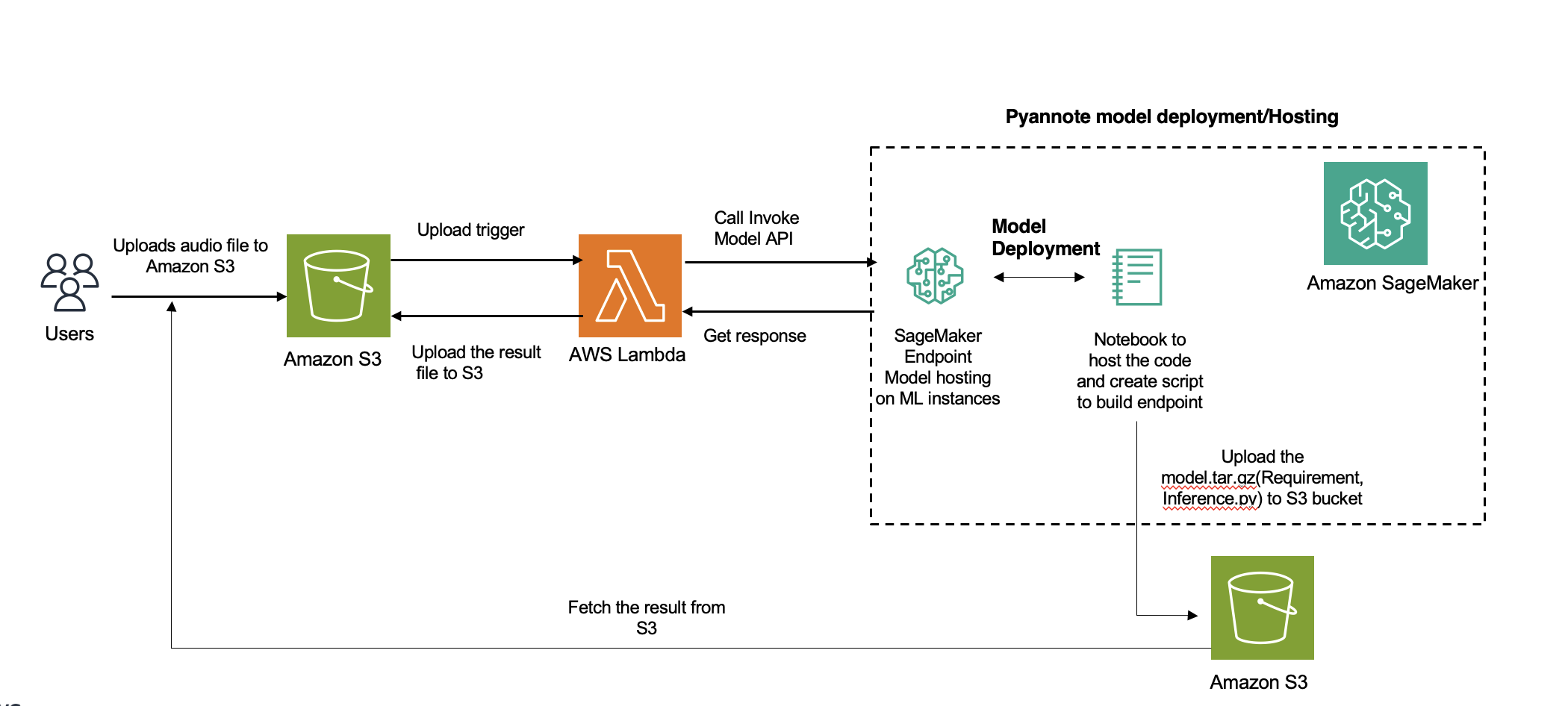
Diarisasi pembicara, sebuah proses penting dalam analisis audio, mengelompokkan file audio berdasarkan identitas pembicara. Posting ini mempelajari cara mengintegrasikan PyAnnote Hugging Face untuk diarisasi pembicara Amazon SageMaker titik akhir asinkron.
Kami memberikan panduan komprehensif tentang cara menerapkan solusi segmentasi dan pengelompokan speaker menggunakan SageMaker di AWS Cloud. Anda dapat menggunakan solusi ini untuk aplikasi yang menangani rekaman audio multi-speaker (lebih dari 100).
Ikhtisar solusi
Amazon Transkripsikan adalah layanan masuk untuk diarisasi pembicara di AWS. Namun, untuk bahasa yang tidak didukung, Anda dapat menggunakan model lain (dalam kasus kami, PyAnnote) yang akan diterapkan di SageMaker untuk inferensi. Untuk file audio pendek yang inferensinya memerlukan waktu hingga 60 detik, Anda dapat menggunakan inferensi waktu-nyata. Selama lebih dari 60 detik, asynchronous inferensi harus digunakan. Manfaat tambahan dari inferensi asinkron adalah penghematan biaya dengan menskalakan jumlah instans secara otomatis ke nol ketika tidak ada permintaan untuk diproses.
Wajah Memeluk adalah hub sumber terbuka yang populer untuk model pembelajaran mesin (ML). AWS dan Hugging Face memiliki persekutuan yang memungkinkan integrasi mulus melalui SageMaker dengan serangkaian AWS Deep Learning Containers (DLC) untuk pelatihan dan inferensi di PyTorch atau TensorFlow, serta estimator dan prediktor Hugging Face untuk SageMaker Python SDK. Fitur dan kemampuan SageMaker membantu pengembang dan ilmuwan data memulai pemrosesan bahasa alami (NLP) di AWS dengan mudah.
Integrasi untuk solusi ini melibatkan penggunaan model diarisasi pembicara terlatih Hugging Face menggunakan Perpustakaan PyAnnote. PyAnnote adalah toolkit sumber terbuka yang ditulis dengan Python untuk diarisasi pembicara. Model ini, yang dilatih pada contoh kumpulan data audio, memungkinkan partisi speaker yang efektif dalam file audio. Model ini diterapkan di SageMaker sebagai pengaturan titik akhir asinkron, memberikan pemrosesan tugas diarisasi yang efisien dan skalabel.
Diagram berikut menggambarkan arsitektur solusi.
Untuk posting ini, kami menggunakan file audio berikut.
File audio stereo atau multi-saluran secara otomatis di-downmix menjadi mono dengan merata-ratakan saluran. File audio yang diambil sampelnya pada kecepatan berbeda akan diambil sampelnya ulang menjadi 16kHz secara otomatis saat dimuat.
Pastikan akun AWS memiliki kuota layanan untuk menghosting titik akhir SageMaker untuk instans ml.g5.2xlarge.
Buat fungsi model untuk mengakses diarisasi speaker PyAnnote dari Hugging Face
Anda dapat menggunakan Hugging Face Hub untuk mengakses pelatihan sebelumnya yang diinginkan Model diarisasi pembicara PyAnnote. Anda menggunakan skrip yang sama untuk mengunduh file model saat membuat titik akhir SageMaker.
Lihat kode berikut:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
Kemas kode model
Siapkan file penting seperti inference.py, yang berisi kode inferensi:
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data[turn] = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=["start", "end", "speaker"])
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
Siapkan a requirements.txt file, yang berisi pustaka Python yang diperlukan untuk menjalankan inferensi:
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
Terakhir, kompres inference.py dan file persyaratan.txt dan simpan sebagai model.tar.gz:
!tar zcvf model.tar.gz *
Konfigurasikan model SageMaker
Tentukan sumber daya model SageMaker dengan menentukan URI gambar, lokasi data model Layanan Penyimpanan Sederhana Amazon (S3), dan peran SageMaker:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client("iam")
role = iam.get_role(RoleName="sagemaker_execution_role")["Role"]["Arn"]
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
Unggah model ke Amazon S3
Unggah file model PyAnnote Hugging Face yang telah di-zip ke bucket S3:
Konfigurasikan titik akhir asinkron untuk menerapkan model di SageMaker menggunakan konfigurasi inferensi asinkron yang disediakan:
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
Uji titik akhir
Evaluasi fungsionalitas titik akhir dengan mengirimkan file audio untuk diarisasi dan mengambil output JSON yang disimpan di jalur output S3 yang ditentukan:
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
Untuk menerapkan solusi ini dalam skala besar, kami menyarankan untuk menggunakan AWS Lambda, Layanan Pemberitahuan Sederhana Amazon (Amazon SNS), atau Layanan Antrian Sederhana Amazon (Amazon SQS). Layanan ini dirancang untuk skalabilitas, arsitektur berbasis peristiwa, dan pemanfaatan sumber daya yang efisien. Mereka dapat membantu memisahkan proses inferensi asinkron dari pemrosesan hasil, memungkinkan Anda menskalakan setiap komponen secara independen dan menangani lonjakan permintaan inferensi dengan lebih efektif.
Hasil
Output model disimpan di s3://sagemaker-xxxx /async_inference/output/. Outputnya menunjukkan bahwa rekaman audio telah disegmentasi menjadi tiga kolom:
Anda dapat menetapkan kebijakan penskalaan ke nol dengan mengatur MinCapacity ke 0; inferensi asinkron memungkinkan Anda menskalakan secara otomatis ke nol tanpa permintaan. Anda tidak perlu menghapus titik akhir, itu sisik dari nol saat dibutuhkan lagi, mengurangi biaya saat tidak digunakan. Lihat kode berikut:
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
Jika Anda ingin menghapus titik akhir, gunakan kode berikut:
Solusinya dapat secara efisien menangani banyak atau file audio berukuran besar.
Contoh ini menggunakan satu contoh untuk demonstrasi. Jika Anda ingin menggunakan solusi ini untuk ratusan atau ribuan video dan menggunakan titik akhir asinkron untuk memproses di beberapa contoh, Anda dapat menggunakan kebijakan penskalaan otomatis, yang dirancang untuk sejumlah besar dokumen sumber. Penskalaan otomatis secara dinamis menyesuaikan jumlah instans yang disediakan untuk model sebagai respons terhadap perubahan beban kerja Anda.
Solusi ini mengoptimalkan sumber daya dan mengurangi beban sistem dengan memisahkan tugas-tugas yang berjalan lama dari inferensi waktu nyata.
Kesimpulan
Dalam postingan ini, kami memberikan pendekatan langsung untuk menerapkan model diarisasi speaker Hugging Face di SageMaker menggunakan skrip Python. Menggunakan titik akhir asinkron memberikan cara yang efisien dan terukur untuk memberikan prediksi diarisasi sebagai layanan, mengakomodasi permintaan bersamaan dengan lancar.
Mulailah hari ini dengan diarisasi speaker asinkron untuk proyek audio Anda. Hubungi komentar jika Anda memiliki pertanyaan tentang cara mengaktifkan dan menjalankan titik akhir diarisasi asinkron Anda sendiri.
Tentang Penulis
Sanjaya Tiwary adalah Arsitek Solusi Spesialis AI/ML yang menghabiskan waktunya bekerja dengan pelanggan strategis untuk menentukan kebutuhan bisnis, menyediakan sesi L300 seputar kasus penggunaan tertentu, dan merancang aplikasi dan layanan AI/ML yang skalabel, andal, dan berperforma tinggi. Dia telah membantu meluncurkan dan menskalakan layanan Amazon SageMaker yang didukung AI/ML dan telah menerapkan beberapa bukti konsep menggunakan layanan Amazon AI. Ia juga telah mengembangkan platform analitik canggih sebagai bagian dari perjalanan transformasi digital.
Kiran Challapalli adalah pengembang bisnis teknologi mendalam dengan sektor publik AWS. Dia memiliki lebih dari 8 tahun pengalaman dalam AI/ML dan 23 tahun dalam pengembangan perangkat lunak dan pengalaman penjualan secara keseluruhan. Kiran membantu bisnis sektor publik di seluruh India mengeksplorasi dan bersama-sama menciptakan solusi berbasis cloud yang menggunakan teknologi AI, ML, dan AI generatif—termasuk model bahasa besar.
 Sanjaya Tiwary adalah Arsitek Solusi Spesialis AI/ML yang menghabiskan waktunya bekerja dengan pelanggan strategis untuk menentukan kebutuhan bisnis, menyediakan sesi L300 seputar kasus penggunaan tertentu, dan merancang aplikasi dan layanan AI/ML yang skalabel, andal, dan berperforma tinggi. Dia telah membantu meluncurkan dan menskalakan layanan Amazon SageMaker yang didukung AI/ML dan telah menerapkan beberapa bukti konsep menggunakan layanan Amazon AI. Ia juga telah mengembangkan platform analitik canggih sebagai bagian dari perjalanan transformasi digital.
Sanjaya Tiwary adalah Arsitek Solusi Spesialis AI/ML yang menghabiskan waktunya bekerja dengan pelanggan strategis untuk menentukan kebutuhan bisnis, menyediakan sesi L300 seputar kasus penggunaan tertentu, dan merancang aplikasi dan layanan AI/ML yang skalabel, andal, dan berperforma tinggi. Dia telah membantu meluncurkan dan menskalakan layanan Amazon SageMaker yang didukung AI/ML dan telah menerapkan beberapa bukti konsep menggunakan layanan Amazon AI. Ia juga telah mengembangkan platform analitik canggih sebagai bagian dari perjalanan transformasi digital. Kiran Challapalli adalah pengembang bisnis teknologi mendalam dengan sektor publik AWS. Dia memiliki lebih dari 8 tahun pengalaman dalam AI/ML dan 23 tahun dalam pengembangan perangkat lunak dan pengalaman penjualan secara keseluruhan. Kiran membantu bisnis sektor publik di seluruh India mengeksplorasi dan bersama-sama menciptakan solusi berbasis cloud yang menggunakan teknologi AI, ML, dan AI generatif—termasuk model bahasa besar.
Kiran Challapalli adalah pengembang bisnis teknologi mendalam dengan sektor publik AWS. Dia memiliki lebih dari 8 tahun pengalaman dalam AI/ML dan 23 tahun dalam pengembangan perangkat lunak dan pengalaman penjualan secara keseluruhan. Kiran membantu bisnis sektor publik di seluruh India mengeksplorasi dan bersama-sama menciptakan solusi berbasis cloud yang menggunakan teknologi AI, ML, dan AI generatif—termasuk model bahasa besar.
