នៅក្នុងការគ្រប់គ្រងទ្រព្យសកម្ម អ្នកគ្រប់គ្រងផលប័ត្រត្រូវតាមដានយ៉ាងដិតដល់នូវក្រុមហ៊ុននៅក្នុងសកលលោកនៃការវិនិយោគរបស់ពួកគេដើម្បីកំណត់ហានិភ័យ និងឱកាស និងណែនាំការសម្រេចចិត្តវិនិយោគ។ ការតាមដានព្រឹត្តិការណ៍ដោយផ្ទាល់ដូចជារបាយការណ៍ប្រាក់ចំណូល ឬការបន្ទាបចំណាត់ថ្នាក់ឥណទានគឺត្រង់ - អ្នកអាចរៀបចំការជូនដំណឹងដើម្បីជូនដំណឹងដល់អ្នកគ្រប់គ្រងអំពីព័ត៌មានដែលមានឈ្មោះក្រុមហ៊ុន។ ទោះជាយ៉ាងណាក៏ដោយ ការរកឃើញផលប៉ះពាល់លំដាប់ទីពីរ និងទីបីដែលកើតឡើងពីព្រឹត្តិការណ៍នៅឯអ្នកផ្គត់ផ្គង់ អតិថិជន ដៃគូ ឬអង្គភាពផ្សេងទៀតនៅក្នុងប្រព័ន្ធអេកូរបស់ក្រុមហ៊ុនគឺមានបញ្ហាប្រឈម។
ជាឧទាហរណ៍ ការរអាក់រអួលនៃសង្វាក់ផ្គត់ផ្គង់របស់អ្នកលក់សំខាន់ទំនងជានឹងជះឥទ្ធិពលអវិជ្ជមានដល់ក្រុមហ៊ុនផលិតនៅខាងក្រោម។ ឬការបាត់បង់អតិថិជនកំពូលសម្រាប់អតិថិជនធំ បង្កហានិភ័យតម្រូវការសម្រាប់អ្នកផ្គត់ផ្គង់។ ជាញឹកញាប់ណាស់ ព្រឹត្តិការណ៍បែបនេះបរាជ័យក្នុងការបង្កើតចំណងជើងដែលបង្ហាញពីក្រុមហ៊ុនដែលរងផលប៉ះពាល់ដោយផ្ទាល់ ប៉ុន្តែនៅតែមានសារៈសំខាន់ក្នុងការយកចិត្តទុកដាក់។ នៅក្នុងការប្រកាសនេះ យើងបង្ហាញពីដំណោះស្រាយស្វ័យប្រវត្តិដែលរួមបញ្ចូលគ្នានូវក្រាហ្វចំណេះដឹង និង បញ្ញាសិប្បនិមិត្ត (AI) ដើម្បីបង្ហាញហានិភ័យបែបនេះដោយផែនទីទំនាក់ទំនងឆ្លងយោងជាមួយព័ត៌មានពេលវេលាពិត។
ជាទូទៅ វារួមបញ្ចូលពីរជំហាន៖ ទីមួយ ការកសាងទំនាក់ទំនងដ៏ស្មុគ្រស្មាញរវាងក្រុមហ៊ុន (អតិថិជន អ្នកផ្គត់ផ្គង់ នាយក) ទៅក្នុងក្រាហ្វចំណេះដឹង។ ទីពីរ ការប្រើប្រាស់មូលដ្ឋានទិន្នន័យក្រាហ្វនេះ រួមជាមួយនឹង AI ជំនាន់ថ្មី ដើម្បីរកមើលផលប៉ះពាល់លំដាប់ទីពីរ និងទីបីពីព្រឹត្តិការណ៍ព័ត៌មាន។ ជាឧទាហរណ៍ ដំណោះស្រាយនេះអាចបញ្ជាក់បានថាការពន្យារពេលរបស់អ្នកផ្គត់ផ្គង់គ្រឿងបន្លាស់អាចរំខានដល់ការផលិតសម្រាប់ក្រុមហ៊ុនផលិតរថយន្តខាងក្រោមនៅក្នុងផលប័ត្រ ទោះបីជាមិនមានការយោងដោយផ្ទាល់ក៏ដោយ។
ជាមួយ AWS អ្នកអាចដាក់ឱ្យប្រើប្រាស់ដំណោះស្រាយនេះនៅក្នុងស្ថាបត្យកម្មគ្មានម៉ាស៊ីនមេ ធ្វើមាត្រដ្ឋាន និងដំណើរការដោយព្រឹត្តិការណ៍យ៉ាងពេញលេញ។ ការបង្ហោះនេះបង្ហាញពីភ័ស្តុតាងនៃគំនិតដែលបានបង្កើតឡើងនៅលើសេវាកម្ម AWS សំខាន់ៗចំនួនពីរដែលស័ក្តិសមសម្រាប់តំណាងចំណេះដឹងក្រាហ្វ និងដំណើរការភាសាធម្មជាតិ៖ អាម៉ាហ្សូន Neptune និង ក្រុមហ៊ុន Amazon Bedrock. Neptune គឺជាសេវាកម្មមូលដ្ឋានទិន្នន័យក្រាហ្វដែលគ្រប់គ្រងយ៉ាងពេញលេញ រហ័ស គួរឱ្យទុកចិត្ត ដែលធ្វើឱ្យវាមានភាពសាមញ្ញក្នុងការបង្កើត និងដំណើរការកម្មវិធីដែលដំណើរការជាមួយសំណុំទិន្នន័យដែលមានការតភ្ជាប់ខ្ពស់។ Amazon Bedrock គឺជាសេវាកម្មគ្រប់គ្រងពេញលេញដែលផ្តល់នូវជម្រើសនៃគំរូគ្រឹះដែលដំណើរការខ្ពស់ (FMs) ពីក្រុមហ៊ុន AI ឈានមុខគេដូចជា AI21 Labs, Anthropic, Cohere, Meta, Stability AI និង Amazon តាមរយៈ API តែមួយ រួមជាមួយនឹងសំណុំទូលំទូលាយនៃ សមត្ថភាពបង្កើតកម្មវិធី AI ជំនាន់ថ្មីជាមួយនឹងសុវត្ថិភាព ឯកជនភាព និង AI ទទួលខុសត្រូវ។
សរុបមក គំរូនេះបង្ហាញពីសិល្បៈដែលអាចធ្វើទៅបានជាមួយនឹងក្រាហ្វចំណេះដឹង និង AI បង្កើត - ទទួលបានសញ្ញាដោយភ្ជាប់ចំណុចផ្សេងគ្នា។ Takeaway សម្រាប់អ្នកជំនាញវិនិយោគគឺជាសមត្ថភាពក្នុងការស្ថិតនៅលើកំពូលនៃការអភិវឌ្ឍន៍កាន់តែជិតទៅនឹងសញ្ញាខណៈពេលដែលជៀសវាងសំលេងរំខាន។
បង្កើតក្រាហ្វចំណេះដឹង

ជំហានដំបូងក្នុងដំណោះស្រាយនេះគឺការកសាងក្រាហ្វចំណេះដឹង ហើយប្រភពទិន្នន័យដ៏មានតម្លៃដែលជារឿយៗត្រូវបានគេមើលរំលងសម្រាប់ក្រាហ្វចំណេះដឹងគឺជារបាយការណ៍ប្រចាំឆ្នាំរបស់ក្រុមហ៊ុន។ ដោយសារការបោះពុម្ពផ្សាយសាជីវកម្មផ្លូវការឆ្លងកាត់ការត្រួតពិនិត្យមុនពេលចេញផ្សាយ ព័ត៌មានដែលពួកគេមានទំនងជាត្រឹមត្រូវ និងអាចទុកចិត្តបាន។ ទោះជាយ៉ាងណាក៏ដោយ របាយការណ៍ប្រចាំឆ្នាំត្រូវបានសរសេរក្នុងទម្រង់គ្មានរចនាសម្ព័ន្ធដែលមានន័យសម្រាប់ការអានរបស់មនុស្សជាជាងការប្រើប្រាស់ម៉ាស៊ីន។ ដើម្បីដោះសោសក្តានុពលរបស់ពួកគេ អ្នកត្រូវការវិធីមួយដើម្បីទាញយក និងរៀបចំរចនាសម្ព័ន្ធទ្រព្យសម្បត្តិនៃការពិត និងទំនាក់ទំនងដែលពួកគេមានជាប្រព័ន្ធ។
ជាមួយនឹងសេវាកម្ម AI ទូទៅដូចជា Amazon Bedrock ឥឡូវនេះអ្នកមានសមត្ថភាពក្នុងការធ្វើឱ្យដំណើរការនេះដោយស្វ័យប្រវត្តិ។ អ្នកអាចយករបាយការណ៍ប្រចាំឆ្នាំមួយ ហើយកេះបំពង់ដំណើរការដើម្បីបញ្ចូលរបាយការណ៍ បំបែកវាជាផ្នែកតូចៗ និងអនុវត្តការយល់ដឹងភាសាធម្មជាតិដើម្បីទាញចេញនូវអង្គភាព និងទំនាក់ទំនងសំខាន់ៗ។
ជាឧទាហរណ៍ ប្រយោគដែលបញ្ជាក់ថា "[ក្រុមហ៊ុន A] បានពង្រីកកងដឹកជញ្ជូនអគ្គិសនីនៅអឺរ៉ុបរបស់ខ្លួនជាមួយនឹងការបញ្ជាទិញរថយន្តអគ្គិសនីចំនួន 1,800 គ្រឿងពី [ក្រុមហ៊ុន B]" នឹងអនុញ្ញាតឱ្យក្រុមហ៊ុន Amazon Bedrock កំណត់អត្តសញ្ញាណដូចខាងក្រោម:
- [ក្រុមហ៊ុន A] ជាអតិថិជន
- [ក្រុមហ៊ុន ខ] ជាអ្នកផ្គត់ផ្គង់
- ទំនាក់ទំនងអ្នកផ្គត់ផ្គង់រវាង [ក្រុមហ៊ុន A] និង [ក្រុមហ៊ុន B]
- ព័ត៌មានលម្អិតអំពីទំនាក់ទំនង "អ្នកផ្គត់ផ្គង់រថយន្តដឹកជញ្ជូនអគ្គិសនី"
ការទាញយកទិន្នន័យដែលមានរចនាសម្ព័ន្ធបែបនេះពីឯកសារដែលមិនមានរចនាសម្ព័ន្ធតម្រូវឱ្យផ្តល់នូវការជម្រុញដែលបានបង្កើតដោយប្រុងប្រយ័ត្នចំពោះគំរូភាសាធំ (LLMs) ដូច្នេះពួកគេអាចវិភាគអត្ថបទដើម្បីទាញយកអង្គភាពដូចជាក្រុមហ៊ុន និងមនុស្ស ក៏ដូចជាទំនាក់ទំនងដូចជាអតិថិជន អ្នកផ្គត់ផ្គង់ និងអ្វីៗជាច្រើនទៀត។ ប្រអប់បញ្ចូលមានការណែនាំច្បាស់លាស់អំពីអ្វីដែលត្រូវរកមើល និងរចនាសម្ព័ន្ធដើម្បីបញ្ជូនទិន្នន័យមកវិញ។ ដោយដំណើរការនេះឡើងវិញនៅលើរបាយការណ៍ប្រចាំឆ្នាំទាំងមូល អ្នកអាចស្រង់ចេញនូវអង្គភាព និងទំនាក់ទំនងដែលពាក់ព័ន្ធដើម្បីបង្កើតក្រាហ្វចំណេះដឹងដ៏សម្បូរបែប។
ទោះជាយ៉ាងណាក៏ដោយ មុននឹងបញ្ជូនព័ត៌មានដែលបានស្រង់ចេញទៅកាន់ក្រាហ្វចំណេះដឹង អ្នកត្រូវធ្វើការបកស្រាយអំពីអង្គភាពជាមុនសិន។ ជាឧទាហរណ៍ វាអាចមានអង្គភាព '[ក្រុមហ៊ុន A]' ផ្សេងទៀតរួចហើយនៅក្នុងក្រាហ្វចំណេះដឹង ប៉ុន្តែវាអាចតំណាងឱ្យអង្គការផ្សេងដែលមានឈ្មោះដូចគ្នា។ Amazon Bedrock អាចវែកញែក និងប្រៀបធៀបគុណលក្ខណៈដូចជាតំបន់ផ្តោតលើអាជីវកម្ម ឧស្សាហកម្ម និងឧស្សាហកម្មដែលបង្កើតប្រាក់ចំណូល និងទំនាក់ទំនងទៅអង្គភាពផ្សេងទៀតដើម្បីកំណត់ថាតើអង្គភាពទាំងពីរពិតជាខុសគ្នាឬអត់។ នេះរារាំងការរួមបញ្ចូលក្រុមហ៊ុនដែលមិនពាក់ព័ន្ធដោយមិនត្រឹមត្រូវទៅក្នុងអង្គភាពតែមួយ។
បន្ទាប់ពីភាពមិនច្បាស់លាស់ត្រូវបានបញ្ចប់ អ្នកអាចបន្ថែមអង្គភាព និងទំនាក់ទំនងថ្មីៗទៅក្នុងក្រាហ្វចំណេះដឹង Neptune របស់អ្នកដោយភាពជឿជាក់ ដោយបង្កើនវាជាមួយនឹងការពិតដែលបានស្រង់ចេញពីរបាយការណ៍ប្រចាំឆ្នាំ។ យូរ ៗ ទៅការបញ្ចូលទិន្នន័យដែលអាចទុកចិត្តបាន និងការរួមបញ្ចូលប្រភពទិន្នន័យដែលអាចទុកចិត្តបានកាន់តែច្រើននឹងជួយបង្កើតក្រាហ្វចំណេះដឹងដ៏ទូលំទូលាយដែលអាចគាំទ្រការបង្ហាញការយល់ដឹងតាមរយៈសំណួរក្រាហ្វ និងការវិភាគ។
ស្វ័យប្រវត្តិកម្មនេះបានបើកដំណើរការដោយ AI ជំនាន់ថ្មីធ្វើឱ្យវាអាចដំណើរការរបាយការណ៍ប្រចាំឆ្នាំរាប់ពាន់ និងដោះសោទ្រព្យសម្បត្តិដែលមិនអាចកាត់ថ្លៃបានសម្រាប់ការរៀបចំក្រាហ្វចំណេះដឹង ដែលនឹងមិនអាចដំណើរការបានដោយសារការខិតខំប្រឹងប្រែងដោយដៃខ្ពស់ដែលចាំបាច់។
រូបថតអេក្រង់ខាងក្រោមបង្ហាញពីឧទាហរណ៍នៃការរុករកដែលមើលឃើញដែលអាចធ្វើទៅបាននៅក្នុងមូលដ្ឋានទិន្នន័យក្រាហ្វិក Neptune ដោយប្រើប្រាស់ ក្រាហ្វ Explorer ឧបករណ៍។

ដំណើរការអត្ថបទព័ត៌មាន

ជំហានបន្ទាប់នៃដំណោះស្រាយគឺការបង្កើនព័ត៌មានព័ត៌មានរបស់អ្នកគ្រប់គ្រងផលប័ត្រដោយស្វ័យប្រវត្តិ និងការរំលេចអត្ថបទដែលទាក់ទងនឹងចំណាប់អារម្មណ៍ និងការវិនិយោគរបស់ពួកគេ។ សម្រាប់ព័ត៌មាន ព័ត៌មាន អ្នកគ្រប់គ្រងផលប័ត្រអាចជាវអ្នកផ្តល់ព័ត៌មានភាគីទីបីណាមួយតាមរយៈ ការផ្លាស់ប្តូរទិន្នន័យអេ។ អេស។ អេ ឬ API ព័ត៌មានផ្សេងទៀតនៃជម្រើសរបស់ពួកគេ។
នៅពេលអត្ថបទព័ត៌មានចូលក្នុងប្រព័ន្ធ បំពង់បញ្ចូលត្រូវបានហៅឱ្យដំណើរការខ្លឹមសារ។ ដោយប្រើបច្ចេកទេសស្រដៀងគ្នាទៅនឹងដំណើរការនៃរបាយការណ៍ប្រចាំឆ្នាំ Amazon Bedrock ត្រូវបានប្រើដើម្បីទាញយកអង្គភាព គុណលក្ខណៈ និងទំនាក់ទំនងពីអត្ថបទព័ត៌មាន ដែលបន្ទាប់មកត្រូវបានប្រើដើម្បីធ្វើឱ្យអព្យាក្រឹតប្រឆាំងនឹងក្រាហ្វចំណេះដឹងដើម្បីកំណត់អត្តសញ្ញាណអង្គភាពដែលត្រូវគ្នានៅក្នុងក្រាហ្វចំណេះដឹង។
ក្រាហ្វចំណេះដឹងមានទំនាក់ទំនងរវាងក្រុមហ៊ុន និងមនុស្ស ហើយដោយការភ្ជាប់ធាតុអត្ថបទទៅនឹងថ្នាំងដែលមានស្រាប់ អ្នកអាចកំណត់ថាតើមុខវិជ្ជាណាមួយស្ថិតក្នុងរង្វង់ពីររបស់ក្រុមហ៊ុនដែលអ្នកគ្រប់គ្រងផលប័ត្របានវិនិយោគ ឬចាប់អារម្មណ៍។ ការស្វែងរកការតភ្ជាប់នេះបង្ហាញពី អត្ថបទអាចពាក់ព័ន្ធនឹងអ្នកគ្រប់គ្រងផលប័ត្រ ហើយដោយសារតែទិន្នន័យមូលដ្ឋានត្រូវបានតំណាងនៅក្នុងក្រាហ្វចំណេះដឹង វាអាចត្រូវបានគេមើលឃើញដើម្បីជួយអ្នកគ្រប់គ្រងផលប័ត្រយល់អំពីមូលហេតុ និងរបៀបដែលបរិបទនេះពាក់ព័ន្ធ។ បន្ថែមពីលើការកំណត់អត្តសញ្ញាណការតភ្ជាប់ទៅនឹងផលប័ត្រ អ្នកក៏អាចប្រើ Amazon Bedrock ដើម្បីអនុវត្តការវិភាគមនោសញ្ចេតនាលើអង្គភាពដែលបានយោងផងដែរ។
លទ្ធផលចុងក្រោយគឺជាអត្ថបទដែលបង្ហាញព័ត៌មានដែលសំបូរទៅដោយអត្ថបទដែលទំនងជាមានឥទ្ធិពលលើផ្នែកចំណាប់អារម្មណ៍ និងការវិនិយោគរបស់អ្នកគ្រប់គ្រងផលប័ត្រ។
ទិដ្ឋភាពទូទៅនៃដំណោះស្រាយ
ស្ថាបត្យកម្មរួមនៃដំណោះស្រាយមើលទៅដូចដ្យាក្រាមខាងក្រោម។
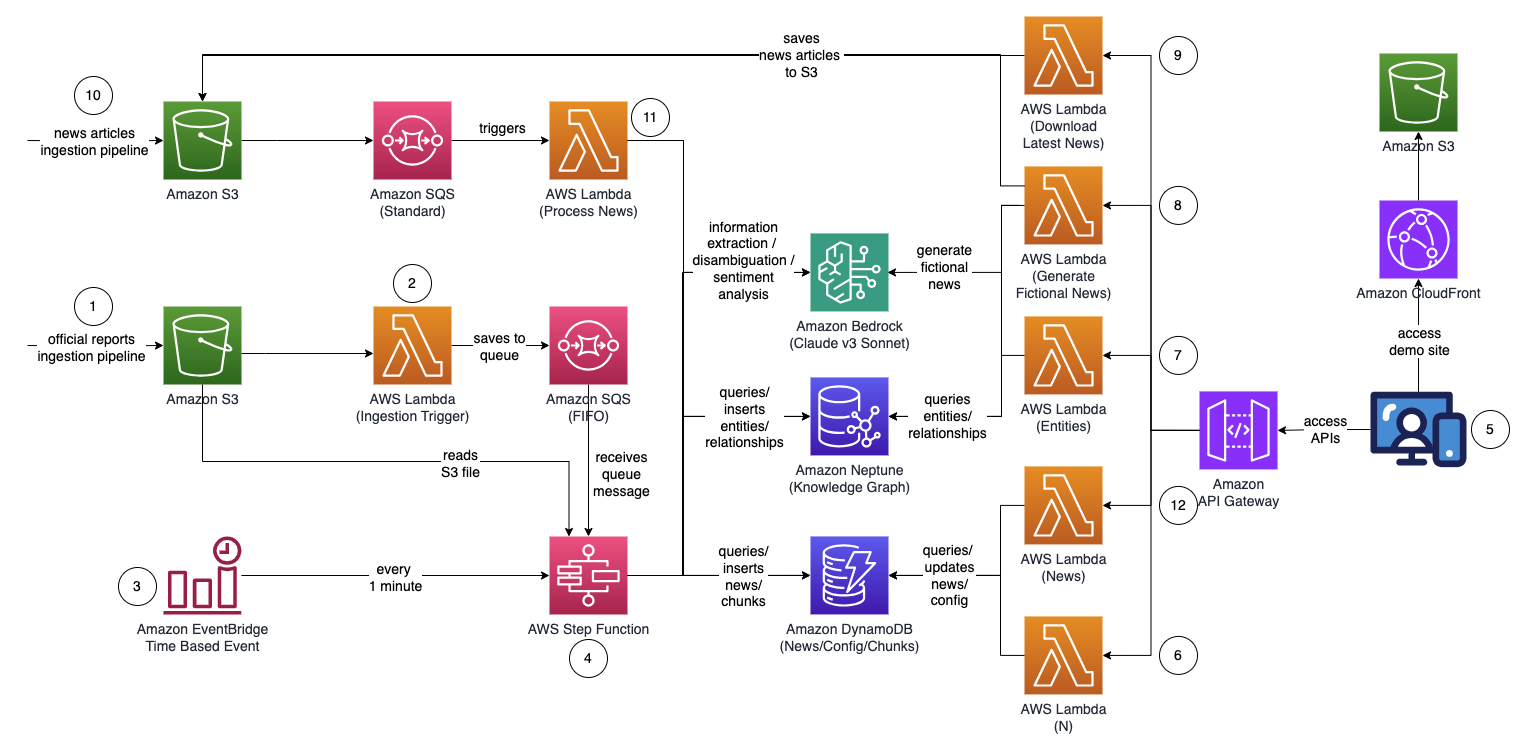
ដំណើរការការងារមានជំហានដូចខាងក្រោមៈ
- អ្នកប្រើប្រាស់បង្ហោះរបាយការណ៍ផ្លូវការ (ជាទម្រង់ PDF) ទៅ សេវាកម្មផ្ទុកសាមញ្ញរបស់ក្រុមហ៊ុន Amazon (Amazon S3) ដាក់ធុង។ របាយការណ៍គួរតែត្រូវបានបោះពុម្ពផ្សាយជាផ្លូវការដើម្បីកាត់បន្ថយការដាក់បញ្ចូលទិន្នន័យមិនត្រឹមត្រូវទៅក្នុងក្រាហ្វចំណេះដឹងរបស់អ្នក (ខុសពីព័ត៌មាន និងផ្ទាំងព័ត៌មាន)។
- ការជូនដំណឹងអំពីព្រឹត្តិការណ៍ S3 អំពាវនាវឱ្យមាន AWS Lambda មុខងារដែលផ្ញើ S3 bucket និងឈ្មោះឯកសារទៅ a សេវាកម្មជួរធម្មតារបស់ Amazon (Amazon SQS) ជួរ។ ជួរ First-in-First-Out (FIFO) ធ្វើឱ្យប្រាកដថាដំណើរការបញ្ចូលរបាយការណ៍ត្រូវបានអនុវត្តជាបន្តបន្ទាប់ ដើម្បីកាត់បន្ថយលទ្ធភាពនៃការណែនាំទិន្នន័យស្ទួនទៅក្នុងក្រាហ្វចំណេះដឹងរបស់អ្នក។
- An ក្រុមហ៊ុន Amazon EventBridge ព្រឹត្តិការណ៍ផ្អែកលើពេលវេលាដំណើរការជារៀងរាល់នាទីដើម្បីចាប់ផ្តើមដំណើរការ អនុគមន៍អេ។ អេស។ អេ ម៉ាស៊ីនរដ្ឋអសមកាល។
- Step Functions state machine ដំណើរការតាមស៊េរីនៃកិច្ចការដើម្បីដំណើរការឯកសារដែលបានផ្ទុកឡើងដោយទាញយកព័ត៌មានសំខាន់ៗ ហើយបញ្ចូលវាទៅក្នុងក្រាហ្វចំណេះដឹងរបស់អ្នក៖
- ទទួលបានសារជួរពី Amazon SQS ។
- ទាញយកឯកសាររបាយការណ៍ PDF ពី Amazon S3 បំបែកវាទៅជាបំណែកអត្ថបទតូចៗជាច្រើន (ប្រហែល 1,000 ពាក្យ) សម្រាប់ដំណើរការ ហើយរក្សាទុកកំណាត់អត្ថបទនៅក្នុង ក្រុមហ៊ុន Amazon DynamoDB.
- ប្រើ Claude v3 Sonnet របស់ Anthropic នៅលើ Amazon Bedrock ដើម្បីដំណើរការកំណាត់អត្ថបទពីរបីដំបូងដើម្បីកំណត់អង្គភាពសំខាន់ដែលរបាយការណ៍កំពុងសំដៅ រួមជាមួយនឹងគុណលក្ខណៈពាក់ព័ន្ធ (ដូចជាឧស្សាហកម្ម)។
- ទាញយកកំណាត់អត្ថបទពី DynamoDB និងសម្រាប់កំណាត់អត្ថបទនីមួយៗ ហៅមុខងារ Lambda ដើម្បីទាញយកអង្គភាព (ដូចជាក្រុមហ៊ុន ឬបុគ្គល) និងទំនាក់ទំនងរបស់វា (អតិថិជន អ្នកផ្គត់ផ្គង់ ដៃគូប្រកួតប្រជែង ឬនាយក) ទៅអង្គភាពសំខាន់ដោយប្រើ Amazon Bedrock .
- បង្រួបបង្រួមព័ត៌មានដែលបានស្រង់ចេញទាំងអស់។
- ត្រងសំឡេងរំខាន និងអង្គភាពដែលមិនពាក់ព័ន្ធ (ឧទាហរណ៍ ពាក្យទូទៅដូចជា "អ្នកប្រើប្រាស់") ដោយប្រើ Amazon Bedrock ។
- ប្រើ Amazon Bedrock ដើម្បីអនុវត្តភាពមិនច្បាស់លាស់ដោយការវែកញែកដោយប្រើព័ត៌មានដែលបានស្រង់ចេញពីបញ្ជីនៃអង្គភាពស្រដៀងគ្នាពីក្រាហ្វចំណេះដឹង។ ប្រសិនបើអង្គភាពមិនមានទេ សូមបញ្ចូលវា។ បើមិនដូច្នោះទេ សូមប្រើធាតុដែលមានរួចហើយនៅក្នុងក្រាហ្វចំណេះដឹង។ បញ្ចូលទំនាក់ទំនងទាំងអស់ដែលបានស្រង់ចេញ។
- សម្អាតដោយលុបសារជួរ SQS និងឯកសារ S3 ។
- អ្នកប្រើប្រាស់ចូលប្រើកម្មវិធីគេហទំព័រដែលមានមូលដ្ឋានលើ React ដើម្បីមើលអត្ថបទព័ត៌មានដែលត្រូវបានបំពេញបន្ថែមដោយអង្គភាព អារម្មណ៍ និងព័ត៌មានផ្លូវតភ្ជាប់។
- ដោយប្រើកម្មវិធីបណ្តាញ អ្នកប្រើប្រាស់បញ្ជាក់ចំនួន hops (លំនាំដើម N=2) នៅលើផ្លូវតភ្ជាប់ដើម្បីត្រួតពិនិត្យ។
- ដោយប្រើកម្មវិធីបណ្តាញ អ្នកប្រើប្រាស់បញ្ជាក់បញ្ជីអង្គភាពដែលត្រូវតាមដាន។
- ដើម្បីបង្កើតព័ត៌មានប្រឌិត អ្នកប្រើប្រាស់ជ្រើសរើស បង្កើតព័ត៌មានគំរូ ដើម្បីបង្កើតអត្ថបទព័ត៌មានហិរញ្ញវត្ថុគំរូចំនួន 10 ជាមួយនឹងមាតិកាចៃដន្យដែលត្រូវបញ្ចូលទៅក្នុងដំណើរការបញ្ចូលព័ត៌មាន។ ខ្លឹមសារត្រូវបានបង្កើតដោយប្រើ Amazon Bedrock និងជាការប្រឌិតសុទ្ធសាធ។
- ដើម្បីទាញយកព័ត៌មានពិត អ្នកប្រើប្រាស់ជ្រើសរើស ទាញយកព័ត៌មានថ្មីៗ ដើម្បីទាញយកព័ត៌មានសំខាន់ៗដែលកើតឡើងនៅថ្ងៃនេះ (ដំណើរការដោយ NewsAPI.org)។
- ឯកសារព័ត៌មាន (ទ្រង់ទ្រាយ TXT) ត្រូវបានផ្ទុកឡើងទៅក្នុងធុងទឹក S3 ។ ជំហានទី 8 និង 9 បង្ហោះព័ត៌មានទៅក្នុងធុង S3 ដោយស្វ័យប្រវត្តិ ប៉ុន្តែអ្នកក៏អាចបង្កើតការរួមបញ្ចូលជាមួយអ្នកផ្តល់ព័ត៌មានដែលអ្នកពេញចិត្តដូចជា AWS Data Exchange ឬអ្នកផ្តល់ព័ត៌មានភាគីទីបីណាមួយដើម្បីទម្លាក់អត្ថបទព័ត៌មានជាឯកសារទៅក្នុងធុង S3 ។ មាតិកាឯកសារទិន្នន័យព័ត៌មានគួរតែត្រូវបានធ្វើទ្រង់ទ្រាយជា
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - ការជូនដំណឹងអំពីព្រឹត្តិការណ៍ S3 ផ្ញើ S3 bucket ឬឈ្មោះឯកសារទៅ Amazon SQS (ស្តង់ដារ) ដែលហៅមុខងារ Lambda ជាច្រើនដើម្បីដំណើរការទិន្នន័យព័ត៌មានស្របគ្នា៖
- ប្រើ Amazon Bedrock ដើម្បីទាញយកអង្គភាពដែលបានលើកឡើងនៅក្នុងព័ត៌មាន រួមជាមួយនឹងព័ត៌មាន ទំនាក់ទំនង និងអារម្មណ៍នៃអង្គភាពដែលបានលើកឡើង។
- ពិនិត្យមើលក្រាហ្វចំណេះដឹង និងប្រើប្រាស់ Amazon Bedrock ដើម្បីធ្វើការបកស្រាយដោយហេតុផលដោយប្រើព័ត៌មានដែលមានពីព័ត៌មាន និងពីក្នុងក្រាហ្វចំណេះដឹងដើម្បីកំណត់អត្តសញ្ញាណអង្គភាពដែលត្រូវគ្នា។
- បន្ទាប់ពីអង្គភាពត្រូវបានគេកំណត់ទីតាំងហើយ សូមស្វែងរកនិងត្រឡប់ផ្លូវតភ្ជាប់ដែលតភ្ជាប់ទៅអង្គភាពដែលបានសម្គាល់
INTERESTED=YESនៅក្នុងក្រាហ្វចំណេះដឹងដែលស្ថិតនៅក្នុង N=2 លោតទៅឆ្ងាយ។
- កម្មវិធីគេហទំព័រនឹងធ្វើឱ្យស្រស់ឡើងវិញដោយស្វ័យប្រវត្តិរៀងរាល់ 1 វិនាទី ដើម្បីទាញយកព័ត៌មានដែលបានដំណើរការចុងក្រោយបំផុតដើម្បីបង្ហាញនៅលើកម្មវិធីគេហទំព័រ។
ដាក់ពង្រាយគំរូដើម
អ្នកអាចដាក់ពង្រាយដំណោះស្រាយគំរូ ហើយចាប់ផ្តើមពិសោធន៍ដោយខ្លួនឯង។ គំរូដើមអាចរកបានពី GitHub និងរួមបញ្ចូលព័ត៌មានលម្អិតដូចខាងក្រោម៖
- លក្ខខណ្ឌនៃការដាក់ពង្រាយ
- ជំហានដាក់ពង្រាយ
- ជំហានសម្អាត
សេចក្តីសង្ខេប
ការបង្ហោះនេះបានបង្ហាញពីភ័ស្តុតាងនៃដំណោះស្រាយគំនិត ដើម្បីជួយអ្នកគ្រប់គ្រងផលប័ត្ររកឃើញហានិភ័យលំដាប់ទីពីរ និងទីបីពីព្រឹត្តិការណ៍ព័ត៌មាន ដោយគ្មានឯកសារយោងផ្ទាល់ទៅកាន់ក្រុមហ៊ុនដែលពួកគេតាមដាន។ តាមរយៈការរួមបញ្ចូលក្រាហ្វចំណេះដឹងនៃទំនាក់ទំនងក្រុមហ៊ុនដ៏ស្មុគស្មាញជាមួយការវិភាគព័ត៌មានតាមពេលវេលាជាក់ស្តែងដោយប្រើ AI ជំនាន់នោះ ផលប៉ះពាល់ខាងក្រោមអាចត្រូវបានគូសបញ្ជាក់ ដូចជាការពន្យារពេលផលិតកម្មពីការរំខានរបស់អ្នកផ្គត់ផ្គង់។
ទោះបីជាវាគ្រាន់តែជាគំរូដើមក៏ដោយ ដំណោះស្រាយនេះបង្ហាញពីការសន្យានៃក្រាហ្វចំណេះដឹង និងគំរូភាសាដើម្បីភ្ជាប់ចំនុច និងទទួលបានសញ្ញាពីសំលេងរំខាន។ បច្ចេកវិទ្យាទាំងនេះអាចជួយអ្នកជំនាញក្នុងការវិនិយោគដោយបង្ហាញពីហានិភ័យកាន់តែលឿនតាមរយៈផែនទីទំនាក់ទំនង និងការវែកញែក។ សរុបមក នេះគឺជាកម្មវិធីដ៏ជោគជ័យនៃមូលដ្ឋានទិន្នន័យក្រាហ្វ និង AI ដែលធានាការរុករកដើម្បីបង្កើនការវិភាគការវិនិយោគ និងការសម្រេចចិត្ត។
ប្រសិនបើឧទាហរណ៍នៃ AI ជំនាន់នេះនៅក្នុងសេវាកម្មហិរញ្ញវត្ថុមានការចាប់អារម្មណ៍ចំពោះអាជីវកម្មរបស់អ្នក ឬអ្នកមានគំនិតស្រដៀងគ្នា សូមទាក់ទងអ្នកគ្រប់គ្រងគណនី AWS របស់អ្នក ហើយយើងនឹងរីករាយក្នុងការស្វែងយល់បន្ថែមជាមួយអ្នក។
អំពីអ្នកនិពន្ធ
 Xan Huang គឺជាស្ថាបត្យករដំណោះស្រាយជាន់ខ្ពស់ជាមួយ AWS ហើយមានមូលដ្ឋាននៅប្រទេសសិង្ហបុរី។ គាត់ធ្វើការជាមួយស្ថាប័នហិរញ្ញវត្ថុធំៗ ដើម្បីរចនា និងបង្កើតដំណោះស្រាយប្រកបដោយសុវត្ថិភាព ធ្វើមាត្រដ្ឋាន និងដំណោះស្រាយដែលមានកម្រិតខ្ពស់នៅក្នុងពពក។ ក្រៅពីការងារ លោក Xan ចំណាយពេលទំនេរភាគច្រើនជាមួយក្រុមគ្រួសារ ហើយត្រូវបានកូនស្រីអាយុ៣ឆ្នាំធ្វើជាថៅកែ។ អ្នកអាចស្វែងរក Xan នៅលើ LinkedIn.
Xan Huang គឺជាស្ថាបត្យករដំណោះស្រាយជាន់ខ្ពស់ជាមួយ AWS ហើយមានមូលដ្ឋាននៅប្រទេសសិង្ហបុរី។ គាត់ធ្វើការជាមួយស្ថាប័នហិរញ្ញវត្ថុធំៗ ដើម្បីរចនា និងបង្កើតដំណោះស្រាយប្រកបដោយសុវត្ថិភាព ធ្វើមាត្រដ្ឋាន និងដំណោះស្រាយដែលមានកម្រិតខ្ពស់នៅក្នុងពពក។ ក្រៅពីការងារ លោក Xan ចំណាយពេលទំនេរភាគច្រើនជាមួយក្រុមគ្រួសារ ហើយត្រូវបានកូនស្រីអាយុ៣ឆ្នាំធ្វើជាថៅកែ។ អ្នកអាចស្វែងរក Xan នៅលើ LinkedIn.
- SEO ដែលដំណើរការដោយមាតិកា និងការចែកចាយ PR ។ ទទួលបានការពង្រីកថ្ងៃនេះ។
- PlatoData.Network Vertical Generative Ai. ផ្តល់អំណាចដល់ខ្លួនអ្នក។ ចូលប្រើទីនេះ។
- PlatoAiStream Web3 Intelligence ។ ចំណេះដឹងត្រូវបានពង្រីក។ ចូលប្រើទីនេះ។
- ផ្លាតូអេសជី។ កាបូន CleanTech, ថាមពល, បរិស្ថាន, ពន្លឺព្រះអាទិត្យ ការគ្រប់គ្រងកាកសំណល់។ ចូលប្រើទីនេះ។
- ផ្លាតូសុខភាព។ ជីវបច្ចេកវិទ្យា និង ភាពវៃឆ្លាត សាកល្បងគ្លីនិក។ ចូលប្រើទីនេះ។
- ប្រភព: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

