Amazon SageMaker Studio gir en fullstendig administrert løsning for dataforskere for interaktivt å bygge, trene og distribuere maskinlæringsmodeller (ML). I prosessen med å jobbe med ML-oppgavene starter dataforskere vanligvis arbeidsflyten ved å oppdage relevante datakilder og koble til dem. De bruker deretter SQL til å utforske, analysere, visualisere og integrere data fra ulike kilder før de bruker dem i ML-trening og slutning. Tidligere fant dataforskere ofte å sjonglere med flere verktøy for å støtte SQL i arbeidsflyten, noe som hindret produktiviteten.
Vi er glade for å kunngjøre at JupyterLab-notatbøker i SageMaker Studio nå kommer med innebygd støtte for SQL. Dataforskere kan nå:
- Koble til populære datatjenester inkludert Amazonas Athena, Amazon RedShift, Amazon DataZone, og Snowflake direkte i notatbøkene
- Bla gjennom og søk etter databaser, skjemaer, tabeller og visninger, og forhåndsvis data i grensesnittet for den bærbare datamaskinen
- Bland SQL- og Python-kode i samme notatbok for effektiv utforskning og transformasjon av data for bruk i ML-prosjekter
- Bruk utviklerproduktivitetsfunksjoner som SQL-kommandofullføring, kodeformateringshjelp og syntaksutheving for å akselerere kodeutvikling og forbedre den generelle utviklerproduktiviteten
I tillegg kan administratorer sikkert administrere tilkoblinger til disse datatjenestene, slik at dataforskere kan få tilgang til autoriserte data uten å måtte administrere legitimasjon manuelt.
I dette innlegget veileder vi deg gjennom å sette opp denne funksjonen i SageMaker Studio, og veileder deg gjennom ulike funksjoner i denne funksjonen. Deretter viser vi hvordan du kan forbedre SQL-opplevelsen i den bærbare datamaskinen ved å bruke tekst-til-SQL-funksjoner levert av avanserte store språkmodeller (LLM) for å skrive komplekse SQL-spørringer ved å bruke naturlig språktekst som input. Til slutt, for å gjøre det mulig for et bredere publikum av brukere å generere SQL-spørringer fra naturlig språkinndata i notatbøkene sine, viser vi deg hvordan du distribuerer disse tekst-til-SQL-modellene ved å bruke Amazon SageMaker endepunkter.
Løsningsoversikt
Med SageMaker Studio JupyterLab notebooks SQL-integrasjon kan du nå koble til populære datakilder som Snowflake, Athena, Amazon Redshift og Amazon DataZone. Denne nye funksjonen lar deg utføre ulike funksjoner.
For eksempel kan du visuelt utforske datakilder som databaser, tabeller og skjemaer direkte fra JupyterLab-økosystemet. Hvis dine bærbare miljøer kjører på SageMaker Distribution 1.6 eller høyere, se etter en ny widget på venstre side av JupyterLab-grensesnittet. Dette tillegget forbedrer datatilgjengelighet og administrasjon i utviklingsmiljøet ditt.
Hvis du ikke bruker foreslått SageMaker-distribusjon (1.5 eller lavere) eller i et tilpasset miljø, kan du se vedlegget for mer informasjon.

Etter at du har satt opp tilkoblinger (illustrert i neste avsnitt), kan du liste datatilkoblinger, bla gjennom databaser og tabeller og inspisere skjemaer.

SageMaker Studio JupyterLab innebygde SQL-utvidelse lar deg også kjøre SQL-spørringer direkte fra en bærbar PC. Jupyter-notatbøker kan skille mellom SQL- og Python-kode ved å bruke %%sm_sql magisk kommando, som må plasseres øverst i en celle som inneholder SQL-kode. Denne kommandoen signaliserer til JupyterLab at følgende instruksjoner er SQL-kommandoer i stedet for Python-kode. Utdataene fra en spørring kan vises direkte i den bærbare datamaskinen, noe som letter sømløs integrering av SQL- og Python-arbeidsflyter i dataanalysen.
Utdataene fra en spørring kan vises visuelt som HTML-tabeller, som vist i følgende skjermbilde.

De kan også skrives til en pandas DataFrame.

Forutsetninger
Sørg for at du har tilfredsstilt følgende forutsetninger for å bruke SageMaker Studio notebook SQL-opplevelse:
- SageMaker Studio V2 – Sørg for at du kjører den mest oppdaterte versjonen av din SageMaker Studio-domene og brukerprofiler. Hvis du for øyeblikket bruker SageMaker Studio Classic, se Migrerer fra Amazon SageMaker Studio Classic.
- IAM-rolle – SageMaker krever en AWS identitets- og tilgangsadministrasjon (IAM) rolle som skal tildeles et SageMaker Studio-domene eller brukerprofil for å administrere tillatelser effektivt. En oppdatering av utførelsesrollen kan være nødvendig for å få inn datasurfing og SQL-kjøringsfunksjonen. Følgende eksempelpolicy lar brukere gi, liste opp og kjøre AWS Lim, Athena, Amazon enkel lagringstjeneste (Amazon S3), AWS Secrets Manager, og Amazon Redshift-ressurser:
- JupyterLab Space – Du trenger tilgang til det oppdaterte SageMaker Studio og JupyterLab Space med SageMaker distribusjon v1.6 eller nyere bildeversjoner. Hvis du bruker tilpassede bilder for JupyterLab Spaces eller eldre versjoner av SageMaker Distribution (v1.5 eller lavere), kan du se vedlegget for instruksjoner for å installere nødvendige pakker og moduler for å aktivere denne funksjonen i miljøene dine. For å lære mer om SageMaker Studio JupyterLab Spaces, se Øk produktiviteten på Amazon SageMaker Studio: Vi introduserer JupyterLab Spaces og generative AI-verktøy.
- Datakildetilgangslegitimasjon – Denne notatbokfunksjonen i SageMaker Studio krever brukernavn og passordtilgang til datakilder som Snowflake og Amazon Redshift. Opprett brukernavn og passordbasert tilgang til disse datakildene hvis du ikke allerede har en. OAuth-basert tilgang til Snowflake er ikke en støttet funksjon når dette skrives.
- Last inn SQL-magi – Før du kjører SQL-spørringer fra en Jupyter-notebookcelle, er det viktig å laste inn SQL magics-utvidelsen. Bruk kommandoen
%load_ext amazon_sagemaker_sql_magicfor å aktivere denne funksjonen. I tillegg kan du kjøre%sm_sql?kommando for å vise en omfattende liste over støttede alternativer for spørring fra en SQL-celle. Disse alternativene inkluderer å angi en standard søkegrense på 1,000, kjøre en fullstendig utvinning og injisere spørringsparametere, blant annet. Dette oppsettet tillater fleksibel og effektiv SQL-datamanipulering direkte i ditt bærbare miljø.
Opprett databaseforbindelser
De innebygde SQL-nettlesings- og kjøringsmulighetene til SageMaker Studio er forbedret av AWS Glue-tilkoblinger. En AWS Glue-tilkobling er et AWS Glue Data Catalog-objekt som lagrer viktige data som påloggingsinformasjon, URI-strenger og virtuell privat sky (VPC)-informasjon for spesifikke datalagre. Disse forbindelsene brukes av AWS Glue-crawlere, jobber og utviklingsendepunkter for å få tilgang til ulike typer datalagre. Du kan bruke disse tilkoblingene for både kilde- og måldata, og til og med gjenbruke den samme tilkoblingen på tvers av flere crawlere eller trekke ut, transformere og laste (ETL) jobber.
For å utforske SQL-datakilder i venstre rute i SageMaker Studio, må du først lage AWS Glue-tilkoblingsobjekter. Disse forbindelsene letter tilgangen til forskjellige datakilder og lar deg utforske skjematiske dataelementer.
I de følgende delene går vi gjennom prosessen med å lage SQL-spesifikke AWS Glue-koblinger. Dette vil gjøre det mulig for deg å få tilgang til, se og utforske datasett på tvers av en rekke datalagre. For mer detaljert informasjon om AWS-limforbindelser, se Kobler til data.
Opprett en AWS Glue-tilkobling
Den eneste måten å bringe datakilder inn i SageMaker Studio er med AWS Glue-tilkoblinger. Du må opprette AWS Glue-forbindelser med spesifikke tilkoblingstyper. Når dette skrives, er den eneste støttede mekanismen for å opprette disse forbindelsene å bruke AWS kommandolinjegrensesnitt (AWS CLI).
Tilkoblingsdefinisjon JSON-fil
Når du kobler til forskjellige datakilder i AWS Glue, må du først opprette en JSON-fil som definerer tilkoblingsegenskapene – referert til som definisjonsfil for tilkobling. Denne filen er avgjørende for å etablere en AWS Glue-tilkobling og bør detaljere alle nødvendige konfigurasjoner for å få tilgang til datakilden. For beste praksis for sikkerhet, anbefales det å bruke Secrets Manager til å lagre sensitiv informasjon som passord på en sikker måte. I mellomtiden kan andre tilkoblingsegenskaper administreres direkte gjennom AWS Glue-tilkoblinger. Denne tilnærmingen sørger for at sensitiv legitimasjon er beskyttet samtidig som tilkoblingskonfigurasjonen er tilgjengelig og håndterbar.
Følgende er et eksempel på en tilkoblingsdefinisjon JSON:
Når du setter opp AWS Glue-tilkoblinger for datakildene dine, er det noen viktige retningslinjer å følge for å gi både funksjonalitet og sikkerhet:
- Stringifisering av egenskaper - Innen
PythonPropertiesnøkkel, sørg for at alle egenskaper er strengede nøkkelverdi-par. Det er avgjørende å unnslippe doble anførselstegn ved å bruke omvendt skråstrek () der det er nødvendig. Dette bidrar til å opprettholde riktig format og unngå syntaksfeil i JSON. - Håndtering av sensitiv informasjon – Selv om det er mulig å inkludere alle tilkoblingsegenskaper innenfor
PythonProperties, er det tilrådelig å ikke inkludere sensitive detaljer som passord direkte i disse egenskapene. Bruk heller Secrets Manager for å håndtere sensitiv informasjon. Denne tilnærmingen sikrer dine sensitive data ved å lagre dem i et kontrollert og kryptert miljø, borte fra hovedkonfigurasjonsfilene.
Opprett en AWS Glue-forbindelse ved å bruke AWS CLI
Etter at du har inkludert alle de nødvendige feltene i tilkoblingsdefinisjonen JSON-filen din, er du klar til å etablere en AWS Glue-tilkobling for datakilden din ved å bruke AWS CLI og følgende kommando:
Denne kommandoen starter en ny AWS Glue-tilkobling basert på spesifikasjonene som er beskrevet i JSON-filen din. Følgende er en rask oversikt over kommandokomponentene:
- -region – Dette spesifiserer AWS-regionen der AWS Glue-forbindelsen din skal opprettes. Det er avgjørende å velge regionen der datakildene og andre tjenester er plassert for å minimere ventetiden og overholde kravene til dataopphold.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Denne parameteren leder AWS CLI til å lese inngangskonfigurasjonen fra en lokal fil som inneholder tilkoblingsdefinisjonen din i JSON-format.
Du bør kunne opprette AWS Glue-forbindelser med den foregående AWS CLI-kommandoen fra Studio JupyterLab-terminalen. På filet meny, velg Ny og terminal.

Dersom create-connection kommandoen kjører vellykket, bør du se datakilden din oppført i SQL-nettleserruten. Hvis du ikke ser datakilden din oppført, velger du Forfriske for å oppdatere cachen.
Opprett en Snowflake-tilkobling
I denne delen fokuserer vi på å integrere en Snowflake-datakilde med SageMaker Studio. Oppretting av Snowflake-kontoer, databaser og varehus faller utenfor dette innlegget. For å komme i gang med Snowflake, se Snowflake brukerveiledning. I dette innlegget konsentrerer vi oss om å lage en Snowflake-definisjon JSON-fil og etablere en Snowflake-datakildeforbindelse ved å bruke AWS Glue.
Lag en Secrets Manager-hemmelighet
Du kan koble til Snowflake-kontoen din enten ved å bruke en bruker-ID og passord eller ved å bruke private nøkler. For å koble til med en bruker-ID og et passord, må du lagre legitimasjonen din på en sikker måte i Secrets Manager. Som nevnt tidligere, selv om det er mulig å bygge inn denne informasjonen under PythonProperties, anbefales det ikke å lagre sensitiv informasjon i vanlig tekstformat. Sørg alltid for at sensitive data håndteres sikkert for å unngå potensielle sikkerhetsrisikoer.
For å lagre informasjon i Secrets Manager, fullfør følgende trinn:
- Velg på Secrets Manager-konsollen Lagre en ny hemmelighet.
- Til Hemmelig type, velg Annen type hemmelighet.
- For nøkkelverdi-paret, velg klartekst og skriv inn følgende:
- Skriv inn et navn for hemmeligheten din, for eksempel
sm-sql-snowflake-secret. - La de andre innstillingene være standard eller tilpass om nødvendig.
- Skap hemmeligheten.
Lag en AWS-limforbindelse for Snowflake
Som diskutert tidligere, er AWS Glue-tilkoblinger avgjørende for å få tilgang til enhver tilkobling fra SageMaker Studio. Du kan finne en liste over alle støttede tilkoblingsegenskaper for Snowflake. Følgende er et eksempel på tilkoblingsdefinisjon JSON for Snowflake. Erstatt plassholderverdiene med de riktige verdiene før du lagrer den på disk:
For å opprette et AWS Glue-tilkoblingsobjekt for Snowflake-datakilden, bruk følgende kommando:
Denne kommandoen oppretter en ny Snowflake-datakildetilkobling i SQL-nettleserruten som er søkbar, og du kan kjøre SQL-spørringer mot den fra JupyterLab-notebookcellen.

Opprett en Amazon Redshift-tilkobling
Amazon Redshift er en fullstendig administrert, petabyte-skala datavarehustjeneste som forenkler og reduserer kostnadene ved å analysere alle dataene dine ved hjelp av standard SQL. Prosedyren for å opprette en Amazon Redshift-forbindelse gjenspeiler nøye den for en Snowflake-forbindelse.
Lag en Secrets Manager-hemmelighet
I likhet med Snowflake-oppsettet, for å koble til Amazon Redshift ved hjelp av en bruker-ID og et passord, må du trygt lagre hemmelighetsinformasjonen i Secrets Manager. Fullfør følgende trinn:
- Velg på Secrets Manager-konsollen Lagre en ny hemmelighet.
- Til Hemmelig type, velg Påloggingsinformasjon for Amazon Redshift-klyngen.
- Skriv inn legitimasjonen som brukes til å logge på for å få tilgang til Amazon Redshift som en datakilde.
- Velg Redshift-klyngen knyttet til hemmelighetene.
- Skriv inn et navn for hemmeligheten, for eksempel
sm-sql-redshift-secret. - La de andre innstillingene være standard eller tilpass om nødvendig.
- Skap hemmeligheten.
Ved å følge disse trinnene sørger du for at tilkoblingslegitimasjonen din håndteres sikkert, ved å bruke de robuste sikkerhetsfunksjonene til AWS for å administrere sensitive data effektivt.
Opprett en AWS Glue-tilkobling for Amazon Redshift
For å sette opp en forbindelse med Amazon Redshift ved å bruke en JSON-definisjon, fyll ut de nødvendige feltene og lagre følgende JSON-konfigurasjon på disken:
For å opprette et AWS Glue-tilkoblingsobjekt for Redshift-datakilden, bruk følgende AWS CLI-kommando:
Denne kommandoen oppretter en tilkobling i AWS Glue koblet til din Redshift-datakilde. Hvis kommandoen kjører vellykket, vil du kunne se Redshift-datakilden din i SageMaker Studio JupyterLab-notisboken, klar til å kjøre SQL-spørringer og utføre dataanalyse.

Opprett en Athena-forbindelse
Athena er en fullstendig administrert SQL-spørringstjeneste fra AWS som muliggjør analyse av data lagret i Amazon S3 ved hjelp av standard SQL. For å sette opp en Athena-tilkobling som en datakilde i JupyterLab-notatbokens SQL-nettleser, må du opprette en Athena-eksempeltilkoblingsdefinisjon JSON. Følgende JSON-struktur konfigurerer de nødvendige detaljene for å koble til Athena, og spesifiserer datakatalogen, S3-stasjonskatalogen og regionen:
For å opprette et AWS Glue-tilkoblingsobjekt for Athena-datakilden, bruk følgende AWS CLI-kommando:
Hvis kommandoen er vellykket, vil du kunne få tilgang til Athena datakatalog og tabeller direkte fra SQL-nettleseren i SageMaker Studio JupyterLab-notisboken.

Spør etter data fra flere kilder
Hvis du har flere datakilder integrert i SageMaker Studio gjennom den innebygde SQL-nettleseren og den bærbare SQL-funksjonen, kan du raskt kjøre spørringer og enkelt bytte mellom datakildenes backends i påfølgende celler i en notatbok. Denne funksjonen tillater sømløse overganger mellom ulike databaser eller datakilder under analysearbeidsflyten.
Du kan kjøre spørringer mot en mangfoldig samling av datakilde-backends og bringe resultatene direkte inn i Python-området for videre analyse eller visualisering. Dette tilrettelegges av %%sm_sql magisk kommando tilgjengelig i SageMaker Studio-notatbøker. For å sende ut resultatene av SQL-spørringen din til en pandas DataFrame, er det to alternativer:
- Velg utdatatypen fra den bærbare celleverktøylinjen Dataramme og navngi DataFrame-variabelen
- Legg til følgende parameter til din
%%sm_sqlkommando:
Følgende diagram illustrerer denne arbeidsflyten og viser hvordan du enkelt kan kjøre spørringer på tvers av ulike kilder i påfølgende bærbare celler, samt trene en SageMaker-modell ved å bruke opplæringsjobber eller direkte i den bærbare datamaskinen ved å bruke lokal databehandling. I tillegg fremhever diagrammet hvordan den innebygde SQL-integrasjonen til SageMaker Studio forenkler prosessene med utvinning og bygging direkte i det kjente miljøet til en JupyterLab-notebookcelle.

Tekst til SQL: Bruk av naturlig språk for å forbedre søking
SQL er et komplekst språk som krever forståelse av databaser, tabeller, syntakser og metadata. I dag kan generativ kunstig intelligens (AI) gjøre deg i stand til å skrive komplekse SQL-spørringer uten å kreve inngående SQL-erfaring. Utviklingen av LLM-er har betydelig påvirket naturlig språkbehandling (NLP)-basert SQL-generering, noe som gjør det mulig å lage presise SQL-spørringer fra naturlige språkbeskrivelser - en teknikk referert til som tekst-til-SQL. Imidlertid er det viktig å erkjenne de iboende forskjellene mellom menneskelig språk og SQL. Menneskelig språk kan noen ganger være tvetydig eller upresist, mens SQL er strukturert, eksplisitt og entydig. Å bygge bro over dette gapet og nøyaktig konvertere naturlig språk til SQL-spørringer kan by på en formidabel utfordring. Når de er utstyrt med passende meldinger, kan LLM-er bidra til å bygge bro over dette gapet ved å forstå intensjonen bak det menneskelige språket og generere nøyaktige SQL-spørringer deretter.
Med utgivelsen av SageMaker Studios SQL-spørringsfunksjon i den bærbare datamaskinen, gjør SageMaker Studio det enkelt å inspisere databaser og skjemaer, og skrive, kjøre og feilsøke SQL-spørringer uten å forlate Jupyter bærbare IDE. Denne delen utforsker hvordan tekst-til-SQL-funksjonene til avanserte LLM-er kan lette genereringen av SQL-spørringer ved bruk av naturlig språk i Jupyter-notatbøker. Vi bruker den banebrytende tekst-til-SQL-modellen defog/sqlcoder-7b-2 i forbindelse med Jupyter AI, en generativ AI-assistent spesielt utviklet for Jupyter-notebooks, for å lage komplekse SQL-spørringer fra naturlig språk. Ved å bruke denne avanserte modellen kan vi enkelt og effektivt lage komplekse SQL-spørringer ved hjelp av naturlig språk, og dermed forbedre SQL-opplevelsen vår innen bærbare datamaskiner.
Prototyping av bærbar PC ved hjelp av Hugging Face Hub
For å starte prototyping trenger du følgende:
- GitHub-kode – Koden presentert i denne delen er tilgjengelig i det følgende GitHub repo og ved å referere til eksempel notisbok.
- JupyterLab Space – Tilgang til et SageMaker Studio JupyterLab Space støttet av GPU-baserte forekomster er avgjørende. For
defog/sqlcoder-7b-2modell, en 7B parameter modell, som bruker en ml.g5.2xlarge instans anbefales. Alternativer som f.eksdefog/sqlcoder-70b-alpha ellerdefog/sqlcoder-34b-alphaer også levedyktige for konvertering av naturlig språk til SQL, men større forekomsttyper kan være nødvendig for prototyping. Sørg for at du har kvoten til å starte en GPU-støttet forekomst ved å navigere til Service Quotas-konsollen, søke etter SageMaker og søke etterStudio JupyterLab Apps running on <instance type>.
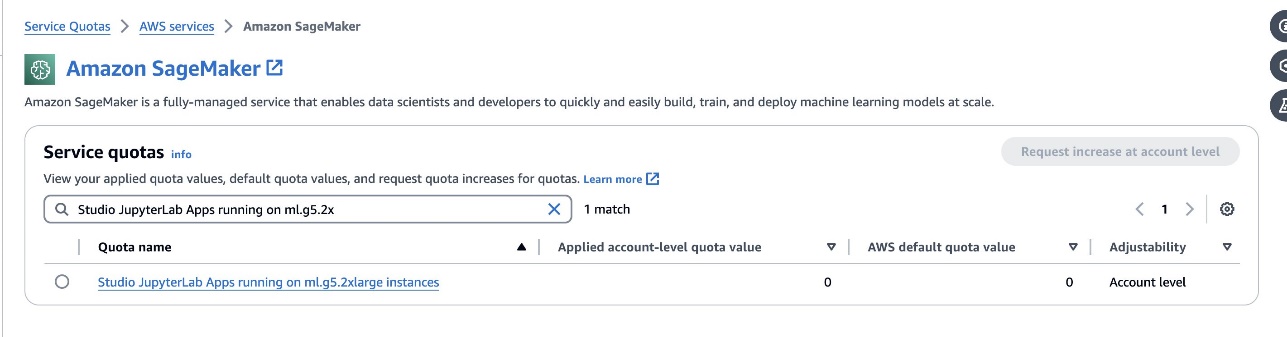
Lanser en ny GPU-støttet JupyterLab Space fra SageMaker Studio. Det anbefales å lage en ny JupyterLab Space med minst 75 GB Amazon Elastic Block Store (Amazon EBS) lagring for en 7B parametermodell.


- Klemmer Face Hub – Hvis SageMaker Studio-domenet ditt har tilgang til å laste ned modeller fra Klemmer Face Hub, kan du bruke
AutoModelForCausalLMklasse fra huggingface/transformatorer for å automatisk laste ned modeller og feste dem til dine lokale GPUer. Modellvektene vil bli lagret i din lokale maskins cache. Se følgende kode:
Etter at modellen er fullstendig lastet ned og lastet inn i minnet, bør du observere en økning i GPU-utnyttelsen på din lokale maskin. Dette indikerer at modellen aktivt bruker GPU-ressursene til beregningsoppgaver. Du kan bekrefte dette i ditt eget JupyterLab-rom ved å kjøre nvidia-smi (for en engangsvisning) eller nvidia-smi —loop=1 (for å gjenta hvert sekund) fra JupyterLab-terminalen.

Tekst-til-SQL-modeller utmerker seg ved å forstå intensjonen og konteksten til en brukers forespørsel, selv når språket som brukes er samtale eller tvetydig. Prosessen innebærer å oversette naturlige språkinndata til de riktige databaseskjemaelementene, for eksempel tabellnavn, kolonnenavn og betingelser. Imidlertid vil en hyllevare Tekst-til-SQL-modell ikke i seg selv kjenne strukturen til datavarehuset ditt, de spesifikke databaseskjemaene eller være i stand til å tolke innholdet i en tabell nøyaktig basert utelukkende på kolonnenavn. For å effektivt bruke disse modellene til å generere praktiske og effektive SQL-spørringer fra naturlig språk, er det nødvendig å tilpasse SQL-tekstgenereringsmodellen til ditt spesifikke lagerdatabaseskjema. Denne tilpasningen tilrettelegges gjennom bruk av LLM spør. Følgende er en anbefalt ledetekstmal for defog/sqlcoder-7b-2 Text-to-SQL-modellen, delt inn i fire deler:
- Oppgave – Denne delen bør spesifisere en oppgave på høyt nivå som skal utføres av modellen. Den bør inkludere typen databasebackend (som Amazon RDS, PostgreSQL eller Amazon Redshift) for å gjøre modellen oppmerksom på eventuelle nyanserte syntaktiske forskjeller som kan påvirke genereringen av den endelige SQL-spørringen.
- Instruksjoner – Denne delen bør definere oppgavegrenser og domenebevissthet for modellen, og kan inkludere eksempler for å veilede modellen i å generere finjusterte SQL-spørringer.
- Databaseskjema – Denne delen bør detaljere lagerdatabaseskjemaene dine, og skissere relasjonene mellom tabeller og kolonner for å hjelpe modellen med å forstå databasestrukturen.
- Svar – Denne delen er reservert for modellen for å sende ut SQL-spørringssvaret til det naturlige språket.
Et eksempel på databaseskjemaet og ledeteksten som brukes i denne delen er tilgjengelig i GitHub Repo.
Rask prosjektering handler ikke bare om å stille spørsmål eller utsagn; det er en nyansert kunst og vitenskap som i betydelig grad påvirker kvaliteten på interaksjoner med en AI-modell. Måten du lager en forespørsel på, kan ha stor innvirkning på arten og nytten av AIs respons. Denne ferdigheten er sentral for å maksimere potensialet til AI-interaksjoner, spesielt i komplekse oppgaver som krever spesialisert forståelse og detaljerte svar.
Det er viktig å ha muligheten til raskt å bygge og teste en modells respons for en gitt forespørsel og optimalisere forespørselen basert på responsen. JupyterLab-notebooks gir muligheten til å motta øyeblikkelig modelltilbakemelding fra en modell som kjører på lokal databehandling og optimalisere forespørselen og justere modellens respons ytterligere eller endre en modell helt. I dette innlegget bruker vi en SageMaker Studio JupyterLab-notisbok støttet av ml.g5.2xlarge sin NVIDIA A10G 24 GB GPU for å kjøre tekst-til-SQL-modellslutning på den bærbare datamaskinen og interaktivt bygge modellforespørselen vår til modellens respons er tilstrekkelig innstilt til å gi svar som er direkte kjørbare i JupyterLabs SQL-celler. For å kjøre modellslutning og samtidig streame modellsvar, bruker vi en kombinasjon av model.generate og TextIteratorStreamer som definert i følgende kode:
Modellens utgang kan dekoreres med SageMaker SQL-magi %%sm_sql ..., som lar JupyterLab-notisboken identifisere cellen som en SQL-celle.
Vær vert for tekst-til-SQL-modeller som SageMaker-endepunkter
På slutten av prototypingstadiet har vi valgt vår foretrukne tekst-til-SQL LLM, et effektivt ledetekstformat og en passende forekomsttype for å være vert for modellen (enten enkelt-GPU eller multi-GPU). SageMaker forenkler skalerbar hosting av tilpassede modeller gjennom bruk av SageMaker-endepunkter. Disse endepunktene kan defineres i henhold til spesifikke kriterier, noe som gjør det mulig å distribuere LLM-er som endepunkter. Denne muligheten lar deg skalere løsningen til et bredere publikum, slik at brukere kan generere SQL-spørringer fra naturlige språkinndata ved å bruke tilpassede vertsbaserte LLM-er. Følgende diagram illustrerer denne arkitekturen.
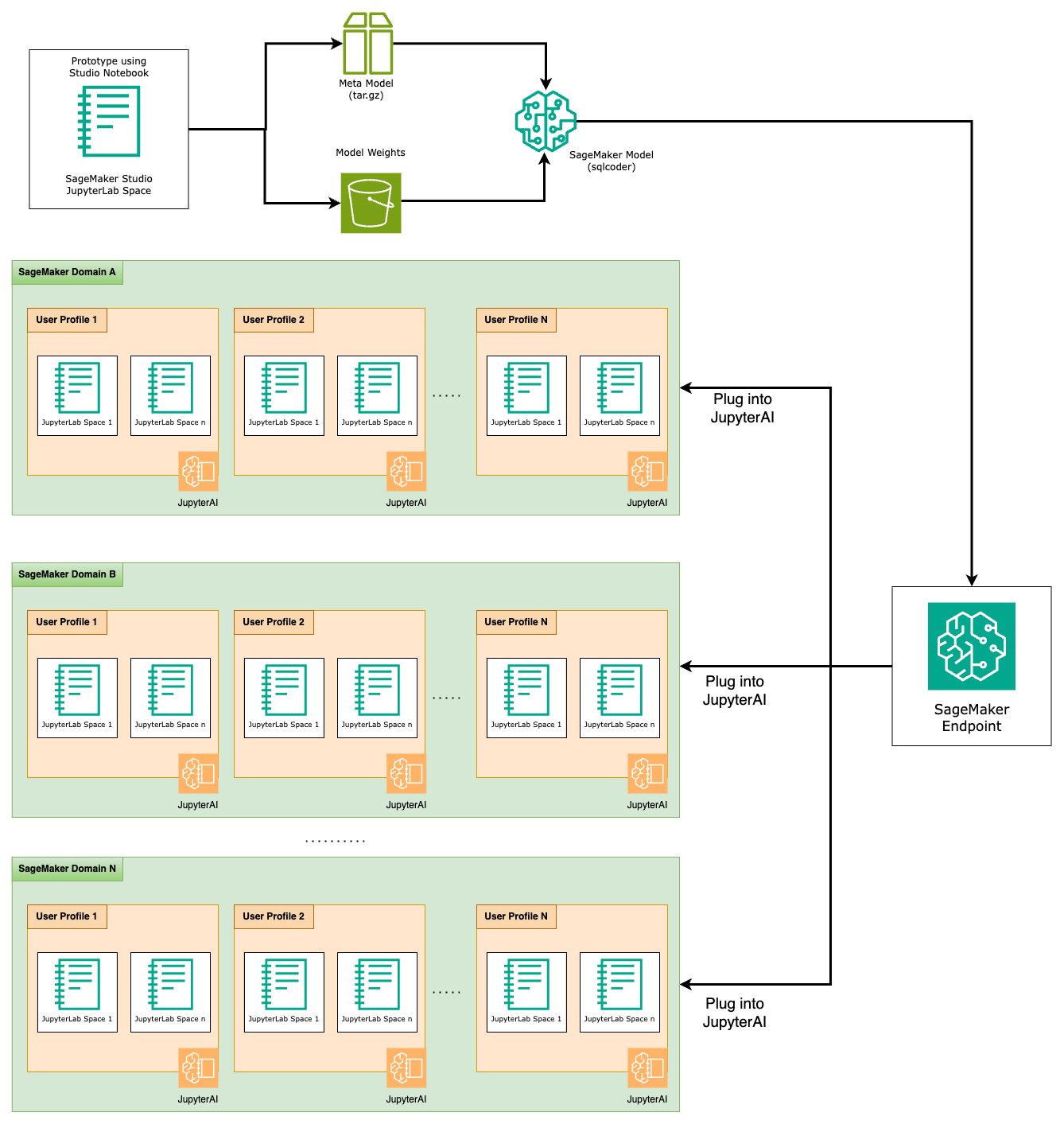
For å være vert for din LLM som et SageMaker-endepunkt, genererer du flere artefakter.
Den første artefakten er modellvekter. SageMaker Deep Java Library (DJL) servering containere lar deg sette opp konfigurasjoner gjennom en meta serveringsegenskaper fil, som lar deg styre hvordan modellene er hentet – enten direkte fra Hugging Face Hub eller ved å laste ned modellartefakter fra Amazon S3. Hvis du spesifiserer model_id=defog/sqlcoder-7b-2, DJL Serving vil forsøke å laste ned denne modellen direkte fra Hugging Face Hub. Du kan imidlertid pådra deg kostnader for nettverksinngang/utgang hver gang endepunktet distribueres eller skaleres elastisk. For å unngå disse kostnadene og potensielt øke hastigheten på nedlastingen av modellartefakter, anbefales det å hoppe over bruken model_id in serving.properties og lagre modellvekter som S3-artefakter og spesifiser dem bare med s3url=s3://path/to/model/bin.
Å lagre en modell (med tokenizer) til disk og laste den opp til Amazon S3 kan oppnås med bare noen få linjer med kode:
Du bruker også en databasepromptfil. I dette oppsettet er databasespørsmålet sammensatt av Task, Instructions, Database Schemaog Answer sections. For den nåværende arkitekturen tildeler vi en separat ledetekstfil for hvert databaseskjema. Det er imidlertid fleksibilitet til å utvide dette oppsettet til å inkludere flere databaser per ledetekstfil, slik at modellen kan kjøre sammensatte sammenføyninger på tvers av databaser på samme server. I løpet av prototypingstadiet lagrer vi databasemeldingen som en navngitt tekstfil <Database-Glue-Connection-Name>.prompt, Hvor Database-Glue-Connection-Name tilsvarer tilkoblingsnavnet som er synlig i JupyterLab-miljøet. For eksempel refererer dette innlegget til en Snowflake-forbindelse som heter Airlines_Dataset, så databasepromptfilen heter Airlines_Dataset.prompt. Denne filen blir deretter lagret på Amazon S3 og deretter lest og bufret av vår modelltjenestelogikk.
Dessuten tillater denne arkitekturen alle autoriserte brukere av dette endepunktet å definere, lagre og generere naturlig språk til SQL-spørringer uten behov for flere omplasseringer av modellen. Vi bruker følgende eksempel på en databaseforespørsel for å demonstrere tekst-til-SQL-funksjonaliteten.
Deretter genererer du tilpasset modelltjenestelogikk. I denne delen skisserer du en egendefinert slutningslogikk kalt modell.py. Dette skriptet er utviklet for å optimalisere ytelsen og integreringen av våre tekst-til-SQL-tjenester:
- Definer logikken for hurtigbufringslogikken for databaseprompten – For å minimere ventetiden implementerer vi en tilpasset logikk for nedlasting og bufring av databasemeldingsfiler. Denne mekanismen sørger for at forespørsler er lett tilgjengelige, noe som reduserer kostnadene forbundet med hyppige nedlastinger.
- Definer tilpasset modellslutningslogikk – For å øke inferenshastigheten, lastes tekst-til-SQL-modellen vår inn i float16-presisjonsformatet og konverteres deretter til en DeepSpeed-modell. Dette trinnet muliggjør mer effektiv beregning. I tillegg, innenfor denne logikken, spesifiserer du hvilke parametere brukere kan justere under slutningssamtaler for å skreddersy funksjonaliteten etter deres behov.
- Definer tilpasset inngangs- og utgangslogikk – Å etablere klare og tilpassede input/output-formater er avgjørende for jevn integrasjon med nedstrømsapplikasjoner. En slik applikasjon er JupyterAI, som vi diskuterer i den påfølgende delen.
I tillegg inkluderer vi en serving.properties fil, som fungerer som en global konfigurasjonsfil for modeller som er vert med DJL-servering. For mer informasjon, se Konfigurasjoner og innstillinger.
Til slutt kan du også inkludere en requirements.txt fil for å definere tilleggsmoduler som kreves for inferens og pakke alt inn i en tarball for distribusjon.
Se følgende kode:
Integrer endepunktet ditt med SageMaker Studio Jupyter AI-assistent
Jupyter AI er et åpen kildekodeverktøy som bringer generativ AI til Jupyter bærbare datamaskiner, og tilbyr en robust og brukervennlig plattform for å utforske generative AI-modeller. Det forbedrer produktiviteten i JupyterLab og Jupyter bærbare PC-er ved å tilby funksjoner som %%ai-magien for å lage en generativ AI-lekeplass inne i notatbøker, et innebygd chat-brukergrensesnitt i JupyterLab for samhandling med AI som en samtaleassistent, og støtte for et bredt spekter av LLM-er fra tilbydere liker Amazon Titan, AI21, Anthropic, Cohere og Hugging Face eller administrerte tjenester som Amazonas grunnfjell og SageMaker-endepunkter. For dette innlegget bruker vi Jupyter AI sin ut-av-boksen integrasjon med SageMaker-endepunkter for å bringe tekst-til-SQL-funksjonen inn i JupyterLab-notatbøker. Jupyter AI-verktøyet kommer forhåndsinstallert i alle SageMaker Studio JupyterLab Spaces støttet av SageMaker Distribution bilder; sluttbrukere er ikke pålagt å gjøre noen ekstra konfigurasjoner for å begynne å bruke Jupyter AI-utvidelsen for å integrere med et SageMaker-verts endepunkt. I denne delen diskuterer vi de to måtene å bruke det integrerte Jupyter AI-verktøyet på.
Jupyter AI inne i en bærbar PC ved hjelp av magi
Jupyter AI %%ai magisk kommando lar deg transformere SageMaker Studio JupyterLab-notatbøkene dine til et reproduserbart generativt AI-miljø. For å begynne å bruke AI-magics, sørg for at du har lastet jupyter_ai_magics-utvidelsen til bruk %%ai magi, og last i tillegg amazon_sagemaker_sql_magic å bruke %%sm_sql magi:
For å ringe til SageMaker-endepunktet fra den bærbare datamaskinen ved hjelp av %%ai magisk kommando, oppgi følgende parametere og strukturer kommandoen som følger:
- –region-navn – Spesifiser regionen der endepunktet ditt er distribuert. Dette sikrer at forespørselen blir rutet til riktig geografisk plassering.
- –forespørsel-skjema – Ta med skjemaet for inngangsdataene. Dette skjemaet skisserer det forventede formatet og typene av inndataene som modellen din trenger for å behandle forespørselen.
- –responsbane – Definer banen innenfor responsobjektet der utdataene til modellen din er plassert. Denne banen brukes til å trekke ut de relevante dataene fra svaret som returneres av modellen din.
- -f (valgfritt) - Dette er en utdataformater flagg som indikerer typen utdata som returneres av modellen. I sammenheng med en Jupyter-notatbok, hvis utdata er kode, bør dette flagget settes tilsvarende for å formatere utdata som kjørbar kode øverst i en Jupyter-notatbokcelle, etterfulgt av et fritekstinntastingsområde for brukerinteraksjon.
For eksempel kan kommandoen i en Jupyter notatbokcelle se ut som følgende kode:
Jupyter AI chattevindu
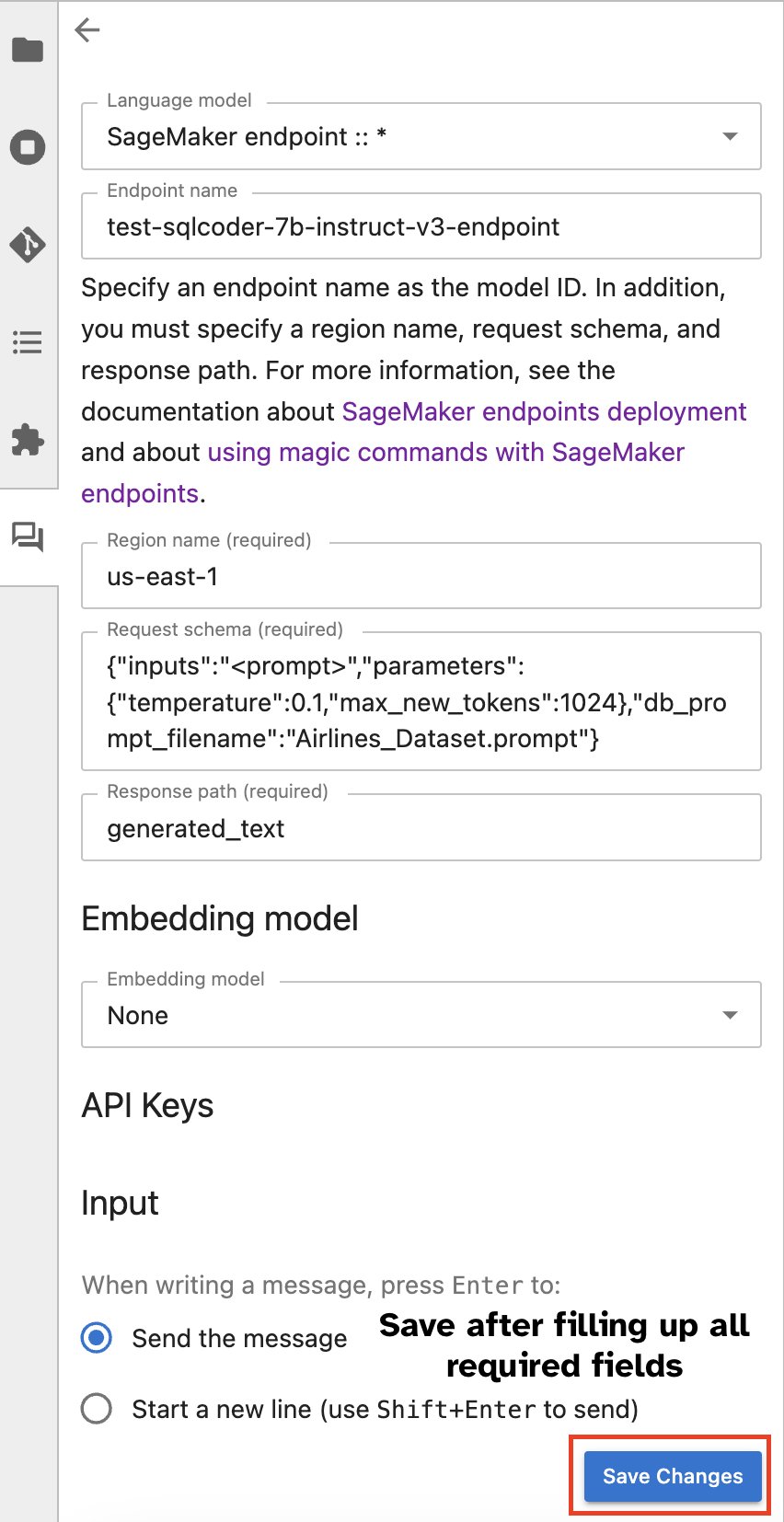
Alternativt kan du samhandle med SageMaker-endepunkter gjennom et innebygd brukergrensesnitt, noe som forenkler prosessen med å generere spørringer eller delta i dialog. Før du begynner å chatte med SageMaker-endepunktet ditt, konfigurer de relevante innstillingene i Jupyter AI for SageMaker-endepunktet, som vist i følgende skjermbilde.
 |
 |
konklusjonen
SageMaker Studio forenkler og effektiviserer nå dataforskers arbeidsflyt ved å integrere SQL-støtte i JupyterLab-notatbøker. Dette lar dataforskere fokusere på oppgavene sine uten å måtte administrere flere verktøy. Videre gjør den nye innebygde SQL-integrasjonen i SageMaker Studio det mulig for datapersonas å enkelt generere SQL-spørringer ved å bruke naturlig språktekst som input, og dermed akselerere arbeidsflyten deres.
Vi oppfordrer deg til å utforske disse funksjonene i SageMaker Studio. For mer informasjon, se Forbered data med SQL i Studio.
Vedlegg
Aktiver SQL-nettleseren og den bærbare SQL-cellen i tilpassede miljøer
Hvis du ikke bruker et SageMaker Distribution-bilde eller bruker Distribution Images 1.5 eller lavere, kjør følgende kommandoer for å aktivere SQL-nettlesingsfunksjonen i JupyterLab-miljøet ditt:
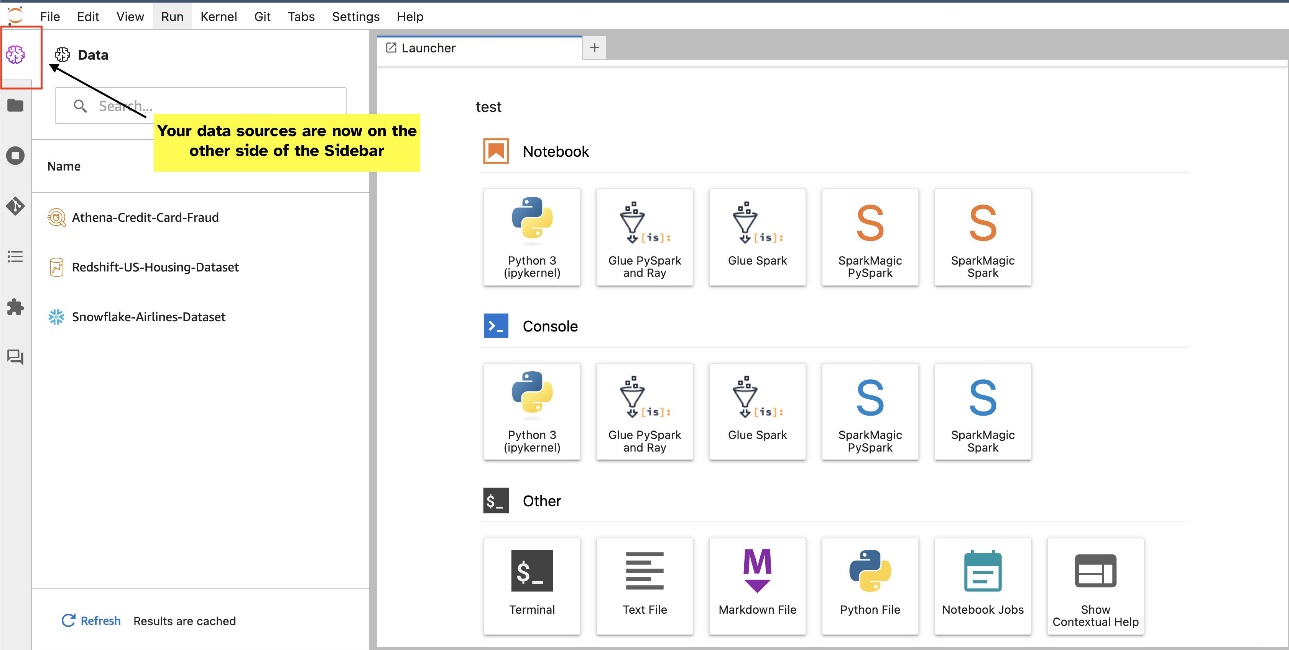
Flytt SQL-nettleserwidgeten
JupyterLab-widgets tillater flytting. Avhengig av dine preferanser, kan du flytte widgets til hver side av JupyterLab-widgets-ruten. Hvis du foretrekker det, kan du flytte retningen til SQL-widgeten til motsatt side (høyre til venstre) av sidefeltet med et enkelt høyreklikk på widget-ikonet og velge Bytt sidepanelside.
 |
 |
Om forfatterne
 Pranav Murthy er AI/ML Specialist Solutions Architect hos AWS. Han fokuserer på å hjelpe kunder med å bygge, trene, distribuere og migrere maskinlæring (ML) arbeidsbelastninger til SageMaker. Han har tidligere jobbet i halvlederindustrien med å utvikle modeller for store datasyn (CV) og naturlig språkbehandling (NLP) for å forbedre halvlederprosesser ved å bruke avanserte ML-teknikker. På fritiden liker han å spille sjakk og reise. Du kan finne Pranav på Linkedin.
Pranav Murthy er AI/ML Specialist Solutions Architect hos AWS. Han fokuserer på å hjelpe kunder med å bygge, trene, distribuere og migrere maskinlæring (ML) arbeidsbelastninger til SageMaker. Han har tidligere jobbet i halvlederindustrien med å utvikle modeller for store datasyn (CV) og naturlig språkbehandling (NLP) for å forbedre halvlederprosesser ved å bruke avanserte ML-teknikker. På fritiden liker han å spille sjakk og reise. Du kan finne Pranav på Linkedin.
 Varun Shah er en programvareingeniør som jobber på Amazon SageMaker Studio hos Amazon Web Services. Han er fokusert på å bygge interaktive ML-løsninger som forenkler databehandling og dataforberedelsesreiser. På fritiden liker Varun utendørsaktiviteter, inkludert fotturer og skigåing, og er alltid klar for å oppdage nye, spennende steder.
Varun Shah er en programvareingeniør som jobber på Amazon SageMaker Studio hos Amazon Web Services. Han er fokusert på å bygge interaktive ML-løsninger som forenkler databehandling og dataforberedelsesreiser. På fritiden liker Varun utendørsaktiviteter, inkludert fotturer og skigåing, og er alltid klar for å oppdage nye, spennende steder.
 Sumedha Swamy er en hovedproduktsjef hos Amazon Web Services hvor han leder SageMaker Studio-teamet i deres oppdrag om å utvikle IDE-valg for datavitenskap og maskinlæring. Han har dedikert de siste 15 årene til å bygge maskinlæringsbaserte forbruker- og bedriftsprodukter.
Sumedha Swamy er en hovedproduktsjef hos Amazon Web Services hvor han leder SageMaker Studio-teamet i deres oppdrag om å utvikle IDE-valg for datavitenskap og maskinlæring. Han har dedikert de siste 15 årene til å bygge maskinlæringsbaserte forbruker- og bedriftsprodukter.
 Bosco Albuquerque er Sr. Partner Solutions Architect hos AWS og har over 20 års erfaring med å jobbe med database- og analyseprodukter fra bedriftsdatabaseleverandører og skyleverandører. Han har hjulpet teknologiselskaper med å designe og implementere dataanalyseløsninger og -produkter.
Bosco Albuquerque er Sr. Partner Solutions Architect hos AWS og har over 20 års erfaring med å jobbe med database- og analyseprodukter fra bedriftsdatabaseleverandører og skyleverandører. Han har hjulpet teknologiselskaper med å designe og implementere dataanalyseløsninger og -produkter.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

