Perkembangan terkini dalam pembelajaran mesin (ML) telah menghasilkan model yang semakin besar, beberapa di antaranya memerlukan ratusan miliar parameter. Meskipun model ini lebih canggih, pelatihan dan inferensi pada model tersebut memerlukan sumber daya komputasi yang besar. Meskipun tersedia perpustakaan pelatihan terdistribusi tingkat lanjut, pekerjaan pelatihan dan inferensi biasanya memerlukan ratusan akselerator (GPU atau chip ML yang dibuat khusus seperti Pelatihan AWS dan Inferensi AWS), dan karenanya puluhan atau ratusan contoh.
Dalam lingkungan terdistribusi seperti itu, kemampuan observasi terhadap instance dan chip ML menjadi kunci untuk menyempurnakan performa model dan mengoptimalkan biaya. Metrik memungkinkan tim memahami perilaku beban kerja dan mengoptimalkan alokasi dan pemanfaatan sumber daya, mendiagnosis anomali, dan meningkatkan efisiensi infrastruktur secara keseluruhan. Bagi data scientist, pemanfaatan dan saturasi chip ML juga relevan untuk perencanaan kapasitas.
Posting ini memandu Anda melalui Pola Observabilitas Sumber Terbuka untuk AWS Inferentia, yang menunjukkan kepada Anda cara memantau kinerja chip ML, yang digunakan dalam sebuah Layanan Amazon Elastic Kubernetes Kluster (Amazon EKS), dengan node bidang data berdasarkan Cloud komputasi elastis Amazon (Amazon EC2) tipe instans inf1 dan inf2.
Polanya adalah bagian dari Akselerator Observabilitas AWS CDK, serangkaian modul yang disetujui untuk membantu Anda mengatur kemampuan observasi untuk klaster Amazon EKS. Akselerator Observabilitas AWS CDK disusun berdasarkan pola, yang merupakan unit yang dapat digunakan kembali untuk menerapkan beberapa sumber daya. Kumpulan instrumen pola observasi sumber terbuka yang dapat diamati dengan Grafana yang Dikelola Amazon dasbor, sebuah Distro AWS untuk OpenTelemetry kolektor untuk mengumpulkan metrik, dan Layanan Terkelola Amazon untuk Prometheus untuk menyimpannya.
Ikhtisar solusi
Diagram berikut menggambarkan arsitektur solusi.

Solusi ini menyebarkan klaster Amazon EKS dengan grup simpul yang mencakup instans Inf1.
Tipe AMI dari grup simpul adalah AL2_x86_64_GPU, yang menggunakan Amazon EKS mengoptimalkan akselerasi Amazon Linux AMI. Selain konfigurasi AMI standar yang dioptimalkan Amazon EKS, AMI yang dipercepat mencakup Waktu proses NeuronX.
Untuk mengakses chip ML dari Kubernetes, pola tersebut menyebarkan Neuron AWS plugin perangkat.
Metrik diekspos ke Amazon Managed Service untuk Prometheus oleh neuron-monitor DaemonSet, yang menyebarkan container minimal, dengan Alat neuron dipasang. Secara khusus, neuron-monitor DaemonSet menjalankan neuron-monitor perintah disalurkan ke neuron-monitor-prometheus.py skrip pendamping (kedua perintah adalah bagian dari wadah):
Perintah ini menggunakan komponen-komponen berikut:
neuron-monitormengumpulkan metrik dan statistik dari aplikasi Neuron yang berjalan di sistem dan mengalirkan data yang dikumpulkan ke stdout Format JSONneuron-monitor-prometheus.pymemetakan dan memaparkan data telemetri dari format JSON ke dalam format yang kompatibel dengan Prometheus
Data divisualisasikan di Amazon Managed Grafana melalui dasbor yang sesuai.
Penyiapan selanjutnya untuk mengumpulkan dan memvisualisasikan metrik dengan Amazon Managed Service untuk Prometheus dan Amazon Managed Grafana serupa dengan yang digunakan dalam pola berbasis sumber terbuka lainnya, yang disertakan dalam AWS Observability Accelerator for CDK Repositori GitHub.
Prasyarat
Anda memerlukan yang berikut ini untuk menyelesaikan langkah-langkah dalam posting ini:
Mengatur lingkungan
Selesaikan langkah-langkah berikut untuk menyiapkan lingkungan Anda:
- Buka jendela terminal dan jalankan perintah berikut:
- Ambil ID ruang kerja dari ruang kerja Amazon Managed Grafana yang ada:
Berikut ini adalah contoh keluaran kami:
- Tetapkan nilai dari
iddanendpointke variabel lingkungan berikut:
COA_AMG_ENDPOINT_URL perlu disertakan https://.
- Buat kunci API Grafana dari ruang kerja Amazon Managed Grafana:
- Siapkan rahasia di Manajer Sistem AWS:
Rahasia tersebut akan diakses oleh add-on Rahasia Eksternal dan tersedia sebagai rahasia asli Kubernetes di cluster EKS.
Bootstrap lingkungan AWS CDK
Langkah pertama dalam penerapan AWS CDK adalah melakukan bootstrap terhadap lingkungan. Anda menggunakan cdk bootstrap perintah di CLI AWS CDK untuk mempersiapkan lingkungan (kombinasi akun AWS dan Wilayah AWS) dengan sumber daya yang diperlukan oleh AWS CDK untuk melakukan penerapan ke lingkungan tersebut. Bootstrapping AWS CDK diperlukan untuk setiap kombinasi akun dan Wilayah, jadi jika Anda sudah melakukan bootstrap AWS CDK di suatu Wilayah, Anda tidak perlu mengulangi proses bootstrapping.
Terapkan solusinya
Selesaikan langkah-langkah berikut untuk menyebarkan solusi:
- Clone file cdk-aws-observabilitas-akselerator repositori dan instal paket ketergantungan. Repositori ini berisi kode AWS CDK v2 yang ditulis dalam TypeScript.
Pengaturan sebenarnya untuk file JSON dasbor Grafana diharapkan ditentukan dalam konteks AWS CDK. Anda perlu memperbarui context dalam cdk.json file, terletak di direktori saat ini. Lokasi dasbor ditentukan oleh fluxRepository.values.GRAFANA_NEURON_DASH_URL parameter, dan neuronNodeGroup digunakan untuk mengatur jenis instance, nomor, dan Toko Blok Elastis Amazon (Amazon EBS) ukuran yang digunakan untuk node.
- Masukkan cuplikan berikut ke dalamnya
cdk.json, mengganticontext:
Anda dapat mengganti jenis instans Inf1 dengan Inf2 dan mengubah ukurannya sesuai kebutuhan. Untuk memeriksa ketersediaan di Wilayah yang Anda pilih, jalankan perintah berikut (ubah Values sesuai keinginan Anda):
- Instal dependensi proyek:
- Jalankan perintah berikut untuk menyebarkan pola observasi sumber terbuka:
Validasi solusinya
Selesaikan langkah-langkah berikut untuk memvalidasi solusi:
- Jalankan
update-kubeconfigmemerintah. Anda seharusnya bisa mendapatkan perintah dari pesan keluaran dari perintah sebelumnya:
- Verifikasi sumber daya yang Anda buat:
Tangkapan layar berikut menunjukkan contoh keluaran kami.

- Pastikan
neuron-device-plugin-daemonsetDaemonSet sedang berjalan:
Berikut ini adalah hasil yang kami harapkan:
- Konfirmasikan bahwa
neuron-monitorDaemonSet sedang berjalan:
Berikut ini adalah hasil yang kami harapkan:
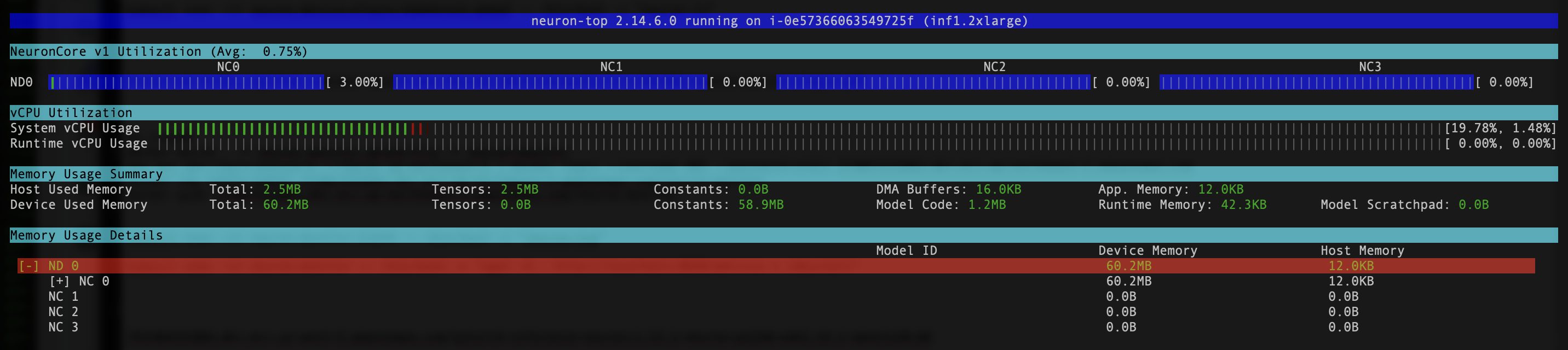
- Untuk memverifikasi bahwa perangkat dan inti Neuron terlihat, jalankan
neuron-lsdanneuron-topperintah dari, misalnya, pod monitor neuron Anda (Anda bisa mendapatkan nama pod dari outputkubectl get pods -A):
Tangkapan layar berikut menunjukkan keluaran yang diharapkan.

Tangkapan layar berikut menunjukkan keluaran yang diharapkan.
Visualisasikan data menggunakan dashboard Grafana Neuron
Masuk ke ruang kerja Amazon Managed Grafana Anda dan navigasikan ke Dashboard panel. Anda akan melihat dasbor bernama Neuron/Pemantau.
Untuk melihat beberapa metrik menarik di dashboard Grafana, kami menerapkan manifes berikut:
Ini adalah contoh beban kerja yang mengkompilasi model oborvision ResNet50 dan menjalankan inferensi berulang dalam satu lingkaran untuk menghasilkan data telemetri.
Untuk memverifikasi pod berhasil di-deploy, jalankan kode berikut:
Anda akan melihat sebuah pod bernama pytorch-inference-resnet50.
Setelah beberapa menit, melihat ke dalam Neuron/Pemantau dasbor, Anda akan melihat metrik yang dikumpulkan serupa dengan tangkapan layar berikut.




Operator Grafana dan Flux selalu bekerja sama untuk menyinkronkan dasbor Anda dengan Git. Jika Anda menghapus dasbor secara tidak sengaja, dasbor tersebut akan disediakan ulang secara otomatis.
Membersihkan
Anda dapat menghapus seluruh tumpukan AWS CDK dengan perintah berikut:
Kesimpulan
Dalam postingan ini, kami menunjukkan kepada Anda cara memperkenalkan kemampuan observasi, dengan peralatan sumber terbuka, ke dalam klaster EKS yang menampilkan bidang data yang menjalankan instans EC2 Inf1. Kami memulai dengan memilih AMI terakselerasi yang dioptimalkan Amazon EKS untuk node bidang data, yang mencakup runtime kontainer Neuron, yang menyediakan akses ke perangkat AWS Inferentia dan Trainium Neuron. Kemudian, untuk mengekspos inti dan perangkat Neuron ke Kubernetes, kami menerapkan plugin perangkat Neuron. Pengumpulan dan pemetaan data telemetri yang sebenarnya ke dalam format yang kompatibel dengan Prometheus dicapai melalui neuron-monitor dan neuron-monitor-prometheus.py. Metrik bersumber dari Amazon Managed Service untuk Prometheus dan ditampilkan di dasbor Neuron Amazon Managed Grafana.
Kami menyarankan Anda menjelajahi pola observasi tambahan di Akselerator Observabilitas AWS untuk CDK Repo GitHub. Untuk mempelajari lebih lanjut tentang Neuron, lihat Dokumentasi Neuron AWS.
tentang Penulis
 Riccardo Freschi adalah Sr. Solutions Architect di AWS, dengan fokus pada modernisasi aplikasi. Dia bekerja sama dengan mitra dan pelanggan untuk membantu mereka mengubah lanskap TI dalam perjalanan mereka menuju AWS Cloud dengan memfaktorkan ulang aplikasi yang sudah ada dan membangun aplikasi baru.
Riccardo Freschi adalah Sr. Solutions Architect di AWS, dengan fokus pada modernisasi aplikasi. Dia bekerja sama dengan mitra dan pelanggan untuk membantu mereka mengubah lanskap TI dalam perjalanan mereka menuju AWS Cloud dengan memfaktorkan ulang aplikasi yang sudah ada dan membangun aplikasi baru.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/open-source-observability-for-aws-inferentia-nodes-within-amazon-eks-clusters/

