នៅក្នុងទិដ្ឋភាពនៃការវិវត្តនៃផលិតកម្ម ថាមពលផ្លាស់ប្តូរនៃ AI និង machine learning (ML) គឺជាភស្តុតាងដែលជំរុញឱ្យមានបដិវត្តន៍ឌីជីថលដែលសម្រួលប្រតិបត្តិការ និងបង្កើនផលិតភាព។ ទោះជាយ៉ាងណាក៏ដោយ វឌ្ឍនភាពនេះបង្ហាញពីបញ្ហាប្រឈមតែមួយគត់សម្រាប់សហគ្រាសដែលស្វែងរកដំណោះស្រាយដែលផ្អែកលើទិន្នន័យ។ គ្រឿងបរិក្ខារឧស្សាហកម្មជួបប្រជុំជាមួយបរិមាណដ៏ធំនៃទិន្នន័យដែលមិនមានរចនាសម្ព័ន្ធ ដែលមានប្រភពមកពីឧបករណ៍ចាប់សញ្ញា ប្រព័ន្ធតេឡេម៉ែត្រ និងឧបករណ៍ដែលបែកខ្ញែកនៅទូទាំងខ្សែផលិតកម្ម។ ទិន្នន័យពេលវេលាពិតមានសារៈសំខាន់សម្រាប់កម្មវិធីដូចជាការថែទាំព្យាករណ៍ និងការរកឃើញភាពមិនប្រក្រតី ប៉ុន្តែការបង្កើតគំរូ ML ផ្ទាល់ខ្លួនសម្រាប់ករណីប្រើប្រាស់ក្នុងឧស្សាហកម្មនីមួយៗជាមួយនឹងទិន្នន័យស៊េរីពេលវេលាបែបនេះទាមទារពេលវេលា និងធនធានយ៉ាងច្រើនពីអ្នកវិទ្យាសាស្ត្រទិន្នន័យ ដែលរារាំងការទទួលយកយ៉ាងទូលំទូលាយ។
AI បង្កើត ដោយប្រើគំរូគ្រឹះដែលបានបណ្តុះបណ្តាលមុនធំ (FMs) ដូចជា លោក Claude អាចបង្កើតមាតិកាជាច្រើនយ៉ាងយ៉ាងឆាប់រហ័សពីអត្ថបទសន្ទនាទៅកូដកុំព្យូទ័រដោយផ្អែកលើការបញ្ចូលអត្ថបទសាមញ្ញដែលគេស្គាល់ថាជា ការជម្រុញឱ្យបាញ់សូន្យ. នេះលុបបំបាត់តម្រូវការសម្រាប់អ្នកវិទ្យាសាស្ត្រទិន្នន័យក្នុងការអភិវឌ្ឍគំរូ ML ជាក់លាក់ដោយដៃសម្រាប់ករណីប្រើប្រាស់នីមួយៗ ហើយដូច្នេះធ្វើប្រជាធិបតេយ្យដល់ការចូលប្រើ AI ដោយផ្តល់អត្ថប្រយោជន៍ដល់ក្រុមហ៊ុនផលិតតូចៗ។ កម្មករទទួលបានផលិតភាពតាមរយៈការយល់ដឹងដែលបង្កើតដោយ AI វិស្វករអាចរកឃើញភាពមិនប្រក្រតី អ្នកគ្រប់គ្រងសង្វាក់ផ្គត់ផ្គង់បង្កើនប្រសិទ្ធភាពសារពើភ័ណ្ឌ និងភាពជាអ្នកដឹកនាំរបស់រោងចក្រធ្វើការសម្រេចចិត្តដោយទិន្នន័យដែលមានព័ត៌មាន។
ទោះជាយ៉ាងណាក៏ដោយ FMs ឯករាជ្យប្រឈមមុខនឹងដែនកំណត់ក្នុងការគ្រប់គ្រងទិន្នន័យឧស្សាហកម្មស្មុគស្មាញជាមួយនឹងដែនកំណត់ទំហំបរិបទ (ជាធម្មតា ថូខឹនតិចជាង 200,000) ដែលបង្កបញ្ហាប្រឈម។ ដើម្បីដោះស្រាយបញ្ហានេះ អ្នកអាចប្រើសមត្ថភាពរបស់ FM ដើម្បីបង្កើតកូដក្នុងការឆ្លើយតបទៅនឹងសំណួរភាសាធម្មជាតិ (NLQs)។ ភ្នាក់ងារចូលចិត្ត PandasAI ចាប់ផ្តើមដំណើរការកូដនេះនៅលើទិន្នន័យស៊េរីពេលវេលាដែលមានគុណភាពបង្ហាញខ្ពស់ និងដោះស្រាយកំហុសដោយប្រើ FMs ។ PandasAI គឺជាបណ្ណាល័យ Python ដែលបន្ថែមសមត្ថភាព AI ជំនាន់ថ្មីដល់ខ្លាឃ្មុំផេនដា ដែលជាឧបករណ៍វិភាគទិន្នន័យដ៏ពេញនិយម និងរៀបចំ។
ទោះជាយ៉ាងណាក៏ដោយ NLQs ស្មុគស្មាញ ដូចជាដំណើរការទិន្នន័យស៊េរីពេលវេលា ការប្រមូលផ្តុំពហុកម្រិត និងប្រតិបត្តិការតារាងជំនួយអាចផ្តល់ភាពត្រឹមត្រូវនៃអក្សរ Python ដែលមិនស៊ីសង្វាក់គ្នាជាមួយនឹងប្រអប់បញ្ចូលសូន្យ។
ដើម្បីបង្កើនភាពត្រឹមត្រូវនៃការបង្កើតកូដ យើងស្នើឱ្យបង្កើតថាមវន្ត ការជម្រុញការបាញ់ច្រើនដង សម្រាប់ NLQs ។ ការជម្រុញការបាញ់ច្រើនផ្តល់នូវបរិបទបន្ថែមដល់ FM ដោយបង្ហាញវានូវឧទាហរណ៍ជាច្រើននៃលទ្ធផលដែលចង់បានសម្រាប់ការជម្រុញស្រដៀងគ្នា បង្កើនភាពត្រឹមត្រូវ និងស្ថិរភាព។ នៅក្នុងការបង្ហោះនេះ ការជម្រុញការបាញ់ច្រើនត្រូវបានទាញយកពីការបង្កប់ដែលមានកូដ Python ជោគជ័យដំណើរការលើប្រភេទទិន្នន័យស្រដៀងគ្នា (ឧទាហរណ៍ ទិន្នន័យស៊េរីពេលវេលាដែលមានគុណភាពបង្ហាញខ្ពស់ពីឧបករណ៍ Internet of Things)។ ប្រអប់បញ្ចូលបាញ់ច្រើនដែលបង្កើតដោយថាមវន្តផ្តល់នូវបរិបទដែលពាក់ព័ន្ធបំផុតដល់ FM និងបង្កើនសមត្ថភាពរបស់ FM ក្នុងការគណនាគណិតវិទ្យាកម្រិតខ្ពស់ ដំណើរការទិន្នន័យស៊េរីពេលវេលា និងការយល់ដឹងអក្សរកាត់ទិន្នន័យ។ ការឆ្លើយតបដែលប្រសើរឡើងនេះជួយសម្រួលដល់កម្មករសហគ្រាស និងក្រុមប្រតិបត្តិការក្នុងការចូលរួមជាមួយទិន្នន័យ ទទួលបានការយល់ដឹងដោយមិនទាមទារជំនាញវិទ្យាសាស្ត្រទិន្នន័យទូលំទូលាយ។
លើសពីការវិភាគទិន្នន័យស៊េរីពេលវេលា FMs បង្ហាញថាមានតម្លៃនៅក្នុងកម្មវិធីឧស្សាហកម្មផ្សេងៗ។ ក្រុមថែទាំវាយតម្លៃសុខភាពទ្រព្យសម្បត្តិ ចាប់យករូបភាពសម្រាប់ ការទទួលស្គាល់របស់ក្រុមហ៊ុន Amazon ។-ការសង្ខេបមុខងារផ្អែកលើ និងការវិភាគមូលហេតុដើមមិនប្រក្រតី ដោយប្រើការស្វែងរកឆ្លាតវៃជាមួយ ទាញយកជំនាន់ដែលបានបន្ថែម (RAG) ។ ដើម្បីសម្រួលលំហូរការងារទាំងនេះ AWS បានណែនាំ ក្រុមហ៊ុន Amazon Bedrockអនុញ្ញាតឱ្យអ្នកបង្កើត និងធ្វើមាត្រដ្ឋានកម្មវិធី AI ជំនាន់ថ្មីជាមួយ FMs ដែលបានទទួលការបណ្តុះបណ្តាលជាមុនដូចជា ក្លូដ v2។ ជាមួយ មូលដ្ឋានចំណេះដឹងសម្រាប់ Amazon Bedrockអ្នកអាចធ្វើឱ្យដំណើរការអភិវឌ្ឍន៍ RAG មានភាពសាមញ្ញ ដើម្បីផ្តល់នូវការវិភាគមូលហេតុនៃភាពមិនប្រក្រតីដែលត្រឹមត្រូវជាងមុនសម្រាប់កម្មកររោងចក្រ។ ការបង្ហោះរបស់យើងបង្ហាញពីជំនួយការឆ្លាតវៃសម្រាប់ករណីប្រើប្រាស់ក្នុងឧស្សាហកម្មដែលដំណើរការដោយ Amazon Bedrock ដោះស្រាយបញ្ហាប្រឈម NLQ បង្កើតការសង្ខេបផ្នែកពីរូបភាព និងបង្កើនការឆ្លើយតប FM សម្រាប់ការធ្វើរោគវិនិច្ឆ័យឧបករណ៍តាមរយៈវិធីសាស្រ្ត RAG ។
ទិដ្ឋភាពទូទៅនៃដំណោះស្រាយ
ដ្យាក្រាមខាងក្រោមបង្ហាញពីស្ថាបត្យកម្មដំណោះស្រាយ។
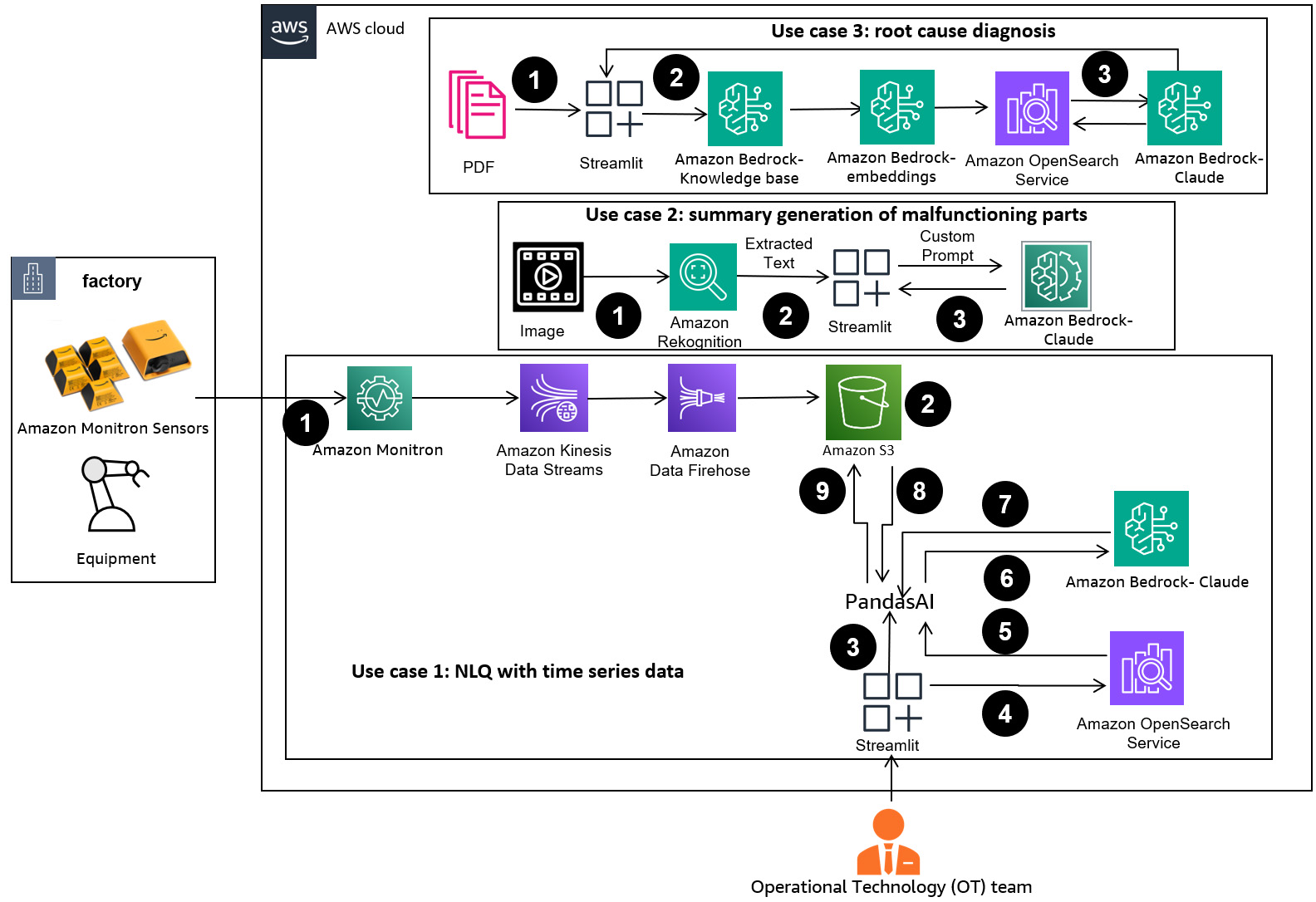
ដំណើរការការងាររួមមានករណីប្រើប្រាស់បីផ្សេងគ្នា៖
ប្រើករណីទី 1: NLQ ជាមួយនឹងទិន្នន័យស៊េរីពេលវេលា
លំហូរការងារសម្រាប់ NLQ ជាមួយនឹងទិន្នន័យស៊េរីពេលវេលាមានជំហានដូចខាងក្រោមៈ
- យើងប្រើប្រព័ន្ធត្រួតពិនិត្យស្ថានភាពដែលមានសមត្ថភាព ML សម្រាប់ការរកឃើញភាពមិនប្រក្រតី ដូចជា ក្រុមហ៊ុន Amazon Monitronដើម្បីតាមដានសុខភាពឧបករណ៍ឧស្សាហកម្ម។ Amazon Monitron អាចរកឃើញការបរាជ័យឧបករណ៍ដែលអាចកើតមានពីការរំញ័រ និងការវាស់សីតុណ្ហភាពរបស់ឧបករណ៍។
- យើងប្រមូលទិន្នន័យស៊េរីពេលវេលាដោយដំណើរការ ក្រុមហ៊ុន Amazon Monitron ទិន្នន័យតាមរយៈ ស្ទ្រីមទិន្នន័យអាម៉ាហ្សូន Kinesis និង Amazon Data Firehoseបំប្លែងវាទៅជាទម្រង់ CSV តារាង ហើយរក្សាទុកវាក្នុង សេវាកម្មផ្ទុកសាមញ្ញរបស់ក្រុមហ៊ុន Amazon (ក្រុមហ៊ុន Amazon S3) ដាក់ធុង។
- អ្នកប្រើប្រាស់ចុងក្រោយអាចចាប់ផ្តើមជជែកជាមួយទិន្នន័យស៊េរីពេលវេលារបស់ពួកគេនៅក្នុង Amazon S3 ដោយផ្ញើសំណួរភាសាធម្មជាតិទៅកាន់កម្មវិធី Streamlit ។
- កម្មវិធី Streamlit បញ្ជូនសំណួរអ្នកប្រើប្រាស់ទៅកាន់ គំរូបង្កប់អត្ថបទ Amazon Bedrock Titan ដើម្បីបង្កប់សំណួរនេះ និងអនុវត្តការស្វែងរកស្រដៀងគ្នានៅក្នុងមួយ។ សេវាកម្ម Amazon OpenSearch សន្ទស្សន៍ដែលមាន NLQs ពីមុន និងកូដឧទាហរណ៍។
- បន្ទាប់ពីការស្វែងរកភាពស្រដៀងគ្នា គំរូស្រដៀងគ្នាកំពូល រួមទាំងសំណួរ NLQ គ្រោងការណ៍ទិន្នន័យ និងកូដ Python ត្រូវបានបញ្ចូលក្នុងប្រអប់បញ្ចូលផ្ទាល់ខ្លួន។
- PandasAI ផ្ញើការជម្រុញផ្ទាល់ខ្លួននេះទៅកាន់ម៉ូដែល Amazon Bedrock Claude v2 ។
- កម្មវិធីនេះប្រើភ្នាក់ងារ PandasAI ដើម្បីធ្វើអន្តរកម្មជាមួយគំរូ Amazon Bedrock Claude v2 ដោយបង្កើតកូដ Python សម្រាប់ការវិភាគទិន្នន័យ Amazon Monitron និងការឆ្លើយតប NLQ ។
- បន្ទាប់ពីម៉ូដែល Amazon Bedrock Claude v2 ត្រឡប់លេខកូដ Python នោះ PandasAI ដំណើរការសំណួរ Python លើទិន្នន័យ Amazon Monitron ដែលបានបង្ហោះពីកម្មវិធី ដោយប្រមូលលទ្ធផលកូដ និងដោះស្រាយការព្យាយាមឡើងវិញចាំបាច់សម្រាប់ការរត់ដែលបរាជ័យ។
- កម្មវិធី Streamlit ប្រមូលការឆ្លើយតបតាមរយៈ PandasAI និងផ្តល់លទ្ធផលដល់អ្នកប្រើប្រាស់។ ប្រសិនបើលទ្ធផលគឺពេញចិត្ត អ្នកប្រើប្រាស់អាចសម្គាល់វាថាមានប្រយោជន៍ ដោយរក្សាទុក NLQ និងកូដ Python ដែលបង្កើតដោយ Claude នៅក្នុងសេវាកម្ម OpenSearch ។
ការប្រើប្រាស់ករណីទី 2៖ ការបង្កើតផ្នែកដែលដំណើរការដោយសង្ខេប
ករណីប្រើប្រាស់ជំនាន់សង្ខេបរបស់យើងមានជំហានដូចខាងក្រោមៈ
- បន្ទាប់ពីអ្នកប្រើប្រាស់ដឹងថាទ្រព្យសកម្មឧស្សាហកម្មណាមួយបង្ហាញអាកប្បកិរិយាមិនប្រក្រតី ពួកគេអាចបង្ហោះរូបភាពនៃផ្នែកដែលមានដំណើរការខុសប្រក្រតី ដើម្បីកំណត់ថាតើមានអ្វីមួយខុសប្រក្រតីជាមួយផ្នែកនេះ យោងទៅតាមលក្ខណៈបច្ចេកទេស និងលក្ខខណ្ឌប្រតិបត្តិការរបស់វា។
- អ្នកប្រើអាចប្រើឯកសារ Amazon Recognition DetectText API ដើម្បីទាញយកទិន្នន័យអត្ថបទពីរូបភាពទាំងនេះ។
- ទិន្នន័យអត្ថបទដែលបានស្រង់ចេញត្រូវបានរួមបញ្ចូលនៅក្នុងប្រអប់បញ្ចូលសម្រាប់គំរូ Amazon Bedrock Claude v2 ដែលអនុញ្ញាតឱ្យម៉ូដែលនេះបង្កើតការសង្ខេប 200 ពាក្យនៃផ្នែកដែលដំណើរការខុសប្រក្រតី។ អ្នកប្រើប្រាស់អាចប្រើប្រាស់ព័ត៌មាននេះ ដើម្បីត្រួតពិនិត្យផ្នែកបន្ថែម។
ករណីទី ៣៖ ការធ្វើរោគវិនិច្ឆ័យមូលហេតុ
ករណីប្រើការធ្វើរោគវិនិច្ឆ័យមូលហេតុឫសគល់របស់យើងមានជំហានដូចខាងក្រោមៈ
- អ្នកប្រើទទួលបានទិន្នន័យសហគ្រាសក្នុងទម្រង់ឯកសារផ្សេងៗ (PDF, TXT និងច្រើនទៀត) ដែលទាក់ទងនឹងទ្រព្យសកម្មដែលមិនដំណើរការ ហើយផ្ទុកឡើងពួកវាទៅធុងទឹក S3។
- មូលដ្ឋានចំណេះដឹងនៃឯកសារទាំងនេះត្រូវបានបង្កើតនៅក្នុង Amazon Bedrock ជាមួយនឹងគំរូបង្កប់អត្ថបទ Titan និងហាងវ៉ិចទ័រ OpenSearch Service លំនាំដើម។
- អ្នកប្រើចោទជាសំណួរទាក់ទងនឹងការធ្វើរោគវិនិច្ឆ័យរកមូលហេតុសម្រាប់ឧបករណ៍មិនដំណើរការ។ ចម្លើយត្រូវបានបង្កើតតាមរយៈមូលដ្ឋានចំណេះដឹង Amazon Bedrock ជាមួយនឹងវិធីសាស្រ្ត RAG ។
តម្រូវការជាមុន
ដើម្បីអនុវត្តតាមការប្រកាសនេះ អ្នកគួរតែបំពេញតាមលក្ខខណ្ឌខាងក្រោម៖
ដាក់ពង្រាយហេដ្ឋារចនាសម្ព័ន្ធដំណោះស្រាយ
ដើម្បីរៀបចំធនធានដំណោះស្រាយរបស់អ្នក សូមបំពេញជំហានខាងក្រោម៖
- ដាក់ពង្រាយ AWS CloudFormation
ពុម្ព opensearchsagemaker.ymlដែលបង្កើតការប្រមូល និងលិបិក្រមសេវាកម្ម OpenSearch ក្រុមហ៊ុន Amazon SageMaker សៀវភៅកត់ត្រា និងធុង S3 ។ អ្នកអាចដាក់ឈ្មោះជង់ AWS CloudFormation នេះថាជា៖
genai-sagemaker. - បើកឧទាហរណ៍សៀវភៅកត់ត្រា SageMaker នៅក្នុង JupyterLab ។ អ្នកនឹងឃើញដូចខាងក្រោម GitHub repo បានទាញយករួចហើយនៅលើឧទាហរណ៍នេះ៖ ការដោះសោ-the-potential-of-generative-ai-in-ឧស្សាហកម្ម-ប្រតិបត្តិការ.
- ដំណើរការសៀវភៅកត់ត្រាពីថតខាងក្រោមនៅក្នុងឃ្លាំងនេះ៖ ដោះសោ-the-potential-of-generative-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. សៀវភៅកត់ត្រានេះនឹងផ្ទុកសន្ទស្សន៍សេវាកម្ម OpenSearch ដោយប្រើសៀវភៅកត់ត្រា SageMaker ដើម្បីរក្សាទុកគូតម្លៃគន្លឹះពី ឧទាហរណ៍ 23 NLQ ដែលមានស្រាប់.
- ផ្ទុកឡើងឯកសារពីថតទិន្នន័យ ទ្រព្យសកម្មpartdoc នៅក្នុងឃ្លាំង GitHub ទៅធុង S3 ដែលបានរាយក្នុងលទ្ធផលជង់ CloudFormation ។

បន្ទាប់មក អ្នកបង្កើតមូលដ្ឋានចំណេះដឹងសម្រាប់ឯកសារនៅក្នុង Amazon S3 ។
- នៅលើកុងសូល Amazon Bedrock សូមជ្រើសរើស មូលដ្ឋានចំណេះដឹង នៅក្នុងផ្ទាំងរុករក។
- ជ្រើស បង្កើតមូលដ្ឋានចំណេះដឹង.
- សម្រាប់ ឈ្មោះមូលដ្ឋានចំណេះដឹងបញ្ចូលឈ្មោះ។
- សម្រាប់ តួនាទីពេលរត់ជ្រើសរើស បង្កើត និងប្រើប្រាស់តួនាទីសេវាកម្មថ្មី។.

- សម្រាប់ ឈ្មោះប្រភពទិន្នន័យបញ្ចូលឈ្មោះប្រភពទិន្នន័យរបស់អ្នក។
- សម្រាប់ S3 URIបញ្ចូលផ្លូវ S3 នៃធុងដែលអ្នកបានបង្ហោះឯកសារមូលហេតុឫសគល់។
- ជ្រើស បន្ទាប់.
 គំរូបង្កប់ Titan ត្រូវបានជ្រើសរើសដោយស្វ័យប្រវត្តិ។
គំរូបង្កប់ Titan ត្រូវបានជ្រើសរើសដោយស្វ័យប្រវត្តិ។ - ជ្រើសប៊ូតុង បង្កើតហាងវ៉ិចទ័រថ្មី។.

- ពិនិត្យមើលការកំណត់របស់អ្នក និងបង្កើតមូលដ្ឋានចំណេះដឹងដោយជ្រើសរើស បង្កើតមូលដ្ឋានចំណេះដឹង.
- បន្ទាប់ពីមូលដ្ឋានចំណេះដឹងត្រូវបានបង្កើតដោយជោគជ័យ សូមជ្រើសរើស ធ្វើសមកាលកម្ម ដើម្បីធ្វើសមកាលកម្មធុង S3 ជាមួយនឹងមូលដ្ឋានចំណេះដឹង។

- បន្ទាប់ពីអ្នកបង្កើតមូលដ្ឋានចំណេះដឹងរួច អ្នកអាចសាកល្បងវិធីសាស្រ្ត RAG សម្រាប់ការធ្វើរោគវិនិច្ឆ័យមូលហេតុឫសគល់ដោយសួរសំណួរដូចជា "My actuator ធ្វើដំណើរយឺត តើអាចមានបញ្ហាអ្វី?"

ជំហានបន្ទាប់គឺត្រូវដាក់ឱ្យប្រើប្រាស់កម្មវិធីជាមួយនឹងកញ្ចប់បណ្ណាល័យដែលត្រូវការនៅលើកុំព្យូទ័ររបស់អ្នក ឬ EC2 instance (Ubuntu Server 22.04 LTS)។
- កំណត់អត្តសញ្ញាណ AWS របស់អ្នក។ ជាមួយ AWS CLI នៅលើកុំព្យូទ័រក្នុងតំបន់របស់អ្នក។ សម្រាប់ភាពសាមញ្ញ អ្នកអាចប្រើតួនាទីអ្នកគ្រប់គ្រងដូចគ្នាដែលអ្នកធ្លាប់ប្រើដើម្បីដាក់ពង្រាយ CloudFormation stack ។ ប្រសិនបើអ្នកកំពុងប្រើ Amazon EC2, ភ្ជាប់តួនាទី IAM សមស្របទៅនឹងឧទាហរណ៍.
- ក្លូន GitHub repo:
- ផ្លាស់ប្តូរថតឯកសារទៅ
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcនិងរត់setup.shស្គ្រីបនៅក្នុងថតនេះដើម្បីដំឡើងកញ្ចប់ដែលត្រូវការ រួមទាំង LangChain និង PandasAI៖cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - ដំណើរការកម្មវិធី Streamlit ដោយប្រើពាក្យបញ្ជាខាងក្រោម៖
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
ផ្តល់ការប្រមូលសេវាកម្ម OpenSearch ARN ដែលអ្នកបានបង្កើតនៅក្នុង Amazon Bedrock ពីជំហានមុន។
ជជែកជាមួយជំនួយការសុខភាពទ្រព្យសម្បត្តិរបស់អ្នក។
បន្ទាប់ពីអ្នកបញ្ចប់ការដាក់ពង្រាយពីចុងដល់ចប់ អ្នកអាចចូលប្រើកម្មវិធីតាមរយៈ localhost នៅលើច្រក 8501 ដែលបើកបង្អួចកម្មវិធីរុករកតាមអ៊ីនធឺណិតជាមួយនឹងចំណុចប្រទាក់គេហទំព័រ។ ប្រសិនបើអ្នកដាក់ពង្រាយកម្មវិធីនៅលើឧទាហរណ៍ EC2 ។ អនុញ្ញាតឱ្យចូលប្រើច្រក 8501 តាមរយៈច្បាប់ចូលក្រុមសុវត្ថិភាព. អ្នកអាចរុករកទៅផ្ទាំងផ្សេងគ្នាសម្រាប់ករណីប្រើប្រាស់ផ្សេងៗ។
ស្វែងយល់ពីករណីប្រើប្រាស់ 1
ដើម្បីស្វែងយល់ពីករណីប្រើប្រាស់ដំបូង សូមជ្រើសរើស ទិន្នន័យ និងគំនូសតាង. ចាប់ផ្តើមដោយការបង្ហោះទិន្នន័យស៊េរីពេលវេលារបស់អ្នក។ ប្រសិនបើអ្នកមិនមានឯកសារទិន្នន័យស៊េរីពេលវេលាដែលមានស្រាប់សម្រាប់ប្រើទេ អ្នកអាចផ្ទុកឯកសារខាងក្រោមបាន។ ឯកសារ CSV គំរូ ជាមួយនឹងទិន្នន័យគម្រោង Amazon Monitron អនាមិក។ ប្រសិនបើអ្នកមានគម្រោង Amazon Monitron រួចហើយ សូមមើល បង្កើតការយល់ដឹងដែលអាចអនុវត្តបានសម្រាប់ការគ្រប់គ្រងការថែទាំដែលព្យាករណ៍ជាមួយ Amazon Monitron និង Amazon Kinesis ដើម្បីចាក់ផ្សាយទិន្នន័យ Amazon Monitron របស់អ្នកទៅ Amazon S3 ហើយប្រើទិន្នន័យរបស់អ្នកជាមួយកម្មវិធីនេះ។
នៅពេលការបង្ហោះបានបញ្ចប់ សូមបញ្ចូលសំណួរដើម្បីចាប់ផ្តើមការសន្ទនាជាមួយទិន្នន័យរបស់អ្នក។ របារចំហៀងខាងឆ្វេងផ្តល់នូវសំណួរឧទាហរណ៍ជាច្រើនសម្រាប់ភាពងាយស្រួលរបស់អ្នក។ រូបថតអេក្រង់ខាងក្រោមបង្ហាញពីការឆ្លើយតប និងលេខកូដ Python ដែលបង្កើតដោយ FM នៅពេលបញ្ចូលសំណួរដូចជា "ប្រាប់ខ្ញុំពីចំនួនឧបករណ៍ចាប់សញ្ញាតែមួយគត់សម្រាប់គេហទំព័រនីមួយៗដែលបង្ហាញជា Warning ឬ Alarm រៀងគ្នា?" (សំណួរកម្រិតរឹង) ឬ "សម្រាប់ឧបករណ៍ចាប់សញ្ញាដែលបង្ហាញសញ្ញាសីតុណ្ហភាពថាមិនមានសុខភាពល្អ តើអ្នកអាចគណនារយៈពេលជាថ្ងៃសម្រាប់ឧបករណ៍ចាប់សញ្ញានីមួយៗដែលបង្ហាញសញ្ញារំញ័រមិនធម្មតាបានទេ?" (សំណួរកម្រិតប្រឈម)។ កម្មវិធីនឹងឆ្លើយសំណួររបស់អ្នក ហើយនឹងបង្ហាញស្គ្រីប Python នៃការវិភាគទិន្នន័យដែលវាបានអនុវត្តដើម្បីបង្កើតលទ្ធផលបែបនេះ។
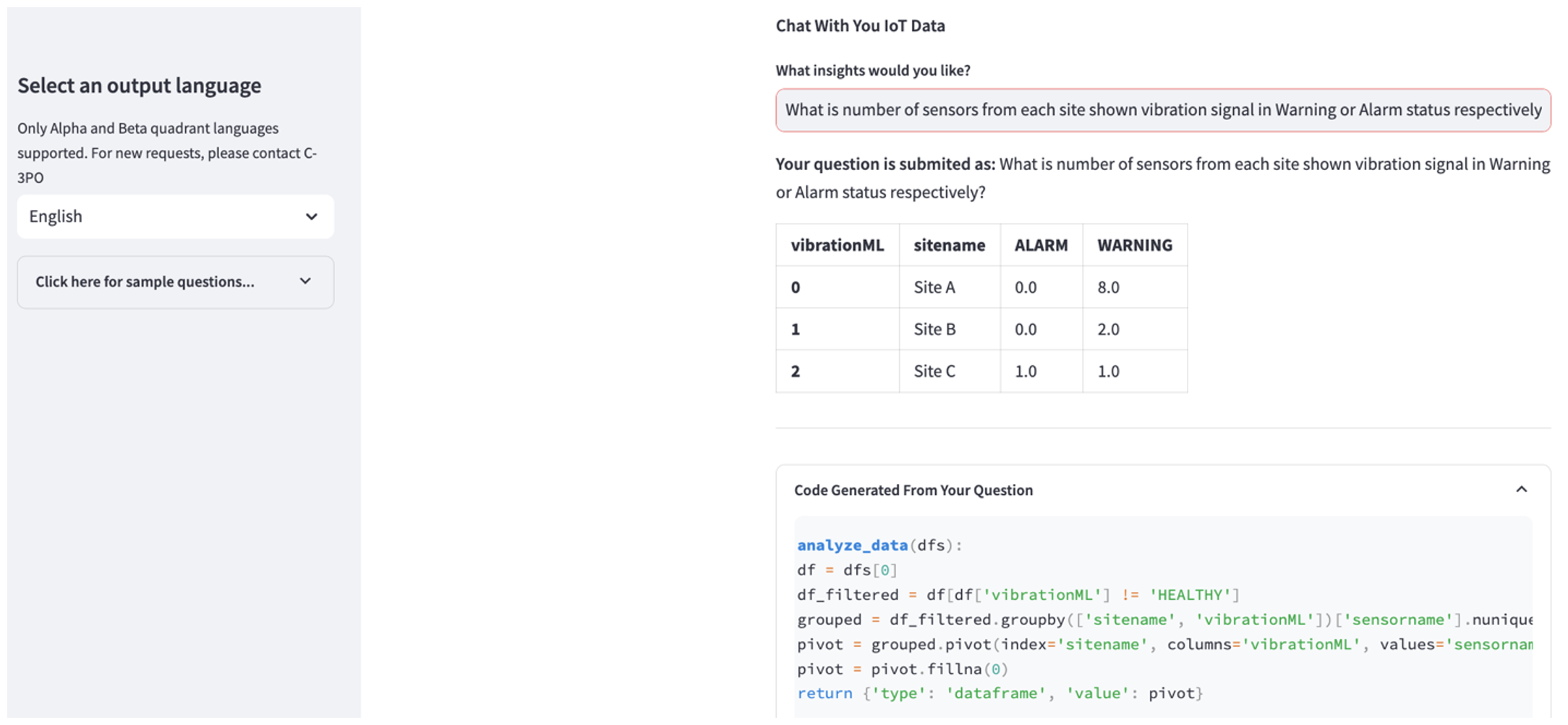

ប្រសិនបើអ្នកពេញចិត្តនឹងចម្លើយ អ្នកអាចសម្គាល់វាជា ប្រយោជន៍រក្សាទុក NLQ និងកូដ Python ដែលបង្កើតដោយ Claude ទៅសន្ទស្សន៍សេវាកម្ម OpenSearch ។

ស្វែងយល់ពីករណីប្រើប្រាស់ 2
ដើម្បីស្វែងយល់ពីករណីប្រើប្រាស់ទីពីរ សូមជ្រើសរើស សង្ខេបរូបភាពដែលបានថត ផ្ទាំងនៅក្នុងកម្មវិធី Streamlit ។ អ្នកអាចបង្ហោះរូបភាពនៃទ្រព្យសកម្មឧស្សាហកម្មរបស់អ្នក ហើយកម្មវិធីនឹងបង្កើតការសង្ខេប 200 ពាក្យនៃលក្ខណៈបច្ចេកទេស និងលក្ខខណ្ឌប្រតិបត្តិការរបស់វាដោយផ្អែកលើព័ត៌មានរូបភាព។ រូបថតអេក្រង់ខាងក្រោមបង្ហាញពីការសង្ខេបដែលបានបង្កើតចេញពីរូបភាពនៃដ្រាយម៉ូទ័រខ្សែក្រវ៉ាត់។ ដើម្បីសាកល្បងមុខងារនេះ ប្រសិនបើអ្នកខ្វះរូបភាពសមរម្យ អ្នកអាចប្រើដូចខាងក្រោម រូបភាពឧទាហរណ៍.

ស្លាកសញ្ញាម៉ូទ័រជណ្តើរយន្ត"ដោយ Clarence Risher ត្រូវបានផ្តល់អាជ្ញាប័ណ្ណក្រោម CC BY-SA 2.0.

ស្វែងយល់ពីករណីប្រើប្រាស់ 3
ដើម្បីស្វែងយល់ពីករណីប្រើប្រាស់ទីបី សូមជ្រើសរើស ការធ្វើរោគវិនិច្ឆ័យមូលហេតុ ផ្ទាំង។ បញ្ចូលសំណួរទាក់ទងនឹងទ្រព្យសកម្មឧស្សាហកម្មដែលខូចរបស់អ្នក ដូចជា "ឧបករណ៍ដំណើរការរបស់ខ្ញុំដំណើរការយឺត តើមានបញ្ហាអ្វី?" ដូចដែលបានបង្ហាញនៅក្នុងរូបថតអេក្រង់ខាងក្រោម កម្មវិធីផ្តល់នូវការឆ្លើយតបជាមួយនឹងសម្រង់ឯកសារប្រភពដែលប្រើដើម្បីបង្កើតចម្លើយ។

ការប្រើប្រាស់ករណីទី 1: ព័ត៌មានលម្អិតអំពីការរចនា
នៅក្នុងផ្នែកនេះ យើងពិភាក្សាអំពីព័ត៌មានលម្អិតនៃការរចនានៃដំណើរការកម្មវិធីសម្រាប់ករណីប្រើប្រាស់ដំបូង។
ការស្ថាបនាប្រអប់បញ្ចូលផ្ទាល់ខ្លួន
សំណួរភាសាធម្មជាតិរបស់អ្នកប្រើប្រាស់ភ្ជាប់មកជាមួយកម្រិតពិបាកផ្សេងៗគ្នា៖ ងាយស្រួល ពិបាក និងបញ្ហាប្រឈម។
សំណួរត្រង់អាចរួមបញ្ចូលសំណើដូចខាងក្រោមៈ
- ជ្រើសរើសតម្លៃពិសេស
- រាប់ចំនួនសរុប
- តម្រៀបតម្លៃ
សម្រាប់សំណួរទាំងនេះ PandasAI អាចធ្វើអន្តរកម្មដោយផ្ទាល់ជាមួយ FM ដើម្បីបង្កើតស្គ្រីប Python សម្រាប់ដំណើរការ។
សំណួរពិបាកទាមទារប្រតិបត្តិការប្រមូលផ្តុំជាមូលដ្ឋាន ឬការវិភាគស៊េរីពេលវេលាដូចជា៖
- ជ្រើសរើសតម្លៃដំបូង ហើយលទ្ធផលជាក្រុមតាមឋានានុក្រម
- អនុវត្តស្ថិតិបន្ទាប់ពីការជ្រើសរើសកំណត់ត្រាដំបូង
- ចំនួនត្រាពេលវេលា (ឧទាហរណ៍ អប្បបរមា និងអតិបរមា)
សម្រាប់សំណួរពិបាក គំរូប្រអប់បញ្ចូលដែលមានការណែនាំលម្អិតជាជំហាន ៗ ជួយ FMs ក្នុងការផ្តល់នូវការឆ្លើយតបត្រឹមត្រូវ។
សំណួរកម្រិត Challenge ត្រូវការការគណនាគណិតវិទ្យាកម្រិតខ្ពស់ និងដំណើរការស៊េរីពេលវេលាដូចជា៖
- គណនារយៈពេលមិនប្រក្រតីសម្រាប់ឧបករណ៍ចាប់សញ្ញានីមួយៗ
- គណនាឧបករណ៍ចាប់សញ្ញាមិនប្រក្រតីសម្រាប់គេហទំព័រជារៀងរាល់ខែ
- ប្រៀបធៀបការអានរបស់ឧបករណ៍ចាប់សញ្ញានៅក្រោមប្រតិបត្តិការធម្មតា និងលក្ខខណ្ឌមិនប្រក្រតី
សម្រាប់សំណួរទាំងនេះ អ្នកអាចប្រើការបាញ់ច្រើននៅក្នុងប្រអប់បញ្ចូលផ្ទាល់ខ្លួន ដើម្បីបង្កើនភាពត្រឹមត្រូវនៃការឆ្លើយតប។ ការបាញ់ប្រហារច្រើនបែបនេះបង្ហាញឧទាហរណ៍នៃដំណើរការស៊េរីពេលវេលាកម្រិតខ្ពស់ និងការគណនាគណិតវិទ្យា ហើយនឹងផ្តល់បរិបទសម្រាប់ FM ដើម្បីអនុវត្តការសន្និដ្ឋានពាក់ព័ន្ធលើការវិភាគស្រដៀងគ្នា។ ការបញ្ចូលឧទាហរណ៍ដែលពាក់ព័ន្ធបំផុតពីធនាគារសំណួរ NLQ ទៅក្នុងប្រអប់បញ្ចូលអាចជាបញ្ហាប្រឈមមួយ។ ដំណោះស្រាយមួយគឺបង្កើតការបង្កប់ពីគំរូសំណួរ NLQ ដែលមានស្រាប់ ហើយរក្សាទុកការបង្កប់ទាំងនេះនៅក្នុងហាងវ៉ិចទ័រដូចជា OpenSearch Service។ នៅពេលដែលសំណួរត្រូវបានផ្ញើទៅកាន់កម្មវិធី Streamlit សំណួរនឹងត្រូវបានសរសេរជាវ៉ិចទ័រ Bedrock ការបង្កប់. ការបង្កប់ដែលពាក់ព័ន្ធបំផុតរបស់ N កំពូលទៅនឹងសំណួរនោះត្រូវបានទាញយកមកវិញដោយប្រើ opensearch_vector_search.similarity_search ហើយបញ្ចូលទៅក្នុងគំរូប្រអប់បញ្ចូលជាប្រអប់បញ្ចូលពហុបាញ់។
ដ្យាក្រាមខាងក្រោមបង្ហាញពីដំណើរការការងារនេះ។
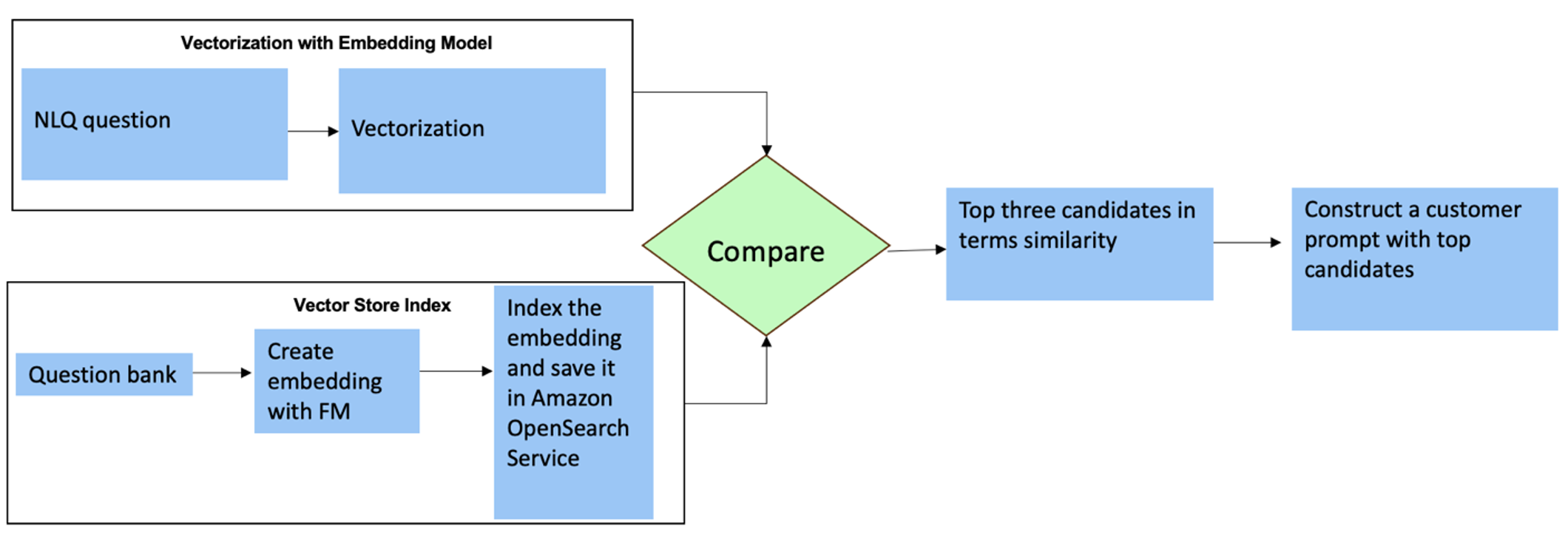
ស្រទាប់បង្កប់ត្រូវបានសាងសង់ដោយប្រើឧបករណ៍សំខាន់ៗចំនួនបី៖
- ម៉ូដែលបង្កប់ - យើងប្រើ Amazon Titan Embeddings ដែលអាចរកបានតាមរយៈ Amazon Bedrock (amazon.titan-embed-text-v1) ដើម្បីបង្កើតតំណាងជាលេខនៃឯកសារអត្ថបទ។
- ហាងវ៉ិចទ័រ - សម្រាប់ហាងវ៉ិចទ័ររបស់យើង យើងប្រើប្រាស់សេវាកម្ម OpenSearch តាមរយៈក្របខណ្ឌ LangChain ដែលសម្រួលការផ្ទុកបង្កប់ដែលបង្កើតចេញពីឧទាហរណ៍ NLQ នៅក្នុងសៀវភៅកត់ត្រានេះ។
- សន្ទស្សន៍ - សន្ទស្សន៍សេវាកម្ម OpenSearch ដើរតួនាទីយ៉ាងសំខាន់ក្នុងការប្រៀបធៀបការបញ្ចូលបញ្ចូលទៅក្នុងឯកសារបង្កប់ និងសម្រួលដល់ការទាញយកឯកសារពាក់ព័ន្ធ។ ដោយសារតែកូដឧទាហរណ៍ Python ត្រូវបានរក្សាទុកជាឯកសារ JSON ពួកវាត្រូវបានដាក់លិបិក្រមនៅក្នុងសេវាកម្ម OpenSearch ជាវ៉ិចទ័រតាមរយៈ OpenSearchVevtorSearch.fromtexts ការហៅ API ។
ការប្រមូលផ្តុំជាបន្តបន្ទាប់នៃគំរូសវនកម្មរបស់មនុស្សតាមរយៈ Streamlit
នៅដើមដំបូងនៃការអភិវឌ្ឍន៍កម្មវិធី យើងបានចាប់ផ្តើមជាមួយនឹងឧទាហរណ៍ដែលបានរក្សាទុកតែ 23 នៅក្នុងសន្ទស្សន៍សេវាកម្ម OpenSearch ជាការបង្កប់។ នៅពេលដែលកម្មវិធីនេះដំណើរការនៅក្នុងវិស័យ អ្នកប្រើប្រាស់ចាប់ផ្តើមបញ្ចូល NLQs របស់ពួកគេតាមរយៈកម្មវិធី។ ទោះយ៉ាងណាក៏ដោយ ដោយសារឧទាហរណ៍មានកម្រិតដែលមាននៅក្នុងគំរូ NLQs មួយចំនួនប្រហែលជាមិនអាចរកឃើញការជម្រុញស្រដៀងគ្នានេះទេ។ ដើម្បីបង្កើនការបង្កប់ទាំងនេះជាបន្តបន្ទាប់ និងផ្តល់នូវការជម្រុញអ្នកប្រើប្រាស់ដែលពាក់ព័ន្ធជាងមុន អ្នកអាចប្រើកម្មវិធី Streamlit សម្រាប់ការប្រមូលផ្តុំឧទាហរណ៍ដែលធ្វើសវនកម្មដោយមនុស្ស។
នៅក្នុងកម្មវិធី មុខងារខាងក្រោមបម្រើគោលបំណងនេះ។ នៅពេលដែលអ្នកប្រើប្រាស់ចុងក្រោយយល់ថាលទ្ធផលមានប្រយោជន៍ ហើយជ្រើសរើស ប្រយោជន៍កម្មវិធីនេះអនុវត្តតាមជំហានទាំងនេះ៖
- ប្រើវិធីហៅត្រឡប់ពី PandasAI ដើម្បីប្រមូលស្គ្រីប Python ។
- ធ្វើទ្រង់ទ្រាយអក្សរ Python បញ្ចូលសំណួរ និងទិន្នន័យមេតា CSV ទៅក្នុងខ្សែអក្សរ។
- ពិនិត្យមើលថាតើឧទាហរណ៍ NLQ នេះមានរួចហើយនៅក្នុងសន្ទស្សន៍សេវាកម្ម OpenSearch បច្ចុប្បន្នដោយប្រើ opensearch_vector_search.similarity_search_with_score.
- ប្រសិនបើមិនមានឧទាហរណ៍ស្រដៀងគ្នាទេ NLQ នេះត្រូវបានបន្ថែមទៅសន្ទស្សន៍សេវាកម្ម OpenSearch ដោយប្រើ opensearch_vector_search.add_texts.
ក្នុងករណីដែលអ្នកប្រើប្រាស់ជ្រើសរើស មិនមានប្រយោជន៍មិនមានចំណាត់ការអ្វីទេ។ ដំណើរការដដែលៗនេះធ្វើឱ្យប្រាកដថាប្រព័ន្ធបន្តធ្វើឱ្យប្រសើរឡើងដោយបញ្ចូលឧទាហរណ៍ដែលរួមចំណែកដោយអ្នកប្រើប្រាស់។
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
តាមរយៈការបញ្ចូលការធ្វើសវនកម្មរបស់មនុស្ស បរិមាណនៃឧទាហរណ៍នៅក្នុងសេវាកម្ម OpenSearch ដែលមានសម្រាប់ការបញ្ចូលភ្លាមៗកើនឡើង នៅពេលដែលកម្មវិធីទទួលបានការប្រើប្រាស់។ សំណុំទិន្នន័យបង្កប់ដែលបានពង្រីកនេះនាំឱ្យបង្កើនភាពត្រឹមត្រូវនៃការស្វែងរកតាមពេលវេលា។ ជាពិសេស សម្រាប់ NLQs ដែលកំពុងប្រឈម ភាពត្រឹមត្រូវនៃការឆ្លើយតបរបស់ FM ឈានដល់ប្រហែល 90% នៅពេលបញ្ចូលគំរូស្រដៀងគ្នាយ៉ាងសកម្មដើម្បីបង្កើតការជម្រុញផ្ទាល់ខ្លួនសម្រាប់សំណួរ NLQ នីមួយៗ។ នេះតំណាងឱ្យការកើនឡើង 28% គួរឱ្យកត់សម្គាល់បើប្រៀបធៀបទៅនឹងសេណារីយ៉ូដែលគ្មានការជម្រុញឱ្យមានការបាញ់ច្រើនដង។
ការប្រើប្រាស់ករណីទី 2: ព័ត៌មានលម្អិតអំពីការរចនា
នៅលើកម្មវិធី Streamlit សង្ខេបរូបភាពដែលបានថត ផ្ទាំង អ្នកអាចបង្ហោះឯកសាររូបភាពដោយផ្ទាល់។ នេះចាប់ផ្តើម Amazon Rekognition API (detect_text API) ទាញយកអត្ថបទពីស្លាករូបភាពដែលលម្អិតអំពីលក្ខណៈម៉ាស៊ីន។ ក្រោយមក ទិន្នន័យអត្ថបទដែលបានស្រង់ចេញត្រូវបានផ្ញើទៅកាន់គំរូ Amazon Bedrock Claude ជាបរិបទនៃការជម្រុញ ដែលបណ្តាលឱ្យមានការសង្ខេបពាក្យ 200 ។
តាមទស្សនៈបទពិសោធន៍របស់អ្នកប្រើ ការបើកមុខងារស្ទ្រីមសម្រាប់កិច្ចការសង្ខេបអត្ថបទគឺសំខាន់បំផុត ដែលអនុញ្ញាតឱ្យអ្នកប្រើប្រាស់អានការសង្ខេបដែលបង្កើតដោយ FM ជាផ្នែកតូចៗជាជាងរង់ចាំលទ្ធផលទាំងមូល។ Amazon Bedrock សម្របសម្រួលការផ្សាយតាមរយៈ API របស់វា (bedrock_runtime.invoke_model_with_response_stream).
ការប្រើប្រាស់ករណីទី 3: ព័ត៌មានលម្អិតអំពីការរចនា
នៅក្នុងសេណារីយ៉ូនេះ យើងបានបង្កើតកម្មវិធី chatbot ដែលផ្តោតលើការវិភាគមូលហេតុឫសគល់ ដោយប្រើប្រាស់វិធីសាស្រ្ត RAG ។ chatbot នេះទាញយកពីឯកសារជាច្រើនដែលទាក់ទងនឹងឧបករណ៍ផ្ទុកដើម្បីជួយសម្រួលដល់ការវិភាគមូលហេតុឫសគល់។ chatbot ការវិភាគមូលហេតុដែលមានមូលដ្ឋានលើ RAG នេះប្រើមូលដ្ឋានចំណេះដឹងសម្រាប់បង្កើតតំណាងអត្ថបទវ៉ិចទ័រ ឬការបង្កប់។ មូលដ្ឋានចំណេះដឹងសម្រាប់ Amazon Bedrock គឺជាសមត្ថភាពគ្រប់គ្រងយ៉ាងពេញលេញដែលជួយអ្នកអនុវត្តលំហូរការងារ RAG ទាំងមូល ចាប់ពីការបញ្ចូលទៅការទាញយក និងបង្កើនភ្លាមៗ ដោយមិនចាំបាច់បង្កើតការរួមបញ្ចូលផ្ទាល់ខ្លួនទៅនឹងប្រភពទិន្នន័យ ឬគ្រប់គ្រងលំហូរទិន្នន័យ និងព័ត៌មានលម្អិតអំពីការអនុវត្ត RAG ។
នៅពេលអ្នកពេញចិត្តនឹងការឆ្លើយតបមូលដ្ឋានចំណេះដឹងពី Amazon Bedrock អ្នកអាចបញ្ចូលការឆ្លើយតបពីមូលហេតុឫសគល់ពីមូលដ្ឋានចំណេះដឹងទៅកម្មវិធី Streamlit ។
សម្អាត។
ដើម្បីសន្សំការចំណាយ សូមលុបធនធានដែលអ្នកបានបង្កើតនៅក្នុងប្រកាសនេះ៖
- លុបមូលដ្ឋានចំណេះដឹងពី Amazon Bedrock ។
- លុបសន្ទស្សន៍សេវាកម្ម OpenSearch ។
- លុបជង់ genai-sagemaker CloudFormation ។
- បញ្ឈប់ឧទាហរណ៍ EC2 ប្រសិនបើអ្នកបានប្រើឧទាហរណ៍ EC2 ដើម្បីដំណើរការកម្មវិធី Streamlit ។
សន្និដ្ឋាន
កម្មវិធី AI ជំនាន់ថ្មីបានផ្លាស់ប្តូរដំណើរការអាជីវកម្មផ្សេងៗរួចហើយ បង្កើនផលិតភាពការងារ និងសំណុំជំនាញ។ ទោះជាយ៉ាងណាក៏ដោយ ដែនកំណត់នៃ FMs ក្នុងការគ្រប់គ្រងការវិភាគទិន្នន័យស៊េរីពេលវេលាបានរារាំងការប្រើប្រាស់ពេញលេញរបស់ពួកគេដោយអតិថិជនឧស្សាហកម្ម។ ឧបសគ្គនេះបានរារាំងការអនុវត្ត AI ជំនាន់ថ្មីទៅនឹងប្រភេទទិន្នន័យលេចធ្លោដែលត្រូវបានដំណើរការជារៀងរាល់ថ្ងៃ។
នៅក្នុងការប្រកាសនេះ យើងបានណែនាំដំណោះស្រាយកម្មវិធី AI ជំនាន់ថ្មីដែលត្រូវបានរចនាឡើងដើម្បីកាត់បន្ថយបញ្ហាប្រឈមនេះសម្រាប់អ្នកប្រើប្រាស់ឧស្សាហកម្ម។ កម្មវិធីនេះប្រើភ្នាក់ងារប្រភពបើកចំហ PandasAI ដើម្បីពង្រឹងសមត្ថភាពវិភាគស៊េរីពេលវេលារបស់ FM ។ ជាជាងការបញ្ជូនទិន្នន័យស៊េរីពេលវេលាដោយផ្ទាល់ទៅ FMs កម្មវិធីនេះប្រើ PandasAI ដើម្បីបង្កើតកូដ Python សម្រាប់ការវិភាគទិន្នន័យស៊េរីពេលវេលាដែលមិនមានរចនាសម្ព័ន្ធ។ ដើម្បីបង្កើនភាពត្រឹមត្រូវនៃការបង្កើតកូដ Python ដំណើរការបង្កើតការជម្រុញផ្ទាល់ខ្លួនជាមួយការធ្វើសវនកម្មរបស់មនុស្សត្រូវបានអនុវត្ត។
ដោយទទួលបានសិទ្ធិអំណាចជាមួយនឹងការយល់ដឹងអំពីសុខភាពទ្រព្យសម្បត្តិរបស់ពួកគេ កម្មករឧស្សាហកម្មអាចប្រើប្រាស់យ៉ាងពេញលេញនូវសក្តានុពលនៃ AI ជំនាន់ថ្មីនៅទូទាំងករណីប្រើប្រាស់ផ្សេងៗ រួមទាំងការធ្វើរោគវិនិច្ឆ័យមូលហេតុឫសគល់ និងការធ្វើផែនការជំនួសផ្នែក។ ជាមួយនឹងមូលដ្ឋានចំណេះដឹងសម្រាប់ Amazon Bedrock ដំណោះស្រាយ RAG គឺត្រង់សម្រាប់អ្នកអភិវឌ្ឍន៍ក្នុងការសាងសង់ និងគ្រប់គ្រង។
គន្លងនៃការគ្រប់គ្រងទិន្នន័យ និងប្រតិបត្តិការរបស់សហគ្រាសកំពុងផ្លាស់ប្តូរដោយមិននឹកស្មានដល់ឆ្ពោះទៅរកការធ្វើសមាហរណកម្មកាន់តែស៊ីជម្រៅជាមួយ AI ជំនាន់ថ្មីសម្រាប់ការយល់ដឹងទូលំទូលាយអំពីសុខភាពប្រតិបត្តិការ។ ការផ្លាស់ប្តូរនេះដឹកនាំដោយ Amazon Bedrock ត្រូវបានពង្រីកយ៉ាងខ្លាំងដោយការកើនឡើងដ៏រឹងមាំ និងសក្តានុពលនៃ LLMs ដូចជា Amazon Bedrock Claude ៣ ដើម្បីបង្កើនដំណោះស្រាយបន្ថែមទៀត។ ដើម្បីស្វែងយល់បន្ថែម សូមចូលទៅកាន់ ពិគ្រោះ ឯកសារ Amazon Bedrockនិងទទួលបានដៃនៅលើ សិក្ខាសាលា Amazon Bedrock.
អំពីអ្នកនិពន្ធ
 Julia Hu គឺជាស្ថាបត្យករ AI/ML Solutions Architect នៅ Amazon Web Services ។ នាងមានឯកទេសផ្នែក AI ជំនាន់ថ្មី វិទ្យាសាស្ត្រទិន្នន័យអនុវត្ត និងស្ថាបត្យកម្ម IoT ។ បច្ចុប្បន្ននាងគឺជាផ្នែកនៃក្រុម Amazon Q និងជាសមាជិកសកម្ម/អ្នកណែនាំនៅក្នុងសហគមន៍វាលបច្ចេកទេសរៀនម៉ាស៊ីន។ នាងធ្វើការជាមួយអតិថិជន ចាប់ពីការចាប់ផ្តើមអាជីវកម្មរហូតដល់សហគ្រាស ដើម្បីបង្កើតដំណោះស្រាយ AI ជំនាន់ AWSome ។ នាងមានចំណង់ខ្លាំងជាពិសេសក្នុងការប្រើគំរូភាសាធំសម្រាប់ការវិភាគទិន្នន័យកម្រិតខ្ពស់ និងការស្វែងរកកម្មវិធីជាក់ស្តែងដែលដោះស្រាយបញ្ហាប្រឈមក្នុងពិភពពិត។
Julia Hu គឺជាស្ថាបត្យករ AI/ML Solutions Architect នៅ Amazon Web Services ។ នាងមានឯកទេសផ្នែក AI ជំនាន់ថ្មី វិទ្យាសាស្ត្រទិន្នន័យអនុវត្ត និងស្ថាបត្យកម្ម IoT ។ បច្ចុប្បន្ននាងគឺជាផ្នែកនៃក្រុម Amazon Q និងជាសមាជិកសកម្ម/អ្នកណែនាំនៅក្នុងសហគមន៍វាលបច្ចេកទេសរៀនម៉ាស៊ីន។ នាងធ្វើការជាមួយអតិថិជន ចាប់ពីការចាប់ផ្តើមអាជីវកម្មរហូតដល់សហគ្រាស ដើម្បីបង្កើតដំណោះស្រាយ AI ជំនាន់ AWSome ។ នាងមានចំណង់ខ្លាំងជាពិសេសក្នុងការប្រើគំរូភាសាធំសម្រាប់ការវិភាគទិន្នន័យកម្រិតខ្ពស់ និងការស្វែងរកកម្មវិធីជាក់ស្តែងដែលដោះស្រាយបញ្ហាប្រឈមក្នុងពិភពពិត។
 Sudeesh Sasidharan គឺជាស្ថាបត្យករដំណោះស្រាយជាន់ខ្ពស់នៅ AWS ក្នុងក្រុមថាមពល។ Sudeesh ចូលចិត្តពិសោធន៍ជាមួយបច្ចេកវិទ្យាថ្មីៗ និងការកសាងដំណោះស្រាយប្រកបដោយភាពច្នៃប្រឌិតដែលដោះស្រាយបញ្ហាប្រឈមមុខជំនួញដ៏ស្មុគស្មាញ។ នៅពេលដែលគាត់មិនរចនាដំណោះស្រាយ ឬប្រើប្រាស់បច្ចេកវិទ្យាចុងក្រោយបំផុត អ្នកអាចស្វែងរកគាត់នៅលើទីលានវាយកូនបាល់ដែលកំពុងធ្វើការលើដៃរបស់គាត់។
Sudeesh Sasidharan គឺជាស្ថាបត្យករដំណោះស្រាយជាន់ខ្ពស់នៅ AWS ក្នុងក្រុមថាមពល។ Sudeesh ចូលចិត្តពិសោធន៍ជាមួយបច្ចេកវិទ្យាថ្មីៗ និងការកសាងដំណោះស្រាយប្រកបដោយភាពច្នៃប្រឌិតដែលដោះស្រាយបញ្ហាប្រឈមមុខជំនួញដ៏ស្មុគស្មាញ។ នៅពេលដែលគាត់មិនរចនាដំណោះស្រាយ ឬប្រើប្រាស់បច្ចេកវិទ្យាចុងក្រោយបំផុត អ្នកអាចស្វែងរកគាត់នៅលើទីលានវាយកូនបាល់ដែលកំពុងធ្វើការលើដៃរបស់គាត់។
 នីល ដេសាយ គឺជានាយកប្រតិបត្តិផ្នែកបច្ចេកវិទ្យាដែលមានបទពិសោធន៍ជាង 20 ឆ្នាំក្នុងផ្នែកបញ្ញាសិប្បនិម្មិត (AI) វិទ្យាសាស្ត្រទិន្នន័យ វិស្វកម្មកម្មវិធី និងស្ថាបត្យកម្មសហគ្រាស។ នៅ AWS គាត់ដឹកនាំក្រុមស្ថាបត្យករឯកទេសដំណោះស្រាយសេវាកម្ម AI ទូទាំងពិភពលោក ដែលជួយអតិថិជនបង្កើតដំណោះស្រាយដែលដំណើរការដោយ AI ប្រកបដោយភាពច្នៃប្រឌិត ចែករំលែកការអនុវត្តល្អបំផុតជាមួយអតិថិជន និងជំរុញផែនទីបង្ហាញផ្លូវផលិតផល។ នៅក្នុងតួនាទីពីមុនរបស់គាត់នៅ Vestas, Honeywell និង Quest Diagnostics លោក Neil បានកាន់តួនាទីជាអ្នកដឹកនាំក្នុងការអភិវឌ្ឍន៍ និងចាប់ផ្តើមផលិតផល និងសេវាកម្មប្រកបដោយភាពច្នៃប្រឌិត ដែលបានជួយក្រុមហ៊ុនកែលម្អប្រតិបត្តិការរបស់ពួកគេ កាត់បន្ថយការចំណាយ និងបង្កើនប្រាក់ចំណូល។ គាត់ស្រលាញ់ការប្រើប្រាស់បច្ចេកវិទ្យាដើម្បីដោះស្រាយបញ្ហាក្នុងពិភពពិត និងជាអ្នកគិតយុទ្ធសាស្ត្រជាមួយនឹងកំណត់ត្រាជោគជ័យដែលបង្ហាញឱ្យឃើញ។
នីល ដេសាយ គឺជានាយកប្រតិបត្តិផ្នែកបច្ចេកវិទ្យាដែលមានបទពិសោធន៍ជាង 20 ឆ្នាំក្នុងផ្នែកបញ្ញាសិប្បនិម្មិត (AI) វិទ្យាសាស្ត្រទិន្នន័យ វិស្វកម្មកម្មវិធី និងស្ថាបត្យកម្មសហគ្រាស។ នៅ AWS គាត់ដឹកនាំក្រុមស្ថាបត្យករឯកទេសដំណោះស្រាយសេវាកម្ម AI ទូទាំងពិភពលោក ដែលជួយអតិថិជនបង្កើតដំណោះស្រាយដែលដំណើរការដោយ AI ប្រកបដោយភាពច្នៃប្រឌិត ចែករំលែកការអនុវត្តល្អបំផុតជាមួយអតិថិជន និងជំរុញផែនទីបង្ហាញផ្លូវផលិតផល។ នៅក្នុងតួនាទីពីមុនរបស់គាត់នៅ Vestas, Honeywell និង Quest Diagnostics លោក Neil បានកាន់តួនាទីជាអ្នកដឹកនាំក្នុងការអភិវឌ្ឍន៍ និងចាប់ផ្តើមផលិតផល និងសេវាកម្មប្រកបដោយភាពច្នៃប្រឌិត ដែលបានជួយក្រុមហ៊ុនកែលម្អប្រតិបត្តិការរបស់ពួកគេ កាត់បន្ថយការចំណាយ និងបង្កើនប្រាក់ចំណូល។ គាត់ស្រលាញ់ការប្រើប្រាស់បច្ចេកវិទ្យាដើម្បីដោះស្រាយបញ្ហាក្នុងពិភពពិត និងជាអ្នកគិតយុទ្ធសាស្ត្រជាមួយនឹងកំណត់ត្រាជោគជ័យដែលបង្ហាញឱ្យឃើញ។
- SEO ដែលដំណើរការដោយមាតិកា និងការចែកចាយ PR ។ ទទួលបានការពង្រីកថ្ងៃនេះ។
- PlatoData.Network Vertical Generative Ai. ផ្តល់អំណាចដល់ខ្លួនអ្នក។ ចូលប្រើទីនេះ។
- PlatoAiStream Web3 Intelligence ។ ចំណេះដឹងត្រូវបានពង្រីក។ ចូលប្រើទីនេះ។
- ផ្លាតូអេសជី។ កាបូន CleanTech, ថាមពល, បរិស្ថាន, ពន្លឺព្រះអាទិត្យ ការគ្រប់គ្រងកាកសំណល់។ ចូលប្រើទីនេះ។
- ផ្លាតូសុខភាព។ ជីវបច្ចេកវិទ្យា និង ភាពវៃឆ្លាត សាកល្បងគ្លីនិក។ ចូលប្រើទីនេះ។
- ប្រភព: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

