Questo è un post sul blog ospite scritto da Nitin Kumar, Lead Data Scientist presso T e T Consulting Services, Inc.
In questo post discutiamo del valore e del potenziale impatto dell'apprendimento federato in campo sanitario. Questo approccio può aiutare i pazienti affetti da ictus, i medici e i ricercatori con diagnosi più rapide, un processo decisionale arricchito e un lavoro di ricerca più informato e inclusivo sui problemi di salute legati all'ictus, utilizzando un approccio nativo del cloud con i servizi AWS per un sollevamento leggero e un'adozione semplice .
Difficoltà diagnostiche in caso di ictus cardiaco
Statistiche dal Centers for Disease Control and Prevention (CDC) mostrano che ogni anno negli Stati Uniti più di 795,000 persone soffrono del primo ictus e circa il 25% di loro sperimenta attacchi ricorrenti. Secondo l'OMS è la quinta causa di morte Associazione americana dell'ictus e una delle principali cause di disabilità negli Stati Uniti. Pertanto, è fondamentale disporre di una diagnosi e di un trattamento tempestivi per ridurre il danno cerebrale e altre complicazioni nei pazienti con ictus acuto.
La TC e la risonanza magnetica rappresentano il gold standard nelle tecnologie di imaging per classificare diversi sottotipi di ictus e sono cruciali durante la valutazione preliminare dei pazienti, la determinazione della causa principale e il trattamento. Una sfida fondamentale qui, soprattutto nel caso di ictus acuto, è il momento della diagnosi per immagini, che in media varia da 30 minuti fino a un'ora e può essere molto più lungo a seconda dell'affollamento del pronto soccorso.
I medici e il personale medico necessitano di una diagnosi per immagini rapida e accurata per valutare le condizioni del paziente e proporre opzioni di trattamento. Nelle parole del Dr. Werner Vogels a AWS re: Invent 2023, “ogni secondo che una persona ha un ictus conta”. Le vittime di ictus possono perdere circa 1.9 miliardi di neuroni ogni secondo in cui non vengono curate.
Restrizioni sui dati medici
È possibile utilizzare l’apprendimento automatico (ML) per assistere medici e ricercatori nelle attività di diagnosi, accelerando così il processo. Tuttavia, i set di dati necessari per creare modelli ML e fornire risultati affidabili si trovano in silos tra diversi sistemi e organizzazioni sanitarie. Questi dati legacy isolati hanno il potenziale per un impatto enorme se cumulati. Allora perché non è stato ancora utilizzato?
Quando si lavora con set di dati di domini medici e si creano soluzioni ML si incontrano molteplici sfide, tra cui la privacy dei pazienti, la sicurezza dei dati personali e alcune restrizioni burocratiche e politiche. Inoltre, gli istituti di ricerca hanno rafforzato le loro pratiche di condivisione dei dati. Questi ostacoli impediscono inoltre ai team di ricerca internazionali di lavorare insieme su set di dati diversi e ricchi, il che potrebbe salvare vite umane e prevenire le disabilità che possono derivare da ictus cardiaci, tra gli altri vantaggi.
Politiche e regolamenti come Regolamento generale sulla protezione dei dati (GDPR), Legge sulla portabilità e responsabilità delle assicurazioni sanitarie (HIPPA), e California Consumer Privacy Act (CCPA) ha posto delle barriere alla condivisione dei dati provenienti dal settore medico, in particolare dei dati dei pazienti. Inoltre, i set di dati dei singoli istituti, organizzazioni e ospedali sono spesso troppo piccoli, sbilanciati o con una distribuzione distorta, il che porta a vincoli di generalizzazione del modello.
Apprendimento federato: un'introduzione
L'apprendimento federato (FL) è una forma decentralizzata di ML, un approccio ingegneristico dinamico. In questo approccio ML decentralizzato, il modello ML è condiviso tra le organizzazioni per la formazione su sottoinsiemi di dati proprietari, a differenza della tradizionale formazione ML centralizzata, in cui il modello generalmente viene addestrato su set di dati aggregati. I dati rimangono protetti dietro i firewall o il VPC dell'organizzazione, mentre il modello con i relativi metadati viene condiviso.
Nella fase di formazione, un modello FL globale viene diffuso e sincronizzato tra le organizzazioni delle unità per la formazione su set di dati individuali e viene restituito un modello addestrato locale. Il modello globale finale può essere utilizzato per fare previsioni per tutti i partecipanti e può anche essere utilizzato come base per ulteriore formazione per costruire modelli personalizzati locali per le organizzazioni partecipanti. Può essere ulteriormente esteso a beneficio di altri istituti. Questo approccio può ridurre in modo significativo i requisiti di sicurezza informatica per i dati in transito eliminando del tutto la necessità che i dati transitino al di fuori dei confini dell'organizzazione.
Il diagramma seguente illustra un'architettura di esempio.
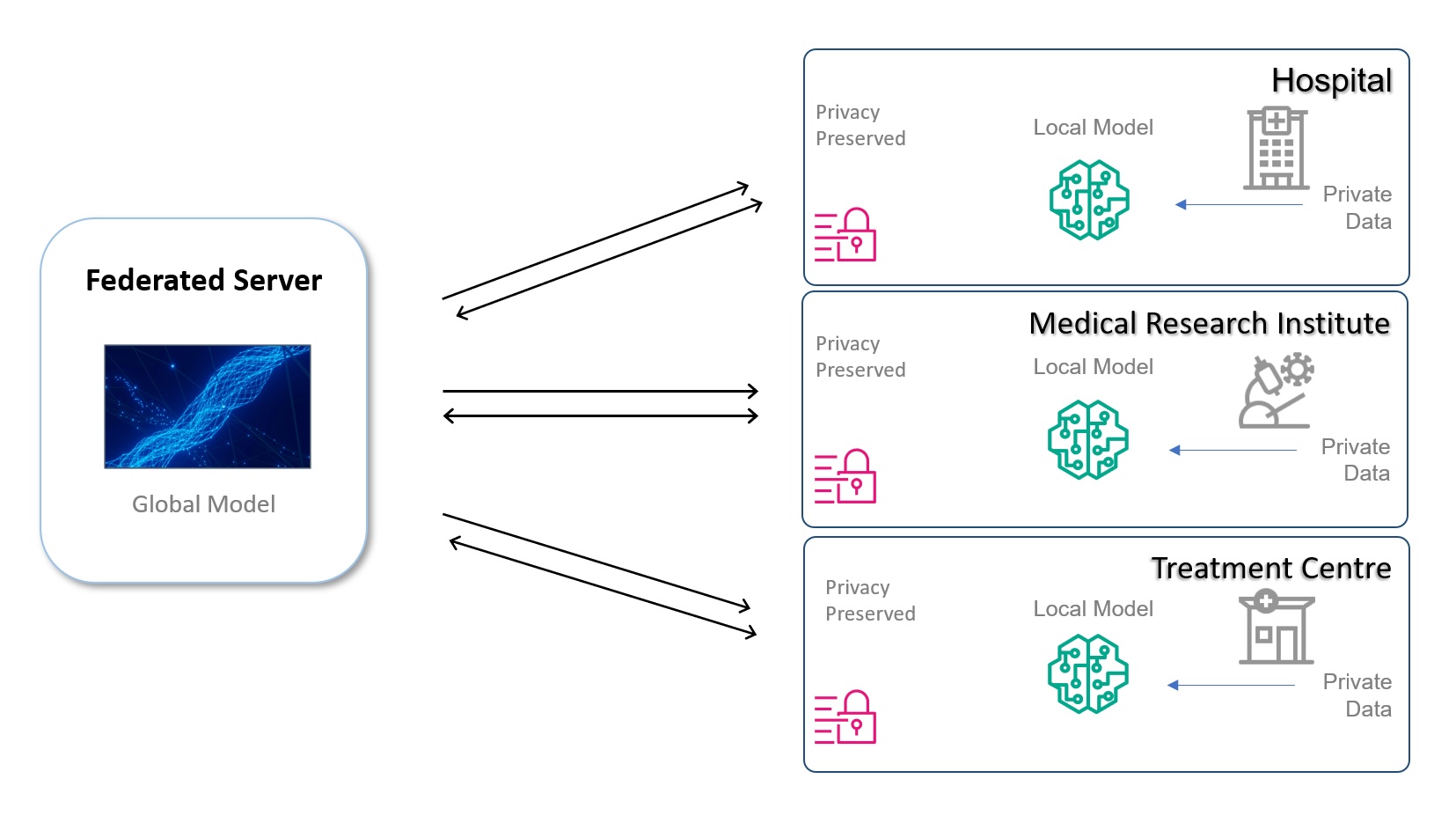
Nelle sezioni seguenti, discutiamo di come l’apprendimento federato può essere d’aiuto.
La Federazione impara a salvare la situazione (e salvare vite umane)
Per una buona intelligenza artificiale (AI), sono necessari buoni dati.
I sistemi legacy, che si trovano spesso nel dominio federale, pongono sfide significative nell’elaborazione dei dati prima che sia possibile ricavare informazioni o unirle con set di dati più recenti. Questo è un ostacolo nel fornire informazioni preziose ai leader. Può portare a un processo decisionale impreciso perché la percentuale di dati legacy a volte è molto più preziosa rispetto al nuovo set di dati di piccole dimensioni. Desideri risolvere questo collo di bottiglia in modo efficace e senza carichi di lavoro di consolidamento manuale e sforzi di integrazione (compresi ingombranti processi di mappatura) per set di dati legacy e più recenti presenti in ospedali e istituti, che possono richiedere molti mesi, se non anni, in molti casi. I dati legacy sono piuttosto preziosi perché contengono importanti informazioni contestuali necessarie per un processo decisionale accurato e una formazione di modelli ben informata, che porta a un’intelligenza artificiale affidabile nel mondo reale. La durata dei dati fornisce informazioni su variazioni e modelli a lungo termine nel set di dati che altrimenti non verrebbero rilevati e porterebbero a previsioni distorte e infondate.
Abbattere questi silos di dati per unire il potenziale inutilizzato dei dati sparsi può salvare e trasformare molte vite. Può anche accelerare la ricerca relativa ai problemi di salute secondari derivanti dall’ictus cardiaco. Questa soluzione può aiutarti a condividere approfondimenti provenienti da dati isolati tra istituti a causa di politiche e altri motivi, che tu sia un ospedale, un istituto di ricerca o altre organizzazioni incentrate sui dati sanitari. Può consentire decisioni informate sulla direzione della ricerca e sulla diagnosi. Inoltre, il risultato è un archivio centralizzato di intelligence tramite una base di conoscenza sicura, privata e globale.

L'apprendimento federato presenta molti vantaggi in generale e in particolare per le impostazioni dei dati medici.
Funzionalità di sicurezza e privacy:
- Mantiene i dati sensibili lontani da Internet e li utilizza comunque per il machine learning e sfrutta la sua intelligenza con una privacy differenziale
- Consente di creare, addestrare e distribuire modelli imparziali e robusti non solo sulle macchine ma anche sulle reti, senza rischi per la sicurezza dei dati
- Supera gli ostacoli legati alla gestione dei dati da parte di più fornitori
- Elimina la necessità di condivisione dei dati tra siti e di governance globale
- Preserva la privacy con privacy differenziale e offre un calcolo multipartitico sicuro con formazione locale
Miglioramenti delle prestazioni:
- Risolve il problema delle dimensioni ridotte del campione nel settore dell'imaging medico e dei costosi processi di etichettatura
- Bilancia la distribuzione dei dati
- Consente di incorporare i metodi ML e deep learning (DL) più tradizionali
- Utilizza set di immagini raggruppate per contribuire a migliorare la potenza statistica, superando i limiti delle dimensioni del campione delle singole istituzioni
Vantaggi della resilienza:
- Se un partito decide di andarsene, ciò non ostacolerà la formazione
- Un nuovo ospedale o istituto può aderire in qualsiasi momento; non dipende da alcun set di dati specifico con alcuna organizzazione del nodo
- Non sono necessarie ampie pipeline di ingegneria dei dati per i dati legacy sparsi in aree geografiche diffuse
Queste funzionalità possono aiutare ad abbattere i muri tra le istituzioni che ospitano set di dati isolati su domini simili. La soluzione può diventare un moltiplicatore di forza sfruttando le potenzialità unificate dei set di dati distribuiti e migliorando l’efficienza trasformando radicalmente l’aspetto della scalabilità senza il pesante sollevamento dell’infrastruttura. Questo approccio aiuta il machine learning a raggiungere il suo pieno potenziale, diventando esperto a livello clinico e non solo di ricerca.
L'apprendimento federato ha prestazioni paragonabili al normale ML, come mostrato di seguito esperimento di NVidia Clara (su Medical Modal ARchive (MMAR) utilizzando il set di dati BRATS2018). In questo caso, FL ha ottenuto prestazioni di segmentazione paragonabili rispetto all'addestramento con dati centralizzati: oltre l'80% con circa 600 epoche durante l'addestramento di un'attività di segmentazione del tumore cerebrale multimodale e multiclasse.
L’apprendimento federato è stato recentemente testato in alcuni sottocampi medici per casi d’uso tra cui l’apprendimento della somiglianza del paziente, l’apprendimento della rappresentazione del paziente, la fenotipizzazione e la modellazione predittiva.
Progetto dell'applicazione: l'apprendimento federato lo rende possibile e semplice
Per iniziare con FL, puoi scegliere tra molti set di dati di alta qualità. Ad esempio, i set di dati con immagini del cervello includono RESTA (iniziativa Autism Brain Imaging Data Exchange), ADNI (Iniziativa di neuroimaging della malattia di Alzheimer), RSNA (Società Radiologica del Nord America) TC cerebrale, Reggiseni (Multimodal Brain Tumor Image Segmentation Benchmark) aggiornato regolarmente per la Brain Tumor Segmentation Challenge di seguito UPenn (Università della Pennsylvania), UK BioBank (coperto nel seguente NIH carta), E XI. Allo stesso modo, per le immagini cardiache, è possibile scegliere tra diverse opzioni disponibili al pubblico, tra cui ACDC (Automatic Cardiac Diagnosis Challenge), che è un set di dati di valutazione MRI cardiaca con annotazione completa menzionato dalla National Library of Medicine di seguito cartae la sfida di segmentazione cardiaca M&M (multicentro, multivendor e multimalattia) menzionata di seguito IEEE carta.
Le immagini seguenti mostrano a mappa probabilistica di sovrapposizione delle lesioni per le lesioni primarie dal set di dati ATLAS R1.1. (Gli ictus sono una delle cause più comuni di lesioni cerebrali secondo Cleveland Clinic.)

Per i dati delle cartelle cliniche elettroniche (EHR), sono disponibili alcuni set di dati che seguono il Risorse di interoperabilità sanitaria rapida (FHIR) norma. Questo standard ti aiuta a creare progetti pilota semplici eliminando alcune sfide con set di dati eterogenei e non normalizzati, consentendo uno scambio, una condivisione e un'integrazione fluidi e sicuri dei set di dati. Il FHIR consente la massima interoperabilità. Gli esempi di set di dati includono MIMIC-IV (Mercato di informazione medica per la terapia intensiva). Altri set di dati di buona qualità che attualmente non sono FHIR ma che possono essere facilmente convertiti includono Centri per i servizi Medicare e Medicaid (CMS) File di uso pubblico (PUF) e Banca dati di ricerca collaborativa eICU dal MIT (Massachusetts Institute of Technology). Stanno diventando disponibili anche altre risorse che offrono set di dati basati su FHIR.
Il ciclo di vita per l'implementazione di FL può includere quanto segue passi: inizializzazione delle attività, selezione, configurazione, addestramento del modello, comunicazione client/server, pianificazione e ottimizzazione, controllo delle versioni, test, distribuzione e terminazione. La preparazione dei dati di imaging medico per il machine learning tradizionale richiede molti passaggi dispendiosi in termini di tempo, come descritto di seguito carta. In alcuni scenari potrebbe essere necessaria la conoscenza del dominio per preelaborare i dati grezzi dei pazienti, soprattutto a causa della loro natura sensibile e privata. Questi possono essere consolidati e talvolta eliminati per FL, risparmiando tempo cruciale per la formazione e fornendo risultati più rapidi.
Implementazione
Gli strumenti e le librerie FL sono cresciuti con un supporto diffuso, rendendo semplice l'utilizzo di FL senza un pesante sollevamento dall'alto. Ci sono molte buone risorse e opzioni di framework disponibili per iniziare. È possibile fare riferimento a quanto segue vasto elenco dei framework e degli strumenti più popolari nel dominio FL, inclusi PySyft, FedML, Fiore, ApriFL, DESTINO, TensorFlow federatoe NVFlare. Fornisce un elenco di progetti per principianti da cui iniziare rapidamente e su cui sviluppare.
Puoi implementare un approccio nativo del cloud con Amazon Sage Maker con cui funziona perfettamente Peering AWS VPC, mantenendo l'addestramento di ciascun nodo in una sottorete privata nel rispettivo VPC e consentendo la comunicazione tramite indirizzi IPv4 privati. Inoltre, hosting di modelli su JumpStart di Amazon SageMaker può aiutare esponendo l'API dell'endpoint senza condividere i pesi del modello.
Elimina inoltre potenziali sfide di elaborazione di alto livello con l'hardware locale Cloud di calcolo elastico di Amazon (Amazon EC2) risorse. Puoi implementare il client e i server FL su AWS con Taccuini SageMaker ed Servizio di archiviazione semplice Amazon (Amazon S3), mantenere un accesso regolamentato ai dati e al modello con Gestione dell'identità e dell'accesso di AWS (IAM) ruoli e utilizzo Servizio token di sicurezza AWS (AWS STS) per la sicurezza lato client. Puoi anche creare il tuo sistema personalizzato per FL utilizzando Amazon EC2.
Per una panoramica dettagliata dell'implementazione di FL con il file Fiore framework su SageMaker e una discussione sulla sua differenza rispetto alla formazione distribuita, fare riferimento a Apprendimento automatico con dati di addestramento decentralizzati utilizzando l'apprendimento federato su Amazon SageMaker.
Le figure seguenti illustrano l'architettura del trasferimento dell'apprendimento in FL.

Affrontare le sfide relative ai dati FL
L’apprendimento federato comporta le proprie sfide relative ai dati, tra cui privacy e sicurezza, ma sono semplici da affrontare. In primo luogo, è necessario affrontare il problema dell’eterogeneità dei dati relativi all’imaging medico derivante da dati archiviati in diversi siti e organizzazioni partecipanti, noto come spostamento di dominio problema (noto anche come spostamento del cliente in un sistema FL), come evidenziato da Guan e Liu nel seguito carta. Ciò può portare a una differenza nella convergenza del modello globale.
Altri componenti da considerare includono la garanzia della qualità e dell’uniformità dei dati alla fonte, l’integrazione della conoscenza degli esperti nel processo di apprendimento per ispirare fiducia nel sistema tra i professionisti medici e il raggiungimento della precisione del modello. Per ulteriori informazioni su alcune delle potenziali sfide che potresti incontrare durante l'implementazione, fai riferimento a quanto segue carta.
AWS ti aiuta a risolvere queste sfide con funzionalità come l'elaborazione flessibile di Amazon EC2 e soluzioni predefinite Immagini docker in SageMaker per una distribuzione semplice. Puoi risolvere problemi lato client come dati sbilanciati e risorse di calcolo per ciascuna organizzazione del nodo. Puoi risolvere i problemi di apprendimento lato server come gli attacchi di avvelenamento da parte di soggetti malintenzionati con Cloud privato virtuale di Amazon (VPC Amazon), gruppi di sicurezzae altri standard di sicurezza, prevenendo la corruzione dei client e implementando i servizi di rilevamento delle anomalie AWS.
AWS aiuta inoltre ad affrontare le sfide di implementazione del mondo reale, che possono includere sfide di integrazione, problemi di compatibilità con i sistemi ospedalieri attuali o preesistenti e ostacoli all'adozione da parte degli utenti, offrendo soluzioni tecnologiche per ascensori flessibili, facili da usare e senza sforzo.
Con i servizi AWS, puoi abilitare la ricerca su larga scala basata su FL e l'implementazione e distribuzione clinica, che può comprendere vari siti in tutto il mondo.
Le recenti politiche sull’interoperabilità evidenziano la necessità di un apprendimento federato
Molte leggi recentemente approvate dal governo si concentrano sull’interoperabilità dei dati, rafforzando la necessità di interoperabilità tra organizzazioni dei dati per l’intelligence. Ciò può essere soddisfatto utilizzando FL, inclusi framework come TEFCA (Trusted Exchange Framework and Common Agreement) e ampliato USCDI (Dati fondamentali per l'interoperabilità degli Stati Uniti).
L'idea proposta contribuisce anche all'iniziativa di cattura e distribuzione del CDC Il CDC va avanti. La seguente citazione dall'articolo del GovCIO Condivisione dei dati e intelligenza artificiale: le principali priorità dell'Agenzia sanitaria federale nel 2024 riecheggia anche un tema simile: “Queste capacità possono anche supportare il pubblico in modo equo, incontrando i pazienti dove si trovano e sbloccando l’accesso fondamentale a questi servizi. Gran parte di questo lavoro si riduce ai dati”.
Ciò può aiutare gli istituti e le agenzie mediche in tutto il paese (e in tutto il mondo) con silos di dati. Possono trarre vantaggio da un’integrazione perfetta e sicura e dall’interoperabilità dei dati, rendendo i dati medici utilizzabili per previsioni di impatto basate sul machine learning e riconoscimento di modelli. Puoi iniziare con le immagini, ma l'approccio è applicabile anche a tutte le cartelle cliniche elettroniche. L'obiettivo è trovare l'approccio migliore per le parti interessate ai dati, con una pipeline nativa del cloud per normalizzare e standardizzare i dati o utilizzarli direttamente per FL.
Esploriamo un caso d'uso di esempio. I dati e le scansioni delle immagini dell’ictus cardiaco sono sparsi in tutto il paese e nel mondo, conservati in silos isolati in istituti, università e ospedali e separati da confini burocratici, geografici e politici. Non esiste un'unica fonte aggregata e non esiste un modo semplice per i professionisti medici (non programmatori) di estrarne informazioni. Allo stesso tempo, non è possibile addestrare modelli ML e DL su questi dati, il che potrebbe aiutare i professionisti medici a prendere decisioni più rapide e accurate in momenti critici in cui le scansioni cardiache possono richiedere ore per essere eseguite mentre la vita del paziente potrebbe essere in bilico. bilancia.
Altri casi d'uso noti includono POTS (Sistema di monitoraggio degli acquisti online) su NIH (National Institutes of Health) e sicurezza informatica per esigenze di soluzioni di intelligence sparse e su più livelli nelle sedi COMCOM/MAJCOM in tutto il mondo.
Conclusione
L'apprendimento federato rappresenta una grande promessa per l'analisi e l'intelligence dei dati sanitari legacy. È semplice implementare una soluzione nativa del cloud con i servizi AWS e FL è particolarmente utile per le organizzazioni mediche con dati legacy e sfide tecniche. FL può avere un potenziale impatto sull’intero ciclo di trattamento, e ora ancora di più con l’attenzione posta sull’interoperabilità dei dati da parte di grandi organizzazioni federali e leader governativi.
Questa soluzione può aiutarti a evitare di reinventare la ruota e a utilizzare la tecnologia più recente per fare un salto rispetto ai sistemi legacy ed essere in prima linea in questo mondo in continua evoluzione dell'intelligenza artificiale. Puoi anche diventare un leader per le migliori pratiche e un approccio efficiente all'interoperabilità dei dati all'interno e tra agenzie e istituti nel settore sanitario e oltre. Se sei un istituto o un'agenzia con silos di dati sparsi in tutto il paese, puoi trarre vantaggio da questa integrazione perfetta e sicura.
Il contenuto e le opinioni di questo post sono quelli dell'autore di terze parti e AWS non è responsabile del contenuto o dell'accuratezza di questo post. È responsabilità di ciascun cliente determinare se è soggetto all'HIPAA e, in tal caso, come conformarsi al meglio all'HIPAA e ai relativi regolamenti di attuazione. Prima di utilizzare AWS in relazione a informazioni sanitarie protette, i clienti devono inserire un AWS Business Associate Addendum (BAA) e seguire i relativi requisiti di configurazione.
L'autore

Nitin Kumar (SM, CMU) è Lead Data Scientist presso T and T Consulting Services, Inc. Ha una vasta esperienza nella prototipazione di ricerca e sviluppo, nell'informatica sanitaria, nei dati del settore pubblico e nell'interoperabilità dei dati. Applica la sua conoscenza dei metodi di ricerca all'avanguardia al settore federale per fornire documenti tecnici, POC e MVP innovativi. Ha collaborato con diverse agenzie federali per promuovere i loro dati e gli obiettivi di intelligenza artificiale. Le altre aree di interesse di Nitin includono l'elaborazione del linguaggio naturale (NLP), le pipeline di dati e l'intelligenza artificiale generativa.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/enable-data-sharing-through-federated-learning-a-policy-approach-for-chief-digital-officers/

