Evoluțiile recente în învățarea automată (ML) au condus la modele din ce în ce mai mari, dintre care unele necesită sute de miliarde de parametri. Deși sunt mai puternice, instruirea și inferența asupra acestor modele necesită resurse de calcul semnificative. În ciuda disponibilității bibliotecilor de instruire distribuite avansate, este obișnuit ca locurile de muncă de instruire și inferență să aibă nevoie de sute de acceleratoare (GPU-uri sau cipuri ML create special, cum ar fi AWS Trainium și Inferentia AWS), și prin urmare zeci sau sute de instanțe.
În astfel de medii distribuite, observabilitatea atât a instanțelor, cât și a cipurilor ML devine cheia pentru reglarea fină a performanței modelului și optimizarea costurilor. Metricurile permit echipelor să înțeleagă comportamentul sarcinii de lucru și să optimizeze alocarea și utilizarea resurselor, să diagnosticheze anomaliile și să mărească eficiența generală a infrastructurii. Pentru oamenii de știință de date, utilizarea și saturația cipurilor ML sunt, de asemenea, relevante pentru planificarea capacității.
Această postare vă ghidează prin Model de observabilitate open source pentru AWS Inferentia, care vă arată cum să monitorizați performanța cipurilor ML, utilizate într-un Serviciul Amazon Elastic Kubernetes cluster (Amazon EKS), cu noduri de date bazate pe Cloud Elastic de calcul Amazon (Amazon EC2) instanțe de tip Inf1 și Inf2.
Modelul face parte din AWS CDK Observability Accelerator, un set de module cu opinii care să vă ajute să setați observabilitatea pentru clusterele Amazon EKS. AWS CDK Observability Accelerator este organizat în jurul modelelor, care sunt unități reutilizabile pentru implementarea mai multor resurse. Setul de modele de observabilitate open source instrumentează observabilitatea cu Grafana gestionată de Amazon tablouri de bord, an AWS Distro pentru OpenTelemetry colector pentru a colecta valori și Serviciul gestionat Amazon pentru Prometheus pentru a le depozita.
Prezentare generală a soluțiilor
Următoarea diagramă ilustrează arhitectura soluției.

Această soluție implementează un cluster Amazon EKS cu un grup de noduri care include instanțe Inf1.
Tipul AMI al grupului de noduri este AL2_x86_64_GPU, care folosește Amazon EKS optimizat accelerat Amazon Linux AMI. Pe lângă configurația standard AMI optimizată pentru Amazon EKS, AMI accelerată include Timpul de rulare NeuronX.
Pentru a accesa cipurile ML din Kubernetes, modelul implementează AWS Neuron plugin pentru dispozitiv.
Valorile sunt expuse la Amazon Managed Service pentru Prometheus de către neuron-monitor DaemonSet, care implementează un container minim, cu Instrumente pentru neuroni instalat. Mai exact, cel neuron-monitor DaemonSet rulează neuron-monitor comanda introdusă în neuron-monitor-prometheus.py script însoțitor (ambele comenzi fac parte din container):
Comanda folosește următoarele componente:
neuron-monitorcolectează valori și statistici de la aplicațiile Neuron care rulează pe sistem și transmite datele colectate către stdout în Format JSONneuron-monitor-prometheus.pymapează și expune datele de telemetrie din formatul JSON în format compatibil cu Prometheus
Datele sunt vizualizate în Amazon Managed Grafana prin tabloul de bord corespunzător.
Restul configurației pentru a colecta și vizualiza valorile cu Amazon Managed Service pentru Prometheus și Amazon Managed Grafana este similară cu cea utilizată în alte modele bazate pe sursă deschisă, care sunt incluse în AWS Observability Accelerator for CDK Depozitul GitHub.
Cerințe preliminare
Aveți nevoie de următoarele pentru a parcurge pașii din această postare:
Configurați mediul înconjurător
Parcurgeți următorii pași pentru a vă configura mediul:
- Deschideți o fereastră de terminal și executați următoarele comenzi:
- Preluați ID-urile spațiului de lucru ale oricărui spațiu de lucru Amazon Managed Grafana existent:
Următorul este exemplul nostru de rezultat:
- Atribuiți valorile lui
idșiendpointla următoarele variabile de mediu:
COA_AMG_ENDPOINT_URL trebuie să includă https://.
- Creați o cheie API Grafana din spațiul de lucru Amazon Managed Grafana:
- Stabilește un secret în Manager sistem AWS:
Secretul va fi accesat de suplimentul External Secrets și va fi disponibil ca secret nativ Kubernetes în clusterul EKS.
Bootstrap mediul AWS CDK
Primul pas către orice implementare AWS CDK este bootstrap-ul mediului. Folosești cdk bootstrap comandă în AWS CDK CLI pentru a pregăti mediul (o combinație de cont AWS și Regiunea AWS) cu resursele necesare AWS CDK pentru a realiza implementări în acel mediu. Bootstrapping-ul AWS CDK este necesar pentru fiecare combinație de cont și regiune, așa că dacă ați încărcat deja AWS CDK într-o regiune, nu trebuie să repetați procesul de bootstrapping.
Implementați soluția
Parcurgeți următorii pași pentru a implementa soluția:
- Clonați cdk-aws-observability-accelerator depozit și instalați pachetele de dependență. Acest depozit conține cod AWS CDK v2 scris în TypeScript.
Se așteaptă ca setările reale pentru fișierele JSON de tablou de bord Grafana să fie specificate în contextul AWS CDK. Trebuie să actualizați context în cdk.json fișier, aflat în directorul curent. Locația tabloului de bord este specificată de fluxRepository.values.GRAFANA_NEURON_DASH_URL parametru și neuronNodeGroup este folosit pentru a seta tipul instanței, numărul și Magazin Amazon Elastic Block (Amazon EBS) dimensiune utilizată pentru noduri.
- Introduceți următorul fragment în
cdk.json, înlocuindcontext:
Puteți înlocui tipul instanței Inf1 cu Inf2 și puteți modifica dimensiunea după cum este necesar. Pentru a verifica disponibilitatea în Regiunea selectată, rulați următoarea comandă (modificare Values dupa cum crezi de cuviinta):
- Instalați dependențele proiectului:
- Rulați următoarele comenzi pentru a implementa modelul de observabilitate open source:
Validați soluția
Parcurgeți următorii pași pentru a valida soluția:
- Pornește
update-kubeconfigcomanda. Ar trebui să puteți obține comanda din mesajul de ieșire al comenzii anterioare:
- Verificați resursele pe care le-ați creat:
Următoarea captură de ecran arată rezultatul nostru exemplu.

- Asigurați-vă că
neuron-device-plugin-daemonsetDaemonSet rulează:
Următoarele sunt rezultatele așteptate:
- Confirmați că
neuron-monitorDaemonSet rulează:
Următoarele sunt rezultatele așteptate:
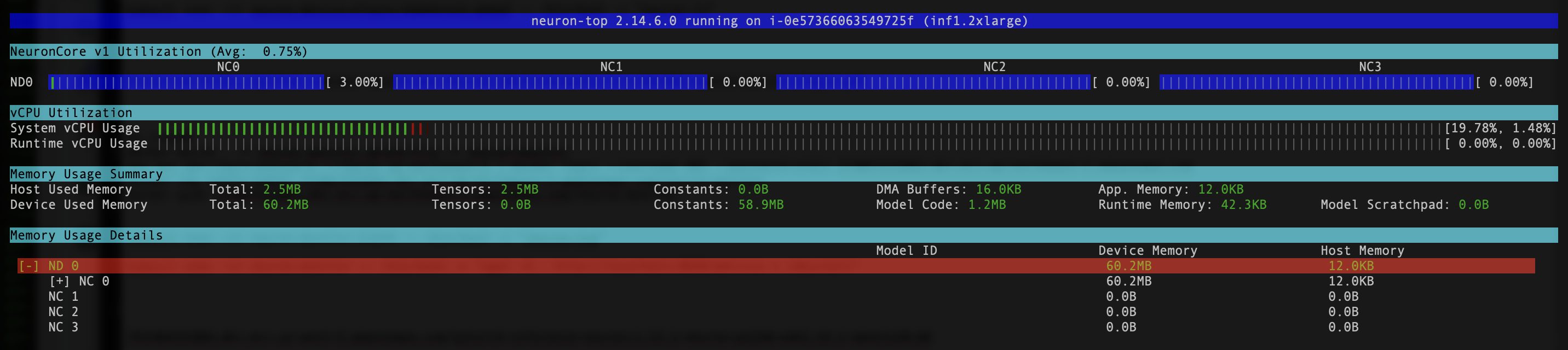
- Pentru a verifica dacă dispozitivele și nucleele Neuron sunt vizibile, rulați
neuron-lsșineuron-topcomenzi de la, de exemplu, podul de monitorizare a neuronilor (puteți obține numele podului din rezultatulkubectl get pods -A):
Următoarea captură de ecran arată rezultatul așteptat.

Următoarea captură de ecran arată rezultatul așteptat.
Vizualizați datele folosind tabloul de bord Grafana Neuron
Conectați-vă la spațiul dvs. de lucru Amazon Managed Grafana și navigați la Tablourile de bord panou. Ar trebui să vedeți un tablou de bord numit Neuron / Monitor.
Pentru a vedea câteva valori interesante pe tabloul de bord Grafana, aplicăm următorul manifest:
Acesta este un exemplu de încărcare de lucru care compilează fișierul modelul torchvision ResNet50 și rulează inferențe repetitive într-o buclă pentru a genera date de telemetrie.
Pentru a verifica că podul a fost implementat cu succes, rulați următorul cod:
Ar trebui să vedeți un pod numit pytorch-inference-resnet50.
După câteva minute, uitându-mă în Neuron / Monitor tabloul de bord, ar trebui să vedeți valorile adunate similare cu următoarele capturi de ecran.




Grafana Operator și Flux lucrează întotdeauna împreună pentru a vă sincroniza tablourile de bord cu Git. Dacă ștergeți tablourile de bord din întâmplare, acestea vor fi reprovizionate automat.
A curăța
Puteți șterge întreaga stivă AWS CDK cu următoarea comandă:
Concluzie
În această postare, v-am arătat cum să introduceți observabilitatea, cu instrumente open source, într-un cluster EKS cu un plan de date care rulează instanțe EC2 Inf1. Am început prin a selecta AMI-ul accelerat optimizat pentru Amazon EKS pentru nodurile planului de date, care include durata de rulare a containerului Neuron, oferind acces la dispozitivele AWS Inferentia și Trainium Neuron. Apoi, pentru a expune nucleele și dispozitivele Neuron la Kubernetes, am implementat pluginul pentru dispozitivul Neuron. Colectarea și maparea efectivă a datelor de telemetrie în format compatibil cu Prometheus a fost realizată prin neuron-monitor și neuron-monitor-prometheus.py. Valorile au fost obținute de la Amazon Managed Service pentru Prometheus și afișate pe tabloul de bord Neuron al Amazon Managed Grafana.
Vă recomandăm să explorați modele de observabilitate suplimentare în AWS Observability Accelerator pentru CDK Repoziție GitHub. Pentru a afla mai multe despre Neuron, consultați Documentația AWS Neuron.
Despre autor
 Riccardo Freschi este arhitect senior de soluții la AWS, concentrându-se pe modernizarea aplicațiilor. El lucrează îndeaproape cu partenerii și clienții pentru a-i ajuta să-și transforme peisajul IT în călătoria lor către AWS Cloud prin refactorizarea aplicațiilor existente și construind altele noi.
Riccardo Freschi este arhitect senior de soluții la AWS, concentrându-se pe modernizarea aplicațiilor. El lucrează îndeaproape cu partenerii și clienții pentru a-i ajuta să-și transforme peisajul IT în călătoria lor către AWS Cloud prin refactorizarea aplicațiilor existente și construind altele noi.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/open-source-observability-for-aws-inferentia-nodes-within-amazon-eks-clusters/

