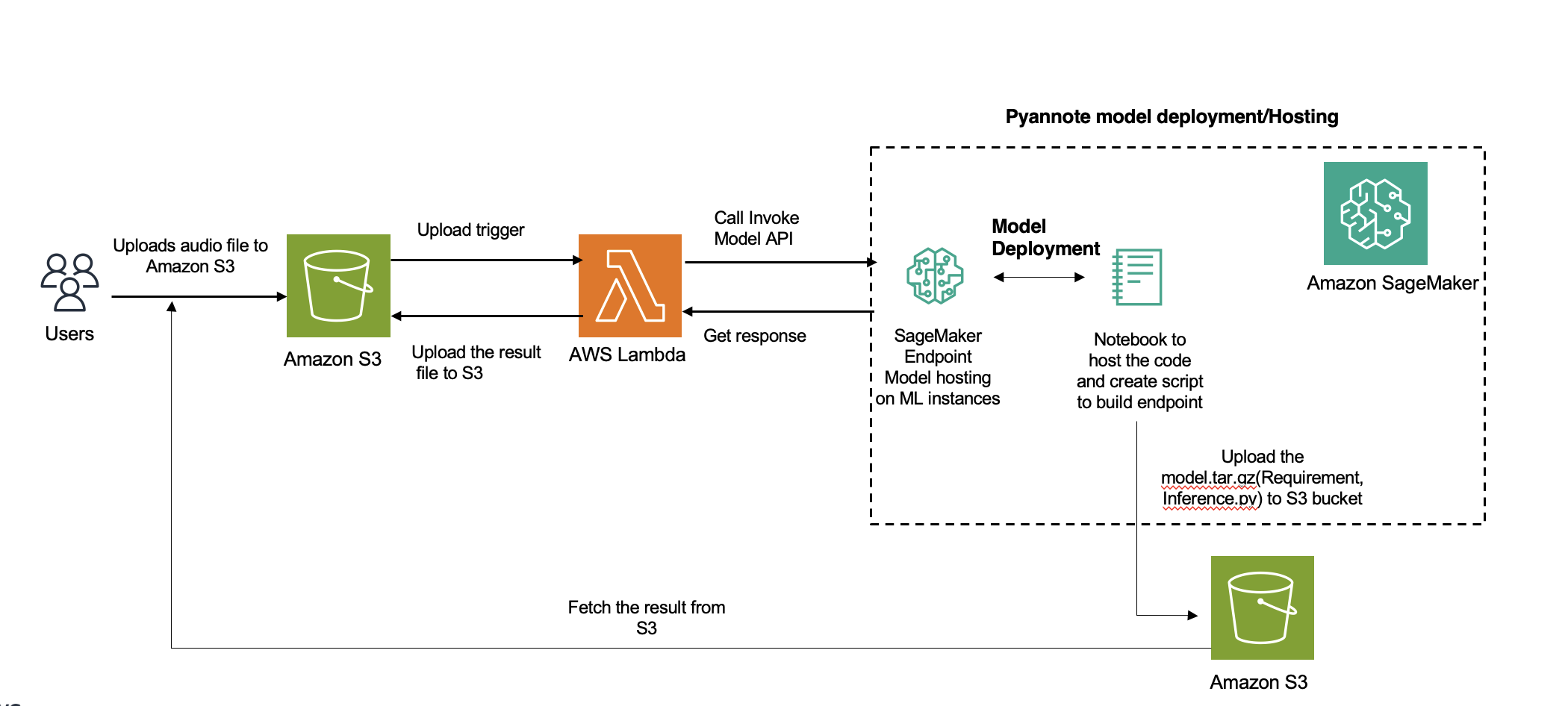
ការបញ្ចេញសំឡេងរបស់អ្នកនិយាយ ដែលជាដំណើរការសំខាន់មួយក្នុងការវិភាគសំឡេង បែងចែកឯកសារអូឌីយ៉ូដោយផ្អែកលើអត្តសញ្ញាណអ្នកនិយាយ។ ការបង្ហោះនេះផ្តោតលើការរួមបញ្ចូល PyAnnote របស់ Hugging Face សម្រាប់ការបំភាយវាគ្មិនជាមួយ ក្រុមហ៊ុន Amazon SageMaker ចំណុចបញ្ចប់អសមកាល។
យើងផ្តល់មគ្គុទ្ទេសក៍ដ៏ទូលំទូលាយមួយអំពីរបៀបដាក់ពង្រាយការបែងចែកវាគ្មិន និងដំណោះស្រាយចង្កោមដោយប្រើ SageMaker នៅលើ AWS Cloud ។ អ្នកអាចប្រើដំណោះស្រាយនេះសម្រាប់កម្មវិធីដែលទាក់ទងនឹងការថតសំឡេងច្រើនវាគ្មិន (ជាង 100)។
ទិដ្ឋភាពទូទៅនៃដំណោះស្រាយ
អាម៉ាហ្សូនចម្លង។ គឺជាសេវាទៅកាន់សម្រាប់ការបំប្លែងសំឡេងអ្នកនិយាយក្នុង AWS ។ ទោះយ៉ាងណាក៏ដោយ សម្រាប់ភាសាដែលមិនគាំទ្រ អ្នកអាចប្រើគំរូផ្សេងទៀត (ក្នុងករណីរបស់យើង PyAnnote) ដែលនឹងត្រូវបានដាក់ឱ្យប្រើប្រាស់នៅក្នុង SageMaker សម្រាប់ការសន្និដ្ឋាន។ សម្រាប់ឯកសារអូឌីយ៉ូខ្លីដែលការសន្និដ្ឋានត្រូវចំណាយពេលរហូតដល់ 60 វិនាទី អ្នកអាចប្រើ ការសន្និដ្ឋានតាមពេលវេលាជាក់ស្តែង . លើសពី 60 វិនាទី អសមកាល ការសន្និដ្ឋានគួរតែត្រូវបានប្រើ។ អត្ថប្រយោជន៍បន្ថែមនៃការសន្និដ្ឋានអសមកាលគឺការសន្សំការចំណាយដោយការធ្វើមាត្រដ្ឋានដោយស្វ័យប្រវត្តិនូវវត្ថុរាប់ដល់សូន្យ នៅពេលដែលមិនមានសំណើដើម្បីដំណើរការ។
មុខឱប គឺជាមជ្ឈមណ្ឌលប្រភពបើកចំហដ៏ពេញនិយមសម្រាប់ម៉ូដែលរៀនម៉ាស៊ីន (ML)។ AWS និង Hugging Face មាន ភាពជាដៃគូ ដែលអនុញ្ញាតឱ្យមានសមាហរណកម្មយ៉ាងរលូនតាមរយៈ SageMaker ជាមួយនឹងសំណុំនៃ AWS Deep Learning Containers (DLCs) សម្រាប់ការបណ្តុះបណ្តាល និងការសន្និដ្ឋាននៅក្នុង PyTorch ឬ TensorFlow និងការប៉ាន់ប្រមាណមុខឱប និងការព្យាករណ៍សម្រាប់ SageMaker Python SDK ។ លក្ខណៈពិសេស និងសមត្ថភាពរបស់ SageMaker ជួយអ្នកអភិវឌ្ឍន៍ និងអ្នកវិទ្យាសាស្ត្រទិន្នន័យ ចាប់ផ្តើមជាមួយនឹងដំណើរការភាសាធម្មជាតិ (NLP) នៅលើ AWS ដោយភាពងាយស្រួល។
សមាហរណកម្មសម្រាប់ដំណោះស្រាយនេះពាក់ព័ន្ធនឹងការប្រើប្រាស់គំរូនៃការបំប្លែងឧបករណ៍បំពងសំឡេងដែលបានបណ្តុះបណ្តាលជាមុនរបស់ Hugging Face ដោយប្រើ បណ្ណាល័យ PyAnnote . PyAnnote គឺជាកញ្ចប់ឧបករណ៍ប្រភពបើកចំហដែលសរសេរនៅក្នុង Python សម្រាប់ diarization អ្នកនិយាយ។ គំរូនេះដែលត្រូវបានបណ្តុះបណ្តាលលើសំណុំទិន្នន័យអូឌីយ៉ូគំរូ អនុញ្ញាតឱ្យការបែងចែកវាគ្មិនប្រកបដោយប្រសិទ្ធភាពនៅក្នុងឯកសារអូឌីយ៉ូ។ គំរូនេះត្រូវបានដាក់ពង្រាយនៅលើ SageMaker ជាការដំឡើងចំណុចបញ្ចប់អសមកាល ដែលផ្តល់នូវដំណើរការប្រកបដោយប្រសិទ្ធភាព និងអាចធ្វើមាត្រដ្ឋាននៃកិច្ចការ diariization ។
ដ្យាក្រាមខាងក្រោមបង្ហាញពីស្ថាបត្យកម្មដំណោះស្រាយ។
សម្រាប់ការប្រកាសនេះ យើងប្រើឯកសារសំឡេងខាងក្រោម។
ឯកសារអូឌីយ៉ូស្តេរ៉េអូ ឬពហុឆានែលត្រូវបានបង្រួមដោយស្វ័យប្រវត្តិទៅជាម៉ូណូដោយជាមធ្យមឆានែល។ ឯកសារអូឌីយ៉ូដែលបានយកគំរូតាមអត្រាផ្សេងត្រូវបានយកគំរូទៅជា 16kHz ដោយស្វ័យប្រវត្តិពេលផ្ទុក។
តម្រូវការជាមុន
បំពេញតម្រូវការជាមុនដូចខាងក្រោមៈ
បង្កើតដែន SageMaker .ត្រូវប្រាកដថាអ្នក អត្តសញ្ញាណ AWS និងការគ្រប់គ្រងការចូលប្រើ អ្នកប្រើប្រាស់ (IAM) មានសិទ្ធិចូលប្រើចាំបាច់សម្រាប់បង្កើត a តួនាទី SageMaker .
សូមប្រាកដថាគណនី AWS មានកូតាសេវាកម្មសម្រាប់ការបង្ហោះ SageMaker endpoint សម្រាប់ឧទាហរណ៍ ml.g5.2xlarge ។
បង្កើតមុខងារគំរូមួយសម្រាប់ការចូលប្រើឧបករណ៍បំពងសំឡេង PyAnnote diarization ពី Hugging Face
អ្នកអាចប្រើ Hugging Face Hub ដើម្បីចូលទៅកាន់ការបណ្តុះបណ្តាលមុនដែលអ្នកចង់បាន គំរូបំប្លែងសំឡេងរបស់វាគ្មិន PyAnnote . អ្នកប្រើស្គ្រីបដូចគ្នាសម្រាប់ការទាញយកឯកសារគំរូនៅពេលបង្កើតចំណុចបញ្ចប់ SageMaker ។
សូមមើលលេខកូដខាងក្រោម៖
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
ខ្ចប់លេខកូដគំរូ
រៀបចំឯកសារសំខាន់ៗដូចជា inference.py ដែលមានលេខកូដប្រឌិត៖
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data[turn] = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=["start", "end", "speaker"])
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
រៀបចំក requirements.txt ឯកសារដែលមានបណ្ណាល័យ Python ដែលត្រូវការចាំបាច់ដើម្បីដំណើរការការសន្និដ្ឋាន៖
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
ជាចុងក្រោយ, បង្រួម inference.py និងឯកសារ require.txt ហើយរក្សាទុកវាជា model.tar.gz:
កំណត់រចនាសម្ព័ន្ធគំរូ SageMaker
កំណត់ធនធានគំរូ SageMaker ដោយបញ្ជាក់ URI រូបភាព ទីតាំងទិន្នន័យគំរូនៅក្នុង សេវាកម្មផ្ទុកសាមញ្ញរបស់ក្រុមហ៊ុន Amazon (S3) និងតួនាទី SageMaker៖
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client("iam")
role = iam.get_role(RoleName="sagemaker_execution_role")["Role"]["Arn"]
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
ផ្ទុកឡើងម៉ូដែលទៅ Amazon S3
បង្ហោះឯកសារគំរូ PyAnnote Hugging Face ដែលបានបង្ហាប់ទៅធុង S3៖
s3_location = f"s3://{sagemaker_session_bucket}/whisper/model/model.tar.gz"
!aws s3 cp model.tar.gz $s3_location
បង្កើតចំណុចបញ្ចប់អសមកាល SageMaker
កំណត់រចនាសម្ព័ន្ធចំណុចបញ្ចប់អសមកាលសម្រាប់ដាក់ពង្រាយគំរូនៅលើ SageMaker ដោយប្រើការកំណត់រចនាសម្ព័ន្ធការសន្និដ្ឋានអសមកាលដែលបានផ្តល់៖
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
សាកល្បងចំណុចបញ្ចប់
វាយតម្លៃមុខងារនៃចំណុចបញ្ចប់ដោយការផ្ញើឯកសារអូឌីយ៉ូសម្រាប់ diarization និងទាញយកលទ្ធផល JSON ដែលរក្សាទុកក្នុងផ្លូវលទ្ធផល S3 ដែលបានបញ្ជាក់៖
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
ដើម្បីប្រើដំណោះស្រាយនេះតាមមាត្រដ្ឋាន យើងស្នើឱ្យប្រើ AWS Lambda , សេវាកម្មជូនដំណឹងសាមញ្ញរបស់ក្រុមហ៊ុន Amazon (Amazon SNS), ឬ សេវាកម្មជួរធម្មតារបស់ Amazon (Amazon SQS) ។ សេវាកម្មទាំងនេះត្រូវបានរចនាឡើងសម្រាប់វិសាលភាព ស្ថាបត្យកម្មដែលជំរុញដោយព្រឹត្តិការណ៍ និងការប្រើប្រាស់ធនធានប្រកបដោយប្រសិទ្ធភាព។ ពួកវាអាចជួយបំបែកដំណើរការសន្និដ្ឋានអសមកាលចេញពីដំណើរការលទ្ធផល ដែលអនុញ្ញាតឱ្យអ្នកធ្វើមាត្រដ្ឋានសមាសធាតុនីមួយៗដោយឯករាជ្យ និងដោះស្រាយការស្នើសុំការសន្និដ្ឋានប្រកបដោយប្រសិទ្ធភាពជាងមុន។
លទ្ធផល
ទិន្នផលគំរូត្រូវបានរក្សាទុកនៅ s3://sagemaker-xxxx /async_inference/output/. លទ្ធផលបង្ហាញថាការថតសំឡេងត្រូវបានបែងចែកទៅជាបីជួរ៖
ចាប់ផ្តើម (ពេលវេលាចាប់ផ្តើមគិតជាវិនាទី)
បញ្ចប់ (ពេលវេលាបញ្ចប់គិតជាវិនាទី)
Speaker (ស្លាកសញ្ញាឧបករណ៍បំពងសំឡេង)
កូដខាងក្រោមបង្ហាញឧទាហរណ៍នៃលទ្ធផលរបស់យើង៖
[0.9762308998, 8.9049235993, "SPEAKER_01"]
[9.533106961, 12.1646859083, "SPEAKER_01"]
[13.1324278438, 13.9303904924, "SPEAKER_00"]
[14.3548387097, 26.1884550085, "SPEAKER_00"]
[27.2410865874, 28.2258064516, "SPEAKER_01"]
[28.3446519525, 31.298811545, "SPEAKER_01"]
សម្អាត។
អ្នកអាចកំណត់គោលការណ៍ធ្វើមាត្រដ្ឋានទៅសូន្យដោយកំណត់ MinCapacity ទៅ 0; ការសន្និដ្ឋានអសមកាល អនុញ្ញាតឱ្យអ្នកធ្វើមាត្រដ្ឋានដោយស្វ័យប្រវត្តិទៅសូន្យដោយគ្មានសំណើ។ អ្នកមិនចាំបាច់លុបចំណុចបញ្ចប់នោះទេ។ ជញ្ជីង ពីសូន្យនៅពេលចាំបាច់ម្តងទៀត កាត់បន្ថយការចំណាយនៅពេលមិនប្រើប្រាស់។ សូមមើលកូដខាងក្រោម៖
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
ប្រសិនបើអ្នកចង់លុបចំណុចបញ្ចប់ សូមប្រើកូដខាងក្រោម៖
async_predictor.delete_endpoint(async_endpoint_name)
អត្ថប្រយោជន៍នៃការដាក់ពង្រាយចំណុចបញ្ចប់អសមកាល
ដំណោះស្រាយនេះផ្តល់អត្ថប្រយោជន៍ដូចខាងក្រោមៈ
ដំណោះស្រាយអាចគ្រប់គ្រងឯកសារអូឌីយ៉ូច្រើន ឬធំប្រកបដោយប្រសិទ្ធភាព។
ឧទាហរណ៍នេះប្រើឧទាហរណ៍តែមួយសម្រាប់ការបង្ហាញ។ ប្រសិនបើអ្នកចង់ប្រើដំណោះស្រាយនេះសម្រាប់វីដេអូរាប់រយ ឬរាប់ពាន់ ហើយប្រើចំណុចបញ្ចប់អសមកាលដើម្បីដំណើរការលើករណីជាច្រើន អ្នកអាចប្រើ គោលការណ៍ធ្វើមាត្រដ្ឋានដោយស្វ័យប្រវត្តិ ដែលត្រូវបានរចនាឡើងសម្រាប់ឯកសារប្រភពមួយចំនួនធំ។ ការធ្វើមាត្រដ្ឋានដោយស្វ័យប្រវត្តិកែតម្រូវជាលក្ខណៈថាមវន្តចំនួននៃករណីដែលបានផ្តល់សម្រាប់គំរូក្នុងការឆ្លើយតបទៅនឹងការផ្លាស់ប្តូរនៅក្នុងបន្ទុកការងាររបស់អ្នក។
ដំណោះស្រាយបង្កើនប្រសិទ្ធភាពធនធាន និងកាត់បន្ថយការផ្ទុកប្រព័ន្ធដោយបំបែកកិច្ចការដែលដំណើរការយូរពីការសន្និដ្ឋានតាមពេលវេលាជាក់ស្តែង។
សន្និដ្ឋាន
នៅក្នុងការបង្ហោះនេះ យើងបានផ្តល់នូវវិធីសាស្រ្តត្រង់ៗក្នុងការដាក់ពង្រាយគំរូ diarization speaker របស់ Hugging Face នៅលើ SageMaker ដោយប្រើស្គ្រីប Python ។ ការប្រើប្រាស់ចំណុចបញ្ចប់អសមកាលផ្តល់នូវមធ្យោបាយដ៏មានប្រសិទ្ធភាព និងអាចធ្វើមាត្រដ្ឋានបាន ដើម្បីផ្តល់ការព្យាករណ៍ diarization ជាសេវាកម្ម បំពេញសំណើស្របគ្នាយ៉ាងរលូន។
ចាប់ផ្តើមថ្ងៃនេះជាមួយនឹងការបំប្លែងបំពងសំឡេងអសមកាលសម្រាប់គម្រោងសំឡេងរបស់អ្នក។ ទាក់ទងនៅក្នុងមតិយោបល់ ប្រសិនបើអ្នកមានសំណួរណាមួយអំពីការទទួលបានចំណុចបញ្ចប់នៃការ diarization អសមកាលផ្ទាល់ខ្លួនរបស់អ្នក និងដំណើរការ។
អំពីនិពន្ធនេះ
Sanjay Tiwary គឺជាអ្នកឯកទេសដំណោះស្រាយដំណោះស្រាយស្ថាបត្យករ AI/ML ដែលចំណាយពេលវេលារបស់គាត់ធ្វើការជាមួយអតិថិជនជាយុទ្ធសាស្រ្តដើម្បីកំណត់តម្រូវការអាជីវកម្ម ផ្តល់វគ្គ L300 ជុំវិញករណីប្រើប្រាស់ជាក់លាក់ និងរចនាកម្មវិធី និងសេវាកម្ម AI/ML ដែលអាចធ្វើមាត្រដ្ឋាន ជឿជាក់ និងដំណើរការបាន។ គាត់បានជួយបើកដំណើរការ និងពង្រីកសេវាកម្ម Amazon SageMaker ដែលដំណើរការដោយ AI/ML និងបានអនុវត្តភស្តុតាងជាច្រើននៃគំនិតដោយប្រើសេវាកម្ម Amazon AI ។ គាត់ក៏បានបង្កើតវេទិកាវិភាគកម្រិតខ្ពស់ផងដែរ ដែលជាផ្នែកមួយនៃដំណើរផ្លាស់ប្តូរឌីជីថល។
Kiran Challapalli គឺជាអ្នកអភិវឌ្ឍន៍អាជីវកម្មបច្ចេកវិទ្យាស៊ីជម្រៅជាមួយផ្នែកសាធារណៈ AWS ។ គាត់មានបទពិសោធន៍ជាង 8 ឆ្នាំនៅក្នុង AI/ML និង 23 ឆ្នាំនៃការអភិវឌ្ឍន៍ផ្នែកទន់ និងបទពិសោធន៍ផ្នែកលក់។ Kiran ជួយអាជីវកម្មផ្នែកសាធារណៈនៅទូទាំងប្រទេសឥណ្ឌាស្វែងរក និងសហការបង្កើតដំណោះស្រាយផ្អែកលើពពកដែលប្រើ AI, ML និង AI ជំនាន់ថ្មី រួមទាំងម៉ូដែលភាសាធំៗផងដែរ បច្ចេកវិទ្យា។
 Sanjay Tiwary គឺជាអ្នកឯកទេសដំណោះស្រាយដំណោះស្រាយស្ថាបត្យករ AI/ML ដែលចំណាយពេលវេលារបស់គាត់ធ្វើការជាមួយអតិថិជនជាយុទ្ធសាស្រ្តដើម្បីកំណត់តម្រូវការអាជីវកម្ម ផ្តល់វគ្គ L300 ជុំវិញករណីប្រើប្រាស់ជាក់លាក់ និងរចនាកម្មវិធី និងសេវាកម្ម AI/ML ដែលអាចធ្វើមាត្រដ្ឋាន ជឿជាក់ និងដំណើរការបាន។ គាត់បានជួយបើកដំណើរការ និងពង្រីកសេវាកម្ម Amazon SageMaker ដែលដំណើរការដោយ AI/ML និងបានអនុវត្តភស្តុតាងជាច្រើននៃគំនិតដោយប្រើសេវាកម្ម Amazon AI ។ គាត់ក៏បានបង្កើតវេទិកាវិភាគកម្រិតខ្ពស់ផងដែរ ដែលជាផ្នែកមួយនៃដំណើរផ្លាស់ប្តូរឌីជីថល។
Sanjay Tiwary គឺជាអ្នកឯកទេសដំណោះស្រាយដំណោះស្រាយស្ថាបត្យករ AI/ML ដែលចំណាយពេលវេលារបស់គាត់ធ្វើការជាមួយអតិថិជនជាយុទ្ធសាស្រ្តដើម្បីកំណត់តម្រូវការអាជីវកម្ម ផ្តល់វគ្គ L300 ជុំវិញករណីប្រើប្រាស់ជាក់លាក់ និងរចនាកម្មវិធី និងសេវាកម្ម AI/ML ដែលអាចធ្វើមាត្រដ្ឋាន ជឿជាក់ និងដំណើរការបាន។ គាត់បានជួយបើកដំណើរការ និងពង្រីកសេវាកម្ម Amazon SageMaker ដែលដំណើរការដោយ AI/ML និងបានអនុវត្តភស្តុតាងជាច្រើននៃគំនិតដោយប្រើសេវាកម្ម Amazon AI ។ គាត់ក៏បានបង្កើតវេទិកាវិភាគកម្រិតខ្ពស់ផងដែរ ដែលជាផ្នែកមួយនៃដំណើរផ្លាស់ប្តូរឌីជីថល។ Kiran Challapalli គឺជាអ្នកអភិវឌ្ឍន៍អាជីវកម្មបច្ចេកវិទ្យាស៊ីជម្រៅជាមួយផ្នែកសាធារណៈ AWS ។ គាត់មានបទពិសោធន៍ជាង 8 ឆ្នាំនៅក្នុង AI/ML និង 23 ឆ្នាំនៃការអភិវឌ្ឍន៍ផ្នែកទន់ និងបទពិសោធន៍ផ្នែកលក់។ Kiran ជួយអាជីវកម្មផ្នែកសាធារណៈនៅទូទាំងប្រទេសឥណ្ឌាស្វែងរក និងសហការបង្កើតដំណោះស្រាយផ្អែកលើពពកដែលប្រើ AI, ML និង AI ជំនាន់ថ្មី រួមទាំងម៉ូដែលភាសាធំៗផងដែរ បច្ចេកវិទ្យា។
Kiran Challapalli គឺជាអ្នកអភិវឌ្ឍន៍អាជីវកម្មបច្ចេកវិទ្យាស៊ីជម្រៅជាមួយផ្នែកសាធារណៈ AWS ។ គាត់មានបទពិសោធន៍ជាង 8 ឆ្នាំនៅក្នុង AI/ML និង 23 ឆ្នាំនៃការអភិវឌ្ឍន៍ផ្នែកទន់ និងបទពិសោធន៍ផ្នែកលក់។ Kiran ជួយអាជីវកម្មផ្នែកសាធារណៈនៅទូទាំងប្រទេសឥណ្ឌាស្វែងរក និងសហការបង្កើតដំណោះស្រាយផ្អែកលើពពកដែលប្រើ AI, ML និង AI ជំនាន់ថ្មី រួមទាំងម៉ូដែលភាសាធំៗផងដែរ បច្ចេកវិទ្យា។
