Nell'odierno panorama in rapida evoluzione dell'intelligenza artificiale, i modelli di deep learning si sono trovati in prima linea nell'innovazione, con applicazioni che spaziano dalla visione artificiale (CV), all'elaborazione del linguaggio naturale (NLP) e ai sistemi di raccomandazione. Tuttavia, i costi crescenti associati alla formazione e al perfezionamento di questi modelli rappresentano una sfida per le imprese. Questo costo è principalmente determinato dall’enorme volume di dati utilizzati nell’addestramento dei modelli di deep learning. Oggi, i modelli di grandi dimensioni vengono spesso addestrati su terabyte di dati e l'addestramento può richiedere settimane, anche con GPU potenti o AWSTrainiumhardware basato su. In genere, i clienti si affidano a tecniche e ottimizzazioni che migliorano l'efficienza del ciclo di addestramento di un modello, come kernel o livelli ottimizzati, addestramento a precisione mista o funzionalità come Amazon Sage Maker librerie di formazione distribuite. Tuttavia, oggi c’è meno attenzione all’efficienza dei dati di addestramento stessi. Non tutti i dati contribuiscono allo stesso modo al processo di apprendimento durante l'addestramento del modello: una parte significativa delle risorse computazionali può essere spesa per l'elaborazione di esempi semplici che non contribuiscono in modo sostanziale all'accuratezza complessiva del modello.
I clienti si affidano tradizionalmente a tecniche di preelaborazione quali upsampling o downsampling e deduplicazione per perfezionare e migliorare la qualità delle informazioni dei propri dati. Queste tecniche possono aiutare, ma spesso richiedono molto tempo, richiedono esperienza specializzata nella scienza dei dati e talvolta possono essere più arte che scienza. I clienti spesso fanno affidamento anche su set di dati curati, come Web raffinato, per migliorare le prestazioni dei propri modelli; tuttavia, questi set di dati non sono sempre completamente open source e spesso hanno uno scopo più generale e non sono correlati al caso d'uso specifico.
In quale altro modo è possibile superare questa inefficienza legata ai campioni di dati con poche informazioni durante l'addestramento del modello?
Siamo entusiasti di annunciare un'anteprima pubblica di smart sifting, una nuova funzionalità di SageMaker che può ridurre i costi di addestramento dei modelli di deep learning fino al 35%. Il vaglio intelligente è una nuova tecnica di efficienza dei dati che analizza attivamente i campioni di dati durante l'addestramento e filtra i campioni meno informativi per il modello. Eseguendo l'addestramento su un sottoinsieme più piccolo di dati con solo i campioni che contribuiscono maggiormente alla convergenza del modello, l'addestramento totale e i costi diminuiscono con un impatto minimo o nullo sull'accuratezza. Inoltre, poiché la funzionalità funziona online durante l'addestramento del modello, il vaglio intelligente non richiede modifiche ai dati upstream o alla pipeline di addestramento downstream.
In questo post, trattiamo i seguenti argomenti:
- La nuova funzionalità di setacciatura intelligente in SageMaker e come funziona
- Come utilizzare il setacciamento intelligente con i carichi di lavoro di formazione PyTorch
Puoi anche controllare il nostro documentazione ed quaderni di esempio per ulteriori risorse su come iniziare con il vaglio intelligente.
Come funziona la setacciatura intelligente di SageMaker
Iniziamo questo post con una panoramica di come la funzionalità di setacciatura intelligente può accelerare l'addestramento del modello su SageMaker.
Il compito dello Smart Sifting è quello di vagliare i dati di training durante il processo di training e inserire nel modello solo i campioni più informativi. Durante un tipico addestramento con PyTorch, i dati vengono inviati iterativamente in batch al ciclo di addestramento e ai dispositivi acceleratori (ad esempio GPU o chip Trainium) dal Caricatore dati PyTorch. Il vaglio intelligente viene implementato in questa fase di caricamento dei dati e pertanto è indipendente da qualsiasi preelaborazione dei dati a monte nella pipeline di addestramento.
Il vaglio intelligente utilizza il tuo modello e una funzione di perdita specificata dall'utente per eseguire un passaggio valutativo in avanti di ciascun campione di dati man mano che viene caricato. I campioni con perdite elevate avranno un impatto significativo sull'addestramento del modello e pertanto verranno utilizzati nell'addestramento; i campioni di dati con perdite relativamente basse vengono messi da parte ed esclusi dalla formazione.
Un input chiave per il vaglio intelligente è la proporzione di dati da escludere: ad esempio, impostando la proporzione al 33% (beta_value=0.5), i campioni che si trovano approssimativamente nel terzo inferiore della perdita di ciascun lotto verranno esclusi dall'addestramento. Quando sono stati identificati abbastanza campioni con perdite elevate per completare un batch, i dati vengono inviati attraverso l'intero ciclo di addestramento e il modello apprende e si addestra normalmente. Non è necessario apportare modifiche al ciclo di allenamento quando il setaccio intelligente è abilitato.
Il diagramma seguente illustra questo flusso di lavoro.

Includendo solo un sottoinsieme dei dati di addestramento, il vaglio intelligente riduce il tempo e i calcoli necessari per addestrare il modello. Nei nostri test abbiamo ottenuto una riduzione fino al 40% circa dei tempi e dei costi totali di formazione. Con il vaglio intelligente dei dati, l’impatto sull’accuratezza del modello può essere minimo o nullo perché i campioni esclusi presentavano perdite relativamente basse per il modello. Nella tabella seguente includiamo una serie di risultati sperimentali che dimostrano il miglioramento delle prestazioni possibile con il setacciamento intelligente di SageMaker.
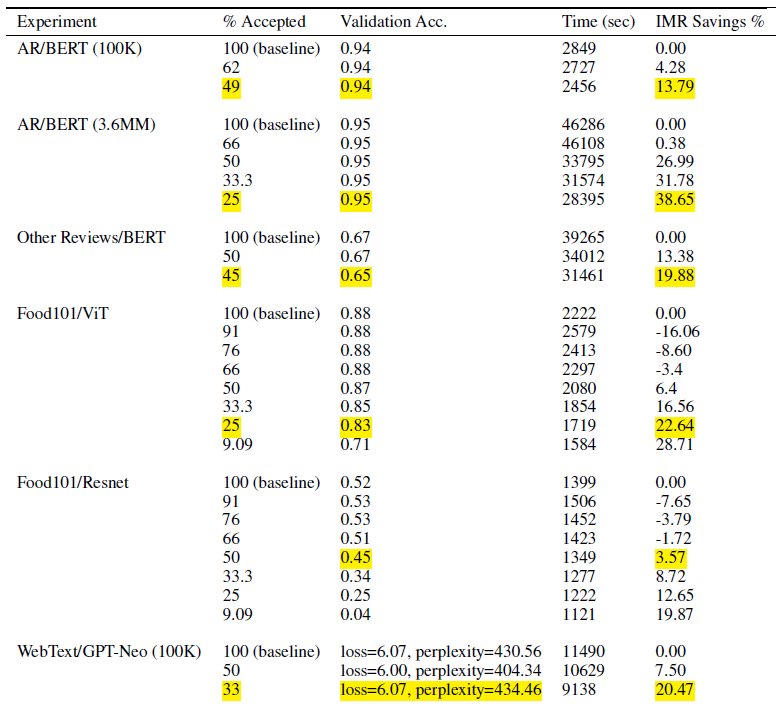
Nella tabella, la colonna % accettata indica la proporzione di dati inclusi e utilizzati nel ciclo di addestramento. L'aumento di questo parametro regolabile riduce il costo (come dimostrato nella colonna % risparmio IMR), ma può anche influire sulla precisione. L'impostazione appropriata per % accettata è una funzione del set di dati e del modello; dovresti sperimentare e ottimizzare questo parametro per ottenere il miglior equilibrio tra costi ridotti e impatto sulla precisione.
Panoramica della soluzione
Nelle sezioni seguenti, esamineremo un esempio pratico di abilitazione del sifting intelligente con un lavoro di formazione PyTorch su SageMaker. Se vuoi iniziare rapidamente, puoi passare al file Esempi di PyTorch o PyTorch Lightning.
Prerequisiti
Presumiamo che tu sappia già come addestrare un modello utilizzando PyTorch o PyTorch Lightning utilizzando SageMaker Python SDK e la classe Estimator utilizzando SageMaker Deep Learning Containers per l'addestramento. In caso contrario, fare riferimento a Utilizzo di SageMaker Python SDK prima di continuare
Inizia con il setacciamento intelligente di SageMaker
In un tipico lavoro di formazione PyTorch, inizializzi la formazione PyTorch Caricatore dati Data con il set di dati e altri parametri richiesti, che fornisce batch di input man mano che la formazione procede. Per abilitare il setacciamento intelligente dei dati di allenamento, utilizzerai un nuovo file DataLoader classe: smart_sifting.dataloader.sift_dataloader.SiftingDataloader. Questa classe viene utilizzata come wrapper sopra il PyTorch esistente DataLoader e il processo di formazione utilizzerà invece SiftingDataloader per ottenere batch di input. IL SiftingDataLoader ottiene il batch di input dal tuo PyTorch originale DataLoader, valuta l'importanza dei campioni nel lotto e costruisce un lotto setacciato con campioni ad alte perdite, che vengono poi passati alla fase di addestramento. Il wrapper è simile al seguente codice:
Il SiftingDataloader richiede alcuni parametri aggiuntivi per analizzare i dati di allenamento, che puoi specificare tramite il file sift_config parametro. Per prima cosa, crea un file smart_sifting.sift_config.sift_configs.RelativeProbabilisticSiftConfig oggetto. Questo oggetto contiene il configurabile e richiesto beta_value ed loss_history_length, che definiscono rispettivamente la proporzione di campioni da conservare e la finestra di campioni da includere nella valutazione della perdita relativa. Tieni presente che, poiché il vaglio intelligente utilizza il tuo modello per definire l'importanza del campione, possono esserci implicazioni negative se utilizziamo un modello con pesi completamente casuali. Invece, puoi usare loss_based_sift_config e sift_delay per ritardare il processo di vagliatura finché i pesi dei parametri nel modello non vengono aggiornati oltre i valori casuali. (Per maggiori dettagli consultare Applica il setacciamento intelligente al tuo script di formazione.) Nel codice seguente definiamo sift_config e specificare beta_value ed loss_history_length, oltre a ritardare l'inizio del setacciamento utilizzando loss_based_sift_config:
Successivamente, devi includere anche a loss_impl parametro nel SiftingDataloader oggetto. Il vaglio intelligente funziona a livello di singolo campione ed è fondamentale avere accesso a un metodo di calcolo delle perdite per determinare l'importanza del campione. È necessario implementare un metodo di sifting delle perdite che restituisca un tensore nx1, che contenga valori di perdita di n campioni. In genere, specifichi lo stesso metodo di perdita utilizzato dal tuo model durante l'allenamento. Infine, includi un puntatore al tuo modello nel file SiftingDataloader oggetto, che viene utilizzato per valutare i campioni prima che vengano inclusi nell'addestramento. Vedere il seguente codice:
Il codice seguente mostra un esempio completo di abilitazione del sifting intelligente con un lavoro di formazione BERT esistente:
Conclusione
In questo post, abbiamo esplorato l'anteprima pubblica dello smart sifting, una nuova funzionalità di SageMaker che può ridurre i costi di formazione del modello di deep learning fino al 35%. Questa funzionalità migliora l'efficienza dei dati durante l'addestramento filtrando campioni di dati meno informativi. Includendo solo i dati di maggiore impatto per la convergenza dei modelli, puoi ridurre significativamente i tempi e i costi di formazione, il tutto mantenendo la precisione. Inoltre, si integra perfettamente nei processi esistenti senza richiedere modifiche ai dati o alla pipeline di formazione.
Per approfondire il setacciamento intelligente di SageMaker, esplorare come funziona e implementarlo con i carichi di lavoro di formazione PyTorch, consulta il nostro documentazione ed quaderni di esempio e iniziare con questa nuova funzionalità.
Circa gli autori
 Roberto Van Dusen è un Senior Product Manager presso Amazon SageMaker. Dirige framework, compilatori e tecniche di ottimizzazione per la formazione sul deep learning.
Roberto Van Dusen è un Senior Product Manager presso Amazon SageMaker. Dirige framework, compilatori e tecniche di ottimizzazione per la formazione sul deep learning.
 K Lokesh Kumar Reddy è un ingegnere senior nel team AI di Amazon Applied. Si concentra su tecniche di formazione ML efficienti e sulla creazione di strumenti per migliorare i sistemi di intelligenza artificiale conversazionale. Nel tempo libero gli piace scoprire nuove culture, nuove esperienze e rimanere aggiornato sulle ultime tendenze tecnologiche.
K Lokesh Kumar Reddy è un ingegnere senior nel team AI di Amazon Applied. Si concentra su tecniche di formazione ML efficienti e sulla creazione di strumenti per migliorare i sistemi di intelligenza artificiale conversazionale. Nel tempo libero gli piace scoprire nuove culture, nuove esperienze e rimanere aggiornato sulle ultime tendenze tecnologiche.
 Abhishek Dan è un Dev Manager senior nel team AI di Amazon Applied e lavora su sistemi di machine learning e intelligenza artificiale conversazionale. È appassionato di tecnologie di intelligenza artificiale e lavora all'intersezione tra scienza e ingegneria per migliorare le capacità dei sistemi di intelligenza artificiale per creare interazioni uomo-computer più intuitive e senza soluzione di continuità. Attualmente sta creando applicazioni su modelli linguistici di grandi dimensioni per favorire l'efficienza e i miglioramenti della CX per Amazon.
Abhishek Dan è un Dev Manager senior nel team AI di Amazon Applied e lavora su sistemi di machine learning e intelligenza artificiale conversazionale. È appassionato di tecnologie di intelligenza artificiale e lavora all'intersezione tra scienza e ingegneria per migliorare le capacità dei sistemi di intelligenza artificiale per creare interazioni uomo-computer più intuitive e senza soluzione di continuità. Attualmente sta creando applicazioni su modelli linguistici di grandi dimensioni per favorire l'efficienza e i miglioramenti della CX per Amazon.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/accelerate-deep-learning-model-training-up-to-35-with-amazon-sagemaker-smart-sifting/

