סטודיו SageMaker של אמזון מספק פתרון מנוהל במלואו עבור מדעני נתונים לבנייה, אימון ופריסה אינטראקטיבית של מודלים של למידת מכונה (ML). בתהליך העבודה על משימות ה-ML שלהם, מדעני נתונים מתחילים בדרך כלל את זרימת העבודה שלהם על ידי גילוי מקורות נתונים רלוונטיים וחיבור אליהם. לאחר מכן הם משתמשים ב-SQL כדי לחקור, לנתח, להמחיש ולשלב נתונים ממקורות שונים לפני שהם משתמשים בהם בהכשרה והסקת ML שלהם. בעבר, מדעני נתונים מצאו את עצמם לעתים קרובות מלהטט בכלים מרובים כדי לתמוך ב-SQL בזרימת העבודה שלהם, מה שהפריע לפרודוקטיביות.
אנו נרגשים להכריז שמחברות JupyterLab ב-SageMaker Studio מגיעות כעת עם תמיכה מובנית עבור SQL. מדעני נתונים יכולים כעת:
- התחבר לשירותי נתונים פופולריים כולל אמזונה אתנה, האדום של אמזון, אמזון DataZone, ו- Snowflake ישירות בתוך המחברות
- דפדף וחפש מסדי נתונים, סכימות, טבלאות ותצוגות, ותצוגה מקדימה של נתונים בממשק המחברת
- מערבבים קוד SQL ו-Python באותה מחברת לחקירה יעילה והמרת נתונים לשימוש בפרויקטים של ML
- השתמש בתכונות פרודוקטיביות של מפתחים כגון השלמת פקודות SQL, סיוע בעיצוב קוד והדגשת תחביר כדי לעזור להאיץ את פיתוח הקוד ולשפר את הפרודוקטיביות הכוללת של מפתחים
בנוסף, מנהלי מערכת יכולים לנהל בצורה מאובטחת חיבורים לשירותי נתונים אלה, מה שמאפשר למדעני נתונים לגשת לנתונים מורשים ללא צורך בניהול אישורים באופן ידני.
בפוסט זה, אנו מנחים אותך דרך הגדרת התכונה הזו ב-SageMaker Studio, ונלווה אותך דרך היכולות השונות של התכונה הזו. לאחר מכן אנו מראים כיצד ניתן לשפר את חוויית ה-SQL במחברת באמצעות יכולות טקסט ל-SQL המסופקות על ידי מודלים מתקדמים של שפה גדולה (LLMs) לכתיבת שאילתות SQL מורכבות תוך שימוש בטקסט בשפה טבעית כקלט. לבסוף, כדי לאפשר לקהל רחב יותר של משתמשים ליצור שאילתות SQL מקלט שפה טבעית במחברות שלהם, אנו מראים לך כיצד לפרוס את המודלים של טקסט ל-SQL באמצעות אמזון SageMaker נקודות קצה.
סקירת פתרונות
עם שילוב SQL של מחברת SageMaker Studio JupyterLab, אתה יכול כעת להתחבר למקורות נתונים פופולריים כמו Snowflake, Athena, Amazon Redshift ו-Amazon DataZone. תכונה חדשה זו מאפשרת לך לבצע פונקציות שונות.
לדוגמה, אתה יכול לחקור חזותית מקורות נתונים כמו מסדי נתונים, טבלאות וסכמות ישירות מהמערכת האקולוגית שלך JupyterLab. אם סביבות המחשב הנייד שלך פועלות על SageMaker Distribution 1.6 ומעלה, חפש ווידג'ט חדש בצד שמאל של ממשק JupyterLab שלך. תוספת זו משפרת את הנגישות והניהול של הנתונים בתוך סביבת הפיתוח שלך.
אם אינך נמצא כעת ב-SageMaker Distribution המוצע (1.5 ומטה) או בסביבה מותאמת אישית, עיין בנספח למידע נוסף.

לאחר הגדרת חיבורים (מודגם בסעיף הבא), תוכל לרשום חיבורי נתונים, לגלוש בבסיסי נתונים ובטבלאות ולבדוק סכמות.

סיומת ה-SQL המובנית של SageMaker Studio JupyterLab מאפשרת לך גם להריץ שאילתות SQL ישירות ממחברת. מחברות Jupyter יכולות להבדיל בין קוד SQL ו-Python באמצעות ה %%sm_sql פקודת magic, אשר חייבת להיות ממוקמת בראש כל תא המכיל קוד SQL. פקודה זו מאותתת ל-JupyterLab שההוראות הבאות הן פקודות SQL ולא קוד Python. ניתן להציג את הפלט של שאילתה ישירות בתוך המחברת, מה שמאפשר שילוב חלק של זרימות עבודה של SQL ו-Python בניתוח הנתונים שלך.
ניתן להציג את הפלט של שאילתה בצורה ויזואלית כטבלאות HTML, כפי שמוצג בצילום המסך הבא.

ניתן לכתוב אותם גם לא פנדה DataFrame.

תנאים מוקדמים
ודא שעמדת בתנאים המוקדמים הבאים כדי להשתמש בחוויית SQL Notebook Notebook של SageMaker Studio:
- SageMaker Studio V2 - ודא שאתה מפעיל את הגרסה המעודכנת ביותר של שלך SageMaker Studio דומיין ופרופילי משתמשים. אם אתה משתמש כעת ב-SageMaker Studio Classic, עיין ב מעבר מאמזון SageMaker Studio Classic.
- תפקיד IAM – SageMaker דורש AWS זהות וניהול גישה תפקיד (IAM) שיוקצה לדומיין של SageMaker Studio או לפרופיל משתמש כדי לנהל הרשאות בצורה יעילה. ייתכן שיידרש עדכון תפקיד ביצוע כדי להכניס גלישה בנתונים ותכונת ההפעלה של SQL. מדיניות הדוגמה הבאה מאפשרת למשתמשים להעניק, לרשום ולהפעיל דבק AWS, אתנה, שירות אחסון פשוט של אמזון (אמזון S3), מנהל סודות AWS, ומשאבים של אמזון לאדום:
- JupyterLab Space - אתה צריך גישה ל-SageMaker Studio המעודכן ול-JupyterLab Space עם הפצת SageMaker גרסאות תמונה v1.6 ואילך. אם אתה משתמש בתמונות מותאמות אישית עבור JupyterLab Spaces או גרסאות ישנות יותר של SageMaker Distribution (v1.5 ומטה), עיין בנספח לקבלת הוראות להתקנת חבילות ומודולים הדרושים כדי להפעיל תכונה זו בסביבות שלך. למידע נוסף על SageMaker Studio JupyterLab Spaces, עיין ב שפר את הפרודוקטיביות ב-Amazon SageMaker Studio: הצגת JupyterLab Spaces וכלי AI גנרטיביים.
- אישורי גישה למקור נתונים - תכונת מחברת SageMaker Studio דורשת גישה לשם משתמש וסיסמה למקורות נתונים כגון Snowflake ו-Amazon Redshift. צור גישה מבוססת שם משתמש וסיסמה למקורות הנתונים האלה אם עדיין אין לך אחד כזה. גישה מבוססת OAuth ל- Snowflake אינה תכונה נתמכת נכון לכתיבת שורות אלה.
- טען קסם SQL – לפני שתפעיל שאילתות SQL מתא מחברת Jupyter, חיוני לטעון את תוסף SQL magics. השתמש בפקודה
%load_ext amazon_sagemaker_sql_magicכדי להפעיל תכונה זו. בנוסף, אתה יכול להפעיל את%sm_sql?הפקודה לצפייה ברשימה מקיפה של אפשרויות נתמכות לשאילתה מתא SQL. אפשרויות אלה כוללות הגדרת מגבלת ברירת מחדל לשאילתות של 1,000, הפעלת חילוץ מלא והזרקת פרמטרי שאילתה, בין היתר. הגדרה זו מאפשרת מניפולציה גמישה ויעילה של נתוני SQL ישירות בתוך סביבת המחברת שלך.
יצירת חיבורי מסד נתונים
יכולות הגלישה והביצוע של SQL המובנות של SageMaker Studio משופרות על ידי חיבורי AWS Glue. חיבור AWS Glue הוא אובייקט AWS Glue Data Catalog המאחסן נתונים חיוניים כגון אישורי כניסה, מחרוזות URI ומידע ענן פרטי וירטואלי (VPC) עבור מאגרי נתונים ספציפיים. חיבורים אלה משמשים סורקי AWS Glue, עבודות ונקודות קצה של פיתוח כדי לגשת לסוגים שונים של מאגרי מידע. אתה יכול להשתמש בחיבורים אלה גם לנתוני מקור וגם לנתוני יעד, ואפילו לעשות שימוש חוזר באותו חיבור על פני סורקים מרובים או לחלץ, לשנות ולטעון (ETL) עבודות.
כדי לחקור מקורות נתונים של SQL בחלונית השמאלית של SageMaker Studio, תחילה עליך ליצור אובייקטי חיבור של AWS Glue. חיבורים אלה מקלים על גישה למקורות נתונים שונים ומאפשרים לך לחקור את רכיבי הנתונים הסכמטיים שלהם.
בסעיפים הבאים, אנו עוברים על תהליך יצירת מחברי AWS Glue ספציפיים ל-SQL. זה יאפשר לך לגשת, להציג ולחקור מערכי נתונים במגוון מאגרי נתונים. למידע מפורט יותר על חיבורי AWS Glue, עיין ב מתחבר לנתונים.
צור חיבור AWS Glue
הדרך היחידה להכניס מקורות נתונים לתוך SageMaker Studio היא באמצעות חיבורי AWS Glue. עליך ליצור חיבורי AWS Glue עם סוגי חיבור ספציפיים. נכון לכתיבת שורות אלה, המנגנון הנתמך היחיד ליצירת קשרים אלה הוא שימוש ב- ממשק שורת הפקודה של AWS (AWS CLI).
הגדרת חיבור קובץ JSON
בעת חיבור למקורות נתונים שונים ב-AWS Glue, עליך ליצור תחילה קובץ JSON המגדיר את מאפייני החיבור - המכונה קובץ הגדרות החיבור. קובץ זה חיוני ליצירת חיבור AWS Glue ואמור לפרט את כל התצורות הדרושות לגישה למקור הנתונים. לשיטות עבודה מומלצות לאבטחה, מומלץ להשתמש במנהל הסודות לאחסון מאובטח של מידע רגיש כגון סיסמאות. בינתיים, ניתן לנהל מאפייני חיבור אחרים ישירות דרך חיבורי AWS Glue. גישה זו מוודאת שאישורים רגישים מוגנים תוך שמירה על תצורת החיבור לנגישה וניתנת לניהול.
להלן דוגמה להגדרת חיבור JSON:
בעת הגדרת חיבורי AWS Glue עבור מקורות הנתונים שלך, יש כמה קווים מנחים חשובים שיש לעקוב אחריהם כדי לספק פונקציונליות ואבטחה כאחד:
- מחרוזת נכסים - בתוך ה
PythonPropertiesמפתח, ודא שכל המאפיינים הם צמדי מפתח-ערך מחרוזים. זה חיוני להימלט כראוי ממרכאות כפולות על ידי שימוש בתו הנטוי האחורי () במידת הצורך. זה עוזר לשמור על הפורמט הנכון ולמנוע שגיאות תחביר ב-JSON שלך. - טיפול במידע רגיש – למרות שניתן לכלול את כל מאפייני החיבור בתוך
PythonProperties, רצוי לא לכלול פרטים רגישים כמו סיסמאות ישירות בנכסים אלו. במקום זאת, השתמש ב- Secrets Manager לטיפול במידע רגיש. גישה זו מאבטחת את הנתונים הרגישים שלך על ידי אחסונם בסביבה מבוקרת ומוצפנת, הרחק מקובצי התצורה הראשיים.
צור חיבור AWS Glue באמצעות AWS CLI
לאחר שתכלול את כל השדות הדרושים בקובץ JSON של הגדרת החיבור שלך, אתה מוכן ליצור חיבור AWS Glue עבור מקור הנתונים שלך באמצעות AWS CLI והפקודה הבאה:
פקודה זו יוזמת חיבור AWS Glue חדש על סמך המפרטים המפורטים בקובץ ה-JSON שלך. להלן פירוט מהיר של רכיבי הפקודה:
- -אזור - זה מציין את אזור ה-AWS שבו ייווצר חיבור ה-AWS Glue שלך. חיוני לבחור את האזור שבו ממוקמים מקורות הנתונים והשירותים האחרים שלך כדי למזער זמן אחזור ולעמוד בדרישות תושבות הנתונים.
- –cli-input-json file:///path/to/file/connection/definition/file.json – פרמטר זה מנחה את AWS CLI לקרוא את תצורת הקלט מקובץ מקומי המכיל את הגדרת החיבור שלך בפורמט JSON.
אתה אמור להיות מסוגל ליצור חיבורי AWS Glue עם פקודת AWS CLI הקודמת ממסוף Studio JupyterLab שלך. על שלח בתפריט, בחר חדש ו מסוף.

אם create-connection הפקודה פועלת בהצלחה, אתה אמור לראות את מקור הנתונים שלך רשום בחלונית דפדפן SQL. אם אינך רואה את מקור הנתונים שלך ברשימה, בחר לרענן כדי לעדכן את המטמון.
צור חיבור Snowflake
בחלק זה, אנו מתמקדים בשילוב מקור נתונים של Snowflake עם SageMaker Studio. יצירת חשבונות Snowflake, מסדי נתונים ומחסנים נופלת מחוץ לתחום הפוסט הזה. כדי להתחיל עם Snowflake, עיין ב- מדריך למשתמש של פתית שלג. בפוסט זה, אנו מתרכזים ביצירת קובץ JSON להגדרת Snowflake ויצירת חיבור מקור נתונים של Snowflake באמצעות AWS Glue.
צור סוד מנהל סודות
אתה יכול להתחבר לחשבון Snowflake שלך על ידי שימוש במזהה משתמש וסיסמה או באמצעות מפתחות פרטיים. כדי להתחבר עם מזהה משתמש וסיסמה, עליך לאחסן את האישורים שלך בצורה מאובטחת במנהל הסודות. כפי שהוזכר קודם לכן, למרות שניתן להטמיע מידע זה תחת PythonProperties, לא מומלץ לאחסן מידע רגיש בפורמט טקסט רגיל. ודא תמיד שהנתונים הרגישים מטופלים בצורה מאובטחת כדי למנוע סיכוני אבטחה פוטנציאליים.
כדי לאחסן מידע במנהל הסודות, בצע את השלבים הבאים:
- במסוף מנהל הסודות בחר אחסן סוד חדש.
- בעד סוג סודי, בחר סוג אחר של סוד.
- עבור צמד מפתח-ערך, בחר טקסט רגיל והזן את הדברים הבאים:
- הזן שם לסוד שלך, כגון
sm-sql-snowflake-secret. - השאר את ההגדרות האחרות כברירת מחדל או התאם אישית במידת הצורך.
- צור את הסוד.
צור חיבור AWS Glue עבור Snowflake
כפי שנדון קודם לכן, חיבורי AWS Glue חיוניים לגישה לכל חיבור מ-SageMaker Studio. אתה יכול למצוא רשימה של כל מאפייני החיבור הנתמכים עבור Snowflake. להלן דוגמה להגדרת חיבור JSON עבור Snowflake. החלף את ערכי מציין המיקום בערכים המתאימים לפני שמירתם בדיסק:
כדי ליצור אובייקט חיבור AWS Glue עבור מקור הנתונים Snowflake, השתמש בפקודה הבאה:
פקודה זו יוצרת חיבור מקור נתונים חדש של Snowflake בחלונית דפדפן SQL שלך שניתן לדפדף בו, ותוכל להריץ נגדו שאילתות SQL מתא המחברת JupyterLab שלך.

צור חיבור אמזון לאדום
Amazon Redshift הוא שירות מחסן נתונים בקנה מידה פטה-בייט מנוהל במלואו, המפשט ומפחית את העלות של ניתוח כל הנתונים שלך באמצעות SQL סטנדרטי. ההליך ליצירת חיבור אמזון לאדום משקף היטב את זה עבור חיבור Snowflake.
צור סוד מנהל סודות
בדומה להגדרת Snowflake, כדי להתחבר לאמזון Redshift באמצעות מזהה משתמש וסיסמה, עליך לאחסן בצורה מאובטחת את פרטי הסודות ב- Secrets Manager. השלם את השלבים הבאים:
- במסוף מנהל הסודות בחר אחסן סוד חדש.
- בעד סוג סודי, בחר אישורים לאשכול האדום של אמזון.
- הזן את האישורים המשמשים לכניסה כדי לגשת לאמזון Redshift כמקור נתונים.
- בחר את אשכול ההסטה לאדום המשויך לסודות.
- הזן שם לסוד, כגון
sm-sql-redshift-secret. - השאר את ההגדרות האחרות כברירת מחדל או התאם אישית במידת הצורך.
- צור את הסוד.
על ידי ביצוע שלבים אלה, אתה מוודא שאישורי החיבור שלך מטופלים בצורה מאובטחת, תוך שימוש בתכונות האבטחה החזקות של AWS לניהול נתונים רגישים ביעילות.
צור חיבור AWS Glue עבור Amazon Redshift
כדי להגדיר חיבור עם Amazon Redshift באמצעות הגדרת JSON, מלא את השדות הדרושים ושמור את תצורת ה-JSON הבאה בדיסק:
כדי ליצור אובייקט חיבור AWS Glue עבור מקור הנתונים Redshift, השתמש בפקודה הבאה של AWS CLI:
פקודה זו יוצרת חיבור ב-AWS Glue המקושר למקור הנתונים שלך Redshift. אם הפקודה פועלת בהצלחה, תוכל לראות את מקור הנתונים Redshift שלך בתוך מחברת SageMaker Studio JupyterLab, מוכן להרצת שאילתות SQL ולביצוע ניתוח נתונים.

צור חיבור אתנה
Athena הוא שירות שאילתות SQL מנוהל במלואו מבית AWS המאפשר ניתוח נתונים המאוחסנים באמזון S3 באמצעות SQL רגיל. כדי להגדיר חיבור Athena כמקור נתונים בדפדפן ה-SQL של מחברת JupyterLab, עליך ליצור JSON הגדרת חיבור לדוגמה של Athena. מבנה ה-JSON הבא מגדיר את הפרטים הדרושים כדי להתחבר לאתנה, תוך ציון קטלוג הנתונים, ספריית ה-S3 בימוי והאזור:
כדי ליצור אובייקט חיבור AWS Glue עבור מקור הנתונים Athena, השתמש בפקודה הבאה של AWS CLI:
אם הפקודה תצליח, תוכל לגשת לקטלוג הנתונים והטבלאות של Athena ישירות מדפדפן SQL בתוך מחברת SageMaker Studio JupyterLab שלך.

שאילתות נתונים ממקורות מרובים
אם יש לך מקורות נתונים מרובים המשולבים ב-SageMaker Studio באמצעות דפדפן SQL המובנה ותכונת SQL של מחברת, תוכל להריץ שאילתות במהירות ולעבור ללא מאמץ בין הקצה האחורי של מקור הנתונים בתאים הבאים בתוך מחברת. יכולת זו מאפשרת מעברים חלקים בין מסדי נתונים או מקורות נתונים שונים במהלך זרימת העבודה של הניתוח שלך.
אתה יכול להריץ שאילתות מול אוסף מגוון של קצה קצה של מקור נתונים ולהביא את התוצאות ישירות למרחב Python לניתוח או הדמיה נוספת. זה מקל על ידי ה %%sm_sql פקודת קסם זמינה במחברות של SageMaker Studio. כדי להוציא את התוצאות של שאילתת ה-SQL שלך ל-Pandas DataFrame, ישנן שתי אפשרויות:
- מסרגל הכלים של תא המחברת, בחר את סוג הפלט DataFrame ותן שם למשתנה DataFrame שלך
- הוסף את הפרמטר הבא שלך
%%sm_sqlפקודה:
התרשים הבא ממחיש זרימת עבודה זו ומציג כיצד ניתן להריץ שאילתות ללא מאמץ על פני מקורות שונים בתאי המחברת הבאים, כמו גם לאמן מודל SageMaker באמצעות עבודות הדרכה או ישירות בתוך המחברת באמצעות מחשוב מקומי. בנוסף, התרשים מדגיש כיצד שילוב SQL המובנה של SageMaker Studio מפשט את תהליכי החילוץ והבנייה ישירות בתוך הסביבה המוכרת של תא מחברת JupyterLab.

טקסט ל-SQL: שימוש בשפה טבעית כדי לשפר את עריכת השאילתות
SQL היא שפה מורכבת הדורשת הבנה של מסדי נתונים, טבלאות, תחבירים ומטא נתונים. כיום, בינה מלאכותית גנרטיבית (AI) יכולה לאפשר לך לכתוב שאילתות SQL מורכבות ללא צורך בניסיון מעמיק ב-SQL. התקדמותם של LLMs השפיעה באופן משמעותי על יצירת SQL מבוססת עיבוד שפה טבעית (NLP), המאפשרת יצירת שאילתות SQL מדויקות מתיאורי שפה טבעית - טכניקה המכונה Text-to-SQL. עם זאת, חיוני להכיר בהבדלים המובנים בין השפה האנושית ל-SQL. השפה האנושית יכולה לפעמים להיות מעורפלת או לא מדוייקת, בעוד ש-SQL הוא מובנה, מפורש וחד משמעי. גישור על פער זה והמרה מדויקת של שפה טבעית לשאילתות SQL יכולים להוות אתגר אדיר. כאשר הם מספקים הנחיות מתאימות, LLMs יכולים לעזור לגשר על פער זה על ידי הבנת הכוונה מאחורי השפה האנושית ויצירת שאילתות SQL מדויקות בהתאם.
עם שחרורו של תכונת השאילתות של SageMaker Studio במחברת, SageMaker Studio מאפשר לבדוק מסדי נתונים וסכימות, וליצור, להריץ ולבצע ניפוי באגים של שאילתות SQL מבלי לעזוב את IDE המחברת Jupyter. חלק זה בוחן כיצד יכולות הטקסט ל-SQL של LLMs מתקדמים יכולות להקל על יצירת שאילתות SQL באמצעות שפה טבעית בתוך מחברות Jupyter. אנו משתמשים במודל ה-Text-to-SQL החדיש defog/sqlcoder-7b-2 בשילוב עם Jupyter AI, עוזר AI מחולל שתוכנן במיוחד עבור מחברות Jupyter, ליצירת שאילתות SQL מורכבות משפה טבעית. על ידי שימוש במודל מתקדם זה, אנו יכולים ליצור ללא מאמץ וביעילות שאילתות SQL מורכבות באמצעות שפה טבעית, ובכך לשפר את חווית ה-SQL שלנו במחברות.
יצירת אב טיפוס למחשב נייד באמצעות Hugging Face Hub
כדי להתחיל ליצור אב טיפוס, אתה צריך את הדברים הבאים:
- קוד GitHub – הקוד המוצג בסעיף זה זמין בהמשך GitHub ריפו ועל ידי הפניה ל מחברת דוגמה.
- JupyterLab Space – גישה ל-SageMaker Studio JupyterLab Space המגובה במופעים מבוססי GPU היא חיונית. בשביל ה
defog/sqlcoder-7b-2מומלץ מודל, מודל של פרמטר 7B, באמצעות מופע ml.g5.2xlarge. חלופות כגוןdefog/sqlcoder-70b-alpha אוdefog/sqlcoder-34b-alphaאפשריים גם להמרת שפה טבעית ל-SQL, אך ייתכן שיידרשו סוגי מופעים גדולים יותר עבור יצירת אב טיפוס. ודא שיש לך את המכסה להשיק מופע מגובה GPU על ידי ניווט למסוף שירות מכסות, חיפוש של SageMaker וחיפוש אחרStudio JupyterLab Apps running on <instance type>.
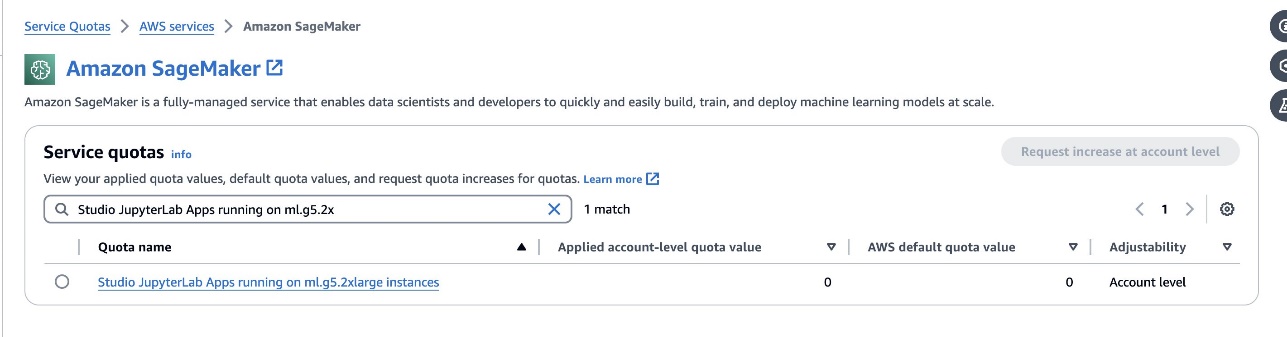
השקת JupyterLab Space חדש מגובת GPU מסטודיו SageMaker שלך. מומלץ ליצור JupyterLab Space חדש עם לפחות 75 GB של חנות בלוקים אלסטית של אמזון (Amazon EBS) אחסון לדגם 7B פרמטרים.


- חיבוק Face Hub - אם לדומיין SageMaker Studio שלך יש גישה להורדת דגמים מה- חיבוק Face Hub, אתה יכול להשתמש
AutoModelForCausalLMכיתה מ חיבוק פנים/שנאים כדי להוריד דגמים באופן אוטומטי ולהצמיד אותם למעבדי ה-GPU המקומיים שלך. משקלי הדגם יאוחסנו במטמון של המכונה המקומית שלך. ראה את הקוד הבא:
לאחר ההורדה המלאה של הדגם ונטען לזיכרון, עליך לראות עלייה בניצול ה-GPU במחשב המקומי שלך. זה מצביע על כך שהמודל משתמש באופן פעיל במשאבי ה-GPU עבור משימות חישוביות. אתה יכול לאמת זאת במרחב JupyterLab משלך על ידי ריצה nvidia-smi (לתצוגה חד פעמית) או nvidia-smi —loop=1 (לחזור על כל שנייה) ממסוף JupyterLab שלך.

מודלים של טקסט ל-SQL מצטיינים בהבנת הכוונה וההקשר של בקשת המשתמש, גם כאשר השפה שבה נעשה שימוש היא שיחה או דו-משמעית. התהליך כולל תרגום קלט שפה טבעית לרכיבי סכימת מסד נתונים נכונים, כגון שמות טבלאות, שמות עמודות ותנאים. עם זאת, מודל טקסט ל-SQL מהמדף לא יכיר מטבעו את המבנה של מחסן הנתונים שלך, את סכימות מסד הנתונים הספציפיות, או יוכל לפרש במדויק את התוכן של טבלה המבוססת רק על שמות עמודות. כדי להשתמש במודלים אלה ביעילות כדי ליצור שאילתות SQL מעשיות ויעילות משפה טבעית, יש צורך להתאים את מודל יצירת הטקסט של SQL לסכימת מסד הנתונים הספציפית של המחסן שלך. הסתגלות זו מתאפשרת באמצעות שימוש ב הנחיות LLM. להלן תבנית הנחיה מומלצת עבור מודל defog/sqlcoder-7b-2 Text-to-SQL, המחולקת לארבעה חלקים:
- המשימות - סעיף זה צריך לציין משימה ברמה גבוהה שיש לבצע על ידי המודל. זה צריך לכלול את סוג הקצה האחורי של מסד הנתונים (כגון Amazon RDS, PostgreSQL או Amazon Redshift) כדי להפוך את המודל למודע להבדלים תחביריים בעלי ניואנסים שעשויים להשפיע על יצירת שאילתת SQL הסופית.
- הוראות – סעיף זה צריך להגדיר גבולות משימות ומודעות לתחום עבור המודל, והוא עשוי לכלול דוגמאות מועטות כדי להנחות את המודל ביצירת שאילתות SQL מכווננות היטב.
- סכימת מסד נתונים - סעיף זה אמור לפרט את סכימות מסד הנתונים של המחסן שלך, תוך התוויית הקשרים בין טבלאות ועמודות כדי לסייע למודל בהבנת מבנה מסד הנתונים.
- תשובה – סעיף זה שמור למודל כדי להוציא את תגובת שאילתת SQL לקלט השפה הטבעית.
דוגמה לסכימת מסד הנתונים וההנחיה המשמשת בסעיף זה זמינה ב- ריפו של GitHub.
הנדסה מהירה אינה רק יצירת שאלות או הצהרות; זוהי אמנות ומדע בעלי ניואנסים שמשפיעים באופן משמעותי על איכות האינטראקציות עם מודל AI. הדרך שבה אתה יוצר הנחיה יכולה להשפיע עמוקות על האופי והתועלת של תגובת הבינה המלאכותית. מיומנות זו היא חיונית במקסום הפוטנציאל של אינטראקציות בינה מלאכותית, במיוחד במשימות מורכבות הדורשות הבנה מיוחדת ותגובות מפורטות.
חשוב שתהיה לך אפשרות לבנות ולבדוק במהירות את תגובת המודל עבור הנחיה נתונה ולייעל את ההנחיה על סמך התגובה. מחברות JupyterLab מספקות את היכולת לקבל משוב מיידי של מודל ממודל הפועל על מחשוב מקומי ולמטב את ההנחיה ולכוונן עוד יותר את תגובת המודל או לשנות מודל לחלוטין. בפוסט זה, אנו משתמשים במחברת SageMaker Studio JupyterLab מגובה ב-NVIDIA A5.2G 10 GB GPU של ml.g24xlarge כדי להפעיל הסקת מודל טקסט ל-SQL על המחשב הנייד ולבנות באופן אינטראקטיבי את הנחיית הדגם שלנו עד שתגובת הדגם תהיה מכווננת מספיק כדי לספק תגובות הניתנות להפעלה ישירות בתאי SQL של JupyterLab. כדי להפעיל מסקנות מודל ובו זמנית להזרים תגובות מודל, אנו משתמשים בשילוב של model.generate ו TextIteratorStreamer כפי שמוגדר בקוד הבא:
ניתן לקשט את הפלט של הדגם עם SageMaker SQL magic %%sm_sql ..., המאפשר למחברת JupyterLab לזהות את התא כתא SQL.
מארח דגמי טקסט ל-SQL כנקודות קצה של SageMaker
בסוף שלב יצירת האב-טיפוס, בחרנו את Text-to-SQL LLM המועדף עלינו, פורמט הנחיה יעיל וסוג מופע מתאים לאירוח הדגם (יחיד-GPU או רב-GPU). SageMaker מאפשר אירוח ניתן להרחבה של מודלים מותאמים אישית באמצעות שימוש בנקודות קצה של SageMaker. ניתן להגדיר נקודות קצה אלו על פי קריטריונים ספציפיים, המאפשרים פריסה של LLMs כנקודות קצה. יכולת זו מאפשרת לך להרחיב את הפתרון לקהל רחב יותר, ומאפשרת למשתמשים ליצור שאילתות SQL מקלט שפה טבעית באמצעות LLMs מתארחים מותאמים אישית. התרשים הבא ממחיש ארכיטקטורה זו.
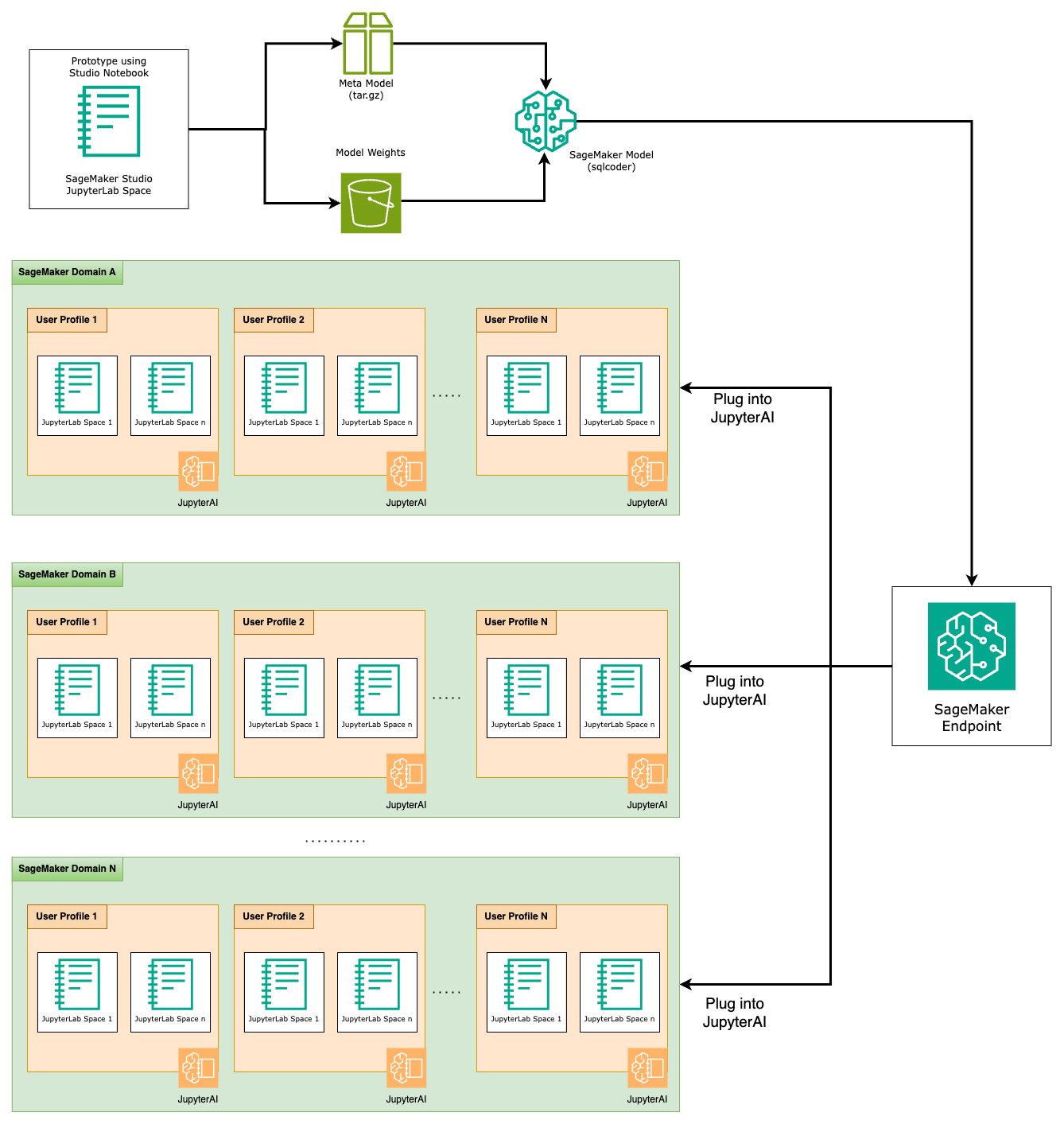
כדי לארח את ה-LLM שלך כנקודת קצה של SageMaker, אתה יוצר מספר חפצים.
החפץ הראשון הוא משקולות מודל. הגשה של SageMaker Deep Java Library (DJL). קונטיינרים מאפשרים לך להגדיר תצורות דרך מטא הגשה.נכסים קובץ, המאפשר לך לכוון את האופן שבו הדגמים מגיעים - ישירות מ-Hugging Face Hub או על ידי הורדת חפצי דגם מאמזון S3. אם תפרט model_id=defog/sqlcoder-7b-2, DJL Serving ינסה להוריד ישירות את הדגם הזה מ-Hugging Face Hub. עם זאת, אתה עלול לגרור חיובי כניסה/יציאה לרשת בכל פעם שנקודת הקצה נפרסת או בקנה מידה גמיש. כדי להימנע מחיובים אלה ועלול להאיץ את ההורדה של חפצי מודל, מומלץ לדלג על השימוש model_id in serving.properties ולשמור משקלים של הדגם כחפצי S3 ולציין אותם רק עם s3url=s3://path/to/model/bin.
שמירת דגם (עם הטוקנייזר שלו) בדיסק והעלאתו לאמזון S3 יכולה להתבצע באמצעות מספר שורות קוד בלבד:
אתה גם משתמש בקובץ הנחיות למסד נתונים. בהגדרה זו, הפקודה של מסד הנתונים מורכבת Task, Instructions, Database Schema, ו Answer sections. עבור הארכיטקטורה הנוכחית, אנו מקצים קובץ הנחיה נפרד לכל סכימת מסד נתונים. עם זאת, קיימת גמישות להרחיב את ההגדרה הזו כדי לכלול מסדי נתונים מרובים לכל קובץ הנחיה, מה שמאפשר למודל להריץ חיבורים מורכבים בין מסדי נתונים באותו שרת. בשלב יצירת האב-טיפוס שלנו, אנו שומרים את ההנחיה של מסד הנתונים כקובץ טקסט בשם <Database-Glue-Connection-Name>.prompt, שם Database-Glue-Connection-Name מתאים לשם החיבור הנראה בסביבת JupyterLab שלך. לדוגמה, פוסט זה מתייחס לחיבור של פתית שלג בשם Airlines_Dataset, כך שמו של קובץ ההנחיה של מסד הנתונים Airlines_Dataset.prompt. לאחר מכן קובץ זה מאוחסן ב-Amazon S3 ולאחר מכן נקרא ומאחסן במטמון על ידי לוגיקת הגשת המודל שלנו.
יתרה מכך, ארכיטקטורה זו מאפשרת לכל משתמש מורשה של נקודת קצה זו להגדיר, לאחסן וליצור שפה טבעית לשאילתות SQL ללא צורך בפריסה מחדש מרובת של המודל. אנו משתמשים בדברים הבאים דוגמה לבקשת מסד נתונים כדי להדגים את הפונקציונליות של טקסט ל-SQL.
לאחר מכן, אתה יוצר לוגיקה של שירות מודל מותאם אישית. בסעיף זה, אתה מתאר לוגיקת מסקנות מותאמת אישית בשם model.py. סקריפט זה נועד לייעל את הביצועים והשילוב של שירותי הטקסט ל-SQL שלנו:
- הגדר את הלוגיקה של אחסון הקבצים של בקשת מסד הנתונים – כדי למזער את זמן ההשהיה, אנו מיישמים לוגיקה מותאמת אישית להורדה ושמירת קבצי הנחיות למסד נתונים. מנגנון זה מוודא שההנחיות זמינות בקלות, ומפחית את התקורה הקשורה להורדות תכופות.
- הגדר לוגיקה של מסקנות מודל מותאם אישית - כדי לשפר את מהירות ההסקה, מודל הטקסט ל-SQL שלנו נטען בפורמט המדויק float16 ולאחר מכן מומר למודל DeepSpeed. שלב זה מאפשר חישוב יעיל יותר. בנוסף, בתוך ההיגיון הזה, אתה מציין אילו פרמטרים המשתמשים יכולים להתאים במהלך שיחות מסקנות כדי להתאים את הפונקציונליות בהתאם לצרכים שלהם.
- הגדר לוגיקת קלט ופלט מותאמים אישית – יצירת פורמטי קלט/פלט ברורים ומותאמים אישית חיונית לאינטגרציה חלקה עם יישומים במורד הזרם. יישום אחד כזה הוא JupyterAI, עליו נדון בסעיף הבא.
בנוסף, אנו כוללים א serving.properties קובץ, הפועל כקובץ תצורה גלובלי עבור דגמים המתארחים באמצעות שרת DJL. למידע נוסף, עיין ב תצורות והגדרות.
לבסוף, אתה יכול לכלול גם א requirements.txt קובץ כדי להגדיר מודולים נוספים הנדרשים להסקת מסקנות ולארוז הכל ל-tarball לפריסה.
ראה את הקוד הבא:
שלב את נקודת הקצה שלך עם עוזר ה-AI של SageMaker Studio Jupyter
Jupyter AI הוא כלי קוד פתוח שמביא בינה מלאכותית למחשבי Jupyter, ומציע פלטפורמה חזקה וידידותית למשתמש לחקר דגמי בינה מלאכותית גנרטיבית. זה משפר את הפרודוקטיביות במחברות JupyterLab ו-Jupyter על-ידי מתן תכונות כמו קסם %%ai ליצירת מגרש משחקים מחולל בינה מלאכותית בתוך מחברות, ממשק משתמש צ'אט מקורי ב-JupyterLab לאינטראקציה עם AI כעוזר שיחה, ותמיכה במגוון רחב של LLMs מ ספקים אוהבים אמזון טיטאן, AI21, Anthropic, Cohere ו-Huging Face או שירותים מנוהלים כמו סלע אמזון ונקודות קצה של SageMaker. עבור פוסט זה, אנו משתמשים באינטגרציה של Jupyter AI עם נקודות קצה של SageMaker כדי להביא את יכולת ה-Text-to-SQL למחברות JupyterLab. כלי Jupyter AI מגיע מותקן מראש בכל מרחבי SageMaker Studio JupyterLab מגובים על ידי תמונות של SageMaker Distribution; משתמשי קצה אינם נדרשים לבצע תצורות נוספות כדי להתחיל להשתמש בתוסף Jupyter AI כדי להשתלב עם נקודת קצה מתארחת של SageMaker. בחלק זה, אנו דנים בשתי הדרכים לשימוש בכלי Jupyter AI המשולב.
Jupyter AI בתוך מחברת באמצעות קסמים
AI של Jupyter %%ai פקודת קסם מאפשרת לך להפוך את מחברות SageMaker Studio JupyterLab שלך לסביבת בינה מלאכותית ניתנת לשחזור. כדי להתחיל להשתמש ב-AI magics, ודא שטעינת את התוסף jupyter_ai_magics לשימוש %%ai קסם, ובנוסף לטעון amazon_sagemaker_sql_magic כדי להשתמש %%sm_sql קֶסֶם:
כדי להפעיל שיחה לנקודת הקצה של SageMaker מהמחברת שלך באמצעות ה %%ai פקודת קסם, ספק את הפרמטרים הבאים ובנה את הפקודה באופן הבא:
- –שם-אזור – ציין את האזור שבו נקודת הקצה שלך פרוסה. זה מוודא שהבקשה מנותבת למיקום הגיאוגרפי הנכון.
- –סכמה-בקשה - כלול את הסכימה של נתוני הקלט. סכימה זו מתארת את הפורמט והסוגים הצפויים של נתוני הקלט שהמודל שלך צריך כדי לעבד את הבקשה.
- -נתיב תגובה – הגדר את הנתיב בתוך אובייקט התגובה שבו נמצא הפלט של המודל שלך. נתיב זה משמש כדי לחלץ את הנתונים הרלוונטיים מהתגובה המוחזרת על ידי המודל שלך.
- -f (אופציונלי) - זה פורמט פלט דגל המציין את סוג הפלט המוחזר על ידי המודל. בהקשר של מחברת Jupyter, אם הפלט הוא קוד, יש להגדיר דגל זה בהתאם כדי לעצב את הפלט כקוד הפעלה בחלק העליון של תא מחברת Jupyter, ואחריו אזור קלט טקסט חופשי לאינטראקציה עם המשתמש.
לדוגמה, הפקודה בתא מחברת Jupyter עשויה להיראות כמו הקוד הבא:
חלון צ'אט של Jupyter AI
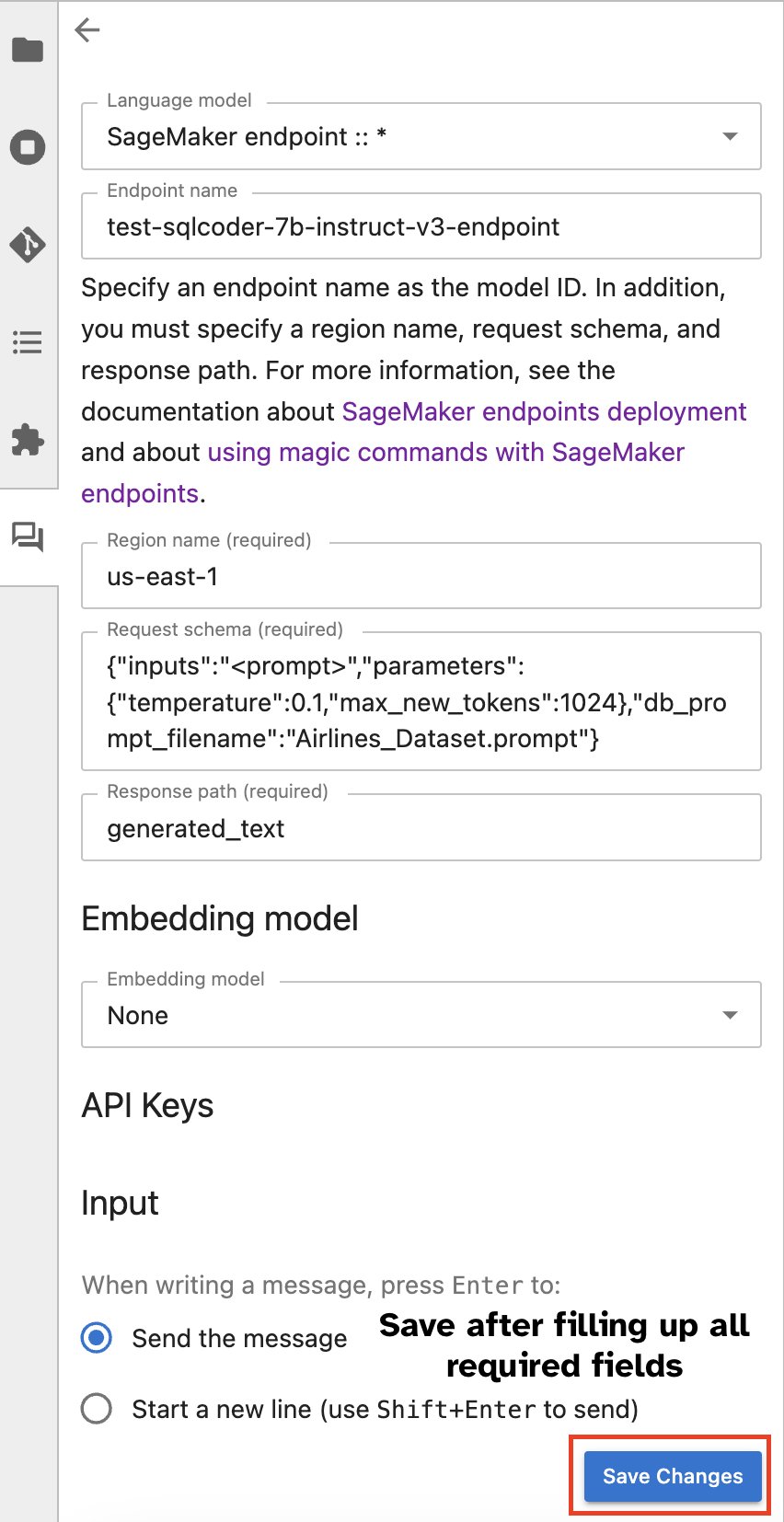
לחלופין, אתה יכול ליצור אינטראקציה עם נקודות הקצה של SageMaker באמצעות ממשק משתמש מובנה, המפשט את תהליך יצירת השאילתות או התקשרות בדיאלוג. לפני שמתחילים לשוחח בצ'אט עם נקודת הקצה של SageMaker, הגדר את ההגדרות הרלוונטיות ב-Jupyter AI עבור נקודת הקצה של SageMaker, כפי שמוצג בצילום המסך הבא.
 |
 |
סיכום
SageMaker Studio מפשט ומייעל כעת את זרימת העבודה של מדעני הנתונים על ידי שילוב תמיכת SQL במחברות JupyterLab. זה מאפשר למדעני נתונים להתמקד במשימות שלהם ללא צורך בניהול כלים מרובים. יתר על כן, שילוב ה-SQL המובנה החדש ב-SageMaker Studio מאפשר לפרסונות נתונים ליצור ללא מאמץ שאילתות SQL תוך שימוש בטקסט בשפה טבעית כקלט, ובכך להאיץ את זרימת העבודה שלהם.
אנו ממליצים לך לחקור את התכונות הללו ב-SageMaker Studio. למידע נוסף, עיין ב הכן נתונים עם SQL בסטודיו.
נספח
הפעל את תא ה-SQL של דפדפן SQL ושל המחברת בסביבות מותאמות אישית
אם אינך משתמש בתמונת SageMaker Distribution או משתמש ב-Distribution Images 1.5 ומטה, הפעל את הפקודות הבאות כדי להפעיל את תכונת הגלישה של SQL בתוך סביבת JupyterLab שלך:
העבר את הווידג'ט של דפדפן SQL
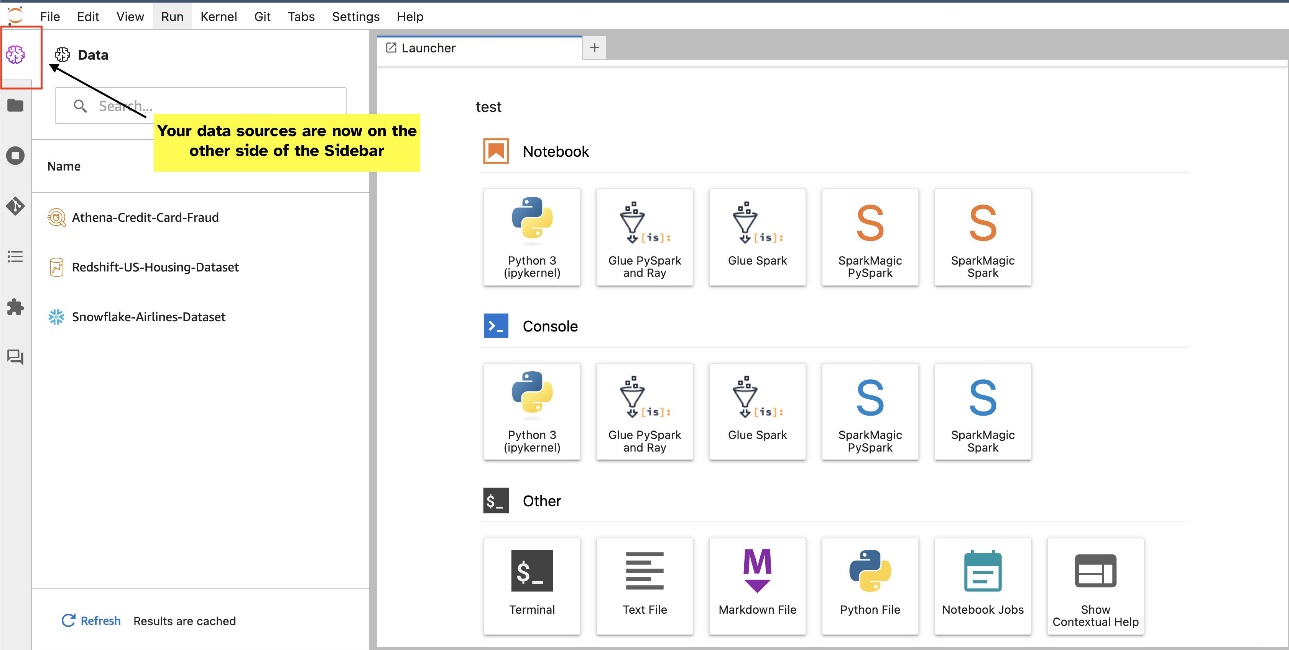
ווידג'טים של JupyterLab מאפשרים העברה. בהתאם להעדפה שלך, תוכל להעביר ווידג'טים לשני הצדדים של חלונית הווידג'טים של JupyterLab. אם אתה מעדיף, אתה יכול להעביר את הכיוון של יישומון SQL לצד הנגדי (מימין לשמאל) של סרגל הצד בלחיצה ימנית פשוטה על סמל הווידג'ט ובחירה החלף צד בסרגל הצד.
 |
 |
על המחברים
 פראנב מרתי הוא אדריכל פתרונות AI/ML מומחה ב-AWS. הוא מתמקד בסיוע ללקוחות לבנות, לאמן, לפרוס ולהעביר עומסי עבודה של למידת מכונה (ML) אל SageMaker. הוא עבד בעבר בתעשיית המוליכים למחצה בפיתוח מודלים של ראייה ממוחשבת גדולה (CV) ועיבוד שפה טבעית (NLP) לשיפור תהליכי מוליכים למחצה תוך שימוש בטכניקות ML מתקדמות. בזמנו הפנוי הוא נהנה לשחק שח ולטייל. אתה יכול למצוא את Pranav על לינקדין.
פראנב מרתי הוא אדריכל פתרונות AI/ML מומחה ב-AWS. הוא מתמקד בסיוע ללקוחות לבנות, לאמן, לפרוס ולהעביר עומסי עבודה של למידת מכונה (ML) אל SageMaker. הוא עבד בעבר בתעשיית המוליכים למחצה בפיתוח מודלים של ראייה ממוחשבת גדולה (CV) ועיבוד שפה טבעית (NLP) לשיפור תהליכי מוליכים למחצה תוך שימוש בטכניקות ML מתקדמות. בזמנו הפנוי הוא נהנה לשחק שח ולטייל. אתה יכול למצוא את Pranav על לינקדין.
 וארון שאה הוא מהנדס תוכנה שעובד על Amazon SageMaker Studio בשירותי האינטרנט של אמזון. הוא מתמקד בבניית פתרונות ML אינטראקטיביים המפשטים את עיבוד הנתונים ומסעות הכנת הנתונים. בזמנו הפנוי, וארון נהנה מפעילויות חוצות כולל טיולים וסקי, והוא תמיד מוכן לגלות מקומות חדשים ומרגשים.
וארון שאה הוא מהנדס תוכנה שעובד על Amazon SageMaker Studio בשירותי האינטרנט של אמזון. הוא מתמקד בבניית פתרונות ML אינטראקטיביים המפשטים את עיבוד הנתונים ומסעות הכנת הנתונים. בזמנו הפנוי, וארון נהנה מפעילויות חוצות כולל טיולים וסקי, והוא תמיד מוכן לגלות מקומות חדשים ומרגשים.
 סומדה סוואמי הוא מנהל מוצר ראשי בשירותי האינטרנט של אמזון, שם הוא מוביל את צוות SageMaker Studio במשימתו לפתח IDE מובחר עבור מדעי נתונים ולמידת מכונה. הוא הקדיש את 15 השנים האחרונות לבניית מוצרי צריכה וארגונים מבוססי למידת מכונה.
סומדה סוואמי הוא מנהל מוצר ראשי בשירותי האינטרנט של אמזון, שם הוא מוביל את צוות SageMaker Studio במשימתו לפתח IDE מובחר עבור מדעי נתונים ולמידת מכונה. הוא הקדיש את 15 השנים האחרונות לבניית מוצרי צריכה וארגונים מבוססי למידת מכונה.
 בוסקו אלבוקרקי הוא Sr. Partner Solutions Architect ב-AWS ובעל ניסיון של למעלה מ-20 שנה בעבודה עם מוצרי מסדי נתונים וניתוח של ספקי מסדי נתונים ארגוניים וספקי ענן. הוא עזר לחברות טכנולוגיה לתכנן ולהטמיע פתרונות ומוצרים לניתוח נתונים.
בוסקו אלבוקרקי הוא Sr. Partner Solutions Architect ב-AWS ובעל ניסיון של למעלה מ-20 שנה בעבודה עם מוצרי מסדי נתונים וניתוח של ספקי מסדי נתונים ארגוניים וספקי ענן. הוא עזר לחברות טכנולוגיה לתכנן ולהטמיע פתרונות ומוצרים לניתוח נתונים.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

