Amazon SageMaker Ground Truth Plus helps you prepare high-quality training datasets by removing the undifferentiated heavy lifting associated with building data labeling applications and managing the labeling workforce. All you do is share data along with labeling requirements, and Ground Truth Plus sets up and manages your data labeling workflow based on these requirements. From there, an expert workforce that is trained on a variety of machine learning (ML) tasks labels your data. You don’t even need deep ML expertise or knowledge of workflow design and quality management to use Ground Truth Plus. Now, Ground Truth Plus is serving customers who need data labeling and human feedback for fine-tuning foundation models for generative AI applications.
In this post, you will learn about recent advancements in human feedback for generative AI available through SageMaker Ground Truth Plus. This includes new workflows and user interfaces (UIs) available for preparing demonstration datasets used in supervised fine-tuning, gathering high-quality human feedback to make preference datasets for aligning generative AI foundation models with human preferences, as well as customizing models to application builders’ requirements for style, substance, and voice.
Challenges of getting started with generative AI
Generative AI applications around the world incorporate both single-mode and multi-modal foundation models to solve for many different use cases. Common among them are chatbots, image generators, and video generators. Large language models (LLMs) are being used in chatbots for creative pursuits, academic and personal assistants, business intelligence tools, and productivity tools. You can use text-to-image models to generate abstract or realistic AI art and marketing assets. Text-to-video models are being used to generate videos for art projects, highly engaging advertisements, video game development, and even film development.
Two of the most important problems to solve for both model producers who create foundation models and application builders who use existing generative foundation models to build their own tools and applications are:
- Fine-tuning these foundation models to be able to perform specific tasks
- Aligning them with human preferences to ensure they output helpful, accurate, and harmless information
Foundation models are typically pre-trained on large corpora of unlabeled data, and therefore don’t perform well following natural language instructions. For an LLM, that means that they may be able to parse and generate language in general, but they may not be able to answer questions coherently or summarize text up to a user’s required quality. For example, when a user requests a summary of a text in a prompt, a model that hasn’t been fine-tuned how to summarize text may just recite the prompt text back to the user or respond with something irrelevant. If a user asks a question about a topic, the response from a model could just be a recitation of the question. For multi-modal models, such as text-to-image or text-to-video models, the models may output content unrelated to the prompt. For example, if a corporate graphic designer prompts a text-to-image model to create a new logo or an image for an advertisement, the model may not generate a relevant graphic related to the prompt if it has only a general concept of an image and elements of an image. In some cases, a model may output a harmful image or video, risking user confidence or company reputation.
Even if models are fine-tuned to perform specific tasks, they may not be aligned with human preferences with respect to the meaning, style, or substance of their output content. In an LLM, this could manifest itself as inaccurate or even harmful content being generated by the model. For example, a model that isn’t aligned with human preferences through fine-tuning may output dangerous, unethical, or even illegal instructions when prompted by a user. No care will have been taken to limit the content being generated by the model to ensure it is aligned with human preferences to be accurate, relevant, and useful. This misalignment can be a problem for companies that rely on generative AI models for their applications, such as chatbots and multimedia creation. For multi-modal models, this may take the form of toxic, dangerous, or abusive images or video being generated. This is a risk when prompts are input to the model without the intention of generating sensitive content, and also if the model producer or application builder had not intended to allow the model to generate that kind of content, but it was generated anyway.
To solve the issues of task-specific capability and aligning generative foundation models with human preferences, model producers and application builders must fine-tune the models with data using human-directed demonstrations and human feedback of model outputs.
Data and training types
There are several types of fine-tuning methods with different types of labeled data that are categorized as instruction tuning – or teaching a model how to follow instructions. Among them are supervised fine-tuning (SFT) using demonstration data, and reinforcement learning from human feedback (RLHF) using preference data.
Demonstration data for supervised fine-tuning
To fine-tune foundation models to perform specific tasks such as answering questions or summarizing text with high quality, the models undergo SFT with demonstration data. The purpose of demonstration data is to guide the model by providing it with labeled examples (demonstrations) of completed tasks being done by humans. For example, to teach an LLM how to answer questions, a human annotator will create a labeled dataset of human-generated question and answer pairs to demonstrate how a question and answer interaction works linguistically and what the content means semantically. This kind of SFT trains the model to recognize patterns of behavior demonstrated by the humans in the demonstration training data. Model producers need to do this type of fine-tuning to show that their models are capable of performing such tasks for downstream adopters. Application builders who use existing foundation models for their generative AI applications may need to fine-tune their models with demonstration data on these tasks with industry-specific or company-specific data to improve the relevancy and accuracy of their applications.
Preference data for instruction tuning such as RLHF
To further align foundation models with human preferences, model producers—and especially application builders—need to generate preference datasets to perform instruction tuning. Preference data in the context of instruction tuning is labeled data that captures human feedback with respect to a set of options output by a generative foundation model. It typically includes rating or ranking several inferences or pairwise comparing two inferences from a foundation model according to some specific attribute. For LLMs, these attributes may be helpfulness, accuracy, and harmlessness. For text-to-image models, it may be an aesthetic quality or text-image alignment. This preference data based on human feedback can then be used in various instruction tuning methods—including RLHF—in order to further fine-tune a model to align with human preferences.
Instruction tuning using preference data plays a crucial role in enhancing the personalization and effectiveness of foundation models. This is a key step in building custom applications on top of pre-trained foundation models and is a powerful method to ensure models are generating helpful, accurate, and harmless content. A common example of instruction tuning is to instruct a chatbot to generate three responses to a query, and have a human read and rank all three according to some specified dimension, such as toxicity, factual accuracy, or readability. For example, a company may use a chatbot for its marketing department and wants to make sure that content is aligned to its brand message, doesn’t exhibit biases, and is clearly readable. The company would prompt the chatbot during instruction tuning to produce three examples, and have their internal experts select the ones that most align to their goal. Over time, they build a dataset used to teach the model what style of content humans prefer through reinforcement learning. This enables the chatbot application to output more relevant, readable, and safe content.
SageMaker Ground Truth Plus
Ground Truth Plus helps you address both challenges—generating demonstration datasets with task-specific capabilities, as well as gathering preference datasets from human feedback to align models with human preferences. You can request projects for LLMs and multi-modal models such as text-to-image and text-to-video. For LLMs, key demonstration datasets include generating questions and answers (Q&A), text summarization, text generation, and text reworking for the purposes of content moderation, style change, or length change. Key LLM preference datasets include ranking and classifying text outputs. For multi-modal models, key task types include captioning images or videos as well as logging timestamps of events in videos. Therefore, Ground Truth Plus can help both model producers and application builders on their generative AI journey.
In this post, we dive deeper into the human annotator and feedback journey on four cases covering both demonstration data and preference data for both LLMs and multi-modal models: question and answer pair generation and text ranking for LLMs, as well as image captioning and video captioning for multi-modal models.
Large language models
In this section, we discuss question and answer pairs and text ranking for LLMs, along with customizations you may want for your use case.
Question and answer pairs
The following screenshot shows a labeling UI in which a human annotator will read a text passage and generate both questions and answers in the process of building a Q&A demonstration dataset.

Let’s walk through a tour of the UI in the annotator’s shoes. On the left side of the UI, the job requester’s specific instructions are presented to the annotator. In this case, the annotator is supposed to read the passage of text presented in the center of the UI and create questions and answers based on the text. On the right side, the questions and answers that the annotator has written are shown. The text passage as well as type, length, and number of questions and answers can all be customized by the job requester during the project setup with the Ground Truth Plus team. In this case, the annotator has created a question that requires understanding the whole text passage to answer and is marked with a References entire passage check box. The other two questions and answers are based on specific parts of the text passage, as shown by the annotator highlights with color-coded matching. Optionally, you may want to request that questions and answers are generated without a provided text passage, and provide other guidelines for human annotators—this is also supported by Ground Truth Plus.
After the questions and answers are submitted, they can flow to an optional quality control loop workflow where other human reviewers will confirm that customer-defined distribution and types of questions and answers have been created. If there is a mismatch between the customer requirements and what the human annotator has produced, the work will get funneled back to a human for rework before being exported as part of the dataset to deliver to the customer. When the dataset is delivered back to you, it’s ready to incorporate into the supervised fine-tuning workflow at your discretion.
Text ranking
The following screenshot shows a UI for ranking the outputs from an LLM based on a prompt.

You can simply write the instructions for the human reviewer, and bring prompts and pre-generated responses to the Ground Truth Plus project team to start the job. In this case, we have requested for a human reviewer to rank three responses per prompt from an LLM on the dimension of writing clarity (readability). Again, the left pane shows the instructions given to the reviewer by the job requester. In the center, the prompt is at the top of the page, and the three pre-generated responses are the main body for ease of use. On the right side of the UI, the human reviewer will rank them in order of most to least clear writing.
Customers wanting to generate this type of preference dataset include application builders interested in building human-like chatbots, and therefore want to customize the instructions for their own use. The length of the prompt, number of responses, and ranking dimension can all be customized. For example, you may want to rank five responses in order of most to least factually accurate, biased, or toxic, or even rank and classify multiple dimensions simultaneously. These customizations are supported in Ground Truth Plus.
Multi-modal models
In this section, we discuss image and video captioning for training multi-modal models such as text-to-image and text-to-video models, as well as customizations you may want to make for your particular use case.
Image captioning
The following screenshot shows a labeling UI for image captioning. You can request a project with image captioning to gather data to train a text-to-image model or an image-to-text model.
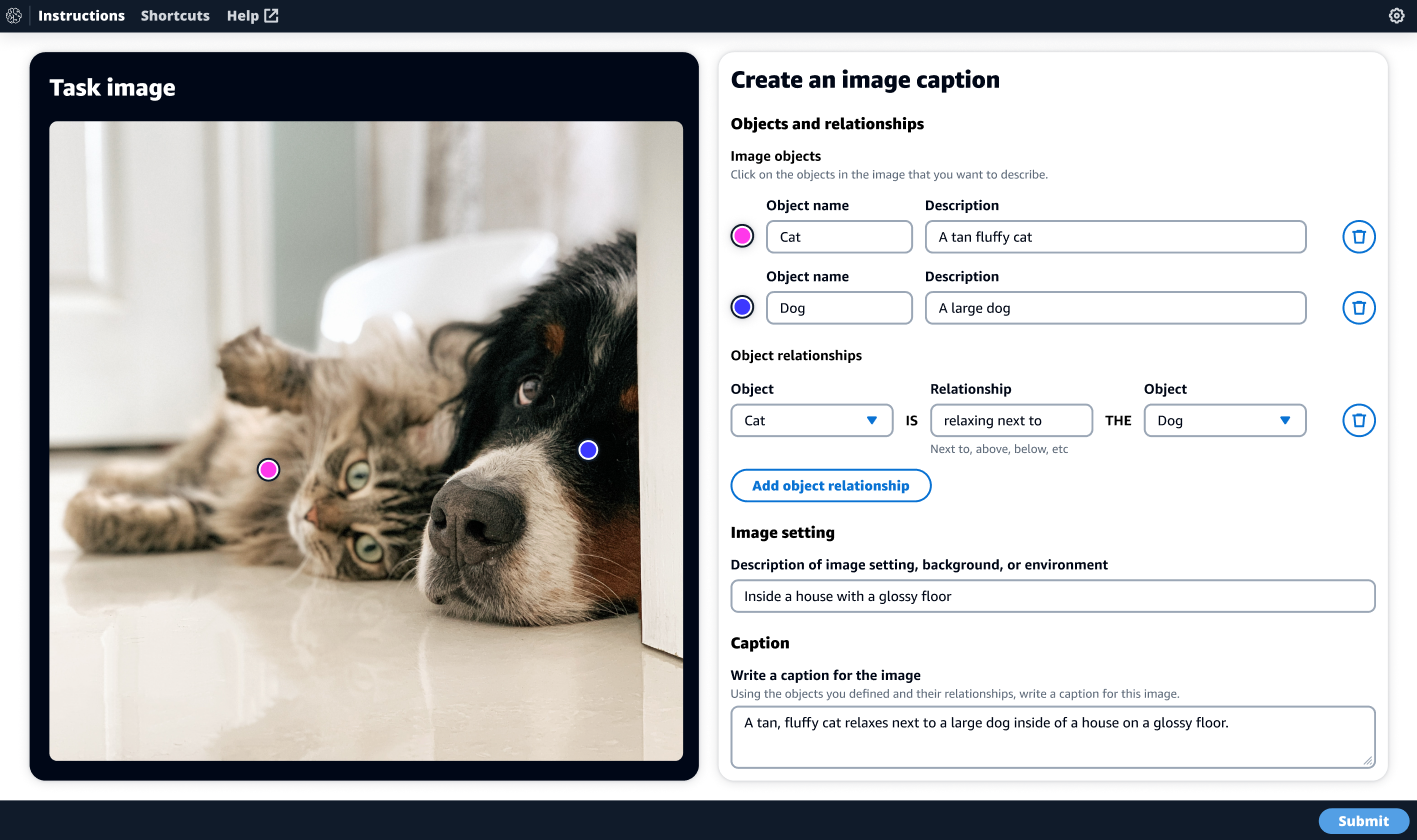
In this case, we have requested to train a text-to-image model and have set specific requirements on the caption in terms of length and detail. The UI is designed to walk the human annotators through the cognitive process of generating rich captions by providing a mental framework through assistive and descriptive tools. We have found that providing this mental framework for annotators results in more descriptive and accurate captions than simply providing an editable text box alone.
The first step in the framework is for the human annotator to identify key objects in the image. When the annotator chooses an object in the image, a color-coded dot appears on the object. In this case, the annotator has chosen both the dog and the cat, creating two editable fields on the right side of the UI wherein the annotator will enter the names of the objects—cat and dog—along with a detailed description of each object. Next, the annotator is guided to identify all the relationships between all the objects in the image. In this case, the cat is relaxing next to the dog. Next, the annotator is asked to identify specific attributes about the image, such as the setting, background, or environment. Finally, in the caption input text box, the annotator is instructed to combine all of what they wrote in the objects, relationships, and image setting fields into a complete single descriptive caption of the image.
Optionally, you can configure this image caption to be passed through a human-based quality check loop with specific instructions to ensure that the caption meets the requirements. If there is an issue identified, such as a missing key object, that caption can be sent back for a human to correct the issue before exporting as part of the training dataset.
Video captioning
The following screenshot shows a video captioning UI to generate rich video captions with timestamp tags. You can request a video caption project to gather data to build text-to-video or video-to-text models.

In this labeling UI, we have built a similar mental framework to ensure high-quality captions are written. The human annotator can control the video on the left side and create descriptions and timestamps for each activity shown in the video on the right side with the UI elements. Similar to the image captioning UI, there is also a place for the annotator to write a detailed description of the video setting, background, and environment. Finally, the annotator is instructed to combine all the elements into a coherent video caption.
Similar to the image caption case, the video captions may optionally flow through a human-based quality control workflow to determine if your requirements are met. If there is an issue with the video captions, it will be sent for rework by the human annotator workforce.
Conclusion
Ground Truth Plus can help you prepare high-quality datasets to fine-tune foundation models for generative AI tasks, from answering questions to generating images and videos. It also allows skilled human workforces to review model outputs to ensure that they are aligned with human preferences. Additionally, it enables application builders to customize models using their industry or company data to ensure their application represents their preferred voice and style. These are the first of many innovations in Ground Truth Plus, and more are in development. Stay tuned for future posts.
Interested in starting a project to build or improve your generative AI models and applications? Get started with Ground Truth Plus by connecting with our team today.
About the authors
 Jesse Manders is a Senior Product Manager in the AWS AI/ML human in the loop services team. He works at the intersection of AI and human interaction with the goal of creating and improving AI/ML products and services to meet our needs. Previously, Jesse held leadership roles in engineering at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the University of Florida, and an MBA from the University of California, Berkeley, Haas School of Business.
Jesse Manders is a Senior Product Manager in the AWS AI/ML human in the loop services team. He works at the intersection of AI and human interaction with the goal of creating and improving AI/ML products and services to meet our needs. Previously, Jesse held leadership roles in engineering at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the University of Florida, and an MBA from the University of California, Berkeley, Haas School of Business.
 Romi Datta is a Senior Manager of Product Management in the Amazon SageMaker team responsible for Human in the Loop services. He has been in AWS for over 4 years, holding several product management leadership roles in SageMaker, S3 and IoT. Prior to AWS he worked in various product management, engineering and operational leadership roles at IBM, Texas Instruments and Nvidia. He has an M.S. and Ph.D. in Electrical and Computer Engineering from the University of Texas at Austin, and an MBA from the University of Chicago Booth School of Business.
Romi Datta is a Senior Manager of Product Management in the Amazon SageMaker team responsible for Human in the Loop services. He has been in AWS for over 4 years, holding several product management leadership roles in SageMaker, S3 and IoT. Prior to AWS he worked in various product management, engineering and operational leadership roles at IBM, Texas Instruments and Nvidia. He has an M.S. and Ph.D. in Electrical and Computer Engineering from the University of Texas at Austin, and an MBA from the University of Chicago Booth School of Business.
 Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers.
Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers.
 Alex Williams is an applied scientist in the human-in-the-loop science team at AWS AI where he conducts interactive systems research at the intersection of human-computer interaction (HCI) and machine learning. Before joining Amazon, he was a professor in the Department of Electrical Engineering and Computer Science at the University of Tennessee where he co-directed the People, Agents, Interactions, and Systems (PAIRS) research laboratory. He has also held research positions at Microsoft Research, Mozilla Research, and the University of Oxford. He regularly publishes his work at premier publication venues for HCI, such as CHI, CSCW, and UIST. He holds a PhD from the University of Waterloo.
Alex Williams is an applied scientist in the human-in-the-loop science team at AWS AI where he conducts interactive systems research at the intersection of human-computer interaction (HCI) and machine learning. Before joining Amazon, he was a professor in the Department of Electrical Engineering and Computer Science at the University of Tennessee where he co-directed the People, Agents, Interactions, and Systems (PAIRS) research laboratory. He has also held research positions at Microsoft Research, Mozilla Research, and the University of Oxford. He regularly publishes his work at premier publication venues for HCI, such as CHI, CSCW, and UIST. He holds a PhD from the University of Waterloo.
 Sarah Gao is a Software Development Manager in Amazon SageMaker Human In the Loop (HIL) responsible for building the ML based labeling platform. Sarah has been in AWS for over 4 years, holding several software management leadership roles in EC2 security and SageMaker. Prior to AWS she worked in various engineering management roles at Oracle and Sun Microsystem.
Sarah Gao is a Software Development Manager in Amazon SageMaker Human In the Loop (HIL) responsible for building the ML based labeling platform. Sarah has been in AWS for over 4 years, holding several software management leadership roles in EC2 security and SageMaker. Prior to AWS she worked in various engineering management roles at Oracle and Sun Microsystem.
 Erran Li is the applied science manager at human-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
Erran Li is the applied science manager at human-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoAiStream. Web3 Data Intelligence. Knowledge Amplified. Access Here.
- Minting the Future w Adryenn Ashley. Access Here.
- Buy and Sell Shares in PRE-IPO Companies with PREIPO®. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/high-quality-human-feedback-for-your-generative-ai-applications-from-amazon-sagemaker-ground-truth-plus/

