Bij vermogensbeheer moeten portefeuillebeheerders bedrijven in hun beleggingsuniversum nauwlettend volgen om risico's en kansen te identificeren en beleggingsbeslissingen te begeleiden. Het volgen van directe gebeurtenissen zoals winstrapporten of kredietverlagingen is eenvoudig: u kunt waarschuwingen instellen om managers op de hoogte te stellen van nieuws dat bedrijfsnamen bevat. Het detecteren van tweede- en derde-orde-effecten die voortkomen uit gebeurtenissen bij leveranciers, klanten, partners of andere entiteiten in het ecosysteem van een bedrijf is echter een uitdaging.
Een verstoring van de toeleveringsketen bij een belangrijke leverancier zou bijvoorbeeld waarschijnlijk een negatieve impact hebben op downstream-fabrikanten. Of het wegvallen van een topklant bij een grote klant vormt een vraagrisico voor de leverancier. Heel vaak halen dergelijke gebeurtenissen niet de krantenkoppen waarin het getroffen bedrijf rechtstreeks centraal staat, maar het is toch belangrijk om er aandacht aan te besteden. In dit bericht demonstreren we een geautomatiseerde oplossing die kennisgrafieken en generatieve kunstmatige intelligentie (AI) om dergelijke risico's aan het licht te brengen door relatiekaarten te vergelijken met realtime nieuws.
In grote lijnen omvat dit twee stappen: Ten eerste, het opbouwen van de ingewikkelde relaties tussen bedrijven (klanten, leveranciers, directeuren) in een kennisgrafiek. Ten tweede, het gebruik van deze grafiekendatabase samen met generatieve AI om tweede- en derde-orde-effecten van nieuwsgebeurtenissen te detecteren. Deze oplossing kan bijvoorbeeld benadrukken dat vertragingen bij een onderdelenleverancier de productie van downstream-autofabrikanten in een portfolio kunnen verstoren, hoewel daar niet direct naar wordt verwezen.
Met AWS kunt u deze oplossing implementeren in een serverloze, schaalbare en volledig gebeurtenisgestuurde architectuur. Dit bericht demonstreert een proof of concept, gebouwd op twee belangrijke AWS-services die zeer geschikt zijn voor grafische kennisrepresentatie en natuurlijke taalverwerking: Amazone Neptunus en Amazonebodem. Neptune is een snelle, betrouwbare, volledig beheerde grafiekdatabaseservice waarmee u eenvoudig applicaties kunt bouwen en uitvoeren die werken met sterk verbonden datasets. Amazon Bedrock is een volledig beheerde service die via één API een keuze biedt uit goed presterende basismodellen (FM's) van toonaangevende AI-bedrijven zoals AI21 Labs, Anthropic, Cohere, Meta, Stability AI en Amazon, samen met een brede reeks mogelijkheden om generatieve AI-toepassingen te bouwen met beveiliging, privacy en verantwoorde AI.
Over het geheel genomen demonstreert dit prototype de kunst van het mogelijke met kennisgrafieken en generatieve AI, waarbij signalen worden afgeleid door ongelijksoortige punten met elkaar te verbinden. Het voordeel voor beleggingsprofessionals is het vermogen om op de hoogte te blijven van ontwikkelingen die dichter bij het signaal staan en tegelijkertijd ruis te vermijden.
Bouw de kennisgrafiek

De eerste stap in deze oplossing is het bouwen van een kennisgrafiek, en een waardevolle maar vaak over het hoofd geziene gegevensbron voor kennisgrafieken zijn de jaarverslagen van bedrijven. Omdat officiële bedrijfspublicaties vóór publicatie aan een nauwkeurig onderzoek worden onderworpen, is de informatie die ze bevatten waarschijnlijk accuraat en betrouwbaar. Jaarverslagen worden echter geschreven in een ongestructureerd formaat dat bedoeld is voor menselijk lezen en niet voor machinale consumptie. Om hun potentieel te ontsluiten, heb je een manier nodig om de rijkdom aan feiten en relaties die ze bevatten systematisch te extraheren en te structureren.
Met generatieve AI-diensten zoals Amazon Bedrock heb je nu de mogelijkheid om dit proces te automatiseren. U kunt een jaarverslag nemen en een verwerkingspijplijn activeren om het rapport op te nemen, het in kleinere delen op te splitsen en het begrip van natuurlijke taal toe te passen om opvallende entiteiten en relaties naar voren te halen.
Een zin waarin staat dat “[Bedrijf A] zijn Europese vloot voor elektrische bezorging heeft uitgebreid met een bestelling voor 1,800 elektrische bestelwagens van [Bedrijf B]” zou Amazon Bedrock bijvoorbeeld in staat stellen het volgende te identificeren:
- [Bedrijf A] als klant
- [Bedrijf B] als leverancier
- Een leveranciersrelatie tussen [Bedrijf A] en [Bedrijf B]
- Relatiegegevens van “leverancier van elektrische bestelauto’s”
Het extraheren van dergelijke gestructureerde gegevens uit ongestructureerde documenten vereist zorgvuldig opgestelde aanwijzingen voor grote taalmodellen (LLM's), zodat ze tekst kunnen analyseren om entiteiten zoals bedrijven en mensen eruit te halen, maar ook relaties zoals klanten, leveranciers en meer. De aanwijzingen bevatten duidelijke instructies over waar u op moet letten en de structuur waarin u de gegevens moet retourneren. Door dit proces in het hele jaarverslag te herhalen, kunt u de relevante entiteiten en relaties eruit halen om een rijke kennisgrafiek te construeren.
Voordat u de geëxtraheerde informatie echter aan de kennisgrafiek toevoegt, moet u eerst de entiteiten ondubbelzinnig maken. Er kan bijvoorbeeld al een andere '[Bedrijf A]'-entiteit in de kennisgrafiek staan, maar deze kan een andere organisatie met dezelfde naam vertegenwoordigen. Amazon Bedrock kan de kenmerken, zoals het focusgebied van het bedrijf, de industrie en de inkomstengenererende industrieën en relaties met andere entiteiten, redeneren en vergelijken om te bepalen of de twee entiteiten daadwerkelijk van elkaar verschillen. Dit voorkomt dat niet-verbonden bedrijven op onnauwkeurige wijze worden samengevoegd tot één entiteit.
Nadat het ondubbelzinnig maken is voltooid, kunt u op betrouwbare wijze nieuwe entiteiten en relaties toevoegen aan uw Neptune-kennisgrafiek, en deze verrijken met de feiten uit jaarverslagen. In de loop van de tijd zal de opname van betrouwbare gegevens en de integratie van betrouwbaardere gegevensbronnen helpen bij het opbouwen van een uitgebreide kennisgrafiek die het onthullen van inzichten kan ondersteunen via grafiekquery's en analyses.
Deze automatisering, mogelijk gemaakt door generatieve AI, maakt het mogelijk om duizenden jaarverslagen te verwerken en ontgrendelt een onschatbare troef voor het beheer van kennisgrafieken die anders ongebruikt zou blijven vanwege de onbetaalbaar hoge handmatige inspanning die nodig is.
De volgende schermafbeelding toont een voorbeeld van de visuele verkenning die mogelijk is in een grafiekdatabase van Neptunus met behulp van de Grafiekverkenner gereedschap.

Verwerken nieuwsartikelen

De volgende stap van de oplossing is het automatisch verrijken van de nieuwsfeeds van portefeuillebeheerders en het onder de aandacht brengen van artikelen die relevant zijn voor hun interesses en beleggingen. Voor de nieuwsfeed kunnen portefeuillebeheerders zich abonneren op elke externe nieuwsprovider AWS-gegevensuitwisseling of een andere nieuws-API naar keuze.
Wanneer een nieuwsartikel het systeem binnenkomt, wordt een opnamepijplijn aangeroepen om de inhoud te verwerken. Met behulp van technieken die vergelijkbaar zijn met de verwerking van jaarverslagen, wordt Amazon Bedrock gebruikt om entiteiten, attributen en relaties uit het nieuwsartikel te extraheren, die vervolgens worden gebruikt om de kennisgrafiek ondubbelzinnig te maken om de overeenkomstige entiteit in de kennisgrafiek te identificeren.
De kennisgrafiek bevat verbindingen tussen bedrijven en mensen, en door artikelentiteiten aan bestaande knooppunten te koppelen, kunt u identificeren of onderwerpen zich binnen twee hops bevinden van de bedrijven waarin de portefeuillebeheerder heeft geïnvesteerd of waarin hij geïnteresseerd is. Het vinden van een dergelijke verbinding geeft de artikel kan relevant zijn voor de portefeuillebeheerder, en omdat de onderliggende gegevens worden weergegeven in een kennisgrafiek, kunnen deze worden gevisualiseerd om de portefeuillebeheerder te helpen begrijpen waarom en hoe deze context relevant is. Naast het identificeren van verbindingen met de portefeuille, kunt u Amazon Bedrock ook gebruiken om sentimentanalyses uit te voeren op de entiteiten waarnaar wordt verwezen.
Het uiteindelijke resultaat is een verrijkte nieuwsfeed waarin artikelen verschijnen die waarschijnlijk van invloed zijn op de interessegebieden en beleggingen van de portefeuillebeheerder.
Overzicht oplossingen
De algehele architectuur van de oplossing ziet er uit als in het volgende diagram.
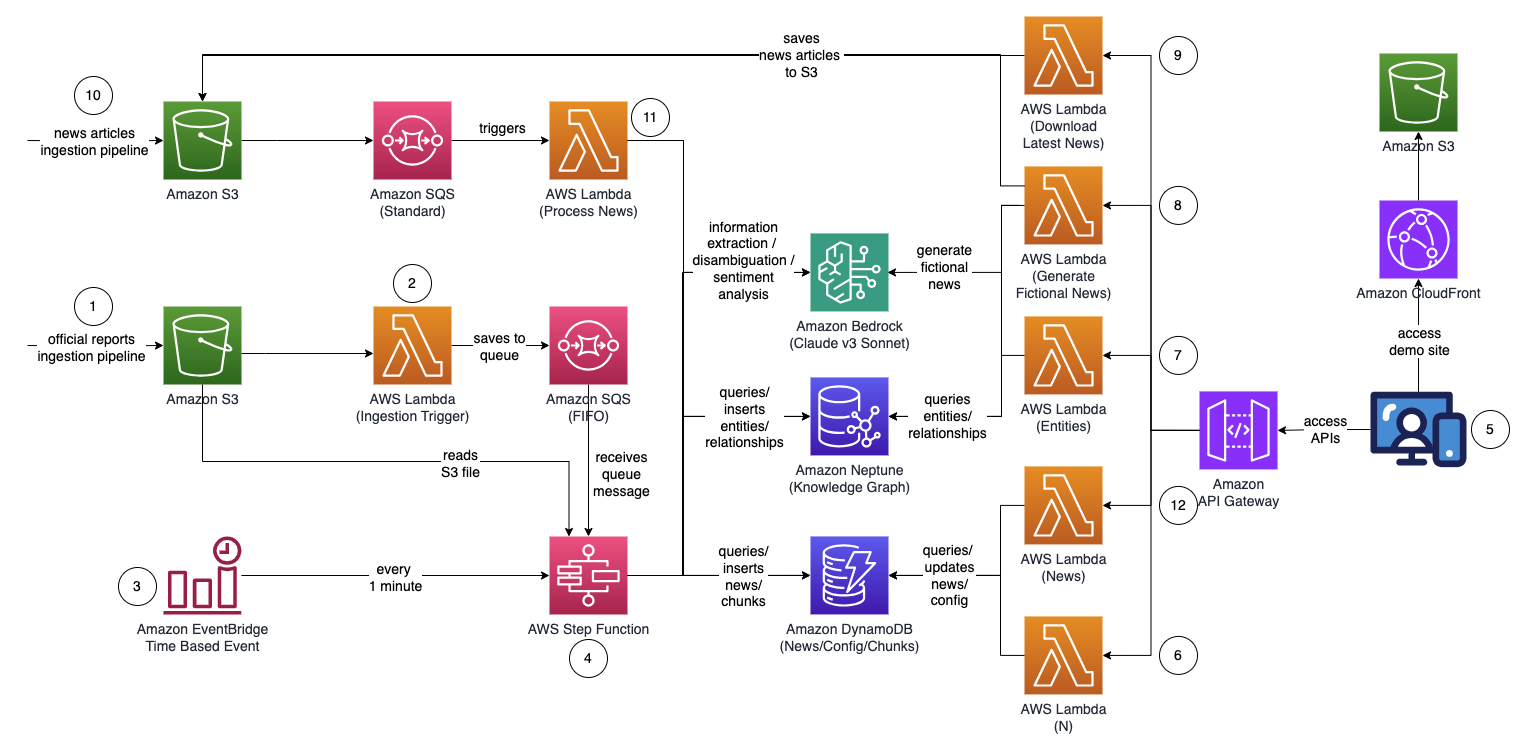
De workflow bestaat uit de volgende stappen:
- Een gebruiker uploadt proces-verbaal (in PDF-formaat) naar een Amazon eenvoudige opslagservice (Amazon S3) bak. De rapporten moeten officieel gepubliceerde rapporten zijn om de opname van onnauwkeurige gegevens in uw kennisgrafiek te minimaliseren (in tegenstelling tot nieuws en roddelbladen).
- De S3-gebeurtenismelding roept een AWS Lambda functie, die de S3-bucket en bestandsnaam naar een Amazon Simple Queue-service (Amazon SQS) wachtrij. De FIFO-wachtrij (First-In-First-Out) zorgt ervoor dat het rapportopnameproces opeenvolgend wordt uitgevoerd om de kans te verkleinen dat dubbele gegevens in uw kennisgrafiek worden geïntroduceerd.
- An Amazon EventBridge op tijd gebaseerde gebeurtenis wordt elke minuut uitgevoerd om de uitvoering van een te starten AWS Stap Functies state machine asynchroon.
- De Step Functions-statusmachine doorloopt een reeks taken om het geüploade document te verwerken door belangrijke informatie te extraheren en in uw kennisgrafiek in te voegen:
- Ontvang het wachtrijbericht van Amazon SQS.
- Download het PDF-rapportbestand van Amazon S3, splits het op in meerdere kleinere tekstblokken (ongeveer 1,000 woorden) voor verwerking en sla de tekstblokken op in Amazon DynamoDB.
- Gebruik Claude v3 Sonnet van Anthropic op Amazon Bedrock om de eerste paar tekstfragmenten te verwerken om de hoofdentiteit te bepalen waarnaar het rapport verwijst, samen met relevante kenmerken (zoals de industrie).
- Haal de tekstfragmenten op uit DynamoDB en roep voor elk tekstfragment een Lambda-functie aan om entiteiten (zoals bedrijf of persoon) en de relatie ervan (klant, leverancier, partner, concurrent of directeur) met de hoofdentiteit eruit te halen met behulp van Amazon Bedrock .
- Consolideer alle geëxtraheerde informatie.
- Filter ruis en irrelevante entiteiten (bijvoorbeeld algemene termen zoals ‘consumenten’) weg met Amazon Bedrock.
- Gebruik Amazon Bedrock om ondubbelzinnig te maken door te redeneren met behulp van de geëxtraheerde informatie tegen de lijst met vergelijkbare entiteiten uit de kennisgrafiek. Als de entiteit niet bestaat, voegt u deze in. Gebruik anders de entiteit die al bestaat in de kennisgrafiek. Voeg alle uitgepakte relaties in.
- Ruim op door het SQS-wachtrijbericht en het S3-bestand te verwijderen.
- Een gebruiker heeft toegang tot een op React gebaseerde webapplicatie om de nieuwsartikelen te bekijken die zijn aangevuld met informatie over de entiteit, het sentiment en het verbindingspad.
- Met behulp van de webapplicatie specificeert de gebruiker het aantal hops (standaard N=2) op het verbindingspad dat moet worden gecontroleerd.
- Met behulp van de webapplicatie specificeert de gebruiker de lijst met entiteiten die moeten worden gevolgd.
- Om fictief nieuws te genereren, kiest de gebruiker Genereer voorbeeldnieuws om 10 voorbeelden van financiële nieuwsartikelen met willekeurige inhoud te genereren die in het nieuwsopnameproces kunnen worden ingevoerd. Inhoud wordt gegenereerd met behulp van Amazon Bedrock en is puur fictief.
- Om actueel nieuws te downloaden, kiest de gebruiker Laatste nieuws downloaden om het belangrijkste nieuws van vandaag te downloaden (mogelijk gemaakt door NewsAPI.org).
- Het nieuwsbestand (TXT-formaat) wordt geüpload naar een S3-bucket. Stappen 8 en 9 uploaden nieuws automatisch naar de S3-bucket, maar u kunt ook integraties bouwen met uw favoriete nieuwsprovider, zoals AWS Data Exchange of een nieuwsprovider van derden, om nieuwsartikelen als bestanden in de S3-bucket te plaatsen. De inhoud van nieuwsgegevensbestanden moet worden geformatteerd als
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - De S3-gebeurtenismelding stuurt de S3-bucket of bestandsnaam naar Amazon SQS (standaard), die meerdere Lambda-functies aanroept om de nieuwsgegevens parallel te verwerken:
- Gebruik Amazon Bedrock om entiteiten te extraheren die in het nieuws worden genoemd, samen met alle gerelateerde informatie, relaties en sentimenten van de genoemde entiteit.
- Vergelijk het met de kennisgrafiek en gebruik Amazon Bedrock om ondubbelzinnig te maken door te redeneren met behulp van de beschikbare informatie uit het nieuws en vanuit de kennisgrafiek om de overeenkomstige entiteit te identificeren.
- Nadat de entiteit is gelokaliseerd, zoekt u naar eventuele verbindingspaden die verbinding maken met entiteiten gemarkeerd met en retourneert u deze
INTERESTED=YESin de kennisgrafiek die binnen N=2 hops verwijderd zijn.
- De webapplicatie wordt elke seconde automatisch vernieuwd om de laatste reeks verwerkte nieuwsberichten op te halen en weer te geven in de webapplicatie.
Implementeer het prototype
U kunt de prototypeoplossing inzetten en zelf gaan experimenteren. Het prototype is verkrijgbaar vanaf GitHub en bevat details over het volgende:
- Vereisten voor implementatie
- Implementatiestappen
- Opruimstappen
Samengevat
Dit bericht demonstreerde een proof-of-concept-oplossing om portefeuillebeheerders te helpen tweede- en derde-orderisico's van nieuwsgebeurtenissen te detecteren, zonder directe verwijzingen naar bedrijven die ze volgen. Door een kennisgrafiek van ingewikkelde bedrijfsrelaties te combineren met realtime nieuwsanalyse met behulp van generatieve AI, kunnen de gevolgen stroomafwaarts worden benadrukt, zoals productievertragingen als gevolg van haperingen bij leveranciers.
Hoewel het slechts een prototype is, toont deze oplossing de belofte van kennisgrafieken en taalmodellen om punten met elkaar te verbinden en signalen uit ruis af te leiden. Deze technologieën kunnen beleggingsprofessionals helpen door risico's sneller aan het licht te brengen door het in kaart brengen van relaties en redeneren. Over het geheel genomen is dit een veelbelovende toepassing van grafische databases en AI die onderzoek rechtvaardigt om de investeringsanalyse en besluitvorming te verbeteren.
Als dit voorbeeld van generatieve AI in de financiële dienstverlening interessant is voor uw bedrijf, of als u een soortgelijk idee heeft, neem dan contact op met uw AWS-accountmanager. Wij gaan dan graag verder met u op onderzoek uit.
Over de auteur
 Xan Huang is een Senior Solutions Architect bij AWS en is gevestigd in Singapore. Hij werkt samen met grote financiële instellingen om veilige, schaalbare en zeer beschikbare oplossingen in de cloud te ontwerpen en bouwen. Buiten zijn werk brengt Xan het grootste deel van zijn vrije tijd door met zijn gezin en krijgt hij de leiding over zijn driejarige dochter. Je kunt Xan vinden op LinkedIn.
Xan Huang is een Senior Solutions Architect bij AWS en is gevestigd in Singapore. Hij werkt samen met grote financiële instellingen om veilige, schaalbare en zeer beschikbare oplossingen in de cloud te ontwerpen en bouwen. Buiten zijn werk brengt Xan het grootste deel van zijn vrije tijd door met zijn gezin en krijgt hij de leiding over zijn driejarige dochter. Je kunt Xan vinden op LinkedIn.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

