Il s'agit d'un article invité co-écrit avec l'équipe de direction d'Iambic Therapeutics.
Thérapeutique Iambique est une startup de découverte de médicaments dont la mission est de créer des technologies innovantes basées sur l'IA pour fournir plus rapidement de meilleurs médicaments aux patients atteints de cancer.
Nos outils avancés d’intelligence artificielle (IA) générative et prédictive nous permettent de rechercher plus rapidement et plus efficacement le vaste espace des molécules médicamenteuses possibles. Nos technologies sont polyvalentes et applicables dans tous les domaines thérapeutiques, classes de protéines et mécanismes d’action. Au-delà de la création d'outils d'IA différenciés, nous avons créé une plate-forme intégrée qui fusionne des logiciels d'IA, des données basées sur le cloud, une infrastructure de calcul évolutive et des capacités de chimie et de biologie à haut débit. La plateforme permet à la fois notre IA – en fournissant des données pour affiner nos modèles – et est rendue possible par elle, en capitalisant sur les opportunités de prise de décision et de traitement des données automatisés.
Nous mesurons le succès par notre capacité à produire des candidats cliniques de qualité supérieure pour répondre aux besoins urgents des patients, à une vitesse sans précédent : nous sommes passés du lancement du programme aux candidats cliniques en seulement 24 mois, bien plus rapidement que nos concurrents.
Dans cet article, nous nous concentrons sur la façon dont nous avons utilisé Karpenter on Service Amazon Elastic Kubernetes (Amazon EKS) pour faire évoluer la formation et l'inférence de l'IA, qui sont des éléments essentiels de la plateforme de découverte Iambic.
La nécessité d’une formation et d’une inférence évolutives en IA
Chaque semaine, Iambic effectue des inférences d'IA sur des dizaines de modèles et des millions de molécules, répondant à deux cas d'utilisation principaux :
- Les chimistes médicinaux et autres scientifiques utilisent notre application Web, Insight, pour explorer l'espace chimique, accéder et interpréter des données expérimentales et prédire les propriétés de molécules nouvellement conçues. Tout ce travail est effectué de manière interactive en temps réel, créant un besoin d'inférence avec une faible latence et un débit moyen.
- Dans le même temps, nos modèles d’IA générative conçoivent automatiquement des molécules ciblant l’amélioration de nombreuses propriétés, recherchant des millions de candidats et nécessitant un débit énorme et une latence moyenne.
Guidée par les technologies de l’IA et des chasseurs de médicaments experts, notre plateforme expérimentale génère des milliers de molécules uniques chaque semaine, et chacune est soumise à de multiples tests biologiques. Les points de données générés sont automatiquement traités et utilisés chaque semaine pour affiner nos modèles d'IA. Au départ, le réglage fin de notre modèle prenait des heures de temps CPU, il était donc impératif de disposer d'un cadre permettant de mettre à l'échelle le réglage fin du modèle sur les GPU.
Nos modèles d'apprentissage profond ont des exigences non triviales : ils mesurent des gigaoctets, sont nombreux et hétérogènes, et nécessitent des GPU pour une inférence et un réglage rapides. En ce qui concerne l'infrastructure cloud, nous avions besoin d'un système qui nous permette d'accéder aux GPU, d'évoluer rapidement pour gérer des charges de travail pointues et hétérogènes et d'exécuter de grandes images Docker.
Nous voulions créer un système évolutif pour prendre en charge la formation et l'inférence de l'IA. Nous utilisons Amazon EKS et recherchions la meilleure solution pour mettre à l'échelle automatiquement nos nœuds de travail. Nous avons choisi Karpenter pour la mise à l'échelle automatique des nœuds Kubernetes pour plusieurs raisons :
- Facilité d'intégration avec Kubernetes, en utilisant la sémantique Kubernetes pour définir les exigences des nœuds et les spécifications des pods pour la mise à l'échelle
- Évolutivité des nœuds à faible latence
- Facilité d'intégration avec notre infrastructure en tant qu'outil de code (Terraform)
Les fournisseurs de nœuds prennent en charge une intégration sans effort avec Amazon EKS et d'autres ressources AWS telles que Cloud de calcul élastique Amazon (Amazon EC2) et Boutique de blocs élastiques Amazon tomes. La sémantique Kubernetes utilisée par les fournisseurs prend en charge la planification dirigée à l'aide de constructions Kubernetes telles que les teintes ou les tolérances et les spécifications d'affinité ou d'anti-affinité ; ils facilitent également le contrôle du nombre et des types d'instances GPU pouvant être planifiées par Karpenter.
Vue d'ensemble de la solution
Dans cette section, nous présentons une architecture générique similaire à celle que nous utilisons pour nos propres charges de travail, qui permet un déploiement élastique de modèles utilisant une mise à l'échelle automatique efficace basée sur des métriques personnalisées.
Le diagramme suivant illustre l'architecture de la solution.

L'architecture déploie un prestation simple dans un pod Kubernetes au sein d'un Pôle EKS. Il peut s'agir d'une inférence de modèle, d'une simulation de données ou de tout autre service conteneurisé, accessible par requête HTTP. Le service est exposé derrière un proxy inverse utilisant Traefik. Le proxy inverse collecte des métriques sur les appels au service et les expose via une API de métriques standard à Prométhée. L'autoscaler piloté par les événements Kubernetes (KÉDA) est configuré pour adapter automatiquement le nombre de pods de service, en fonction des métriques personnalisées disponibles dans Prometheus. Ici, nous utilisons le nombre de requêtes par seconde comme mesure personnalisée. La même approche architecturale s'applique si vous choisissez une métrique différente pour votre charge de travail.
Karpenter surveille tous les pods en attente qui ne peuvent pas s'exécuter en raison d'un manque de ressources suffisantes dans le cluster. Si de tels pods sont détectés, Karpenter ajoute plus de nœuds au cluster pour fournir les ressources nécessaires. À l'inverse, s'il y a plus de nœuds dans le cluster que ce qui est nécessaire aux pods planifiés, Karpenter supprime certains nœuds de travail et les pods sont replanifiés, les consolidant sur moins d'instances. Le nombre de requêtes HTTP par seconde et le nombre de nœuds peuvent être visualisés à l'aide d'un grafana tableau de bord. Pour démontrer la mise à l'échelle automatique, nous exécutons un ou plusieurs pods simples générateurs de charge, qui envoient des requêtes HTTP au service en utilisant boucle.
Déploiement de la solution
Dans le procédure pas à pas, nous utilisons AWSCloud9 comme environnement pour déployer l’architecture. Cela permet d'effectuer toutes les étapes à partir d'un navigateur Web. Vous pouvez également déployer la solution à partir d'un ordinateur local ou d'une instance EC2.
Pour simplifier le déploiement et améliorer la reproductibilité, nous suivons les principes du faire-cadre et la structure du modèle dépendant du docker. Nous clonons le aws-do-eks projet et, en utilisant Docker, nous construisons une image de conteneur équipée des outils et des scripts nécessaires. Dans le conteneur, nous parcourons toutes les étapes de la procédure pas à pas de bout en bout, de la création d'un cluster EKS avec Karpenter à la mise à l'échelle. Instances EC2.
Pour l'exemple de cet article, nous utilisons ce qui suit Manifeste du cluster EKS:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-karpenter
version: '1.28'
region: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- name: aws-ebs-csi-driver
version: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- name: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueCe manifeste définit un cluster nommé do-eks-yaml-karpenter avec le pilote EBS CSI installé en tant que module complémentaire. Un groupe de nœuds gérés avec deux c5.xlarge Les nœuds sont inclus pour exécuter les pods système nécessaires au cluster. Les nœuds de travail sont hébergés dans des sous-réseaux privés et le point de terminaison de l'API du cluster est public par défaut.
Vous pouvez également utiliser un cluster EKS existant au lieu d'en créer un. Nous déployons Karpenter en suivant les Des instructions dans la documentation Karpenter, ou en exécutant la commande suivante scénario, qui automatise les instructions de déploiement.
Le code suivant montre la configuration Karpenter que nous utilisons dans cet exemple :
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
purpose: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
role: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueNous définissons un Karpenter NodePool par défaut avec les exigences suivantes :
- Karpenter peut lancer des instances à partir des deux
spotainsi que leon-demandpools de capacité - Les instances doivent provenir du «
c" (calcul optimisé), "m" (usage général), "r" (mémoire optimisée), ou "g" et "p" Familles informatiques (accélérées par GPU) - La génération d'instances doit être supérieure à 2 ; Par exemple,
g3est acceptable, maisg2n'est pas
Le NodePool par défaut définit également les politiques de perturbation. Les nœuds sous-utilisés seront supprimés afin que les pods puissent être consolidés pour s'exécuter sur des nœuds moins nombreux ou plus petits. Alternativement, nous pouvons configurer les nœuds vides pour qu'ils soient supprimés après la période de temps spécifiée. Le expireAfter Le paramètre spécifie la durée de vie maximale de tout nœud, avant qu'il ne soit arrêté et remplacé si nécessaire. Cela permet de réduire les vulnérabilités de sécurité et d'éviter les problèmes typiques des nœuds avec une longue disponibilité, tels que la fragmentation des fichiers ou les fuites de mémoire.
Par défaut, Karpenter provisionne les nœuds avec un petit volume racine, ce qui peut s'avérer insuffisant pour exécuter des charges de travail d'IA ou d'apprentissage automatique (ML). Certaines images de conteneurs d'apprentissage en profondeur peuvent atteindre des dizaines de Go, et nous devons nous assurer qu'il y a suffisamment d'espace de stockage sur les nœuds pour exécuter des pods utilisant ces images. Pour ce faire, nous définissons EC2NodeClass comprenant blockDeviceMappings, comme indiqué dans le code précédent.
Karpenter est responsable de la mise à l'échelle automatique au niveau du cluster. Pour configurer la mise à l'échelle automatique au niveau du pod, nous utilisons KEDA pour définir une ressource personnalisée appelée ScaledObject, comme indiqué dans le code suivant :
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
name: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.local:80
metricName: http_requests_total
threshold: '1'
query: rate(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])Le manifeste précédent définit un ScaledObject nommé keda-prometheus-hpa, qui est responsable de la mise à l'échelle du déploiement de php-apache et maintient toujours au moins une réplique en cours d'exécution. Il met à l'échelle les pods de ce déploiement en fonction de la métrique http_requests_total disponible dans Prometheus obtenu par la requête spécifiée et vise à faire évoluer les pods afin que chaque pod ne réponde pas à plus d'une requête par seconde. Il réduit les réplicas une fois que la charge de la requête est restée inférieure au seuil pendant plus de 30 secondes.
Les spécification de déploiement pour notre exemple, le service contient les éléments suivants demandes et limites de ressources:
resources:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1Avec cette configuration, chacun des pods de service utilisera exactement un GPU NVIDIA. Lorsque de nouveaux pods sont créés, ils seront à l'état En attente jusqu'à ce qu'un GPU soit disponible. Karpenter ajoute des nœuds GPU au cluster selon les besoins pour accueillir les pods en attente.
A nacelle génératrice de charge envoie des requêtes HTTP au service avec une fréquence prédéfinie. Nous augmentons le nombre de requêtes en augmentant le nombre de répliques dans le déploiement du générateur de charge.
Un cycle de mise à l'échelle complet avec consolidation des nœuds basée sur l'utilisation est visualisé dans un tableau de bord Grafana. Le tableau de bord suivant affiche le nombre de nœuds dans le cluster par type d'instance (en haut), le nombre de requêtes par seconde (en bas à gauche) et le nombre de pods (en bas à droite).
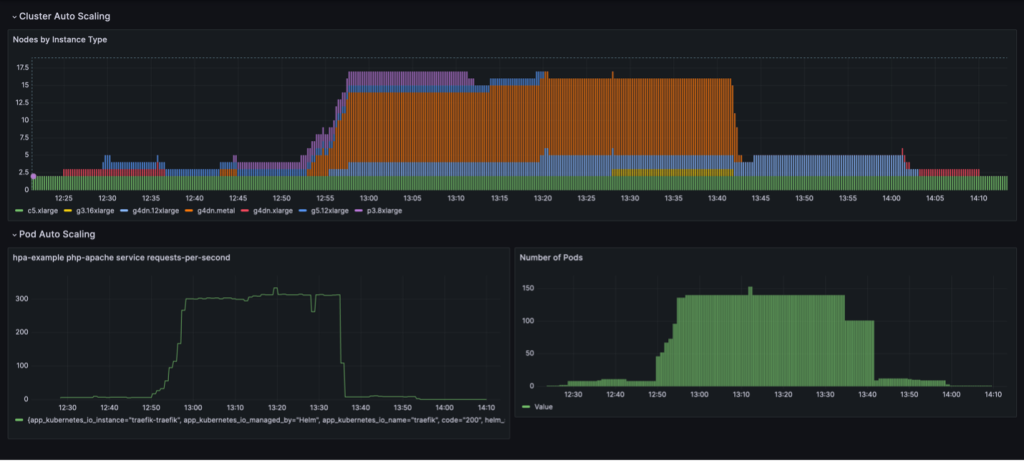
Nous commençons avec uniquement les deux instances de processeur c5.xlarge avec lesquelles le cluster a été créé. Ensuite, nous déployons une instance de service, qui nécessite un seul GPU. Karpenter ajoute une instance g4dn.xlarge pour répondre à ce besoin. Nous déployons ensuite le générateur de charge, ce qui amène KEDA à ajouter plus de pods de service et Karpenter ajoute plus d'instances GPU. Après optimisation, l'état s'installe sur une instance p3.8xlarge avec 8 GPU et une instance g5.12xlarge avec 4 GPU.
Lorsque nous étendons le déploiement générateur de charge à 40 réplicas, KEDA crée des pods de service supplémentaires pour maintenir la charge de requêtes requise par pod. Karpenter ajoute les nœuds g4dn.metal et g4dn.12xlarge au cluster pour fournir les GPU nécessaires pour les pods supplémentaires. À l'état mis à l'échelle, le cluster contient 16 nœuds GPU et traite environ 300 requêtes par seconde. Lorsque nous réduisons le générateur de charge à 1 réplique, le processus inverse a lieu. Après la période de refroidissement, KEDA réduit le nombre de modules de service. Ensuite, à mesure que moins de pods s'exécutent, Karpenter supprime les nœuds sous-utilisés du cluster et les pods de service sont consolidés pour s'exécuter sur moins de nœuds. Lorsque le pod du générateur de charge est supprimé, un seul pod de service sur une seule instance g4dn.xlarge avec 1 GPU reste en cours d'exécution. Lorsque nous supprimons également le pod de service, le cluster reste dans son état initial avec seulement deux nœuds CPU.
Nous pouvons observer ce comportement lorsque le NodePool a le réglage consolidationPolicy: WhenUnderutilized.
Avec ce paramètre, Karpenter configure dynamiquement le cluster avec le moins de nœuds possible, tout en fournissant suffisamment de ressources pour que tous les pods puissent fonctionner et en minimisant également les coûts.
Le comportement de mise à l'échelle présenté dans le tableau de bord suivant est observé lorsque le NodePool la politique de consolidation est fixée à WhenEmpty, along with consolidateAfter: 30s.
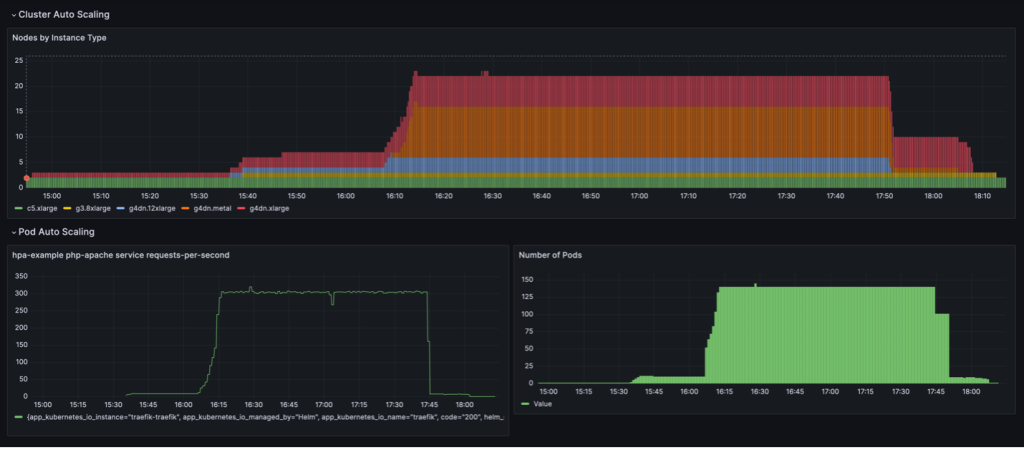
Dans ce scénario, les nœuds sont arrêtés uniquement lorsqu'aucun pod n'est exécuté sur eux après la période de réflexion. La courbe de mise à l’échelle semble lisse par rapport à la politique de consolidation basée sur l’utilisation ; cependant, on peut constater que davantage de nœuds sont utilisés dans l’état mis à l’échelle (22 contre 16).
Dans l'ensemble, la combinaison de la mise à l'échelle automatique des pods et des clusters garantit que le cluster évolue de manière dynamique avec la charge de travail, en allouant les ressources en cas de besoin et en les supprimant lorsqu'elles ne sont pas utilisées, maximisant ainsi l'utilisation et minimisant les coûts.
Résultats
Iambic a utilisé cette architecture pour permettre une utilisation efficace des GPU sur AWS et migrer les charges de travail du CPU vers le GPU. En utilisant des instances alimentées par GPU EC2, Amazon EKS et Karpenter, nous avons pu permettre une inférence plus rapide pour nos modèles basés sur la physique et des temps d'itération d'expérimentation plus rapides pour les scientifiques appliqués qui s'appuient sur la formation en tant que service.
Le tableau suivant résume certaines des mesures temporelles de cette migration.
| Tâche | CPU | GPU |
| Inférence à l'aide de modèles de diffusion pour les modèles ML basés sur la physique | en 3,600 secondes |
en 100 secondes (en raison du regroupement inhérent aux GPU) |
| Formation de modèle ML en tant que service | 180 minutes | 4 minutes |
Le tableau suivant résume certaines de nos mesures de temps et de coûts.
| Tâche | Performance/Coût | |
| CPU | GPU | |
| Formation sur le modèle ML |
240 minutes en moyenne 0.70 $ par tâche de formation |
20 minutes en moyenne 0.38 $ par tâche de formation |
Résumé
Dans cet article, nous avons montré comment Iambic a utilisé Karpenter et KEDA pour faire évoluer notre infrastructure Amazon EKS afin de répondre aux exigences de latence de nos charges de travail d'inférence et de formation d'IA. Karpenter et KEDA sont de puissants outils open source qui permettent de mettre automatiquement à l'échelle les clusters EKS et les charges de travail qui s'y exécutent. Cela permet d'optimiser les coûts de calcul tout en répondant aux exigences de performances. Vous pouvez consulter le code et déployer la même architecture dans votre propre environnement en suivant la procédure complète de ce document. GitHub repo.
À propos des auteurs
 Matthieu Welborn est le directeur de l'apprentissage automatique chez Iambic Therapeutics. Lui et son équipe exploitent l’IA pour accélérer l’identification et le développement de nouveaux traitements, permettant ainsi d’apporter plus rapidement aux patients des médicaments qui sauvent des vies.
Matthieu Welborn est le directeur de l'apprentissage automatique chez Iambic Therapeutics. Lui et son équipe exploitent l’IA pour accélérer l’identification et le développement de nouveaux traitements, permettant ainsi d’apporter plus rapidement aux patients des médicaments qui sauvent des vies.
 Paul Whittemore est ingénieur principal chez Iambic Therapeutics. Il soutient la fourniture de l'infrastructure pour la plateforme de découverte de médicaments basée sur l'IA Iambic.
Paul Whittemore est ingénieur principal chez Iambic Therapeutics. Il soutient la fourniture de l'infrastructure pour la plateforme de découverte de médicaments basée sur l'IA Iambic.
 Alex Yankoulski est un architecte de solutions principal, ML/AI Frameworks, qui s'efforce d'aider les clients à orchestrer leurs charges de travail d'IA à l'aide de conteneurs et d'une infrastructure informatique accélérée sur AWS.
Alex Yankoulski est un architecte de solutions principal, ML/AI Frameworks, qui s'efforce d'aider les clients à orchestrer leurs charges de travail d'IA à l'aide de conteneurs et d'une infrastructure informatique accélérée sur AWS.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/scale-ai-training-and-inference-for-drug-discovery-through-amazon-eks-and-karpenter/

