យើងកំពុងឃើញការកើនឡើងយ៉ាងឆាប់រហ័សក្នុងការទទួលយកគំរូភាសាធំ (LLM) ដែលផ្តល់ថាមពលដល់កម្មវិធី AI ទូទាំងឧស្សាហកម្ម។ LLMs មានសមត្ថភាពធ្វើការងារជាច្រើនដូចជា បង្កើតមាតិកាច្នៃប្រឌិត ឆ្លើយសំណួរតាមរយៈ chatbots បង្កើតកូដ និងច្រើនទៀត។
អង្គការដែលកំពុងស្វែងរកការប្រើប្រាស់ LLMs ដើម្បីផ្តល់ថាមពលដល់កម្មវិធីរបស់ពួកគេ មានការប្រុងប្រយ័ត្នកាន់តែខ្លាំងឡើងអំពីភាពឯកជននៃទិន្នន័យ ដើម្បីធានាថាការជឿទុកចិត្ត និងសុវត្ថិភាពត្រូវបានរក្សានៅក្នុងកម្មវិធី AI ជំនាន់របស់ពួកគេ។ នេះរាប់បញ្ចូលទាំងការគ្រប់គ្រងទិន្នន័យព័ត៌មានអត្តសញ្ញាណផ្ទាល់ខ្លួន (PII) របស់អតិថិជនឱ្យបានត្រឹមត្រូវ។ វាក៏រួមបញ្ចូលផងដែរនូវការការពារខ្លឹមសារបំពាន និងមិនមានសុវត្ថិភាពពីការផ្សព្វផ្សាយទៅកាន់ LLMs និងពិនិត្យមើលថាទិន្នន័យដែលបង្កើតដោយ LLMs អនុវត្តតាមគោលការណ៍ដូចគ្នា។
នៅក្នុងការប្រកាសនេះ យើងពិភាក្សាអំពីមុខងារថ្មីៗដែលដំណើរការដោយ ក្រុមហ៊ុន Amazon យល់។ ដែលអនុញ្ញាតឱ្យមានការរួមបញ្ចូលយ៉ាងរលូន ដើម្បីធានាបាននូវភាពឯកជនទិន្នន័យ សុវត្ថិភាពខ្លឹមសារ និងសុវត្ថិភាពភ្លាមៗនៅក្នុងកម្មវិធី AI ជំនាន់ថ្មី និងដែលមានស្រាប់។

Amazon Comprehend គឺជាសេវាកម្មដំណើរការភាសាធម្មជាតិ (NLP) ដែលប្រើការរៀនម៉ាស៊ីន (ML) ដើម្បីបង្ហាញព័ត៌មាននៅក្នុងទិន្នន័យដែលមិនមានរចនាសម្ព័ន្ធ និងអត្ថបទនៅក្នុងឯកសារ។ នៅក្នុងការប្រកាសនេះ យើងពិភាក្សាអំពីមូលហេតុដែលទំនុកចិត្ត និងសុវត្ថិភាពជាមួយ LLMs មានសារៈសំខាន់សម្រាប់បន្ទុកការងាររបស់អ្នក។ យើងក៏ស្វែងយល់កាន់តែស៊ីជម្រៅអំពីរបៀបដែលសមត្ថភាពសម្របសម្រួលថ្មីទាំងនេះត្រូវបានប្រើប្រាស់ជាមួយនឹងក្របខ័ណ្ឌអភិវឌ្ឍន៍ AI ដ៏ពេញនិយម LangChain ដើម្បីណែនាំយន្តការសុវត្ថិភាព និងទំនុកចិត្តដែលអាចប្ដូរតាមបំណងបានសម្រាប់ករណីប្រើប្រាស់របស់អ្នក។
ហេតុអ្វីបានជាការជឿទុកចិត្ត និងសុវត្ថិភាពជាមួយ LLMs មានសារៈសំខាន់
ការជឿទុកចិត្ត និងសុវត្ថិភាពគឺសំខាន់បំផុតនៅពេលធ្វើការជាមួយ LLMs ដោយសារតែផលប៉ះពាល់យ៉ាងជ្រាលជ្រៅរបស់ពួកគេទៅលើកម្មវិធីជាច្រើន ចាប់ពី chatbots ជំនួយអតិថិជន រហូតដល់ការបង្កើតមាតិកា។ នៅពេលដែលគំរូទាំងនេះដំណើរការទិន្នន័យយ៉ាងច្រើន និងបង្កើតការឆ្លើយតបដូចមនុស្ស សក្តានុពលនៃការប្រើប្រាស់ខុស ឬលទ្ធផលដែលមិនចង់បានកើនឡើង។ ការធានាថាប្រព័ន្ធ AI ទាំងនេះដំណើរការក្នុងដែនកំណត់ប្រកបដោយក្រមសីលធម៌ និងអាចទុកចិត្តបានគឺមានសារៈសំខាន់ មិនត្រឹមតែសម្រាប់កេរ្តិ៍ឈ្មោះរបស់អាជីវកម្មដែលប្រើប្រាស់វាប៉ុណ្ណោះទេ ប៉ុន្តែថែមទាំងសម្រាប់រក្សាការជឿទុកចិត្តរបស់អ្នកប្រើប្រាស់ និងអតិថិជនផងដែរ។
លើសពីនេះទៅទៀត នៅពេលដែល LLMs កាន់តែរួមបញ្ចូលទៅក្នុងបទពិសោធន៍ឌីជីថលប្រចាំថ្ងៃរបស់យើង ឥទ្ធិពលរបស់វាទៅលើការយល់ឃើញ ជំនឿ និងការសម្រេចចិត្តរបស់យើងកើនឡើង។ ការធានានូវទំនុកចិត្ត និងសុវត្ថិភាពជាមួយ LLMs លើសពីវិធានការបច្ចេកទេស។ វានិយាយអំពីទំនួលខុសត្រូវដ៏ទូលំទូលាយរបស់អ្នកអនុវត្ត AI និងអង្គការនានាក្នុងការលើកកម្ពស់ស្តង់ដារសីលធម៌។ តាមរយៈការផ្តល់អាទិភាពដល់ការជឿទុកចិត្ត និងសុវត្ថិភាព អង្គការមិនត្រឹមតែការពារអ្នកប្រើប្រាស់របស់ពួកគេប៉ុណ្ណោះទេ ប៉ុន្តែថែមទាំងធានាបាននូវកំណើនប្រកបដោយនិរន្តរភាព និងការទទួលខុសត្រូវរបស់ AI នៅក្នុងសង្គមផងដែរ។ វាក៏អាចជួយកាត់បន្ថយហានិភ័យនៃការបង្កើតមាតិកាដែលបង្កគ្រោះថ្នាក់ និងជួយប្រកាន់ខ្ជាប់នូវតម្រូវការបទប្បញ្ញត្តិ។
នៅក្នុងអាណាចក្រនៃភាពជឿជាក់ និងសុវត្ថិភាព ការសម្របសម្រួលខ្លឹមសារគឺជាយន្តការដែលដោះស្រាយទិដ្ឋភាពផ្សេងៗ រួមទាំងប៉ុន្តែមិនកំណត់ចំពោះ៖
- ភាពឯកជន - អ្នកប្រើប្រាស់អាចផ្តល់អត្ថបទដែលមានព័ត៌មានរសើបដោយអចេតនា ដែលបង្កគ្រោះថ្នាក់ដល់ឯកជនភាពរបស់ពួកគេ។ ការរកឃើញ និងកំណត់ឡើងវិញនូវ PII ណាមួយគឺចាំបាច់។
- ភាពធន់ - ការទទួលស្គាល់ និងត្រងខ្លឹមសារដែលបង្កគ្រោះថ្នាក់ ដូចជាពាក្យសំដីស្អប់ ការគំរាមកំហែង ឬការរំលោភបំពាន គឺជាសារៈសំខាន់បំផុត។
- ចេតនារបស់អ្នកប្រើ - ការកំណត់ថាតើការបញ្ចូលរបស់អ្នកប្រើ (ប្រអប់បញ្ចូល) មានសុវត្ថិភាពឬមិនមានសុវត្ថិភាពគឺមានសារៈសំខាន់។ ការជម្រុញដែលមិនមានសុវត្ថិភាពអាចបង្ហាញយ៉ាងច្បាស់ ឬដោយចេតនានូវចេតនាអាក្រក់ ដូចជាការស្នើសុំព័ត៌មានផ្ទាល់ខ្លួន ឬឯកជន និងបង្កើតខ្លឹមសារប្រមាថ ការរើសអើង ឬខុសច្បាប់។ ការបំផុសគំនិតក៏អាចបង្ហាញដោយប្រយោល ឬស្នើសុំការណែនាំអំពីវេជ្ជសាស្ត្រ ច្បាប់ នយោបាយ វិវាទ ផ្ទាល់ខ្លួន ឬហិរញ្ញវត្ថុ

ការសម្របសម្រួលមាតិកាជាមួយ Amazon Comprehend
នៅក្នុងផ្នែកនេះ យើងពិភាក្សាអំពីអត្ថប្រយោជន៍នៃការសម្របសម្រួលមាតិកាជាមួយ Amazon Comprehend ។
ដោះស្រាយភាពឯកជន
Amazon Comprehend ដោះស្រាយភាពឯកជនរួចហើយតាមរយៈការរកឃើញ PII ដែលមានស្រាប់ និងសមត្ថភាព redaction តាមរយៈ រកឃើញPIIEntities និង មានPIIEntities APIs APIs ទាំងពីរនេះត្រូវបានគាំទ្រដោយម៉ូដែល NLP ដែលអាចរកឃើញចំនួនដ៏ច្រើននៃអង្គភាព PII ដូចជាលេខសន្តិសុខសង្គម (SSNs) លេខប័ណ្ណឥណទាន ឈ្មោះ អាស័យដ្ឋាន លេខទូរស័ព្ទជាដើម។ សម្រាប់បញ្ជីពេញលេញនៃអង្គភាព សូមមើល ប្រភេទអង្គភាពសកល PII. DetectPII ក៏ផ្តល់នូវទីតាំងកម្រិតតួអក្សរនៃអង្គភាព PII នៅក្នុងអត្ថបទមួយ។ ឧទាហរណ៍ ទីតាំងតួអក្សរចាប់ផ្តើមនៃអង្គភាព NAME (John Doe) ក្នុងប្រយោគ “ឈ្មោះរបស់ខ្ញុំគឺ Jអូហូe” គឺ 12 ហើយទីតាំងតួអក្សរបញ្ចប់គឺ 19 ។ អុហ្វសិតទាំងនេះអាចត្រូវបានប្រើដើម្បីអនុវត្តការបិទបាំង ឬការផ្លាស់ប្តូរតម្លៃ ដោយកាត់បន្ថយហានិភ័យនៃការផ្សព្វផ្សាយទិន្នន័យឯកជនទៅក្នុង LLMs ។
ដោះស្រាយការពុល និងសុវត្ថិភាពភ្លាមៗ
ថ្ងៃនេះ យើងកំពុងប្រកាសអំពីលក្ខណៈពិសេសថ្មីពីររបស់ Amazon Comprehend ក្នុងទម្រង់ APIs៖ ការរកឃើញជាតិពុលតាមរយៈ DetectToxicContent API និងការចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗតាមរយៈ ClassifyDocument ការ API. ចំណាំថា DetectToxicContent គឺជា API ថ្មី ចំណែកឯ ClassifyDocument គឺជា API ដែលមានស្រាប់ ដែលឥឡូវនេះគាំទ្រការចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗ។
ការរកឃើញជាតិពុល
ជាមួយនឹងការរកឃើញជាតិពុល Amazon Comprehend អ្នកអាចកំណត់អត្តសញ្ញាណ និងដាក់ទង់មាតិកាដែលអាចមានគ្រោះថ្នាក់ ប្រមាថ ឬមិនសមរម្យ។ សមត្ថភាពនេះមានតម្លៃជាពិសេសសម្រាប់វេទិកាដែលអ្នកប្រើប្រាស់បង្កើតមាតិកាដូចជា គេហទំព័រប្រព័ន្ធផ្សព្វផ្សាយសង្គម វេទិកា chatbots ផ្នែកមតិយោបល់ និងកម្មវិធីដែលប្រើ LLMs ដើម្បីបង្កើតមាតិកា។ គោលដៅចម្បងគឺដើម្បីរក្សាបរិយាកាសវិជ្ជមាន និងសុវត្ថិភាពដោយការទប់ស្កាត់ការផ្សព្វផ្សាយនៃសារធាតុពុល។
ជាស្នូលរបស់វា គំរូនៃការរកឃើញជាតិពុលវិភាគអត្ថបទដើម្បីកំណត់លទ្ធភាពរបស់វាដែលមានមាតិកាស្អប់ ការគំរាមកំហែង អាសអាភាស ឬទម្រង់ផ្សេងទៀតនៃអត្ថបទដែលបង្កគ្រោះថ្នាក់។ គំរូនេះត្រូវបានបណ្តុះបណ្តាលលើសំណុំទិន្នន័យដ៏ធំដែលមានឧទាហរណ៍នៃមាតិកាពុល និងគ្មានជាតិពុល។ API ជាតិពុលវាយតម្លៃអត្ថបទដែលបានផ្តល់ឱ្យដើម្បីផ្តល់នូវចំណាត់ថ្នាក់ជាតិពុល និងពិន្ទុទំនុកចិត្ត។ កម្មវិធី AI ជំនាន់ក្រោយអាចប្រើព័ត៌មាននេះ ដើម្បីធ្វើសកម្មភាពសមស្រប ដូចជាការបញ្ឈប់អត្ថបទពីការផ្សព្វផ្សាយទៅ LLMs ។ តាមការសរសេរនេះ ស្លាកដែលរកឃើញដោយ API រកឃើញជាតិពុលគឺ HATE_SPEECH, GRAPHIC, HARRASMENT_OR_ABUSE, SEXUAL, VIOLENCE_OR_THREAT, INSULTនិង PROFANITY. កូដខាងក្រោមបង្ហាញពីការហៅ API ជាមួយ Python Boto3 សម្រាប់ Amazon Comprehend ការរកឃើញជាតិពុល៖
ការចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗ
ការចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗជាមួយ Amazon Comprehend ជួយចាត់ថ្នាក់ប្រអប់បញ្ចូលអត្ថបទថាមានសុវត្ថិភាព ឬមិនមានសុវត្ថិភាព។ សមត្ថភាពនេះគឺមានសារៈសំខាន់សម្រាប់កម្មវិធីដូចជា chatbots ជំនួយការនិម្មិត ឬឧបករណ៍សម្របសម្រួលមាតិកា ដែលការយល់ដឹងអំពីសុវត្ថិភាពនៃការជម្រុញអាចកំណត់ការឆ្លើយតប សកម្មភាព ឬការផ្សព្វផ្សាយខ្លឹមសារទៅកាន់ LLMs ។
ជារួម ចំណាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗវិភាគធាតុចូលរបស់មនុស្សសម្រាប់ចេតនាព្យាបាទជាក់ស្តែង ឬដោយប្រយោល ដូចជាការស្នើសុំព័ត៌មានផ្ទាល់ខ្លួន ឬឯកជន និងការបង្កើតខ្លឹមសារប្រមាថ ការរើសអើង ឬខុសច្បាប់។ វាក៏ដាក់ទង់ដាស់តឿនឱ្យស្វែងរកការណែនាំអំពីមុខវិជ្ជាវេជ្ជសាស្រ្ត ច្បាប់ នយោបាយ វិវាទ បុគ្គល ឬមុខវិជ្ជាហិរញ្ញវត្ថុ។ ការចាត់ថ្នាក់ភ្លាមៗត្រឡប់ថ្នាក់ពីរ, UNSAFE_PROMPT និង SAFE_PROMPTសម្រាប់អត្ថបទដែលពាក់ព័ន្ធ ជាមួយនឹងពិន្ទុទំនុកចិត្តដែលពាក់ព័ន្ធសម្រាប់នីមួយៗ។ ពិន្ទុភាពជឿជាក់មានចន្លោះពី 0–1 ហើយបូកបញ្ចូលគ្នានឹងបូកសរុបរហូតដល់ 1។ ឧទាហរណ៍ នៅក្នុង chatbot ជំនួយអតិថិជន អត្ថបទ "តើខ្ញុំត្រូវកំណត់ពាក្យសម្ងាត់របស់ខ្ញុំឡើងវិញដោយរបៀបណា?” បង្ហាញពីចេតនាស្វែងរកការណែនាំអំពីនីតិវិធីកំណត់ពាក្យសម្ងាត់ឡើងវិញ ហើយត្រូវបានដាក់ស្លាកថាជា SAFE_PROMPT. ស្រដៀងគ្នានេះដែរ សេចក្តីថ្លែងការណ៍ដូចជា “ខ្ញុំសូមជូនពរឱ្យអ្នកមានអ្វីអាក្រក់កើតឡើង"អាចត្រូវបានដាក់ទង់ថាមានចេតនាដែលអាចបង្កគ្រោះថ្នាក់ និងដាក់ស្លាកថាជា UNSAFE_PROMPT. វាជារឿងសំខាន់ក្នុងការកត់សម្គាល់ថាការចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗគឺផ្តោតជាចម្បងលើការស្វែងរកចេតនាពីធាតុចូលរបស់មនុស្ស (ប្រអប់បញ្ចូល) ជាជាងអត្ថបទដែលបង្កើតដោយម៉ាស៊ីន (លទ្ធផល LLM)។ កូដខាងក្រោមបង្ហាញពីរបៀបចូលប្រើមុខងារចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗជាមួយ ClassifyDocument API៖
ចំណាំថា endpoint_arn នៅក្នុងកូដមុនគឺ AWS-provided លេខធនធាន Amazon (ARN) នៃលំនាំ arn:aws:comprehend:<region>:aws:document-classifier-endpoint/prompt-safety, ដែលជាកន្លែងដែល <region> គឺជាតំបន់ AWS នៃជម្រើសរបស់អ្នក។ Amazon Comprehend អាចរកបាន.
ដើម្បីបង្ហាញពីសមត្ថភាពទាំងនេះ យើងបានបង្កើតកម្មវិធីជជែកគំរូមួយ ដែលយើងស្នើឱ្យ LLM ទាញយកធាតុ PII ដូចជាអាសយដ្ឋាន លេខទូរស័ព្ទ និង SSN ពីអត្ថបទដែលបានផ្តល់ឱ្យ។ LLM ស្វែងរក និងបញ្ជូនធាតុ PII ដែលសមស្របដូចបង្ហាញក្នុងរូបភាពនៅខាងឆ្វេង។
ជាមួយនឹងការសម្របសម្រួល Amazon Comprehend យើងអាចផ្លាស់ប្តូរការបញ្ចូលទៅ LLM និងទិន្នផលពី LLM ។ នៅក្នុងរូបភាពនៅខាងស្តាំ តម្លៃ SSN ត្រូវបានអនុញ្ញាតឱ្យបញ្ជូនទៅ LLM ដោយមិនមានប្រតិកម្មឡើងវិញ។ ទោះយ៉ាងណាក៏ដោយ តម្លៃ SSN ណាមួយនៅក្នុងការឆ្លើយតបរបស់ LLM ត្រូវបានកែប្រែឡើងវិញ។

ខាងក្រោមនេះគឺជាឧទាហរណ៍នៃរបៀបដែលប្រអប់បញ្ចូលដែលមានព័ត៌មាន PII អាចត្រូវបានរារាំងពីការទៅដល់ LLM ទាំងអស់គ្នា។ ឧទាហរណ៍នេះបង្ហាញពីអ្នកប្រើប្រាស់ដែលសួរសំណួរដែលមានព័ត៌មាន PII ។ យើងប្រើការសម្របសម្រួល Amazon Comprehend ដើម្បីរកឃើញអង្គភាព PII នៅក្នុងប្រអប់បញ្ចូល ហើយបង្ហាញកំហុសដោយការរំខានលំហូរ។
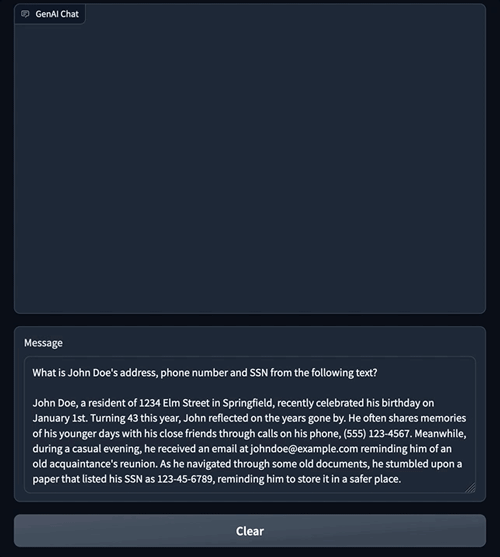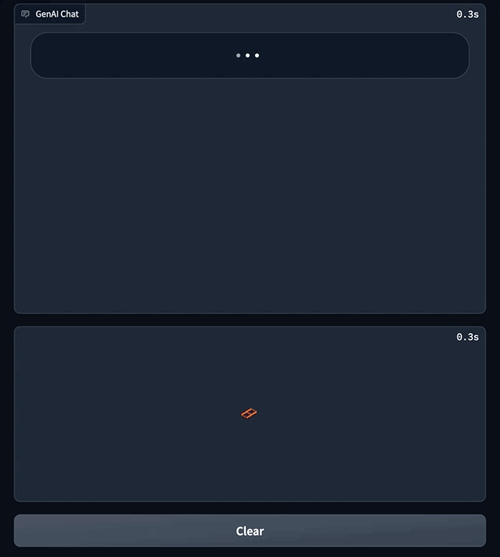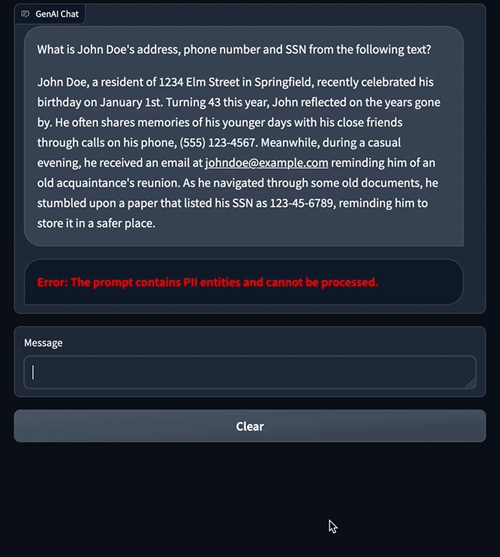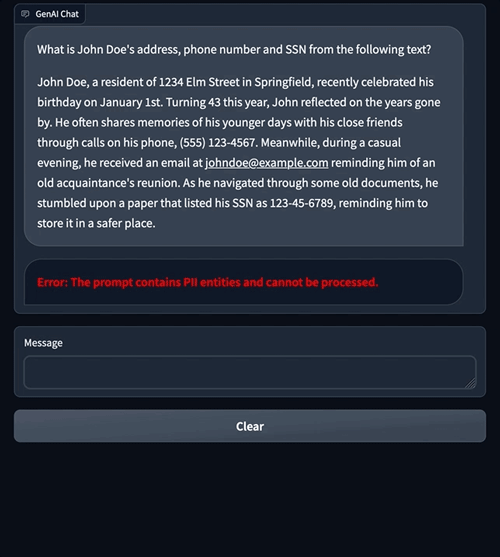
ឧទាហរណ៍នៃការជជែកពីមុនបង្ហាញពីរបៀបដែលការសម្របសម្រួល Amazon Comprehend អនុវត្តការរឹតបន្តឹងលើទិន្នន័យដែលត្រូវបានផ្ញើទៅ LLM ។ នៅក្នុងផ្នែកខាងក្រោម យើងពន្យល់ពីរបៀបដែលយន្តការសម្របសម្រួលនេះត្រូវបានអនុវត្តដោយប្រើ LangChain ។
ការរួមបញ្ចូលជាមួយ LangChain
ជាមួយនឹងលទ្ធភាពគ្មានទីបញ្ចប់នៃកម្មវិធី LLMs ទៅក្នុងករណីប្រើប្រាស់ផ្សេងៗ វាមានសារៈសំខាន់ដូចគ្នាក្នុងការសម្រួលដល់ការអភិវឌ្ឍន៍កម្មវិធី AI ជំនាន់ថ្មី។ LangChain គឺជាក្របខ័ណ្ឌប្រភពបើកចំហដ៏ពេញនិយមដែលធ្វើឱ្យវាពិបាកក្នុងការអភិវឌ្ឍកម្មវិធី AI ជំនាន់។ ការសម្របសម្រួល Amazon Comprehend ពង្រីកក្របខ័ណ្ឌ LangChain ដើម្បីផ្តល់ជូននូវការកំណត់អត្តសញ្ញាណ PII និងការបញ្ចេញឡើងវិញ ការរកឃើញជាតិពុល និងសមត្ថភាពចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗតាមរយៈ AmazonComprehendModerationChain.
AmazonComprehendModerationChain គឺជាការអនុវត្តផ្ទាល់ខ្លួនរបស់ ខ្សែសង្វាក់មូលដ្ឋាន LangChain ចំណុចប្រទាក់។ នេះមានន័យថាកម្មវិធីអាចប្រើខ្សែសង្វាក់នេះជាមួយនឹងរបស់ពួកគេផ្ទាល់ ខ្សែសង្វាក់ LLM ដើម្បីអនុវត្តការសម្របសម្រួលដែលចង់បានទៅប្រអប់បញ្ចូលក៏ដូចជាអត្ថបទលទ្ធផលពី LLM ។ ខ្សែសង្វាក់អាចត្រូវបានសាងសង់ដោយការរួមបញ្ចូលគ្នារវាងច្រវាក់ជាច្រើនឬដោយការលាយច្រវ៉ាក់ជាមួយសមាសធាតុផ្សេងទៀត។ លោកអ្នកអាចប្រើ AmazonComprehendModerationChain ជាមួយនឹងខ្សែសង្វាក់ LLM ផ្សេងទៀតដើម្បីបង្កើតកម្មវិធី AI ស្មុគស្មាញក្នុងលក្ខណៈម៉ូឌុល និងអាចបត់បែនបាន។
ដើម្បីពន្យល់វាបន្ថែមទៀត យើងផ្តល់គំរូមួយចំនួននៅក្នុងផ្នែកខាងក្រោម។ កូដប្រភពសម្រាប់អេ AmazonComprehendModerationChain ការអនុវត្តអាចត្រូវបានរកឃើញនៅក្នុង ឃ្លាំងប្រភពបើកចំហ LangChain. សម្រាប់ឯកសារពេញលេញនៃចំណុចប្រទាក់ API សូមមើលឯកសារ LangChain API សម្រាប់ ខ្សែសង្វាក់ការសម្របសម្រួលរបស់ Amazon យល់. ការប្រើខ្សែសង្វាក់ការសម្របសម្រួលនេះគឺសាមញ្ញដូចជាការចាប់ផ្តើមឧទាហរណ៍នៃថ្នាក់ជាមួយនឹងការកំណត់លំនាំដើម៖
នៅពីក្រោយឆាក ខ្សែសង្វាក់ការសម្របសម្រួលធ្វើការត្រួតពិនិត្យការសម្របសម្រួលចំនួនបីជាប់ៗគ្នាគឺ PII ការពុល និងសុវត្ថិភាពភ្លាមៗ ដូចដែលបានពន្យល់នៅក្នុងដ្យាក្រាមខាងក្រោម។ នេះគឺជាលំហូរលំនាំដើមសម្រាប់ការសម្របសម្រួល។

អត្ថបទកូដខាងក្រោមបង្ហាញឧទាហរណ៍សាមញ្ញមួយនៃការប្រើខ្សែសង្វាក់សម្របសម្រួលជាមួយ ក្រុមហ៊ុន Amazon FalconLite LLM (ដែលជាកំណែបរិមាណនៃ ម៉ូដែល Falcon 40B SFT OASST-TOP1) រៀបចំនៅ Hugging Face Hub៖
នៅក្នុងឧទាហរណ៍មុន យើងបង្កើនខ្សែសង្វាក់របស់យើងជាមួយ comprehend_moderation សម្រាប់អត្ថបទទាំងពីរចូលទៅក្នុង LLM និងអត្ថបទដែលបង្កើតដោយ LLM ។ វានឹងអនុវត្តការសម្របសម្រួលលំនាំដើមដែលនឹងពិនិត្យ PII, ជាតិពុល និងការចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗនៅក្នុងលំដាប់នោះ។
កំណត់ការសម្របសម្រួលរបស់អ្នកតាមបំណងជាមួយនឹងការកំណត់រចនាសម្ព័ន្ធតម្រង
អ្នកអាចប្រើ AmazonComprehendModerationChain ជាមួយនឹងការកំណត់រចនាសម្ព័ន្ធជាក់លាក់ ដែលផ្តល់ឱ្យអ្នកនូវសមត្ថភាពក្នុងការគ្រប់គ្រងការសម្របសម្រួលណាមួយដែលអ្នកចង់អនុវត្តនៅក្នុងកម្មវិធីដែលមានមូលដ្ឋានលើ AI ជំនាន់របស់អ្នក។ នៅស្នូលនៃការកំណត់រចនាសម្ព័ន្ធ អ្នកមានការកំណត់រចនាសម្ព័ន្ធតម្រងបីដែលអាចប្រើបាន។
- ModerationPiiConfig - ប្រើដើម្បីកំណត់រចនាសម្ព័ន្ធតម្រង PII ។
- កម្រិតជាតិពុលកម្រិតមធ្យម - ប្រើដើម្បីកំណត់រចនាសម្ព័ន្ធតម្រងមាតិកាពុល។
- ModerationIntentConfig - ប្រើដើម្បីកំណត់រចនាសម្ព័ន្ធតម្រងចេតនា។
អ្នកអាចប្រើការកំណត់រចនាសម្ព័ន្ធតម្រងនីមួយៗនេះដើម្បីប្ដូរឥរិយាបថតាមចិត្តរបៀបដែលការសម្របសម្រួលរបស់អ្នកប្រព្រឹត្ត។ ការកំណត់រចនាសម្ព័ន្ធរបស់តម្រងនីមួយៗមានប៉ារ៉ាម៉ែត្រទូទៅមួយចំនួន និងប៉ារ៉ាម៉ែត្រពិសេសមួយចំនួន ដែលពួកវាអាចត្រូវបានចាប់ផ្តើមជាមួយ។ បន្ទាប់ពីអ្នកកំណត់ការកំណត់រួច អ្នកនឹងប្រើពាក្យ BaseModerationConfig class ដើម្បីកំណត់លំដាប់ដែលតម្រងត្រូវតែអនុវត្តចំពោះអត្ថបទ។ ជាឧទាហរណ៍ នៅក្នុងកូដខាងក្រោម យើងកំណត់ការកំណត់រចនាសម្ព័ន្ធតម្រងបីជាមុនសិន ហើយបញ្ជាក់ជាបន្តបន្ទាប់នូវលំដាប់ដែលពួកគេត្រូវអនុវត្ត៖
ចូរយើងស្វែងយល់ឱ្យកាន់តែស៊ីជម្រៅបន្តិច ដើម្បីយល់ពីអ្វីដែលការកំណត់រចនាសម្ព័ន្ធនេះសម្រេចបាន៖
- ទីមួយ សម្រាប់តម្រងជាតិពុល យើងបានបញ្ជាក់កម្រិត 0.6។ នេះមានន័យថា ប្រសិនបើអត្ថបទមានស្លាក ឬធាតុពុលដែលមានពិន្ទុលើសពីកម្រិតកំណត់ ខ្សែសង្វាក់ទាំងមូលនឹងត្រូវបានរំខាន។
- ប្រសិនបើមិនមានមាតិកាពុលត្រូវបានរកឃើញនៅក្នុងអត្ថបទទេ ការត្រួតពិនិត្យ PII គឺក្នុងករណីនេះ យើងចាប់អារម្មណ៍ក្នុងការពិនិត្យមើលថាតើអត្ថបទមានតម្លៃ SSN ដែរឬទេ។ ដោយសារតែ
redactប៉ារ៉ាម៉ែត្រត្រូវបានកំណត់ទៅTrueខ្សែសង្វាក់នឹងបិទបាំងតម្លៃ SSN ដែលបានរកឃើញ (ប្រសិនបើមាន) ដែលពិន្ទុទំនុកចិត្តរបស់អង្គភាព SSN ធំជាង ឬស្មើ 0.5 ជាមួយនឹងតួអក្សររបាំងដែលបានបញ្ជាក់ (X) ។ ប្រសិនបើredactត្រូវបានកំណត់ទៅFalseខ្សែសង្វាក់នឹងត្រូវបានរំខានសម្រាប់ SSN ណាមួយដែលបានរកឃើញ។ - ជាចុងក្រោយ ខ្សែសង្វាក់នេះអនុវត្តការចាត់ថ្នាក់សុវត្ថិភាពភ្លាមៗ ហើយនឹងបញ្ឈប់ខ្លឹមសារពីការផ្សព្វផ្សាយបន្តបន្ទាប់ទៀត ប្រសិនបើខ្លឹមសារត្រូវបានចាត់ថ្នាក់ដោយ
UNSAFE_PROMPTជាមួយនឹងពិន្ទុទំនុកចិត្តធំជាង ឬស្មើ 0.8 ។
ដ្យាក្រាមខាងក្រោមបង្ហាញពីដំណើរការការងារនេះ។

ក្នុងករណីមានការរំខានដល់ខ្សែសង្វាក់កម្រិតមធ្យម (ក្នុងឧទាហរណ៍នេះ ដែលអាចអនុវត្តបានសម្រាប់តម្រងការចាត់ថ្នាក់សុវត្ថិភាពនៃការពុល និងភ្លាមៗ) ខ្សែសង្វាក់នឹងបង្កើន ករណីលើកលែង Pythonជាសំខាន់ការបញ្ឈប់ខ្សែសង្វាក់ដែលកំពុងដំណើរការ និងអនុញ្ញាតឱ្យអ្នកចាប់យកករណីលើកលែង (នៅក្នុងប្លុកសាកល្បង) និងអនុវត្តសកម្មភាពពាក់ព័ន្ធណាមួយ។ ប្រភេទករណីលើកលែងបីប្រភេទគឺ៖
ModerationPIIErrorModerationToxicityErrorModerationPromptSafetyError
អ្នកអាចកំណត់រចនាសម្ព័ន្ធតម្រងមួយ ឬច្រើនជាងមួយតម្រងដោយប្រើ BaseModerationConfig. អ្នកក៏អាចមានប្រភេទតម្រងដូចគ្នាជាមួយនឹងការកំណត់រចនាសម្ព័ន្ធផ្សេងគ្នានៅក្នុងខ្សែសង្វាក់តែមួយ។ ឧទាហរណ៍ ប្រសិនបើករណីប្រើប្រាស់របស់អ្នកពាក់ព័ន្ធតែជាមួយ PII អ្នកអាចបញ្ជាក់ការកំណត់រចនាសម្ព័ន្ធដែលត្រូវតែរំខានខ្សែសង្វាក់ ប្រសិនបើក្នុងករណីដែល SSN ត្រូវបានរកឃើញ។ បើមិនដូច្នេះទេ វាត្រូវតែអនុវត្តឡើងវិញលើអាយុ និងឈ្មោះអង្គភាព PII ។ ការកំណត់រចនាសម្ព័ន្ធសម្រាប់នេះអាចត្រូវបានកំណត់ដូចខាងក្រោម:
ការប្រើប្រាស់ការហៅត្រឡប់មកវិញ និងឧបករណ៍កំណត់អត្តសញ្ញាណតែមួយគត់
ប្រសិនបើអ្នកស៊ាំនឹងគំនិតនៃលំហូរការងារ អ្នកក៏អាចស្គាល់ផងដែរ។ ការហៅត្រឡប់មកវិញ. ការហៅត្រឡប់មកវិញនៅក្នុងលំហូរការងារគឺជាបំណែកឯករាជ្យនៃកូដដែលដំណើរការនៅពេលដែលលក្ខខណ្ឌជាក់លាក់ត្រូវបានបំពេញនៅក្នុងលំហូរការងារ។ ការហៅត្រឡប់មកវិញអាចជាការរារាំង ឬមិនរារាំងលំហូរការងារ។ ខ្សែសង្វាក់ LangChain គឺជាលំហូរការងារសម្រាប់ LLMs ។ AmazonComprehendModerationChain អនុញ្ញាតឱ្យអ្នកកំណត់មុខងារហៅត្រឡប់មកវិញផ្ទាល់ខ្លួនរបស់អ្នក។ ដំបូង ការអនុវត្តត្រូវបានកំណត់ចំពោះមុខងារហៅត្រឡប់មកវិញអសមកាល (មិនទប់ស្កាត់) ប៉ុណ្ណោះ។
នេះមានន័យយ៉ាងមានប្រសិទ្ធភាពថា ប្រសិនបើអ្នកប្រើការហៅត្រឡប់មកវិញជាមួយនឹងខ្សែសង្វាក់ការសម្របសម្រួល ពួកគេនឹងដំណើរការដោយឯករាជ្យពីការរត់របស់ខ្សែសង្វាក់ដោយមិនរារាំងវា។ សម្រាប់ខ្សែសង្វាក់ការសម្របសម្រួល អ្នកទទួលបានជម្រើសដើម្បីដំណើរការបំណែកនៃកូដ ជាមួយនឹងតក្កវិជ្ជាអាជីវកម្មណាមួយ បន្ទាប់ពីដំណើរការសម្របសម្រួលនីមួយៗ ឯករាជ្យពីខ្សែសង្វាក់។
អ្នកក៏អាចផ្តល់ជាជម្រើសជាជម្រើសនូវខ្សែអក្សរកំណត់អត្តសញ្ញាណតែមួយគត់នៅពេលបង្កើត AmazonComprehendModerationChain ដើម្បីបើកការកត់ត្រា និងការវិភាគនៅពេលក្រោយ។ ឧទាហរណ៍ ប្រសិនបើអ្នកកំពុងដំណើរការ chatbot ដែលដំណើរការដោយ LLM អ្នកប្រហែលជាចង់តាមដានអ្នកប្រើប្រាស់ដែលបំពានជាប្រចាំ ឬកំពុងបញ្ចេញព័ត៌មានផ្ទាល់ខ្លួនដោយចេតនា ឬដោយមិនដឹងខ្លួន។ ក្នុងករណីបែបនេះ វាចាំបាច់ដើម្បីតាមដានប្រភពដើមនៃការជម្រុញបែបនេះ ហើយប្រហែលជារក្សាទុកពួកវាក្នុងមូលដ្ឋានទិន្នន័យ ឬកត់ត្រាពួកវាឱ្យបានត្រឹមត្រូវសម្រាប់សកម្មភាពបន្ថែម។ អ្នកអាចឆ្លងកាត់លេខសម្គាល់តែមួយគត់ដែលកំណត់អត្តសញ្ញាណអ្នកប្រើប្រាស់យ៉ាងច្បាស់ ដូចជាឈ្មោះអ្នកប្រើប្រាស់ ឬអ៊ីមែលរបស់ពួកគេ ឬឈ្មោះកម្មវិធីដែលកំពុងបង្កើតប្រអប់បញ្ចូល។
ការរួមបញ្ចូលគ្នានៃការហៅត្រលប់មកវិញ និងឧបករណ៍កំណត់អត្តសញ្ញាណតែមួយគត់ផ្តល់ឱ្យអ្នកនូវវិធីដ៏មានអានុភាពក្នុងការអនុវត្តខ្សែសង្វាក់កម្រិតមធ្យមដែលសមស្របនឹងករណីប្រើប្រាស់របស់អ្នកក្នុងលក្ខណៈស្អិតរមួតជាងមុនជាមួយនឹងលេខកូដតិចជាង ដែលងាយស្រួលក្នុងការថែទាំ។ ឧបករណ៍ដោះស្រាយការហៅត្រឡប់មកវិញអាចរកបានតាមរយៈ BaseModerationCallbackHandlerជាមួយនឹងការហៅត្រឡប់មកវិញដែលមានបី៖ on_after_pii(), on_after_toxicity()និង on_after_prompt_safety(). មុខងារហៅត្រឡប់ទាំងនេះនីមួយៗត្រូវបានគេហៅថាអសមកាលបន្ទាប់ពីការត្រួតពិនិត្យការសម្របសម្រួលរៀងៗខ្លួនត្រូវបានអនុវត្តនៅក្នុងខ្សែសង្វាក់។ មុខងារទាំងនេះក៏ទទួលបានប៉ារ៉ាម៉ែត្រលំនាំដើមពីរផងដែរ៖
- moderation_beacon - វចនានុក្រមដែលមានព័ត៌មានលម្អិតដូចជាអត្ថបទដែលការសម្របសម្រួលត្រូវបានអនុវត្ត លទ្ធផល JSON ពេញលេញនៃ Amazon Comprehend API ប្រភេទនៃការសម្របសម្រួល ហើយប្រសិនបើស្លាកដែលបានផ្គត់ផ្គង់ (ក្នុងការកំណត់រចនាសម្ព័ន្ធ) ត្រូវបានរកឃើញនៅក្នុងអត្ថបទឬអត់។
- unique_id - លេខសម្គាល់តែមួយគត់ដែលអ្នកបានកំណត់ពេលចាប់ផ្តើមឧទាហរណ៍នៃ
AmazonComprehendModerationChain.
ខាងក្រោមនេះគឺជាឧទាហរណ៍នៃរបៀបដែលការអនុវត្តជាមួយនឹងការហៅត្រឡប់វិញដំណើរការ។ ក្នុងករណីនេះ យើងបានកំណត់ការហៅត្រឡប់មកវិញតែមួយដែលយើងចង់ឱ្យខ្សែសង្វាក់ដំណើរការបន្ទាប់ពីការត្រួតពិនិត្យ PII ត្រូវបានអនុវត្ត៖
បន្ទាប់មកយើងប្រើ my_callback វត្ថុខណៈពេលដែលចាប់ផ្តើមខ្សែសង្វាក់ការសម្របសម្រួលហើយក៏ឆ្លងកាត់ a unique_id. អ្នកអាចប្រើការហៅត្រឡប់មកវិញ និងឧបករណ៍កំណត់អត្តសញ្ញាណតែមួយគត់ដោយមាន ឬគ្មានការកំណត់រចនាសម្ព័ន្ធ។ នៅពេលអ្នកថ្នាក់រង BaseModerationCallbackHandlerអ្នកត្រូវតែអនុវត្តវិធីសាស្រ្តហៅត្រឡប់មកវិញមួយ ឬទាំងអស់ អាស្រ័យលើតម្រងដែលអ្នកមានបំណងប្រើ។ សម្រាប់ភាពសង្ខេប ឧទាហរណ៍ខាងក្រោមបង្ហាញពីវិធីប្រើការហៅត្រឡប់ និង unique_id ដោយគ្មានការកំណត់ណាមួយ៖
ដ្យាក្រាមខាងក្រោមពន្យល់ពីរបៀបដែលខ្សែសង្វាក់សម្របសម្រួលនេះជាមួយនឹងការហៅត្រឡប់មកវិញ និងឧបករណ៍កំណត់អត្តសញ្ញាណតែមួយគត់ដំណើរការ។ ជាពិសេស យើងបានអនុវត្តការហៅត្រឡប់ PII ដែលគួរសរសេរឯកសារ JSON ជាមួយនឹងទិន្នន័យដែលមាននៅក្នុង moderation_beacon និង unique_id ឆ្លងកាត់ (អ៊ីមែលរបស់អ្នកប្រើក្នុងករណីនេះ) ។

ដូចខាងក្រោម សៀវភៅកត់ត្រា Pythonយើងបានចងក្រងវិធីផ្សេងគ្នាមួយចំនួនដែលអ្នកអាចកំណត់រចនាសម្ព័ន្ធ និងប្រើខ្សែសង្វាក់សម្របសម្រួលជាមួយ LLMs ផ្សេងៗដូចជា LLMs ដែលរៀបចំជាមួយ ក្រុមហ៊ុន Amazon SageMaker JumpStart និងធ្វើជាម្ចាស់ផ្ទះនៅក្នុង កន្លែងឱបមុខ. យើងក៏បានរួមបញ្ចូលនូវកម្មវិធីជជែកជាគំរូដែលយើងបានពិភាក្សាមុននេះជាមួយនឹងដូចខាងក្រោម សៀវភៅកត់ត្រា Python.
សន្និដ្ឋាន
សក្តានុពលបំប្លែងនៃគំរូភាសាធំៗ និង AI ជំនាន់គឺមិនអាចប្រកែកបាន។ ទោះជាយ៉ាងណាក៏ដោយ ការប្រើប្រាស់ប្រកបដោយទំនួលខុសត្រូវ និងក្រមសីលធម៌របស់ពួកគេ ផ្តោតលើការដោះស្រាយបញ្ហានៃការជឿទុកចិត្ត និងសុវត្ថិភាព។ តាមរយៈការទទួលស្គាល់បញ្ហាប្រឈម និងការអនុវត្តយ៉ាងសកម្មនូវវិធានការកាត់បន្ថយហានិភ័យ អ្នកអភិវឌ្ឍន៍ អង្គការ និងសង្គមទាំងមូលអាចទាញយកអត្ថប្រយោជន៍នៃបច្ចេកវិទ្យាទាំងនេះ ខណៈពេលដែលរក្សាបាននូវទំនុកចិត្ត និងសុវត្ថិភាពដែលគាំទ្រការរួមបញ្ចូលប្រកបដោយជោគជ័យរបស់ពួកគេ។ ប្រើ Amazon Comprehend ContentModerationChain ដើម្បីបន្ថែមភាពជឿជាក់ និងសុវត្ថិភាពដល់លំហូរការងាររបស់ LLM ណាមួយ រួមទាំងលំហូរការងារ Retrieval Augmented Generation (RAG) ដែលបានអនុវត្តនៅក្នុង LangChain ។
សម្រាប់ព័ត៌មានស្តីពីការកសាងដំណោះស្រាយផ្អែកលើ RAG ដោយប្រើ LangChain និង Amazon Kendra ដែលមានភាពត្រឹមត្រូវខ្ពស់ ការរៀនម៉ាស៊ីន (ML) ដែលដំណើរការដោយថាមពល ការស្វែងរកឆ្លាតវៃសូមមើល - បង្កើតកម្មវិធី AI Generative ដែលមានភាពត្រឹមត្រូវខ្ពស់យ៉ាងឆាប់រហ័សលើទិន្នន័យសហគ្រាសដោយប្រើ Amazon Kendra, LangChain និងគំរូភាសាធំ. ជាជំហានបន្ទាប់ យោងទៅ គំរូកូដ យើងបានបង្កើតសម្រាប់ការប្រើប្រាស់ការសម្របសម្រួល Amazon Comprehend ជាមួយ LangChain ។ សម្រាប់ឯកសារពេញលេញនៃ Amazon Comprehend moderation chain API សូមមើល LangChain ឯកសារ API.
អំពីអ្នកនិពន្ធ
 Wrick Talukdar គឺជាស្ថាបត្យករជាន់ខ្ពស់ជាមួយក្រុម Amazon Comprehend Service។ គាត់ធ្វើការជាមួយអតិថិជន AWS ដើម្បីជួយពួកគេទទួលយកការរៀនម៉ាស៊ីននៅលើខ្នាតធំ។ នៅខាងក្រៅការងារ គាត់ចូលចិត្តអាន និងថតរូប។
Wrick Talukdar គឺជាស្ថាបត្យករជាន់ខ្ពស់ជាមួយក្រុម Amazon Comprehend Service។ គាត់ធ្វើការជាមួយអតិថិជន AWS ដើម្បីជួយពួកគេទទួលយកការរៀនម៉ាស៊ីននៅលើខ្នាតធំ។ នៅខាងក្រៅការងារ គាត់ចូលចិត្តអាន និងថតរូប។
 អាន់យ៉ាន ប៊ីសវ៉ាស គឺជាស្ថាបត្យករដំណោះស្រាយសេវាកម្ម AI ជាន់ខ្ពស់ ដោយផ្តោតលើ AI/ML និងការវិភាគទិន្នន័យ។ Anjan គឺជាផ្នែកមួយនៃក្រុមសេវាកម្ម AI ទូទាំងពិភពលោក ហើយធ្វើការជាមួយអតិថិជនដើម្បីជួយពួកគេយល់ និងបង្កើតដំណោះស្រាយចំពោះបញ្ហាអាជីវកម្មជាមួយ AI និង ML ។ Anjan មានបទពិសោធន៍ជាង 14 ឆ្នាំដែលធ្វើការជាមួយបណ្តាញផ្គត់ផ្គង់សកល ការផលិត និងអង្គការលក់រាយ ហើយកំពុងជួយយ៉ាងសកម្មដល់អតិថិជនក្នុងការចាប់ផ្តើម និងធ្វើមាត្រដ្ឋានលើសេវាកម្ម AWS AI ។
អាន់យ៉ាន ប៊ីសវ៉ាស គឺជាស្ថាបត្យករដំណោះស្រាយសេវាកម្ម AI ជាន់ខ្ពស់ ដោយផ្តោតលើ AI/ML និងការវិភាគទិន្នន័យ។ Anjan គឺជាផ្នែកមួយនៃក្រុមសេវាកម្ម AI ទូទាំងពិភពលោក ហើយធ្វើការជាមួយអតិថិជនដើម្បីជួយពួកគេយល់ និងបង្កើតដំណោះស្រាយចំពោះបញ្ហាអាជីវកម្មជាមួយ AI និង ML ។ Anjan មានបទពិសោធន៍ជាង 14 ឆ្នាំដែលធ្វើការជាមួយបណ្តាញផ្គត់ផ្គង់សកល ការផលិត និងអង្គការលក់រាយ ហើយកំពុងជួយយ៉ាងសកម្មដល់អតិថិជនក្នុងការចាប់ផ្តើម និងធ្វើមាត្រដ្ឋានលើសេវាកម្ម AWS AI ។
 Nikhil Jha គឺជាអ្នកគ្រប់គ្រងគណនីបច្ចេកទេសជាន់ខ្ពស់នៅ Amazon Web Services ។ ផ្នែកផ្តោតអារម្មណ៍របស់គាត់រួមមាន AI/ML និងការវិភាគ។ ពេលទំនេរ គាត់ចូលចិត្តលេងកីឡាវាយសីជាមួយកូនស្រី ហើយដើរលេងនៅខាងក្រៅ។
Nikhil Jha គឺជាអ្នកគ្រប់គ្រងគណនីបច្ចេកទេសជាន់ខ្ពស់នៅ Amazon Web Services ។ ផ្នែកផ្តោតអារម្មណ៍របស់គាត់រួមមាន AI/ML និងការវិភាគ។ ពេលទំនេរ គាត់ចូលចិត្តលេងកីឡាវាយសីជាមួយកូនស្រី ហើយដើរលេងនៅខាងក្រៅ។
 ឈិន រ៉ាណេ គឺជាស្ថាបត្យករឯកទេសដំណោះស្រាយ AI/ML នៅ Amazon Web Services។ នាងមានចំណង់ចំណូលចិត្តលើគណិតវិទ្យាអនុវត្ត និងការរៀនម៉ាស៊ីន។ នាងផ្តោតលើការរចនាដំណោះស្រាយដំណើរការឯកសារឆ្លាតវៃសម្រាប់អតិថិជន AWS ។ នៅខាងក្រៅការងារ នាងចូលចិត្តរាំសាល់សា និងបាឆាតា។
ឈិន រ៉ាណេ គឺជាស្ថាបត្យករឯកទេសដំណោះស្រាយ AI/ML នៅ Amazon Web Services។ នាងមានចំណង់ចំណូលចិត្តលើគណិតវិទ្យាអនុវត្ត និងការរៀនម៉ាស៊ីន។ នាងផ្តោតលើការរចនាដំណោះស្រាយដំណើរការឯកសារឆ្លាតវៃសម្រាប់អតិថិជន AWS ។ នៅខាងក្រៅការងារ នាងចូលចិត្តរាំសាល់សា និងបាឆាតា។
- SEO ដែលដំណើរការដោយមាតិកា និងការចែកចាយ PR ។ ទទួលបានការពង្រីកថ្ងៃនេះ។
- PlatoData.Network Vertical Generative Ai. ផ្តល់អំណាចដល់ខ្លួនអ្នក។ ចូលប្រើទីនេះ។
- PlatoAiStream Web3 Intelligence ។ ចំណេះដឹងត្រូវបានពង្រីក។ ចូលប្រើទីនេះ។
- ផ្លាតូអេសជី។ កាបូន CleanTech, ថាមពល, បរិស្ថាន, ពន្លឺព្រះអាទិត្យ ការគ្រប់គ្រងកាកសំណល់។ ចូលប្រើទីនេះ។
- ផ្លាតូសុខភាព។ ជីវបច្ចេកវិទ្យា និង ភាពវៃឆ្លាត សាកល្បងគ្លីនិក។ ចូលប្រើទីនេះ។
- ប្រភព: https://aws.amazon.com/blogs/machine-learning/build-trust-and-safety-for-generative-ai-applications-with-amazon-comprehend-and-langchain/

