ആമസോൺ സേജ് മേക്കർ സ്റ്റുഡിയോ മെഷീൻ ലേണിംഗ് (ML) മോഡലുകൾ സംവേദനാത്മകമായി നിർമ്മിക്കാനും പരിശീലിപ്പിക്കാനും വിന്യസിക്കാനും ഡാറ്റാ സയൻ്റിസ്റ്റുകൾക്ക് പൂർണ്ണമായി കൈകാര്യം ചെയ്യാവുന്ന ഒരു പരിഹാരം നൽകുന്നു. അവരുടെ ML ടാസ്ക്കുകളിൽ പ്രവർത്തിക്കുന്ന പ്രക്രിയയിൽ, ഡാറ്റാ സയൻ്റിസ്റ്റുകൾ സാധാരണയായി പ്രസക്തമായ ഡാറ്റ ഉറവിടങ്ങൾ കണ്ടെത്തി അവയുമായി ബന്ധിപ്പിച്ചുകൊണ്ട് അവരുടെ വർക്ക്ഫ്ലോ ആരംഭിക്കുന്നു. ML പരിശീലനത്തിലും അനുമാനത്തിലും ഉപയോഗിക്കുന്നതിന് മുമ്പ് വിവിധ ഉറവിടങ്ങളിൽ നിന്നുള്ള ഡാറ്റ പര്യവേക്ഷണം ചെയ്യുന്നതിനും വിശകലനം ചെയ്യുന്നതിനും ദൃശ്യവൽക്കരിക്കുന്നതിനും സംയോജിപ്പിക്കുന്നതിനും അവർ SQL ഉപയോഗിക്കുന്നു. മുമ്പ്, ഡാറ്റാ സയൻ്റിസ്റ്റുകൾ തങ്ങളുടെ വർക്ക്ഫ്ലോയിൽ SQL-നെ പിന്തുണയ്ക്കുന്നതിന് ഒന്നിലധികം ടൂളുകൾ കൈകാര്യം ചെയ്യുന്നതായി കണ്ടെത്തി, ഇത് ഉൽപാദനക്ഷമതയെ തടസ്സപ്പെടുത്തി.
SageMaker സ്റ്റുഡിയോയിലെ JupyterLab നോട്ട്ബുക്കുകൾ ഇപ്പോൾ SQL-നുള്ള ബിൽറ്റ്-ഇൻ പിന്തുണയോടെയാണ് വരുന്നതെന്ന് അറിയിക്കുന്നതിൽ ഞങ്ങൾക്ക് സന്തോഷമുണ്ട്. ഡാറ്റ ശാസ്ത്രജ്ഞർക്ക് ഇപ്പോൾ കഴിയും:
- ഉൾപ്പെടെയുള്ള ജനപ്രിയ ഡാറ്റ സേവനങ്ങളിലേക്ക് കണക്റ്റുചെയ്യുക ആമസോൺ അഥീന, ആമസോൺ റെഡ്ഷിഫ്റ്റ്, ആമസോൺ ഡാറ്റ സോൺ, നോട്ട്ബുക്കുകൾക്കുള്ളിൽ നേരിട്ട് സ്നോഫ്ലെക്ക്
- ഡാറ്റാബേസുകൾ, സ്കീമകൾ, പട്ടികകൾ, കാഴ്ചകൾ എന്നിവയ്ക്കായി ബ്രൗസ് ചെയ്യുകയും തിരയുകയും നോട്ട്ബുക്ക് ഇൻ്റർഫേസിനുള്ളിൽ ഡാറ്റ പ്രിവ്യൂ ചെയ്യുകയും ചെയ്യുക
- ML പ്രോജക്റ്റുകളിൽ ഉപയോഗിക്കുന്നതിന് ഡാറ്റയുടെ കാര്യക്ഷമമായ പര്യവേക്ഷണത്തിനും പരിവർത്തനത്തിനും ഒരേ നോട്ട്ബുക്കിൽ SQL, പൈത്തൺ കോഡ് എന്നിവ മിക്സ് ചെയ്യുക
- കോഡ് വികസനം ത്വരിതപ്പെടുത്താനും മൊത്തത്തിലുള്ള ഡെവലപ്പർ ഉൽപ്പാദനക്ഷമത മെച്ചപ്പെടുത്താനും സഹായിക്കുന്നതിന് SQL കമാൻഡ് പൂർത്തിയാക്കൽ, കോഡ് ഫോർമാറ്റിംഗ് സഹായം, വാക്യഘടന ഹൈലൈറ്റിംഗ് എന്നിവ പോലുള്ള ഡെവലപ്പർ ഉൽപ്പാദനക്ഷമത സവിശേഷതകൾ ഉപയോഗിക്കുക.
കൂടാതെ, അഡ്മിനിസ്ട്രേറ്റർമാർക്ക് ഈ ഡാറ്റ സേവനങ്ങളിലേക്കുള്ള കണക്ഷനുകൾ സുരക്ഷിതമായി മാനേജുചെയ്യാനാകും, ക്രെഡൻഷ്യലുകൾ സ്വമേധയാ കൈകാര്യം ചെയ്യാതെ തന്നെ അംഗീകൃത ഡാറ്റ ആക്സസ് ചെയ്യാൻ ഡാറ്റ ശാസ്ത്രജ്ഞരെ അനുവദിക്കുന്നു.
ഈ പോസ്റ്റിൽ, SageMaker സ്റ്റുഡിയോയിൽ ഈ സവിശേഷത സജ്ജീകരിക്കുന്നതിലൂടെ ഞങ്ങൾ നിങ്ങളെ നയിക്കുകയും ഈ സവിശേഷതയുടെ വിവിധ കഴിവുകളിലൂടെ നിങ്ങളെ നയിക്കുകയും ചെയ്യുന്നു. സ്വാഭാവിക ഭാഷാ ടെക്സ്റ്റ് ഇൻപുട്ടായി ഉപയോഗിച്ച് സങ്കീർണ്ണമായ SQL അന്വേഷണങ്ങൾ എഴുതുന്നതിന് വിപുലമായ വലിയ ഭാഷാ മോഡലുകൾ (LLMs) നൽകുന്ന ടെക്സ്റ്റ്-ടു-SQL കഴിവുകൾ ഉപയോഗിച്ച് നിങ്ങൾക്ക് എങ്ങനെ ഇൻ-നോട്ട്ബുക്ക് SQL അനുഭവം മെച്ചപ്പെടുത്താമെന്ന് ഞങ്ങൾ കാണിക്കുന്നു. അവസാനമായി, ഉപയോക്താക്കളുടെ വിശാലമായ പ്രേക്ഷകരെ അവരുടെ നോട്ട്ബുക്കുകളിൽ സ്വാഭാവിക ഭാഷാ ഇൻപുട്ടിൽ നിന്ന് SQL ചോദ്യങ്ങൾ സൃഷ്ടിക്കാൻ പ്രാപ്തമാക്കുന്നതിന്, ഈ ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ മോഡലുകൾ എങ്ങനെ വിന്യസിക്കാമെന്ന് ഞങ്ങൾ കാണിച്ചുതരുന്നു. ആമസോൺ സേജ് മേക്കർ അവസാന പോയിന്റുകൾ.
പരിഹാര അവലോകനം
SageMaker Studio JupyterLab നോട്ട്ബുക്കിൻ്റെ SQL ഇൻ്റഗ്രേഷൻ ഉപയോഗിച്ച്, നിങ്ങൾക്ക് ഇപ്പോൾ Snowflake, Athena, Amazon Redshift, Amazon DataZone തുടങ്ങിയ ജനപ്രിയ ഡാറ്റ ഉറവിടങ്ങളിലേക്ക് കണക്റ്റുചെയ്യാനാകും. ഈ പുതിയ ഫീച്ചർ വിവിധ പ്രവർത്തനങ്ങൾ നടത്താൻ നിങ്ങളെ പ്രാപ്തരാക്കുന്നു.
ഉദാഹരണത്തിന്, നിങ്ങളുടെ JupyterLab ഇക്കോസിസ്റ്റത്തിൽ നിന്ന് നേരിട്ട് ഡാറ്റാബേസുകൾ, പട്ടികകൾ, സ്കീമകൾ എന്നിവ പോലുള്ള ഡാറ്റ ഉറവിടങ്ങൾ നിങ്ങൾക്ക് ദൃശ്യപരമായി പര്യവേക്ഷണം ചെയ്യാം. നിങ്ങളുടെ നോട്ട്ബുക്ക് പരിതസ്ഥിതികൾ SageMaker Distribution 1.6 അല്ലെങ്കിൽ അതിലും ഉയർന്നതിലാണ് പ്രവർത്തിക്കുന്നതെങ്കിൽ, നിങ്ങളുടെ JupyterLab ഇൻ്റർഫേസിൻ്റെ ഇടതുവശത്ത് ഒരു പുതിയ വിജറ്റിനായി നോക്കുക. ഈ കൂട്ടിച്ചേർക്കൽ നിങ്ങളുടെ വികസന പരിതസ്ഥിതിയിൽ ഡാറ്റ പ്രവേശനക്ഷമതയും മാനേജ്മെൻ്റും വർദ്ധിപ്പിക്കുന്നു.
നിങ്ങൾ നിലവിൽ നിർദ്ദേശിക്കപ്പെട്ട SageMaker വിതരണത്തിലോ (1.5 അല്ലെങ്കിൽ അതിൽ താഴെയോ) അല്ലെങ്കിൽ ഒരു ഇഷ്ടാനുസൃത പരിതസ്ഥിതിയിലല്ലെങ്കിൽ, കൂടുതൽ വിവരങ്ങൾക്ക് അനുബന്ധം കാണുക.

നിങ്ങൾ കണക്ഷനുകൾ സജ്ജീകരിച്ച ശേഷം (അടുത്ത വിഭാഗത്തിൽ ചിത്രീകരിച്ചിരിക്കുന്നു), നിങ്ങൾക്ക് ഡാറ്റ കണക്ഷനുകൾ ലിസ്റ്റുചെയ്യാനും ഡാറ്റാബേസുകളും പട്ടികകളും ബ്രൗസുചെയ്യാനും സ്കീമകൾ പരിശോധിക്കാനും കഴിയും.

SageMaker Studio JupyterLab ബിൽറ്റ്-ഇൻ SQL വിപുലീകരണവും ഒരു നോട്ട്ബുക്കിൽ നിന്ന് നേരിട്ട് SQL അന്വേഷണങ്ങൾ പ്രവർത്തിപ്പിക്കുന്നതിന് നിങ്ങളെ പ്രാപ്തമാക്കുന്നു. ജൂപ്പിറ്റർ നോട്ട്ബുക്കുകൾക്ക് SQL-ഉം പൈത്തൺ കോഡും തമ്മിൽ വേർതിരിച്ചറിയാൻ കഴിയും %%sm_sql മാജിക് കമാൻഡ്, SQL കോഡ് അടങ്ങിയിരിക്കുന്ന ഏത് സെല്ലിൻ്റെയും മുകളിൽ സ്ഥാപിക്കണം. ഇനിപ്പറയുന്ന നിർദ്ദേശങ്ങൾ പൈത്തൺ കോഡിനേക്കാൾ SQL കമാൻഡുകൾ ആണെന്ന് ഈ കമാൻഡ് JupyterLab-ന് സൂചന നൽകുന്നു. നിങ്ങളുടെ ഡാറ്റാ വിശകലനത്തിൽ SQL, പൈത്തൺ വർക്ക്ഫ്ലോകൾ എന്നിവയുടെ തടസ്സമില്ലാത്ത സംയോജനം സുഗമമാക്കിക്കൊണ്ട് ഒരു ചോദ്യത്തിൻ്റെ ഔട്ട്പുട്ട് നോട്ട്ബുക്കിൽ നേരിട്ട് പ്രദർശിപ്പിക്കാൻ കഴിയും.
ഇനിപ്പറയുന്ന സ്ക്രീൻഷോട്ടിൽ കാണിച്ചിരിക്കുന്നതുപോലെ, ഒരു അന്വേഷണത്തിൻ്റെ ഔട്ട്പുട്ട് ദൃശ്യപരമായി HTML പട്ടികകളായി പ്രദർശിപ്പിക്കാൻ കഴിയും.

അവ എ യ്ക്കും എഴുതാം പാണ്ടസ് ഡാറ്റ ഫ്രെയിം.

മുൻവ്യവസ്ഥകൾ
SageMaker Studio നോട്ട്ബുക്ക് SQL അനുഭവം ഉപയോഗിക്കുന്നതിന് ഇനിപ്പറയുന്ന മുൻവ്യവസ്ഥകൾ നിങ്ങൾ തൃപ്തിപ്പെടുത്തിയിട്ടുണ്ടെന്ന് ഉറപ്പാക്കുക:
- സേജ് മേക്കർ സ്റ്റുഡിയോ V2 – നിങ്ങളുടെ ഏറ്റവും കാലികമായ പതിപ്പാണ് നിങ്ങൾ റൺ ചെയ്യുന്നതെന്ന് ഉറപ്പാക്കുക SageMaker സ്റ്റുഡിയോ ഡൊമെയ്നും ഉപയോക്തൃ പ്രൊഫൈലുകളും. നിങ്ങൾ നിലവിൽ SageMaker സ്റ്റുഡിയോ ക്ലാസിക്കിൽ ആണെങ്കിൽ, റഫർ ചെയ്യുക Amazon SageMaker Studio Classic-ൽ നിന്ന് മൈഗ്രേറ്റ് ചെയ്യുന്നു.
- IAM റോൾ – SageMaker ഒരു ആവശ്യമാണ് AWS ഐഡന്റിറ്റി, ആക്സസ് മാനേജുമെന്റ് (IAM) അനുമതികൾ ഫലപ്രദമായി കൈകാര്യം ചെയ്യുന്നതിനായി ഒരു SageMaker സ്റ്റുഡിയോ ഡൊമെയ്നിലോ ഉപയോക്തൃ പ്രൊഫൈലിലോ നിയോഗിക്കേണ്ടതാണ്. ഡാറ്റ ബ്രൗസിംഗും SQL റൺ ഫീച്ചറും കൊണ്ടുവരാൻ ഒരു എക്സിക്യൂഷൻ റോൾ അപ്ഡേറ്റ് ആവശ്യമായി വന്നേക്കാം. ഇനിപ്പറയുന്ന ഉദാഹരണ നയം ഉപയോക്താക്കളെ അനുവദിക്കാനും ലിസ്റ്റ് ചെയ്യാനും പ്രവർത്തിപ്പിക്കാനും പ്രാപ്തമാക്കുന്നു AWS പശ, അഥീന, ആമസോൺ ലളിതമായ സംഭരണ സേവനം (ആമസോൺ എസ് 3), AWS സീക്രട്ട്സ് മാനേജർ, കൂടാതെ ആമസോൺ റെഡ്ഷിഫ്റ്റ് ഉറവിടങ്ങൾ:
- ജൂപ്പിറ്റർ ലാബ് സ്പേസ് - നിങ്ങൾക്ക് അപ്ഡേറ്റ് ചെയ്ത SageMaker സ്റ്റുഡിയോയിലേക്കും JupyterLab സ്പെയ്സിലേക്കും ആക്സസ് ആവശ്യമാണ് സേജ് മേക്കർ വിതരണം v1.6 അല്ലെങ്കിൽ പിന്നീടുള്ള ഇമേജ് പതിപ്പുകൾ. JupyterLab Spaces അല്ലെങ്കിൽ SageMaker Distribution-ൻ്റെ (v1.5 അല്ലെങ്കിൽ അതിൽ താഴെയുള്ള) പഴയ പതിപ്പുകൾക്കായി നിങ്ങൾ ഇഷ്ടാനുസൃത ഇമേജുകൾ ഉപയോഗിക്കുകയാണെങ്കിൽ, നിങ്ങളുടെ പരിതസ്ഥിതികളിൽ ഈ സവിശേഷത പ്രവർത്തനക്ഷമമാക്കുന്നതിന് ആവശ്യമായ പാക്കേജുകളും മൊഡ്യൂളുകളും ഇൻസ്റ്റാൾ ചെയ്യുന്നതിനുള്ള നിർദ്ദേശങ്ങൾക്കായി അനുബന്ധം കാണുക. SageMaker Studio JupyterLab Spaces-നെ കുറിച്ച് കൂടുതലറിയാൻ, റഫർ ചെയ്യുക ആമസോൺ സേജ് മേക്കർ സ്റ്റുഡിയോയിൽ ഉൽപ്പാദനക്ഷമത വർദ്ധിപ്പിക്കുക: ജൂപ്പിറ്റർ ലാബ് സ്പേസുകളും ജനറേറ്റീവ് എഐ ടൂളുകളും അവതരിപ്പിക്കുന്നു.
- ഡാറ്റ ഉറവിട ആക്സസ് ക്രെഡൻഷ്യലുകൾ - ഈ സേജ് മേക്കർ സ്റ്റുഡിയോ നോട്ട്ബുക്ക് ഫീച്ചറിന് സ്നോഫ്ലെക്ക്, ആമസോൺ റെഡ്ഷിഫ്റ്റ് തുടങ്ങിയ ഡാറ്റാ ഉറവിടങ്ങളിലേക്ക് ഉപയോക്തൃനാമവും പാസ്വേഡും ആവശ്യമാണ്. നിങ്ങൾക്ക് ഇതിനകം ഒന്നുമില്ലെങ്കിൽ ഈ ഡാറ്റ ഉറവിടങ്ങളിലേക്ക് ഉപയോക്തൃനാമവും പാസ്വേഡ് അടിസ്ഥാനമാക്കിയുള്ള ആക്സസും സൃഷ്ടിക്കുക. Snowflake-ലേക്കുള്ള OAuth-അധിഷ്ഠിത ആക്സസ് ഈ എഴുത്ത് പോലെ പിന്തുണയ്ക്കുന്ന സവിശേഷതയല്ല.
- SQL മാജിക് ലോഡ് ചെയ്യുക - നിങ്ങൾ ഒരു ജൂപ്പിറ്റർ നോട്ട്ബുക്ക് സെല്ലിൽ നിന്ന് SQL അന്വേഷണങ്ങൾ പ്രവർത്തിപ്പിക്കുന്നതിന് മുമ്പ്, SQL മാജിക് എക്സ്റ്റൻഷൻ ലോഡ് ചെയ്യേണ്ടത് അത്യാവശ്യമാണ്. കമാൻഡ് ഉപയോഗിക്കുക
%load_ext amazon_sagemaker_sql_magicഈ സവിശേഷത പ്രവർത്തനക്ഷമമാക്കാൻ. കൂടാതെ, നിങ്ങൾക്ക് പ്രവർത്തിപ്പിക്കാൻ കഴിയും%sm_sql?ഒരു SQL സെല്ലിൽ നിന്ന് അന്വേഷിക്കുന്നതിനുള്ള പിന്തുണയുള്ള ഓപ്ഷനുകളുടെ ഒരു സമഗ്രമായ ലിസ്റ്റ് കാണാനുള്ള കമാൻഡ്. ഈ ഓപ്ഷനുകളിൽ ഡിഫോൾട്ട് ക്വറി ലിമിറ്റ് 1,000 സജ്ജീകരിക്കുക, പൂർണ്ണമായ എക്സ്ട്രാക്ഷൻ പ്രവർത്തിപ്പിക്കുക, അന്വേഷണ പാരാമീറ്ററുകൾ കുത്തിവയ്ക്കൽ എന്നിവ ഉൾപ്പെടുന്നു. ഈ സജ്ജീകരണം നിങ്ങളുടെ നോട്ട്ബുക്ക് പരിതസ്ഥിതിയിൽ നേരിട്ട് വഴക്കമുള്ളതും കാര്യക്ഷമവുമായ SQL ഡാറ്റ കൈകാര്യം ചെയ്യാൻ അനുവദിക്കുന്നു.
ഡാറ്റാബേസ് കണക്ഷനുകൾ സൃഷ്ടിക്കുക
SageMaker സ്റ്റുഡിയോയുടെ അന്തർനിർമ്മിത SQL ബ്രൗസിംഗും നിർവ്വഹണ ശേഷിയും AWS ഗ്ലൂ കണക്ഷനുകൾ വഴി മെച്ചപ്പെടുത്തിയിരിക്കുന്നു. നിർദ്ദിഷ്ട ഡാറ്റ സ്റ്റോറുകൾക്കായി ലോഗിൻ ക്രെഡൻഷ്യലുകൾ, URI സ്ട്രിംഗുകൾ, വെർച്വൽ പ്രൈവറ്റ് ക്ലൗഡ് (VPC) വിവരങ്ങൾ എന്നിവ പോലുള്ള അവശ്യ ഡാറ്റ സംഭരിക്കുന്ന ഒരു AWS ഗ്ലൂ ഡാറ്റ കാറ്റലോഗ് ഒബ്ജക്റ്റാണ് AWS ഗ്ലൂ കണക്ഷൻ. വിവിധ തരം ഡാറ്റ സ്റ്റോറുകൾ ആക്സസ് ചെയ്യുന്നതിന് AWS ഗ്ലൂ ക്രാളറുകൾ, ജോലികൾ, വികസന എൻഡ്പോയിൻ്റുകൾ എന്നിവ ഈ കണക്ഷനുകൾ ഉപയോഗിക്കുന്നു. ഉറവിടത്തിനും ടാർഗെറ്റ് ഡാറ്റയ്ക്കുമായി നിങ്ങൾക്ക് ഈ കണക്ഷനുകൾ ഉപയോഗിക്കാം, കൂടാതെ ഒന്നിലധികം ക്രാളറുകളിലുടനീളം ഒരേ കണക്ഷൻ വീണ്ടും ഉപയോഗിക്കാനും അല്ലെങ്കിൽ എക്സ്ട്രാക്റ്റ് ചെയ്യാനും രൂപാന്തരപ്പെടുത്താനും ലോഡ് (ETL) ജോലികൾ ചെയ്യാനും കഴിയും.
SageMaker സ്റ്റുഡിയോയുടെ ഇടത് പാളിയിൽ SQL ഡാറ്റ ഉറവിടങ്ങൾ പര്യവേക്ഷണം ചെയ്യുന്നതിന്, നിങ്ങൾ ആദ്യം AWS ഗ്ലൂ കണക്ഷൻ ഒബ്ജക്റ്റുകൾ സൃഷ്ടിക്കേണ്ടതുണ്ട്. ഈ കണക്ഷനുകൾ വ്യത്യസ്ത ഡാറ്റ ഉറവിടങ്ങളിലേക്കുള്ള ആക്സസ് സുഗമമാക്കുകയും അവയുടെ സ്കീമാറ്റിക് ഡാറ്റ ഘടകങ്ങൾ പര്യവേക്ഷണം ചെയ്യാൻ നിങ്ങളെ അനുവദിക്കുകയും ചെയ്യുന്നു.
ഇനിപ്പറയുന്ന വിഭാഗങ്ങളിൽ, ഞങ്ങൾ SQL-നിർദ്ദിഷ്ട AWS ഗ്ലൂ കണക്ടറുകൾ സൃഷ്ടിക്കുന്ന പ്രക്രിയയിലൂടെ കടന്നുപോകുന്നു. വിവിധ ഡാറ്റാ സ്റ്റോറുകളിൽ ഉടനീളം ഡാറ്റാസെറ്റുകൾ ആക്സസ് ചെയ്യാനും കാണാനും പര്യവേക്ഷണം ചെയ്യാനും ഇത് നിങ്ങളെ പ്രാപ്തമാക്കും. AWS ഗ്ലൂ കണക്ഷനുകളെക്കുറിച്ചുള്ള കൂടുതൽ വിശദമായ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക ഡാറ്റയുമായി ബന്ധിപ്പിക്കുന്നു.
ഒരു AWS ഗ്ലൂ കണക്ഷൻ സൃഷ്ടിക്കുക
SageMaker സ്റ്റുഡിയോയിലേക്ക് ഡാറ്റ ഉറവിടങ്ങൾ കൊണ്ടുവരാനുള്ള ഏക മാർഗം AWS ഗ്ലൂ കണക്ഷനുകൾ ആണ്. നിർദ്ദിഷ്ട കണക്ഷൻ തരങ്ങളുള്ള AWS ഗ്ലൂ കണക്ഷനുകൾ നിങ്ങൾ സൃഷ്ടിക്കേണ്ടതുണ്ട്. ഇത് എഴുതുമ്പോൾ, ഈ കണക്ഷനുകൾ സൃഷ്ടിക്കുന്നതിനുള്ള ഏക പിന്തുണയുള്ള സംവിധാനം ഉപയോഗിക്കുന്നത് ആണ് AWS കമാൻഡ് ലൈൻ ഇന്റർഫേസ് (AWS CLI).
കണക്ഷൻ ഡെഫനിഷൻ JSON ഫയൽ
AWS Glue-ലെ വ്യത്യസ്ത ഡാറ്റാ ഉറവിടങ്ങളിലേക്ക് കണക്റ്റ് ചെയ്യുമ്പോൾ, നിങ്ങൾ ആദ്യം കണക്ഷൻ പ്രോപ്പർട്ടികൾ നിർവചിക്കുന്ന ഒരു JSON ഫയൽ സൃഷ്ടിക്കണം-ഇത് കണക്ഷൻ ഡെഫനിഷൻ ഫയൽ. ഒരു AWS ഗ്ലൂ കണക്ഷൻ സ്ഥാപിക്കുന്നതിന് ഈ ഫയൽ നിർണായകമാണ് കൂടാതെ ഡാറ്റ ഉറവിടം ആക്സസ് ചെയ്യുന്നതിന് ആവശ്യമായ എല്ലാ കോൺഫിഗറേഷനുകളും വിശദമാക്കണം. സുരക്ഷാ മികച്ച രീതികൾക്കായി, പാസ്വേഡുകൾ പോലുള്ള തന്ത്രപ്രധാനമായ വിവരങ്ങൾ സുരക്ഷിതമായി സംഭരിക്കാൻ സീക്രട്ട്സ് മാനേജർ ഉപയോഗിക്കാൻ ശുപാർശ ചെയ്യുന്നു. അതേസമയം, മറ്റ് കണക്ഷൻ പ്രോപ്പർട്ടികൾ AWS ഗ്ലൂ കണക്ഷനുകൾ വഴി നേരിട്ട് കൈകാര്യം ചെയ്യാൻ കഴിയും. കണക്ഷൻ കോൺഫിഗറേഷൻ ആക്സസ് ചെയ്യാവുന്നതും കൈകാര്യം ചെയ്യാവുന്നതുമാക്കുമ്പോൾ തന്നെ സെൻസിറ്റീവ് ക്രെഡൻഷ്യലുകൾ പരിരക്ഷിക്കപ്പെട്ടിട്ടുണ്ടെന്ന് ഈ സമീപനം ഉറപ്പാക്കുന്നു.
JSON കണക്ഷൻ നിർവചനത്തിൻ്റെ ഒരു ഉദാഹരണമാണ് ഇനിപ്പറയുന്നത്:
നിങ്ങളുടെ ഡാറ്റ സ്രോതസ്സുകൾക്കായി AWS ഗ്ലൂ കണക്ഷനുകൾ സജ്ജീകരിക്കുമ്പോൾ, പ്രവർത്തനക്ഷമതയും സുരക്ഷയും നൽകുന്നതിന് ചില പ്രധാന മാർഗ്ഗനിർദ്ദേശങ്ങൾ പാലിക്കേണ്ടതുണ്ട്:
- വസ്തുവകകളുടെ സ്ട്രിംഗ്ഫിക്കേഷൻ - ഉള്ളിൽ
PythonPropertiesകീ, എല്ലാ പ്രോപ്പർട്ടികളും ഉണ്ടെന്ന് ഉറപ്പാക്കുക സ്ട്രിംഗ്ഫൈഡ് കീ-വാല്യൂ ജോഡികൾ. ആവശ്യമുള്ളിടത്ത് ബാക്ക്സ്ലാഷ് () പ്രതീകം ഉപയോഗിച്ച് ഇരട്ട ഉദ്ധരണികളിൽ നിന്ന് ശരിയായി രക്ഷപ്പെടുന്നത് വളരെ പ്രധാനമാണ്. ഇത് ശരിയായ ഫോർമാറ്റ് നിലനിർത്താനും നിങ്ങളുടെ JSON-ൽ വാക്യഘടന പിശകുകൾ ഒഴിവാക്കാനും സഹായിക്കുന്നു. - സെൻസിറ്റീവ് വിവരങ്ങൾ കൈകാര്യം ചെയ്യുന്നു – ഉള്ളിൽ എല്ലാ കണക്ഷൻ പ്രോപ്പർട്ടികൾ ഉൾപ്പെടുത്തുന്നത് സാധ്യമാണെങ്കിലും
PythonProperties, ഈ പ്രോപ്പർട്ടികളിൽ നേരിട്ട് പാസ്വേഡുകൾ പോലുള്ള സെൻസിറ്റീവ് വിശദാംശങ്ങൾ ഉൾപ്പെടുത്താതിരിക്കുന്നതാണ് ഉചിതം. പകരം, സെൻസിറ്റീവ് വിവരങ്ങൾ കൈകാര്യം ചെയ്യാൻ സീക്രട്ട്സ് മാനേജർ ഉപയോഗിക്കുക. ഈ സമീപനം നിങ്ങളുടെ സെൻസിറ്റീവ് ഡാറ്റയെ പ്രധാന കോൺഫിഗറേഷൻ ഫയലുകളിൽ നിന്ന് മാറ്റി നിയന്ത്രിതവും എൻക്രിപ്റ്റ് ചെയ്തതുമായ പരിതസ്ഥിതിയിൽ സംഭരിച്ച് സുരക്ഷിതമാക്കുന്നു.
AWS CLI ഉപയോഗിച്ച് ഒരു AWS ഗ്ലൂ കണക്ഷൻ സൃഷ്ടിക്കുക
നിങ്ങളുടെ കണക്ഷൻ ഡെഫനിഷൻ JSON ഫയലിൽ ആവശ്യമായ എല്ലാ ഫീൽഡുകളും ഉൾപ്പെടുത്തിയ ശേഷം, AWS CLI യും ഇനിപ്പറയുന്ന കമാൻഡും ഉപയോഗിച്ച് നിങ്ങളുടെ ഡാറ്റ ഉറവിടത്തിനായി ഒരു AWS ഗ്ലൂ കണക്ഷൻ സ്ഥാപിക്കാൻ നിങ്ങൾ തയ്യാറാണ്:
ഈ കമാൻഡ് നിങ്ങളുടെ JSON ഫയലിൽ വിശദമാക്കിയിരിക്കുന്ന സവിശേഷതകളെ അടിസ്ഥാനമാക്കി ഒരു പുതിയ AWS ഗ്ലൂ കണക്ഷൻ ആരംഭിക്കുന്നു. കമാൻഡ് ഘടകങ്ങളുടെ ദ്രുത തകർച്ചയാണ് ഇനിപ്പറയുന്നത്:
- -പ്രദേശം - ഇത് നിങ്ങളുടെ AWS ഗ്ലൂ കണക്ഷൻ സൃഷ്ടിക്കുന്ന AWS മേഖലയെ വ്യക്തമാക്കുന്നു. ലേറ്റൻസി കുറയ്ക്കുന്നതിനും ഡാറ്റ റെസിഡൻസി ആവശ്യകതകൾ പാലിക്കുന്നതിനും നിങ്ങളുടെ ഡാറ്റ ഉറവിടങ്ങളും മറ്റ് സേവനങ്ങളും സ്ഥിതി ചെയ്യുന്ന പ്രദേശം തിരഞ്ഞെടുക്കുന്നത് നിർണായകമാണ്.
- –cli-input-json ഫയൽ:///path/to/file/connection/definition/file.json - JSON ഫോർമാറ്റിൽ നിങ്ങളുടെ കണക്ഷൻ നിർവചനം ഉൾക്കൊള്ളുന്ന ഒരു ലോക്കൽ ഫയലിൽ നിന്നുള്ള ഇൻപുട്ട് കോൺഫിഗറേഷൻ വായിക്കാൻ AWS CLI-യെ ഈ പരാമീറ്റർ നിർദ്ദേശിക്കുന്നു.
നിങ്ങളുടെ സ്റ്റുഡിയോ ജൂപ്പിറ്റർ ലാബ് ടെർമിനലിൽ നിന്ന് മുമ്പത്തെ AWS CLI കമാൻഡ് ഉപയോഗിച്ച് നിങ്ങൾക്ക് AWS ഗ്ലൂ കണക്ഷനുകൾ സൃഷ്ടിക്കാൻ കഴിയണം. ന് ഫയല് മെനു, തിരഞ്ഞെടുക്കുക പുതിയ ഒപ്പം ടെർമിനൽ.

എങ്കില് create-connection കമാൻഡ് വിജയകരമായി പ്രവർത്തിക്കുന്നു, SQL ബ്രൗസർ പാളിയിൽ ലിസ്റ്റുചെയ്തിരിക്കുന്ന നിങ്ങളുടെ ഡാറ്റ ഉറവിടം നിങ്ങൾ കാണും. നിങ്ങളുടെ ഡാറ്റ ഉറവിടം ലിസ്റ്റുചെയ്തിരിക്കുന്നതായി കാണുന്നില്ലെങ്കിൽ, തിരഞ്ഞെടുക്കുക ഉന്മേഷം വീണ്ടെടുക്കുക കാഷെ അപ്ഡേറ്റ് ചെയ്യാൻ.
ഒരു സ്നോഫ്ലെക്ക് കണക്ഷൻ സൃഷ്ടിക്കുക
ഈ വിഭാഗത്തിൽ, SageMaker സ്റ്റുഡിയോയുമായി ഒരു Snowflake ഡാറ്റ ഉറവിടം സമന്വയിപ്പിക്കുന്നതിൽ ഞങ്ങൾ ശ്രദ്ധ കേന്ദ്രീകരിക്കുന്നു. സ്നോഫ്ലെക്ക് അക്കൗണ്ടുകൾ, ഡാറ്റാബേസുകൾ, വെയർഹൗസുകൾ എന്നിവ സൃഷ്ടിക്കുന്നത് ഈ പോസ്റ്റിൻ്റെ പരിധിക്ക് പുറത്താണ്. സ്നോഫ്ലെക്ക് ഉപയോഗിച്ച് ആരംഭിക്കുന്നതിന്, റഫർ ചെയ്യുക സ്നോഫ്ലെക്ക് ഉപയോക്തൃ ഗൈഡ്. ഈ പോസ്റ്റിൽ, ഒരു സ്നോഫ്ലെക്ക് ഡെഫനിഷൻ JSON ഫയൽ സൃഷ്ടിക്കുന്നതിലും AWS ഗ്ലൂ ഉപയോഗിച്ച് ഒരു സ്നോഫ്ലെക്ക് ഡാറ്റ ഉറവിട കണക്ഷൻ സ്ഥാപിക്കുന്നതിലും ഞങ്ങൾ ശ്രദ്ധ കേന്ദ്രീകരിക്കുന്നു.
ഒരു സീക്രട്ട്സ് മാനേജർ രഹസ്യം സൃഷ്ടിക്കുക
ഒരു യൂസർ ഐഡിയും പാസ്വേഡും ഉപയോഗിച്ചോ സ്വകാര്യ കീകൾ ഉപയോഗിച്ചോ നിങ്ങൾക്ക് സ്നോഫ്ലെക്ക് അക്കൗണ്ടിലേക്ക് കണക്റ്റുചെയ്യാനാകും. ഒരു ഉപയോക്തൃ ഐഡിയും പാസ്വേഡും ഉപയോഗിച്ച് കണക്റ്റുചെയ്യുന്നതിന്, നിങ്ങളുടെ ക്രെഡൻഷ്യലുകൾ സീക്രട്ട്സ് മാനേജറിൽ സുരക്ഷിതമായി സൂക്ഷിക്കേണ്ടതുണ്ട്. മുമ്പ് സൂചിപ്പിച്ചതുപോലെ, PythonProperties-ന് കീഴിൽ ഈ വിവരങ്ങൾ ഉൾച്ചേർക്കാൻ കഴിയുമെങ്കിലും, സെൻസിറ്റീവ് വിവരങ്ങൾ പ്ലെയിൻ ടെക്സ്റ്റ് ഫോർമാറ്റിൽ സൂക്ഷിക്കാൻ ശുപാർശ ചെയ്യുന്നില്ല. സാധ്യതയുള്ള സുരക്ഷാ അപകടസാധ്യതകൾ ഒഴിവാക്കാൻ സെൻസിറ്റീവ് ഡാറ്റ സുരക്ഷിതമായി കൈകാര്യം ചെയ്യുന്നുവെന്ന് എല്ലായ്പ്പോഴും ഉറപ്പാക്കുക.
സീക്രട്ട്സ് മാനേജറിൽ വിവരങ്ങൾ സംഭരിക്കുന്നതിന്, ഇനിപ്പറയുന്ന ഘട്ടങ്ങൾ പൂർത്തിയാക്കുക:
- സീക്രട്ട്സ് മാനേജർ കൺസോളിൽ, തിരഞ്ഞെടുക്കുക ഒരു പുതിയ രഹസ്യം സൂക്ഷിക്കുക.
- വേണ്ടി രഹസ്യ തരം, തിരഞ്ഞെടുക്കുക മറ്റൊരു തരം രഹസ്യം.
- കീ-വാല്യൂ ജോഡിക്കായി, തിരഞ്ഞെടുക്കുക പ്ലെയിൻടെക്സ്റ്റ് കൂടാതെ ഇനിപ്പറയുന്നവ നൽകുക:
- നിങ്ങളുടെ രഹസ്യത്തിന് ഒരു പേര് നൽകുക
sm-sql-snowflake-secret. - മറ്റ് ക്രമീകരണങ്ങൾ ഡിഫോൾട്ടായി വിടുക അല്ലെങ്കിൽ ആവശ്യമെങ്കിൽ ഇഷ്ടാനുസൃതമാക്കുക.
- രഹസ്യം സൃഷ്ടിക്കുക.
സ്നോഫ്ലേക്കിനായി ഒരു AWS ഗ്ലൂ കണക്ഷൻ സൃഷ്ടിക്കുക
നേരത്തെ ചർച്ച ചെയ്തതുപോലെ, സേജ് മേക്കർ സ്റ്റുഡിയോയിൽ നിന്ന് ഏത് കണക്ഷനും ആക്സസ് ചെയ്യുന്നതിന് AWS ഗ്ലൂ കണക്ഷനുകൾ അത്യാവശ്യമാണ്. നിങ്ങൾക്ക് ഒരു ലിസ്റ്റ് കണ്ടെത്താം സ്നോഫ്ലേക്കിനുള്ള എല്ലാ പിന്തുണയുള്ള കണക്ഷൻ പ്രോപ്പർട്ടികൾ. സ്നോഫ്ലേക്കിനുള്ള JSON കണക്ഷൻ നിർവചനം സാമ്പിൾ ആണ്. പ്ലെയ്സ്ഹോൾഡർ മൂല്യങ്ങൾ ഡിസ്കിലേക്ക് സംരക്ഷിക്കുന്നതിന് മുമ്പ് ഉചിതമായ മൂല്യങ്ങൾ ഉപയോഗിച്ച് മാറ്റിസ്ഥാപിക്കുക:
സ്നോഫ്ലെക്ക് ഡാറ്റ ഉറവിടത്തിനായി ഒരു AWS ഗ്ലൂ കണക്ഷൻ ഒബ്ജക്റ്റ് സൃഷ്ടിക്കാൻ, ഇനിപ്പറയുന്ന കമാൻഡ് ഉപയോഗിക്കുക:
ഈ കമാൻഡ് നിങ്ങളുടെ SQL ബ്രൗസർ പാളിയിൽ ഒരു പുതിയ സ്നോഫ്ലെക്ക് ഡാറ്റ സോഴ്സ് കണക്ഷൻ സൃഷ്ടിക്കുന്നു, അത് ബ്രൗസുചെയ്യാനാകും, കൂടാതെ നിങ്ങളുടെ ജൂപ്പിറ്റർലാബ് നോട്ട്ബുക്ക് സെല്ലിൽ നിന്ന് നിങ്ങൾക്ക് SQL അന്വേഷണങ്ങൾ പ്രവർത്തിപ്പിക്കാനാകും.

ഒരു Amazon Redshift കണക്ഷൻ സൃഷ്ടിക്കുക
സാധാരണ SQL ഉപയോഗിച്ച് നിങ്ങളുടെ എല്ലാ ഡാറ്റയും വിശകലനം ചെയ്യുന്നതിനുള്ള ചെലവ് ലളിതമാക്കുകയും കുറയ്ക്കുകയും ചെയ്യുന്ന പൂർണ്ണമായി കൈകാര്യം ചെയ്യപ്പെടുന്ന, പെറ്റാബൈറ്റ് സ്കെയിൽ ഡാറ്റ വെയർഹൗസ് സേവനമാണ് Amazon Redshift. ഒരു ആമസോൺ റെഡ്ഷിഫ്റ്റ് കണക്ഷൻ സൃഷ്ടിക്കുന്നതിനുള്ള നടപടിക്രമം ഒരു സ്നോഫ്ലെക്ക് കണക്ഷനെ പ്രതിഫലിപ്പിക്കുന്നു.
ഒരു സീക്രട്ട്സ് മാനേജർ രഹസ്യം സൃഷ്ടിക്കുക
സ്നോഫ്ലെക്ക് സജ്ജീകരണത്തിന് സമാനമായി, ഒരു ഉപയോക്തൃ ഐഡിയും പാസ്വേഡും ഉപയോഗിച്ച് ആമസോൺ റെഡ്ഷിഫ്റ്റിലേക്ക് കണക്റ്റുചെയ്യുന്നതിന്, നിങ്ങൾ സീക്രട്ട്സ് മാനേജറിൽ രഹസ്യ വിവരങ്ങൾ സുരക്ഷിതമായി സൂക്ഷിക്കേണ്ടതുണ്ട്. ഇനിപ്പറയുന്ന ഘട്ടങ്ങൾ പൂർത്തിയാക്കുക:
- സീക്രട്ട്സ് മാനേജർ കൺസോളിൽ, തിരഞ്ഞെടുക്കുക ഒരു പുതിയ രഹസ്യം സൂക്ഷിക്കുക.
- വേണ്ടി രഹസ്യ തരം, തിരഞ്ഞെടുക്കുക ആമസോൺ റെഡ്ഷിഫ്റ്റ് ക്ലസ്റ്ററിനുള്ള ക്രെഡൻഷ്യലുകൾ.
- ആമസോൺ റെഡ്ഷിഫ്റ്റ് ഒരു ഡാറ്റാ ഉറവിടമായി ആക്സസ് ചെയ്യാൻ ലോഗിൻ ചെയ്യാൻ ഉപയോഗിക്കുന്ന ക്രെഡൻഷ്യലുകൾ നൽകുക.
- രഹസ്യങ്ങളുമായി ബന്ധപ്പെട്ട റെഡ്ഷിഫ്റ്റ് ക്ലസ്റ്റർ തിരഞ്ഞെടുക്കുക.
- രഹസ്യത്തിന് ഒരു പേര് നൽകുക
sm-sql-redshift-secret. - മറ്റ് ക്രമീകരണങ്ങൾ ഡിഫോൾട്ടായി വിടുക അല്ലെങ്കിൽ ആവശ്യമെങ്കിൽ ഇഷ്ടാനുസൃതമാക്കുക.
- രഹസ്യം സൃഷ്ടിക്കുക.
ഈ ഘട്ടങ്ങൾ പാലിക്കുന്നതിലൂടെ, സെൻസിറ്റീവ് ഡാറ്റ ഫലപ്രദമായി കൈകാര്യം ചെയ്യുന്നതിന് AWS-ൻ്റെ ശക്തമായ സുരക്ഷാ സവിശേഷതകൾ ഉപയോഗിച്ച് നിങ്ങളുടെ കണക്ഷൻ ക്രെഡൻഷ്യലുകൾ സുരക്ഷിതമായി കൈകാര്യം ചെയ്യപ്പെടുന്നുവെന്ന് നിങ്ങൾ ഉറപ്പാക്കുന്നു.
ആമസോൺ റെഡ്ഷിഫ്റ്റിനായി ഒരു AWS ഗ്ലൂ കണക്ഷൻ സൃഷ്ടിക്കുക
ഒരു JSON നിർവചനം ഉപയോഗിച്ച് Amazon Redshift-മായി ഒരു കണക്ഷൻ സജ്ജീകരിക്കുന്നതിന്, ആവശ്യമായ ഫീൽഡുകൾ പൂരിപ്പിച്ച് ഇനിപ്പറയുന്ന JSON കോൺഫിഗറേഷൻ ഡിസ്കിലേക്ക് സംരക്ഷിക്കുക:
റെഡ്ഷിഫ്റ്റ് ഡാറ്റ ഉറവിടത്തിനായി ഒരു AWS ഗ്ലൂ കണക്ഷൻ ഒബ്ജക്റ്റ് സൃഷ്ടിക്കാൻ, ഇനിപ്പറയുന്ന AWS CLI കമാൻഡ് ഉപയോഗിക്കുക:
ഈ കമാൻഡ് നിങ്ങളുടെ Redshift ഡാറ്റാ ഉറവിടവുമായി ബന്ധിപ്പിച്ച AWS ഗ്ലൂവിൽ ഒരു കണക്ഷൻ സൃഷ്ടിക്കുന്നു. കമാൻഡ് വിജയകരമായി പ്രവർത്തിക്കുകയാണെങ്കിൽ, SQL അന്വേഷണങ്ങൾ പ്രവർത്തിപ്പിക്കുന്നതിനും ഡാറ്റ വിശകലനം നടത്തുന്നതിനും തയ്യാറായ SageMaker Studio JupyterLab നോട്ട്ബുക്കിനുള്ളിൽ നിങ്ങളുടെ Redshift ഡാറ്റ ഉറവിടം നിങ്ങൾക്ക് കാണാൻ കഴിയും.

ഒരു അഥീന കണക്ഷൻ സൃഷ്ടിക്കുക
സ്റ്റാൻഡേർഡ് SQL ഉപയോഗിച്ച് Amazon S3-ൽ സംഭരിച്ചിരിക്കുന്ന ഡാറ്റയുടെ വിശകലനം പ്രവർത്തനക്ഷമമാക്കുന്ന AWS-ൽ നിന്നുള്ള പൂർണ്ണമായി കൈകാര്യം ചെയ്യപ്പെടുന്ന SQL അന്വേഷണ സേവനമാണ് അഥീന. JupyterLab നോട്ട്ബുക്കിൻ്റെ SQL ബ്രൗസറിൽ ഒരു ഡാറ്റ ഉറവിടമായി Athena കണക്ഷൻ സജ്ജീകരിക്കുന്നതിന്, നിങ്ങൾ ഒരു Athena സാമ്പിൾ കണക്ഷൻ നിർവചനം JSON സൃഷ്ടിക്കേണ്ടതുണ്ട്. ഇനിപ്പറയുന്ന JSON ഘടന, ഡാറ്റ കാറ്റലോഗ്, S3 സ്റ്റേജിംഗ് ഡയറക്ടറി, പ്രദേശം എന്നിവ വ്യക്തമാക്കിക്കൊണ്ട് അഥീനയിലേക്ക് കണക്റ്റുചെയ്യുന്നതിന് ആവശ്യമായ വിശദാംശങ്ങൾ കോൺഫിഗർ ചെയ്യുന്നു:
അഥീന ഡാറ്റ ഉറവിടത്തിനായി ഒരു AWS ഗ്ലൂ കണക്ഷൻ ഒബ്ജക്റ്റ് സൃഷ്ടിക്കുന്നതിന്, ഇനിപ്പറയുന്ന AWS CLI കമാൻഡ് ഉപയോഗിക്കുക:
കമാൻഡ് വിജയകരമാണെങ്കിൽ, നിങ്ങളുടെ SageMaker Studio JupyterLab നോട്ട്ബുക്കിലെ SQL ബ്രൗസറിൽ നിന്ന് നേരിട്ട് Athena ഡാറ്റ കാറ്റലോഗും പട്ടികകളും നിങ്ങൾക്ക് ആക്സസ് ചെയ്യാൻ കഴിയും.

ഒന്നിലധികം ഉറവിടങ്ങളിൽ നിന്നുള്ള ഡാറ്റ അന്വേഷിക്കുക
ബിൽറ്റ്-ഇൻ SQL ബ്രൗസറും നോട്ട്ബുക്ക് SQL സവിശേഷതയും വഴി നിങ്ങൾക്ക് SageMaker സ്റ്റുഡിയോയിൽ ഒന്നിലധികം ഡാറ്റാ സ്രോതസ്സുകൾ സംയോജിപ്പിച്ചിട്ടുണ്ടെങ്കിൽ, നിങ്ങൾക്ക് വേഗത്തിൽ ചോദ്യങ്ങൾ പ്രവർത്തിപ്പിക്കാനും ഒരു നോട്ട്ബുക്കിനുള്ളിലെ തുടർന്നുള്ള സെല്ലുകളിലെ ഡാറ്റ ഉറവിട ബാക്കെൻഡുകൾക്കിടയിൽ അനായാസമായി മാറാനും കഴിയും. നിങ്ങളുടെ വിശകലന വർക്ക്ഫ്ലോ സമയത്ത് വ്യത്യസ്ത ഡാറ്റാബേസുകൾ അല്ലെങ്കിൽ ഡാറ്റ സ്രോതസ്സുകൾക്കിടയിൽ തടസ്സമില്ലാത്ത പരിവർത്തനങ്ങൾ ഈ കഴിവ് അനുവദിക്കുന്നു.
ഡാറ്റാ ഉറവിട ബാക്കെൻഡുകളുടെ വൈവിധ്യമാർന്ന ശേഖരത്തിനെതിരെ നിങ്ങൾക്ക് ചോദ്യങ്ങൾ പ്രവർത്തിപ്പിക്കാനും കൂടുതൽ വിശകലനത്തിനോ ദൃശ്യവൽക്കരണത്തിനോ വേണ്ടി ഫലങ്ങൾ നേരിട്ട് പൈത്തൺ സ്പെയ്സിലേക്ക് കൊണ്ടുവരാനും കഴിയും. ഇത് സുഗമമാക്കുന്നത് %%sm_sql SageMaker സ്റ്റുഡിയോ നോട്ട്ബുക്കുകളിൽ മാജിക് കമാൻഡ് ലഭ്യമാണ്. നിങ്ങളുടെ SQL അന്വേഷണത്തിൻ്റെ ഫലങ്ങൾ ഒരു പാണ്ടസ് ഡാറ്റാഫ്രെയിമിലേക്ക് ഔട്ട്പുട്ട് ചെയ്യുന്നതിന്, രണ്ട് ഓപ്ഷനുകൾ ഉണ്ട്:
- നിങ്ങളുടെ നോട്ട്ബുക്ക് സെൽ ടൂൾബാറിൽ നിന്ന്, ഔട്ട്പുട്ട് തരം തിരഞ്ഞെടുക്കുക ഡാറ്റാഫ്രെയിം നിങ്ങളുടെ DataFrame വേരിയബിളിന് പേര് നൽകുക
- ഇനിപ്പറയുന്ന പാരാമീറ്റർ നിങ്ങളിലേക്ക് ചേർക്കുക
%%sm_sqlകമാൻഡ്:
ഇനിപ്പറയുന്ന ഡയഗ്രം ഈ വർക്ക്ഫ്ലോ ചിത്രീകരിക്കുകയും തുടർന്നുള്ള നോട്ട്ബുക്ക് സെല്ലുകളിലെ വിവിധ ഉറവിടങ്ങളിൽ നിങ്ങൾക്ക് എങ്ങനെ അനായാസമായി ചോദ്യങ്ങൾ പ്രവർത്തിപ്പിക്കാമെന്നും അതുപോലെ പരിശീലന ജോലികൾ ഉപയോഗിച്ചോ അല്ലെങ്കിൽ ലോക്കൽ കമ്പ്യൂട്ട് ഉപയോഗിച്ച് നോട്ട്ബുക്കിനുള്ളിൽ നേരിട്ട് ഒരു സേജ് മേക്കർ മോഡലിനെ പരിശീലിപ്പിക്കാമെന്നും കാണിക്കുന്നു. കൂടാതെ, SageMaker സ്റ്റുഡിയോയുടെ ബിൽറ്റ്-ഇൻ SQL സംയോജനം ഒരു JupyterLab നോട്ട്ബുക്ക് സെല്ലിൻ്റെ പരിചിതമായ പരിതസ്ഥിതിയിൽ നേരിട്ട് വേർതിരിച്ചെടുക്കുന്നതിനും നിർമ്മിക്കുന്നതിനുമുള്ള പ്രക്രിയകളെ എങ്ങനെ ലളിതമാക്കുന്നു എന്ന് ഡയഗ്രം എടുത്തുകാണിക്കുന്നു.

SQL-ലേക്ക് ടെക്സ്റ്റ് ചെയ്യുക: അന്വേഷണ രചയിതാവ് വർദ്ധിപ്പിക്കുന്നതിന് സ്വാഭാവിക ഭാഷ ഉപയോഗിക്കുന്നു
ഡാറ്റാബേസുകൾ, പട്ടികകൾ, വാക്യഘടനകൾ, മെറ്റാഡാറ്റ എന്നിവയെക്കുറിച്ച് മനസ്സിലാക്കേണ്ട ഒരു സങ്കീർണ്ണ ഭാഷയാണ് SQL. ഇന്ന്, ആഴത്തിലുള്ള SQL അനുഭവം ആവശ്യമില്ലാതെ സങ്കീർണ്ണമായ SQL അന്വേഷണങ്ങൾ എഴുതാൻ ജനറേറ്റീവ് ആർട്ടിഫിഷ്യൽ ഇൻ്റലിജൻസിന് (AI) നിങ്ങളെ പ്രാപ്തരാക്കും. LLM-കളുടെ മുന്നേറ്റം നാച്ചുറൽ ലാംഗ്വേജ് പ്രോസസ്സിംഗിനെ (NLP) അടിസ്ഥാനമാക്കിയുള്ള SQL ജനറേഷനെ സാരമായി ബാധിച്ചിട്ടുണ്ട്, ഇത് സ്വാഭാവിക ഭാഷാ വിവരണങ്ങളിൽ നിന്ന് കൃത്യമായ SQL അന്വേഷണങ്ങൾ സൃഷ്ടിക്കാൻ അനുവദിക്കുന്നു-ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ എന്ന് വിളിക്കപ്പെടുന്ന ഒരു സാങ്കേതികത. എന്നിരുന്നാലും, മനുഷ്യ ഭാഷയും SQL ഉം തമ്മിലുള്ള അന്തർലീനമായ വ്യത്യാസങ്ങൾ അംഗീകരിക്കേണ്ടത് അത്യാവശ്യമാണ്. മനുഷ്യ ഭാഷ ചിലപ്പോൾ അവ്യക്തമോ കൃത്യതയില്ലാത്തതോ ആകാം, അതേസമയം SQL ഘടനാപരവും വ്യക്തവും അവ്യക്തവുമാണ്. ഈ വിടവ് നികത്തുന്നതും സ്വാഭാവിക ഭാഷയെ എസ്ക്യുഎൽ അന്വേഷണങ്ങളാക്കി കൃത്യമായി പരിവർത്തനം ചെയ്യുന്നതും കടുത്ത വെല്ലുവിളിയാണ്. ഉചിതമായ നിർദ്ദേശങ്ങൾ നൽകുമ്പോൾ, മനുഷ്യ ഭാഷയുടെ പിന്നിലെ ഉദ്ദേശം മനസ്സിലാക്കി അതിനനുസരിച്ച് കൃത്യമായ SQL അന്വേഷണങ്ങൾ സൃഷ്ടിച്ചുകൊണ്ട് ഈ വിടവ് നികത്താൻ LLM-കൾക്ക് കഴിയും.
SageMaker Studio ഇൻ-നോട്ട്ബുക്ക് SQL ക്വറി ഫീച്ചറിൻ്റെ പ്രകാശനത്തോടെ, SageMaker Studio, ഡാറ്റാബേസുകളും സ്കീമകളും പരിശോധിക്കുന്നതും ജൂപ്പിറ്റർ നോട്ട്ബുക്ക് IDE-ൽ നിന്ന് പുറത്തുപോകാതെ തന്നെ SQL അന്വേഷണങ്ങൾ രചിക്കുന്നതും പ്രവർത്തിപ്പിക്കുന്നതും ഡീബഗ് ചെയ്യുന്നതും ലളിതമാക്കുന്നു. നൂതന LLM-കളുടെ ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ കഴിവുകൾ ജൂപ്പിറ്റർ നോട്ട്ബുക്കുകളിൽ സ്വാഭാവിക ഭാഷ ഉപയോഗിച്ച് എസ്ക്യുഎൽ അന്വേഷണങ്ങൾ സൃഷ്ടിക്കുന്നത് എങ്ങനെയെന്ന് ഈ വിഭാഗം പര്യവേക്ഷണം ചെയ്യുന്നു. ഞങ്ങൾ അത്യാധുനിക ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ മോഡൽ ഉപയോഗിക്കുന്നു defog/sqlcoder-7b-2 സ്വാഭാവിക ഭാഷയിൽ നിന്ന് സങ്കീർണ്ണമായ SQL അന്വേഷണങ്ങൾ സൃഷ്ടിക്കുന്നതിന് ജൂപ്പിറ്റർ നോട്ട്ബുക്കുകൾക്കായി പ്രത്യേകം രൂപകൽപ്പന ചെയ്ത ഒരു ജനറേറ്റീവ് AI അസിസ്റ്റൻ്റായ Jupyter AI-യുമായി ചേർന്ന്. ഈ നൂതന മോഡൽ ഉപയോഗിക്കുന്നതിലൂടെ, നമുക്ക് സ്വാഭാവിക ഭാഷ ഉപയോഗിച്ച് സങ്കീർണ്ണമായ SQL അന്വേഷണങ്ങൾ അനായാസമായും കാര്യക്ഷമമായും സൃഷ്ടിക്കാൻ കഴിയും, അതുവഴി നോട്ട്ബുക്കുകളിൽ ഞങ്ങളുടെ SQL അനുഭവം വർദ്ധിപ്പിക്കും.
ഹഗ്ഗിംഗ് ഫേസ് ഹബ് ഉപയോഗിച്ച് നോട്ട്ബുക്ക് പ്രോട്ടോടൈപ്പിംഗ്
പ്രോട്ടോടൈപ്പിംഗ് ആരംഭിക്കുന്നതിന്, നിങ്ങൾക്ക് ഇനിപ്പറയുന്നവ ആവശ്യമാണ്:
- GitHub കോഡ് - ഈ വിഭാഗത്തിൽ അവതരിപ്പിച്ചിരിക്കുന്ന കോഡ് ഇനിപ്പറയുന്നതിൽ ലഭ്യമാണ് ഗിറ്റ്ഹബ് റെപ്പോ എന്നിവയെ പരാമർശിച്ചുകൊണ്ട് ഉദാഹരണം നോട്ട്ബുക്ക്.
- ജൂപ്പിറ്റർ ലാബ് സ്പേസ് - GPU-അധിഷ്ഠിത സംഭവങ്ങളുടെ പിന്തുണയുള്ള ഒരു SageMaker Studio JupyterLab സ്പെയ്സിലേക്കുള്ള ആക്സസ് അത്യാവശ്യമാണ്. വേണ്ടി
defog/sqlcoder-7b-2മോഡൽ, 7B പാരാമീറ്റർ മോഡൽ, ml.g5.2xlarge ഉദാഹരണം ഉപയോഗിക്കുന്നത് ശുപാർശ ചെയ്യുന്നു. പോലുള്ള ബദലുകൾdefog/sqlcoder-70b-alpha അല്ലെങ്കിൽdefog/sqlcoder-34b-alphaസ്വാഭാവിക ഭാഷയും SQL-ലേക്കുള്ള പരിവർത്തനവും സാധ്യമാണ്, എന്നാൽ പ്രോട്ടോടൈപ്പിംഗിന് വലിയ ഉദാഹരണ തരങ്ങൾ ആവശ്യമായി വന്നേക്കാം. സേവന ക്വാട്ട കൺസോളിലേക്ക് നാവിഗേറ്റ് ചെയ്യുന്നതിലൂടെയും SageMaker-നായി തിരയുന്നതിലൂടെയും GPU- പിന്തുണയുള്ള ഒരു ഉദാഹരണം സമാരംഭിക്കുന്നതിനുള്ള ക്വാട്ട നിങ്ങൾക്കുണ്ടെന്ന് ഉറപ്പാക്കുകStudio JupyterLab Apps running on <instance type>.
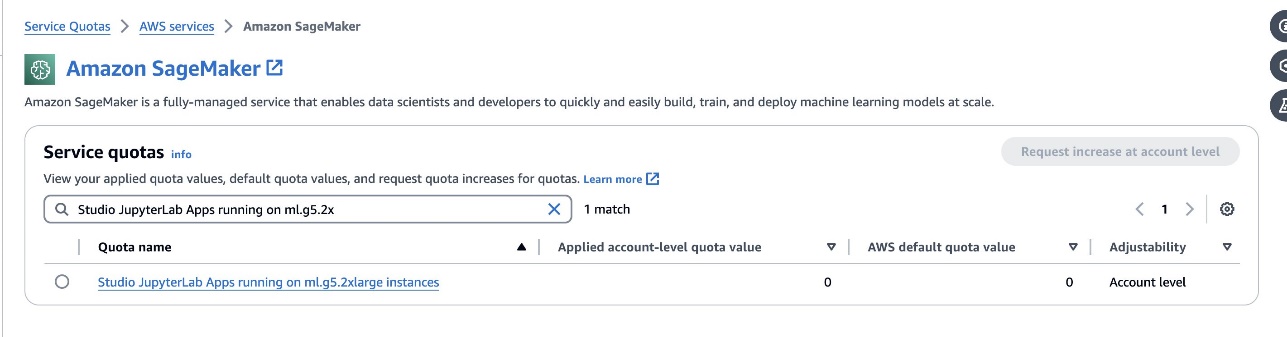
നിങ്ങളുടെ സേജ് മേക്കർ സ്റ്റുഡിയോയിൽ നിന്ന് ഒരു പുതിയ GPU പിന്തുണയുള്ള JupyterLab സ്പേസ് സമാരംഭിക്കുക. കുറഞ്ഞത് 75 GB എങ്കിലും ഉള്ള ഒരു പുതിയ JupyterLab സ്പേസ് സൃഷ്ടിക്കാൻ ശുപാർശ ചെയ്യുന്നു ആമസോൺ ഇലാസ്റ്റിക് ബ്ലോക്ക് സ്റ്റോർ (Amazon EBS) ഒരു 7B പാരാമീറ്റർ മോഡലിനുള്ള സംഭരണം.


- ഹഗ്ഗിംഗ് ഫേസ് ഹബ് - നിങ്ങളുടെ SageMaker സ്റ്റുഡിയോ ഡൊമെയ്നിന് മോഡലുകൾ ഡൗൺലോഡ് ചെയ്യാൻ ആക്സസ് ഉണ്ടെങ്കിൽ ഹഗ്ഗിംഗ് ഫേസ് ഹബ്, നിങ്ങൾക്ക് ഉപയോഗിക്കാം
AutoModelForCausalLMമുതൽ ക്ലാസ് ആലിംഗനം/ട്രാൻസ്ഫോർമറുകൾ മോഡലുകൾ സ്വയമേവ ഡൗൺലോഡ് ചെയ്യാനും അവയെ നിങ്ങളുടെ പ്രാദേശിക GPU-കളിൽ പിൻ ചെയ്യാനും. മോഡൽ വെയ്റ്റുകൾ നിങ്ങളുടെ ലോക്കൽ മെഷീൻ്റെ കാഷെയിൽ സൂക്ഷിക്കും. ഇനിപ്പറയുന്ന കോഡ് കാണുക:
മോഡൽ പൂർണ്ണമായി ഡൗൺലോഡ് ചെയ്ത് മെമ്മറിയിലേക്ക് ലോഡ് ചെയ്ത ശേഷം, നിങ്ങളുടെ പ്രാദേശിക മെഷീനിൽ GPU ഉപയോഗത്തിൽ വർദ്ധനവ് നിങ്ങൾ നിരീക്ഷിക്കണം. കമ്പ്യൂട്ടേഷണൽ ജോലികൾക്കായി മോഡൽ GPU ഉറവിടങ്ങൾ സജീവമായി ഉപയോഗിക്കുന്നുണ്ടെന്ന് ഇത് സൂചിപ്പിക്കുന്നു. പ്രവർത്തിപ്പിക്കുന്നതിലൂടെ നിങ്ങളുടെ സ്വന്തം JupyterLab സ്പെയ്സിൽ ഇത് സ്ഥിരീകരിക്കാനാകും nvidia-smi (ഒറ്റത്തവണ പ്രദർശിപ്പിക്കുന്നതിന്) അല്ലെങ്കിൽ nvidia-smi —loop=1 (ഓരോ സെക്കൻഡിലും ആവർത്തിക്കാൻ) നിങ്ങളുടെ JupyterLab ടെർമിനലിൽ നിന്ന്.

ഉപയോഗിക്കുന്ന ഭാഷ സംഭാഷണപരമോ അവ്യക്തമോ ആണെങ്കിൽപ്പോലും, ഒരു ഉപയോക്താവിൻ്റെ അഭ്യർത്ഥനയുടെ ഉദ്ദേശ്യവും സന്ദർഭവും മനസ്സിലാക്കുന്നതിൽ ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ മോഡലുകൾ മികച്ചതാണ്. പട്ടിക നാമങ്ങൾ, കോളം നാമങ്ങൾ, വ്യവസ്ഥകൾ എന്നിവ പോലുള്ള ശരിയായ ഡാറ്റാബേസ് സ്കീമ ഘടകങ്ങളിലേക്ക് സ്വാഭാവിക ഭാഷാ ഇൻപുട്ടുകൾ വിവർത്തനം ചെയ്യുന്നത് പ്രക്രിയയിൽ ഉൾപ്പെടുന്നു. എന്നിരുന്നാലും, ഒരു ഓഫ്-ദി-ഷെൽഫ് ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ മോഡലിന് നിങ്ങളുടെ ഡാറ്റ വെയർഹൗസിൻ്റെ ഘടനയോ നിർദ്ദിഷ്ട ഡാറ്റാബേസ് സ്കീമകളോ അന്തർലീനമായി അറിയാൻ കഴിയില്ല, അല്ലെങ്കിൽ കോളം പേരുകളെ മാത്രം അടിസ്ഥാനമാക്കി ഒരു പട്ടികയുടെ ഉള്ളടക്കം കൃത്യമായി വ്യാഖ്യാനിക്കാൻ കഴിയില്ല. സ്വാഭാവിക ഭാഷയിൽ നിന്ന് പ്രായോഗികവും കാര്യക്ഷമവുമായ SQL അന്വേഷണങ്ങൾ സൃഷ്ടിക്കുന്നതിന് ഈ മോഡലുകൾ ഫലപ്രദമായി ഉപയോഗിക്കുന്നതിന്, നിങ്ങളുടെ നിർദ്ദിഷ്ട വെയർഹൗസ് ഡാറ്റാബേസ് സ്കീമയിലേക്ക് SQL ടെക്സ്റ്റ്-ജനറേഷൻ മോഡൽ പൊരുത്തപ്പെടുത്തേണ്ടത് ആവശ്യമാണ്. ഈ പൊരുത്തപ്പെടുത്തൽ ഉപയോഗത്തിലൂടെ സുഗമമാക്കുന്നു LLM ആവശ്യപ്പെടുന്നു. defog/sqlcoder-7b-2 ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ മോഡലിനായുള്ള ശുപാർശ ചെയ്ത പ്രോംപ്റ്റ് ടെംപ്ലേറ്റാണ് ഇനിപ്പറയുന്നത്, നാല് ഭാഗങ്ങളായി തിരിച്ചിരിക്കുന്നു:
- ടാസ്ക് - ഈ വിഭാഗം മോഡൽ പൂർത്തിയാക്കേണ്ട ഒരു ഉയർന്ന തലത്തിലുള്ള ചുമതല വ്യക്തമാക്കണം. അന്തിമ SQL അന്വേഷണത്തിൻ്റെ ജനറേഷനെ ബാധിച്ചേക്കാവുന്ന സൂക്ഷ്മമായ വാക്യഘടനാ വ്യത്യാസങ്ങളെക്കുറിച്ച് മോഡലിനെ ബോധവാന്മാരാക്കുന്നതിന് അതിൽ ഡാറ്റാബേസ് ബാക്കെൻഡ് തരം (Amazon RDS, PostgreSQL, അല്ലെങ്കിൽ Amazon Redshift പോലുള്ളവ) ഉൾപ്പെടുത്തണം.
- നിർദ്ദേശങ്ങൾ - ഈ വിഭാഗം മോഡലിനായുള്ള ടാസ്ക് അതിരുകളും ഡൊമെയ്ൻ അവബോധവും നിർവചിക്കേണ്ടതാണ്, കൂടാതെ മികച്ച രീതിയിൽ ട്യൂൺ ചെയ്ത SQL അന്വേഷണങ്ങൾ സൃഷ്ടിക്കുന്നതിന് മോഡലിനെ നയിക്കുന്നതിന് കുറച്ച്-ഷോട്ട് ഉദാഹരണങ്ങൾ ഉൾപ്പെടുത്തിയേക്കാം.
- ഡാറ്റാബേസ് സ്കീമ - ഈ വിഭാഗം നിങ്ങളുടെ വെയർഹൗസ് ഡാറ്റാബേസ് സ്കീമകൾ വിശദമാക്കണം, ഡാറ്റാബേസ് ഘടന മനസ്സിലാക്കാൻ മോഡലിനെ സഹായിക്കുന്നതിന് പട്ടികകളും നിരകളും തമ്മിലുള്ള ബന്ധത്തെ വിവരിക്കുന്നു.
- ഉത്തരം - സ്വാഭാവിക ഭാഷാ ഇൻപുട്ടിലേക്കുള്ള SQL അന്വേഷണ പ്രതികരണം ഔട്ട്പുട്ട് ചെയ്യുന്നതിനുള്ള മോഡലിനായി ഈ വിഭാഗം നീക്കിവച്ചിരിക്കുന്നു.
ഈ വിഭാഗത്തിൽ ഉപയോഗിച്ചിരിക്കുന്ന ഡാറ്റാബേസ് സ്കീമയുടെയും പ്രോംപ്റ്റിൻ്റെയും ഒരു ഉദാഹരണം ഇതിൽ ലഭ്യമാണ് GitHub റിപ്പോ.
പ്രോംപ്റ്റ് എഞ്ചിനീയറിംഗ് എന്നത് ചോദ്യങ്ങളോ പ്രസ്താവനകളോ രൂപപ്പെടുത്തുന്നത് മാത്രമല്ല; ഇത് ഒരു AI മോഡലുമായുള്ള ഇടപെടലുകളുടെ ഗുണനിലവാരത്തെ സാരമായി ബാധിക്കുന്ന ഒരു സൂക്ഷ്മ കലയും ശാസ്ത്രവുമാണ്. നിങ്ങൾ ഒരു പ്രോംപ്റ്റ് തയ്യാറാക്കുന്ന രീതി AI-യുടെ പ്രതികരണത്തിൻ്റെ സ്വഭാവത്തെയും ഉപയോഗത്തെയും ആഴത്തിൽ സ്വാധീനിക്കും. AI ഇടപെടലുകളുടെ സാധ്യതകൾ പരമാവധി വർദ്ധിപ്പിക്കുന്നതിൽ ഈ വൈദഗ്ദ്ധ്യം നിർണായകമാണ്, പ്രത്യേകിച്ച് സവിശേഷമായ ധാരണയും വിശദമായ പ്രതികരണങ്ങളും ആവശ്യമായ സങ്കീർണ്ണമായ ജോലികളിൽ.
തന്നിരിക്കുന്ന പ്രോംപ്റ്റിനായി ഒരു മോഡലിൻ്റെ പ്രതികരണം വേഗത്തിൽ നിർമ്മിക്കാനും പരിശോധിക്കാനുമുള്ള ഓപ്ഷൻ ഉണ്ടായിരിക്കുകയും പ്രതികരണത്തെ അടിസ്ഥാനമാക്കി പ്രോംപ്റ്റ് ഒപ്റ്റിമൈസ് ചെയ്യുകയും ചെയ്യേണ്ടത് പ്രധാനമാണ്. ലോക്കൽ കംപ്യൂട്ടിൽ പ്രവർത്തിക്കുന്ന ഒരു മോഡലിൽ നിന്ന് തൽക്ഷണ മോഡൽ ഫീഡ്ബാക്ക് സ്വീകരിക്കാനും പ്രോംപ്റ്റ് ഒപ്റ്റിമൈസ് ചെയ്യാനും മോഡലിൻ്റെ പ്രതികരണം ട്യൂൺ ചെയ്യാനും അല്ലെങ്കിൽ മോഡൽ പൂർണ്ണമായും മാറ്റാനുമുള്ള കഴിവ് JupyterLab നോട്ട്ബുക്കുകൾ നൽകുന്നു. ഈ പോസ്റ്റിൽ, നോട്ട്ബുക്കിൽ ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ മോഡൽ അനുമാനം പ്രവർത്തിപ്പിക്കുന്നതിനും മോഡലിൻ്റെ പ്രതികരണം നൽകാൻ വേണ്ടത്ര ട്യൂൺ ചെയ്യപ്പെടുന്നതുവരെ ഞങ്ങളുടെ മോഡൽ പ്രോംപ്റ്റ് സംവേദനാത്മകമായി നിർമ്മിക്കുന്നതിനും ml.g5.2xlarge-ൻ്റെ NVIDIA A10G 24 GB GPU പിന്തുണയുള്ള SageMaker Studio JupyterLab നോട്ട്ബുക്ക് ഞങ്ങൾ ഉപയോഗിക്കുന്നു. JupyterLab-ൻ്റെ SQL സെല്ലുകളിൽ നേരിട്ട് നടപ്പിലാക്കാൻ കഴിയുന്ന പ്രതികരണങ്ങൾ. മോഡൽ അനുമാനം പ്രവർത്തിപ്പിക്കുന്നതിനും ഒരേസമയം മോഡൽ പ്രതികരണങ്ങൾ സ്ട്രീം ചെയ്യുന്നതിനും, ഞങ്ങൾ ഒരു കോമ്പിനേഷൻ ഉപയോഗിക്കുന്നു model.generate ഒപ്പം TextIteratorStreamer ഇനിപ്പറയുന്ന കോഡിൽ നിർവചിച്ചിരിക്കുന്നത് പോലെ:
മോഡലിൻ്റെ ഔട്ട്പുട്ട് SageMaker SQL മാജിക് ഉപയോഗിച്ച് അലങ്കരിക്കാവുന്നതാണ് %%sm_sql ..., ഇത് സെല്ലിനെ ഒരു SQL സെല്ലായി തിരിച്ചറിയാൻ JupyterLab നോട്ട്ബുക്കിനെ അനുവദിക്കുന്നു.
SageMaker എൻഡ് പോയിൻ്റുകളായി ടെക്സ്റ്റ്-ടു-SQL മോഡലുകൾ ഹോസ്റ്റ് ചെയ്യുക
പ്രോട്ടോടൈപ്പിംഗ് ഘട്ടത്തിൻ്റെ അവസാനം, ഞങ്ങൾ തിരഞ്ഞെടുത്ത ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ എൽഎൽഎം, ഫലപ്രദമായ പ്രോംപ്റ്റ് ഫോർമാറ്റ്, മോഡൽ ഹോസ്റ്റുചെയ്യുന്നതിനുള്ള ഉചിതമായ ഉദാഹരണ തരം (ഒന്നുകിൽ-ജിപിയു അല്ലെങ്കിൽ മൾട്ടി-ജിപിയു). SageMaker എൻഡ്പോയിൻ്റുകളുടെ ഉപയോഗത്തിലൂടെ ഇഷ്ടാനുസൃത മോഡലുകളുടെ സ്കേലബിൾ ഹോസ്റ്റിംഗ് സുഗമമാക്കുന്നു. ഈ എൻഡ്പോയിൻ്റുകൾ നിർദ്ദിഷ്ട മാനദണ്ഡങ്ങൾക്കനുസൃതമായി നിർവചിക്കാവുന്നതാണ്, ഇത് LLM-കളെ എൻഡ്പോയിൻ്റുകളായി വിന്യസിക്കാൻ അനുവദിക്കുന്നു. ഇഷ്ടാനുസൃത ഹോസ്റ്റ് ചെയ്ത LLM-കൾ ഉപയോഗിച്ച് സ്വാഭാവിക ഭാഷാ ഇൻപുട്ടുകളിൽ നിന്ന് SQL ചോദ്യങ്ങൾ സൃഷ്ടിക്കാൻ ഉപയോക്താക്കളെ അനുവദിക്കുന്ന, വിശാലമായ പ്രേക്ഷകരിലേക്ക് പരിഹാരം അളക്കാൻ ഈ കഴിവ് നിങ്ങളെ പ്രാപ്തമാക്കുന്നു. ഇനിപ്പറയുന്ന ഡയഗ്രം ഈ വാസ്തുവിദ്യയെ വ്യക്തമാക്കുന്നു.
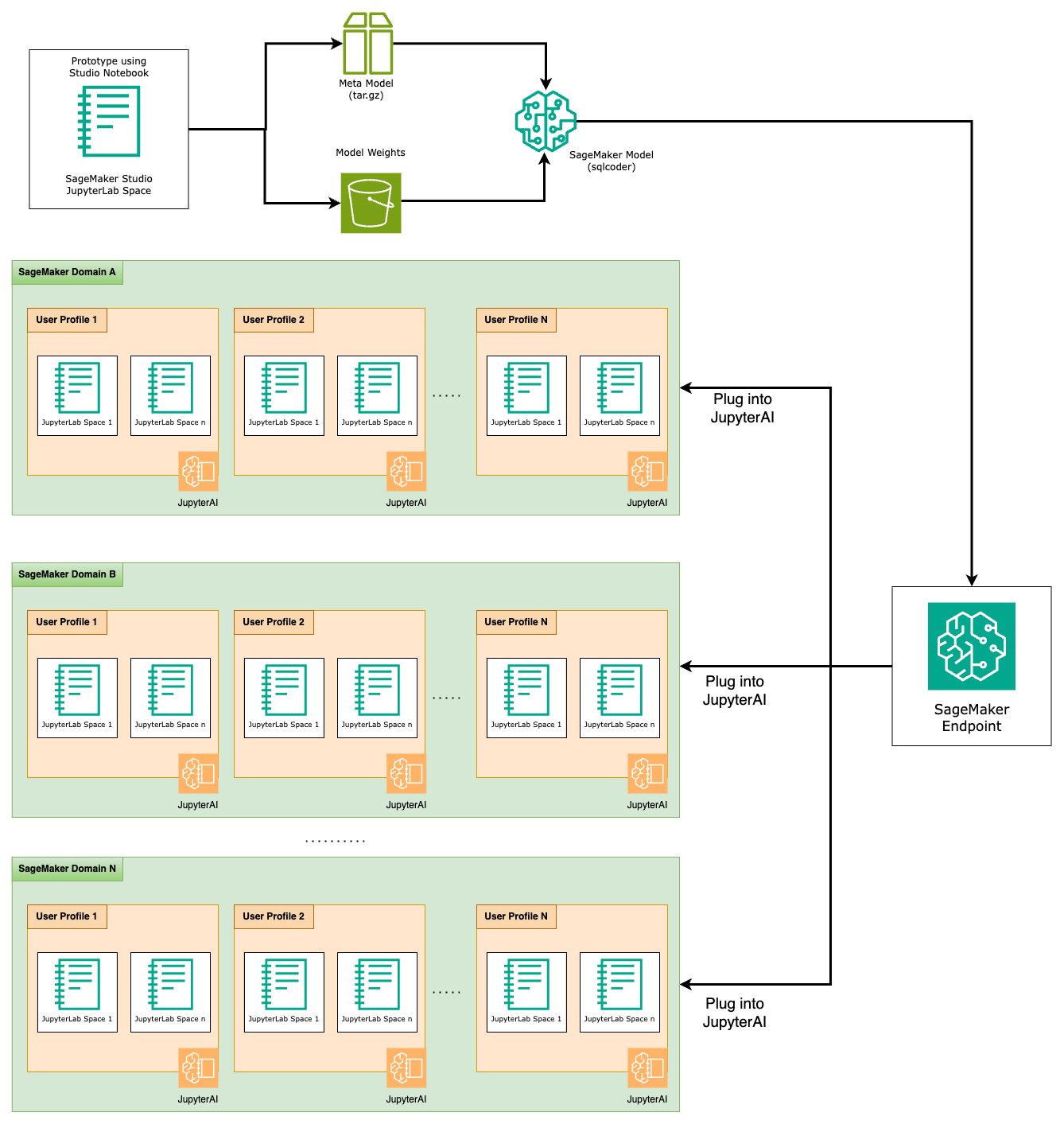
ഒരു സേജ് മേക്കർ എൻഡ് പോയിൻ്റായി നിങ്ങളുടെ LLM ഹോസ്റ്റ് ചെയ്യുന്നതിന്, നിങ്ങൾ നിരവധി പുരാവസ്തുക്കൾ സൃഷ്ടിക്കുന്നു.
ആദ്യത്തെ ആർട്ടിഫാക്റ്റ് മോഡൽ വെയ്റ്റുകളാണ്. സേജ് മേക്കർ ഡീപ് ജാവ ലൈബ്രറി (ഡിജെഎൽ) സേവനം നൽകുന്നു ഒരു മെറ്റാ വഴി കോൺഫിഗറേഷനുകൾ സജ്ജീകരിക്കാൻ കണ്ടെയ്നറുകൾ നിങ്ങളെ അനുവദിക്കുന്നു serving.properties ഹഗ്ഗിംഗ് ഫേസ് ഹബിൽ നിന്ന് നേരിട്ടോ അല്ലെങ്കിൽ Amazon S3-ൽ നിന്ന് മോഡൽ ആർട്ടിഫാക്റ്റുകൾ ഡൗൺലോഡ് ചെയ്തോ - എങ്ങനെ മോഡലുകൾ സ്രോതസ്സ് ചെയ്യപ്പെടുന്നുവെന്ന് നേരിട്ട് നിങ്ങളെ പ്രാപ്തമാക്കുന്ന ഫയൽ. നിങ്ങൾ വ്യക്തമാക്കിയാൽ model_id=defog/sqlcoder-7b-2, DJL സെർവിംഗ് ഈ മോഡൽ ഹഗ്ഗിംഗ് ഫേസ് ഹബിൽ നിന്ന് നേരിട്ട് ഡൗൺലോഡ് ചെയ്യാൻ ശ്രമിക്കും. എന്നിരുന്നാലും, ഓരോ തവണയും എൻഡ്പോയിൻ്റ് വിന്യസിക്കുമ്പോഴോ ഇലാസ്റ്റിക് സ്കെയിൽ ചെയ്യുമ്പോഴോ നിങ്ങൾക്ക് നെറ്റ്വർക്കിംഗ് ഇൻഗ്രെസ്/എഗ്രസ് ചാർജുകൾ ഉണ്ടായേക്കാം. ഈ നിരക്കുകൾ ഒഴിവാക്കാനും മോഡൽ ആർട്ടിഫാക്റ്റുകളുടെ ഡൗൺലോഡ് വേഗത്തിലാക്കാനും, ഉപയോഗിക്കുന്നത് ഒഴിവാക്കാൻ ശുപാർശ ചെയ്യുന്നു model_id in serving.properties കൂടാതെ മോഡൽ വെയ്റ്റുകൾ S3 ആർട്ടിഫാക്റ്റുകളായി സംരക്ഷിക്കുകയും അവ ഉപയോഗിച്ച് മാത്രം വ്യക്തമാക്കുകയും ചെയ്യുക s3url=s3://path/to/model/bin.
ഒരു മോഡൽ (അതിൻ്റെ ടോക്കനൈസർ ഉപയോഗിച്ച്) ഡിസ്കിലേക്ക് സംരക്ഷിക്കുകയും ആമസോൺ എസ് 3 ലേക്ക് അപ്ലോഡ് ചെയ്യുകയും ചെയ്യുന്നത് കുറച്ച് വരി കോഡ് ഉപയോഗിച്ച് പൂർത്തിയാക്കാൻ കഴിയും:
നിങ്ങൾ ഒരു ഡാറ്റാബേസ് പ്രോംപ്റ്റ് ഫയലും ഉപയോഗിക്കുന്നു. ഈ സജ്ജീകരണത്തിൽ, ഡാറ്റാബേസ് പ്രോംപ്റ്റ് അടങ്ങിയിരിക്കുന്നു Task, Instructions, Database Schema, ഒപ്പം Answer sections. നിലവിലെ ആർക്കിടെക്ചറിനായി, ഓരോ ഡാറ്റാബേസ് സ്കീമയ്ക്കും ഞങ്ങൾ ഒരു പ്രത്യേക പ്രോംപ്റ്റ് ഫയൽ അനുവദിക്കും. എന്നിരുന്നാലും, ഒരു പ്രോംപ്റ്റ് ഫയലിൽ ഒന്നിലധികം ഡാറ്റാബേസുകൾ ഉൾപ്പെടുത്തുന്നതിനായി ഈ സജ്ജീകരണം വിപുലീകരിക്കുന്നതിനുള്ള ഫ്ലെക്സിബിലിറ്റി ഉണ്ട്, ഒരേ സെർവറിലെ ഡാറ്റാബേസുകളിലുടനീളം സംയോജിത ജോയിനുകൾ പ്രവർത്തിപ്പിക്കാൻ മോഡലിനെ അനുവദിക്കുന്നു. ഞങ്ങളുടെ പ്രോട്ടോടൈപ്പിംഗ് ഘട്ടത്തിൽ, ഞങ്ങൾ ഡാറ്റാബേസ് പ്രോംപ്റ്റിനെ ഒരു ടെക്സ്റ്റ് ഫയലായി സേവ് ചെയ്യുന്നു <Database-Glue-Connection-Name>.promptഎവിടെ Database-Glue-Connection-Name നിങ്ങളുടെ JupyterLab പരിതസ്ഥിതിയിൽ ദൃശ്യമാകുന്ന കണക്ഷൻ പേരുമായി പൊരുത്തപ്പെടുന്നു. ഉദാഹരണത്തിന്, ഈ പോസ്റ്റ് ഒരു സ്നോഫ്ലെക്ക് കണക്ഷനെ സൂചിപ്പിക്കുന്നു Airlines_Dataset, അതിനാൽ ഡാറ്റാബേസ് പ്രോംപ്റ്റ് ഫയലിന് പേര് നൽകിയിരിക്കുന്നു Airlines_Dataset.prompt. ഈ ഫയൽ ആമസോൺ S3-ൽ സംഭരിക്കുകയും പിന്നീട് ഞങ്ങളുടെ മോഡൽ സെർവിംഗ് ലോജിക് ഉപയോഗിച്ച് വായിക്കുകയും കാഷെ ചെയ്യുകയും ചെയ്യുന്നു.
കൂടാതെ, മോഡലിൻ്റെ ഒന്നിലധികം പുനർവിന്യാസങ്ങൾ ആവശ്യമില്ലാതെ തന്നെ SQL അന്വേഷണങ്ങളിലേക്ക് സ്വാഭാവിക ഭാഷ നിർവചിക്കാനും സംഭരിക്കാനും സൃഷ്ടിക്കാനും ഈ എൻഡ്പോയിൻ്റിൻ്റെ അംഗീകൃത ഉപയോക്താക്കളെ ഈ ആർക്കിടെക്ചർ അനുവദിക്കുന്നു. ഞങ്ങൾ ഇനിപ്പറയുന്നവ ഉപയോഗിക്കുന്നു ഒരു ഡാറ്റാബേസ് പ്രോംപ്റ്റിൻ്റെ ഉദാഹരണം ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ പ്രവർത്തനക്ഷമത പ്രകടിപ്പിക്കാൻ.
അടുത്തതായി, നിങ്ങൾ ഇഷ്ടാനുസൃത മോഡൽ സേവന ലോജിക് സൃഷ്ടിക്കുന്നു. ഈ വിഭാഗത്തിൽ, നിങ്ങൾ ഒരു ഇഷ്ടാനുസൃത അനുമാന യുക്തിയുടെ രൂപരേഖ നൽകുന്നു model.py. ഞങ്ങളുടെ ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ സേവനങ്ങളുടെ പ്രകടനവും സംയോജനവും ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിനാണ് ഈ സ്ക്രിപ്റ്റ് രൂപകൽപ്പന ചെയ്തിരിക്കുന്നത്:
- ഡാറ്റാബേസ് പ്രോംപ്റ്റ് ഫയൽ കാഷിംഗ് ലോജിക് നിർവചിക്കുക - ലേറ്റൻസി കുറയ്ക്കുന്നതിന്, ഡാറ്റാബേസ് പ്രോംപ്റ്റ് ഫയലുകൾ ഡൗൺലോഡ് ചെയ്യുന്നതിനും കാഷെ ചെയ്യുന്നതിനുമുള്ള ഒരു ഇഷ്ടാനുസൃത ലോജിക് ഞങ്ങൾ നടപ്പിലാക്കുന്നു. ഈ സംവിധാനം പ്രോംപ്റ്റുകൾ എളുപ്പത്തിൽ ലഭ്യമാണെന്ന് ഉറപ്പാക്കുന്നു, പതിവായി ഡൗൺലോഡ് ചെയ്യുന്നതുമായി ബന്ധപ്പെട്ട ഓവർഹെഡ് കുറയ്ക്കുന്നു.
- ഇഷ്ടാനുസൃത മോഡൽ അനുമാന യുക്തി നിർവചിക്കുക - അനുമാന വേഗത വർദ്ധിപ്പിക്കുന്നതിന്, ഞങ്ങളുടെ ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ മോഡൽ ഫ്ലോട്ട്16 പ്രിസിഷൻ ഫോർമാറ്റിൽ ലോഡുചെയ്ത് ഒരു ഡീപ്സ്പീഡ് മോഡലാക്കി മാറ്റുന്നു. ഈ ഘട്ടം കൂടുതൽ കാര്യക്ഷമമായ കണക്കുകൂട്ടൽ അനുവദിക്കുന്നു. കൂടാതെ, ഈ ലോജിക്കിൽ, ഉപയോക്താക്കൾക്ക് അവരുടെ ആവശ്യങ്ങൾക്കനുസരിച്ച് പ്രവർത്തനക്ഷമത ക്രമീകരിക്കുന്നതിന് അനുമാന കോളുകൾ സമയത്ത് ക്രമീകരിക്കാൻ കഴിയുന്ന പാരാമീറ്ററുകൾ നിങ്ങൾ വ്യക്തമാക്കും.
- ഇഷ്ടാനുസൃത ഇൻപുട്ടും ഔട്ട്പുട്ട് ലോജിക്കും നിർവചിക്കുക - ഡൗൺസ്ട്രീം ആപ്ലിക്കേഷനുകളുമായുള്ള സുഗമമായ സംയോജനത്തിന് വ്യക്തവും ഇഷ്ടാനുസൃതമാക്കിയതുമായ ഇൻപുട്ട്/ഔട്ട്പുട്ട് ഫോർമാറ്റുകൾ സ്ഥാപിക്കേണ്ടത് അത്യാവശ്യമാണ്. അത്തരത്തിലുള്ള ഒരു ആപ്ലിക്കേഷനാണ് JupyterAI, അത് ഞങ്ങൾ തുടർന്നുള്ള വിഭാഗത്തിൽ ചർച്ച ചെയ്യുന്നു.
കൂടാതെ, ഞങ്ങൾ ഒരു ഉൾപ്പെടുന്നു serving.properties ഫയൽ, DJL സെർവിംഗ് ഉപയോഗിച്ച് ഹോസ്റ്റ് ചെയ്ത മോഡലുകൾക്കുള്ള ആഗോള കോൺഫിഗറേഷൻ ഫയലായി വർത്തിക്കുന്നു. കൂടുതൽ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക കോൺഫിഗറേഷനുകളും ക്രമീകരണങ്ങളും.
അവസാനമായി, നിങ്ങൾക്ക് എയും ഉൾപ്പെടുത്താം requirements.txt അനുമാനത്തിന് ആവശ്യമായ അധിക മൊഡ്യൂളുകൾ നിർവചിക്കുന്നതിനുള്ള ഫയൽ, വിന്യാസത്തിനായി എല്ലാം ടാർബോളിലേക്ക് പാക്കേജുചെയ്യുക.
ഇനിപ്പറയുന്ന കോഡ് കാണുക:
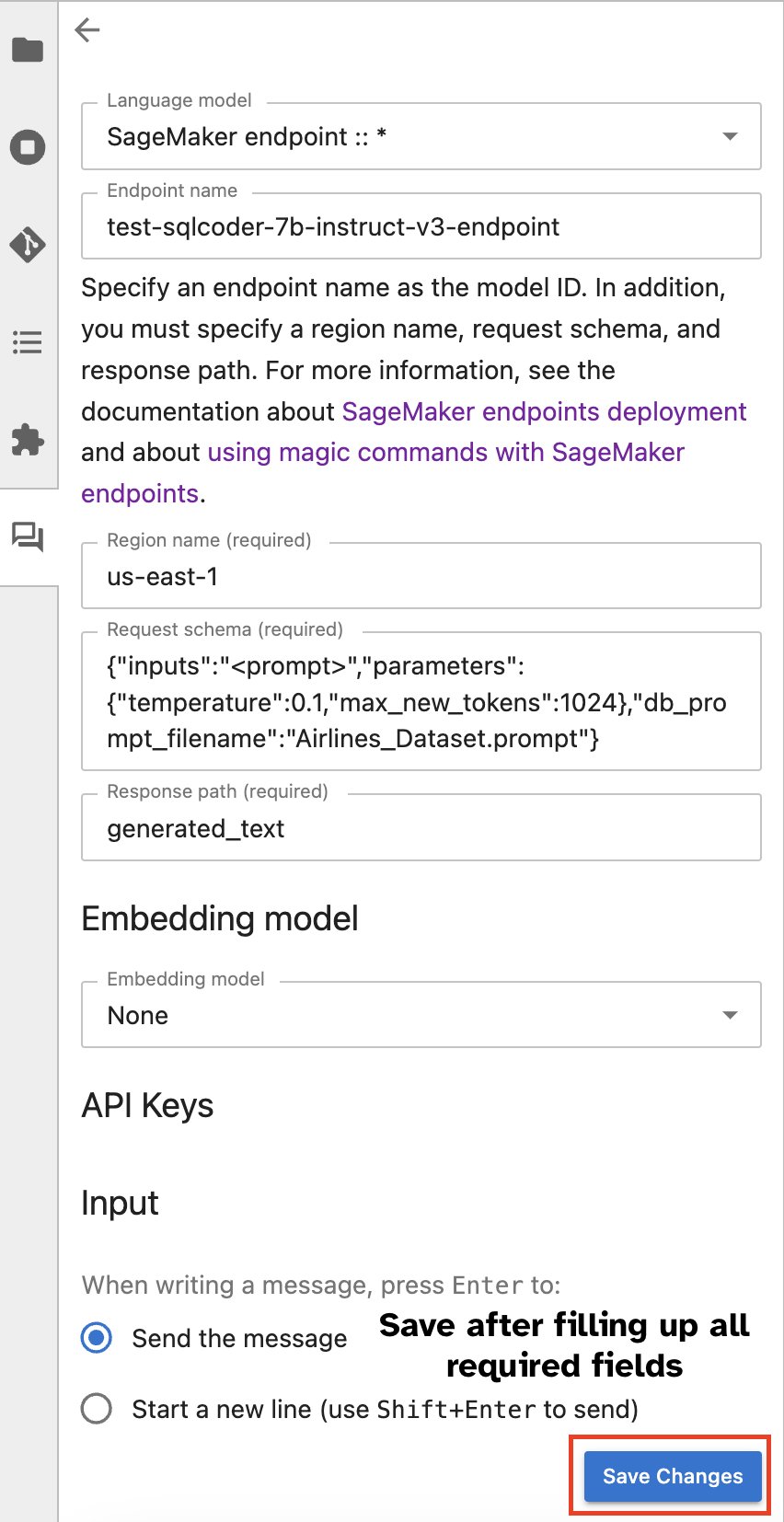
SageMaker Studio Jupyter AI അസിസ്റ്റൻ്റുമായി നിങ്ങളുടെ എൻഡ്പോയിൻ്റ് സമന്വയിപ്പിക്കുക
ജൂപ്പിറ്റർ AI ജെനറേറ്റീവ് AI മോഡലുകൾ പര്യവേക്ഷണം ചെയ്യുന്നതിനായി ശക്തവും ഉപയോക്തൃ-സൗഹൃദവുമായ പ്ലാറ്റ്ഫോം വാഗ്ദാനം ചെയ്യുന്ന, ജൂപ്പിറ്റർ നോട്ട്ബുക്കുകളിലേക്ക് ജനറേറ്റീവ് AI കൊണ്ടുവരുന്ന ഒരു ഓപ്പൺ സോഴ്സ് ടൂളാണ്. നോട്ട്ബുക്കുകൾക്കുള്ളിൽ ജനറേറ്റീവ് AI കളിസ്ഥലം സൃഷ്ടിക്കുന്നതിനുള്ള %%ai മാജിക്, ഒരു സംഭാഷണ സഹായിയായി AI-യുമായി സംവദിക്കുന്നതിന് JupyterLab-ലെ ഒരു നേറ്റീവ് ചാറ്റ് UI, കൂടാതെ LLM-കൾക്കുള്ള പിന്തുണ എന്നിവ പോലുള്ള സവിശേഷതകൾ നൽകിക്കൊണ്ട് JupyterLab, Jupyter നോട്ട്ബുക്കുകളിൽ ഇത് ഉൽപ്പാദനക്ഷമത വർദ്ധിപ്പിക്കുന്നു. ദാതാക്കൾ ഇഷ്ടപ്പെടുന്നു ആമസോൺ ടൈറ്റൻ, AI21, ആന്ത്രോപിക്, കോഹെർ, ഹഗ്ഗിംഗ് ഫേസ് അല്ലെങ്കിൽ നിയന്ത്രിത സേവനങ്ങൾ ആമസോൺ ബെഡ്റോക്ക് കൂടാതെ സേജ് മേക്കർ എൻഡ് പോയിൻ്റുകളും. ഈ പോസ്റ്റിനായി, ജൂപ്പിറ്റർ ലാബ് നോട്ട്ബുക്കുകളിലേക്ക് ടെക്സ്റ്റ്-ടു-എസ്ക്യുഎൽ ശേഷി കൊണ്ടുവരാൻ സേജ് മേക്കർ എൻഡ്പോയിൻ്റുകളുമായുള്ള ജൂപ്പിറ്റർ എഐയുടെ ഔട്ട്-ഓഫ്-ദി-ബോക്സ് ഇൻ്റഗ്രേഷൻ ഞങ്ങൾ ഉപയോഗിക്കുന്നു. ജൂപ്പിറ്റർ എഐ ടൂൾ എല്ലാ സേജ് മേക്കർ സ്റ്റുഡിയോ ജൂപ്പിറ്റർ ലാബ് സ്പേസുകളിലും മുൻകൂട്ടി ഇൻസ്റ്റാൾ ചെയ്തിട്ടുണ്ട്. സേജ് മേക്കർ വിതരണ ചിത്രങ്ങൾ; ഒരു SageMaker ഹോസ്റ്റ് ചെയ്ത എൻഡ്പോയിൻ്റുമായി സംയോജിപ്പിക്കുന്നതിന് Jupyter AI വിപുലീകരണം ഉപയോഗിച്ച് ആരംഭിക്കുന്നതിന് അന്തിമ ഉപയോക്താക്കൾ അധിക കോൺഫിഗറേഷനുകളൊന്നും നടത്തേണ്ടതില്ല. ഈ വിഭാഗത്തിൽ, സംയോജിത ജൂപ്പിറ്റർ AI ടൂൾ ഉപയോഗിക്കുന്നതിനുള്ള രണ്ട് വഴികൾ ഞങ്ങൾ ചർച്ച ചെയ്യുന്നു.
ജാലവിദ്യകൾ ഉപയോഗിച്ച് ഒരു നോട്ട്ബുക്കിനുള്ളിൽ ജൂപ്പിറ്റർ AI
ജൂപ്പിറ്റർ എഐയുടെ %%ai നിങ്ങളുടെ SageMaker Studio JupyterLab നോട്ട്ബുക്കുകളെ പുനരുൽപ്പാദിപ്പിക്കാവുന്ന AI പരിതസ്ഥിതിയിലേക്ക് മാറ്റാൻ മാജിക് കമാൻഡ് നിങ്ങളെ അനുവദിക്കുന്നു. AI മാജിക്കുകൾ ഉപയോഗിക്കാൻ തുടങ്ങുന്നതിന്, നിങ്ങൾ ഉപയോഗിക്കാനായി jupyter_ai_magics എക്സ്റ്റൻഷൻ ലോഡ് ചെയ്തിട്ടുണ്ടെന്ന് ഉറപ്പാക്കുക. %%ai മാജിക്, കൂടാതെ അധികമായി ലോഡ് ചെയ്യുക amazon_sagemaker_sql_magic ഉപയോഗിക്കാൻ %%sm_sql ജാലവിദ്യ:
ഉപയോഗിച്ച് നിങ്ങളുടെ നോട്ട്ബുക്കിൽ നിന്ന് നിങ്ങളുടെ SageMaker എൻഡ്പോയിൻ്റിലേക്ക് ഒരു കോൾ റൺ ചെയ്യാൻ %%ai മാജിക് കമാൻഡ്, ഇനിപ്പറയുന്ന പാരാമീറ്ററുകൾ നൽകുകയും കമാൻഡ് ഇനിപ്പറയുന്ന രീതിയിൽ ക്രമീകരിക്കുകയും ചെയ്യുക:
- -മേഖല-പേര് - നിങ്ങളുടെ അവസാന പോയിൻ്റ് വിന്യസിച്ചിരിക്കുന്ന പ്രദേശം വ്യക്തമാക്കുക. അഭ്യർത്ഥന ശരിയായ ഭൂമിശാസ്ത്രപരമായ ലൊക്കേഷനിലേക്കാണെന്ന് ഇത് ഉറപ്പാക്കുന്നു.
- -അഭ്യർത്ഥന-സ്കീമ - ഇൻപുട്ട് ഡാറ്റയുടെ സ്കീമ ഉൾപ്പെടുത്തുക. അഭ്യർത്ഥന പ്രോസസ്സ് ചെയ്യുന്നതിന് നിങ്ങളുടെ മോഡലിന് ആവശ്യമായ ഇൻപുട്ട് ഡാറ്റയുടെ പ്രതീക്ഷിക്കുന്ന ഫോർമാറ്റും തരങ്ങളും ഈ സ്കീമ വിവരിക്കുന്നു.
- - പ്രതികരണ പാത - നിങ്ങളുടെ മോഡലിൻ്റെ ഔട്ട്പുട്ട് സ്ഥിതി ചെയ്യുന്ന പ്രതികരണ ഒബ്ജക്റ്റിനുള്ളിലെ പാത നിർവചിക്കുക. നിങ്ങളുടെ മോഡൽ നൽകുന്ന പ്രതികരണത്തിൽ നിന്ന് പ്രസക്തമായ ഡാറ്റ എക്സ്ട്രാക്റ്റുചെയ്യാൻ ഈ പാത ഉപയോഗിക്കുന്നു.
- -f (ഓപ്ഷണൽ) - ഇതൊരു ഔട്ട്പുട്ട് ഫോർമാറ്റർ മോഡൽ നൽകുന്ന ഔട്ട്പുട്ടിൻ്റെ തരം സൂചിപ്പിക്കുന്ന ഫ്ലാഗ്. ജൂപ്പിറ്റർ നോട്ട്ബുക്കിൻ്റെ സന്ദർഭത്തിൽ, ഔട്ട്പുട്ട് കോഡ് ആണെങ്കിൽ, ജൂപ്പിറ്റർ നോട്ട്ബുക്ക് സെല്ലിൻ്റെ മുകളിൽ എക്സിക്യൂട്ടബിൾ കോഡായി ഔട്ട്പുട്ടിനെ ഫോർമാറ്റ് ചെയ്യുന്നതിനായി ഈ ഫ്ലാഗ് സജ്ജീകരിക്കണം, തുടർന്ന് ഉപയോക്തൃ ഇടപെടലിനായി ഒരു സൗജന്യ ടെക്സ്റ്റ് ഇൻപുട്ട് ഏരിയ.
ഉദാഹരണത്തിന്, ജൂപ്പിറ്റർ നോട്ട്ബുക്ക് സെല്ലിലെ കമാൻഡ് ഇനിപ്പറയുന്ന കോഡ് പോലെയായിരിക്കാം:
Jupyter AI ചാറ്റ് വിൻഡോ
പകരമായി, നിങ്ങൾക്ക് ഒരു അന്തർനിർമ്മിത ഉപയോക്തൃ ഇൻ്റർഫേസിലൂടെ സേജ് മേക്കർ എൻഡ് പോയിൻ്റുകളുമായി സംവദിക്കാം, ചോദ്യങ്ങൾ സൃഷ്ടിക്കുന്ന പ്രക്രിയ ലളിതമാക്കുകയോ സംഭാഷണത്തിൽ ഏർപ്പെടുകയോ ചെയ്യാം. നിങ്ങളുടെ SageMaker എൻഡ്പോയിൻ്റുമായി ചാറ്റ് ചെയ്യാൻ തുടങ്ങുന്നതിനുമുമ്പ്, ഇനിപ്പറയുന്ന സ്ക്രീൻഷോട്ടിൽ കാണിച്ചിരിക്കുന്നതുപോലെ, SageMaker എൻഡ്പോയിൻ്റിനായി Jupyter AI-യിൽ പ്രസക്തമായ ക്രമീകരണങ്ങൾ കോൺഫിഗർ ചെയ്യുക.
 |
 |
തീരുമാനം
ജൂപ്പിറ്റർ ലാബ് നോട്ട്ബുക്കുകളിലേക്ക് SQL പിന്തുണ സമന്വയിപ്പിച്ചുകൊണ്ട് SageMaker സ്റ്റുഡിയോ ഇപ്പോൾ ഡാറ്റാ സയൻ്റിസ്റ്റ് വർക്ക്ഫ്ലോ ലളിതമാക്കുകയും കാര്യക്ഷമമാക്കുകയും ചെയ്യുന്നു. ഒന്നിലധികം ടൂളുകൾ കൈകാര്യം ചെയ്യാതെ തന്നെ തങ്ങളുടെ ജോലികളിൽ ശ്രദ്ധ കേന്ദ്രീകരിക്കാൻ ഇത് ഡാറ്റ ശാസ്ത്രജ്ഞരെ അനുവദിക്കുന്നു. കൂടാതെ, SageMaker സ്റ്റുഡിയോയിലെ പുതിയ അന്തർനിർമ്മിത SQL സംയോജനം, സ്വാഭാവിക ഭാഷാ ടെക്സ്റ്റ് ഇൻപുട്ടായി ഉപയോഗിച്ച് SQL അന്വേഷണങ്ങൾ അനായാസമായി ജനറേറ്റുചെയ്യാൻ ഡാറ്റ വ്യക്തികളെ പ്രാപ്തമാക്കുന്നു, അതുവഴി അവയുടെ വർക്ക്ഫ്ലോ ത്വരിതപ്പെടുത്തുന്നു.
SageMaker സ്റ്റുഡിയോയിൽ ഈ സവിശേഷതകൾ പര്യവേക്ഷണം ചെയ്യാൻ ഞങ്ങൾ നിങ്ങളെ പ്രോത്സാഹിപ്പിക്കുന്നു. കൂടുതൽ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക സ്റ്റുഡിയോയിൽ SQL ഉപയോഗിച്ച് ഡാറ്റ തയ്യാറാക്കുക.
അനുബന്ധം
ഇഷ്ടാനുസൃത പരിതസ്ഥിതികളിൽ SQL ബ്രൗസറും നോട്ട്ബുക്ക് SQL സെല്ലും പ്രവർത്തനക്ഷമമാക്കുക
നിങ്ങൾ ഒരു SageMaker വിതരണ ചിത്രം ഉപയോഗിക്കുന്നില്ലെങ്കിലോ 1.5 അല്ലെങ്കിൽ അതിൽ താഴെയുള്ള വിതരണ ചിത്രങ്ങൾ ഉപയോഗിക്കുന്നില്ലെങ്കിലോ, നിങ്ങളുടെ JupyterLab പരിതസ്ഥിതിയിൽ SQL ബ്രൗസിംഗ് സവിശേഷത പ്രവർത്തനക്ഷമമാക്കാൻ ഇനിപ്പറയുന്ന കമാൻഡുകൾ പ്രവർത്തിപ്പിക്കുക:
SQL ബ്രൗസർ വിജറ്റ് മാറ്റിസ്ഥാപിക്കുക
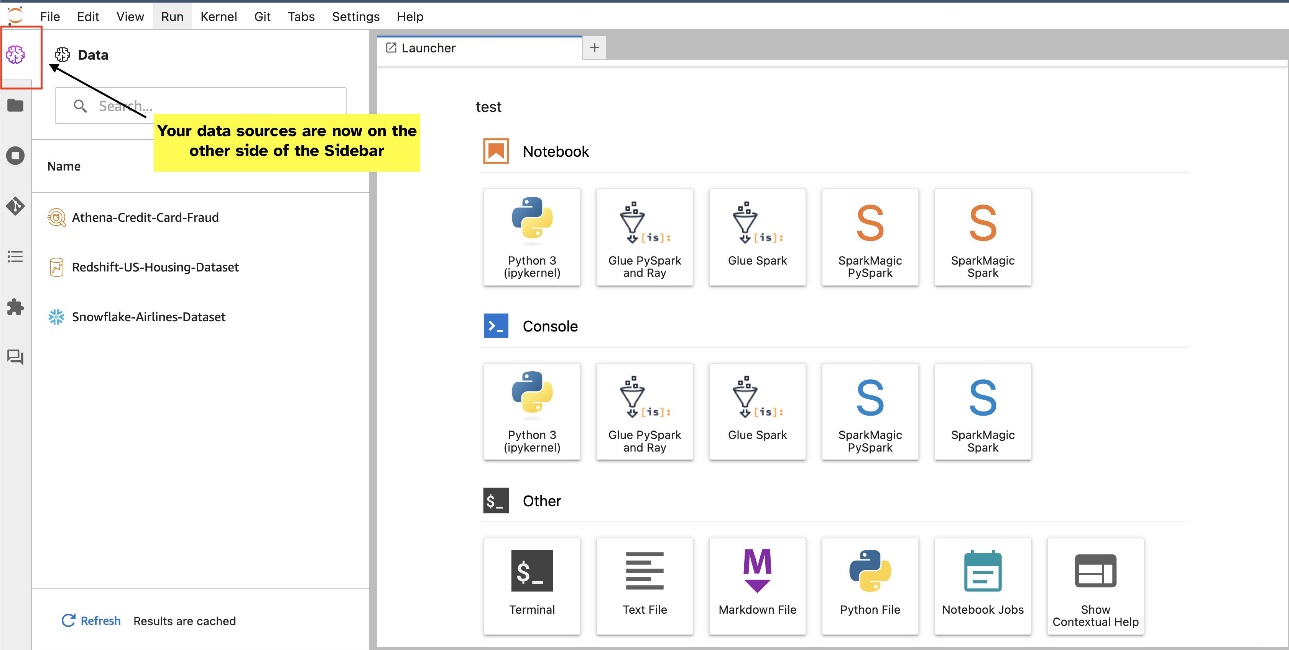
JupyterLab വിജറ്റുകൾ സ്ഥലം മാറ്റാൻ അനുവദിക്കുന്നു. നിങ്ങളുടെ മുൻഗണന അനുസരിച്ച്, JupyterLab വിജറ്റ് പാളിയുടെ ഇരുവശങ്ങളിലേക്കും നിങ്ങൾക്ക് വിജറ്റുകൾ നീക്കാനാകും. നിങ്ങൾക്ക് താൽപ്പര്യമുണ്ടെങ്കിൽ, വിജറ്റ് ഐക്കണിൽ ലളിതമായ വലത്-ക്ലിക്കുചെയ്ത് തിരഞ്ഞെടുക്കുന്നതിലൂടെ നിങ്ങൾക്ക് SQL വിജറ്റിൻ്റെ ദിശ സൈഡ്ബാറിൻ്റെ എതിർ വശത്തേക്ക് (വലത്തുനിന്ന് ഇടത്തേക്ക്) നീക്കാം. സൈഡ്ബാർ സൈഡ് മാറുക.
 |
 |
രചയിതാക്കളെക്കുറിച്ച്
 പ്രണവ് മൂർത്തി AWS-ലെ AI/ML സ്പെഷ്യലിസ്റ്റ് സൊല്യൂഷൻസ് ആർക്കിടെക്റ്റാണ്. മെഷീൻ ലേണിംഗ് (ML) ജോലിഭാരം SageMaker-ലേക്ക് നിർമ്മിക്കാനും പരിശീലിപ്പിക്കാനും വിന്യസിക്കാനും മൈഗ്രേറ്റ് ചെയ്യാനും ഉപഭോക്താക്കളെ സഹായിക്കുന്നതിൽ അദ്ദേഹം ശ്രദ്ധ കേന്ദ്രീകരിക്കുന്നു. അത്യാധുനിക ML ടെക്നിക്കുകൾ ഉപയോഗിച്ച് അർദ്ധചാലക പ്രക്രിയകൾ മെച്ചപ്പെടുത്തുന്നതിനായി വലിയ കമ്പ്യൂട്ടർ വിഷൻ (CV), നാച്ചുറൽ ലാംഗ്വേജ് പ്രോസസ്സിംഗ് (NLP) മോഡലുകൾ വികസിപ്പിക്കുന്ന അർദ്ധചാലക വ്യവസായത്തിൽ അദ്ദേഹം മുമ്പ് പ്രവർത്തിച്ചിട്ടുണ്ട്. ഒഴിവുസമയങ്ങളിൽ ചെസ്സ് കളിക്കാനും യാത്ര ചെയ്യാനും അവൻ ഇഷ്ടപ്പെടുന്നു. നിങ്ങൾക്ക് പ്രണവിനെ കണ്ടെത്താം ലിങ്ക്ഡ്.
പ്രണവ് മൂർത്തി AWS-ലെ AI/ML സ്പെഷ്യലിസ്റ്റ് സൊല്യൂഷൻസ് ആർക്കിടെക്റ്റാണ്. മെഷീൻ ലേണിംഗ് (ML) ജോലിഭാരം SageMaker-ലേക്ക് നിർമ്മിക്കാനും പരിശീലിപ്പിക്കാനും വിന്യസിക്കാനും മൈഗ്രേറ്റ് ചെയ്യാനും ഉപഭോക്താക്കളെ സഹായിക്കുന്നതിൽ അദ്ദേഹം ശ്രദ്ധ കേന്ദ്രീകരിക്കുന്നു. അത്യാധുനിക ML ടെക്നിക്കുകൾ ഉപയോഗിച്ച് അർദ്ധചാലക പ്രക്രിയകൾ മെച്ചപ്പെടുത്തുന്നതിനായി വലിയ കമ്പ്യൂട്ടർ വിഷൻ (CV), നാച്ചുറൽ ലാംഗ്വേജ് പ്രോസസ്സിംഗ് (NLP) മോഡലുകൾ വികസിപ്പിക്കുന്ന അർദ്ധചാലക വ്യവസായത്തിൽ അദ്ദേഹം മുമ്പ് പ്രവർത്തിച്ചിട്ടുണ്ട്. ഒഴിവുസമയങ്ങളിൽ ചെസ്സ് കളിക്കാനും യാത്ര ചെയ്യാനും അവൻ ഇഷ്ടപ്പെടുന്നു. നിങ്ങൾക്ക് പ്രണവിനെ കണ്ടെത്താം ലിങ്ക്ഡ്.
 വരുൺ ഷാ ആമസോൺ വെബ് സേവനങ്ങളിലെ ആമസോൺ സേജ് മേക്കർ സ്റ്റുഡിയോയിൽ പ്രവർത്തിക്കുന്ന ഒരു സോഫ്റ്റ്വെയർ എഞ്ചിനീയറാണ്. ഡാറ്റ പ്രോസസ്സിംഗും ഡാറ്റ തയ്യാറാക്കൽ യാത്രകളും ലളിതമാക്കുന്ന ഇൻ്ററാക്ടീവ് ML സൊല്യൂഷനുകൾ നിർമ്മിക്കുന്നതിൽ അദ്ദേഹം ശ്രദ്ധ കേന്ദ്രീകരിച്ചിരിക്കുന്നു. തൻ്റെ ഒഴിവുസമയങ്ങളിൽ, വരുൺ ഹൈക്കിംഗും സ്കീയിംഗും ഉൾപ്പെടെയുള്ള ഔട്ട്ഡോർ ആക്റ്റിവിറ്റികൾ ആസ്വദിക്കുന്നു, ഒപ്പം പുതിയതും ആവേശകരവുമായ സ്ഥലങ്ങൾ കണ്ടെത്തുന്നതിന് എപ്പോഴും തയ്യാറാണ്.
വരുൺ ഷാ ആമസോൺ വെബ് സേവനങ്ങളിലെ ആമസോൺ സേജ് മേക്കർ സ്റ്റുഡിയോയിൽ പ്രവർത്തിക്കുന്ന ഒരു സോഫ്റ്റ്വെയർ എഞ്ചിനീയറാണ്. ഡാറ്റ പ്രോസസ്സിംഗും ഡാറ്റ തയ്യാറാക്കൽ യാത്രകളും ലളിതമാക്കുന്ന ഇൻ്ററാക്ടീവ് ML സൊല്യൂഷനുകൾ നിർമ്മിക്കുന്നതിൽ അദ്ദേഹം ശ്രദ്ധ കേന്ദ്രീകരിച്ചിരിക്കുന്നു. തൻ്റെ ഒഴിവുസമയങ്ങളിൽ, വരുൺ ഹൈക്കിംഗും സ്കീയിംഗും ഉൾപ്പെടെയുള്ള ഔട്ട്ഡോർ ആക്റ്റിവിറ്റികൾ ആസ്വദിക്കുന്നു, ഒപ്പം പുതിയതും ആവേശകരവുമായ സ്ഥലങ്ങൾ കണ്ടെത്തുന്നതിന് എപ്പോഴും തയ്യാറാണ്.
 സുമേധ സ്വാമി ആമസോൺ വെബ് സേവനങ്ങളിലെ പ്രിൻസിപ്പൽ പ്രൊഡക്റ്റ് മാനേജരാണ്, അവിടെ അദ്ദേഹം ഡാറ്റാ സയൻസിനും മെഷീൻ ലേണിംഗിനും ഇഷ്ടമുള്ള IDE വികസിപ്പിക്കാനുള്ള ദൗത്യത്തിൽ സേജ് മേക്കർ സ്റ്റുഡിയോ ടീമിനെ നയിക്കുന്നു. കഴിഞ്ഞ 15 വർഷമായി മെഷീൻ ലേണിംഗ് അടിസ്ഥാനമാക്കിയുള്ള ഉപഭോക്തൃ, എൻ്റർപ്രൈസ് ഉൽപ്പന്നങ്ങൾ നിർമ്മിക്കാൻ അദ്ദേഹം സമർപ്പിച്ചു.
സുമേധ സ്വാമി ആമസോൺ വെബ് സേവനങ്ങളിലെ പ്രിൻസിപ്പൽ പ്രൊഡക്റ്റ് മാനേജരാണ്, അവിടെ അദ്ദേഹം ഡാറ്റാ സയൻസിനും മെഷീൻ ലേണിംഗിനും ഇഷ്ടമുള്ള IDE വികസിപ്പിക്കാനുള്ള ദൗത്യത്തിൽ സേജ് മേക്കർ സ്റ്റുഡിയോ ടീമിനെ നയിക്കുന്നു. കഴിഞ്ഞ 15 വർഷമായി മെഷീൻ ലേണിംഗ് അടിസ്ഥാനമാക്കിയുള്ള ഉപഭോക്തൃ, എൻ്റർപ്രൈസ് ഉൽപ്പന്നങ്ങൾ നിർമ്മിക്കാൻ അദ്ദേഹം സമർപ്പിച്ചു.
 ബോസ്കോ അൽബുക്കർക് AWS-ലെ ഒരു സീനിയർ പാർട്ണർ സൊല്യൂഷൻസ് ആർക്കിടെക്റ്റാണ്, കൂടാതെ എന്റർപ്രൈസ് ഡാറ്റാബേസ് വെണ്ടർമാരിൽ നിന്നും ക്ലൗഡ് ദാതാക്കളിൽ നിന്നുമുള്ള ഡാറ്റാബേസ്, അനലിറ്റിക്സ് ഉൽപ്പന്നങ്ങളുമായി 20 വർഷത്തിലേറെ പരിചയമുണ്ട്. ഡാറ്റാ അനലിറ്റിക്സ് സൊല്യൂഷനുകളും ഉൽപ്പന്നങ്ങളും രൂപകൽപ്പന ചെയ്യാനും നടപ്പിലാക്കാനും സാങ്കേതിക കമ്പനികളെ അദ്ദേഹം സഹായിച്ചിട്ടുണ്ട്.
ബോസ്കോ അൽബുക്കർക് AWS-ലെ ഒരു സീനിയർ പാർട്ണർ സൊല്യൂഷൻസ് ആർക്കിടെക്റ്റാണ്, കൂടാതെ എന്റർപ്രൈസ് ഡാറ്റാബേസ് വെണ്ടർമാരിൽ നിന്നും ക്ലൗഡ് ദാതാക്കളിൽ നിന്നുമുള്ള ഡാറ്റാബേസ്, അനലിറ്റിക്സ് ഉൽപ്പന്നങ്ങളുമായി 20 വർഷത്തിലേറെ പരിചയമുണ്ട്. ഡാറ്റാ അനലിറ്റിക്സ് സൊല്യൂഷനുകളും ഉൽപ്പന്നങ്ങളും രൂപകൽപ്പന ചെയ്യാനും നടപ്പിലാക്കാനും സാങ്കേതിക കമ്പനികളെ അദ്ദേഹം സഹായിച്ചിട്ടുണ്ട്.
- SEO പവർ ചെയ്ത ഉള്ളടക്കവും PR വിതരണവും. ഇന്ന് ആംപ്ലിഫൈഡ് നേടുക.
- PlatoData.Network ലംബ ജനറേറ്റീവ് Ai. സ്വയം ശാക്തീകരിക്കുക. ഇവിടെ പ്രവേശിക്കുക.
- PlatoAiStream. Web3 ഇന്റലിജൻസ്. വിജ്ഞാനം വർധിപ്പിച്ചു. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോഇഎസ്ജി. കാർബൺ, ക്ലീൻ ടെക്, ഊർജ്ജം, പരിസ്ഥിതി, സോളാർ, മാലിന്യ സംസ്കരണം. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോ ഹെൽത്ത്. ബയോടെക് ആൻഡ് ക്ലിനിക്കൽ ട്രയൽസ് ഇന്റലിജൻസ്. ഇവിടെ പ്രവേശിക്കുക.
- അവലംബം: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

