Asystenci konwersacyjnej sztucznej inteligencji (AI) zostali stworzeni tak, aby zapewniać precyzyjne odpowiedzi w czasie rzeczywistym poprzez inteligentne kierowanie zapytań do najbardziej odpowiednich funkcji AI. Dzięki generatywnym usługom AI AWS, takim jak Amazońska skała macierzystaprogramiści mogą tworzyć systemy, które fachowo zarządzają żądaniami użytkowników i odpowiadają na nie. Amazon Bedrock to w pełni zarządzana usługa oferująca wybór wydajnych modeli podstawowych (FM) od wiodących firm zajmujących się sztuczną inteligencją, takich jak AI21 Labs, Anthropic, Cohere, Meta, Stability AI i Amazon, korzystających z jednego interfejsu API, wraz z szerokim zestawem możliwości potrzebne do tworzenia generatywnych aplikacji AI zapewniających bezpieczeństwo, prywatność i odpowiedzialną sztuczną inteligencję.
W tym poście dokonano oceny dwóch głównych podejść do tworzenia asystentów AI: korzystanie z usług zarządzanych, takich jak Agenci Amazon Bedrocki wykorzystujące technologie open source, takie jak LangChain. Badamy zalety i wyzwania każdego z nich, abyś mógł wybrać ścieżkę najbardziej odpowiednią dla swoich potrzeb.
Kim jest asystent AI?
Asystent AI to inteligentny system, który rozumie zapytania w języku naturalnym i wchodzi w interakcję z różnymi narzędziami, źródłami danych i interfejsami API w celu wykonywania zadań lub pobierania informacji w imieniu użytkownika. Skuteczni asystenci AI posiadają następujące kluczowe możliwości:
- Przetwarzanie języka naturalnego (NLP) i przepływ konwersacji
- Integracja bazy wiedzy i wyszukiwania semantyczne w celu zrozumienia i odzyskania odpowiednich informacji w oparciu o niuanse kontekstu rozmowy
- Uruchamianie zadań, takich jak zapytania do bazy danych i niestandardowe AWS Lambda Funkcje
- Obsługa specjalistycznych rozmów i żądań użytkowników
Pokazujemy zalety asystentów AI na przykładzie zarządzania urządzeniami Internetu rzeczy (IoT). W tym przypadku sztuczna inteligencja może pomóc technikom w efektywnym zarządzaniu maszynami za pomocą poleceń pobierających dane lub automatyzujących zadania, usprawniając operacje w produkcji.
Agenci podejścia Amazon Bedrock
Agenci Amazon Bedrock umożliwia tworzenie generatywnych aplikacji AI, które mogą wykonywać wieloetapowe zadania w systemach i źródłach danych firmy. Oferuje następujące kluczowe możliwości:
- Automatyczne tworzenie podpowiedzi na podstawie instrukcji, szczegółów interfejsu API i informacji o źródle danych, oszczędzając tygodnie szybkiego wysiłku inżynieryjnego
- Generowanie rozszerzone pobierania (RAG) w celu bezpiecznego łączenia agentów ze źródłami danych firmy i zapewniania odpowiednich odpowiedzi
- Orkiestrowanie i uruchamianie zadań wieloetapowych poprzez dzielenie żądań na logiczne sekwencje i wywoływanie niezbędnych API
- Wgląd w rozumowanie agenta poprzez ślad łańcucha myśli (CoT), umożliwiający rozwiązywanie problemów i sterowanie zachowaniem modelu
- Możliwość modyfikowania automatycznie wygenerowanego szablonu podpowiedzi w celu zwiększenia kontroli nad agentami
Możesz używać agentów dla Amazon Bedrock i Bazy wiedzy na temat Amazon Bedrock do tworzenia i wdrażania asystentów AI do złożonych przypadków użycia routingu. Zapewniają strategiczną przewagę programistom i organizacjom, upraszczając zarządzanie infrastrukturą, zwiększając skalowalność, poprawiając bezpieczeństwo i ograniczając niezróżnicowane podnoszenie ciężkich przedmiotów. Pozwalają również na prostszy kod warstwy aplikacji, ponieważ logika routingu, wektoryzacja i pamięć są w pełni zarządzane.
Omówienie rozwiązania
To rozwiązanie wprowadza konwersacyjnego asystenta AI dostosowanego do zarządzania urządzeniami IoT i operacji podczas korzystania z Anthropic Claude v2.1 na Amazon Bedrock. Podstawową funkcjonalnością asystenta AI reguluje kompleksowy zestaw instrukcji, tzw monit systemowy, który określa jego możliwości i obszary specjalizacji. Dzięki tym wskazówkom asystent AI może wykonywać szeroki zakres zadań, od zarządzania informacjami o urządzeniu po uruchamianie poleceń operacyjnych.
Wyposażony w te możliwości, które opisano szczegółowo w wierszu poleceń, asystent AI postępuje według zorganizowanego przepływu pracy, aby odpowiedzieć na pytania użytkowników. Poniższy rysunek przedstawia wizualną reprezentację tego przepływu pracy, ilustrując każdy krok od początkowej interakcji z użytkownikiem do ostatecznej odpowiedzi.

Przepływ pracy składa się z następujących kroków:
- Proces rozpoczyna się, gdy użytkownik poprosi asystenta o wykonanie zadania; na przykład pytanie o maksymalną liczbę punktów danych dla konkretnego urządzenia IoT
device_xxx. Ten wprowadzony tekst jest przechwytywany i wysyłany do asystenta AI. - Asystent AI interpretuje tekst wprowadzany przez użytkownika. Wykorzystuje dostarczoną historię rozmów, grupy działań i bazy wiedzy, aby zrozumieć kontekst i określić niezbędne zadania.
- Po przeanalizowaniu i zrozumieniu intencji użytkownika asystent AI definiuje zadania. Opiera się to na instrukcjach interpretowanych przez asystenta zgodnie z komunikatem systemowym i danymi wprowadzonymi przez użytkownika.
- Zadania są następnie uruchamiane poprzez serię wywołań API. Odbywa się to za pomocą Reagować monitowanie, które dzieli zadanie na serię kroków przetwarzanych sekwencyjnie:
- Do sprawdzania metryk urządzenia używamy metody
check-device-metricsgrupa akcji, która obejmuje wywołanie API do funkcji Lambda, które następnie wysyłają zapytania Amazonka Atena dla żądanych danych. - Do bezpośrednich działań na urządzeniu, takich jak uruchamianie, zatrzymywanie lub ponowne uruchamianie, używamy
action-on-devicegrupa akcji, która wywołuje funkcję Lambda. Funkcja ta inicjuje proces wysyłający polecenia do urządzenia IoT. W przypadku tego wpisu funkcja Lambda wysyła powiadomienia za pomocą Prosta usługa e-mail Amazon (Amazon SES). - Korzystamy z baz wiedzy dla Amazon Bedrock w celu pobierania danych historycznych przechowywanych jako osadzenia w Usługa Amazon OpenSearch baza danych wektorowych.
- Do sprawdzania metryk urządzenia używamy metody
- Po wykonaniu zadań ostateczna odpowiedź jest generowana przez Amazon Bedrock FM i przekazywana użytkownikowi.
- Agenci dla Amazon Bedrock automatycznie przechowują informacje, korzystając z sesji stanowej, aby utrzymać tę samą konwersację. Stan jest usuwany po upływie konfigurowalnego limitu czasu bezczynności.
Przegląd techniczny
Poniższy diagram ilustruje architekturę wdrażania asystenta AI z agentami dla Amazon Bedrock.

Składa się z następujących kluczowych elementów:
- Interfejs konwersacyjny – Interfejs konwersacyjny wykorzystuje Streamlit, bibliotekę Pythona o otwartym kodzie źródłowym, która upraszcza tworzenie niestandardowych, atrakcyjnych wizualnie aplikacji internetowych do uczenia maszynowego (ML) i nauki o danych. Jest hostowany na Usługa Amazon Elastic Container Service (Amazon ECS) z AWS-Fargatei można uzyskać do niego dostęp za pomocą modułu równoważenia obciążenia aplikacji. Do uruchomienia możesz używać Fargate z Amazon ECS Pojemniki bez konieczności zarządzania serwerami, klastrami czy maszynami wirtualnymi.
- Agenci Amazon Bedrock – Agenci Amazon Bedrock uzupełniają zapytania użytkowników poprzez serię etapów rozumowania i odpowiednich działań Monit ReAct:
- Bazy wiedzy na temat Amazon Bedrock – Bazy wiedzy dla Amazon Bedrock zapewniają pełne zarządzanie RAG aby zapewnić asystentowi AI dostęp do Twoich danych. W naszym przypadku przesłaliśmy specyfikacje urządzenia do pliku Usługa Amazon Simple Storage Łyżka (Amazon S3). Służy jako źródło danych do bazy wiedzy.
- Grupy działania – Są to zdefiniowane schematy API, które wywołują określone funkcje Lambda w celu interakcji z urządzeniami IoT i innymi usługami AWS.
- Anthropic Claude v2.1 na Amazon Bedrock – Model ten interpretuje zapytania użytkowników i koordynuje przepływ zadań.
- Osadzania Amazon Titan – Model ten służy jako model osadzania tekstu, przekształcający tekst w języku naturalnym – od pojedynczych słów po złożone dokumenty – w wektory numeryczne. Umożliwia to wyszukiwanie wektorowe, dzięki czemu system może semantycznie dopasowywać zapytania użytkowników do najbardziej odpowiednich wpisów w bazie wiedzy w celu efektywnego wyszukiwania.
Rozwiązanie jest zintegrowane z usługami AWS, takimi jak Lambda do uruchamiania kodu w odpowiedzi na wywołania API, Athena do wysyłania zapytań do zbiorów danych, OpenSearch Service do przeszukiwania baz wiedzy i Amazon S3 do przechowywania danych. Usługi te współpracują ze sobą, aby zapewnić płynne zarządzanie operacjami urządzeń IoT za pomocą poleceń w języku naturalnym.
Benefity
To rozwiązanie oferuje następujące korzyści:
- Złożoność wdrożenia:
- Wymaganych jest mniej linii kodu, ponieważ agenty dla Amazon Bedrock eliminują większość podstawowej złożoności, zmniejszając wysiłek programistyczny
- Zarządzanie wektorowymi bazami danych, takimi jak usługa OpenSearch, jest uproszczone, ponieważ Bazy wiedzy dla Amazon Bedrock obsługują wektoryzację i przechowywanie
- Integracja z różnymi usługami AWS jest usprawniona dzięki predefiniowanym grupom działań
- Doświadczenie programisty:
- Konsola Amazon Bedrock zapewnia przyjazny dla użytkownika interfejs do szybkiego programowania, testowania i analizy przyczyn źródłowych (RCA), poprawiając ogólne doświadczenie programisty
- Zwinność i elastyczność:
- Agents for Amazon Bedrock umożliwia bezproblemową aktualizację do nowszych FM (takich jak Claude 3.0), gdy tylko staną się dostępne, dzięki czemu Twoje rozwiązanie będzie zawsze aktualne i zgodne z najnowszymi osiągnięciami
- Przydziałami i ograniczeniami usług zarządza AWS, co zmniejsza obciążenie związane z monitorowaniem i skalowaniem infrastruktury
- Bezpieczeństwo:
- Amazon Bedrock to w pełni zarządzana usługa zgodna z rygorystycznymi standardami bezpieczeństwa i zgodności AWS, potencjalnie upraszczająca kontrole bezpieczeństwa organizacji
Chociaż Agents for Amazon Bedrock oferuje usprawnione i zarządzane rozwiązanie do tworzenia konwersacyjnych aplikacji AI, niektóre organizacje mogą preferować podejście typu open source. W takich przypadkach można skorzystać z frameworków takich jak LangChain, które omówimy w następnej sekcji.
Podejście do dynamicznego routingu LangChain
LangChain to platforma typu open source, która upraszcza budowanie konwersacyjnej sztucznej inteligencji, umożliwiając integrację dużych modeli językowych (LLM) i możliwości dynamicznego routingu. Dzięki językowi LangChain Expression Language (LCEL) programiści mogą definiować Routing, co umożliwia tworzenie niedeterministycznych łańcuchów, w których wynik poprzedniego kroku definiuje następny krok. Routing pomaga zapewnić strukturę i spójność interakcji z LLM.
W tym poście używamy tego samego przykładu, co asystent AI do zarządzania urządzeniami IoT. Jednak główna różnica polega na tym, że monity systemowe musimy obsługiwać osobno i traktować każdy łańcuch jako odrębną całość. Łańcuch routingu decyduje o łańcuchu docelowym na podstawie danych wprowadzonych przez użytkownika. Decyzja jest podejmowana przy wsparciu LLM poprzez przekazanie monitu systemowego, historii czatów i pytania użytkownika.
Omówienie rozwiązania
Poniższy diagram ilustruje przepływ pracy rozwiązania routingu dynamicznego.
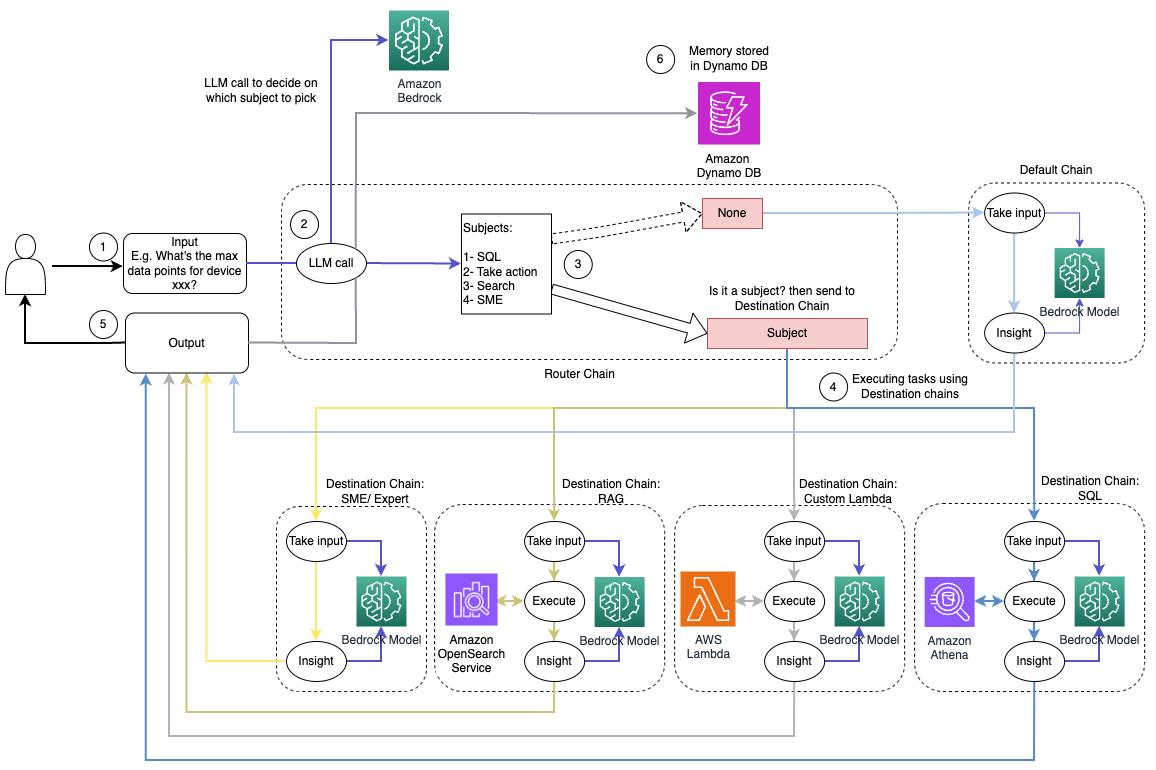
Przepływ pracy składa się z następujących kroków:
- Użytkownik zadaje pytanie asystentowi AI. Na przykład: „Jakie są maksymalne dane dla urządzenia 1009?”
- LLM ocenia każde pytanie wraz z historią czatów z tej samej sesji, aby określić jego charakter i obszar tematyczny, do którego należy (np. SQL, działanie, wyszukiwanie lub MŚP). LLM klasyfikuje dane wejściowe, a łańcuch routingu LCEL przejmuje te dane wejściowe.
- Łańcuch routerów wybiera łańcuch docelowy na podstawie danych wejściowych, a LLM wyświetla następujący komunikat systemowy:
LLM ocenia pytanie użytkownika wraz z historią czatów, aby określić charakter zapytania i obszar tematyczny, którego dotyczy. Następnie LLM klasyfikuje dane wejściowe i wysyła odpowiedź JSON w następującym formacie:
Łańcuch routerów używa tej odpowiedzi JSON do wywołania odpowiedniego łańcucha docelowego. Istnieją cztery tematyczne łańcuchy miejsc docelowych, każdy z własnym monitem systemowym:
- Zapytania związane z SQL są wysyłane do łańcucha docelowego SQL w celu interakcji z bazą danych. Możesz użyć LCEL do zbudowania Łańcuch SQL.
- Pytania zorientowane na akcję odwołują się do niestandardowego łańcucha docelowego Lambda dla uruchomionych operacji. Dzięki LCEL możesz zdefiniować własne funkcja niestandardowa; w naszym przypadku jest to funkcja uruchamiająca predefiniowaną funkcję Lambda w celu wysłania wiadomości e-mail z przeanalizowanym identyfikatorem urządzenia. Przykładowe dane wprowadzone przez użytkownika mogą brzmieć „Wyłącz urządzenie 1009”.
- Zapytania skoncentrowane na wyszukiwaniu są kierowane do RAG łańcuch docelowy do wyszukiwania informacji.
- Pytania dotyczące MŚP kierowane są do łańcucha docelowego MŚP/ekspertów w celu uzyskania specjalistycznych informacji.
- Każdy łańcuch docelowy pobiera dane wejściowe i uruchamia niezbędne modele lub funkcje:
- Łańcuch SQL wykorzystuje technologię Athena do uruchamiania zapytań.
- Łańcuch RAG korzysta z usługi OpenSearch do wyszukiwania semantycznego.
- Niestandardowy łańcuch Lambda uruchamia funkcje Lambda dla akcji.
- Łańcuch MŚP/ekspertów zapewnia spostrzeżenia przy użyciu modelu Amazon Bedrock.
- Odpowiedzi z każdego łańcucha miejsc docelowych są formułowane w spójne spostrzeżenia przez LLM. Te spostrzeżenia są następnie dostarczane użytkownikowi, kończąc cykl zapytania.
- Dane wejściowe i odpowiedzi użytkownika są przechowywane w Amazon DynamoDB aby zapewnić kontekst LLM dla bieżącej sesji i przeszłych interakcji. Czas przechowywania informacji w DynamoDB jest kontrolowany przez aplikację.
Przegląd techniczny
Poniższy diagram ilustruje architekturę rozwiązania do dynamicznego routingu LangChain.
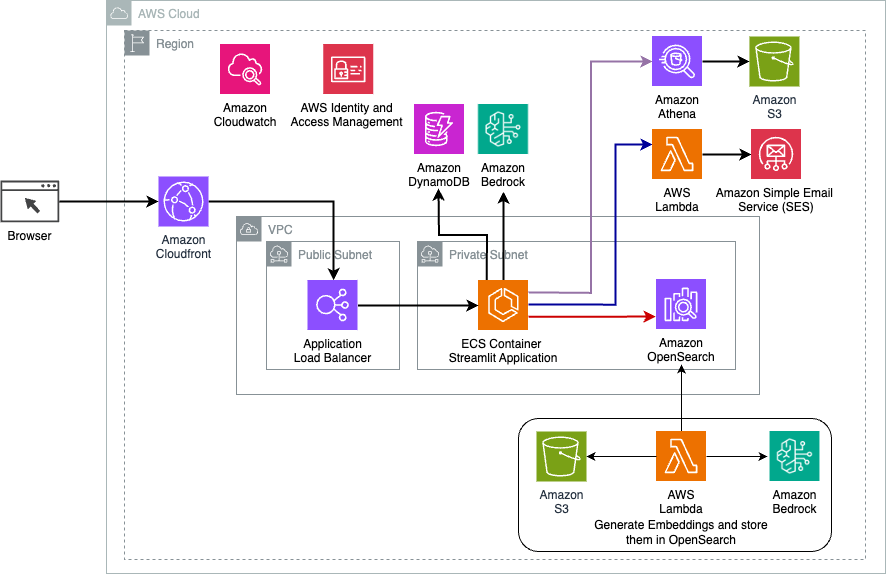
Aplikacja internetowa jest zbudowana na platformie Streamlit hostowanej na Amazon ECS z Fargate i można uzyskać do niej dostęp za pomocą modułu równoważenia obciążenia aplikacji. Używamy Anthropic Claude v2.1 na Amazon Bedrock jako naszego LLM. Aplikacja internetowa współpracuje z modelem za pomocą bibliotek LangChain. Współpracuje także z wieloma innymi usługami AWS, takimi jak OpenSearch Service, Athena i DynamoDB, aby spełniać potrzeby użytkowników końcowych.
Benefity
To rozwiązanie oferuje następujące korzyści:
- Złożoność wdrożenia:
- Chociaż wymaga to więcej kodu i niestandardowego rozwoju, LangChain zapewnia większą elastyczność i kontrolę nad logiką routingu oraz integracją z różnymi komponentami.
- Zarządzanie wektorowymi bazami danych, takimi jak usługa OpenSearch, wymaga dodatkowych działań związanych z instalacją i konfiguracją. Proces wektoryzacji jest zaimplementowany w kodzie.
- Integracja z usługami AWS może wymagać bardziej niestandardowego kodu i konfiguracji.
- Doświadczenie programisty:
- Podejście LangChain oparte na języku Python i obszerna dokumentacja mogą być atrakcyjne dla programistów znających już język Python i narzędzia open source.
- Szybkie tworzenie oprogramowania i debugowanie może wymagać więcej wysiłku ręcznego w porównaniu do korzystania z konsoli Amazon Bedrock.
- Zwinność i elastyczność:
- LangChain obsługuje szeroką gamę LLM, umożliwiając przełączanie pomiędzy różnymi modelami lub dostawcami, zwiększając elastyczność.
- Otwarty charakter oprogramowania LangChain umożliwia wprowadzanie ulepszeń i dostosowywanie przez społeczność.
- Bezpieczeństwo:
- Jako platforma open source, LangChain może wymagać bardziej rygorystycznych przeglądów bezpieczeństwa i weryfikacji w organizacjach, co potencjalnie zwiększa obciążenie.
Wnioski
Konwersacyjni asystenci AI to rewolucyjne narzędzia usprawniające operacje i poprawiające doświadczenia użytkowników. W tym poście omówiono dwa zaawansowane podejścia wykorzystujące usługi AWS: zarządzanych agentów dla Amazon Bedrock i elastyczny, dynamiczny routing LangChain o otwartym kodzie źródłowym. Wybór pomiędzy tymi podejściami zależy od wymagań organizacji, preferencji programistycznych i pożądanego poziomu dostosowania. Niezależnie od obranej ścieżki, AWS umożliwia tworzenie inteligentnych asystentów AI, którzy rewolucjonizują interakcje biznesowe i klientów
Znajdź kod rozwiązania i zasoby wdrożeniowe w naszym Repozytorium GitHub, gdzie możesz wykonać szczegółowe kroki dla każdego konwersacyjnego podejścia do sztucznej inteligencji.
O autorach
 Ameera Hakme jest architektem rozwiązań AWS z siedzibą w Pensylwanii. Współpracuje z niezależnymi dostawcami oprogramowania (ISV) w regionie północno-wschodnim, pomagając im w projektowaniu i budowaniu skalowalnych i nowoczesnych platform w chmurze AWS. Jako ekspert w dziedzinie AI/ML i generatywnej sztucznej inteligencji, Ameer pomaga klientom uwolnić potencjał tych najnowocześniejszych technologii. W wolnym czasie lubi jeździć na motocyklu i spędzać czas z rodziną.
Ameera Hakme jest architektem rozwiązań AWS z siedzibą w Pensylwanii. Współpracuje z niezależnymi dostawcami oprogramowania (ISV) w regionie północno-wschodnim, pomagając im w projektowaniu i budowaniu skalowalnych i nowoczesnych platform w chmurze AWS. Jako ekspert w dziedzinie AI/ML i generatywnej sztucznej inteligencji, Ameer pomaga klientom uwolnić potencjał tych najnowocześniejszych technologii. W wolnym czasie lubi jeździć na motocyklu i spędzać czas z rodziną.
 Sharon Lic jest architektem rozwiązań AI/ML w Amazon Web Services z siedzibą w Bostonie, z pasją do projektowania i tworzenia aplikacji generatywnej AI na platformie AWS. Współpracuje z klientami, aby wykorzystać usługi AWS AI/ML do innowacyjnych rozwiązań.
Sharon Lic jest architektem rozwiązań AI/ML w Amazon Web Services z siedzibą w Bostonie, z pasją do projektowania i tworzenia aplikacji generatywnej AI na platformie AWS. Współpracuje z klientami, aby wykorzystać usługi AWS AI/ML do innowacyjnych rozwiązań.
 Kawasar Kamal jest starszym architektem rozwiązań w Amazon Web Services z ponad 15-letnim doświadczeniem w obszarze automatyzacji infrastruktury i bezpieczeństwa. Pomaga klientom projektować i budować skalowalne rozwiązania DevSecOps i AI/ML w chmurze.
Kawasar Kamal jest starszym architektem rozwiązań w Amazon Web Services z ponad 15-letnim doświadczeniem w obszarze automatyzacji infrastruktury i bezpieczeństwa. Pomaga klientom projektować i budować skalowalne rozwiązania DevSecOps i AI/ML w chmurze.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

