With the rapid adoption of generative AI applications, there is a need for these applications to respond in time to reduce the perceived latency with higher throughput. Foundation models (FMs) are often pre-trained on vast corpora of data with parameters ranging in scale of millions to billions and beyond. Large language models (LLMs) are a type of FM that generate text as a response of the user inference. Inferencing these models with varying configurations of inference parameters may lead to inconsistent latencies. The inconsistency could be because of the varying number of response tokens you are expecting from the model or the type of accelerator the model is deployed on.
In either case, rather than waiting for the full response, you can adopt the approach of response streaming for your inferences, which sends back chunks of information as soon as they are generated. This creates an interactive experience by allowing you to see partial responses streamed in real time instead of a delayed full response.
With the official announcement that Amazon SageMaker real-time inference now supports response streaming, you can now continuously stream inference responses back to the client when using Amazon SageMaker real-time inference with response streaming. This solution will help you build interactive experiences for various generative AI applications such as chatbots, virtual assistants, and music generators. This post shows you how to realize faster response times in the form of Time to First Byte (TTFB) and reduce the overall perceived latency while inferencing Llama 2 models.
To implement the solution, we use SageMaker, a fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. For more information about the various deployment options SageMaker provides, refer to Amazon SageMaker Model Hosting FAQs. Let’s understand how we can address the latency issues using real-time inference with response streaming.
Solution overview
Because we want to address the aforementioned latencies associated with real-time inference with LLMs, let’s first understand how we can use the response streaming support for real-time inferencing for Llama 2. However, any LLM can take advantage of response streaming support with real-time inferencing.
Llama 2 is a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Llama 2 models are autoregressive models with decoder only architecture. When provided with a prompt and inference parameters, Llama 2 models are capable of generating text responses. These models can be used for translation, summarization, question answering, and chat.
For this post, we deploy the Llama 2 Chat model meta-llama/Llama-2-13b-chat-hf on SageMaker for real-time inferencing with response streaming.
When it comes to deploying models on SageMaker endpoints, you can containerize the models using specialized AWS Deep Learning Container (DLC) images available for popular open source libraries. Llama 2 models are text generation models; you can use either the Hugging Face LLM inference containers on SageMaker powered by Hugging Face Text Generation Inference (TGI) or AWS DLCs for Large Model Inference (LMI).
In this post, we deploy the Llama 2 13B Chat model using DLCs on SageMaker Hosting for real-time inference powered by G5 instances. G5 instances are a high-performance GPU-based instances for graphics-intensive applications and ML inference. You can also use supported instance types p4d, p3, g5, and g4dn with appropriate changes as per the instance configuration.
Prerequisites
To implement this solution, you should have the following:
- An AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created as part of the solution.
- If this is your first time working with Amazon SageMaker Studio, you first need to create a SageMaker domain.
- A Hugging Face account. Sign up with your email if you don’t already have account.
- For seamless access of the models available on Hugging Face, especially gated models such as Llama, for fine-tuning and inferencing purposes, you should have a Hugging Face account to obtain a read access token. After you sign up for your Hugging Face account, log in to visit https://huggingface.co/settings/tokens to create a read access token.
- Access to Llama 2, using the same email ID that you used to sign up for Hugging Face.
- The Llama 2 models available via Hugging Face are gated models. The use of the Llama model is governed by the Meta license. To download the model weights and tokenizer, request access to Llama and accept their license.
- After you’re granted access (typically in a couple of days), you will receive an email confirmation. For this example, we use the model
Llama-2-13b-chat-hf, but you should be able to access other variants as well.
Approach 1: Hugging Face TGI
In this section, we show you how to deploy the meta-llama/Llama-2-13b-chat-hf model to a SageMaker real-time endpoint with response streaming using Hugging Face TGI. The following table outlines the specifications for this deployment.
| Specification | Value |
| Container | Hugging Face TGI |
| Model Name | meta-llama/Llama-2-13b-chat-hf |
| ML Instance | ml.g5.12xlarge |
| Inference | Real-time with response streaming |
Deploy the model
First, you retrieve the base image for the LLM to be deployed. You then build the model on the base image. Finally, you deploy the model to the ML instance for SageMaker Hosting for real-time inference.
Let’s observe how to achieve the deployment programmatically. For brevity, only the code that helps with the deployment steps is discussed in this section. The full source code for deployment is available in the notebook llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb.
Retrieve the latest Hugging Face LLM DLC powered by TGI via pre-built SageMaker DLCs. You use this image to deploy the meta-llama/Llama-2-13b-chat-hf model on SageMaker. See the following code:
Define the environment for the model with the configuration parameters defined as follows:
Replace <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> for the config parameter HUGGING_FACE_HUB_TOKEN with the value of the token obtained from your Hugging Face profile as detailed in the prerequisites section of this post. In the configuration, you define the number of GPUs used per replica of a model as 4 for SM_NUM_GPUS. Then you can deploy the meta-llama/Llama-2-13b-chat-hf model on an ml.g5.12xlarge instance that comes with 4 GPUs.
Now you can build the instance of HuggingFaceModel with the aforementioned environment configuration:
Finally, deploy the model by providing arguments to the deploy method available on the model with various parameter values such as endpoint_name, initial_instance_count, and instance_type:
Perform inference
The Hugging Face TGI DLC comes with the ability to stream responses without any customizations or code changes to the model. You can use invoke_endpoint_with_response_stream if you are using Boto3 or InvokeEndpointWithResponseStream when programming with the SageMaker Python SDK.
The InvokeEndpointWithResponseStream API of SageMaker allows developers to stream responses back from SageMaker models, which can help improve customer satisfaction by reducing the perceived latency. This is especially important for applications built with generative AI models, where immediate processing is more important than waiting for the entire response.
For this example, we use Boto3 to infer the model and use the SageMaker API invoke_endpoint_with_response_stream as follows:
The argument CustomAttributes is set to the value accept_eula=false. The accept_eula parameter must be set to true to successfully obtain the response from the Llama 2 models. After the successful invocation using invoke_endpoint_with_response_stream, the method will return a response stream of bytes.
The following diagram illustrates this workflow.
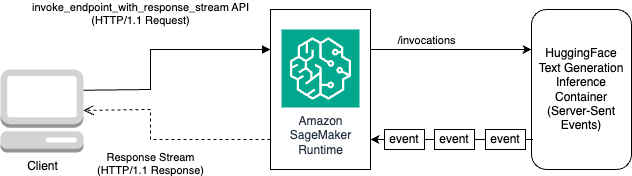
You need an iterator that loops over the stream of bytes and parses them to readable text. The LineIterator implementation can be found at llama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py. Now you’re ready to prepare the prompt and instructions to use them as a payload while inferencing the model.
Prepare a prompt and instructions
In this step, you prepare the prompt and instructions for your LLM. To prompt Llama 2, you should have the following prompt template:
You build the prompt template programmatically defined in the method build_llama2_prompt, which aligns with the aforementioned prompt template. You then define the instructions as per the use case. In this case, we’re instructing the model to generate an email for a marketing campaign as covered in the get_instructions method. The code for these methods is in the llama-2-hf-tgi/llama-2-13b-chat-hf/2-sagemaker-realtime-inference-llama-2-13b-chat-hf-tgi-streaming-response.ipynb notebook. Build the instruction combined with the task to be performed as detailed in user_ask_1 as follows:
We pass the instructions to build the prompt as per the prompt template generated by build_llama2_prompt.
We club the inference parameters along with prompt with the key stream with the value True to form a final payload. Send the payload to get_realtime_response_stream, which will be used to invoke an endpoint with response streaming:
The generated text from the LLM will be streamed to the output as shown in the following animation.
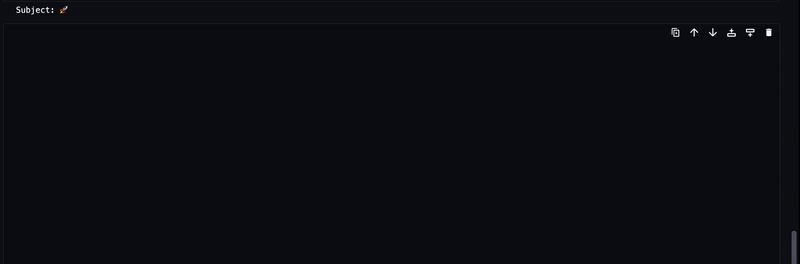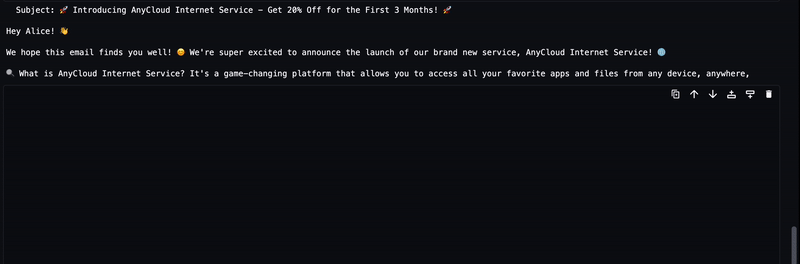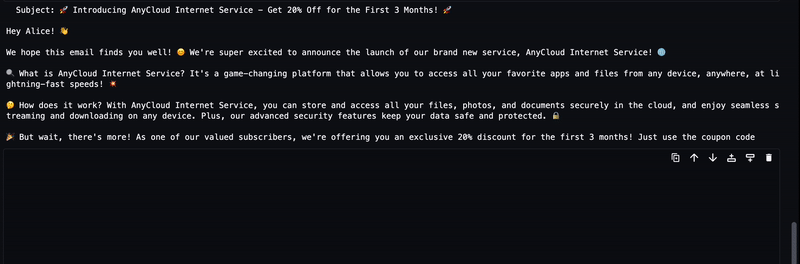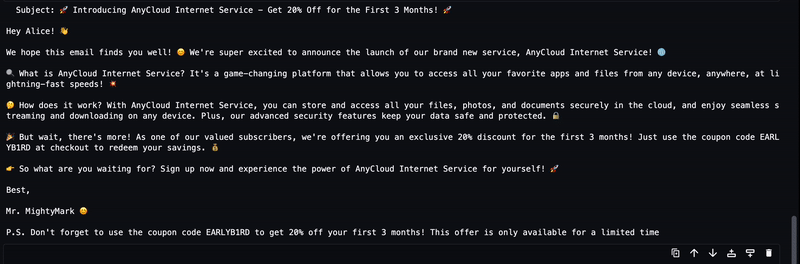
Approach 2: LMI with DJL Serving
In this section, we demonstrate how to deploy the meta-llama/Llama-2-13b-chat-hf model to a SageMaker real-time endpoint with response streaming using LMI with DJL Serving. The following table outlines the specifications for this deployment.
| Specification | Value |
| Container | LMI container image with DJL Serving |
| Model Name | meta-llama/Llama-2-13b-chat-hf |
| ML Instance | ml.g5.12xlarge |
| Inference | Real-time with response streaming |
You first download the model and store it in Amazon Simple Storage Service (Amazon S3). You then specify the S3 URI indicating the S3 prefix of the model in the serving.properties file. Next, you retrieve the base image for the LLM to be deployed. You then build the model on the base image. Finally, you deploy the model to the ML instance for SageMaker Hosting for real-time inference.
Let’s observe how to achieve the aforementioned deployment steps programmatically. For brevity, only the code that helps with the deployment steps is detailed in this section. The full source code for this deployment is available in the notebook llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb.
Download the model snapshot from Hugging Face and upload the model artifacts on Amazon S3
With the aforementioned prerequisites, download the model on the SageMaker notebook instance and then upload it to the S3 bucket for further deployment:
Note that even though you don’t provide a valid access token, the model will download. But when you deploy such a model, the model serving won’t succeed. Therefore, it’s recommended to replace <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> for the argument token with the value of the token obtained from your Hugging Face profile as detailed in the prerequisites. For this post, we specify the official model’s name for Llama 2 as identified on Hugging Face with the value meta-llama/Llama-2-13b-chat-hf. The uncompressed model will be downloaded to local_model_path as a result of running the aforementioned code.
Upload the files to Amazon S3 and obtain the URI, which will be later used in serving.properties.
You will be packaging the meta-llama/Llama-2-13b-chat-hf model on the LMI container image with DJL Serving using the configuration specified via serving.properties. Then you deploy the model along with model artifacts packaged on the container image on the SageMaker ML instance ml.g5.12xlarge. You then use this ML instance for SageMaker Hosting for real-time inferencing.
Prepare model artifacts for DJL Serving
Prepare your model artifacts by creating a serving.properties configuration file:
We use the following settings in this configuration file:
- engine – This specifies the runtime engine for DJL to use. The possible values include
Python,DeepSpeed,FasterTransformer, andMPI. In this case, we set it toMPI. Model Parallelization and Inference (MPI) facilitates partitioning the model across all the available GPUs and therefore accelerates inference. - option.entryPoint – This option specifies which handler offered by DJL Serving you would like to use. The possible values are
djl_python.huggingface,djl_python.deepspeed, anddjl_python.stable-diffusion. We usedjl_python.huggingfacefor Hugging Face Accelerate. - option.tensor_parallel_degree – This option specifies the number of tensor parallel partitions performed on the model. You can set to the number of GPU devices over which Accelerate needs to partition the model. This parameter also controls the number of workers per model that will be started up when DJL serving runs. For example, if we have a 4 GPU machine and we are creating four partitions, then we will have one worker per model to serve the requests.
- option.low_cpu_mem_usage – This reduces CPU memory usage when loading models. We recommend that you set this to
TRUE. - option.rolling_batch – This enables iteration-level batching using one of the supported strategies. Values include
auto,scheduler, andlmi-dist. We uselmi-distfor turning on continuous batching for Llama 2. - option.max_rolling_batch_size – This limits the number of concurrent requests in the continuous batch. The value defaults to 32.
- option.model_id – You should replace
{{model_id}}with the model ID of a pre-trained model hosted inside a model repository on Hugging Face or S3 path to the model artifacts.
More configuration options can be found in Configurations and settings.
Because DJL Serving expects the model artifacts to be packaged and formatted in a .tar file, run the following code snippet to compress and upload the .tar file to Amazon S3:
Retrieve the latest LMI container image with DJL Serving
Next, you use the DLCs available with SageMaker for LMI to deploy the model. Retrieve the SageMaker image URI for the djl-deepspeed container programmatically using the following code:
You can use the aforementioned image to deploy the meta-llama/Llama-2-13b-chat-hf model on SageMaker. Now you can proceed to create the model.
Create the model
You can create the model whose container is built using the inference_image_uri and the model serving code located at the S3 URI indicated by s3_code_artifact:
Now you can create the model config with all the details for the endpoint configuration.
Create the model config
Use the following code to create a model config for the model identified by model_name:
The model config is defined for the ProductionVariants parameter InstanceType for the ML instance ml.g5.12xlarge. You also provide the ModelName using the same name that you used to create the model in the earlier step, thereby establishing a relation between the model and endpoint configuration.
Now that you have defined the model and model config, you can create the SageMaker endpoint.
Create the SageMaker endpoint
Create the endpoint to deploy the model using the following code snippet:
You can view the progress of the deployment using the following code snippet:
After the deployment is successful, the endpoint status will be InService. Now that the endpoint is ready, let’s perform inference with response streaming.
Real-time inference with response streaming
As we covered in the earlier approach for Hugging Face TGI, you can use the same method get_realtime_response_stream to invoke response streaming from the SageMaker endpoint. The code for inferencing using the LMI approach is in the llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb notebook. The LineIterator implementation is located in llama-2-lmi/utils/LineIterator.py. Note that the LineIterator for the Llama 2 Chat model deployed on the LMI container is different to the LineIterator referenced in Hugging Face TGI section. The LineIterator loops over the byte stream from Llama 2 Chat models inferenced with the LMI container with djl-deepspeed version 0.25.0. The following helper function will parse the response stream received from the inference request made via the invoke_endpoint_with_response_stream API:
The preceding method prints the stream of data read by the LineIterator in a human-readable format.
Let’s explore how to prepare the prompt and instructions to use them as a payload while inferencing the model.
Because you’re inferencing the same model in both Hugging Face TGI and LMI, the process of preparing the prompt and instructions is same. Therefore, you can use the methods get_instructions and build_llama2_prompt for inferencing.
The get_instructions method returns the instructions. Build the instructions combined with the task to be performed as detailed in user_ask_2 as follows:
Pass the instructions to build the prompt as per the prompt template generated by build_llama2_prompt:
We club the inference parameters along with the prompt to form a final payload. Then you send the payload to get_realtime_response_stream, which is used to invoke an endpoint with response streaming:
The generated text from the LLM will be streamed to the output as shown in the following animation.
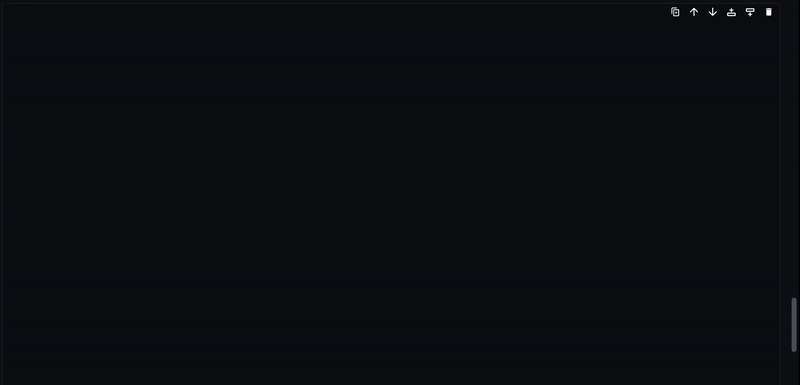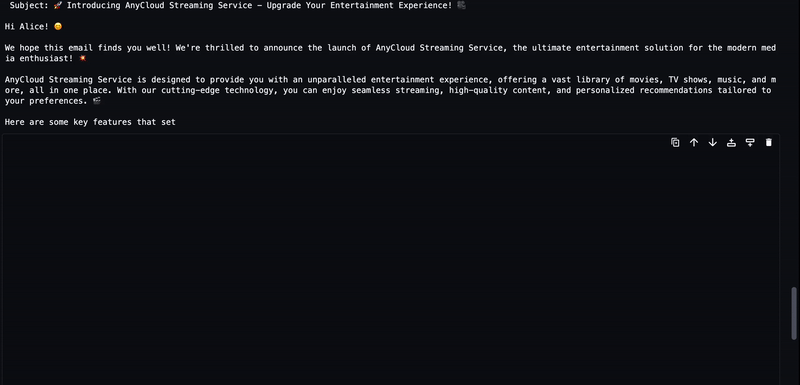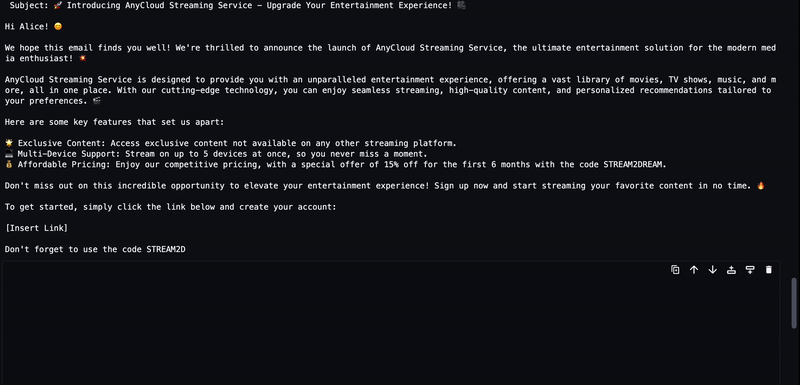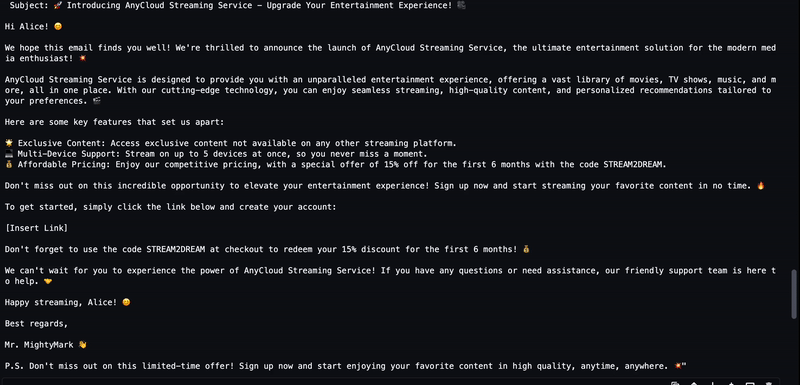
Clean up
To avoid incurring unnecessary charges, use the AWS Management Console to delete the endpoints and its associated resources that were created while running the approaches mentioned in the post. For both deployment approaches, perform the following cleanup routine:
Replace <SageMaker_Real-time_Endpoint_Name> for variable endpoint_name with the actual endpoint.
For the second approach, we stored the model and code artifacts on Amazon S3. You can clean up the S3 bucket using the following code:
Conclusion
In this post, we discussed how a varying number of response tokens or a different set of inference parameters can affect the latencies associated with LLMs. We showed how to address the problem with the help of response streaming. We then identified two approaches for deploying and inferencing Llama 2 Chat models using AWS DLCs—LMI and Hugging Face TGI.
You should now understand the importance of streaming response and how it can reduce perceived latency. Streaming response can improve the user experience, which otherwise would make you wait until the LLM builds the whole response. Additionally, deploying Llama 2 Chat models with response streaming improves the user experience and makes your customers happy.
You can refer to the official aws-samples amazon-sagemaker-llama2-response-streaming-recipes that covers deployment for other Llama 2 model variants.
References
About the Authors
 Pavan Kumar Rao Navule is a Solutions Architect at Amazon Web Services. He works with ISVs in India to help them innovate on AWS. He is a published author for the book “Getting Started with V Programming.” He pursued an Executive M.Tech in Data Science from the Indian Institute of Technology (IIT), Hyderabad. He also pursued an Executive MBA in IT specialization from the Indian School of Business Management and Administration, and holds a B.Tech in Electronics and Communication Engineering from the Vaagdevi Institute of Technology and Science. Pavan is an AWS Certified Solutions Architect Professional and holds other certifications such as AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP), and Microsoft Certified Technology Specialist (MCTS). He is also an open-source enthusiast. In his free time, he loves to listen to the great magical voices of Sia and Rihanna.
Pavan Kumar Rao Navule is a Solutions Architect at Amazon Web Services. He works with ISVs in India to help them innovate on AWS. He is a published author for the book “Getting Started with V Programming.” He pursued an Executive M.Tech in Data Science from the Indian Institute of Technology (IIT), Hyderabad. He also pursued an Executive MBA in IT specialization from the Indian School of Business Management and Administration, and holds a B.Tech in Electronics and Communication Engineering from the Vaagdevi Institute of Technology and Science. Pavan is an AWS Certified Solutions Architect Professional and holds other certifications such as AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP), and Microsoft Certified Technology Specialist (MCTS). He is also an open-source enthusiast. In his free time, he loves to listen to the great magical voices of Sia and Rihanna.
 Sudhanshu Hate is principal AI/ML specialist with AWS and works with clients to advise them on their MLOps and generative AI journey. In his previous role before Amazon, he conceptualized, created, and led teams to build ground-up open source-based AI and gamification platforms, and successfully commercialized it with over 100 clients. Sudhanshu to his credit a couple of patents, has written two books and several papers and blogs, and has presented his points of view in various technical forums. He has been a thought leader and speaker, and has been in the industry for nearly 25 years. He has worked with Fortune 1000 clients across the globe and most recently with digital native clients in India.
Sudhanshu Hate is principal AI/ML specialist with AWS and works with clients to advise them on their MLOps and generative AI journey. In his previous role before Amazon, he conceptualized, created, and led teams to build ground-up open source-based AI and gamification platforms, and successfully commercialized it with over 100 clients. Sudhanshu to his credit a couple of patents, has written two books and several papers and blogs, and has presented his points of view in various technical forums. He has been a thought leader and speaker, and has been in the industry for nearly 25 years. He has worked with Fortune 1000 clients across the globe and most recently with digital native clients in India.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/inference-llama-2-models-with-real-time-response-streaming-using-amazon-sagemaker/

