Recente ontwikkelingen op het gebied van machinaal leren (ML) hebben geleid tot steeds grotere modellen, waarvan sommige honderden miljarden parameters vereisen. Hoewel ze krachtiger zijn, vereisen training en gevolgtrekking op deze modellen aanzienlijke computerbronnen. Ondanks de beschikbaarheid van geavanceerde gedistribueerde trainingsbibliotheken, is het gebruikelijk dat voor trainings- en inferentietaken honderden versnellers nodig zijn (GPU's of speciaal gebouwde ML-chips zoals AWS Trainium en AWS Inferentie), en dus tientallen of honderden exemplaren.
In dergelijke gedistribueerde omgevingen wordt de waarneembaarheid van zowel instances als ML-chips de sleutel tot het verfijnen van de modelprestaties en het optimaliseren van de kosten. Met behulp van statistieken kunnen teams het werklastgedrag begrijpen, de toewijzing en het gebruik van resources optimaliseren, afwijkingen diagnosticeren en de algehele efficiëntie van de infrastructuur verhogen. Voor datawetenschappers zijn het gebruik en de verzadiging van ML-chips ook relevant voor de capaciteitsplanning.
Dit bericht leidt je door de Open Source Observability-patroon voor AWS Inferentia, waarmee u kunt zien hoe u de prestaties van ML-chips kunt controleren, die worden gebruikt in een Amazon Elastic Kubernetes-service (Amazon EKS) cluster, met datavlakknooppunten gebaseerd op Amazon Elastic Compute-cloud (Amazon EC2) exemplaren van het type Info1 en Info2.
Het patroon is onderdeel van de AWS CDK Waarneembaarheidsversneller, een reeks eigenzinnige modules waarmee u de waarneembaarheid voor Amazon EKS-clusters kunt instellen. De AWS CDK Observability Accelerator is georganiseerd rond patronen, dit zijn herbruikbare eenheden voor het inzetten van meerdere bronnen. De open source observatieset van patronen instrumenten waarmee observatie mogelijk is Amazon beheerde Grafana dashboards, een AWS Distro voor OpenTelemetry verzamelaar om statistieken te verzamelen, en Amazon beheerde service voor Prometheus om ze op te slaan.
Overzicht oplossingen
Het volgende diagram illustreert de oplossingsarchitectuur.

Deze oplossing implementeert een Amazon EKS-cluster met een knooppuntgroep die Inf1-instanties bevat.
Het AMI-type van de knooppuntgroep is AL2_x86_64_GPU, die de Amazon EKS geoptimaliseerde versnelde Amazon Linux AMI. Naast de standaard Amazon EKS-geoptimaliseerde AMI-configuratie omvat de versnelde AMI de NeuronX-runtime.
Om toegang te krijgen tot de ML-chips van Kubernetes, implementeert het patroon de AWS-neuron apparaat plug-in.
Metrieken worden beschikbaar gesteld aan Amazon Managed Service for Prometheus door de neuron-monitor DaemonSet, dat een minimale container inzet, met de Neuron hulpmiddelen geïnstalleerd. In het bijzonder de neuron-monitor DaemonSet voert het neuron-monitor commando doorgesluisd naar de neuron-monitor-prometheus.py begeleidend script (beide opdrachten maken deel uit van de container):
De opdracht gebruikt de volgende componenten:
neuron-monitorverzamelt statistieken en statistieken van de Neuron-applicaties die op het systeem draaien en streamt de verzamelde gegevens naar stdout in JSON-indelingneuron-monitor-prometheus.pybrengt de telemetriegegevens uit het JSON-formaat in kaart en stelt deze beschikbaar in een Prometheus-compatibel formaat
Gegevens worden in Amazon Managed Grafana gevisualiseerd door het bijbehorende dashboard.
De rest van de opzet voor het verzamelen en visualiseren van statistieken met Amazon Managed Service voor Prometheus en Amazon Managed Grafana is vergelijkbaar met die gebruikt in andere op open source gebaseerde patronen, die zijn opgenomen in de AWS Observability Accelerator for CDK GitHub-opslagplaats.
Voorwaarden
Je hebt het volgende nodig om de stappen in dit bericht te voltooien:
Stel de omgeving in
Voer de volgende stappen uit om uw omgeving in te stellen:
- Open een terminalvenster en voer de volgende opdrachten uit:
- Haal de werkruimte-ID's op van elke bestaande door Amazon beheerde Grafana-werkruimte:
Het volgende is onze voorbeelduitvoer:
- Wijs de waarden toe van
idenendpointaan de volgende omgevingsvariabelen:
COA_AMG_ENDPOINT_URL hoeft te omvatten https://.
- Maak een Grafana API-sleutel vanuit de door Amazon beheerde Grafana-werkruimte:
- Stel een geheim in AWS-systeembeheerder:
Het geheim is toegankelijk via de add-on External Secrets en wordt beschikbaar gemaakt als een native Kubernetes-geheim in het EKS-cluster.
Bootstrap de AWS CDK-omgeving op
De eerste stap bij elke AWS CDK-implementatie is het opstarten van de omgeving. Je gebruikt de cdk bootstrap opdracht in de AWS CDK CLI om de omgeving (een combinatie van AWS-account en AWS-regio) voor te bereiden met de middelen die AWS CDK nodig heeft om implementaties in die omgeving uit te voeren. AWS CDK-bootstrapping is nodig voor elke combinatie van account en regio, dus als u AWS CDK al in een regio hebt opgestart, hoeft u het bootstrapping-proces niet te herhalen.
Implementeer de oplossing
Voer de volgende stappen uit om de oplossing te implementeren:
- Kloon het cdk-aws-observatie-versneller repository en installeer de afhankelijkheidspakketten. Deze repository bevat AWS CDK v2-code geschreven in TypeScript.
De daadwerkelijke instellingen voor Grafana dashboard JSON-bestanden zullen naar verwachting worden opgegeven in de AWS CDK-context. Je moet updaten context in de cdk.json bestand, gelegen in de huidige map. De locatie van het dashboard wordt gespecificeerd door de fluxRepository.values.GRAFANA_NEURON_DASH_URL parameter, en neuronNodeGroup wordt gebruikt om het exemplaartype, het nummer en Amazon elastische blokwinkel (Amazon EBS) grootte gebruikt voor de knooppunten.
- Voer het volgende fragment in
cdk.json, vervangencontext:
U kunt het Inf1-instantietype vervangen door Inf2 en de grootte indien nodig wijzigen. Om de beschikbaarheid in de door u geselecteerde regio te controleren, voert u de volgende opdracht uit (amend Values wat je passend vindt):
- Installeer de projectafhankelijkheden:
- Voer de volgende opdrachten uit om het open source-observatiepatroon te implementeren:
Valideer de oplossing
Voer de volgende stappen uit om de oplossing te valideren:
- Voer de ... uit
update-kubeconfigcommando. Je zou de opdracht uit het uitvoerbericht van de vorige opdracht moeten kunnen halen:
- Controleer de bronnen die u heeft gemaakt:
De volgende schermafbeelding toont onze voorbeelduitvoer.

- Zorg ervoor dat de
neuron-device-plugin-daemonsetDaemonSet is actief:
Het volgende is onze verwachte output:
- Bevestig dat de
neuron-monitorDaemonSet is actief:
Het volgende is onze verwachte output:
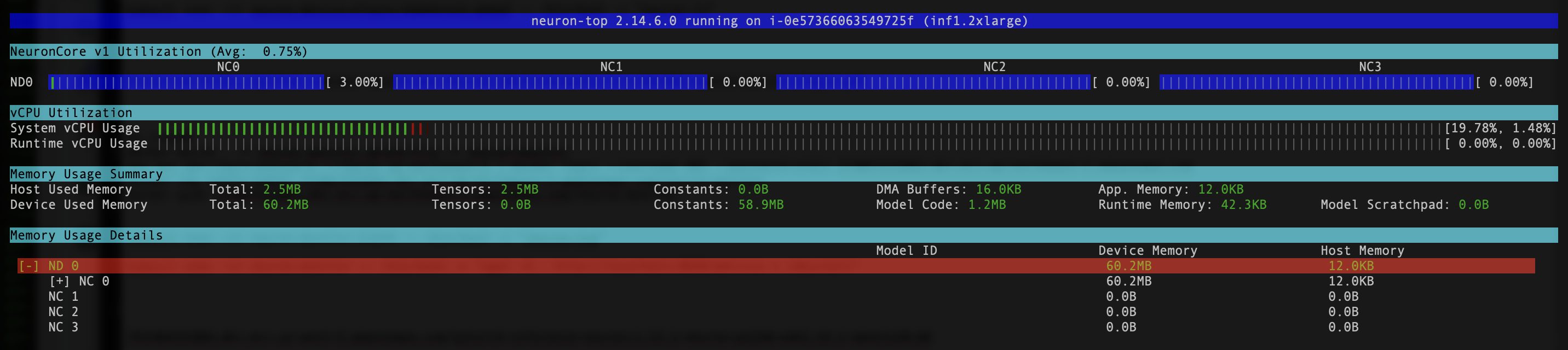
- Om te controleren of de Neuron-apparaten en kernen zichtbaar zijn, voert u de opdracht uit
neuron-lsenneuron-topopdrachten van bijvoorbeeld uw neuronmonitorpod (u kunt de naam van de pod halen uit de uitvoer vankubectl get pods -A):
De volgende schermafbeelding toont onze verwachte output.

De volgende schermafbeelding toont onze verwachte output.
Visualiseer gegevens met behulp van het Grafana Neuron-dashboard
Log in op uw Amazon Managed Grafana-werkruimte en navigeer naar de Dashboards paneel. U zou een dashboard moeten zien met de naam Neuron / Monitor.
Om enkele interessante statistieken op het Grafana-dashboard te zien, passen we het volgende manifest toe:
Dit is een voorbeeld van een werkbelasting waarmee het torchvision ResNet50-model en voert herhaalde gevolgtrekkingen uit in een lus om telemetriegegevens te genereren.
Voer de volgende code uit om te controleren of de pod succesvol is geïmplementeerd:
Je zou een pod moeten zien met de naam pytorch-inference-resnet50.
Na een paar minuten, kijkend in de Neuron / Monitor dashboard, zou u de verzamelde statistieken moeten zien die lijken op de volgende schermafbeeldingen.




Grafana Operator en Flux werken altijd samen om uw dashboards met Git te synchroniseren. Als u uw dashboards per ongeluk verwijdert, worden ze automatisch opnieuw ingericht.
Opruimen
U kunt de volledige AWS CDK-stack verwijderen met de volgende opdracht:
Conclusie
In dit bericht hebben we u laten zien hoe u met open source-tools waarneembaarheid kunt introduceren in een EKS-cluster met een datavlak waarop EC2 Inf1-instanties draaien. We zijn begonnen met het selecteren van de Amazon EKS-geoptimaliseerde versnelde AMI voor de datavlakknooppunten, die de Neuron-containerruntime omvat, die toegang biedt tot AWS Inferentia- en Trainium Neuron-apparaten. Om de Neuron-kernen en apparaten bloot te stellen aan Kubernetes, hebben we vervolgens de Neuron-apparaatplug-in geïmplementeerd. De daadwerkelijke verzameling en mapping van telemetriegegevens in een Prometheus-compatibel formaat werd bereikt via neuron-monitor en neuron-monitor-prometheus.py. Metrieken zijn afkomstig van Amazon Managed Service voor Prometheus en weergegeven op het Neuron-dashboard van Amazon Managed Grafana.
We raden u aan aanvullende waarneembaarheidspatronen in de AWS Observability Accelerator voor CDK GitHub-opslagplaats. Voor meer informatie over Neuron, zie de AWS Neuron-documentatie.
Over de auteur
 Riccardo Freschi is een Sr. Solutions Architect bij AWS, gericht op applicatiemodernisering. Hij werkt nauw samen met partners en klanten om hen te helpen hun IT-landschap te transformeren tijdens hun reis naar de AWS Cloud door bestaande applicaties te refactoren en nieuwe te bouwen.
Riccardo Freschi is een Sr. Solutions Architect bij AWS, gericht op applicatiemodernisering. Hij werkt nauw samen met partners en klanten om hen te helpen hun IT-landschap te transformeren tijdens hun reis naar de AWS Cloud door bestaande applicaties te refactoren en nieuwe te bouwen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/open-source-observability-for-aws-inferentia-nodes-within-amazon-eks-clusters/

