga meniu, alegeți Rulați toate celulele pentru a rula codul din acest caiet.
Acest caiet va descărca o versiune disponibilă publicului punte de alunecare, convertiți fiecare diapozitiv în formatul de fișier JPG și încărcați-le în compartimentul S3.
- Alege
2_data_ingestion.ipynbpentru a-l deschide în JupyterLab. - Pe Alerga meniu, alegeți Rulați toate celulele pentru a rula codul din acest caiet.
În acest blocnotes, creați un index în colecția OpenSearch Serverless. Acest index stochează datele de încorporare pentru pachetul de diapozitive. Vezi următorul cod:
Utilizați modelele Claude 3 Sonnet și Amazon Titan Text Embeddings pentru a converti imaginile JPG create în blocnotesul anterior în înglobări vectoriale. Aceste înglobări și metadate suplimentare (cum ar fi calea S3 și descrierea fișierului imagine) sunt stocate în index împreună cu înglobările. Următorul fragment de cod arată modul în care Claude 3 Sonnet generează descrieri de imagini:
Descrierile imaginilor sunt transmise modelului Amazon Titan Text Embeddings pentru a genera înglobări vectoriale. Aceste înglobări și metadate suplimentare (cum ar fi calea S3 și descrierea fișierului imagine) sunt stocate în index împreună cu înglobările. Următorul fragment de cod arată apelul către modelul Amazon Titan Text Embeddings:
Datele sunt ingerate în indexul OpenSearch Serverless prin efectuarea unui apel API către conducta OSI. Următorul fragment de cod arată apelul efectuat folosind biblioteca Requests HTTP:
- Alege
3_rag_inference.ipynbpentru a-l deschide în JupyterLab. - Pe Alerga meniu, alegeți Rulați toate celulele pentru a rula codul din acest caiet.
Acest notebook implementează soluția RAG: convertiți întrebarea utilizatorului în înglobări, găsiți o descriere a imaginii similare din baza de date vectorială și furnizați descrierea preluată lui Claude 3 Sonnet pentru a genera un răspuns la întrebarea utilizatorului. Utilizați următorul șablon de prompt:
Următorul fragment de cod oferă fluxul de lucru RAG:
REZULTATE
Următorul tabel conține câteva întrebări și răspunsuri ale utilizatorilor generate de implementarea noastră. The Întrebare coloana captează întrebarea utilizatorului și Răspunde coloana este răspunsul textual generat de Claude 3 Sonnet. The Imagine coloana arată potrivirea de diapozitive k-NN returnată de căutarea vectorială OpenSearch Serverless.
Rezultate RAG multimodale
| Întrebare | Răspunde | Imagine |
|---|---|---|
| Cum se compară Inf2 ca performanță cu instanțele EC2 comparabile? Am nevoie de numere. | Pe baza informațiilor furnizate în rezumat, numerele cheie de comparare a performanței date pentru instanțele Amazon EC2 Inf2 în comparație cu alte instanțe sunt: 1. Debit de până la 4 ori mai mare. 2. Latență de până la 10 ori mai mică. Rezumatul nu oferă numere specifice care compară instanțele Inf2 cu alte tipuri de instanțe EC2. Cu toate acestea, evidențiază îmbunătățirile de debit și latență ca fiind principalele avantaje de performanță ale instanțelor Inf2 față de instanțe comparabile pentru rularea modelelor AI generative. |  |
| Conform volantului AI/ML, ce oferă serviciile AWS AI/ML? | Pe baza rezumatului, serviciile AWS AI/ML oferă o serie de capabilități care alimentează un volant AI/ML. Acest volant constă în inovare în dezvoltarea de algoritmi noi și mai buni, care permit mai multe cazuri de utilizare și aplicații, conducând la o adoptare și o cerere mai largi, ceea ce, la rândul său, duce la investiții suplimentare în cercetare și optimizare pentru a stimula mai multă inovație. Serviciile AWS AI/ML par să ofere instrumentele, resursele și infrastructura pentru a sprijini acest ciclu continuu de inovare, dezvoltare de aplicații, adoptare și reinvestire în domeniul inteligenței artificiale și al învățării automate. |  |
| În comparație cu GPT-2, câți parametri mai are GPT-3? Care este diferența numerică dintre dimensiunea parametrului GPT-2 și GPT-3? | Conform informațiilor furnizate în rezumat, GPT-3 din 2020 a avut 175B (175 miliarde) parametri, în timp ce GPT-2 din 2019 avea 1.5B (1.5 miliarde) parametri. Prin urmare, diferența numerică dintre dimensiunea parametrilor GPT-2 și GPT-3 este de 173.5 miliarde de parametri. GPT-3 are de aproximativ 115 ori mai mulți parametri decât GPT-2. |  |
| Ce sunt quarkurile în fizica particulelor? | Din păcate, rezumatul dat nu conține nicio informație despre quarci în fizica particulelor. Rezumatul descrie o imagine legată de evoluția procesării limbajului natural și a tehnologiilor AI generative, dar nu menționează nimic despre fizica particulelor sau despre conceptul de quarci. |  |
Interogați-vă indexul
Puteți utiliza tablourile de bord OpenSearch pentru a interacționa cu API-ul OpenSearch pentru a rula teste rapide asupra indexului și a datelor ingerate.

A curăța
Pentru a evita costurile viitoare, ștergeți resursele. Puteți face acest lucru ștergând stiva folosind consola AWS CloudFormation.

Concluzie
Întreprinderile generează tot timpul conținut nou, iar slide-urile sunt o modalitate obișnuită de a partaja și de a disemina informații în interiorul organizației și extern cu clienții sau la conferințe. De-a lungul timpului, informațiile bogate pot rămâne îngropate și ascunse în modalități non-text, cum ar fi graficele și tabelele din aceste pachete de diapozitive.
Puteți folosi această soluție și puterea FM-urilor multimodale, cum ar fi Amazon Titan Text Embeddings și Claude 3 Sonnet pentru a descoperi noi informații sau a descoperi noi perspective asupra conținutului din slide-uri. Puteți încerca diferite modele Claude disponibile pe Amazon Bedrock prin actualizarea CLAUDE_MODEL_ID în globals.py fișier.
Aceasta este partea 2 a unei serii de trei părți. Am folosit Amazon Titan Multimodal Embeddings și modelul LLaVA în partea 1. În partea 3, vom compara abordările din partea 1 și partea 2.
Porțiuni din acest cod sunt lansate sub Licență Apache 2.0.
Despre autori
 Amit Arora este arhitect specialist AI și ML la Amazon Web Services, ajutând clienții întreprinderilor să folosească servicii de învățare automată bazate pe cloud pentru a-și scala rapid inovațiile. El este, de asemenea, lector adjunct în programul MS de știință a datelor și analiză la Universitatea Georgetown din Washington DC
Amit Arora este arhitect specialist AI și ML la Amazon Web Services, ajutând clienții întreprinderilor să folosească servicii de învățare automată bazate pe cloud pentru a-și scala rapid inovațiile. El este, de asemenea, lector adjunct în programul MS de știință a datelor și analiză la Universitatea Georgetown din Washington DC
 Manju Prasad este arhitect senior de soluții la Amazon Web Services. Ea se concentrează pe furnizarea de îndrumări tehnice într-o varietate de domenii tehnice, inclusiv AI/ML. Înainte de a se alătura AWS, ea a proiectat și construit soluții pentru companii din sectorul serviciilor financiare și, de asemenea, pentru un startup. Este pasionată de împărtășirea cunoștințelor și de stimularea interesului pentru talentele emergente.
Manju Prasad este arhitect senior de soluții la Amazon Web Services. Ea se concentrează pe furnizarea de îndrumări tehnice într-o varietate de domenii tehnice, inclusiv AI/ML. Înainte de a se alătura AWS, ea a proiectat și construit soluții pentru companii din sectorul serviciilor financiare și, de asemenea, pentru un startup. Este pasionată de împărtășirea cunoștințelor și de stimularea interesului pentru talentele emergente.
 Archana Inapudi este arhitect senior de soluții la AWS, care sprijină un client strategic. Ea are peste un deceniu de experiență intersectorială în conducerea inițiativelor tehnice strategice. Archana este un membru aspirant al comunității de domeniu tehnic AI/ML de la AWS. Înainte de a se alătura AWS, Archana a condus o migrare de la sursele tradiționale de date izolate la Hadoop la o companie de asistență medicală. Este pasionată de utilizarea tehnologiei pentru a accelera creșterea, a oferi valoare clienților și a obține rezultate în afaceri.
Archana Inapudi este arhitect senior de soluții la AWS, care sprijină un client strategic. Ea are peste un deceniu de experiență intersectorială în conducerea inițiativelor tehnice strategice. Archana este un membru aspirant al comunității de domeniu tehnic AI/ML de la AWS. Înainte de a se alătura AWS, Archana a condus o migrare de la sursele tradiționale de date izolate la Hadoop la o companie de asistență medicală. Este pasionată de utilizarea tehnologiei pentru a accelera creșterea, a oferi valoare clienților și a obține rezultate în afaceri.
 Antara Raisa este arhitect de soluții AI și ML la Amazon Web Services, care sprijină clienții strategici din Dallas, Texas. Ea are, de asemenea, experiență anterioară de lucru cu mari parteneri la AWS, unde a lucrat ca arhitect de soluții de succes pentru parteneri pentru clienți centrați pe digital.
Antara Raisa este arhitect de soluții AI și ML la Amazon Web Services, care sprijină clienții strategici din Dallas, Texas. Ea are, de asemenea, experiență anterioară de lucru cu mari parteneri la AWS, unde a lucrat ca arhitect de soluții de succes pentru parteneri pentru clienți centrați pe digital.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-2/

