Studio Amazon SageMaker zapewnia w pełni zarządzane rozwiązanie dla analityków danych, umożliwiające interaktywne budowanie, trenowanie i wdrażanie modeli uczenia maszynowego (ML). W procesie pracy nad zadaniami ML badacze danych zazwyczaj rozpoczynają przepływ pracy od odkrycia odpowiednich źródeł danych i nawiązania z nimi połączenia. Następnie używają języka SQL do eksploracji, analizowania, wizualizacji i integrowania danych z różnych źródeł przed wykorzystaniem ich w szkoleniu i wnioskowaniu ML. Wcześniej badacze danych często musieli żonglować wieloma narzędziami do obsługi języka SQL w swojej pracy, co zmniejszało produktywność.
Z radością ogłaszamy, że notatniki JupyterLab w SageMaker Studio mają teraz wbudowaną obsługę języka SQL. Analitycy danych mogą teraz:
- Połącz się z popularnymi usługami transmisji danych, w tym Amazonka Atena, Amazonka Przesunięcie ku czerwieni, Strefa danych Amazonai Płatek śniegu bezpośrednio w notatnikach
- Przeglądaj i wyszukuj bazy danych, schematy, tabele i widoki oraz przeglądaj dane w interfejsie notebooka
- Mieszaj kod SQL i Python w tym samym notatniku, aby efektywnie eksplorować i przekształcać dane do wykorzystania w projektach ML
- Korzystaj z funkcji zwiększających produktywność programistów, takich jak uzupełnianie poleceń SQL, pomoc w formatowaniu kodu i podświetlanie składni, aby przyspieszyć tworzenie kodu i poprawić ogólną produktywność programistów
Ponadto administratorzy mogą bezpiecznie zarządzać połączeniami z tymi usługami danych, umożliwiając analitykom danych dostęp do autoryzowanych danych bez konieczności ręcznego zarządzania danymi uwierzytelniającymi.
W tym poście przeprowadzimy Cię przez konfigurację tej funkcji w SageMaker Studio i przeprowadzimy Cię przez różne możliwości tej funkcji. Następnie pokażemy, jak można ulepszyć obsługę języka SQL w notebooku, korzystając z funkcji zamiany tekstu na SQL udostępnianych przez zaawansowane modele dużego języka (LLM) w celu pisania złożonych zapytań SQL przy użyciu tekstu w języku naturalnym jako danych wejściowych. Na koniec, aby umożliwić szerszemu gronu użytkowników generowanie zapytań SQL na podstawie danych wejściowych w języku naturalnym w ich notatnikach, pokażemy, jak wdrożyć te modele zamiany tekstu na SQL za pomocą Amazon Sage Maker punkty końcowe.
Omówienie rozwiązania
Dzięki integracji SQL w notebooku SageMaker Studio JupyterLab możesz teraz łączyć się z popularnymi źródłami danych, takimi jak Snowflake, Athena, Amazon Redshift i Amazon DataZone. Ta nowa funkcja umożliwia wykonywanie różnych funkcji.
Na przykład możesz wizualnie eksplorować źródła danych, takie jak bazy danych, tabele i schematy, bezpośrednio z ekosystemu JupyterLab. Jeśli środowiska Twoich notebooków działają na platformie SageMaker Distribution 1.6 lub nowszej, poszukaj nowego widżetu po lewej stronie interfejsu JupyterLab. Ten dodatek zwiększa dostępność danych i zarządzanie nimi w środowisku programistycznym.
Jeśli obecnie nie korzystasz z sugerowanej dystrybucji SageMaker (1.5 lub starszej) lub nie korzystasz z niestandardowego środowiska, więcej informacji znajdziesz w dodatku.

Po skonfigurowaniu połączeń (jak pokazano w następnej sekcji) możesz wyświetlić listę połączeń danych, przeglądać bazy danych i tabele oraz sprawdzać schematy.

Wbudowane rozszerzenie SQL SageMaker Studio JupyterLab umożliwia także uruchamianie zapytań SQL bezpośrednio z notatnika. Notatniki Jupyter mogą rozróżniać kod SQL i Python za pomocą %%sm_sql polecenie magiczne, które należy umieścić na górze dowolnej komórki zawierającej kod SQL. To polecenie sygnalizuje JupyterLab, że poniższe instrukcje są poleceniami SQL, a nie kodem Pythona. Wynik zapytania można wyświetlić bezpośrednio w notatniku, co ułatwia płynną integrację przepływów pracy SQL i Python w analizie danych.
Wynik zapytania można wyświetlić wizualnie w postaci tabel HTML, jak pokazano na poniższym zrzucie ekranu.

Można je także zapisywać na panda DataFrame.

Wymagania wstępne
Aby móc korzystać z środowiska SQL notesu SageMaker Studio, upewnij się, że zostały spełnione następujące wymagania wstępne:
- SageMaker Studio V2 – Upewnij się, że korzystasz z najnowszej wersji swojego oprogramowania Profile domeny i użytkowników SageMaker Studio. Jeśli obecnie korzystasz z SageMaker Studio Classic, zapoznaj się z sekcją Migracja z Amazon SageMaker Studio Classic.
- Rola IAM – SageMaker wymaga pliku AWS Zarządzanie tożsamością i dostępem (IAM) do przypisania do domeny lub profilu użytkownika SageMaker Studio w celu skutecznego zarządzania uprawnieniami. Aby włączyć przeglądanie danych i funkcję uruchamiania SQL, może być wymagana aktualizacja roli wykonawczej. Poniższa przykładowa zasada umożliwia użytkownikom przyznawanie, wyświetlanie i uruchamianie Klej AWS, Ateno, Usługa Amazon Simple Storage (Amazonka S3), Menedżer tajemnic AWSi zasoby Amazon Redshift:
- Przestrzeń JupyterLab – Potrzebujesz dostępu do zaktualizowanego SageMaker Studio i JupyterLab Space za pomocą Dystrybucja SageMakera v1.6 lub nowsze wersje obrazu. Jeśli używasz niestandardowych obrazów dla JupyterLab Spaces lub starszych wersji SageMaker Distribution (w wersji 1.5 lub starszej), zapoznaj się z załącznikiem, aby uzyskać instrukcje dotyczące instalowania niezbędnych pakietów i modułów, aby włączyć tę funkcję w swoich środowiskach. Aby dowiedzieć się więcej o SageMaker Studio JupyterLab Spaces, zobacz Zwiększ produktywność w Amazon SageMaker Studio: Przedstawiamy JupyterLab Spaces i generatywne narzędzia AI.
- Poświadczenia dostępu do źródła danych – Ta funkcja notebooka SageMaker Studio wymaga dostępu do źródeł danych, takich jak Snowflake i Amazon Redshift, za pomocą nazwy użytkownika i hasła. Utwórz dostęp do tych źródeł danych oparty na nazwie użytkownika i haśle, jeśli jeszcze go nie masz. W chwili pisania tego tekstu dostęp do Snowflake oparty na protokole OAuth nie jest obsługiwaną funkcją.
- Załaduj magię SQL – Przed uruchomieniem zapytań SQL z komórki notatnika Jupyter konieczne jest załadowanie rozszerzenia SQL magics. Użyj polecenia
%load_ext amazon_sagemaker_sql_magicaby włączyć tę funkcję. Dodatkowo możesz uruchomić%sm_sql?polecenie, aby wyświetlić pełną listę obsługiwanych opcji wykonywania zapytań z komórki SQL. Opcje te obejmują między innymi ustawienie domyślnego limitu zapytań wynoszącego 1,000, uruchomienie pełnej ekstrakcji i wstrzykiwanie parametrów zapytania. Taka konfiguracja umożliwia elastyczną i wydajną manipulację danymi SQL bezpośrednio w środowisku notebooka.
Utwórz połączenia z bazą danych
Wbudowane możliwości przeglądania i wykonywania SQL w SageMaker Studio są ulepszone dzięki połączeniom AWS Glue. Połączenie AWS Glue to obiekt AWS Glue Data Catalog, który przechowuje niezbędne dane, takie jak dane logowania, ciągi URI i informacje o wirtualnej chmurze prywatnej (VPC) dla określonych magazynów danych. Połączenia te są używane przez roboty indeksujące, zadania i punkty końcowe oprogramowania AWS Glue w celu uzyskania dostępu do różnych typów magazynów danych. Połączeń tych można używać zarówno w przypadku danych źródłowych, jak i docelowych, a nawet ponownie wykorzystywać to samo połączenie w wielu robotach przeszukiwających lub zadaniach wyodrębniania, przekształcania i ładowania (ETL).
Aby eksplorować źródła danych SQL w lewym panelu SageMaker Studio, musisz najpierw utworzyć obiekty połączeń AWS Glue. Połączenia te ułatwiają dostęp do różnych źródeł danych i umożliwiają eksplorację ich schematycznych elementów danych.
W poniższych sekcjach omówimy proces tworzenia złączy AWS Glue specyficznych dla języka SQL. Umożliwi to dostęp, przeglądanie i eksplorowanie zestawów danych w różnych magazynach danych. Aby uzyskać bardziej szczegółowe informacje na temat połączeń klejowych AWS, zobacz Łączenie z danymi.
Utwórz połączenie kleju AWS
Jedynym sposobem na wprowadzenie źródeł danych do SageMaker Studio są połączenia AWS Glue. Musisz utworzyć połączenia AWS Glue z określonymi typami połączeń. W chwili pisania tego tekstu jedynym obsługiwanym mechanizmem tworzenia tych połączeń jest użycie Interfejs wiersza poleceń AWS (interfejs wiersza poleceń AWS).
Plik JSON definicji połączenia
Łącząc się z różnymi źródłami danych w AWS Glue, musisz najpierw utworzyć plik JSON, który definiuje właściwości połączenia — określane jako plik definicji połączenia. Plik ten ma kluczowe znaczenie dla nawiązania połączenia AWS Glue i powinien zawierać szczegółowe informacje na temat wszystkich niezbędnych konfiguracji dostępu do źródła danych. Aby zapewnić najlepsze praktyki w zakresie bezpieczeństwa, zaleca się używanie Menedżera wpisów tajnych do bezpiecznego przechowywania poufnych informacji, takich jak hasła. Tymczasem innymi właściwościami połączenia można zarządzać bezpośrednio za pomocą połączeń AWS Glue. Takie podejście zapewnia ochronę wrażliwych poświadczeń, a jednocześnie umożliwia dostępność konfiguracji połączenia i zarządzanie nią.
Poniżej znajduje się przykład definicji połączenia JSON:
Konfigurując połączenia AWS Glue dla źródeł danych, należy przestrzegać kilku ważnych wskazówek, aby zapewnić zarówno funkcjonalność, jak i bezpieczeństwo:
- Stringifikacja właściwości – W ramach
PythonPropertiesklucz, upewnij się, że wszystkie właściwości są ciągnione pary klucz-wartość. Bardzo ważne jest, aby w razie potrzeby prawidłowo unikać cudzysłowów, używając ukośnika odwrotnego (). Pomaga to zachować prawidłowy format i uniknąć błędów składniowych w formacie JSON. - Postępowanie z wrażliwymi informacjami – Chociaż możliwe jest uwzględnienie w nim wszystkich właściwości połączenia
PythonProperties, zaleca się, aby nie umieszczać poufnych szczegółów, takich jak hasła, bezpośrednio w tych właściwościach. Zamiast tego użyj Menedżera sekretów do obsługi poufnych informacji. Takie podejście zabezpiecza wrażliwe dane, przechowując je w kontrolowanym i zaszyfrowanym środowisku, z dala od głównych plików konfiguracyjnych.
Utwórz połączenie AWS Glue za pomocą interfejsu AWS CLI
Po dołączeniu wszystkich niezbędnych pól do pliku JSON definicji połączenia można przystąpić do ustanowienia połączenia AWS Glue ze źródłem danych za pomocą interfejsu CLI AWS i następującego polecenia:
To polecenie inicjuje nowe połączenie AWS Glue w oparciu o specyfikacje wyszczególnione w pliku JSON. Poniżej znajduje się krótki podział komponentów polecenia:
- -region – Określa region AWS, w którym zostanie utworzone połączenie AWS Glue. Aby zminimalizować opóźnienia i spełnić wymagania dotyczące miejsca przechowywania danych, niezwykle istotne jest wybranie regionu, w którym zlokalizowane są źródła danych i inne usługi.
- –cli-input-json plik:///ścieżka/do/pliku/połączenie/definicja/plik.json – Ten parametr nakazuje interfejsowi CLI AWS odczytać konfigurację wejściową z pliku lokalnego zawierającego definicję połączenia w formacie JSON.
Powinieneś być w stanie utworzyć połączenia AWS Glue za pomocą powyższego polecenia AWS CLI z terminala Studio JupyterLab. Na filet menu, wybierz Nowości i terminal.

Jeśli create-connection polecenie zostanie pomyślnie wykonane, w okienku przeglądarki SQL powinno pojawić się źródło danych. Jeśli nie widzisz źródła danych na liście, wybierz Odśwież kod aby zaktualizować pamięć podręczną.
Utwórz połączenie Snowflake
W tej sekcji skupiamy się na integracji źródła danych Snowflake z SageMaker Studio. Tworzenie kont, baz danych i magazynów Snowflake wykracza poza zakres tego posta. Aby rozpocząć korzystanie ze Snowflake, zapoznaj się z sekcją Podręcznik użytkownika płatka śniegu. W tym poście koncentrujemy się na utworzeniu pliku JSON z definicją płatka śniegu i nawiązaniu połączenia ze źródłem danych płatka śniegu za pomocą kleju AWS.
Utwórz klucz tajny Menedżera sekretów
Możesz połączyć się ze swoim kontem Snowflake, używając identyfikatora użytkownika i hasła lub kluczy prywatnych. Aby połączyć się przy użyciu identyfikatora użytkownika i hasła, musisz bezpiecznie przechowywać swoje poświadczenia w Menedżerze sekretów. Jak wspomniano wcześniej, chociaż możliwe jest osadzenie tych informacji w PythonProperties, nie zaleca się przechowywania poufnych informacji w formacie zwykłego tekstu. Zawsze upewnij się, że wrażliwe dane są traktowane bezpiecznie, aby uniknąć potencjalnych zagrożeń bezpieczeństwa.
Aby przechowywać informacje w Menedżerze sekretów, wykonaj następujące kroki:
- W konsoli Secrets Manager wybierz Przechowaj nowy sekret.
- W razie zamówieenia projektu Typ tajnywybierz Inny rodzaj tajemnicy.
- Wybierz parę klucz-wartość zwykły tekst i wprowadź następujące informacje:
- Wprowadź nazwę swojego sekretu, np
sm-sql-snowflake-secret. - Pozostałe ustawienia pozostaw jako domyślne lub dostosuj w razie potrzeby.
- Stwórz sekret.
Utwórz połączenie klejowe AWS dla płatka śniegu
Jak wspomniano wcześniej, połączenia AWS Glue są niezbędne do uzyskania dostępu do dowolnego połączenia z SageMaker Studio. Możesz znaleźć listę wszystkie obsługiwane właściwości połączenia dla płatka śniegu. Poniżej znajduje się przykładowa definicja połączenia JSON dla płatka śniegu. Zastąp wartości zastępcze odpowiednimi wartościami przed zapisaniem ich na dysku:
Aby utworzyć obiekt połączenia AWS Glue dla źródła danych Snowflake, użyj następującego polecenia:
To polecenie tworzy nowe połączenie ze źródłem danych Snowflake w panelu przeglądarki SQL, które można przeglądać, i można uruchamiać względem niego zapytania SQL z komórki notatnika JupyterLab.

Utwórz połączenie Amazon Redshift
Amazon Redshift to w pełni zarządzana usługa hurtowni danych o skali petabajtów, która upraszcza i zmniejsza koszty analizowania wszystkich danych przy użyciu standardowego SQL. Procedura tworzenia połączenia Amazon Redshift jest bardzo podobna do procedury tworzenia połączenia Snowflake.
Utwórz klucz tajny Menedżera sekretów
Podobnie jak w przypadku konfiguracji Snowflake, aby połączyć się z Amazon Redshift przy użyciu identyfikatora użytkownika i hasła, musisz bezpiecznie przechowywać informacje o sekretach w Menedżerze sekretów. Wykonaj następujące kroki:
- W konsoli Secrets Manager wybierz Przechowaj nowy sekret.
- W razie zamówieenia projektu Typ tajnywybierz Poświadczenia dla klastra Amazon Redshift.
- Wprowadź dane uwierzytelniające używane do logowania, aby uzyskać dostęp do Amazon Redshift jako źródła danych.
- Wybierz klaster przesunięcia ku czerwieni powiązany z kluczami tajnymi.
- Wprowadź nazwę sekretu, np
sm-sql-redshift-secret. - Pozostałe ustawienia pozostaw jako domyślne lub dostosuj w razie potrzeby.
- Stwórz sekret.
Wykonując te kroki, masz pewność, że dane uwierzytelniające połączenia są obsługiwane bezpiecznie, korzystając z solidnych funkcji bezpieczeństwa AWS do skutecznego zarządzania wrażliwymi danymi.
Utwórz połączenie AWS Glue dla Amazon Redshift
Aby skonfigurować połączenie z Amazon Redshift przy użyciu definicji JSON, wypełnij niezbędne pola i zapisz na dysku następującą konfigurację JSON:
Aby utworzyć obiekt połączenia AWS Glue dla źródła danych Redshift, użyj następującego polecenia AWS CLI:
To polecenie tworzy połączenie w AWS Glue połączone ze źródłem danych Redshift. Jeśli polecenie zostanie wykonane pomyślnie, w notatniku SageMaker Studio JupyterLab będzie można zobaczyć źródło danych Redshift, gotowe do wykonywania zapytań SQL i przeprowadzania analizy danych.

Utwórz połączenie Athena
Athena to w pełni zarządzana usługa zapytań SQL firmy AWS, która umożliwia analizę danych przechowywanych w Amazon S3 przy użyciu standardowego SQL. Aby skonfigurować połączenie Athena jako źródło danych w przeglądarce SQL notatnika JupyterLab, należy utworzyć przykładową definicję połączenia Athena w formacie JSON. Następująca struktura JSON konfiguruje szczegóły niezbędne do połączenia z usługą Athena, określając katalog danych, katalog pomostowy S3 i region:
Aby utworzyć obiekt połączenia AWS Glue dla źródła danych Athena, użyj następującego polecenia AWS CLI:
Jeśli polecenie się powiedzie, będziesz mieć dostęp do katalogu danych i tabel Athena bezpośrednio z przeglądarki SQL w notatniku SageMaker Studio JupyterLab.

Zapytaj o dane z wielu źródeł
Jeśli masz wiele źródeł danych zintegrowanych z SageMaker Studio za pośrednictwem wbudowanej przeglądarki SQL i funkcji notatnika SQL, możesz szybko uruchamiać zapytania i bezproblemowo przełączać się między źródłami danych w kolejnych komórkach notatnika. Ta funkcja umożliwia płynne przejścia między różnymi bazami danych lub źródłami danych podczas przepływu pracy analitycznej.
Możesz uruchamiać zapytania względem zróżnicowanej kolekcji źródeł danych i przenosić wyniki bezpośrednio do przestrzeni Pythona w celu dalszej analizy lub wizualizacji. Ułatwia to tzw %%sm_sql magiczne polecenie dostępne w notatnikach SageMaker Studio. Aby wyprowadzić wyniki zapytania SQL do ramki DataFrame pandy, istnieją dwie opcje:
- Z paska narzędzi komórki notatnika wybierz typ wyniku Ramka danych i nazwij zmienną DataFrame
- Dołącz następujący parametr do pliku
%%sm_sqlpolecenie:
Poniższy diagram ilustruje ten przepływ pracy i pokazuje, jak można bez wysiłku uruchamiać zapytania między różnymi źródłami w kolejnych komórkach notatnika, a także szkolić model SageMaker przy użyciu zadań szkoleniowych lub bezpośrednio w notatniku przy użyciu lokalnych obliczeń. Dodatkowo diagram pokazuje, jak wbudowana integracja SQL w SageMaker Studio upraszcza procesy wyodrębniania i budowania bezpośrednio w znanym środowisku komórki notatnika JupyterLab.

Tekst do SQL: Używanie języka naturalnego w celu usprawnienia tworzenia zapytań
SQL to złożony język, który wymaga zrozumienia baz danych, tabel, składni i metadanych. Obecnie generatywna sztuczna inteligencja (AI) umożliwia pisanie złożonych zapytań SQL bez konieczności posiadania dogłębnej znajomości języka SQL. Rozwój LLM znacząco wpłynął na generowanie SQL w oparciu o przetwarzanie języka naturalnego (NLP), umożliwiając tworzenie precyzyjnych zapytań SQL na podstawie opisów w języku naturalnym — technikę określaną jako Text-to-SQL. Jednakże istotne jest uznanie nieodłącznych różnic między językiem ludzkim a językiem SQL. Język ludzki może czasami być niejednoznaczny lub nieprecyzyjny, podczas gdy SQL jest ustrukturyzowany, wyraźny i jednoznaczny. Wypełnienie tej luki i dokładne przekształcenie języka naturalnego w zapytania SQL może stanowić ogromne wyzwanie. Po otrzymaniu odpowiednich podpowiedzi LLM mogą pomóc wypełnić tę lukę, rozumiejąc intencje stojące za ludzkim językiem i odpowiednio generując dokładne zapytania SQL.
Wraz z udostępnieniem funkcji zapytań SQL w notesie SageMaker Studio, SageMaker Studio ułatwia inspekcję baz danych i schematów oraz tworzenie, uruchamianie i debugowanie zapytań SQL bez konieczności opuszczania środowiska IDE notatnika Jupyter. W tej sekcji omówiono, w jaki sposób funkcje zamiany tekstu na SQL w zaawansowanych narzędziach LLM mogą ułatwić generowanie zapytań SQL przy użyciu języka naturalnego w notatnikach Jupyter. Stosujemy najnowocześniejszy model Text-to-SQL defog/sqlcoder-7b-2 w połączeniu z Jupyter AI, generatywnym asystentem AI zaprojektowanym specjalnie dla notebooków Jupyter, do tworzenia złożonych zapytań SQL z języka naturalnego. Korzystając z tego zaawansowanego modelu, możemy bez wysiłku i wydajnie tworzyć złożone zapytania SQL przy użyciu języka naturalnego, poprawiając w ten sposób nasze doświadczenie SQL w notatnikach.
Prototypowanie notebooków przy użyciu Hugging Face Hub
Aby rozpocząć prototypowanie, potrzebujesz:
- Kod GitHub – Kod przedstawiony w tej sekcji jest dostępny poniżej GitHub repo i poprzez odniesienie do przykładowy notatnik.
- Przestrzeń JupyterLab – Dostęp do przestrzeni JupyterLab Space SageMaker Studio wspieranej przez instancje oparte na GPU jest niezbędny. Dla
defog/sqlcoder-7b-2model, zalecany jest model parametrów 7B, używający instancji ml.g5.2xlarge. Alternatywy takie jakdefog/sqlcoder-70b-alpha lubdefog/sqlcoder-34b-alphanadają się również do konwersji języka naturalnego na SQL, ale do prototypowania mogą być wymagane większe typy instancji. Upewnij się, że masz limit, aby uruchomić instancję wspieraną przez GPU, przechodząc do konsoli Service Quotas, wyszukując SageMaker i wyszukującStudio JupyterLab Apps running on <instance type>.
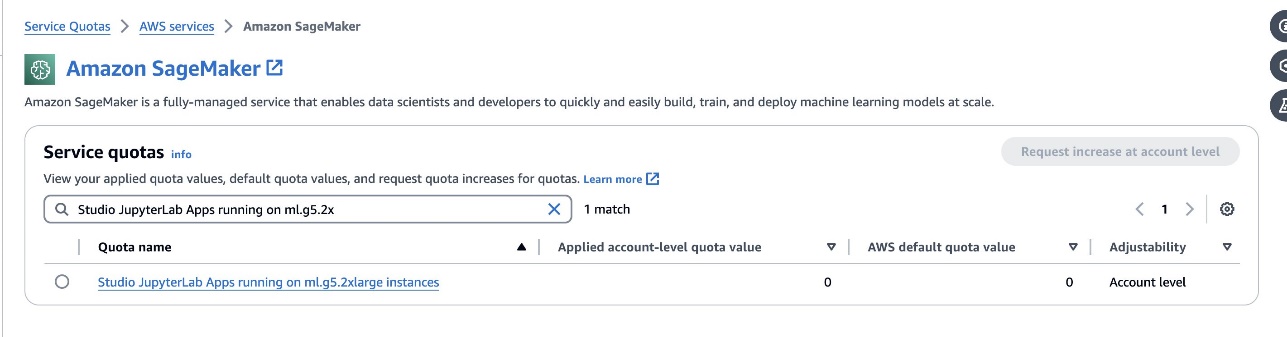
Uruchom nową, wspieraną przez GPU przestrzeń JupyterLab Space ze swojego SageMaker Studio. Zaleca się utworzenie nowej przestrzeni JupyterLab o pojemności co najmniej 75 GB Sklep Amazon Elastic Block (Amazon EBS) pamięć dla modelu parametrów 7B.


- Przytulanie twarzy Hub – Jeśli Twoja domena SageMaker Studio ma dostęp do pobierania modeli z Przytulanie twarzy Hub, możesz użyć
AutoModelForCausalLMklasa od przytulająca twarz/transformatory aby automatycznie pobierać modele i przypinać je do lokalnych procesorów graficznych. Wagi modeli będą przechowywane w pamięci podręcznej komputera lokalnego. Zobacz następujący kod:
Po całkowitym pobraniu modelu i załadowaniu go do pamięci powinieneś zaobserwować wzrost wykorzystania procesora graficznego na komputerze lokalnym. Oznacza to, że model aktywnie wykorzystuje zasoby GPU do zadań obliczeniowych. Możesz to sprawdzić we własnej przestrzeni JupyterLab, uruchamiając nvidia-smi (w przypadku jednorazowego wyświetlenia) lub nvidia-smi —loop=1 (powtarzać co sekundę) z terminala JupyterLab.

Modele zamiany tekstu na SQL doskonale rozumieją intencje i kontekst żądania użytkownika, nawet jeśli używany język jest potoczny lub niejednoznaczny. Proces ten obejmuje tłumaczenie danych wejściowych w języku naturalnym na odpowiednie elementy schematu bazy danych, takie jak nazwy tabel, nazwy kolumn i warunki. Jednak gotowy model zamiany tekstu na SQL nie będzie z natury znał struktury hurtowni danych, konkretnych schematów bazy danych ani nie był w stanie dokładnie zinterpretować zawartości tabeli wyłącznie na podstawie nazw kolumn. Aby efektywnie wykorzystać te modele do generowania praktycznych i wydajnych zapytań SQL z języka naturalnego, konieczne jest dostosowanie modelu generowania tekstu SQL do konkretnego schematu bazy danych hurtowni. Dostosowanie to jest ułatwione dzięki zastosowaniu LLM podpowiada. Poniżej znajduje się zalecany szablon podpowiedzi dla modelu konwersji tekstu na SQL defog/sqlcoder-7b-2, podzielony na cztery części:
- Zadanie – W tej sekcji należy określić zadanie wysokiego poziomu, które ma wykonać model. Powinien zawierać typ zaplecza bazy danych (taki jak Amazon RDS, PostgreSQL lub Amazon Redshift), aby model był świadomy wszelkich niuansów składniowych, które mogą mieć wpływ na wygenerowanie końcowego zapytania SQL.
- Instrukcje – Ta sekcja powinna definiować granice zadań i świadomość domeny modelu i może zawierać kilka przykładów pomagających modelowi w generowaniu precyzyjnie dostrojonych zapytań SQL.
- Schemat bazy danych – W tej sekcji należy szczegółowo opisać schematy bazy danych hurtowni, opisując relacje między tabelami i kolumnami, aby pomóc modelowi w zrozumieniu struktury bazy danych.
- Odpowiedź – Ta sekcja jest zarezerwowana dla modelu w celu wyprowadzenia odpowiedzi na zapytanie SQL na wejście w języku naturalnym.
Przykład schematu bazy danych i podpowiedzi użytych w tej sekcji jest dostępny w pliku Repozytorium GitHub.
Szybka inżynieria nie polega tylko na formułowaniu pytań lub stwierdzeń; to zniuansowana sztuka i nauka, która znacząco wpływa na jakość interakcji z modelem AI. Sposób, w jaki tworzysz podpowiedzi, może znacząco wpłynąć na charakter i użyteczność reakcji sztucznej inteligencji. Umiejętność ta ma kluczowe znaczenie w maksymalizowaniu potencjału interakcji AI, szczególnie w przypadku złożonych zadań wymagających specjalistycznego zrozumienia i szczegółowych odpowiedzi.
Ważne jest, aby mieć możliwość szybkiego zbudowania i przetestowania odpowiedzi modelu dla danego podpowiedzi oraz optymalizacji podpowiedzi na podstawie odpowiedzi. Notatniki JupyterLab umożliwiają natychmiastowe otrzymywanie informacji zwrotnych o modelu działającym na komputerze lokalnym oraz optymalizację monitów i dalsze dostrajanie odpowiedzi modelu lub całkowitą zmianę modelu. W tym poście używamy notebooka SageMaker Studio JupyterLab z procesorem graficznym NVIDIA A5.2G 10 GB firmy ml.g24xlarge do uruchamiania wnioskowania modelu Text-to-SQL na notebooku i interaktywnego budowania podpowiedzi modelu do czasu, aż odpowiedź modelu zostanie dostatecznie dostrojona, aby zapewnić odpowiedzi, które można bezpośrednio wykonać w komórkach SQL JupyterLab. Aby uruchomić wnioskowanie o modelu i jednocześnie przesyłać strumieniowo odpowiedzi modelu, używamy kombinacji model.generate i TextIteratorStreamer zgodnie z definicją w następującym kodzie:
Dane wyjściowe modelu można ozdobić magią SQL SageMaker %%sm_sql ..., co pozwala notatnikowi JupyterLab zidentyfikować komórkę jako komórkę SQL.
Hostuj modele Text-to-SQL jako punkty końcowe SageMaker
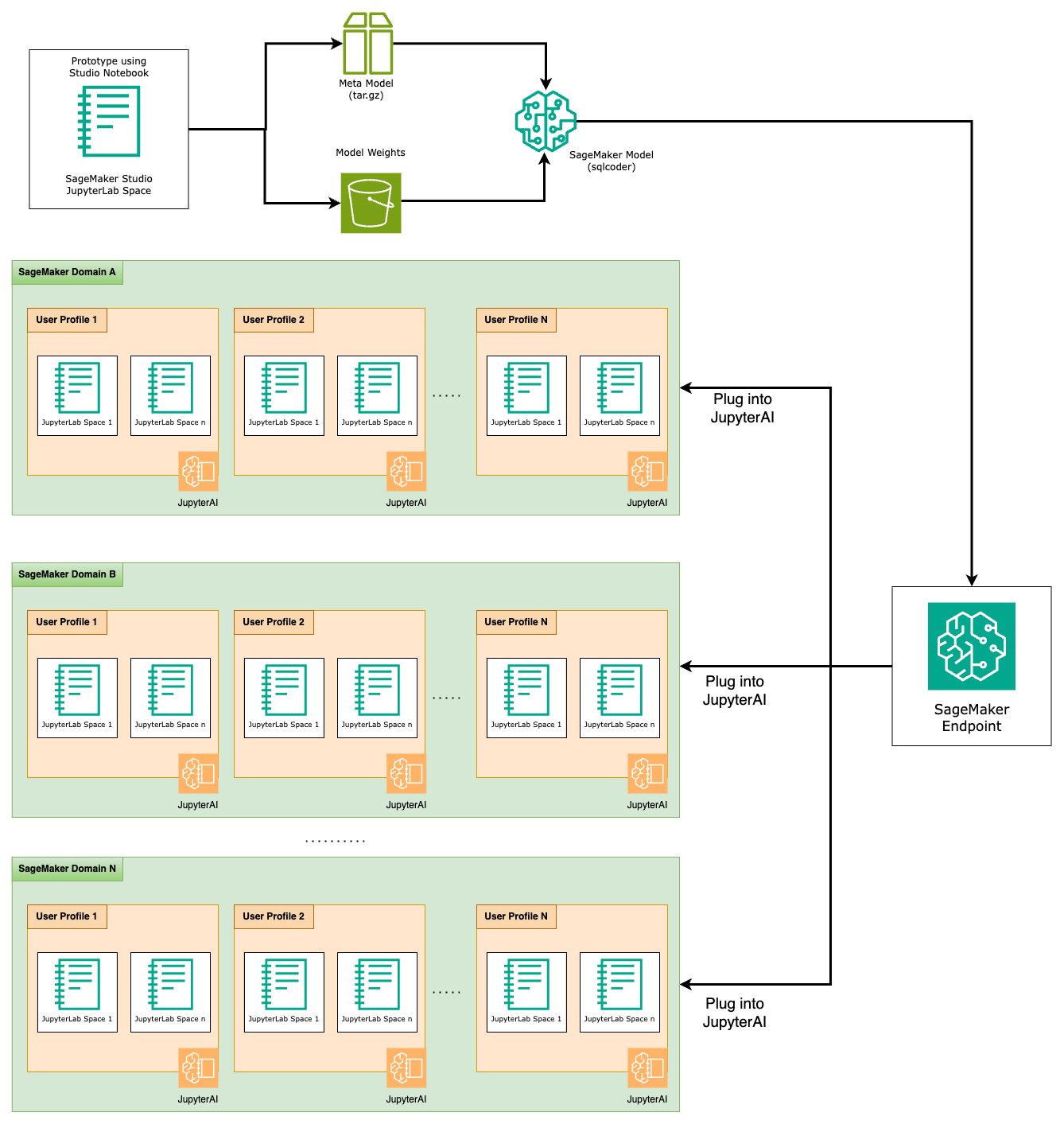
Na koniec etapu prototypowania wybraliśmy preferowany LLM Text-to-SQL, efektywny format podpowiedzi i odpowiedni typ instancji do hostowania modelu (pojedynczy procesor graficzny lub wiele procesorów graficznych). SageMaker ułatwia skalowalny hosting niestandardowych modeli poprzez wykorzystanie punktów końcowych SageMaker. Te punkty końcowe można zdefiniować według określonych kryteriów, co pozwala na wdrożenie LLM jako punktów końcowych. Ta funkcja umożliwia skalowanie rozwiązania do szerszego grona odbiorców, umożliwiając użytkownikom generowanie zapytań SQL na podstawie danych wejściowych w języku naturalnym przy użyciu niestandardowych hostowanych LLM. Poniższy diagram ilustruje tę architekturę.
Aby hostować LLM jako punkt końcowy SageMaker, generujesz kilka artefaktów.
Pierwszym artefaktem są wagi modeli. Obsługa biblioteki głębokiej Java SageMaker (DJL). kontenery umożliwiają konfigurowanie konfiguracji za pomocą meta serwowanie.właściwości plik, który umożliwia kierowanie sposobem pozyskiwania modeli — bezpośrednio z Hugging Face Hub lub poprzez pobranie artefaktów modeli z Amazon S3. Jeśli określisz model_id=defog/sqlcoder-7b-2, DJL Serving podejmie próbę bezpośredniego pobrania tego modelu z Hugging Face Hub. Jednakże za każdym razem, gdy punkt końcowy zostanie wdrożony lub będzie elastycznie skalowany, mogą zostać naliczone opłaty za ruch przychodzący/wychodzący z sieci. Aby uniknąć tych opłat i potencjalnie przyspieszyć pobieranie artefaktów modelu, zaleca się pominięcie korzystania z nich model_id in serving.properties i zapisz wagi modelu jako artefakty S3 i określ je tylko za pomocą s3url=s3://path/to/model/bin.
Zapisanie modelu (wraz z tokenizerem) na dysku i przesłanie go do Amazon S3 można wykonać za pomocą zaledwie kilku linijek kodu:
Używany jest także plik podpowiedzi bazy danych. W tej konfiguracji zachęta bazy danych składa się z Task, Instructions, Database Schema, Answer sections. W przypadku bieżącej architektury dla każdego schematu bazy danych przydzielamy oddzielny plik podpowiedzi. Istnieje jednak możliwość rozszerzenia tej konfiguracji w celu uwzględnienia wielu baz danych w pliku podpowiedzi, co pozwala modelowi na uruchamianie złączeń złożonych między bazami danych na tym samym serwerze. Na etapie prototypowania zapisujemy zachętę bazy danych jako plik tekstowy o nazwie <Database-Glue-Connection-Name>.prompt, Gdzie Database-Glue-Connection-Name odpowiada nazwie połączenia widocznej w Twoim środowisku JupyterLab. Na przykład ten post odnosi się do połączenia Snowflake o nazwie Airlines_Dataset, więc zostanie nazwany plik zachęty bazy danych Airlines_Dataset.prompt. Plik ten jest następnie przechowywany na Amazon S3, a następnie odczytywany i buforowany przez naszą logikę obsługi modelu.
Co więcej, architektura ta umożliwia każdemu autoryzowanemu użytkownikowi tego punktu końcowego definiowanie, przechowywanie i generowanie zapytań SQL w języku naturalnym bez konieczności wielokrotnego ponownego wdrażania modelu. Używamy poniższych przykład zachęty bazy danych aby zademonstrować funkcjonalność zamiany tekstu na SQL.
Następnie wygeneruj niestandardową logikę usługi modelu. W tej sekcji opisano niestandardową logikę wnioskowania o nazwie model.py. Ten skrypt ma na celu optymalizację wydajności i integracji naszych usług zamiany tekstu na SQL:
- Zdefiniuj logikę buforowania pliku podpowiedzi bazy danych – Aby zminimalizować opóźnienia, wdrażamy niestandardową logikę pobierania i buforowania plików podpowiedzi bazy danych. Mechanizm ten zapewnia łatwą dostępność podpowiedzi, redukując obciążenie związane z częstym pobieraniem.
- Zdefiniuj niestandardową logikę wnioskowania modelu – Aby zwiększyć szybkość wnioskowania, nasz model zamiany tekstu na SQL jest ładowany w precyzyjnym formacie float16, a następnie konwertowany na model DeepSpeed. Ten krok pozwala na bardziej wydajne obliczenia. Dodatkowo w ramach tej logiki określasz, które parametry użytkownicy mogą dostosować podczas wywołań wnioskowania, aby dostosować funkcjonalność do swoich potrzeb.
- Zdefiniuj niestandardową logikę wejścia i wyjścia – Ustanowienie jasnych i dostosowanych formatów wejścia/wyjścia jest niezbędne dla płynnej integracji z dalszymi aplikacjami. Jedną z takich aplikacji jest JupyterAI, o którym piszemy w kolejnym rozdziale.
Dodatkowo dołączamy m.in serving.properties plik, który działa jako globalny plik konfiguracyjny dla modeli hostowanych za pomocą usługi DJL. Aby uzyskać więcej informacji, zobacz Konfiguracje i ustawienia.
Na koniec możesz także dołączyć a requirements.txt plik, aby zdefiniować dodatkowe moduły wymagane do wnioskowania i spakować wszystko do archiwum tar w celu wdrożenia.
Zobacz następujący kod:
Zintegruj swój punkt końcowy z asystentem AI SageMaker Studio Jupyter
Sztuczna inteligencja Jupytera to narzędzie typu open source, które przenosi generatywną sztuczną inteligencję do notebooków Jupyter, oferując solidną i przyjazną dla użytkownika platformę do odkrywania generatywnych modeli sztucznej inteligencji. Zwiększa produktywność w notatnikach JupyterLab i Jupyter, zapewniając funkcje takie jak magia %%ai do tworzenia generatywnego placu zabaw AI w notatnikach, natywny interfejs czatu w JupyterLab do interakcji z AI jako asystent konwersacyjny oraz obsługa szerokiej gamy LLM z dostawcy lubią Amazon Tytan, AI21, Anthropic, Cohere i Hugging Face lub usługi zarządzane, takie jak Amazońska skała macierzysta i punkty końcowe SageMaker. W tym poście korzystamy z gotowej integracji Jupyter AI z punktami końcowymi SageMaker, aby zapewnić możliwość zamiany tekstu na SQL w notatnikach JupyterLab. Narzędzie Jupyter AI jest preinstalowane we wszystkich obszarach SageMaker Studio JupyterLab Spaces wspieranych przez Obrazy dystrybucji SageMaker; użytkownicy końcowi nie muszą dokonywać żadnych dodatkowych konfiguracji, aby rozpocząć korzystanie z rozszerzenia Jupyter AI w celu integracji z punktem końcowym hostowanym przez SageMaker. W tej sekcji omawiamy dwa sposoby wykorzystania zintegrowanego narzędzia Jupyter AI.
Jupyter AI w notatniku używający magii
Sztuczna inteligencja Jupytera %%ai Polecenie magic umożliwia przekształcenie notatników SageMaker Studio JupyterLab w odtwarzalne, generatywne środowisko AI. Aby rozpocząć korzystanie z magii AI, upewnij się, że załadowałeś rozszerzenie jupyter_ai_magics %%ai magię i dodatkowo ładuję amazon_sagemaker_sql_magic w użyciu %%sm_sql magia:
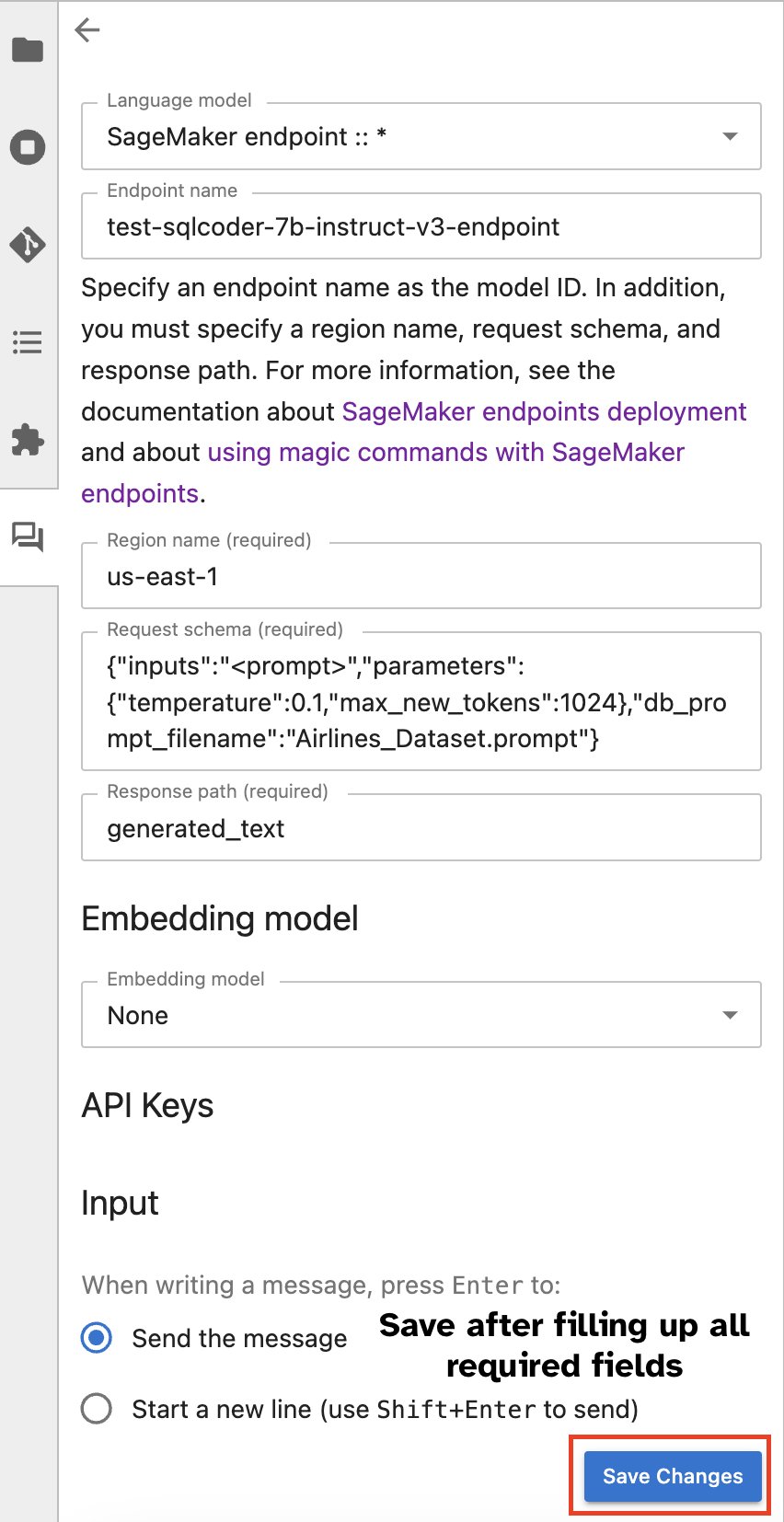
Aby uruchomić połączenie z punktem końcowym SageMaker z notatnika za pomocą %%ai magic, podaj następujące parametry i zbuduj polecenie w następujący sposób:
- –nazwa-regionu – Określ region, w którym wdrożono punkt końcowy. Dzięki temu żądanie jest kierowane do właściwej lokalizacji geograficznej.
- –schemat-żądania – Dołącz schemat danych wejściowych. Ten schemat przedstawia oczekiwany format i typy danych wejściowych, których model potrzebuje do przetworzenia żądania.
- –ścieżka-odpowiedzi – Zdefiniuj ścieżkę w obiekcie odpowiedzi, w której znajdują się dane wyjściowe modelu. Ta ścieżka służy do wyodrębniania odpowiednich danych z odpowiedzi zwróconej przez model.
- -f (opcjonalnie) - To jest formater wyjściowy flaga wskazująca typ wyniku zwróconego przez model. W kontekście notatnika Jupyter, jeśli dane wyjściowe są kodem, należy odpowiednio ustawić tę flagę, aby sformatować dane wyjściowe jako kod wykonywalny na górze komórki notatnika Jupyter, po której następuje obszar wprowadzania wolnego tekstu umożliwiający interakcję użytkownika.
Na przykład polecenie w komórce notatnika Jupyter może wyglądać jak następujący kod:
Okno czatu Jupyter AI
Alternatywnie możesz wchodzić w interakcję z punktami końcowymi SageMaker za pośrednictwem wbudowanego interfejsu użytkownika, upraszczając proces generowania zapytań lub prowadzenia dialogu. Przed rozpoczęciem rozmowy z punktem końcowym SageMaker skonfiguruj odpowiednie ustawienia w Jupyter AI dla punktu końcowego SageMaker, jak pokazano na poniższym zrzucie ekranu.
 |
 |
Wnioski
SageMaker Studio upraszcza i usprawnia pracę analityka danych, integrując obsługę SQL z notatnikami JupyterLab. Dzięki temu badacze danych mogą skoncentrować się na swoich zadaniach bez konieczności zarządzania wieloma narzędziami. Co więcej, nowa wbudowana integracja SQL w SageMaker Studio umożliwia osobom przetwarzającym dane bezproblemowe generowanie zapytań SQL przy użyciu tekstu w języku naturalnym jako danych wejściowych, przyspieszając w ten sposób ich przepływ pracy.
Zachęcamy do zapoznania się z tymi funkcjami w SageMaker Studio. Aby uzyskać więcej informacji, zobacz Przygotuj dane za pomocą SQL w Studio.
dodatek
Włącz przeglądarkę SQL i komórkę SQL notesu w niestandardowych środowiskach
Jeśli nie używasz obrazu dystrybucyjnego SageMaker lub używasz obrazów dystrybucyjnych w wersji 1.5 lub starszej, uruchom następujące polecenia, aby włączyć funkcję przeglądania SQL w środowisku JupyterLab:
Przenieś widżet przeglądarki SQL
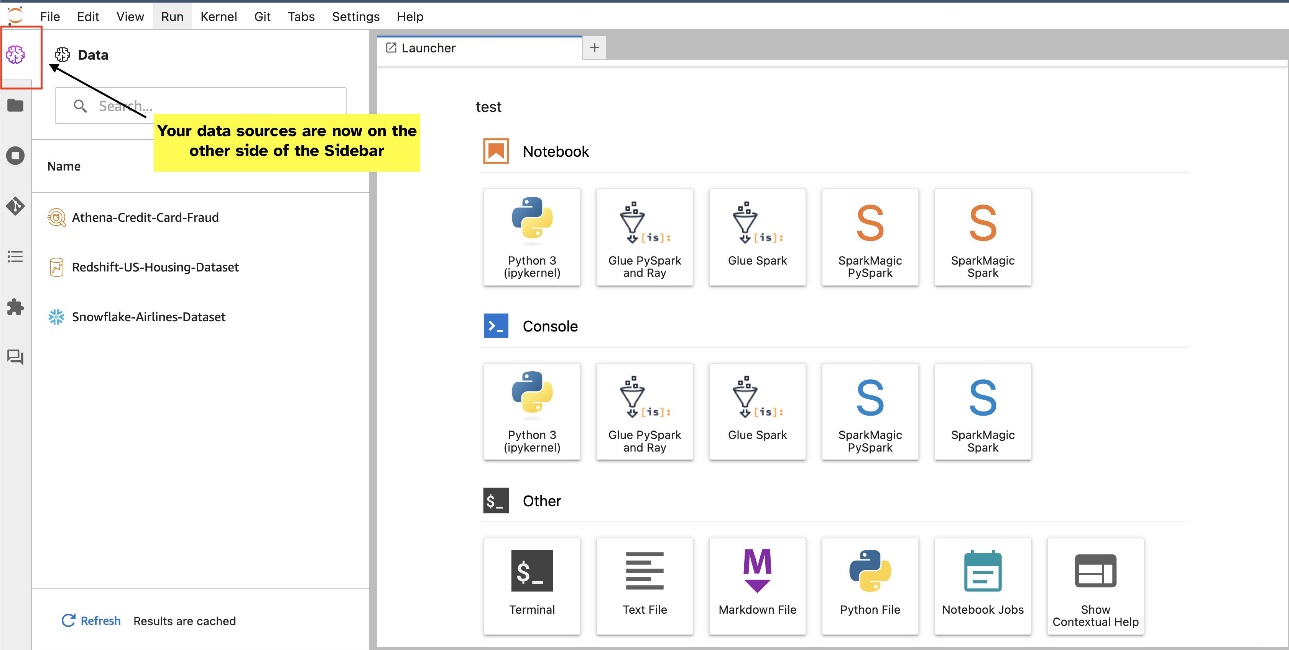
Widżety JupyterLab pozwalają na relokację. W zależności od preferencji możesz przenosić widżety na dowolną stronę panelu widżetów JupyterLab. Jeśli wolisz, możesz przenieść kierunek widżetu SQL na przeciwną stronę (od prawej do lewej) paska bocznego, klikając prawym przyciskiem myszy ikonę widżetu i wybierając Zmień stronę paska bocznego.
 |
 |
O autorach
 Pranava Murthy’ego jest architektem rozwiązań specjalistycznych AI/ML w AWS. Koncentruje się na pomaganiu klientom w budowaniu, szkoleniu, wdrażaniu i migracji obciążeń uczenia maszynowego (ML) do SageMaker. Wcześniej pracował w branży półprzewodników, opracowując duże modele widzenia komputerowego (CV) i przetwarzania języka naturalnego (NLP) w celu ulepszenia procesów półprzewodnikowych przy użyciu najnowocześniejszych technik ML. W wolnym czasie lubi grać w szachy i podróżować. Możesz znaleźć Pranav na LinkedIn.
Pranava Murthy’ego jest architektem rozwiązań specjalistycznych AI/ML w AWS. Koncentruje się na pomaganiu klientom w budowaniu, szkoleniu, wdrażaniu i migracji obciążeń uczenia maszynowego (ML) do SageMaker. Wcześniej pracował w branży półprzewodników, opracowując duże modele widzenia komputerowego (CV) i przetwarzania języka naturalnego (NLP) w celu ulepszenia procesów półprzewodnikowych przy użyciu najnowocześniejszych technik ML. W wolnym czasie lubi grać w szachy i podróżować. Możesz znaleźć Pranav na LinkedIn.
 Varuna Shaha jest inżynierem oprogramowania pracującym w Amazon SageMaker Studio w Amazon Web Services. Koncentruje się na budowaniu interaktywnych rozwiązań ML, które upraszczają procesy przetwarzania i przygotowywania danych. W wolnym czasie Varun lubi zajęcia na świeżym powietrzu, w tym piesze wędrówki i jazdę na nartach, i zawsze jest chętny do odkrywania nowych, ekscytujących miejsc.
Varuna Shaha jest inżynierem oprogramowania pracującym w Amazon SageMaker Studio w Amazon Web Services. Koncentruje się na budowaniu interaktywnych rozwiązań ML, które upraszczają procesy przetwarzania i przygotowywania danych. W wolnym czasie Varun lubi zajęcia na świeżym powietrzu, w tym piesze wędrówki i jazdę na nartach, i zawsze jest chętny do odkrywania nowych, ekscytujących miejsc.
 Sumedha Swamy jest głównym menedżerem produktu w Amazon Web Services, gdzie kieruje zespołem SageMaker Studio realizującym misję opracowywania preferowanego środowiska IDE do analityki danych i uczenia maszynowego. Ostatnie 15 lat poświęcił tworzeniu produktów konsumenckich i korporacyjnych opartych na uczeniu maszynowym.
Sumedha Swamy jest głównym menedżerem produktu w Amazon Web Services, gdzie kieruje zespołem SageMaker Studio realizującym misję opracowywania preferowanego środowiska IDE do analityki danych i uczenia maszynowego. Ostatnie 15 lat poświęcił tworzeniu produktów konsumenckich i korporacyjnych opartych na uczeniu maszynowym.
 Bosko Albuquerque jest starszym architektem rozwiązań partnerskich w AWS i ma ponad 20-letnie doświadczenie w pracy z bazami danych i produktami analitycznymi od dostawców baz danych dla przedsiębiorstw i dostawców chmury. Pomagał firmom technologicznym w projektowaniu i wdrażaniu rozwiązań i produktów do analizy danych.
Bosko Albuquerque jest starszym architektem rozwiązań partnerskich w AWS i ma ponad 20-letnie doświadczenie w pracy z bazami danych i produktami analitycznymi od dostawców baz danych dla przedsiębiorstw i dostawców chmury. Pomagał firmom technologicznym w projektowaniu i wdrażaniu rozwiązań i produktów do analizy danych.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

