در این پست، ما یک راه حل یادگیری ماشینی (ML) برای جستجوهای پیچیده تصویر با استفاده را مورد بحث قرار می دهیم آمازون کندرا و شناسایی آمازون. به طور خاص، ما از نمونه نمودارهای معماری برای تصاویر پیچیده استفاده می کنیم، زیرا آنها از آیکون ها و متن های بصری متعددی استفاده می کنند.
با اینترنت، جستجو و به دست آوردن یک تصویر هرگز آسان نبوده است. در بیشتر مواقع، می توانید تصاویر مورد نظر خود را به دقت پیدا کنید، مانند جستجوی مقصد بعدی تعطیلات. جستجوهای ساده اغلب موفق هستند، زیرا با ویژگی های زیادی مرتبط نیستند. فراتر از مشخصات تصویر مورد نظر، معیارهای جستجو معمولاً به جزئیات قابل توجهی برای یافتن نتیجه مورد نیاز نیاز ندارند. به عنوان مثال، اگر کاربری سعی کند نوع خاصی از بطری آبی را جستجو کند، نتایج بسیاری از انواع مختلف بطری آبی نمایش داده می شود. با این حال، بطری آبی مورد نظر ممکن است به دلیل عبارات جستجوی عمومی به راحتی پیدا نشود.
تفسیر زمینه جستجو نیز به ساده سازی نتایج کمک می کند. وقتی کاربران یک تصویر دلخواه را در ذهن دارند، سعی می کنند آن را در قالب یک عبارت جستجوی متنی قرار دهند. درک تفاوت های ظریف بین عبارت های جستجو برای موضوعات مشابه برای ارائه نتایج مرتبط و به حداقل رساندن تلاش مورد نیاز کاربر برای مرتب سازی دستی نتایج مهم است. به عنوان مثال، عبارت جستجوی «صاحب سگ بازی میکند» به دنبال نمایش نتایج تصویری است که نشان میدهد صاحب سگ در حال انجام بازی واکشی با سگ است. با این حال، نتایج واقعی ایجاد شده ممکن است در عوض روی سگی تمرکز کند که یک شی را بدون نشان دادن دخالت صاحبش می آورد. کاربران ممکن است مجبور شوند به صورت دستی نتایج تصویر نامناسب را هنگام سر و کار داشتن با جستجوهای پیچیده فیلتر کنند.
برای رسیدگی به مشکلات مرتبط با جستجوهای پیچیده، این پست به طور مفصل توضیح می دهد که چگونه می توانید به موتور جستجویی دست پیدا کنید که قادر به جستجوی تصاویر پیچیده با ادغام Amazon Kendra و Amazon Rekognition باشد. Amazon Kendra یک سرویس جستجوی هوشمند است که توسط ML پشتیبانی میشود و Amazon Rekognition یک سرویس ML است که میتواند اشیاء، افراد، متن، صحنهها و فعالیتها را از روی تصاویر یا ویدیوها شناسایی کند.
چه تصاویری می توانند آنقدر پیچیده باشند که قابل جستجو نباشند؟ یک مثال نمودارهای معماری است که بسته به پیچیدگی مورد استفاده و تعداد خدمات فنی مورد نیاز می تواند با معیارهای جستجوی زیادی همراه باشد که منجر به تلاش دستی قابل توجهی برای کاربر می شود. به عنوان مثال، اگر کاربران بخواهند یک راه حل معماری برای استفاده از تأیید مشتری بیابند، معمولاً از یک عبارت جستجوی مشابه «نمودارهای معماری برای تأیید مشتری» استفاده می کنند. با این حال، عبارتهای جستجوی عمومی طیف گستردهای از خدمات و در تاریخهای مختلف ایجاد محتوا را شامل میشود. کاربران باید به صورت دستی نامزدهای معماری مناسب را بر اساس خدمات خاص انتخاب کنند و ارتباط انتخاب های طراحی معماری را با توجه به تاریخ ایجاد محتوا و تاریخ درخواست در نظر بگیرند.
شکل زیر یک نمودار نمونه را نشان می دهد که یک راه حل معماری استخراج، تبدیل و بارگذاری (ETL) هماهنگ شده را نشان می دهد.

برای کاربرانی که با خدمات ارائه شده در پلتفرم ابری آشنا نیستند، ممکن است هنگام جستجوی چنین نموداری، روشها و توضیحات کلی متفاوتی ارائه دهند. در زیر چند نمونه از نحوه جستجوی آن آورده شده است:
- "روی کار ETL را هماهنگ کنید"
- "چگونه پردازش انبوه داده را خودکار کنیم"
- "روش های ایجاد خط لوله برای تبدیل داده ها"
بررسی اجمالی راه حل
ما شما را از طریق مراحل زیر برای پیاده سازی راه حل راهنمایی می کنیم:
- آموزش یک برچسب های سفارشی شناسایی آمازون مدلی برای تشخیص نمادها در نمودارهای معماری
- برای اعتبار سنجی نمادهای نمودار معماری، تشخیص متن شناسایی آمازون را بگنجانید.
- از شناسایی آمازون در داخل یک خزنده وب برای ایجاد یک مخزن برای جستجو استفاده کنید
- از آمازون کندرا برای جستجو در مخزن استفاده کنید.
برای اینکه به راحتی یک مخزن بزرگ از نتایج مرتبط را در اختیار کاربران قرار دهد، راه حل باید روشی خودکار برای جستجو از طریق منابع قابل اعتماد ارائه دهد. با استفاده از نمودارهای معماری به عنوان مثال، راه حل نیاز به جستجو از طریق پیوندهای مرجع و اسناد فنی برای نمودارهای معماری و شناسایی خدمات موجود دارد. شناسایی کلمات کلیدی مانند موارد استفاده و عمودی های صنعتی در این منابع همچنین باعث می شود که اطلاعات گرفته شود و نتایج جستجوی مرتبط تر به کاربر نمایش داده شود.
با توجه به هدف چگونگی جستجوی نمودارهای مرتبط، راه حل جستجوی تصویر باید سه معیار را برآورده کند:
- جستجوی ساده کلمات کلیدی را فعال کنید
- پرس و جوهای جستجو را بر اساس موارد استفاده که کاربران ارائه می دهند تفسیر کنید
- مرتب سازی و ترتیب نتایج جستجو
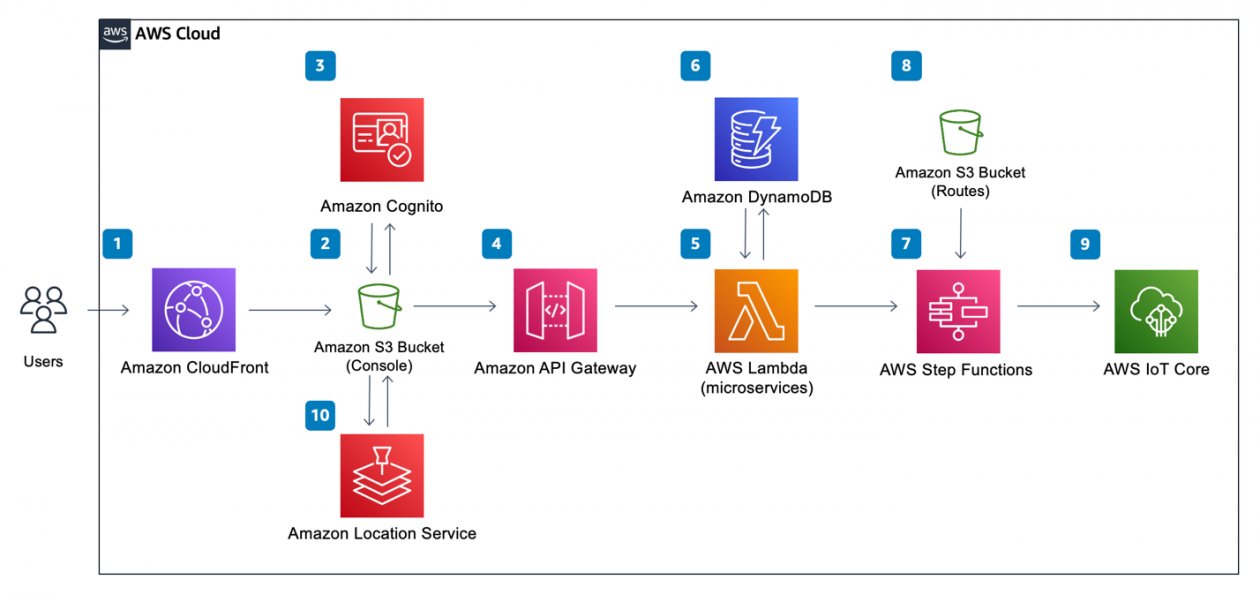
جستجوی کلیدواژه به سادگی جستجوی "Amazon Rekognition" و نشان دادن نمودارهای معماری در مورد نحوه استفاده از سرویس در موارد مختلف است. متناوبا، عبارات جستجو را می توان به طور غیرمستقیم از طریق موارد استفاده و عمودهای صنعتی که ممکن است با معماری مرتبط باشد به نمودار مرتبط کرد. برای مثال، جستجوی عبارت «چگونه خط لوله ETL را هماهنگ کنیم» نتایج نمودارهای معماری ساخته شده با چسب AWS و توابع مرحله AWS. مرتبسازی و مرتبسازی نتایج جستجو بر اساس ویژگیهایی مانند تاریخ ایجاد، تضمین میکند که نمودارهای معماری، علیرغم بهروزرسانیها و نسخههای سرویس، همچنان مرتبط هستند. شکل زیر نمودار معماری راه حل جستجوی تصویر را نشان می دهد.

همانطور که در نمودار قبلی و در نمای کلی راه حل نشان داده شده است، دو جنبه اصلی راه حل وجود دارد. اولین جنبه توسط آمازون Rekognition انجام می شود که می تواند اشیاء، افراد، متن، صحنه ها و فعالیت ها را از روی تصاویر یا ویدئوها شناسایی کند. این شامل مدل های از پیش آموزش دیده است که می تواند برای تجزیه و تحلیل تصاویر و فیلم ها در مقیاس استفاده شود. با ویژگی برچسبهای سفارشی، آمازون Rekognition به شما اجازه میدهد تا با برچسبگذاری تصاویر جمعآوریشده از منابع از طریق نمودارهای معماری در پیوندهای مرجع قابل اعتماد و اسناد فنی، سرویس ML را مطابق با نیازهای تجاری خاص خود تنظیم کنید. با آپلود مجموعه کوچکی از تصاویر آموزشی، Amazon Rekognition به طور خودکار داده های آموزشی را بارگیری و بررسی می کند، الگوریتم های ML مناسب را انتخاب می کند، یک مدل را آموزش می دهد و معیارهای عملکرد مدل را ارائه می دهد. بنابراین، کاربران بدون تخصص ML می توانند از مزایای مدل برچسب های سفارشی از طریق تماس API بهره مند شوند، زیرا مقدار قابل توجهی از سربار کاهش می یابد. این راه حل از برچسب های سفارشی شناسایی آمازون برای شناسایی آرم های سرویس AWS در نمودارهای معماری استفاده می کند تا امکان جستجوی نمودارهای معماری با نام سرویس ها را فراهم کند. پس از مدلسازی، سرویسهای شناساییشده هر تصویر نمودار معماری و ابردادههای آن، مانند مبدا URL و عنوان تصویر، برای اهداف جستجوی آینده نمایهسازی میشوند و در آن ذخیره میشوند. آمازون DynamoDB، یک پایگاه داده NoSQL کاملاً مدیریت شده، بدون سرور و با ارزش کلیدی که برای اجرای برنامه های کاربردی با کارایی بالا طراحی شده است.
جنبه دوم توسط Amazon Kendra پشتیبانی می شود، یک سرویس جستجوی سازمانی هوشمند که توسط ML پشتیبانی می شود و به شما امکان می دهد در مخازن محتوای مختلف جستجو کنید. با آمازون کندرا، می توانید نتایجی مانند تصاویر یا اسناد فهرست شده را جستجو کنید. این نتایج همچنین می توانند در مخازن مختلف ذخیره شوند زیرا سرویس جستجو از اتصال دهنده های داخلی استفاده می کند. برای جستجو می توان از کلمات کلیدی، عبارات و توضیحات استفاده کرد، که به شما امکان می دهد نمودارهایی را که به یک مورد خاص مرتبط هستند به طور دقیق جستجو کنید. بنابراین، می توانید به راحتی یک سرویس جستجوی هوشمند با حداقل هزینه توسعه بسازید.
با درک مشکل و راه حل، بخش های بعدی به چگونگی خودکار کردن منبع یابی داده ها از طریق خزیدن نمودارهای معماری از منابع معتبر می پردازند. پس از این، فرآیند تولید یک مدل ML برچسب سفارشی با یک سرویس کاملاً مدیریت شده را طی می کنیم. در نهایت، ما انتقال دادهها را توسط یک سرویس جستجوی هوشمند که توسط ML پشتیبانی میشود، پوشش میدهیم.
یک مدل شناسایی آمازون با برچسب های سفارشی ایجاد کنید
قبل از به دست آوردن هر نمودار معماری، ما به ابزاری نیاز داریم تا ارزیابی کنیم که آیا می توان یک تصویر را به عنوان نمودار معماری شناسایی کرد یا خیر. Amazon Rekognition Custom Labels یک فرآیند ساده را برای ایجاد یک مدل تشخیص تصویر ارائه میکند که اشیاء و صحنهها را در تصاویر مشخص میکند که مخصوص نیاز یک کسبوکار است. در این مورد، ما از برچسبهای سفارشی شناسایی آمازون برای شناسایی نمادهای سرویس AWS استفاده میکنیم، سپس تصاویر برای جستجوی مرتبطتر با استفاده از Amazon Kendra با سرویسها فهرستبندی میشوند. این مدل تفاوتی نمیکند که آیا تصویر یک نمودار معماری است یا خیر. به سادگی آیکون های سرویس را، در صورت وجود، شناسایی می کند. به این ترتیب، ممکن است مواردی وجود داشته باشد که تصاویری که نمودارهای معماری نیستند در نتایج جستجو قرار گیرند. با این حال، چنین نتایج حداقل است.
شکل زیر مراحلی را نشان می دهد که این راه حل برای ایجاد یک مدل برچسب های سفارشی شناسایی آمازون انجام می دهد.

این فرآیند شامل آپلود مجموعه دادهها، تولید یک فایل مانیفست که به مجموعه دادههای آپلود شده ارجاع میدهد، و سپس این فایل مانیفست را در آمازون Rekognition آپلود میکند. یک اسکریپت پایتون برای کمک به فرآیند آپلود مجموعه داده ها و تولید فایل مانیفست استفاده می شود. پس از تولید موفقیت آمیز فایل مانیفست، سپس در آمازون Rekognition آپلود می شود تا فرآیند آموزش مدل آغاز شود. برای جزئیات بیشتر در مورد اسکریپت پایتون و نحوه اجرای آن، به آدرس زیر مراجعه کنید GitHub repo.
برای آموزش مدل، در پروژه شناسایی آمازون، انتخاب کنید مدل قطار، پروژه ای را که می خواهید آموزش دهید انتخاب کنید، سپس هر برچسب مربوطه را اضافه کنید و انتخاب کنید مدل قطار. برای دستورالعملهای مربوط به شروع پروژه برچسبهای سفارشی شناسایی آمازون، به موارد موجود مراجعه کنید آموزش های ویدئویی. آموزش مدل با این مجموعه داده ممکن است تا 8 ساعت طول بکشد.
هنگامی که آموزش کامل شد، می توانید مدل آموزش دیده را برای مشاهده نتایج ارزیابی انتخاب کنید. برای جزئیات بیشتر در مورد معیارهای مختلف مانند دقت، یادآوری، و F1، مراجعه کنید معیارهای ارزیابی مدل شما. برای استفاده از مدل، به مسیر بروید از مدل استفاده کنید برگه، تعداد واحدهای استنتاج را روی 1 بگذارید و مدل را شروع کنید. سپس می توانیم از an استفاده کنیم AWS لامبدا عملکرد ارسال تصاویر به مدل در base64، و مدل لیستی از برچسب ها و امتیازات اطمینان را برمی گرداند.
پس از آموزش موفقیت آمیز مدل شناسایی آمازون با برچسب های سفارشی شناسایی آمازون، می توانیم از آن برای شناسایی نمادهای سرویس در نمودارهای معماری که خزیده شده اند استفاده کنیم. برای افزایش دقت شناسایی خدمات در نمودار معماری، از یکی دیگر از ویژگی های آمازون Rekognition به نام تشخیص متن. برای استفاده از این ویژگی، از همان تصویر در base64 عبور می کنیم و آمازون Rekognition لیستی از متن های مشخص شده در تصویر را برمی گرداند. در شکلهای زیر، تصویر اصلی را با هم مقایسه میکنیم و بعد از مشخص شدن سرویسهای موجود در تصویر به چه شکل است. شکل اول تصویر اصلی را نشان می دهد.
شکل زیر تصویر اصلی را با سرویس های شناسایی شده نشان می دهد.

برای اطمینان از مقیاس پذیری، از یک تابع Lambda استفاده می کنیم که از طریق یک نقطه پایانی API ایجاد شده با استفاده از دروازه API آمازون. Lambda یک سرویس محاسباتی بدون سرور و رویداد محور است که به شما امکان میدهد کد تقریباً برای هر نوع برنامه کاربردی یا سرویس پشتیبان را بدون تهیه یا مدیریت سرورها اجرا کنید. استفاده از یک تابع Lambda نگرانی رایج در مورد افزایش مقیاس زمانی که حجم زیادی از درخواست ها به نقطه پایانی API ارسال می شود را از بین می برد. Lambda به طور خودکار این تابع را برای فراخوانی API خاص اجرا می کند، که پس از تکمیل فراخوانی متوقف می شود و در نتیجه هزینه تحمیل شده به کاربر را کاهش می دهد. از آنجایی که درخواست به نقطه پایانی آمازون Rekognition هدایت میشود، تنها مقیاس پذیر بودن تابع Lambda کافی نیست. برای اینکه نقطه پایانی شناسایی آمازون مقیاس پذیر باشد، می توانید واحد استنتاج نقطه پایانی را افزایش دهید. برای جزئیات بیشتر در مورد پیکربندی واحد استنتاج، مراجعه کنید واحدهای استنتاج
در زیر یک قطعه کد از تابع Lambda برای فرآیند تشخیص تصویر آمده است:
پس از ایجاد تابع Lambda، میتوانیم با استفاده از API Gateway، آن را به عنوان یک API نمایش دهیم. برای دستورالعملهای مربوط به ایجاد یک API با ادغام پراکسی Lambda، مراجعه کنید آموزش: ساخت Hello World REST API با ادغام پراکسی Lambda.
نمودارهای معماری را خزیدن
برای اینکه ویژگی جستجو به طور عملی کار کند، به یک مخزن از نمودارهای معماری نیاز داریم. اما این نمودارها باید از منابع معتبری مانند وبلاگ AWS و راهنمای تجویزی AWS. ایجاد اعتبار منابع داده تضمین می کند که پیاده سازی اساسی و هدف موارد استفاده دقیق و به خوبی بررسی شده است. گام بعدی راه اندازی یک خزنده است که می تواند به جمع آوری بسیاری از نمودارهای معماری برای تغذیه در مخزن ما کمک کند. ما یک خزنده وب برای استخراج نمودارهای معماری و اطلاعاتی مانند شرح پیاده سازی از منابع مربوطه ایجاد کردیم. راه های متعددی وجود دارد که می توانید به ساخت چنین مکانیزمی دست یابید. برای این مثال، از برنامه ای استفاده می کنیم که روی آن اجرا می شود ابر محاسبه الاستیک آمازون (آمازون EC2). این برنامه ابتدا پیوندهایی به پست های وبلاگ را از یک API وبلاگ AWS به دست می آورد. پاسخ بازگردانده شده از API حاوی اطلاعاتی از پست مانند عنوان، URL، تاریخ و پیوندهای تصاویر موجود در پست است.
در زیر یک قطعه کد از تابع جاوا اسکریپت برای فرآیند خزیدن وب آمده است:
با این مکانیزم به راحتی می توانیم صدها و هزاران تصویر را از وبلاگ های مختلف بخزیم. با این حال، ما به فیلتری نیاز داریم که فقط تصاویری را بپذیرد که حاوی محتوای یک نمودار معماری هستند، که در مورد ما نمادهای خدمات AWS هستند تا تصاویری را که نمودارهای معماری نیستند فیلتر کنیم.
این هدف از مدل شناسایی آمازون ما است. نمودارها از طریق فرآیند تشخیص تصویر می گذرند، که نمادهای سرویس را شناسایی می کند و تعیین می کند که آیا می توان آن را به عنوان یک نمودار معماری معتبر در نظر گرفت.
در زیر یک قطعه کد از تابعی است که تصاویر را به مدل شناسایی آمازون ارسال می کند:
پس از گذراندن بررسی تشخیص تصویر، نتایج حاصل از مدل شناسایی آمازون و اطلاعات مربوط به آن در فرادادههای خودشان دستهبندی میشوند. سپس ابرداده در یک جدول DynamoDB ذخیره میشود، جایی که رکورد برای ورود به Amazon Kendra استفاده میشود.
در زیر یک قطعه کد از تابعی است که ابرداده های نمودار را در DynamoDB ذخیره می کند:
فراداده را در آمازون کندرا وارد کنید
پس از اینکه نمودارهای معماری فرآیند تشخیص تصویر را طی کردند و متادیتا در DynamoDB ذخیره شد، ما به راهی برای جستجوی نمودارها در حین ارجاع به محتوا در فراداده نیاز داریم. رویکرد برای این کار داشتن یک موتور جستجو است که بتواند با برنامه یکپارچه شود و بتواند حجم زیادی از جستجوهای جستجو را مدیریت کند. بنابراین، ما از Amazon Kendra، یک سرویس جستجوی سازمانی هوشمند استفاده می کنیم.
ما از Amazon Kendra به عنوان مؤلفه تعاملی راه حل استفاده می کنیم، زیرا قابلیت جستجوی قدرتمند آن، به ویژه با استفاده از زبان طبیعی است. هنگامی که کاربران در جستجوی نمودارهایی هستند که به آنچه که به دنبال آن هستند نزدیکترین حالت را دارند، این یک لایه سادگی اضافه میکند. آمازون کندرا تعدادی اتصال دهنده منابع داده را برای جذب و اتصال محتوا ارائه می دهد. این راه حل از یک رابط سفارشی برای دریافت اطلاعات نمودارهای معماری از DynamoDB استفاده می کند. برای پیکربندی یک منبع داده برای نمایه آمازون کندرا، میتوانید از یک فهرست موجود یا استفاده کنید یک شاخص جدید ایجاد کنید.
سپس نمودارهای خزیده شده باید در نمایه آمازون کندرا که ایجاد شده است وارد شوند. شکل زیر جریان نحوه نمایه سازی نمودارها را نشان می دهد.

ابتدا، نمودارهای درج شده در DynamoDB یک رویداد Put از طریق ایجاد می کنند آمازون DynamoDB Streams. این رویداد تابع Lambda را فعال می کند که به عنوان یک منبع داده سفارشی برای Amazon Kendra عمل می کند و نمودارها را در فهرست بارگذاری می کند. برای دستورالعملهای مربوط به ایجاد تریگر DynamoDB Streams برای یک تابع Lambda، مراجعه کنید آموزش: استفاده از AWS Lambda با آمازون DynamoDB Streams
پس از اینکه تابع Lambda را با DynamoDB ادغام کردیم، باید رکوردهای نمودارهای ارسال شده به تابع را در نمایه Amazon Kendra وارد کنیم. ایندکس دادهها را از انواع منابع مختلف میپذیرد، و ورود آیتمها به نمایه از تابع Lambda به این معنی است که باید از پیکربندی منبع داده سفارشی استفاده کند. برای دستورالعملهای مربوط به ایجاد یک منبع داده سفارشی برای فهرست خود، به رابط منبع داده سفارشی.
در زیر یک قطعه کد از تابع Lambda برای نحوه نمایه سازی یک نمودار به صورت سفارشی آورده شده است:
عامل مهمی که نمودارها را قادر به جستجو می کند، کلید Blob در یک سند است. این همان چیزی است که آمازون کندرا وقتی کاربران ورودی جستجوی خود را ارائه می دهند به آن توجه می کند. در این کد مثال، کلید Blob حاوی یک نسخه خلاصه شده از مورد استفاده از نمودار است که با اطلاعات شناسایی شده از فرآیند تشخیص تصویر ترکیب شده است. این به کاربران امکان می دهد نمودارهای معماری را بر اساس موارد استفاده مانند "تشخیص کلاهبرداری" یا با نام سرویس هایی مانند "Amazon Kendra" جستجو کنند.
برای نشان دادن مثالی از شکل ظاهری کلید Blob، قطعه زیر به نمودار اولیه ETL اشاره می کند که قبلاً در این پست معرفی کردیم. این شامل توصیفی از نموداری است که هنگام خزیدن به دست آمد، و همچنین خدماتی که توسط مدل شناسایی آمازون شناسایی شدند.
جستجو با آمازون کندرا
پس از اینکه همه اجزا را کنار هم قرار دادیم، نتایج جستجوی نمونه «تحلیل در زمان واقعی» شبیه تصویر زیر است.

با جستجوی این مورد استفاده، نمودارهای معماری مختلفی را تولید می کند. کاربران با این روش های مختلف از حجم کاری خاصی که سعی در پیاده سازی آن دارند ارائه می شوند.
پاک کردن
برای پاکسازی منابعی که به عنوان بخشی از این پست ایجاد کرده اید، مراحل این بخش را تکمیل کنید:
- API را حذف کنید:
- در کنسول API Gateway، API مورد نظر برای حذف را انتخاب کنید.
- بر اعمال منو ، انتخاب کنید حذف.
- را انتخاب کنید حذف برای تایید.
- جدول DynamoDB را حذف کنید:
- در کنسول DynamoDB، را انتخاب کنید جداول در صفحه ناوبری
- جدولی که ایجاد کردید را انتخاب کنید و انتخاب کنید حذف.
- هنگامی که از شما برای تایید خواسته شد، حذف را وارد کنید.
- را انتخاب کنید حذف جدول برای تایید.
- فهرست آمازون کندرا را حذف کنید:
- در کنسول آمازون کندرا، انتخاب کنید شاخص در صفحه ناوبری
- ایندکسی که ایجاد کردید را انتخاب کنید و انتخاب کنید حذف
- زمانی که از شما برای تایید خواسته شد، دلیل وارد کنید.
- را انتخاب کنید حذف برای تایید.
- پروژه شناسایی آمازون را حذف کنید:
- در کنسول آمازون Rekognition، را انتخاب کنید از برچسب های سفارشی استفاده کنید در صفحه پیمایش، سپس انتخاب کنید پروژه ها.
- پروژه ای که ایجاد کرده اید را انتخاب کرده و انتخاب کنید حذف.
- هنگامی که از شما برای تایید خواسته شد، حذف را وارد کنید.
- را انتخاب کنید مجموعه داده ها و مدل های مرتبط را حذف کنید برای تایید.
- تابع Lambda را حذف کنید:
- در کنسول لامبدا، عملکردی را که باید حذف شود انتخاب کنید.
- بر اعمال منو ، انتخاب کنید حذف.
- هنگامی که از شما برای تایید خواسته شد، حذف را وارد کنید.
- را انتخاب کنید حذف برای تایید.
خلاصه
در این پست نمونه ای از نحوه جستجوی هوشمندانه اطلاعات از تصاویر را نشان دادیم. این شامل فرآیند آموزش یک مدل آمازون Rekognition ML است که به عنوان فیلتری برای تصاویر عمل می کند، اتوماسیون خزیدن تصویر، که اعتبار و کارایی را تضمین می کند، و پرس و جو برای نمودارها با پیوست کردن یک منبع داده سفارشی که به شیوه ای انعطاف پذیرتر برای فهرست بندی موارد امکان پذیر می شود. . برای غواصی عمیق تر در پیاده سازی کدها، به آدرس مراجعه کنید GitHub repo.
اکنون که می دانید چگونه می توانید ستون فقرات یک مخزن جستجوی متمرکز را برای جستجوهای پیچیده ارائه دهید، سعی کنید موتور جستجوی تصویر خود را ایجاد کنید. برای اطلاعات بیشتر در مورد ویژگی های اصلی، به شروع با برچسب های سفارشی شناسایی آمازون, تعدیل محتوا، و راهنمای توسعه دهنده آمازون کندرا. اگر با برچسبهای سفارشی شناسایی آمازون تازه کار هستید، آن را با استفاده از ردیف رایگان ما امتحان کنید که 3 ماه طول میکشد و شامل 10 ساعت آموزش رایگان در ماه و 4 ساعت استنتاج رایگان در ماه است.
درباره نویسنده
 رایان ببین یک معمار راه حل در AWS است. او که در سنگاپور مستقر است، با مشتریان کار می کند تا راه حل هایی برای حل مشکلات تجاری آنها بسازد و همچنین یک چشم انداز فنی برای کمک به اجرای حجم های کاری مقیاس پذیرتر و کارآمدتر در فضای ابری ایجاد کند.
رایان ببین یک معمار راه حل در AWS است. او که در سنگاپور مستقر است، با مشتریان کار می کند تا راه حل هایی برای حل مشکلات تجاری آنها بسازد و همچنین یک چشم انداز فنی برای کمک به اجرای حجم های کاری مقیاس پذیرتر و کارآمدتر در فضای ابری ایجاد کند.
 جیمز اونگ جیا شیانگ مدیر راه حل های مشتری در AWS است. او در برنامه شتاب مهاجرت (MAP) تخصص دارد، جایی که به مشتریان و شرکا کمک می کند تا با موفقیت برنامه های مهاجرت در مقیاس بزرگ را به AWS اجرا کنند. او که در سنگاپور مستقر است، همچنین بر پیشبرد نوسازی و ابتکارات تحول سازمانی در سراسر APJ از طریق مکانیسم های مقیاس پذیر تمرکز می کند. او برای اوقات فراغت از فعالیت های طبیعت مانند کوه نوردی و موج سواری لذت می برد.
جیمز اونگ جیا شیانگ مدیر راه حل های مشتری در AWS است. او در برنامه شتاب مهاجرت (MAP) تخصص دارد، جایی که به مشتریان و شرکا کمک می کند تا با موفقیت برنامه های مهاجرت در مقیاس بزرگ را به AWS اجرا کنند. او که در سنگاپور مستقر است، همچنین بر پیشبرد نوسازی و ابتکارات تحول سازمانی در سراسر APJ از طریق مکانیسم های مقیاس پذیر تمرکز می کند. او برای اوقات فراغت از فعالیت های طبیعت مانند کوه نوردی و موج سواری لذت می برد.
 هنگ دوونگ یک معمار راه حل در AWS است. او که در هانوی، ویتنام مستقر است، با ارائه راهحلهای ابری بسیار در دسترس، ایمن و مقیاسپذیر برای مشتریانش، بر پذیرش ابر در سراسر کشورش تمرکز دارد. علاوه بر این، او از ساخت و ساز لذت می برد و در پروژه های مختلف نمونه سازی مشارکت دارد. او همچنین علاقه زیادی به حوزه یادگیری ماشینی دارد.
هنگ دوونگ یک معمار راه حل در AWS است. او که در هانوی، ویتنام مستقر است، با ارائه راهحلهای ابری بسیار در دسترس، ایمن و مقیاسپذیر برای مشتریانش، بر پذیرش ابر در سراسر کشورش تمرکز دارد. علاوه بر این، او از ساخت و ساز لذت می برد و در پروژه های مختلف نمونه سازی مشارکت دارد. او همچنین علاقه زیادی به حوزه یادگیری ماشینی دارد.
 ترینه وو یک معمار راه حل در AWS، مستقر در شهر هوشی مین، ویتنام است. او بر کار با مشتریان در صنایع مختلف و شرکا در ویتنام تمرکز دارد تا معماریها و نمایشهایی از پلتفرم AWS را ایجاد کند که بر خلاف نیازهای تجاری مشتری عمل میکند و پذیرش فناوری AWS مناسب را تسریع میکند. او از غارنوردی و پیاده روی برای اوقات فراغت لذت می برد.
ترینه وو یک معمار راه حل در AWS، مستقر در شهر هوشی مین، ویتنام است. او بر کار با مشتریان در صنایع مختلف و شرکا در ویتنام تمرکز دارد تا معماریها و نمایشهایی از پلتفرم AWS را ایجاد کند که بر خلاف نیازهای تجاری مشتری عمل میکند و پذیرش فناوری AWS مناسب را تسریع میکند. او از غارنوردی و پیاده روی برای اوقات فراغت لذت می برد.
 وای کین تام یک معمار ابر در AWS است. کار روزانه او مستقر در سنگاپور شامل کمک به مشتریان برای مهاجرت به ابر و مدرن کردن پشته فناوری آنها در ابر است. در اوقات فراغت در کلاس های موی تای و جیو جیتسو برزیلی شرکت می کند.
وای کین تام یک معمار ابر در AWS است. کار روزانه او مستقر در سنگاپور شامل کمک به مشتریان برای مهاجرت به ابر و مدرن کردن پشته فناوری آنها در ابر است. در اوقات فراغت در کلاس های موی تای و جیو جیتسو برزیلی شرکت می کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoAiStream. Web3 Data Intelligence دانش تقویت شده دسترسی به اینجا.
- ضرب کردن آینده با آدرین اشلی. دسترسی به اینجا.
- خرید و فروش سهام در شرکت های PRE-IPO با PREIPO®. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/build-an-image-search-engine-with-amazon-kendra-and-amazon-rekognition/

