Obecnie klienci wszystkich branż — czy to usług finansowych, opieki zdrowotnej i nauk przyrodniczych, podróży i hotelarstwa, mediów i rozrywki, telekomunikacji, oprogramowania jako usługi (SaaS), a nawet dostawców modeli zastrzeżonych — korzystają z dużych modeli językowych (LLM) do Twórz aplikacje, takie jak chatboty z pytaniami i odpowiedziami (QnA), wyszukiwarki i bazy wiedzy. Te generatywna sztuczna inteligencja aplikacje służą nie tylko automatyzacji istniejących procesów biznesowych, ale także mają możliwość transformacji doświadczeń klientów korzystających z tych aplikacji. Wraz z postępem w LLM, takich jak Instrukcja Mixtral-8x7B, pochodna architektur takich jak mieszanka ekspertów (MoE)klienci stale szukają sposobów na poprawę wydajności i dokładności generatywnych aplikacji AI, umożliwiając im jednocześnie efektywne korzystanie z szerszej gamy modeli zamkniętych i otwartych.
Zwykle stosuje się wiele technik w celu poprawy dokładności i wydajności wyników LLM, takich jak dostrajanie za pomocą efektywne dostrajanie parametrów (PEFT), uczenie wzmacniające na podstawie informacji zwrotnej od człowieka (RLHF)i występując destylacja wiedzy. Jednak budując generatywne aplikacje AI, można skorzystać z alternatywnego rozwiązania, które pozwala na dynamiczne włączenie wiedzy zewnętrznej i pozwala kontrolować informacje wykorzystywane do generowania bez konieczności dostrajania istniejącego modelu podstawowego. W tym miejscu pojawia się technologia Augmented Generation Retrieval (RAG), szczególnie w przypadku generatywnych zastosowań sztucznej inteligencji, w przeciwieństwie do droższych i niezawodnych alternatyw dostrajających, które omówiliśmy. Jeśli wdrażasz złożone aplikacje RAG do swoich codziennych zadań, możesz napotkać typowe wyzwania związane z systemami RAG, takie jak niedokładne wyszukiwanie, rosnący rozmiar i złożoność dokumentów oraz przepełnienie kontekstu, co może znacząco wpłynąć na jakość i wiarygodność generowanych odpowiedzi .
W tym poście omówiono wzorce RAG mające na celu poprawę dokładności odpowiedzi za pomocą LangChain i narzędzi, takich jak moduł pobierania dokumentów nadrzędnych, a także techniki takie jak kompresja kontekstowa, aby umożliwić programistom ulepszanie istniejących generatywnych aplikacji AI.
Omówienie rozwiązania
W tym poście demonstrujemy użycie generatora tekstu Mixtral-8x7B Instruct w połączeniu z modelem osadzania BGE Large En w celu wydajnego skonstruowania systemu RAG QnA na notatniku Amazon SageMaker przy użyciu narzędzia do wyszukiwania dokumentów nadrzędnych i techniki kompresji kontekstowej. Poniższy diagram ilustruje architekturę tego rozwiązania.
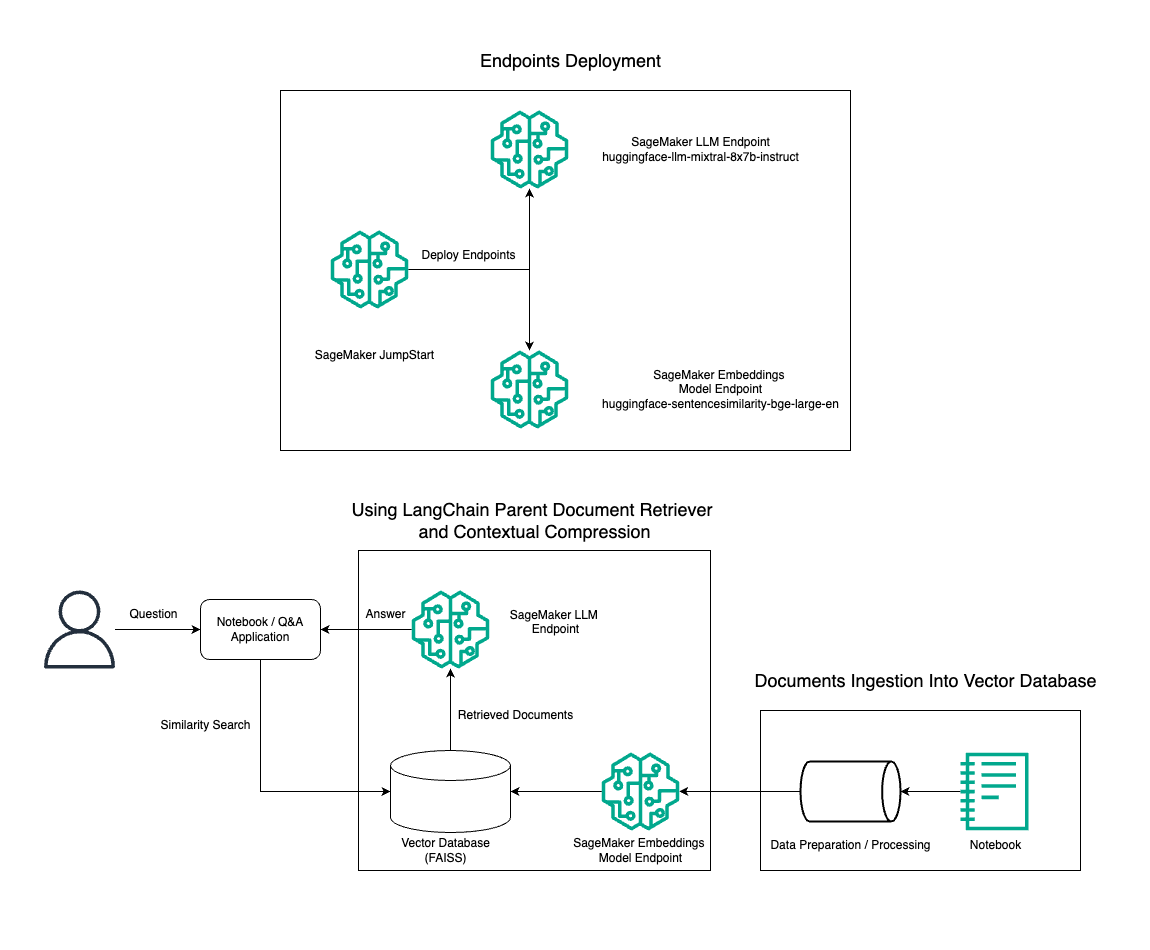
Możesz wdrożyć to rozwiązanie za pomocą kilku kliknięć Amazon SageMaker JumpStart, w pełni zarządzana platforma oferująca najnowocześniejsze modele podstawowe do różnych zastosowań, takich jak pisanie treści, generowanie kodu, odpowiadanie na pytania, copywriting, podsumowywanie, klasyfikacja i wyszukiwanie informacji. Zapewnia kolekcję wstępnie wyszkolonych modeli, które można szybko i łatwo wdrożyć, przyspieszając tworzenie i wdrażanie aplikacji do uczenia maszynowego (ML). Jednym z kluczowych komponentów SageMaker JumpStart jest Model Hub, który oferuje obszerny katalog wstępnie wytrenowanych modeli, takich jak Mixtral-8x7B, do różnych zadań.
Mixtral-8x7B wykorzystuje architekturę MoE. Architektura ta pozwala różnym częściom sieci neuronowej specjalizować się w różnych zadaniach, skutecznie dzieląc obciążenie pracą pomiędzy wielu ekspertów. Takie podejście umożliwia efektywne szkolenie i wdrażanie większych modeli w porównaniu z tradycyjnymi architekturami.
Jedną z głównych zalet architektury MoE jest jej skalowalność. Dzieląc obciążenie pracą na wielu ekspertów, modele MoE można szkolić na większych zbiorach danych i osiągać lepszą wydajność niż tradycyjne modele o tym samym rozmiarze. Ponadto modele MoE mogą być bardziej wydajne podczas wnioskowania, ponieważ dla danych danych wejściowych należy aktywować tylko podzbiór ekspertów.
Więcej informacji na temat Mixtral-8x7B Instruct on AWS można znaleźć w artykule Mixtral-8x7B jest teraz dostępny w Amazon SageMaker JumpStart. Model Mixtral-8x7B udostępniany jest na liberalnej licencji Apache 2.0, do użytku bez ograniczeń.
W tym poście omawiamy, jak możesz z niego skorzystać LangChain do tworzenia skutecznych i wydajniejszych aplikacji RAG. LangChain to biblioteka Pythona typu open source przeznaczona do tworzenia aplikacji za pomocą LLM. Zapewnia modułową i elastyczną platformę do łączenia LLM z innymi komponentami, takimi jak bazy wiedzy, systemy wyszukiwania i inne narzędzia AI, w celu tworzenia wydajnych i konfigurowalnych aplikacji.
Przejdziemy przez proces budowy rurociągu RAG na SageMakerze z Mixtral-8x7B. Używamy modelu generowania tekstu Mixtral-8x7B Instruct z modelem osadzania BGE Large En, aby stworzyć wydajny system QnA przy użyciu RAG na notebooku SageMaker. Używamy instancji ml.t3.medium, aby zademonstrować wdrażanie LLM za pośrednictwem SageMaker JumpStart, do którego można uzyskać dostęp poprzez punkt końcowy API wygenerowany przez SageMaker. Taka konfiguracja pozwala na eksplorację, eksperymentowanie i optymalizację zaawansowanych technik RAG za pomocą LangChain. Ilustrujemy również integrację sklepu FAISS Embedding z przepływem pracy RAG, podkreślając jego rolę w przechowywaniu i odzyskiwaniu osadzonych elementów w celu zwiększenia wydajności systemu.
Przeprowadzamy krótki przegląd notatnika SageMaker. Bardziej szczegółowe instrukcje krok po kroku można znaleźć w Zaawansowane wzorce RAG z Mixtral w repozytorium GitHub SageMaker Jumpstart.
Zapotrzebowanie na zaawansowane wzorce RAG
Zaawansowane wzorce RAG są niezbędne do poprawy obecnych możliwości LLM w przetwarzaniu, rozumieniu i generowaniu tekstu podobnego do ludzkiego. W miarę wzrostu rozmiaru i złożoności dokumentów reprezentowanie wielu aspektów dokumentu w jednym osadzeniu może prowadzić do utraty specyficzności. Chociaż uchwycenie ogólnej istoty dokumentu jest niezbędne, równie ważne jest rozpoznanie i przedstawienie różnorodnych podkontekstów w nim zawartych. Jest to wyzwanie, przed którym często stajesz podczas pracy z większymi dokumentami. Kolejnym wyzwaniem związanym z RAG jest to, że podczas pobierania nie jesteś świadomy konkretnych zapytań, z którymi poradzi sobie Twój system przechowywania dokumentów po przetworzeniu. Może to prowadzić do tego, że informacje najbardziej istotne dla zapytania zostaną ukryte pod tekstem (przepełnienie kontekstu). Aby ograniczyć awarie i ulepszyć istniejącą architekturę RAG, można użyć zaawansowanych wzorców RAG (wyszukiwanie dokumentów nadrzędnych i kompresja kontekstowa), aby ograniczyć błędy wyszukiwania, poprawić jakość odpowiedzi i umożliwić złożoną obsługę pytań.
Dzięki technikom omówionym w tym poście możesz stawić czoła kluczowym wyzwaniom związanym z wyszukiwaniem i integracją wiedzy zewnętrznej, umożliwiając aplikacji dostarczanie bardziej precyzyjnych i uwzględniających kontekst odpowiedzi.
W poniższych sekcjach dowiemy się, jak to zrobić narzędzia do pobierania dokumentów nadrzędnych i kompresja kontekstowa może pomóc Ci uporać się z niektórymi problemami, które omówiliśmy.
Odzyskiwanie dokumentów nadrzędnych
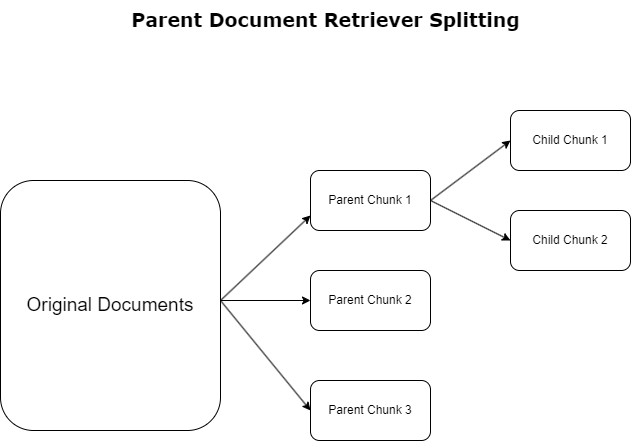
W poprzedniej sekcji podkreśliliśmy wyzwania, jakie napotykają aplikacje RAG podczas pracy z obszernymi dokumentami. Aby sprostać tym wyzwaniom, narzędzia do pobierania dokumentów nadrzędnych kategoryzować i oznaczać dokumenty przychodzące jako dokumenty rodziców. Dokumenty te są uznawane za wszechstronne, ale nie są bezpośrednio wykorzystywane w ich oryginalnej formie do osadzania. Zamiast kompresować cały dokument w jednym osadzeniu, narzędzia do pobierania dokumentów nadrzędnych analizują te dokumenty nadrzędne dokumenty dziecka. Każdy dokument podrzędny przechwytuje odrębne aspekty lub tematy z szerszego dokumentu nadrzędnego. Po zidentyfikowaniu tych segmentów podrzędnych, każdemu z nich przypisuje się indywidualne osadzania, oddając ich specyficzną istotę tematyczną (patrz poniższy diagram). Podczas pobierania wywoływany jest dokument nadrzędny. Technika ta zapewnia ukierunkowane, ale szerokie możliwości wyszukiwania, zapewniając LLM szerszą perspektywę. Narzędzia do wyszukiwania dokumentów nadrzędnych zapewniają LLM podwójną zaletę: specyfikę osadzania dokumentów podrzędnych w celu precyzyjnego i odpowiedniego wyszukiwania informacji, w połączeniu z wywoływaniem dokumentów nadrzędnych w celu generowania odpowiedzi, co wzbogaca wyniki LLM o wielowarstwowy i dokładny kontekst.
Kompresja kontekstowa
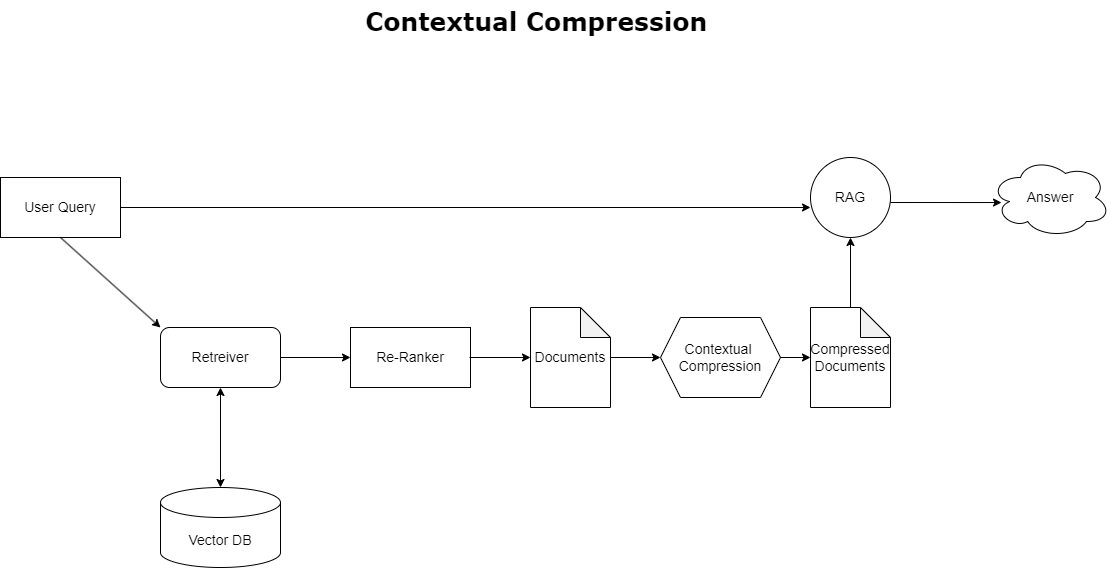
Aby rozwiązać omówiony wcześniej problem przepełnienia kontekstu, możesz użyć kompresja kontekstowa do kompresji i filtrowania pobranych dokumentów zgodnie z kontekstem zapytania, tak aby przechowywane i przetwarzane były tylko istotne informacje. Osiąga się to poprzez połączenie podstawowego modułu pobierania do wstępnego pobierania dokumentów i kompresora dokumentów do udoskonalania tych dokumentów poprzez ograniczanie ich zawartości lub całkowite ich wykluczanie na podstawie trafności, jak pokazano na poniższym schemacie. To uproszczone podejście, ułatwione przez kontekstowy moduł pobierania kompresji, znacznie zwiększa wydajność aplikacji RAG, zapewniając metodę wyodrębniania i wykorzystywania tylko tego, co niezbędne z masy informacji. Rozwiązuje problem przeciążenia informacji i nieistotnego przetwarzania danych, co prowadzi do poprawy jakości odpowiedzi, bardziej opłacalnych operacji LLM i ogólnie płynniejszego procesu wyszukiwania. Zasadniczo jest to filtr, który dopasowuje informacje do zapytania, co czyni go bardzo potrzebnym narzędziem dla programistów chcących zoptymalizować swoje aplikacje RAG w celu uzyskania lepszej wydajności i zadowolenia użytkownika.
Wymagania wstępne
Jeśli dopiero zaczynasz korzystać z SageMaker, zapoznaj się z sekcją Przewodnik programistyczny Amazon SageMaker.
Zanim zaczniesz korzystać z rozwiązania, utwórz konto AWS. Kiedy tworzysz konto AWS, otrzymujesz tożsamość pojedynczego logowania (SSO), która ma pełny dostęp do wszystkich usług i zasobów AWS na koncie. Ta tożsamość nazywa się kontem AWS użytkownik root.
Logowanie do Konsola zarządzania AWS użycie adresu e-mail i hasła użytego do utworzenia konta zapewnia pełny dostęp do wszystkich zasobów AWS na Twoim koncie. Zdecydowanie zalecamy, aby nie używać użytkownika root do codziennych zadań, nawet administracyjnych.
Zamiast tego trzymaj się najlepsze praktyki dotyczące bezpieczeństwa in AWS Zarządzanie tożsamością i dostępem (Ja jestem i utwórz użytkownika i grupę administracyjną. Następnie bezpiecznie zablokuj poświadczenia użytkownika root i używaj ich do wykonywania tylko kilku zadań związanych z zarządzaniem kontami i usługami.
Model Mixtral-8x7b wymaga instancji ml.g5.48xlarge. SageMaker JumpStart zapewnia uproszczony sposób dostępu i wdrażania ponad 100 różnych modeli open source i podstawowych modeli innych firm. W celu uruchom punkt końcowy do hostowania Mixtral-8x7B z SageMaker JumpStart, może być konieczne zażądanie zwiększenia limitu usług, aby uzyskać dostęp do instancji ml.g5.48xlarge na potrzeby użycia punktu końcowego. Możesz zażądać zwiększenia limitu usług przez konsolę, Interfejs wiersza poleceń AWS (AWS CLI) lub API, aby umożliwić dostęp do tych dodatkowych zasobów.
Skonfiguruj instancję notatnika SageMaker i zainstaluj zależności
Aby rozpocząć, utwórz instancję notatnika SageMaker i zainstaluj wymagane zależności. Patrz GitHub repo aby zapewnić pomyślną konfigurację. Po skonfigurowaniu instancji notesu możesz wdrożyć model.
Możesz także uruchomić notatnik lokalnie w preferowanym zintegrowanym środowisku programistycznym (IDE). Upewnij się, że masz zainstalowane laboratorium notebooków Jupyter.
Wdróż model
Wdróż model Mixtral-8X7B Instruct LLM w SageMaker JumpStart:
Wdróż model osadzania BGE Large En w SageMaker JumpStart:
Skonfiguruj LangChain
Po zaimportowaniu wszystkich niezbędnych bibliotek i wdrożeniu modelu Mixtral-8x7B i modelu osadzania BGE Large En, możesz teraz skonfigurować LangChain. Instrukcje krok po kroku można znaleźć w GitHub repo.
Przygotowywanie danych
W tym poście używamy listów Amazon do akcjonariuszy z kilku lat jako korpusu tekstowego, na którym można przeprowadzić QnA. Bardziej szczegółowe kroki przygotowania danych można znaleźć w artykule GitHub repo.
Odpowiadanie na pytania
Po przygotowaniu danych możesz użyć opakowania dostarczonego przez LangChain, które otacza magazyn wektorów i pobiera dane wejściowe dla LLM. To opakowanie wykonuje następujące kroki:
- Weź udział w pytaniu wejściowym.
- Utwórz osadzenie pytania.
- Zdobądź odpowiednie dokumenty.
- Umieść dokumenty i pytanie w podpowiedzi.
- Wywołaj model za pomocą podpowiedzi i wygeneruj odpowiedź w czytelny sposób.
Teraz, gdy sklep wektorowy jest już gotowy, możesz zacząć zadawać pytania:
Zwykły łańcuch retrievera
W poprzednim scenariuszu omówiliśmy szybki i prosty sposób uzyskania kontekstowej odpowiedzi na Twoje pytanie. Przyjrzyjmy się teraz bardziej konfigurowalnej opcji za pomocą RetrievalQA, w której możesz dostosować sposób, w jaki pobrane dokumenty powinny być dodawane do zachęty za pomocą parametru chain_type. Ponadto, aby kontrolować liczbę odpowiednich dokumentów, które należy pobrać, możesz zmienić parametr k w poniższym kodzie, aby wyświetlić różne wyniki. W wielu scenariuszach możesz chcieć wiedzieć, jakich dokumentów źródłowych użył LLM do wygenerowania odpowiedzi. Możesz uzyskać te dokumenty na wyjściu za pomocą return_source_documents, która zwraca dokumenty dodane do kontekstu zachęty LLM. RetrievalQA umożliwia także udostępnienie niestandardowego szablonu podpowiedzi, który może być specyficzny dla modelu.
Zadajmy pytanie:
Łańcuch pobierania dokumentów nadrzędnych
Przyjrzyjmy się bardziej zaawansowanej opcji RAG za pomocą RodzicDocumentRetriever. Podczas pracy z wyszukiwaniem dokumentów możesz napotkać kompromis między przechowywaniem małych fragmentów dokumentu w celu dokładnego osadzenia a większymi dokumentami w celu zachowania większego kontekstu. Nadrzędny moduł pobierania dokumentów zapewnia tę równowagę, dzieląc i przechowując małe fragmenty danych.
Używamy a parent_splitter aby podzielić oryginalne dokumenty na większe części zwane dokumentami nadrzędnymi i a child_splitter aby utworzyć mniejsze dokumenty podrzędne z oryginalnych dokumentów:
Dokumenty podrzędne są następnie indeksowane w magazynie wektorowym przy użyciu osadzania. Umożliwia to efektywne wyszukiwanie odpowiednich dokumentów podrzędnych w oparciu o podobieństwo. Aby pobrać istotne informacje, moduł pobierania dokumentów nadrzędnych najpierw pobiera dokumenty podrzędne z magazynu wektorów. Następnie wyszukuje identyfikatory nadrzędne dla tych dokumentów podrzędnych i zwraca odpowiadające im większe dokumenty nadrzędne.
Zadajmy pytanie:
Kontekstowy łańcuch kompresji
Przyjrzyjmy się innej zaawansowanej opcji RAG o nazwie kompresja kontekstowa. Jednym z wyzwań związanych z odzyskiwaniem jest to, że zazwyczaj nie znamy konkretnych zapytań, z jakimi będzie musiał się zmierzyć Twój system przechowywania dokumentów podczas przyjmowania danych do systemu. Oznacza to, że informacje najbardziej istotne dla zapytania mogą być ukryte w dokumencie zawierającym wiele nieistotnego tekstu. Przekazanie całego dokumentu przez aplikację może prowadzić do droższych połączeń LLM i gorszych odpowiedzi.
Narzędzie do wyszukiwania kompresji kontekstowej rozwiązuje problem odzyskiwania odpowiednich informacji z systemu przechowywania dokumentów, gdzie istotne dane mogą być ukryte w dokumentach zawierających dużo tekstu. Kompresując i filtrując pobrane dokumenty na podstawie danego kontekstu zapytania, zwracane są tylko najbardziej istotne informacje.
Aby skorzystać z narzędzia do pobierania kompresji kontekstowej, będziesz potrzebować:
- Base retriever – Jest to początkowy moduł pobierający, który pobiera dokumenty z systemu przechowywania na podstawie zapytania
- Kompresor dokumentów – Komponent ten pobiera początkowo pobrane dokumenty i je skraca, redukując zawartość poszczególnych dokumentów lub całkowicie usuwając nieistotne dokumenty, wykorzystując kontekst zapytania do określenia trafności
Dodanie kompresji kontekstowej za pomocą ekstraktora łańcucha LLM
Najpierw owiń swojego base retrievera folią ContextualCompressionRetriever. Dodasz Ekstraktor LLMCain, który wykona iterację po początkowo zwróconych dokumentach i wyodrębni z każdego z nich tylko treść istotną dla zapytania.
Zainicjuj łańcuch za pomocą ContextualCompressionRetriever ze związkiem LLMChainExtractor i przekaż monit za pośrednictwem chain_type_kwargs argumenty.
Zadajmy pytanie:
Filtruj dokumenty za pomocą filtra łańcuchowego LLM
Połączenia Filtr LLMCain to nieco prostszy, ale solidniejszy kompresor, który wykorzystuje łańcuch LLM do decydowania, które z początkowo pobranych dokumentów należy odfiltrować, a które zwrócić, bez manipulacji zawartością dokumentu:
Zainicjuj łańcuch za pomocą ContextualCompressionRetriever ze związkiem LLMChainFilter i przekaż monit za pośrednictwem chain_type_kwargs argumenty.
Zadajmy pytanie:
Porównaj wyniki
W poniższej tabeli porównano wyniki różnych zapytań w oparciu o technikę.
| Technika | Zapytanie 1 | Zapytanie 2 | Porównanie |
| Jak ewoluował AWS? | Dlaczego Amazon odniósł sukces? | ||
| Regularne wyjście łańcucha retrievera | AWS (Amazon Web Services) ewoluowało od początkowo nierentownej inwestycji do firmy generującej roczne przychody na poziomie 85 miliardów dolarów i charakteryzującej się dużą rentownością, oferującej szeroki zakres usług i funkcji oraz stającej się znaczącą częścią portfolio Amazon. Pomimo sceptycyzmu i krótkotrwałych trudności, AWS w dalszym ciągu wprowadzał innowacje, przyciągał nowych klientów i migrował aktywnych klientów, oferując korzyści takie jak elastyczność, innowacyjność, efektywność kosztowa i bezpieczeństwo. AWS rozszerzył także swoje długoterminowe inwestycje, w tym rozwój chipów, aby zapewnić nowe możliwości i zmienić to, co jest możliwe dla swoich klientów. | Amazon odnosi sukcesy dzięki ciągłym innowacjom i ekspansji w nowych obszarach, takich jak usługi w zakresie infrastruktury technologicznej, cyfrowe urządzenia do czytania, osobiści asystenci sterowani głosem i nowe modele biznesowe, takie jak rynek stron trzecich. Do jego sukcesu przyczynia się również zdolność do szybkiego skalowania operacji, co widać w szybkim rozwoju sieci realizacji zamówień i sieci transportowych. Ponadto skupienie się Amazona na optymalizacji i wzroście wydajności procesów zaowocowało poprawą produktywności i redukcją kosztów. Przykład Amazon Business podkreśla zdolność firmy do wykorzystania swoich mocnych stron w zakresie handlu elektronicznego i logistyki w różnych sektorach. | Na podstawie odpowiedzi ze zwykłego łańcucha retrieverów zauważamy, że chociaż zapewnia długie odpowiedzi, cierpi na przepełnienie kontekstu i nie wspomina o żadnych istotnych szczegółach z korpusu w odniesieniu do odpowiedzi na dostarczone zapytanie. Regularny łańcuch wyszukiwania nie jest w stanie uchwycić niuansów dzięki dogłębnemu wglądowi w kontekst, potencjalnie pomijając krytyczne aspekty dokumentu. |
| Dane wyjściowe funkcji odzyskiwania dokumentów nadrzędnych | AWS (Amazon Web Services) zaczęło się od ubogiego w funkcje początkowego uruchomienia usługi Elastic Compute Cloud (EC2) w 2006 roku, udostępniając tylko jeden rozmiar instancji, w jednym centrum danych, w jednym regionie świata, z tylko instancjami systemu operacyjnego Linux i bez wielu kluczowych funkcji, takich jak monitorowanie, równoważenie obciążenia, automatyczne skalowanie czy pamięć trwała. Jednak sukces AWS pozwolił im szybko iterować i dodawać brakujące możliwości, ostatecznie rozszerzając ofertę, oferując różne smaki, rozmiary i optymalizacje obliczeń, pamięci masowej i sieci, a także opracowując własne chipy (Graviton), aby jeszcze bardziej podnieść cenę i wydajność . Iteracyjny proces innowacji AWS wymagał znacznych inwestycji w zasoby finansowe i ludzkie na przestrzeni 20 lat, często na długo przed terminem zwrotu, aby zaspokoić potrzeby klientów i poprawić długoterminowe doświadczenia klientów, lojalność i zyski dla akcjonariuszy. | Amazon odnosi sukcesy dzięki zdolności do ciągłego wprowadzania innowacji, dostosowywania się do zmieniających się warunków rynkowych i zaspokajania potrzeb klientów w różnych segmentach rynku. Widać to wyraźnie po sukcesie Amazon Business, który osiągnął roczną sprzedaż brutto w wysokości około 35 miliardów dolarów dzięki zapewnianiu klientom biznesowym wyboru, wartości i wygody. Inwestycje Amazona w możliwości związane z handlem elektronicznym i logistyką umożliwiły także utworzenie usług takich jak Kup z Prime, które pomagają sprzedawcom posiadającym witryny internetowe skierowane bezpośrednio do konsumentów zwiększać konwersję od wyświetleń do zakupów. | Nadrzędny moduł wyszukiwania dokumentów zagłębia się w specyfikę strategii rozwoju AWS, w tym w iteracyjny proces dodawania nowych funkcji w oparciu o opinie klientów i szczegółową drogę od początkowego wprowadzenia na rynek ubogiego w funkcje do dominującej pozycji na rynku, zapewniając jednocześnie odpowiedź bogatą w kontekst . Odpowiedzi obejmują szeroki zakres aspektów, od innowacji technicznych i strategii rynkowej po efektywność organizacyjną i orientację na klienta, zapewniając całościowy obraz czynników przyczyniających się do sukcesu wraz z przykładami. Można to przypisać ukierunkowanym, ale szerokim możliwościom wyszukiwania narzędzia do pobierania dokumentów nadrzędnych. |
| Ekstraktor łańcucha LLM: Kontekstowe wyjście kompresji | AWS ewoluował, zaczynając od małego projektu w Amazonie, wymagającego znacznych inwestycji kapitałowych i spotykającego się ze sceptycyzmem zarówno wewnątrz, jak i na zewnątrz firmy. Jednak AWS miał przewagę nad potencjalnymi konkurentami i wierzył w wartość, jaką może przynieść klientom i Amazonowi. Firma AWS podjęła długoterminowe zobowiązanie do kontynuowania inwestycji, w wyniku czego w 3,300 r. wprowadzono ponad 2022 nowych funkcji i usług. AWS zmienił sposób, w jaki klienci zarządzają swoją infrastrukturą technologiczną, i stał się firmą generującą roczne przychody na poziomie 85 miliardów dolarów i charakteryzującą się dużą rentownością. AWS stale udoskonala także swoją ofertę, na przykład ulepszając EC2 o dodatkowe funkcje i usługi po jego pierwszym uruchomieniu. | W podanym kontekście sukces Amazona można przypisać jego strategicznej ekspansji z platformy sprzedaży książek na rynek globalny z tętniącym życiem ekosystemem sprzedawców zewnętrznych, wczesnej inwestycji w AWS, innowacjom we wprowadzaniu Kindle i Alexy oraz znacznemu wzrostowi rocznych przychodów w latach 2019–2022. Wzrost ten doprowadził do zwiększenia powierzchni centrów logistycznych, utworzenia sieci transportu ostatniej mili i budowy nowej sieci centrów sortowania, które zostały zoptymalizowane pod kątem produktywności i redukcji kosztów. | Ekstraktor łańcucha LLM utrzymuje równowagę pomiędzy kompleksowym omawianiem kluczowych punktów i unikaniem niepotrzebnej głębi. Dynamicznie dostosowuje się do kontekstu zapytania, dzięki czemu wyniki są bezpośrednio istotne i kompleksowe. |
| Filtr łańcucha LLM: Kontekstowe wyjście kompresji | AWS (Amazon Web Services) ewoluowało, wprowadzając początkowo ubogie w funkcje, ale szybko wprowadzając kolejne iteracje w oparciu o opinie klientów w celu dodania niezbędnych funkcji. Takie podejście umożliwiło AWS uruchomienie EC2 w 2006 roku z ograniczonymi funkcjami, a następnie ciągłe dodawanie nowych funkcjonalności, takich jak dodatkowe rozmiary instancji, centra danych, regiony, opcje systemu operacyjnego, narzędzia monitorujące, równoważenie obciążenia, automatyczne skalowanie i trwała pamięć masowa. Z biegiem czasu AWS przekształcił się z usługi ubogiej w funkcje w firmę wartą wiele miliardów dolarów, koncentrując się na potrzebach klientów, elastyczności, innowacjach, efektywności kosztowej i bezpieczeństwie. AWS osiąga obecnie roczne przychody wynoszące 85 miliardów dolarów i oferuje co roku ponad 3,300 nowych funkcji i usług, obsługując szeroką gamę klientów, od start-upów po międzynarodowe firmy i organizacje sektora publicznego. | Amazon odnosi sukcesy dzięki innowacyjnym modelom biznesowym, ciągłemu postępowi technologicznemu i strategicznym zmianom organizacyjnym. Firma konsekwentnie rewolucjonizuje tradycyjne branże, wprowadzając nowe pomysły, takie jak platforma e-commerce dla różnych produktów i usług, rynek stron trzecich, usługi infrastruktury w chmurze (AWS), e-czytnik Kindle i głosowy asystent osobisty Alexa . Ponadto Amazon wprowadził zmiany strukturalne w celu poprawy swojej wydajności, takie jak reorganizacja sieci realizacji zamówień w USA w celu zmniejszenia kosztów i czasu dostaw, co jeszcze bardziej przyczyniło się do jego sukcesu. | Podobnie jak ekstraktor łańcucha LLM, filtr łańcucha LLM zapewnia, że chociaż kluczowe punkty zostaną ujęte, wyniki będą skuteczne dla klientów poszukujących zwięzłych i kontekstowych odpowiedzi. |
Porównując te różne techniki, widzimy, że w kontekstach takich jak szczegółowe opisywanie przejścia AWS od prostej usługi do złożonego podmiotu o wartości wielu miliardów dolarów lub wyjaśnianie strategicznych sukcesów Amazona, regularnej sieci retrieverów brakuje precyzji, jaką oferują bardziej wyrafinowane techniki, co prowadzi do mniej ukierunkowanych informacji. Chociaż pomiędzy omawianymi zaawansowanymi technikami widać bardzo niewiele różnic, dostarczają one znacznie więcej informacji niż zwykłe łańcuchy retrieverów.
W przypadku klientów z branż takich jak opieka zdrowotna, telekomunikacja i usługi finansowe, którzy chcą wdrożyć RAG w swoich zastosowaniach, ograniczenia zwykłego łańcucha aporterów w zapewnianiu precyzji, unikaniu redundancji i skutecznej kompresji informacji sprawiają, że jest on mniej odpowiedni do spełnienia tych potrzeb w porównaniu do bardziej zaawansowanych technik wyszukiwania dokumentów nadrzędnych i kompresji kontekstowej. Techniki te umożliwiają destylację ogromnych ilości informacji w postaci skoncentrowanych, skutecznych spostrzeżeń, których potrzebujesz, pomagając jednocześnie poprawić stosunek ceny do jakości.
Sprzątać
Po zakończeniu korzystania z notatnika usuń utworzone zasoby, aby uniknąć naliczania opłat za używane zasoby:
Wnioski
W tym poście zaprezentowaliśmy rozwiązanie, które umożliwia wdrożenie technik wyszukiwania dokumentów nadrzędnych i kontekstowego łańcucha kompresji w celu zwiększenia zdolności LLM do przetwarzania i generowania informacji. Przetestowaliśmy te zaawansowane techniki RAG z modelami Mixtral-8x7B Instruct i BGE Large En dostępnymi z SageMaker JumpStart. Zbadaliśmy także wykorzystanie trwałego magazynu do osadzania i fragmentów dokumentów oraz integrację z korporacyjnymi magazynami danych.
Techniki, które zastosowaliśmy, nie tylko udoskonalają sposób, w jaki modele LLM uzyskują dostęp do wiedzy zewnętrznej i ją wykorzystują, ale także znacząco poprawiają jakość, przydatność i efektywność ich wyników. Łącząc wyszukiwanie z dużych korpusów tekstowych z możliwościami generowania języka, te zaawansowane techniki RAG umożliwiają LLM tworzenie bardziej opartych na faktach, spójnych i odpowiednich do kontekstu odpowiedzi, zwiększając ich wydajność w różnych zadaniach przetwarzania języka naturalnego.
W centrum tego rozwiązania znajduje się SageMaker JumpStart. Dzięki SageMaker JumpStart zyskujesz dostęp do szerokiego asortymentu modeli o otwartym i zamkniętym kodzie źródłowym, usprawniając proces rozpoczynania pracy z ML i umożliwiając szybkie eksperymentowanie i wdrażanie. Aby rozpocząć wdrażanie tego rozwiązania, przejdź do notesu w pliku GitHub repo.
O autorach
 Niithiyn Vijeaswaran jest architektem rozwiązań w AWS. Jego obszar zainteresowań to generatywna sztuczna inteligencja i akceleratory AWS AI. Posiada tytuł licencjata w dziedzinie informatyki i bioinformatyki. Niithiyn ściśle współpracuje z zespołem Generative AI GTM, aby umożliwić klientom AWS na wielu frontach i przyspieszyć ich wdrażanie generatywnej sztucznej inteligencji. Jest zagorzałym fanem Dallas Mavericks i lubi kolekcjonować trampki.
Niithiyn Vijeaswaran jest architektem rozwiązań w AWS. Jego obszar zainteresowań to generatywna sztuczna inteligencja i akceleratory AWS AI. Posiada tytuł licencjata w dziedzinie informatyki i bioinformatyki. Niithiyn ściśle współpracuje z zespołem Generative AI GTM, aby umożliwić klientom AWS na wielu frontach i przyspieszyć ich wdrażanie generatywnej sztucznej inteligencji. Jest zagorzałym fanem Dallas Mavericks i lubi kolekcjonować trampki.
 Sebastiana Bustillo jest architektem rozwiązań w AWS. Koncentruje się na technologiach AI/ML z głęboką pasją do generatywnej sztucznej inteligencji i akceleratorów obliczeniowych. W AWS pomaga klientom odblokować wartość biznesową dzięki generatywnej sztucznej inteligencji. Kiedy nie jest w pracy, lubi parzyć idealną kawę specialty i zwiedzać świat z żoną.
Sebastiana Bustillo jest architektem rozwiązań w AWS. Koncentruje się na technologiach AI/ML z głęboką pasją do generatywnej sztucznej inteligencji i akceleratorów obliczeniowych. W AWS pomaga klientom odblokować wartość biznesową dzięki generatywnej sztucznej inteligencji. Kiedy nie jest w pracy, lubi parzyć idealną kawę specialty i zwiedzać świat z żoną.
 Armanda Diaza jest architektem rozwiązań w AWS. Koncentruje się na generatywnej sztucznej inteligencji, AI/ML i analizie danych. W AWS Armando pomaga klientom integrować najnowocześniejsze możliwości generatywnej sztucznej inteligencji z ich systemami, wspierając innowacje i przewagę konkurencyjną. Kiedy nie jest w pracy, lubi spędzać czas z żoną i rodziną, wędrować i podróżować po świecie.
Armanda Diaza jest architektem rozwiązań w AWS. Koncentruje się na generatywnej sztucznej inteligencji, AI/ML i analizie danych. W AWS Armando pomaga klientom integrować najnowocześniejsze możliwości generatywnej sztucznej inteligencji z ich systemami, wspierając innowacje i przewagę konkurencyjną. Kiedy nie jest w pracy, lubi spędzać czas z żoną i rodziną, wędrować i podróżować po świecie.
 Doktor Farooq Sabir jest starszym architektem rozwiązań w zakresie sztucznej inteligencji i uczenia maszynowego w AWS. Posiada tytuł doktora i magistra inżynierii elektrycznej uzyskany na University of Texas w Austin oraz tytuł magistra informatyki uzyskany na Georgia Institute of Technology. Ma ponad 15-letnie doświadczenie zawodowe, a także lubi uczyć i mentorować studentów. W AWS pomaga klientom formułować i rozwiązywać ich problemy biznesowe w zakresie nauki o danych, uczenia maszynowego, wizji komputerowej, sztucznej inteligencji, optymalizacji numerycznej i pokrewnych dziedzin. Mieszka w Dallas w Teksasie i wraz z rodziną uwielbia podróżować i wyruszać w długie podróże.
Doktor Farooq Sabir jest starszym architektem rozwiązań w zakresie sztucznej inteligencji i uczenia maszynowego w AWS. Posiada tytuł doktora i magistra inżynierii elektrycznej uzyskany na University of Texas w Austin oraz tytuł magistra informatyki uzyskany na Georgia Institute of Technology. Ma ponad 15-letnie doświadczenie zawodowe, a także lubi uczyć i mentorować studentów. W AWS pomaga klientom formułować i rozwiązywać ich problemy biznesowe w zakresie nauki o danych, uczenia maszynowego, wizji komputerowej, sztucznej inteligencji, optymalizacji numerycznej i pokrewnych dziedzin. Mieszka w Dallas w Teksasie i wraz z rodziną uwielbia podróżować i wyruszać w długie podróże.
 Marek Punio jest architektem rozwiązań skupionym na strategii generatywnej sztucznej inteligencji, stosowanych rozwiązaniach AI i prowadzeniu badań, aby pomóc klientom w hiperskalowaniu na AWS. Marco jest doradcą ds. chmury cyfrowej z doświadczeniem w branżach FinTech, Healthcare i Life Sciences, Software-as-a-service, a ostatnio w branży telekomunikacyjnej. Jest wykwalifikowanym technologiem z pasją do uczenia maszynowego, sztucznej inteligencji oraz fuzji i przejęć. Marco mieszka w Seattle w stanie Waszyngton i w wolnym czasie lubi pisać, czytać, ćwiczyć i tworzyć aplikacje.
Marek Punio jest architektem rozwiązań skupionym na strategii generatywnej sztucznej inteligencji, stosowanych rozwiązaniach AI i prowadzeniu badań, aby pomóc klientom w hiperskalowaniu na AWS. Marco jest doradcą ds. chmury cyfrowej z doświadczeniem w branżach FinTech, Healthcare i Life Sciences, Software-as-a-service, a ostatnio w branży telekomunikacyjnej. Jest wykwalifikowanym technologiem z pasją do uczenia maszynowego, sztucznej inteligencji oraz fuzji i przejęć. Marco mieszka w Seattle w stanie Waszyngton i w wolnym czasie lubi pisać, czytać, ćwiczyć i tworzyć aplikacje.
 AJ Dhimine jest architektem rozwiązań w AWS. Specjalizuje się w generatywnej sztucznej inteligencji, przetwarzaniu bezserwerowym i analizie danych. Jest aktywnym członkiem/mentorem społeczności dziedzin technicznych uczenia maszynowego i opublikował kilka artykułów naukowych na różne tematy AI/ML. Współpracuje z klientami, od start-upów po przedsiębiorstwa, aby opracowywać generatywne rozwiązania AI AWSome. Jego szczególną pasją jest wykorzystywanie modeli wielkojęzykowych do zaawansowanej analizy danych i odkrywania praktycznych zastosowań, które pozwalają sprostać wyzwaniom świata rzeczywistego. Poza pracą AJ lubi podróżować i obecnie przebywa w 53 krajach, a jego celem jest odwiedzenie każdego kraju na świecie.
AJ Dhimine jest architektem rozwiązań w AWS. Specjalizuje się w generatywnej sztucznej inteligencji, przetwarzaniu bezserwerowym i analizie danych. Jest aktywnym członkiem/mentorem społeczności dziedzin technicznych uczenia maszynowego i opublikował kilka artykułów naukowych na różne tematy AI/ML. Współpracuje z klientami, od start-upów po przedsiębiorstwa, aby opracowywać generatywne rozwiązania AI AWSome. Jego szczególną pasją jest wykorzystywanie modeli wielkojęzykowych do zaawansowanej analizy danych i odkrywania praktycznych zastosowań, które pozwalają sprostać wyzwaniom świata rzeczywistego. Poza pracą AJ lubi podróżować i obecnie przebywa w 53 krajach, a jego celem jest odwiedzenie każdego kraju na świecie.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

