Distribuisci un modello di diarizzazione degli altoparlanti Hugging Face (PyAnnote) su Amazon SageMaker come endpoint asincrono | Servizi Web di Amazon
La diarizzazione del relatore, un processo essenziale nell'analisi audio, segmenta un file audio in base all'identità del relatore. Questo post approfondisce l'integrazione di PyAnnote di Hugging Face per la diarizzazione degli oratori Amazon Sage Maker endpoint asincroni.
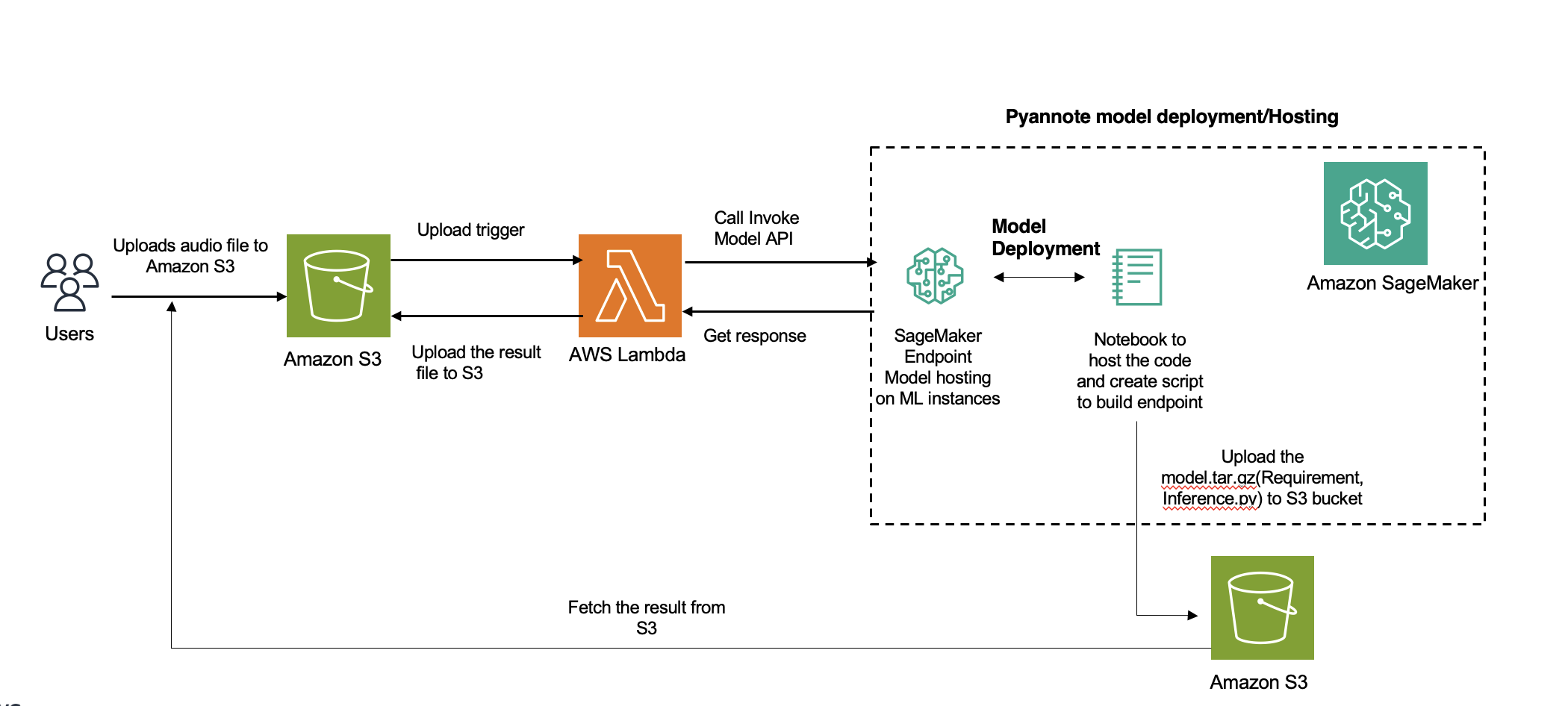
Forniamo una guida completa su come distribuire soluzioni di segmentazione e clustering degli altoparlanti utilizzando SageMaker sul cloud AWS. È possibile utilizzare questa soluzione per applicazioni che gestiscono registrazioni audio con più altoparlanti (oltre 100).
Panoramica della soluzione
Amazon Transcribe è il servizio di riferimento per la diarizzazione degli oratori in AWS. Tuttavia, per le lingue non supportate, puoi utilizzare altri modelli (nel nostro caso, PyAnnote) che verranno distribuiti in SageMaker per l'inferenza. Per file audio brevi in cui l'inferenza richiede fino a 60 secondi, è possibile utilizzare inferenza in tempo reale. Per più di 60 secondi, asincrono si dovrebbe usare l'inferenza. Il vantaggio aggiuntivo dell'inferenza asincrona è il risparmio sui costi grazie al ridimensionamento automatico del conteggio delle istanze fino a zero quando non ci sono richieste da elaborare.
Abbracciare il viso è un popolare hub open source per modelli di machine learning (ML). AWS e Hugging Face hanno un associazione che consente un'integrazione perfetta tramite SageMaker con una serie di AWS Deep Learning Containers (DLC) per l'addestramento e l'inferenza in PyTorch o TensorFlow e stimatori e predittori Hugging Face per SageMaker Python SDK. Le funzionalità e le funzionalità di SageMaker aiutano gli sviluppatori e i data scientist a iniziare facilmente con l'elaborazione del linguaggio naturale (NLP) su AWS.
L'integrazione di questa soluzione prevede l'utilizzo del modello di diarizzazione degli oratori preaddestrato di Hugging Face utilizzando il file Libreria PyAnnote. PyAnnote è un toolkit open source scritto in Python per la diarizzazione degli oratori. Questo modello, addestrato sul set di dati audio di esempio, consente un efficace partizionamento degli oratori nei file audio. Il modello viene distribuito su SageMaker come configurazione di endpoint asincrono, fornendo un'elaborazione efficiente e scalabile delle attività di diarizzazione.
Il diagramma seguente illustra l'architettura della soluzione.
Per questo post utilizziamo il seguente file audio.
I file audio stereo o multicanale vengono automaticamente downmixati in mono calcolando la media dei canali. I file audio campionati a una frequenza diversa vengono ricampionati automaticamente a 16kHz al momento del caricamento.
Assicurati che l'account AWS disponga di una quota di servizio per ospitare un endpoint SageMaker per un'istanza ml.g5.2xlarge.
Crea una funzione modello per accedere alla diarizzazione dell'altoparlante PyAnnote da Hugging Face
È possibile utilizzare Hugging Face Hub per accedere al pre-addestrato desiderato Modello di diarizzazione degli altoparlanti PyAnnote. Utilizzi lo stesso script per scaricare il file del modello durante la creazione dell'endpoint SageMaker.
Vedi il seguente codice:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
Imballa il codice del modello
Prepara file essenziali come inference.py, che contiene il codice di inferenza:
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data[turn] = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=["start", "end", "speaker"])
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
Preparare un requirements.txt file, che contiene le librerie Python necessarie per eseguire l'inferenza:
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
Infine, comprimi il file inference.py erequirements.txt e salvarlo con nome model.tar.gz:
!tar zcvf model.tar.gz *
Configura un modello SageMaker
Definire una risorsa del modello SageMaker specificando l'URI dell'immagine e la posizione dei dati del modello in Servizio di archiviazione semplice Amazon (S3) e ruolo SageMaker:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client("iam")
role = iam.get_role(RoleName="sagemaker_execution_role")["Role"]["Arn"]
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
Carica il modello su Amazon S3
Carica il file compresso del modello PyAnnote Hugging Face in un bucket S3:
Configura un endpoint asincrono per la distribuzione del modello su SageMaker utilizzando la configurazione di inferenza asincrona fornita:
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
Testare l'endpoint
Valuta la funzionalità dell'endpoint inviando un file audio per la diarizzazione e recuperando l'output JSON archiviato nel percorso di output S3 specificato:
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
Per implementare questa soluzione su larga scala, suggeriamo di utilizzare AWS Lambda, Servizio di notifica semplice Amazon (Amazon SNS), o Servizio Amazon Simple Queue (Amazon SQS). Questi servizi sono progettati per garantire scalabilità, architetture basate sugli eventi e un utilizzo efficiente delle risorse. Possono aiutare a disaccoppiare il processo di inferenza asincrona dall'elaborazione dei risultati, consentendo di ridimensionare ciascun componente in modo indipendente e gestire i picchi di richieste di inferenza in modo più efficace.
Risultati
L'output del modello è archiviato in s3://sagemaker-xxxx /async_inference/output/. L'output mostra che la registrazione audio è stata segmentata in tre colonne:
Inizio (ora di inizio in secondi)
Fine (ora di fine in secondi)
Altoparlante (etichetta dell'altoparlante)
Il codice seguente mostra un esempio dei nostri risultati:
È possibile impostare una policy di dimensionamento su zero impostando MinCapacity su 0; inferenza asincrona ti consente di ridimensionare automaticamente fino a zero senza richieste. Non è necessario eliminare l'endpoint, it bilancia da zero quando necessario, riducendo i costi quando non in uso. Vedere il seguente codice:
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
Se desideri eliminare l'endpoint, utilizza il seguente codice:
Vantaggi della distribuzione asincrona degli endpoint
Questa soluzione offre i seguenti vantaggi:
La soluzione può gestire in modo efficiente file audio multipli o di grandi dimensioni.
Questo esempio utilizza una singola istanza per la dimostrazione. Se desideri utilizzare questa soluzione per centinaia o migliaia di video e utilizzare un endpoint asincrono per l'elaborazione su più istanze, puoi utilizzare un criterio di ridimensionamento automatico, progettato per un gran numero di documenti di origine. Il dimensionamento automatico regola dinamicamente il numero di istanze predisposte per un modello in risposta alle modifiche del carico di lavoro.
La soluzione ottimizza le risorse e riduce il carico del sistema separando le attività a lunga esecuzione dall'inferenza in tempo reale.
Conclusione
In questo post, abbiamo fornito un approccio semplice per distribuire il modello di diarizzazione degli altoparlanti di Hugging Face su SageMaker utilizzando script Python. L'utilizzo di un endpoint asincrono fornisce un mezzo efficiente e scalabile per fornire previsioni di diarizzazione come servizio, soddisfacendo senza problemi le richieste simultanee.
Inizia oggi con la diarizzazione asincrona degli altoparlanti per i tuoi progetti audio. Contattaci nei commenti se hai domande su come rendere operativo il tuo endpoint di diarizzazione asincrona.
Informazioni sugli autori
Sanjay Tiwary è uno specialista di soluzioni architetto AI/ML che trascorre il suo tempo lavorando con clienti strategici per definire i requisiti aziendali, fornire sessioni L300 su casi d'uso specifici e progettare applicazioni e servizi AI/ML scalabili, affidabili e performanti. Ha contribuito a lanciare e ampliare il servizio Amazon SageMaker basato su AI/ML e ha implementato diverse prove di concetto utilizzando i servizi Amazon AI. Ha inoltre sviluppato la piattaforma di analisi avanzata come parte del percorso di trasformazione digitale.
Kiran Challapalli è uno sviluppatore di business deep tech con il settore pubblico AWS. Ha più di 8 anni di esperienza nel campo dell'intelligenza artificiale/ML e 23 anni di esperienza complessiva nello sviluppo di software e nelle vendite. Kiran aiuta le aziende del settore pubblico in tutta l'India a esplorare e co-creare soluzioni basate sul cloud che utilizzano tecnologie di intelligenza artificiale, machine learning e intelligenza artificiale generativa, inclusi modelli linguistici di grandi dimensioni.
 Sanjay Tiwary è uno specialista di soluzioni architetto AI/ML che trascorre il suo tempo lavorando con clienti strategici per definire i requisiti aziendali, fornire sessioni L300 su casi d'uso specifici e progettare applicazioni e servizi AI/ML scalabili, affidabili e performanti. Ha contribuito a lanciare e ampliare il servizio Amazon SageMaker basato su AI/ML e ha implementato diverse prove di concetto utilizzando i servizi Amazon AI. Ha inoltre sviluppato la piattaforma di analisi avanzata come parte del percorso di trasformazione digitale.
Sanjay Tiwary è uno specialista di soluzioni architetto AI/ML che trascorre il suo tempo lavorando con clienti strategici per definire i requisiti aziendali, fornire sessioni L300 su casi d'uso specifici e progettare applicazioni e servizi AI/ML scalabili, affidabili e performanti. Ha contribuito a lanciare e ampliare il servizio Amazon SageMaker basato su AI/ML e ha implementato diverse prove di concetto utilizzando i servizi Amazon AI. Ha inoltre sviluppato la piattaforma di analisi avanzata come parte del percorso di trasformazione digitale. Kiran Challapalli è uno sviluppatore di business deep tech con il settore pubblico AWS. Ha più di 8 anni di esperienza nel campo dell'intelligenza artificiale/ML e 23 anni di esperienza complessiva nello sviluppo di software e nelle vendite. Kiran aiuta le aziende del settore pubblico in tutta l'India a esplorare e co-creare soluzioni basate sul cloud che utilizzano tecnologie di intelligenza artificiale, machine learning e intelligenza artificiale generativa, inclusi modelli linguistici di grandi dimensioni.
Kiran Challapalli è uno sviluppatore di business deep tech con il settore pubblico AWS. Ha più di 8 anni di esperienza nel campo dell'intelligenza artificiale/ML e 23 anni di esperienza complessiva nello sviluppo di software e nelle vendite. Kiran aiuta le aziende del settore pubblico in tutta l'India a esplorare e co-creare soluzioni basate sul cloud che utilizzano tecnologie di intelligenza artificiale, machine learning e intelligenza artificiale generativa, inclusi modelli linguistici di grandi dimensioni.
