検索がNLPの最大の問題であることを認識するのに長い時間がかかりました。 Google、Amazon、Bingをご覧ください。 これらは、強力な検索エンジンによってのみ実現可能な数十億ドル規模のビジネスです。
検索に関する私の最初の考えは、監視されていないMLを中心としたものでしたが、 マイクロソフトハッカソン2018 Bingにとっては、ディープラーニングで検索エンジンを作成するさまざまな方法を知るようになりました。
この記事では、次のトピックについて説明します。
NLPアプリケーションに関するこの詳細な技術教育が役立つと思いますか? 新しい関連コンテンツがリリースされたときに更新するには、以下で購読してください.
従来の検索エンジン
検索のプロセスは、4つのステップに分類できます。
- クエリのオートコンプリート—入力した最初の文字に基づいてクエリを提案します
- クエリのフィルタリング—トークンの削除、ステミング、および低下
- クエリ拡張—同義語と頭字語の縮小/拡張の追加
- ドキュメントのスコアリング—ほとんどのスコアリングメカニズムによるScore(document | query) BM25
ここで、これらの手順の説明に時間を費やすことなく、最も人気のある検索エンジンであるLuceneなどの従来の検索エンジンの欠点について説明します。
問題1:トークンの照合
最高の本を見つけることに興味があると想像してみてください 誤差逆伝播法。 ユーザーレビューによると、イアングッドフェローらによるディープラーニング。 トピックとそれを取り巻く他のトピックで最高であると考えられています。 しかし、単語の間には完全な不一致があります。 クエリ:逆伝播 および ドキュメントタイトル:深層学習。 これらはamazon.comの結果です。 深層学習の本はありません!

クエリ「バックプロパゲーション」の結果
深層学習を検索すると、本が一番上に表示されます。

クエリ「ディープラーニング」の結果
これがハードトークンマッチングの問題です。
問題2:文脈化
上記の例は、クエリの深層学習で機能します。 理論を読むだけでなく、実用的な例を含む本を読みたいとしたらどうでしょう。 これにより、 コンテキスト検索。 その場合、これらの本は私にぴったりでした。 だよね?

「ニューラルネットワーク」を学ぶための実用的な本

「ニューラルネットワーク」を学ぶためのもう一つの実用的な本
NLPを検索すると、なぜNLP(神経言語プログラミング)に関する本が表示されるのですか。 コンテキスト検索でこれを解決できます—コンピュータサイエンスに関する書籍を購入していることが検索エンジンでわかっていれば、代わりに自然言語処理に関する書籍が表示されます。

GAN を検索すると、これらの情報が得られます。再び非個人化の問題です。

問題3:クエリの誤解
クエリ: yに対するxの影響 最初の学術論文の結果: xに対するaの影響
つまり、ベルンハルトの学問への影響を見つけるのではなく、最初の論文はヘルバートのベルンハルトへの影響についてです。

14年2019月XNUMX日に検索
トークン照合エンジンは単語のシーケンスを考慮しないため、誤った結果をスローする可能性があります。 😞
ただし、Googleの同様のクエリ提案の方が優れています。

14年2019月XNUMX日に検索
問題4:画像検索
最後に重要なことですが、テキストで画像を検索できる唯一の方法は、説明またはタグ付きのすべての画像のメタデータを生成することです。これは実際には不可能です。
メトリックへの影響は何ですか?
このため、メトリックは悪影響を受けます。
ハードトークンマッチ→少ないリコール
コンテキストがない→精度が低い
検索のディープラーニング🔥
トークン照合だけに関連する問題を理解できたので、ディープラーニングを使用して検索を行う方法について説明します。 私の考えは本に基づいています 検索のディープラーニング Tommaso Teofiliによる。
解決策1:同義語の生成
トークンの一致の問題は、Elasticsearchのカスタムディクショナリを使用して、同義語で単語を増やすことで解決できます。 このため、類義語を必要とする単語を手動で見つけ、その類義語も見つける必要があります。 これは簡単に始められますが、維持するのは困難です。 代わりに、ここでディープラーニングを活用できます! まず、Spacyなどのライブラリを使用してPOS(品詞)を検索し、POS(品詞)が名詞、動詞、または形容詞として含まれている単語の同義語を取得します。 類義語が多すぎたり無関係であったりしないように、類似した単語を選択するために余弦の類似性のカットオフを維持する必要があります。
同義語の増加があると、想起を改善するのに役立ちますが、精度も低下します😅
注意❌
ここでは、特定の単語を拡張しないように注意する必要があります。 驚いたことに、word2vecによる「good」の最も近い単語は「bad」と「poor」です。 これにより、特定の場合に結果が変わる可能性があります。 😅
試着できます https://projector.tensorflow.org
word2vecで「amazing」に最も近い単語は「スパイダー」で、これはアメージングスパイダーマン映画から来ている可能性があります。 これはいくつかの驚くべき結果につながる可能性があります
解決策2:クエリのオートコンプリート
完成したクエリが空の結果をスローしないように、ユーザーが入力中にクエリを完了するのを手伝ってみませんか? Elasticsearchにはクエリのオートコンプリート機能もありますが、有限オートマトンです。 インデックスに表示されなかった文字シーケンスを入力すると、結果は表示されません。 言語モデル(LM)の場合、生成は有限ではありません。 (ただし、モデルが短いシーケンス用にトレーニングされている場合、長いクエリではLM生成が失敗する可能性があります。)
結果が空にならないようにクエリをオートコンプリートする機能により、ユーザーエクスペリエンスが劇的に変わり、チャーンアウトを回避できます☺️
トリック:結果が得られないクエリを提案する意味がないため、空の結果を返すクエリをトレーニングから削除します。
解決策3:代替クエリの生成
ユーザーセッションからのクエリのログがある場合、生成モデルをトレーニングして生成できます(次のクエリ|現在のクエリ)。 セッション内のすべてのクエリは互いに類似しているという仮説です。 ログは次のようになります。
- 人工知能
- テンソルフロー
- ニューラルネットワーク
- ...
トレーニングデータ(x、y)(人工知能、Tensorflow)(Tensorflow、ニューラルネットワーク)
クエリ生成は、ユーザーの購入意向を理解することで、関連クエリの提案に役立ちます。
解決策4:単語とドキュメントの埋め込みを使用する
クエリをユーザーが入力すると、ワンホットまたはTF-IDF正規化形式で表すのではなく、いくつかのアプローチを使用して単語、文、ドキュメントをベクトル化できます。
- 単純な埋め込み平均
- IDF値を乗算することによる重み付けされた埋め込み平均
- infersent、USE(ユニバーサルセンテンスエンコーダ)、センテンスベルトなどのモデルを使用した文章の埋め込み
- seq2seqオートエンコーダー
これは、すべてのトークンを セマンティックおよび圧縮 語彙のサイズに関係なく、固定サイズのベクトルの形式。これには、モデルを使用したベクトル化という 1 回の大きなオーバーヘッドが必要ですが、その後のすべての検索は n 次元でのベクトル検索になります。ベクトル検索における現在の最先端技術は次のとおりです。 マイルバス。 のために 近似最近傍 flannとannoyを使用できます。
ソリューション5:コンテキスト化
コンテキスト化/パーソナライゼーションのために検索エンジンによって考慮される要素
- ユーザー履歴 —彼の過去の検索からの興味と、過去に同じものを検索した場合、何をクリックしたか
- ユーザーの地理 —「大統領」という単語を検索すると、「ラムナスコビンド」が表示されます→現在のインド大統領
- 情報の一時的な変化 —クエリ 'president'の結果は時間とともに変化します
各クリックを固定ベクトルとしてエンコードしてスコアを生成することにより、ユーザー履歴を使用できます(ドキュメント|履歴+クエリ)
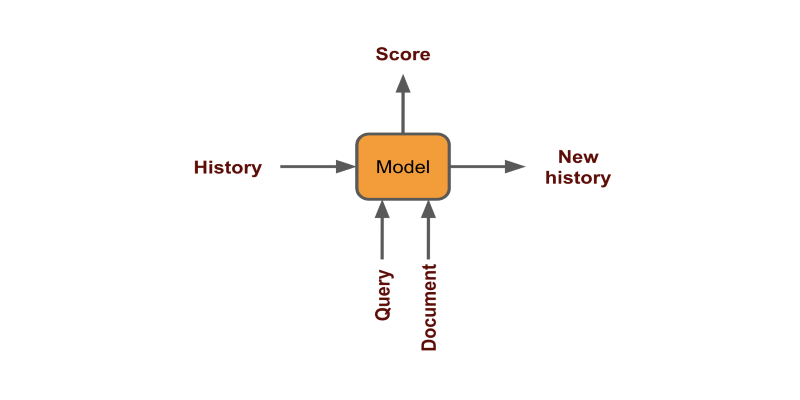
地理と時間は、モデルのトレーニング中にフィルタリングするか、フィーチャとして追加することにより、注意することができます。
パーソナライゼーションにより、人間レベルの提案をユーザーに提供できるため、コンバージョンの改善に役立ちます。
解決策6:ランク付けの学習
TF-IDFスキームのトークンマッチングには欠陥があるため、結果を再ランク付けできるレイヤーが実際に必要です。 このスキームは、珍しい単語に対して高いバイアスを持ち、記事の変換の可能性も考慮していません。 ユーザークエリのログと、ユーザーが検索結果からクリックしたログがある場合は、モデルをトレーニングしてドキュメントをランク付けできます。 データは次のようになります。 (x、y)(人工知能、ブック2のタイトル)(Tensorflow、ブック1のタイトル)(ニューラルネットワーク、ブック4のタイトル)次に結果を表示するときは、最初にトークン照合の安価なプロセスから上位x件の結果を取得しますTF-IDF / BM25を通じて、主にElasticsearchを通じて、すべてのペアのスコアを生成します。 (x、y)
- (クエリ、タイトル1)→スコア1
- (クエリ、タイトル2)→スコア2
- ...
次に、タイトルをスコアで並べ替え、上位の結果を表示します。 あなたは私の中にBERTを使用してこれの実装を見つけることができます githubの.

NSPヘッド付きBERT
問題をランク付けする学習をBERT NextSentencePrediction問題、つまり含意問題として定義できます。
解決策7:アンサンブル
ほとんどの場合、両方のアプローチを活用する方が有利です。 この本は、wordvectorとBM25を組み合わせたスコアを使用することが最も効果的であると述べています。

「検索のためのディープラーニング」から
Ensembleを使用すると、アプローチのハードトークンマッチングとセマンティクスの両方を最大限に活用できます。
解決策8:多言語検索
1にアプローチ

アプリケーションが地理的に異なる特定のケースでは、ユーザーの言語がドキュメントと異なる場合があります。 異なる言語のトークンは一致できないため、このような検索は従来の検索アプローチでは不可能です。 これには、ディープラーニングによる機械翻訳の助けが必要です。
- ユーザークエリの言語を検出する(例:フランス語)
- ドキュメントがあるすべての言語にクエリを翻訳します(フランス語から英語、ドイツ語、スペイン語)
- ドキュメントを検索
- すべての上位スコアのドキュメントをユーザーの言語に翻訳します(英語、ドイツ語、スペイン語からフランス語)
2にアプローチ
代わりに、多言語センテンスエンコーダーを使用して、任意の言語から同様のベクトルへのテキストを表すことができます。 このアプローチを詳しく見ていきましょう。
多言語ユニバーサルセンテンスエンコーダー
私はPOCを行うためにこれらのコンポーネントを取っています:
- モデル —多言語ユニバーサルセンテンスエンコーダー
- ベクトル検索 —ファイス
- 且つ — Quoraの質問ペア カグル
USEの詳細については、 本論文。 16言語に対応しています。
ステップ1.データをロードする
まずデータを読みましょう。 quoraデータセットは巨大で時間がかかるため、データの1%しか取得しません。 これには、エンコードとインデックス作成に約3分かかります。 それは4000問あります。
df = pd.read_csv('quora-question-pairs/train.csv')
df = df.sample(frac=0.01, random_state=1)
df.dropna(inplace=True)
questions = df.question1.values
ステップ2.エンコーダーを作成する
モデルを読み込み、encodeメソッドを持つエンコーダクラスを作成しましょう。 使用できるさまざまなモデルのクラスを作成しました。 すべてのモデルは英語で動作し、他の言語で使用できるのは多言語のみです。
USEは、テキストをサイズ512の固定ベクトルにエンコードします。
モデルのロードにUSEにはTFHubを、BERTにはFlairを使用しています。
class TFEncoder(metaclass=ABCMeta): """Base encoder to be used for all encoders.""" def __init__(self, model_path:str): self.model = hub.load(model_path) @abstractmethod def encode(self, text:list): """Encodes text. Text: should be a list of strings to encode """ class USE(TFEncoder): """Universal sentence encoder""" def __init__(self, model_path): super().__init__(model_path) def encode(self, text): return self.model(text).numpy() class USEQA(TFEncoder): """Universal sentence encoder trained on Question Answer pairs""" def __init__(self, model_path): super().__init__(model_path) def encode(self, text): return self.model.signatures['question_encoder'](tf.constant(s))['outputs'].numpy() class BERT(): """BERT models""" def __init__(self, model_name, layers="-2", pooling_operation="mean"): self.embeddings = BertEmbeddings(model_name, layers=layers, pooling_operation=pooling_operation) self.document_embeddings = DocumentPoolEmbeddings([self.embeddings], fine_tune_mode='nonlinear') def encode(self, text): sentence = Sentence(text) self.document_embeddings.embed(sentence) return sentence.embedding.detach().numpy().reshape(1, -1) model_path = "https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3" encoder = USE(model_path)
ステップ3.インデクサーを作成する
次に、高速ベクトル検索のためにすべての埋め込みを効率的に格納するFAISSインデクサークラスを作成します。
class FAISS: def __init__(self, dimensions:int): self.dimensions = dimensions self.index = faiss.IndexFlatL2(dimensions) self.vectors = {} self.counter = 0 def add(self, text:str, v:list): self.index.add(v) self.vectors[self.counter] = (text, v) self.counter += 1 def search(self, v:list, k:int=10): distance, item_index = self.index.search(v, k) for dist, i in zip(distance[0], item_index[0]): if i==-1: break else: print(f'{self.vectors[i][0]}, %.2f'%dist)
ステップ4.エンコードとインデックス
すべての質問の埋め込みを作成して、FAISSに保存しましょう。 クエリが指定された上位k個の類似結果を表示する検索メソッドを定義します。
d = encoder.encode(['hello']).shape[-1] # get dimension of emb index = FAISS(d) #index all questions for q in tqdm(questions): emb = encoder.encode([q]) index.add(q, emb) # embed and search a question def search(s, k=10): emb = encoder.encode([s]) index.search(emb, k)
ステップ5.検索
以下に、モデルの結果を示します。 最初に英語で質問を書くと、期待した結果が得られます。 次に、Google翻訳を使用してクエリを他の言語に変換すると、結果は再び素晴らしいものになります。 私は「失う」の代わりに「失う」のスペルミスを犯しましたが、モデルはそれがサブワードレベルで機能し、コンテキストに応じてそれを理解します。

ご覧のとおり、結果は非常に印象的であり、モデルを実稼働に投入する価値があります。
完全なコードは 私のコラボノート。 からデータをダウンロードできます こちら.
より良いモデルを作成するには、転移学習を使用してデータの言語モデルを調整する必要があります。 あなたは私でそれについてもっと読むことができます 前回の記事.
こちら セマンティック検索用にテキストをエンコードするためのさまざまなモデルについて詳しく読むことができます。
まとめ
最近Googleが検索結果を強化するためにBERTベースの実装を本番環境にプッシュしたことをすでにご存じかもしれません。 検索にディープラーニングを活用することについて理解が深まるにつれ、セマンティック検索が増加し、業界で一般的になるようです。
この記事は最初に媒体(一部1 および 一部2)そして著者の許可を得てTOPBOTSに再発行されました。
この記事をお楽しみですか? AIおよびNLPの更新プログラムにサインアップしてください。
より詳細な技術教育をリリースするときにお知らせします。

