esittely
Työskentelet konsulttiyrityksessä datatieteilijänä. Projektissa, johon sinut tällä hetkellä määrättiin, on tietoja opiskelijoista, jotka ovat äskettäin suorittaneet taloustieteen kursseja. Kursseja toteuttava rahoitusyhtiö haluaa ymmärtää, onko olemassa yhteisiä tekijöitä, jotka vaikuttavat opiskelijoihin ostamaan samoja kursseja tai ostamaan erilaisia kursseja. Ymmärtämällä nämä tekijät yritys voi luoda opiskelijaprofiilin, luokitella jokaisen opiskelijan profiilin mukaan ja suositella kurssiluetteloa.
Kun tarkastelet eri opiskelijaryhmien tietoja, olet törmännyt kolmeen pisteen sijoitukseen, kuten alla olevissa kohdissa 1, 2 ja 3:
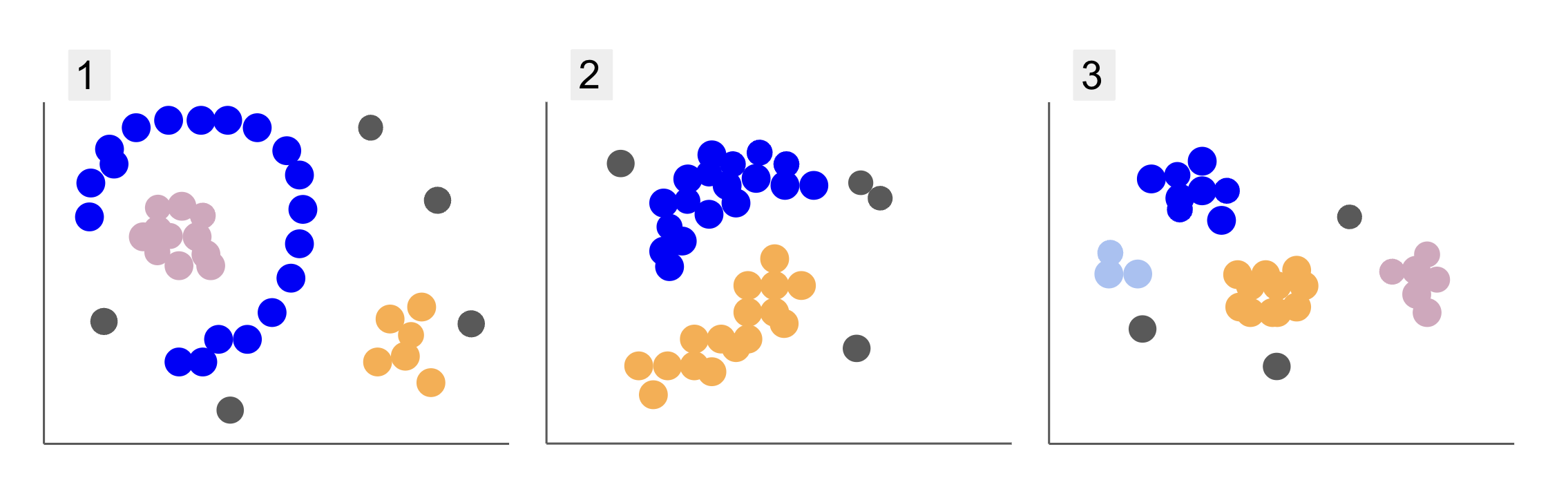
Huomaa, että kaaviossa 1 on purppuraisia pisteitä, jotka on järjestetty puoliympyrään, jossa on massa vaaleanpunaisia pisteitä tämän ympyrän sisällä, hieman oransseja pisteitä tuon puoliympyrän ulkopuolella ja viisi harmaata pistettä, jotka ovat kaukana kaikista muista.
Kaaviossa 2 on pyöreä massa violetteja pisteitä, toinen oransseja pisteitä ja myös neljä harmaata pistettä, jotka ovat kaukana kaikista muista.
Ja kuvassa 3 voimme nähdä neljä pisteen keskittymää, violetti, sininen, oranssi, vaaleanpunainen ja kolme kauempana olevaa harmaata pistettä.
Jos nyt valitsisit mallin, joka voisi ymmärtää uusia opiskelijatietoja ja määrittää samanlaisia ryhmiä, onko olemassa klusterointialgoritmia, joka voisi antaa mielenkiintoisia tuloksia sellaisille tiedoille?
Kun kuvailimme juonia, mainitsimme termit kuten pisteiden massa ja pisteiden keskittyminen, mikä osoittaa, että kaikissa kaavioissa on alueita, joilla on suurempi tiheys. Viitattiin myös pyöreä ja puolipyöreä muotoja, joita on vaikea tunnistaa piirtämällä suora tai pelkästään lähimpiä pisteitä tutkimalla. Lisäksi on joitain kaukaisia kohtia, jotka todennäköisesti poikkeavat päätietojen jakelusta, mikä tuo lisää haasteita tai melu ryhmiä määritettäessä.
Tiheyteen perustuva algoritmi, joka voi suodattaa melun, kuten DBSCAN (Densy-Bhinnoitteluun Spatiaalinen Ckiihkeä Asovellukset Noise) on vahva valinta tilanteisiin, joissa on tiheämpiä alueita, pyöristettyjä muotoja ja melua.
Tietoja DBSCANista
DBSCAN on yksi tutkimuksen eniten siteeratuista algoritmeista, sen ensimmäinen julkaisu ilmestyi vuonna 1996, tämä on alkuperäinen DBSCAN-paperi. Artikkelissa tutkijat osoittavat, kuinka algoritmi pystyy tunnistamaan epälineaarisia spatiaalisia klustereita ja käsittelemään dataa, jolla on suurempi ulottuvuus.
DBSCANin pääajatuksena on, että on olemassa vähimmäismäärä pisteitä, jotka ovat tietyllä etäisyydellä tai säde "keskisimmästä" klusteripisteestä, nimeltään ydinkohta. Tämän säteen sisällä olevat pisteet ovat naapuruston pisteitä, ja pisteet tämän naapuruston reunalla ovat rajapisteitä or rajapisteitä. Sädettä tai lähietäisyyttä kutsutaan epsilonin naapurustossa, ε-naapurustossa tai vain ε (kreikkalaisen kirjaimen epsilon symboli).
Lisäksi, jos on pisteitä, jotka eivät ole ydinpisteitä tai rajapisteitä, koska ne ylittävät tiettyyn klusteriin kuulumisen säteen, eikä niissä ole myöskään vähimmäismäärää pisteitä ydinpisteeksi, ne huomioidaan. melupisteet.
Tämä tarkoittaa, että meillä on kolme erilaista pistettä, nimittäin ydin, reunus ja melu. Lisäksi on tärkeää huomata, että pääidea perustuu pohjimmiltaan säteeseen tai etäisyyteen, mikä tekee DBSCANista – kuten useimmat klusterointimallit – riippuvaisia tästä etäisyysmetriikasta. Tämä mittari voisi olla Euklidinen, Manhattan, Mahalanobis ja monia muita. Siksi on ratkaisevan tärkeää valita sopiva etäisyysmittari, joka ottaa huomioon datan kontekstin. Jos esimerkiksi käytät GPS:n ajoetäisyystietoja, saattaa olla mielenkiintoista käyttää mittaria, joka ottaa huomioon katujen asettelun, kuten Manhattanin etäisyyden.

Huomautus: Koska DBSCAN kartoittaa kohinaa sisältävät pisteet, sitä voidaan käyttää myös outlier-ilmaisualgoritmina. Jos esimerkiksi yrität määrittää, mitkä pankkitapahtumat voivat olla vilpillisiä ja vilpillisten tapahtumien määrä on pieni, DBSCAN voi olla ratkaisu näiden asioiden tunnistamiseen.
Ydinpisteen löytämiseksi DBSCAN valitsee ensin pisteen satunnaisesti, kartoittaa kaikki pisteet sen ε-naapurustossa ja vertaa valitun pisteen naapurien määrää pisteiden minimimäärään. Jos valitulla pisteellä on yhtä monta tai useampia naapureita kuin vähimmäismäärä pisteitä, se merkitään ydinpisteeksi. Tämä ydinpiste ja sen lähipisteet muodostavat ensimmäisen klusterin.
Algoritmi tutkii sitten ensimmäisen klusterin jokaisen pisteen ja katsoo, onko siinä yhtä monta tai enemmän naapuripisteitä kuin ε:n pisteiden vähimmäismäärä. Jos näin on, myös nämä naapuripisteet lisätään ensimmäiseen klusteriin. Tämä prosessi jatkuu, kunnes ensimmäisen klusterin pisteillä on vähemmän naapureita kuin pisteiden vähimmäismäärä ε:n sisällä. Kun näin tapahtuu, algoritmi lopettaa pisteiden lisäämisen kyseiseen klusteriin, tunnistaa toisen ydinpisteen kyseisen klusterin ulkopuolella ja luo uuden klusterin tälle uudelle ydinpisteelle.
DBSCAN toistaa sitten ensimmäisen klusterin prosessin, jossa etsitään kaikki pisteet, jotka on liitetty toisen klusterin uuteen ydinpisteeseen, kunnes kyseiseen klusteriin ei ole enää lisättäviä pisteitä. Sitten se kohtaa toisen ydinpisteen ja luo kolmannen klusterin, tai se toistaa kaikki kohdat, joita se ei ole aiemmin katsonut. Jos nämä pisteet ovat ε etäisyydellä klusterista, ne lisätään kyseiseen klusteriin, jolloin niistä tulee rajapisteitä. Jos ne eivät ole, niitä pidetään melupisteinä.
Neuvo: DBSCANin ideaan liittyy monia sääntöjä ja matemaattisia esityksiä. Jos haluat kaivaa syvemmälle, voit katsoa alkuperäistä paperia, joka on linkitetty yllä.
On mielenkiintoista tietää, miten DBSCAN-algoritmi toimii, vaikka onneksi algoritmia ei tarvitse koodata, kun Pythonin Scikit-Learn-kirjastossa on jo toteutus.
Katsotaan kuinka se toimii käytännössä!
Tietojen tuominen klusterointia varten
Nähdäksemme, miten DBSCAN toimii käytännössä, muutamme projekteja hieman ja käytämme pientä asiakastietojoukkoa, jossa on 200 asiakkaan genre, ikä, vuositulot ja kulutuspisteet.
Kulutuspisteet vaihtelevat 0–100 ja edustaa, kuinka usein henkilö kuluttaa rahaa ostoskeskuksessa asteikolla 1–100. Toisin sanoen, jos asiakkaan arvosana on 0, hän ei koskaan kuluta rahaa, ja jos pistemäärä on 100, he kuluttavat eniten.
Huomautus: Voit ladata tietojoukon tätä.
Kun olet ladannut tietojoukon, näet, että se on CSV-tiedosto (comma-separated values). shopping-data.csv, lataamme sen DataFrameen Pandasin avulla ja tallennamme sen customer_data muuttuja:
import pandas as pd path_to_file = '../../datasets/dbscan/dbscan-with-python-and-scikit-learn-shopping-data.csv'
customer_data = pd.read_csv(path_to_file)
Voit tarkastella tietojemme viittä ensimmäistä riviä suorittamalla customer_data.head():
Tämä johtaa:
CustomerID Genre Age Annual Income (k$) Spending Score (1-100)
0 1 Male 19 15 39
1 2 Male 21 15 81
2 3 Female 20 16 6
3 4 Female 23 16 77
4 5 Female 31 17 40
Tietoja tutkimalla voimme nähdä asiakastunnukset, genren, iän, tulot k$ ja kulutuspisteet. Muista, että joitain tai kaikkia näistä muuttujista käytetään mallissa. Esimerkiksi jos käyttäisimme Age ja Spending Score (1-100) DBSCANin muuttujina, joka käyttää etäisyysmittaria, on tärkeää saattaa ne yhteiselle mittakaavalle vääristymien välttämiseksi, koska Age mitataan vuosina ja Spending Score (1-100) on rajoitettu alue 0 - 100. Tämä tarkoittaa, että suoritamme jonkinlaisen datan skaalaus.
Voimme myös tarkistaa, tarvitsevatko tiedot lisää esikäsittelyä skaalauksen lisäksi tarkistamalla, onko datatyyppi johdonmukainen ja tarkistamalla, onko puuttuvia arvoja, jotka on käsiteltävä suorittamalla Panda's info() menetelmä:
customer_data.info()
Tämä näyttää:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 CustomerID 200 non-null int64 1 Genre 200 non-null object 2 Age 200 non-null int64 3 Annual Income (k$) 200 non-null int64 4 Spending Score (1-100) 200 non-null int64 dtypes: int64(4), object(1)
memory usage: 7.9+ KB
Voimme havaita, että puuttuvia arvoja ei ole, koska jokaiselle asiakasominaisuudesta on 200 ei-null-merkintää. Voimme myös nähdä, että vain genre-sarakkeessa on tekstisisältöä, koska se on kategorinen muuttuja, joka näytetään object, ja kaikki muut ominaisuudet ovat numeerisia, tyyppiä int64. Tietotyyppien johdonmukaisuuden ja nolla-arvojen puuttumisen kannalta tietomme ovat siis valmiita jatkoanalyysiin.
Voimme jatkaa tietojen visualisoimista ja määrittää, mitä ominaisuuksia olisi mielenkiintoista käyttää DBSCANissa. Kun olet valinnut nämä ominaisuudet, voimme skaalata niitä.
Tämä asiakastietojoukko on sama kuin se, jota käytetään lopullisessa hierarkkisen klusteroinnin oppaassamme. Saat lisätietoja näistä tiedoista, niiden tutkimisesta ja etäisyysmittareista katsomalla Lopullinen opas hierarkkiseen klusterointiin Pythonilla ja Scikit-Learnillä!
Tietojen visualisointi
Käyttämällä Seabornia pairplot(), voimme piirtää hajontakaavion kullekin ominaisuuksien yhdistelmälle. Siitä asti kun CustomerID on vain tunniste, ei ominaisuus, poistamme sen drop() ennen piirtämistä:
import seaborn as sns customer_data = customer_data.drop('CustomerID', axis=1) sns.pairplot(customer_data);
Tämä tuottaa:
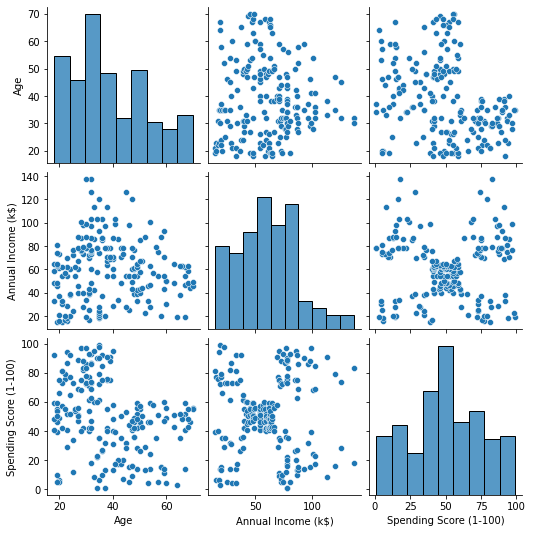
Kun tarkastellaan ominaisuuksien yhdistelmää, jonka on tuottanut pairplot, kaavio Annual Income (k$) with Spending Score (1-100) näyttää näyttävän noin 5 pisteryhmää. Tämä näyttää lupaavimmalta ominaisuuksien yhdistelmältä. Voimme luoda luettelon heidän nimistään, valita ne customer_data DataFrame ja tallenna valinta customer_data muuttuja jälleen käytettäväksi tulevassa mallissamme.
selected_cols = ['Annual Income (k$)', 'Spending Score (1-100)']
customer_data = customer_data[selected_cols]
Sarakkeiden valinnan jälkeen voimme suorittaa edellisessä osiossa käsitellyn skaalauksen. Ominaisuuksien saattamiseksi samaan mittakaavaan tai standardoida voimme tuoda Scikit-Learnin StandardScaler, luo se, sovita tietomme laskemaan sen keskiarvo ja keskihajonnan ja muunna tiedot vähentämällä sen keskiarvo ja jakamalla se keskihajonnalla. Tämä voidaan tehdä yhdessä vaiheessa fit_transform() menetelmä:
from sklearn.preprocessing import StandardScaler ss = StandardScaler() scaled_data = ss.fit_transform(customer_data)
Muuttujat on nyt skaalattu, ja voimme tarkastella niitä yksinkertaisesti tulostamalla sisällön scaled_data muuttuja. Vaihtoehtoisesti voimme myös lisätä ne uuteen scaled_customer_data DataFrame sarakkeiden nimien kanssa ja käytä head() menetelmä uudestaan:
scaled_customer_data = pd.DataFrame(columns=selected_cols, data=scaled_data)
scaled_customer_data.head()
Tämä tuottaa:
Annual Income (k$) Spending Score (1-100)
0 -1.738999 -0.434801
1 -1.738999 1.195704
2 -1.700830 -1.715913
3 -1.700830 1.040418
4 -1.662660 -0.395980 Nämä tiedot ovat valmiita klusteroitavaksi! Esitellessämme DBSCANin mainitsimme pisteiden vähimmäismäärän ja epsilonin. Nämä kaksi arvoa on valittava ennen mallin luomista. Katsotaan kuinka se tehdään.
Valitsemalla Min. Näytteet ja Epsilon
DBSCAN-klusteroinnin pisteiden vähimmäismäärän valitsemiseksi on olemassa nyrkkisääntö, jonka mukaan sen on oltava yhtä suuri tai suurempi kuin datan dimensioiden lukumäärä plus yksi, kuten:
$$
teksti{min. pisteet} >= teksti{tietojen mitat} + 1
$$
Mitat ovat tietokehyksen sarakkeiden lukumäärä, käytämme 2 saraketta, joten min. Pisteiden tulee olla joko 2+1, joka on 3, tai enemmän. Tässä esimerkissä käytetään 5 min. pisteitä.
$$
teksti{5 (vähimmäispisteet)} >= teksti{2 (tietojen mitat)} + 1
$$
Tutustu käytännönläheiseen, käytännölliseen Gitin oppimisoppaaseemme, jossa on parhaat käytännöt, alan hyväksymät standardit ja mukana tuleva huijauslehti. Lopeta Git-komentojen googlailu ja oikeastaan oppia se!
Nyt ε:n arvon valitsemiseksi on olemassa menetelmä, jossa a Lähimmät naapurit Algoritmia käytetään etsimään ennalta määrätyn määrän lähimpien pisteiden etäisyydet jokaiselle pisteelle. Tämä ennalta määritetty naapureiden lukumäärä on min. pisteet, jotka olemme juuri valinneet miinus 1. Joten meidän tapauksessamme algoritmi löytää 5-1 eli 4 lähintä pistettä jokaiselle datamme pisteelle. ne ovat k-naapurit ja meidän k on 4.
$$
teksti{k-naapurit} = teksti{min. pisteet} – 1
$$
Kun naapurit on löydetty, järjestämme niiden etäisyydet suurimmasta pienimpään ja piirrämme y-akselin ja x-akselin pisteiden etäisyydet. Kun katsomme kuvaajaa, löydämme sen, missä se muistuttaa kyynärpään taivutusta, ja y-akselin piste, joka kuvaa kyynärpään taivutusta, on ehdotettu ε-arvo.
Huomautuksia: on mahdollista, että ε-arvon löytämiseen tarkoitetussa kaaviossa on joko yksi tai useampi "kyynärpään taipumus", joko iso tai pieni, kun niin tapahtuu, voit etsiä arvot, testata niitä ja valita ne, joiden tulokset kuvaavat parhaiten klustereita, joko tarkastelemalla kaavioiden mittareita.
Näiden vaiheiden suorittamiseksi voimme tuoda algoritmin, sovittaa sen tietoihin ja sitten poimia kunkin pisteen etäisyydet ja indeksit kneighbors() menetelmä:
from sklearn.neighbors import NearestNeighbors
import numpy as np nn = NearestNeighbors(n_neighbors=4) nbrs = nn.fit(scaled_customer_data)
distances, indices = nbrs.kneighbors(scaled_customer_data)
Kun etäisyydet on löydetty, voimme lajitella ne suurimmasta pienimpään. Koska etäisyydet-taulukon ensimmäinen sarake on pisteestä itsestään (eli kaikki ovat 0), ja toinen sarake sisältää pienimmät etäisyydet, jota seuraa kolmas sarake, jonka etäisyydet ovat suuremmat kuin toisella, ja niin edelleen, voimme valita vain toisen sarakkeen arvot ja tallenna ne distances muuttuja:
distances = np.sort(distances, axis=0)
distances = distances[:,1] Nyt kun meillä on lajitellut pienimmät etäisyydet, voimme tuoda matplotlib, piirrä etäisyydet ja piirrä punainen viiva kohtaan, jossa "kyynärpää" on:
import matplotlib.pyplot as plt plt.figure(figsize=(6,3))
plt.plot(distances)
plt.axhline(y=0.24, color='r', linestyle='--', alpha=0.4) plt.title('Kneighbors distance graph')
plt.xlabel('Data points')
plt.ylabel('Epsilon value')
plt.show();
Tämä on tulos:
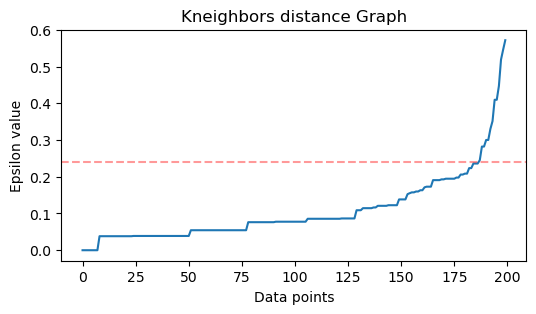
Huomaa, että viivaa piirtäessämme saamme selville ε-arvon, tässä tapauksessa se on 0.24.
Meillä on vihdoin minimipisteemme ja ε. Molemmilla muuttujilla voimme luoda ja suorittaa DBSCAN-mallin.
DBSCAN-mallin luominen
Mallin luomiseksi voimme tuoda sen Scikit-Learnistä, luoda sen ε:lla, joka on sama kuin eps argumentti, ja vähimmäispisteet, joihin on mean_samples Perustelu. Voimme sitten tallentaa sen muuttujaksi, kutsutaan sitä dbs ja sovita se skaalattuihin tietoihin:
from sklearn.cluster import DBSCAN dbs = DBSCAN(eps=0.24, min_samples=5)
dbs.fit(scaled_customer_data)
Juuri näin, meidän DBSCAN-mallimme on luotu ja koulutettu dataan! Tulosten poimimiseksi käytämme labels_ omaisuutta. Voimme myös luoda uuden labels sarake scaled_customer_data datakehys ja täytä se ennakoiduilla tunnisteilla:
labels = dbs.labels_ scaled_customer_data['labels'] = labels
scaled_customer_data.head()
Tämä on lopputulos:
Annual Income (k$) Spending Score (1-100) labels
0 -1.738999 -0.434801 -1
1 -1.738999 1.195704 0
2 -1.700830 -1.715913 -1
3 -1.700830 1.040418 0
4 -1.662660 -0.395980 -1
Huomaa, että meillä on tarrat -1 arvot; nämä ovat melupisteet, jotka eivät kuulu mihinkään klusteriin. Jotta tiedämme, kuinka monta kohinapistettä algoritmi löysi, voimme laskea, kuinka monta kertaa arvo -1 esiintyy tunnisteluettelossamme:
labels_list = list(scaled_customer_data['labels'])
n_noise = labels_list.count(-1)
print("Number of noise points:", n_noise)
Tämä tuottaa:
Number of noise points: 62
Tiedämme jo, että 62 pistettä alkuperäisestä 200 pisteen tiedosta katsottiin meluksi. Tämä on paljon kohinaa, mikä osoittaa, että ehkä DBSCAN-klusterit eivät pitäneet monia pisteitä osana klusteria. Ymmärrämme mitä tapahtui pian, kun kuvaamme dataa.
Aluksi, kun tarkastelimme tietoja, siinä näytti olevan 5 pistettä. Jotta saadaan selville, kuinka monta klusteria DBSCAN on muodostanut, voimme laskea niiden otsikoiden määrän, jotka eivät ole -1. On monia tapoja kirjoittaa tämä koodi; täällä olemme kirjoittaneet for-silmukan, joka toimii myös datalle, josta DBSCAN on löytänyt monia klustereita:
total_labels = np.unique(labels) n_labels = 0
for n in total_labels: if n != -1: n_labels += 1
print("Number of clusters:", n_labels)
Tämä tuottaa:
Number of clusters: 6
Näemme, että algoritmi ennusti datassa olevan 6 klusteria, joissa oli monia kohinapisteitä. Visualisoidaan se piirtämällä se seabornin kanssa scatterplot:
sns.scatterplot(data=scaled_customer_data, x='Annual Income (k$)', y='Spending Score (1-100)', hue='labels', palette='muted').set_title('DBSCAN found clusters');
Tämä johtaa:

Tarkasteltaessa kuvaajaa voimme nähdä, että DBSCAN on kaapannut kohdat, jotka olivat tiiviimmin yhteydessä, ja pisteet, joita voidaan pitää osana samaa klusteria, olivat joko kohinaa tai niiden katsottiin muodostavan toisen pienemmän klusterin.
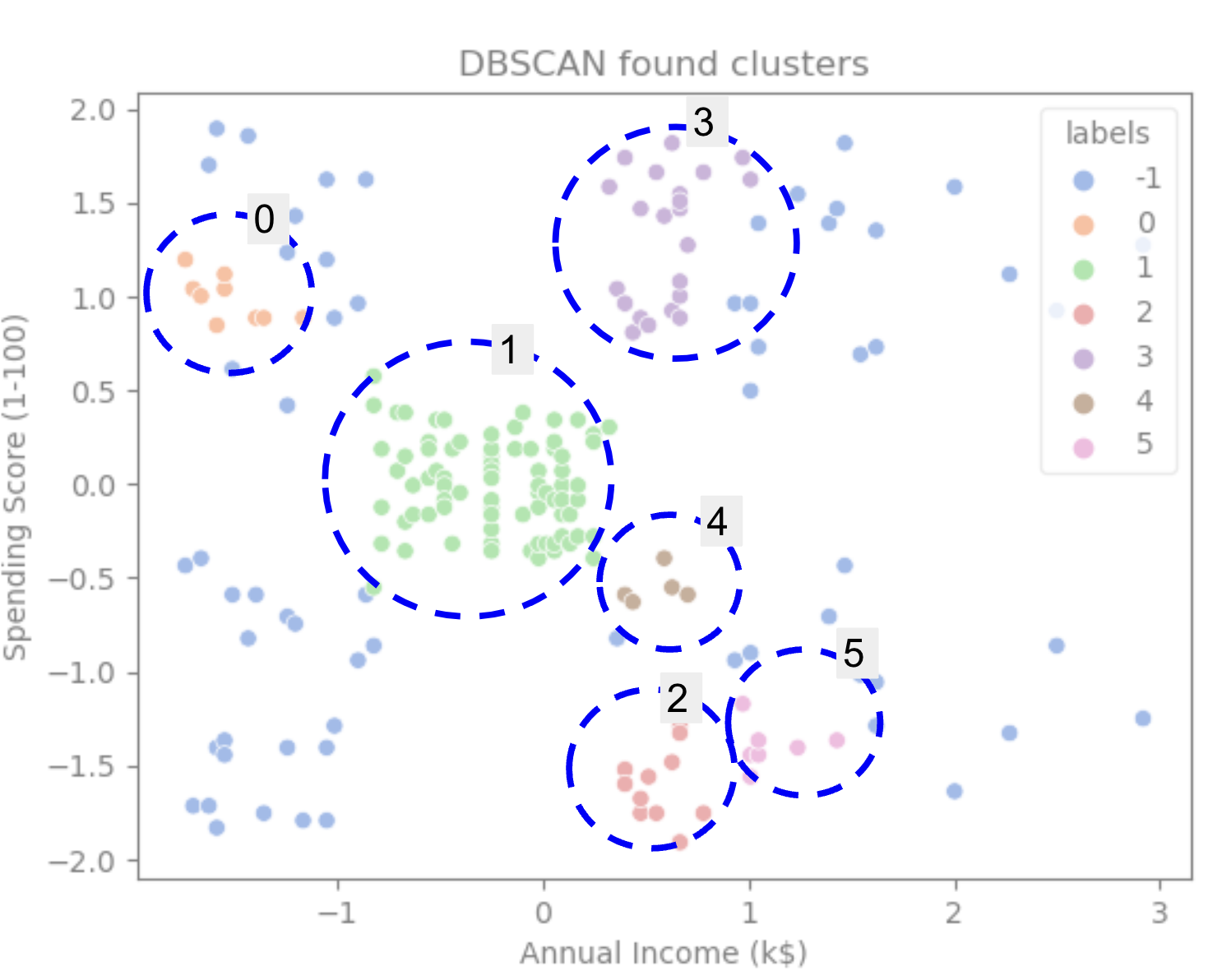
Jos korostamme klusterit, huomaa, kuinka DBSCAN saa klusterin 1 kokonaan, joka on klusteri, jossa on vähemmän tilaa pisteiden välillä. Sitten se saa ne osat klustereista 0 ja 3, joissa pisteet ovat tiiviisti toisiaan, pitäen kauempana olevat pisteet kohina. Se myös pitää vasemman alakulman pisteitä kohinana ja jakaa oikeassa alakulmassa olevat pisteet kolmeen klusteriin, mikä taas kaappaa klusterit 3, 4 ja 2, joissa pisteet ovat lähempänä toisiaan.
Voimme alkaa tulla siihen johtopäätökseen, että DBSCAN oli loistava klustereiden tiheiden alueiden kaappaamiseen, mutta ei niinkään datan suuremman kaavion, 5 klusterin rajausten tunnistamiseen. Olisi mielenkiintoista testata lisää klusterointialgoritmeja tiedoillamme. Katsotaan, vahvistaako mittari tämän hypoteesin.
Algoritmin arviointi
DBSCANin arvioimiseksi käytämme siluettipisteet joka ottaa huomioon saman klusterin pisteiden välisen etäisyyden ja klusterien väliset etäisyydet.
Huomautus: Tällä hetkellä useimpia klusterointimittareita ei todellakaan ole sovitettu käytettäväksi DBSCANin arvioinnissa, koska ne eivät perustu tiheyteen. Tässä käytämme siluettipistemäärää, koska se on jo toteutettu Scikit-learnissä ja koska se yrittää tarkastella klusterin muotoa.
Saadaksesi sopivamman arvioinnin, voit käyttää tai yhdistää sen kanssa Tiheyspohjaisen klusteroinnin validointi (DBCV) -metriikka, joka on suunniteltu erityisesti tiheyteen perustuvaa klusterointia varten. Tästä on saatavilla DBCV-toteutus GitHub.
Ensinnäkin voimme tuoda silhouette_score Scikit-Learnista, välitä sitten sarakkeet ja etiketit:
from sklearn.metrics import silhouette_score s_score = silhouette_score(scaled_customer_data, labels)
print(f"Silhouette coefficient: {s_score:.3f}")
Tämä tuottaa:
Silhouette coefficient: 0.506
Tämän tuloksen mukaan näyttää siltä, että DBSCAN voisi kaapata noin 50% tiedoista.
Yhteenveto
DBSCAN:n edut ja haitat
DBSCAN on hyvin ainutlaatuinen klusterointialgoritmi tai malli.
Jos tarkastelemme sen etuja, se on erittäin hyvä poimimaan tiheitä alueita tiedoista ja pisteistä, jotka ovat kaukana muista. Tämä tarkoittaa, että tiedoilla ei tarvitse olla tiettyä muotoa ja ne voivat olla muiden pisteiden ympäröimiä, kunhan ne ovat myös tiiviisti yhteydessä toisiinsa.
Se edellyttää, että määritämme minimipisteet ja ε, mutta klusterien määrää ei tarvitse määrittää etukäteen, kuten esimerkiksi K-Meansissa. Sitä voidaan käyttää myös erittäin suurten tietokantojen kanssa, koska se on suunniteltu suuriulotteisille tiedoille.
Mitä tulee sen haitoihin, olemme nähneet, että se ei pystynyt sieppaamaan eri tiheyksiä samassa klusterissa, joten sen on vaikea käsitellä suuria tiheyseroja. Se riippuu myös etäisyysmetriikasta ja pisteiden skaalauksesta. Tämä tarkoittaa, että jos dataa ei ymmärretä hyvin, mittakaavassa on eroja ja etäisyysmittarilla ei ole järkeä, se ei todennäköisesti ymmärrä sitä.
DBSCAN-laajennukset
On muitakin algoritmeja, esim Hierarkkinen DBSCAN (HDBSCAN) ja Pisteiden järjestäminen klusterointirakenteen tunnistamiseksi (OPTICS), joita pidetään DBSCANin laajennuksina.
Sekä HDBSCAN että OPTICS voivat yleensä toimia paremmin, kun tiedoissa on vaihtelevan tiheyden omaavia klustereita, ja ne ovat myös vähemmän herkkiä valinnalle tai alkuperäiselle min. pisteet ja ε-parametrit.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://stackabuse.com/dbscan-with-scikit-learn-in-python/

