I modelli linguistici di grandi dimensioni (LLM) vengono generalmente addestrati su grandi set di dati disponibili pubblicamente che sono indipendenti dal dominio. Per esempio, Il lama di Meta i modelli vengono addestrati su set di dati come Scansione comune, C4,Wikipedia e ArXiv. Questi set di dati comprendono una vasta gamma di argomenti e domini. Sebbene i modelli risultanti forniscano risultati sorprendentemente buoni per attività generali, come la generazione di testo e il riconoscimento di entità, è dimostrato che i modelli addestrati con set di dati specifici del dominio possono migliorare ulteriormente le prestazioni LLM. Ad esempio, i dati di addestramento utilizzati per BloombergGPT è costituito per il 51% da documenti specifici del dominio, comprese notizie finanziarie, documenti depositati e altro materiale finanziario. Il LLM risultante supera i LLM addestrati su set di dati non specifici del dominio quando testati su attività specifiche della finanza. Gli autori di BloombergGPT hanno concluso che il loro modello supera tutti gli altri modelli testati per quattro dei cinque compiti finanziari. Il modello ha fornito prestazioni ancora migliori quando testato per le attività finanziarie interne di Bloomberg con un ampio margine, fino a 60 punti migliori (su 100). Sebbene sia possibile saperne di più sui risultati della valutazione completa nel carta, il seguente campione catturato da BloombergGPT Il documento può darti un'idea dei vantaggi della formazione dei LLM utilizzando dati specifici del dominio finanziario. Come mostrato nell'esempio, il modello BloombergGPT ha fornito risposte corrette mentre altri modelli non specifici del dominio hanno avuto difficoltà:
Questo post fornisce una guida alla formazione dei LLM specificatamente per il settore finanziario. Copriamo le seguenti aree chiave:
- Raccolta e preparazione dei dati – Guida all’acquisizione e alla cura dei dati finanziari rilevanti per una formazione efficace del modello
- Pre-formazione continua vs. messa a punto – Quando utilizzare ciascuna tecnica per ottimizzare le prestazioni del tuo LLM
- Efficiente pre-formazione continua – Strategie per snellire il processo di pre-formazione continua, risparmiando tempo e risorse
Questo post riunisce le competenze del team di ricerca scientifica applicata di Amazon Finance Technology e del team di specialisti AWS Worldwide per il settore finanziario globale. Parte del contenuto è basato sul documento Efficiente formazione preliminare continua per la creazione di modelli linguistici di grandi dimensioni specifici per domini.
Raccolta e preparazione dei dati finanziari
La formazione preliminare continua del dominio richiede un set di dati specifico del dominio su larga scala e di alta qualità. Di seguito sono riportati i passaggi principali per la cura del set di dati del dominio:
- Identificare le fonti di dati – Le potenziali fonti di dati per il corpus di domini includono il web aperto, Wikipedia, libri, social media e documenti interni.
- Filtri dati di dominio – Poiché l’obiettivo finale è curare il corpus del dominio, potrebbe essere necessario applicare passaggi aggiuntivi per filtrare campioni irrilevanti per il dominio di destinazione. Ciò riduce il corpus inutile per la pre-formazione continua e riduce i costi di formazione.
- Pre-elaborazione – Potresti prendere in considerazione una serie di passaggi di preelaborazione per migliorare la qualità dei dati e l'efficienza della formazione. Ad esempio, alcune origini dati possono contenere un discreto numero di token rumorosi; la deduplicazione è considerata un passo utile per migliorare la qualità dei dati e ridurre i costi di formazione.
Per sviluppare LLM finanziari, è possibile utilizzare due importanti fonti di dati: News CommonCrawl e documenti SEC. Un deposito SEC è un rendiconto finanziario o un altro documento formale presentato alla Securities and Exchange Commission (SEC) degli Stati Uniti. Le società quotate in borsa sono tenute a depositare regolarmente vari documenti. Ciò crea un gran numero di documenti nel corso degli anni. Notizie CommonCrawl è un set di dati rilasciato da CommonCrawl nel 2016. Contiene articoli di notizie provenienti da siti di notizie di tutto il mondo.
Notizie CommonCrawl è disponibile su Servizio di archiviazione semplice Amazon (Amazon S3) nel commoncrawl secchio a crawl-data/CC-NEWS/. È possibile ottenere l'elenco dei file utilizzando il file Interfaccia della riga di comando di AWS (AWS CLI) e il seguente comando:
In Efficiente formazione preliminare continua per la creazione di modelli linguistici di grandi dimensioni specifici per domini, gli autori utilizzano un approccio basato su URL e parole chiave per filtrare gli articoli di notizie finanziarie dalle notizie generiche. Nello specifico, gli autori mantengono un elenco di importanti organi di informazione finanziaria e una serie di parole chiave relative alle notizie finanziarie. Identifichiamo un articolo come notizie finanziarie se proviene da organi di informazione finanziaria o se sono presenti parole chiave nell'URL. Questo approccio semplice ma efficace ti consente di identificare le notizie finanziarie non solo dai notiziari finanziari ma anche dalle sezioni finanziarie dei notiziari generici.
I documenti depositati alla SEC sono disponibili online tramite il database EDGAR (Electronic Data Gathering, Analysis, and Retrieval) della SEC, che fornisce accesso aperto ai dati. Puoi prelevare i file archiviati direttamente da EDGAR o utilizzare le API Amazon Sage Maker con poche righe di codice, per qualsiasi periodo di tempo e per un numero elevato di ticker (ovvero, l'identificativo assegnato dalla SEC). Per saperne di più, fare riferimento a Recupero archiviazione SEC.
La tabella seguente riassume i dettagli principali di entrambe le origini dati.
| . | Notizie CommonCrawl | Archiviazione SEC |
| Copertura | 2016-2022 | 1993-2022 |
| Taglia | 25.8 miliardi di parole | 5.1 miliardi di parole |
Gli autori eseguono alcuni passaggi aggiuntivi di preelaborazione prima che i dati vengano inseriti in un algoritmo di training. Innanzitutto, osserviamo che i documenti depositati alla SEC contengono testo rumoroso a causa della rimozione di tabelle e figure, quindi gli autori rimuovono frasi brevi che sono considerate etichette di tabelle o figure. In secondo luogo, applichiamo un algoritmo di hashing sensibile alla località per deduplicare i nuovi articoli e documenti. Per le archiviazioni SEC, effettuiamo la deduplicazione a livello di sezione anziché a livello di documento. Infine, concateniamo i documenti in una lunga stringa, la tokenizziamo e suddividiamo la tokenizzazione in parti della lunghezza massima di input supportata dal modello da addestrare. Ciò migliora il rendimento della pre-formazione continua e riduce i costi di formazione.
Pre-formazione continua vs. messa a punto
La maggior parte dei LLM disponibili sono di uso generale e mancano di capacità specifiche del dominio. I LLM di dominio hanno mostrato prestazioni considerevoli nei settori medico, finanziario o scientifico. Affinché un LLM possa acquisire conoscenze specifiche del dominio, esistono quattro metodi: formazione da zero, pre-formazione continua, perfezionamento delle istruzioni sulle attività del dominio e Retrieval Augmented Generation (RAG).
Nei modelli tradizionali, la messa a punto viene solitamente utilizzata per creare modelli specifici per attività per un dominio. Ciò significa mantenere più modelli per più attività come l'estrazione di entità, la classificazione degli intenti, l'analisi del sentiment o la risposta alle domande. Con l'avvento dei LLM, la necessità di mantenere modelli separati è diventata obsoleta utilizzando tecniche come l'apprendimento in contesto o il prompt. Ciò consente di risparmiare lo sforzo necessario per mantenere una pila di modelli per attività correlate ma distinte.
Intuitivamente, puoi formare LLM da zero con dati specifici del dominio. Sebbene la maggior parte del lavoro per creare LLM di domini si sia concentrato sulla formazione da zero, è proibitivamente costoso. Ad esempio, il modello GPT-4 costa oltre $ 100 milioni al treno. Questi modelli vengono addestrati su un mix di dati di dominio aperto e dati di dominio. La formazione preliminare continua può aiutare i modelli ad acquisire conoscenze specifiche del dominio senza sostenere i costi della formazione preliminare da zero perché si preforma un LLM di dominio aperto esistente solo sui dati del dominio.
Con l'ottimizzazione delle istruzioni su un'attività, non è possibile fare in modo che il modello acquisisca la conoscenza del dominio perché LLM acquisisce solo le informazioni sul dominio contenute nel set di dati di ottimizzazione delle istruzioni. A meno che non venga utilizzato un set di dati molto ampio per la messa a punto delle istruzioni, non è sufficiente acquisire la conoscenza del dominio. L'approvvigionamento di set di dati di istruzioni di alta qualità è solitamente impegnativo ed è il motivo per utilizzare in primo luogo i LLM. Inoltre, la messa a punto delle istruzioni su un compito può influenzare le prestazioni di altri compiti (come visto in questo documento). Tuttavia, la messa a punto dell’istruzione è più conveniente rispetto a entrambe le alternative pre-formazione.
La figura seguente mette a confronto la tradizionale regolazione fine specifica dell'attività. vs paradigma di apprendimento in-contesto con LLM.
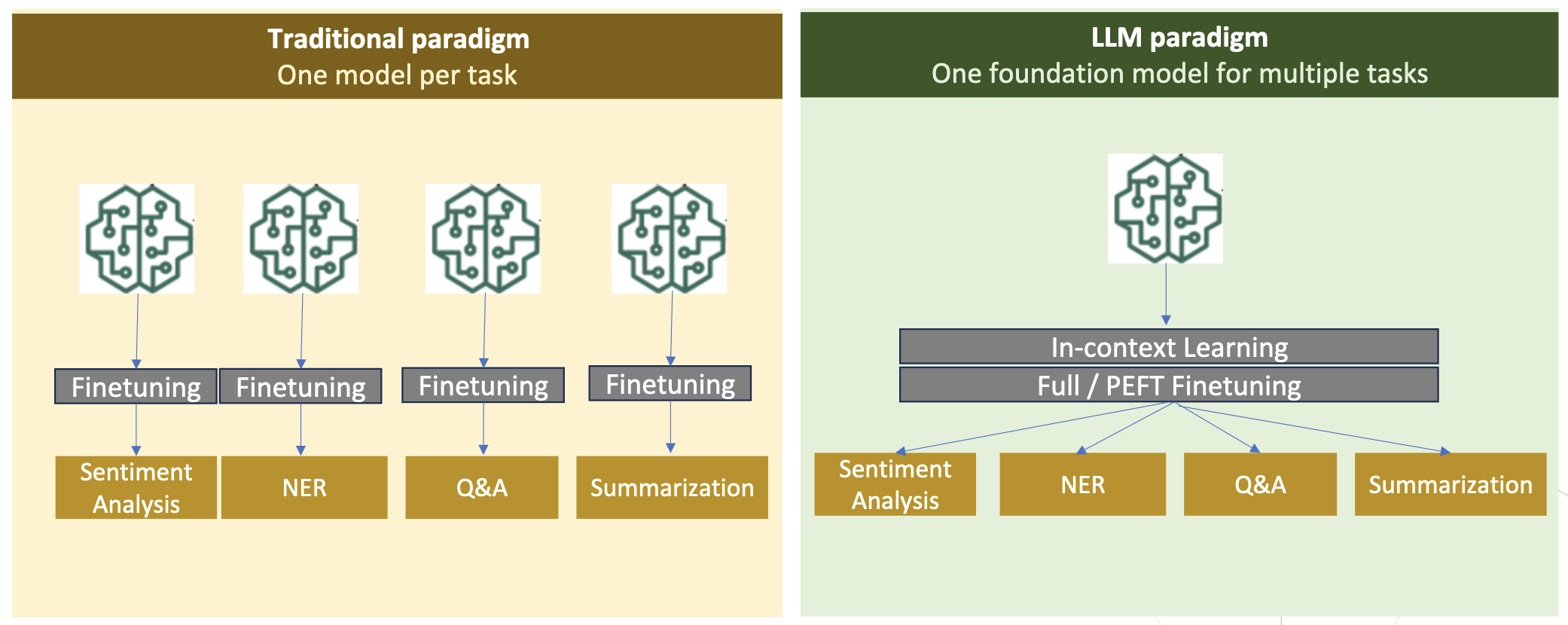 RAG è il modo più efficace per guidare un LLM a generare risposte radicate in un dominio. Sebbene possa guidare un modello per generare risposte fornendo fatti dal dominio come informazioni ausiliarie, non acquisisce il linguaggio specifico del dominio perché LLM si basa ancora su uno stile di linguaggio non di dominio per generare le risposte.
RAG è il modo più efficace per guidare un LLM a generare risposte radicate in un dominio. Sebbene possa guidare un modello per generare risposte fornendo fatti dal dominio come informazioni ausiliarie, non acquisisce il linguaggio specifico del dominio perché LLM si basa ancora su uno stile di linguaggio non di dominio per generare le risposte.
La pre-formazione continua è una via di mezzo tra la pre-formazione e l'ottimizzazione dell'istruzione in termini di costi, pur essendo una forte alternativa all'acquisizione di conoscenze e stili specifici del dominio. Può fornire un modello generale sul quale è possibile eseguire un'ulteriore messa a punto delle istruzioni su dati di istruzioni limitati. La pre-formazione continua può essere una strategia economicamente vantaggiosa per domini specializzati in cui l'insieme di attività a valle è ampio o sconosciuto e i dati di ottimizzazione delle istruzioni etichettate sono limitati. In altri scenari, la messa a punto delle istruzioni o il RAG potrebbero essere più adatti.
Per ulteriori informazioni sull'ottimizzazione, sul RAG e sull'addestramento del modello, fare riferimento a Metti a punto un modello di fondazione, Recupero della generazione aumentata (RAG)e Addestra un modello con Amazon SageMaker, rispettivamente. Per questo post, ci concentriamo su una pre-formazione continua ed efficiente.
Metodologia di pre-formazione continua efficiente
La pre-formazione continua prevede la seguente metodologia:
- Pre-addestramento continuo adattivo al dominio (DACP) – Nel giornale Efficiente formazione preliminare continua per la creazione di modelli linguistici di grandi dimensioni specifici per domini, gli autori pre-addestrano continuamente la suite di modelli linguistici Pythia sul corpus finanziario per adattarla al dominio finanziario. L’obiettivo è creare LLM finanziari inserendo i dati dell’intero dominio finanziario in un modello open source. Poiché il corpus di formazione contiene tutti i set di dati selezionati nel dominio, il modello risultante dovrebbe acquisire conoscenze specifiche della finanza, diventando così un modello versatile per varie attività finanziarie. Ciò si traduce in modelli FinPythia.
- Pre-formazione continua adattiva alle attività (TACP) – Gli autori pre-addestrano ulteriormente i modelli sui dati delle attività etichettate e non etichettate per adattarli a compiti specifici. In determinate circostanze, gli sviluppatori potrebbero preferire modelli che offrono prestazioni migliori su un gruppo di attività all'interno del dominio piuttosto che un modello generico del dominio. Il TACP è concepito come una pre-formazione continua mirata a migliorare le prestazioni su compiti mirati, senza requisiti per i dati etichettati. Nello specifico, gli autori pre-addestrano continuamente i modelli open source sui token delle attività (senza etichette). La limitazione principale del TACP risiede nella costruzione di LLM specifici per attività anziché LLM di base, a causa del solo utilizzo di dati di attività senza etichetta per la formazione. Sebbene il DACP utilizzi un corpus molto più ampio, è proibitivamente costoso. Per bilanciare queste limitazioni, gli autori propongono due approcci che mirano a costruire LLM di base specifici per dominio preservando prestazioni superiori sulle attività target:
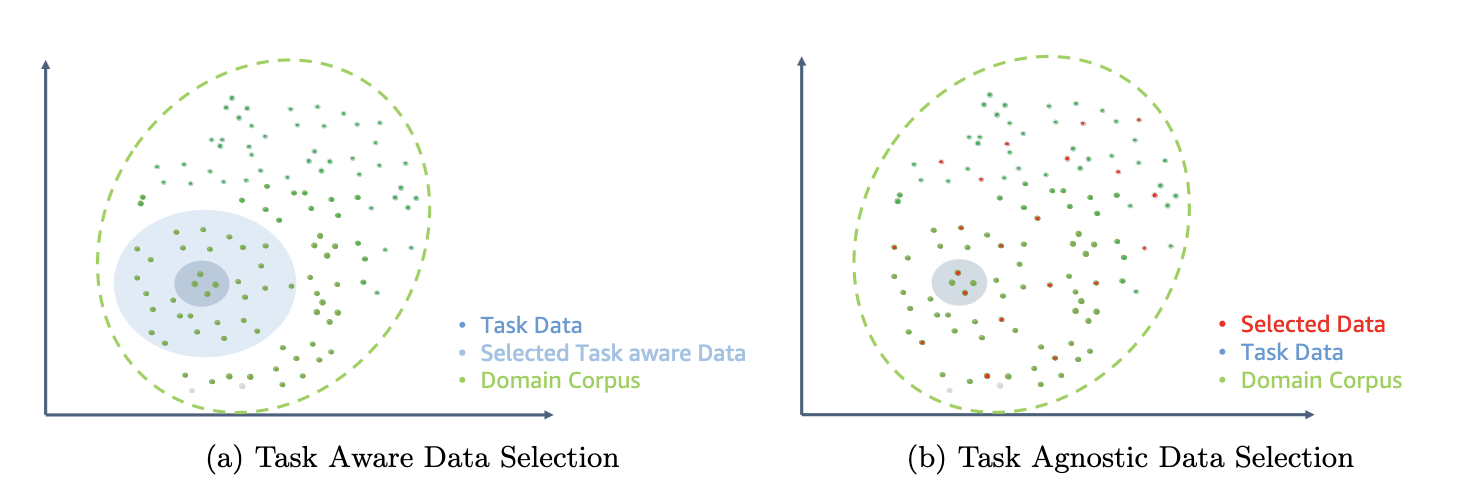
- DACP efficiente con attività simili (ETS-DACP) – Gli autori propongono di selezionare un sottoinsieme del corpus finanziario che è molto simile ai dati del compito utilizzando la somiglianza di incorporamento. Questo sottoinsieme viene utilizzato per il pre-addestramento continuo per renderlo più efficiente. Nello specifico, gli autori pre-addestrano continuamente il LLM open source su un piccolo corpus estratto dal corpus finanziario che è vicino alle attività target nella distribuzione. Ciò può aiutare a migliorare le prestazioni delle attività perché adottiamo il modello per la distribuzione dei token delle attività nonostante i dati etichettati non siano richiesti.
- DACP efficiente e indipendente dalle attività (ETA-DACP) – Gli autori propongono di utilizzare parametri come perplessità ed entropia di tipo token che non richiedono dati sulle attività per selezionare campioni dal corpus finanziario per un pre-addestramento continuo ed efficiente. Questo approccio è progettato per gestire scenari in cui i dati delle attività non sono disponibili o in cui si preferiscono modelli di dominio più versatili per il dominio più ampio. Gli autori adottano due dimensioni per selezionare campioni di dati importanti per ottenere informazioni sul dominio da un sottoinsieme di dati di dominio pre-addestramento: novità e diversità. La novità, misurata dalla perplessità registrata dal modello target, si riferisce alle informazioni che prima non erano state viste dal LLM. I dati con un elevato livello di novità indicano nuove conoscenze per il LLM e tali dati sono considerati più difficili da apprendere. Questo aggiorna i LLM generici con una conoscenza intensiva del dominio durante la pre-formazione continua. La diversità, d'altro canto, cattura la diversità delle distribuzioni dei tipi di token nel corpus del dominio, che è stata documentata come una caratteristica utile nella ricerca dell'apprendimento curriculare sulla modellazione linguistica.
La figura seguente confronta un esempio di ETS-DACP (a sinistra) e ETA-DACP (a destra).
Adottiamo due schemi di campionamento per selezionare attivamente i punti dati dal corpus finanziario curato: campionamento hard e campionamento soft. Il primo viene effettuato classificando prima il corpus finanziario in base ai parametri corrispondenti e quindi selezionando i campioni top-k, dove k è predeterminato in base al budget di formazione. Per quest'ultimo, gli autori assegnano pesi di campionamento per ciascun punto dati in base ai valori metrici, quindi campionano casualmente k punti dati per soddisfare il budget di formazione.
Risultato e analisi
Gli autori valutano i LLM finanziari risultanti su una serie di compiti finanziari per indagare l’efficacia della pre-formazione continua:
- Banca delle frasi finanziarie – Un compito di classificazione del sentiment sulle notizie finanziarie.
- FiQA SA – Un’attività di classificazione del sentiment basata sugli aspetti basata su notizie e titoli finanziari.
- Titolo – Un compito di classificazione binaria per stabilire se un titolo su un'entità finanziaria contiene determinate informazioni.
- NER – Un'attività di estrazione di entità finanziarie denominate basata sulla sezione di valutazione del rischio di credito dei rapporti della SEC. Le parole in questa attività sono annotate con PER, LOC, ORG e MISC.
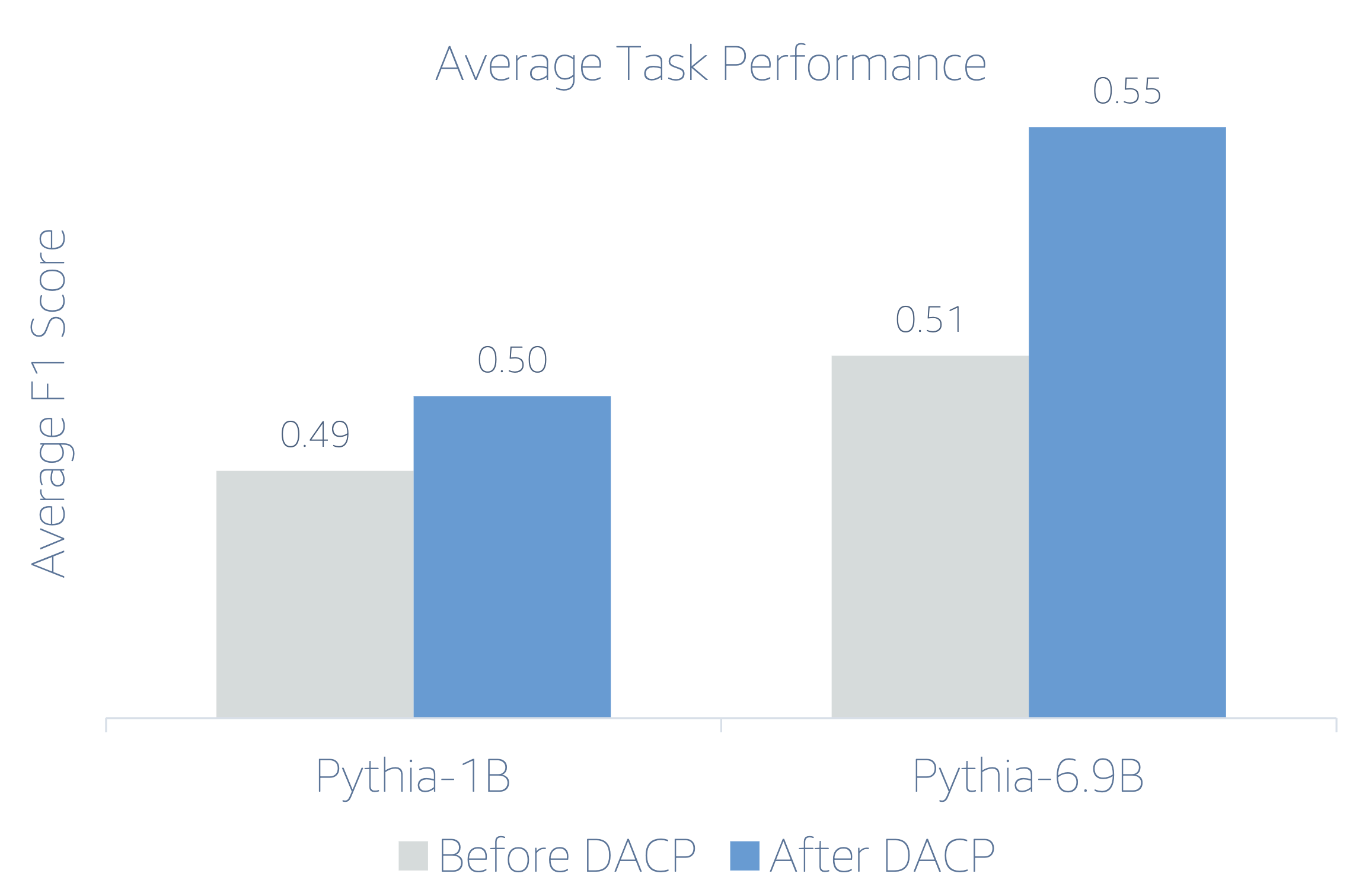
Poiché i LLM finanziari sono istruzioni ottimizzate, gli autori valutano i modelli in un contesto di 5 fasi per ciascuna attività per motivi di robustezza. In media, FinPythia 6.9B supera Pythia 6.9B del 10% in quattro attività, il che dimostra l'efficacia del pre-addestramento continuo specifico del dominio. Per il modello 1B, il miglioramento è meno profondo, ma le prestazioni migliorano comunque in media del 2%.
La figura seguente illustra la differenza di prestazioni prima e dopo DACP su entrambi i modelli.
La figura seguente mostra due esempi qualitativi generati da Pythia 6.9B e FinPythia 6.9B. Per due domande relative alla finanza riguardanti un gestore degli investitori e un termine finanziario, Pythia 6.9B non comprende il termine né riconosce il nome, mentre FinPythia 6.9B genera correttamente risposte dettagliate. Gli esempi qualitativi dimostrano che la pre-formazione continua consente ai LLM di acquisire conoscenze del settore durante il processo.

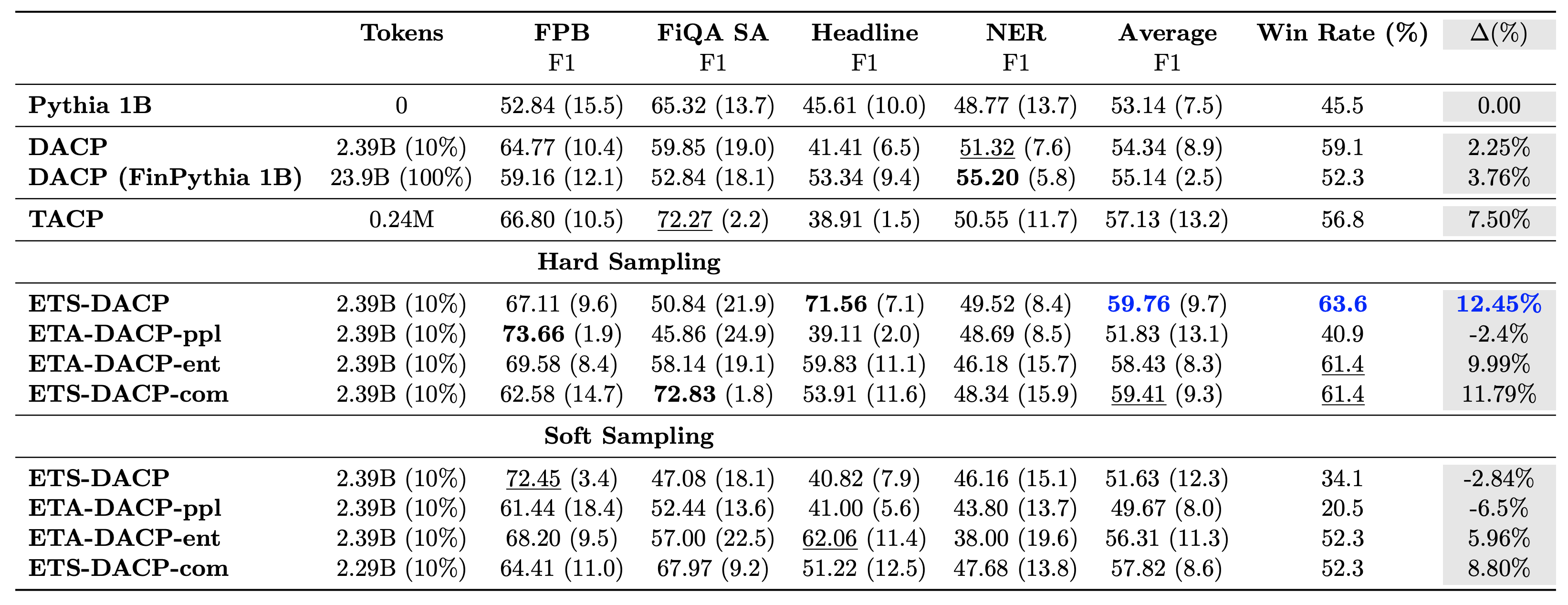
La tabella seguente mette a confronto vari approcci efficienti di pre-formazione continua. ETA-DACP-ppl è ETA-DACP basato sulla perplessità (novità) e ETA-DACP-ent è basato sull'entropia (diversità). ETS-DACP-com è simile a DACP con la selezione dei dati calcolando la media di tutti e tre i parametri. Di seguito sono riportati alcuni punti salienti dei risultati:
- I metodi di selezione dei dati sono efficienti – Superano il pre-addestramento continuo standard con solo il 10% dei dati di addestramento. L'efficiente pre-formazione continua che include DACP Task-Similar (ETS-DACP), DACP Task-Agnostic basato sull'entropia (ESA-DACP-ent) e DACP Task-Similar basato su tutti e tre i parametri (ETS-DACP-com) supera il DACP standard in media nonostante siano formati solo sul 10% del corpus finanziario.
- La selezione dei dati in base al compito funziona al meglio in linea con la ricerca su piccoli modelli linguistici – ETS-DACP registra la migliore prestazione media tra tutti i metodi e, sulla base di tutte e tre le metriche, registra la seconda migliore prestazione dell’attività. Ciò suggerisce che l’utilizzo di dati sulle attività senza etichetta è ancora un approccio efficace per migliorare le prestazioni delle attività nel caso dei LLM.
- La selezione dei dati indipendenti dall'attività è al secondo posto – ESA-DACP-ent segue le prestazioni dell’approccio di selezione dei dati task-aware, il che implica che potremmo comunque migliorare le prestazioni delle attività selezionando attivamente campioni di alta qualità non legati a compiti specifici. Ciò apre la strada alla creazione di LLM finanziari per l'intero dominio ottenendo prestazioni di attività superiori.
Una questione fondamentale riguardante la pre-formazione continua è se influenzi negativamente le prestazioni nelle attività non di dominio. Gli autori valutano inoltre il modello continuamente pre-addestrato su quattro compiti generici ampiamente utilizzati: ARC, MMLU, TruthQA e HellaSwag, che misurano la capacità di risposta alle domande, ragionamento e completamento. Gli autori rilevano che il pre-addestramento continuo non influisce negativamente sulle prestazioni non di dominio. Per ulteriori dettagli, fare riferimento a Efficiente formazione preliminare continua per la creazione di modelli linguistici di grandi dimensioni specifici per domini.
Conclusione
Questo post ha offerto approfondimenti sulla raccolta dei dati e sulle strategie di pre-formazione continue per la formazione dei LLM nel settore finanziario. Puoi iniziare a formare i tuoi LLM per attività finanziarie utilizzando Formazione su Amazon SageMaker or Roccia Amazzonica oggi.
Informazioni sugli autori
 Yong Xie è uno scienziato applicato in Amazon FinTech. Si concentra sullo sviluppo di modelli linguistici di grandi dimensioni e di applicazioni di intelligenza artificiale generativa per la finanza.
Yong Xie è uno scienziato applicato in Amazon FinTech. Si concentra sullo sviluppo di modelli linguistici di grandi dimensioni e di applicazioni di intelligenza artificiale generativa per la finanza.
 Karan Aggarwal è uno scienziato applicato senior presso Amazon FinTech con un focus sull'intelligenza artificiale generativa per casi d'uso finanziari. Karan ha una vasta esperienza nell'analisi di serie temporali e nella PNL, con particolare interesse per l'apprendimento da dati etichettati limitati
Karan Aggarwal è uno scienziato applicato senior presso Amazon FinTech con un focus sull'intelligenza artificiale generativa per casi d'uso finanziari. Karan ha una vasta esperienza nell'analisi di serie temporali e nella PNL, con particolare interesse per l'apprendimento da dati etichettati limitati
 Aitzaz Ahmad è un Applied Science Manager presso Amazon, dove guida un team di scienziati che sviluppano varie applicazioni di machine learning e intelligenza artificiale generativa nella finanza. I suoi interessi di ricerca riguardano la PNL, l'intelligenza artificiale generativa e gli agenti LLM. Ha conseguito il dottorato in ingegneria elettrica presso la Texas A&M University.
Aitzaz Ahmad è un Applied Science Manager presso Amazon, dove guida un team di scienziati che sviluppano varie applicazioni di machine learning e intelligenza artificiale generativa nella finanza. I suoi interessi di ricerca riguardano la PNL, l'intelligenza artificiale generativa e gli agenti LLM. Ha conseguito il dottorato in ingegneria elettrica presso la Texas A&M University.
 QingweiLi è uno specialista di machine learning presso Amazon Web Services. Ha conseguito il dottorato di ricerca. in Ricerca Operativa dopo aver rotto il conto della borsa di ricerca del suo consulente e non aver consegnato il Premio Nobel che aveva promesso. Attualmente aiuta i clienti nel settore dei servizi finanziari a creare soluzioni di machine learning su AWS.
QingweiLi è uno specialista di machine learning presso Amazon Web Services. Ha conseguito il dottorato di ricerca. in Ricerca Operativa dopo aver rotto il conto della borsa di ricerca del suo consulente e non aver consegnato il Premio Nobel che aveva promesso. Attualmente aiuta i clienti nel settore dei servizi finanziari a creare soluzioni di machine learning su AWS.
 Raghvender Arni guida il Customer Acceleration Team (CAT) all'interno di AWS Industries. Il CAT è un team interfunzionale globale di architetti cloud, ingegneri software, data scientist ed esperti e progettisti di intelligenza artificiale/ML a contatto con i clienti che promuove l'innovazione tramite la prototipazione avanzata e promuove l'eccellenza operativa del cloud tramite competenze tecniche specializzate.
Raghvender Arni guida il Customer Acceleration Team (CAT) all'interno di AWS Industries. Il CAT è un team interfunzionale globale di architetti cloud, ingegneri software, data scientist ed esperti e progettisti di intelligenza artificiale/ML a contatto con i clienti che promuove l'innovazione tramite la prototipazione avanzata e promuove l'eccellenza operativa del cloud tramite competenze tecniche specializzate.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

