در این پست، ما در مورد چگونگی یونایتد ایرلاینز، با همکاری آزمایشگاه راه حل های یادگیری ماشین آمازون، یک چارچوب یادگیری فعال در AWS ایجاد کنید تا پردازش اسناد مسافر را خودکار کند.
«به منظور ارائه بهترین تجربه پرواز برای مسافران خود و کارآمدتر کردن فرآیند کسب و کار داخلی خود تا حد امکان، ما یک خط لوله پردازش اسناد مبتنی بر یادگیری ماشین خودکار در AWS ایجاد کردهایم. برای تقویت این برنامهها، و همچنین آنهایی که از روشهای داده دیگر مانند بینایی رایانه استفاده میکنند، به یک گردش کار قوی و کارآمد برای حاشیهنویسی سریع دادهها، آموزش و ارزیابی مدلها و تکرار سریع نیاز داریم. در طی چند ماه، یونایتد با آزمایشگاه راهحلهای یادگیری ماشین آمازون برای طراحی و توسعه یک گردش کار یادگیری فعال قابل استفاده مجدد با استفاده از AWS CDK همکاری کرد. این گردش کار برای برنامههای یادگیری ماشین مبتنی بر دادههای بدون ساختار ما اساسی خواهد بود، زیرا ما را قادر میسازد تلاشهای برچسبگذاری انسانی را به حداقل برسانیم، عملکرد مدل قوی را به سرعت ارائه دهیم و با جابجایی دادهها سازگار شویم.
- جان نلسون، مدیر ارشد علوم داده و یادگیری ماشین در هواپیمایی متحده.
مشکل
تیم فناوری دیجیتال یونایتد متشکل از افراد مختلف در سطح جهانی است که با فناوری پیشرفته با یکدیگر همکاری می کنند تا نتایج کسب و کار را به پیش ببرند و سطح رضایت مشتری را بالا نگه دارند. آنها می خواستند از تکنیک های یادگیری ماشین (ML) مانند بینایی کامپیوتر (CV) و پردازش زبان طبیعی (NLP) برای خودکارسازی خطوط لوله پردازش اسناد استفاده کنند. به عنوان بخشی از این استراتژی، آنها یک مدل تجزیه و تحلیل گذرنامه داخلی برای تأیید شناسه مسافران ایجاد کردند. این فرآیند برای آموزش مدل های ML به حاشیه نویسی های دستی متکی است که بسیار پرهزینه هستند.
یونایتد میخواست یک چارچوب ML انعطافپذیر، انعطافپذیر و مقرونبهصرفه برای تأیید خودکار اطلاعات پاسپورت، اعتبارسنجی هویت مسافران و شناسایی اسناد تقلبی احتمالی ایجاد کند. آنها آزمایشگاه راه حل های ML را برای کمک به دستیابی به این هدف درگیر کردند، که به یونایتد اجازه می دهد به ارائه خدمات در سطح جهانی در مواجهه با رشد مسافران آینده ادامه دهد.
بررسی اجمالی راه حل
تیم مشترک ما یک چارچوب یادگیری فعال را طراحی و توسعه داده است کیت توسعه ابری AWS (AWS CDK)، که به صورت برنامه نویسی تمام خدمات AWS لازم را پیکربندی و ارائه می کند. چارچوب استفاده می کند آمازون SageMaker برای پردازش داده های بدون برچسب، برچسب های نرم ایجاد می کند، کارهای برچسب گذاری دستی را با آن راه اندازی می کند Amazon SageMaker Ground Truth، و یک مدل ML دلخواه را با مجموعه داده حاصل آموزش می دهد. ما با استفاده از متن آمازون برای استخراج خودکار اطلاعات از فیلدهای سند خاص مانند نام و شماره پاسپورت. در سطح بالا، رویکرد را می توان با نمودار زیر توصیف کرد.

داده ها
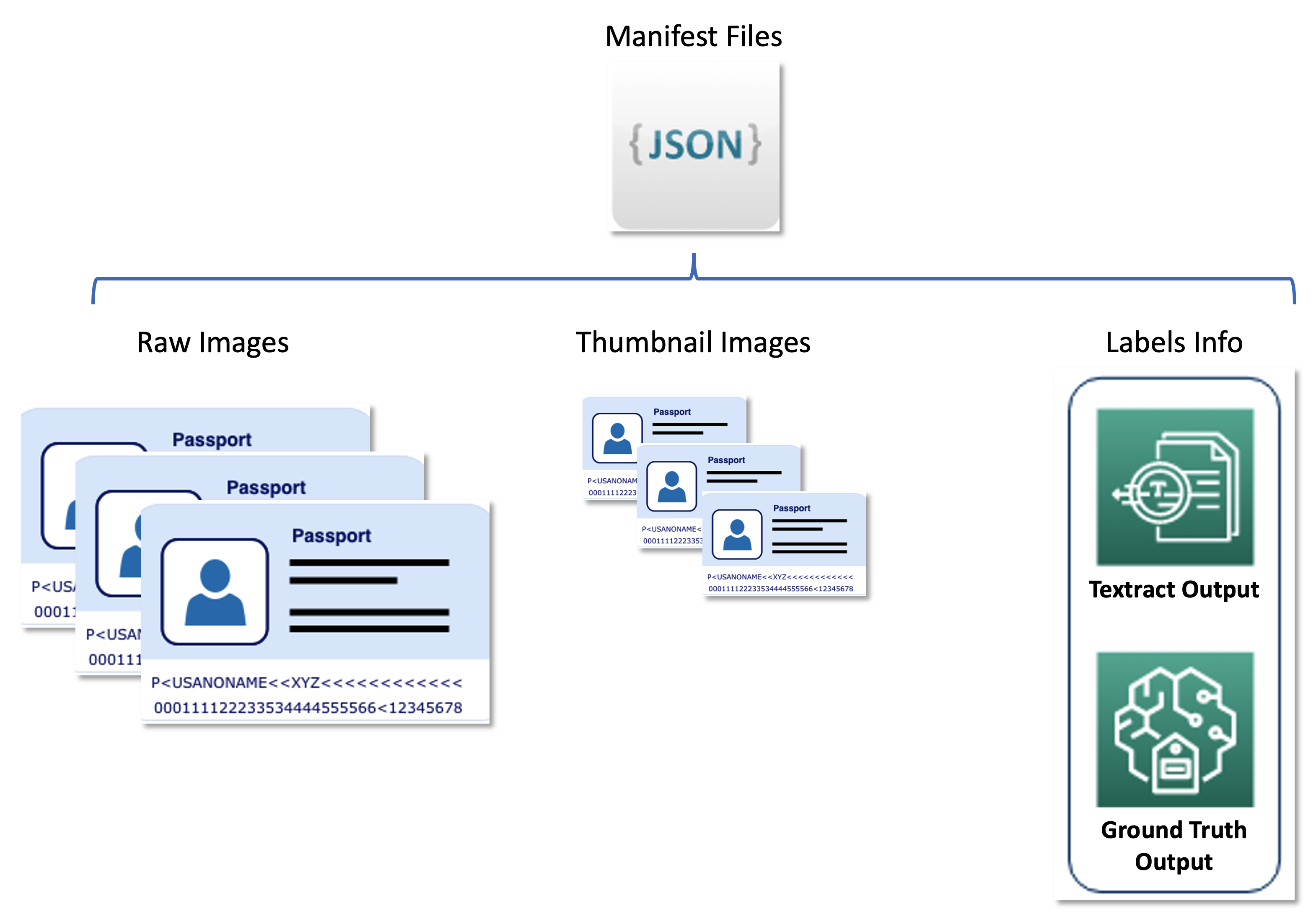
مجموعه داده اولیه برای این مشکل شامل ده ها هزار تصویر گذرنامه صفحه اصلی است که اطلاعات شخصی (نام، تاریخ تولد، شماره پاسپورت و غیره) باید از آنها استخراج شود. اندازه، طرح و ساختار تصویر بسته به کشور صادرکننده سند متفاوت است. ما این تصاویر را به مجموعهای از ریز عکسهای یکنواخت عادی میکنیم، که ورودی عملکردی خط لوله یادگیری فعال (برچسبگذاری خودکار و استنتاج) را تشکیل میدهند.
مجموعه داده دوم حاوی فایلهای مانیفست فرمتشده با خط JSON است که به تصاویر گذرنامه خام، تصاویر کوچک و اطلاعات برچسبها مانند برچسبهای نرم و موقعیتهای جعبه مرزی مربوط میشود. فایلهای مانیفست بهعنوان مجموعه ابردادهای عمل میکنند که نتایج حاصل از سرویسهای مختلف AWS را در قالبی یکپارچه ذخیره میکند و خط لوله یادگیری فعال را از سرویسهای پاییندستی استفادهشده توسط United جدا میکند. نمودار زیر این معماری را نشان می دهد.
کد زیر نمونه فایل مانیفست است:
اجزای راه حل
راه حل شامل دو جزء اصلی است:
- یک چارچوب ML، که مسئول آموزش مدل است
- یک خط لوله برچسب گذاری خودکار، که مسئول بهبود دقت مدل آموزش دیده به روشی مقرون به صرفه است.
چارچوب ML مسئول آموزش مدل ML و استقرار آن به عنوان نقطه پایانی SageMaker است. خط لوله برچسبگذاری خودکار بر خودکارسازی مشاغل SageMaker Ground Truth و نمونهبرداری از تصاویر برای برچسبگذاری از طریق آن مشاغل متمرکز است.
این دو جزء از یکدیگر جدا شدهاند و تنها از طریق مجموعه تصاویر برچسبگذاریشده تولید شده توسط خط لوله برچسبگذاری خودکار، تعامل دارند. یعنی خط لوله برچسبگذاری برچسبهایی ایجاد میکند که بعداً توسط چارچوب ML برای آموزش مدل ML استفاده میشوند.
چارچوب ML
تیم ML Solutions Lab چارچوب ML را با استفاده از اجرای Hugging Face مدل LayoutLMV2 ساخت (LayoutLMv2: پیش آموزش چند وجهی برای درک اسناد بصری غنی، یانگ زو و همکاران). آموزش بر اساس خروجیهای متن آمازون بود که بهعنوان پیشپردازنده عمل میکرد و جعبههای مرزی را در اطراف متن مورد علاقه تولید میکرد. این فریم ورک از آموزش توزیعشده استفاده میکند و بر روی یک کانتینر Docker سفارشی بر اساس تصویر از پیش ساخته شده Hugging Face SageMaker با وابستگیهای اضافی اجرا میشود (وابستگیهایی که در تصویر SageMaker Docker از پیش ساخته نشده اما برای Hugging Face LayoutLMv2 لازم است).
مدل ML برای طبقه بندی فیلدهای سند در 11 کلاس زیر آموزش داده شد:
خط لوله آموزش را می توان در نمودار زیر خلاصه کرد.
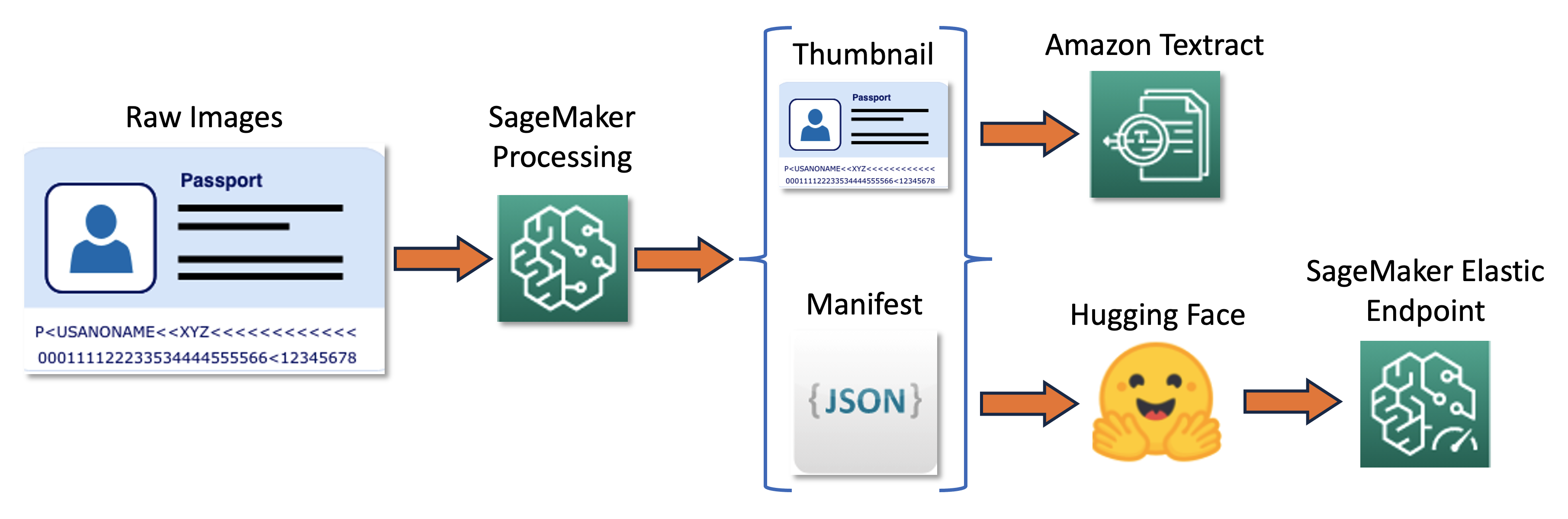
ابتدا، یک دسته از تصاویر خام را تغییر اندازه داده و به صورت ریز عکسها عادی می کنیم. در همان زمان، یک فایل مانیفست خط JSON با یک خط در هر تصویر با اطلاعاتی درباره تصاویر خام و کوچک از دسته ایجاد میشود. در مرحله بعد، ما از متن آمازون برای استخراج کادرهای محدود کننده متن در تصاویر کوچک استفاده می کنیم. تمام اطلاعات تولید شده توسط Amazon Texttract در همان فایل مانیفست ثبت می شود. در نهایت، ما از تصاویر کوچک و داده های مانیفست برای آموزش یک مدل استفاده می کنیم که بعداً به عنوان نقطه پایانی SageMaker به کار گرفته می شود.
خط لوله برچسب گذاری خودکار
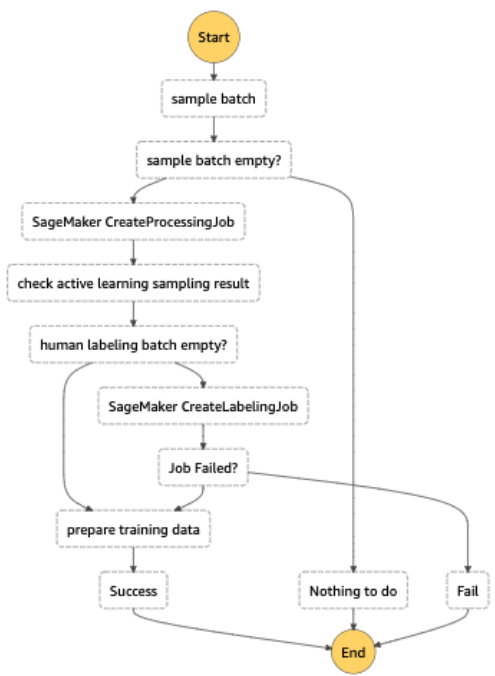
ما یک خط لوله برچسب گذاری خودکار طراحی کردیم که برای انجام عملکردهای زیر طراحی شده است:
- استنتاج دسته ای دوره ای را روی یک مجموعه داده بدون برچسب اجرا کنید.
- نتایج را بر اساس یک استراتژی نمونه گیری عدم قطعیت خاص فیلتر کنید.
- یک کار SageMaker Ground Truth را برای برچسب گذاری تصاویر نمونه برداری شده با استفاده از نیروی انسانی راه اندازی کنید.
- برای اصلاح مدل بعدی، تصاویر جدید برچسبگذاری شده را به مجموعه داده آموزشی اضافه کنید.
استراتژی نمونه گیری عدم قطعیت با انتخاب تصاویری که احتمالاً بیشترین سهم را در بهبود دقت مدل دارند، تعداد تصاویر ارسال شده به شغل برچسب زدن انسانی را کاهش می دهد. از آنجا که برچسب زدن به انسان یک کار پرهزینه است، چنین نمونه برداری یک روش مهم کاهش هزینه است. ما از چهار استراتژی نمونهگیری پشتیبانی میکنیم که میتوان آنها را بهعنوان پارامتر ذخیرهشده در آن انتخاب کرد فروشگاه پارامتر، قابلیتی از مدیر سیستم های AWS:
- کمترین اعتماد به نفس
- اطمینان حاشیه
- نسبت اعتماد به نفس
- آنتروپی
کل گردش کار برچسبگذاری خودکار با پیادهسازی شد توابع مرحله AWS، که کار پردازش را هماهنگ می کند (به نام نقطه پایانی الاستیک برای استنتاج دسته ای)، نمونه گیری عدم قطعیت، و SageMaker Ground Truth. نمودار زیر گردش کار توابع مرحله را نشان می دهد.
مقرون به صرفه
عامل اصلی موثر بر هزینه های برچسب گذاری، حاشیه نویسی دستی است. قبل از استقرار این راه حل، تیم United مجبور بود از یک رویکرد مبتنی بر قانون استفاده کند، که نیازمند حاشیه نویسی دستی گران قیمت و تکنیک های OCR تجزیه شخص ثالث بود. با راه حل ما، یونایتد حجم کاری برچسبگذاری دستی خود را با برچسبگذاری دستی فقط تصاویر کاهش داد که منجر به بزرگترین پیشرفتهای مدل میشد. از آنجایی که این چارچوب مبتنی بر مدل است، می توان از آن در سناریوهای مشابه دیگر استفاده کرد و ارزش آن را فراتر از تصاویر پاسپورت به مجموعه بسیار گسترده تری از اسناد گسترش داد.
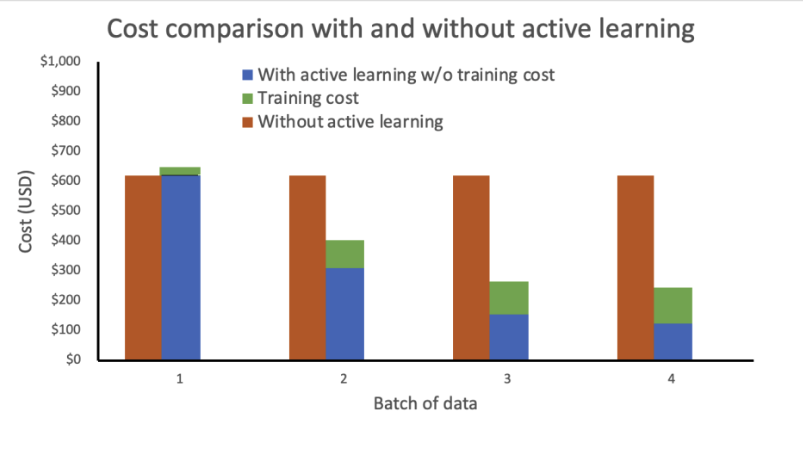
ما یک تحلیل هزینه را بر اساس مفروضات زیر انجام دادیم:
- هر دسته شامل 1,000 تصویر است
- آموزش با استفاده از نمونه mlg4dn.16xlarge انجام می شود
- استنتاج بر روی یک نمونه mlg4dn.xlarge انجام می شود
- آموزش بعد از هر دسته با 10% از برچسب های حاشیه نویسی انجام می شود
- هر دور از آموزش منجر به بهبود دقت زیر می شود:
- 50٪ پس از اولین بسته
- 25٪ پس از دسته دوم
- 10٪ پس از دسته سوم
تجزیه و تحلیل ما نشان می دهد که هزینه آموزش بدون یادگیری فعال ثابت و بالا می ماند. ترکیب یادگیری فعال منجر به کاهش تصاعدی هزینه ها با هر دسته جدید داده می شود.
ما با استفاده از نقطه پایانی استنتاج به عنوان یک نقطه پایانی کشسان با افزودن یک سیاست مقیاسبندی خودکار، هزینهها را کاهش دادیم. منابع نقطه پایانی میتوانند بین صفر و حداکثر تعداد نمونههای پیکربندیشده، افزایش یا کاهش پیدا کنند.
معماری راه حل نهایی
تمرکز ما این بود که به تیم یونایتد کمک کنیم تا ضمن ایجاد یک برنامه ابری مقیاس پذیر و انعطاف پذیر، نیازهای عملکردی خود را برآورده کند. تیم ML Solutions Lab راه حل آماده تولید کامل را با کمک AWS CDK، مدیریت خودکار و ارائه تمام منابع و خدمات ابری، توسعه داد. برنامه ابری نهایی به صورت تکی به کار گرفته شد AWS CloudFormation پشته با چهار پشته تو در تو که هر کدام یک جزء عملکردی واحد را نشان می دهند.
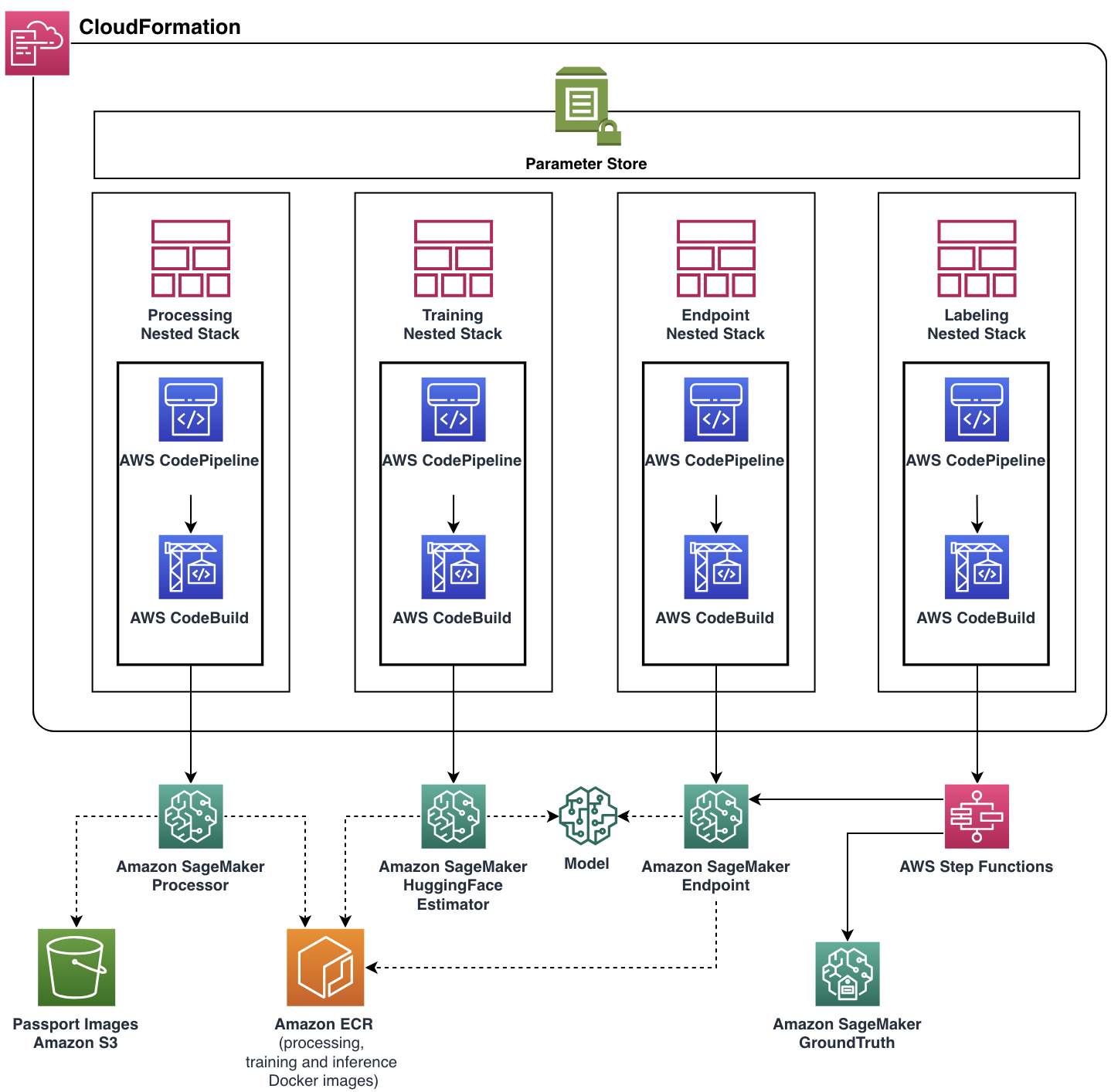
تقریباً همه ویژگیهای خط لوله، از جمله تصاویر Docker، خطمشی مقیاسبندی خودکار نقطه پایانی و موارد دیگر، از طریق Parameter Store پارامتربندی شدند. با چنین انعطافپذیری، همان نمونه خط لوله میتواند با طیف وسیعی از تنظیمات اجرا شود و توانایی آزمایش را اضافه کند.
نتیجه
در این پست، ما در مورد اینکه چگونه United Airlines، با همکاری آزمایشگاه راه حل های ML، یک چارچوب یادگیری فعال در AWS ایجاد کرد تا پردازش اسناد مسافر را خودکار کند، بحث کردیم. این راه حل تاثیر زیادی بر دو جنبه مهم از اهداف اتوماسیون یونایتد داشت:
- قابل استفاده مجدد - با توجه به طراحی مدولار و اجرای مدل-آگنوستیک، هواپیمایی یونایتد می تواند از این راه حل تقریباً در هر مورد دیگر با برچسب خودکار ML استفاده مجدد کند.
- کاهش مکرر هزینه - با ترکیب هوشمندانه فرآیندهای برچسبگذاری دستی و خودکار، تیم United میتواند هزینههای متوسط برچسبگذاری را کاهش داده و خدمات گران قیمت برچسبگذاری شخص ثالث را جایگزین کند.
اگر علاقه مند به پیاده سازی راه حل مشابهی هستید یا می خواهید درباره آزمایشگاه راه حل های ML اطلاعات بیشتری کسب کنید، با مدیر حساب خود تماس بگیرید یا از ما دیدن کنید آزمایشگاه راه حل های یادگیری ماشین آمازون.
درباره نویسنده
 شین گو دانشمند ارشد داده – یادگیری ماشین در بخش تجزیه و تحلیل پیشرفته و نوآوری United Airlines است. او کمک قابل توجهی به طراحی اتوماسیون درک اسناد به کمک یادگیری ماشینی کرد و نقشی کلیدی در گسترش جریانهای کار یادگیری فعال حاشیهنویسی داده در وظایف و مدلهای مختلف داشت. تخصص او در بالا بردن کارایی و کارایی هوش مصنوعی، دستیابی به پیشرفت های قابل توجه در زمینه پیشرفت های فناوری هوشمند در خطوط هوایی متحده است.
شین گو دانشمند ارشد داده – یادگیری ماشین در بخش تجزیه و تحلیل پیشرفته و نوآوری United Airlines است. او کمک قابل توجهی به طراحی اتوماسیون درک اسناد به کمک یادگیری ماشینی کرد و نقشی کلیدی در گسترش جریانهای کار یادگیری فعال حاشیهنویسی داده در وظایف و مدلهای مختلف داشت. تخصص او در بالا بردن کارایی و کارایی هوش مصنوعی، دستیابی به پیشرفت های قابل توجه در زمینه پیشرفت های فناوری هوشمند در خطوط هوایی متحده است.
 جان نلسون مدیر ارشد علوم داده و یادگیری ماشین در هواپیمایی متحده است.
جان نلسون مدیر ارشد علوم داده و یادگیری ماشین در هواپیمایی متحده است.
 الکس گوریانوف مهندس یادگیری ماشین در آمازون AWS است. او معماری میسازد و اجزای اصلی خط لوله یادگیری فعال و برچسبگذاری خودکار را که توسط AWS CDK طراحی شده است، پیادهسازی میکند. الکس متخصص MLOps، معماری محاسبات ابری، تجزیه و تحلیل داده های آماری و پردازش داده در مقیاس بزرگ است.
الکس گوریانوف مهندس یادگیری ماشین در آمازون AWS است. او معماری میسازد و اجزای اصلی خط لوله یادگیری فعال و برچسبگذاری خودکار را که توسط AWS CDK طراحی شده است، پیادهسازی میکند. الکس متخصص MLOps، معماری محاسبات ابری، تجزیه و تحلیل داده های آماری و پردازش داده در مقیاس بزرگ است.
 ویشال داس یک دانشمند کاربردی در آزمایشگاه راه حل های آمازون ML است. قبل از MLSL، ویشال یک معمار راه حل، انرژی، AWS بود. او دکترای خود را در ژئوفیزیک با مدرک دکترای جزئی در رشته آمار از دانشگاه استنفورد دریافت کرد. او متعهد به همکاری با مشتریان است تا به آنها کمک کند بزرگ فکر کنند و نتایج تجاری را ارائه دهند. او متخصص در یادگیری ماشین و کاربرد آن در حل مشکلات تجاری است.
ویشال داس یک دانشمند کاربردی در آزمایشگاه راه حل های آمازون ML است. قبل از MLSL، ویشال یک معمار راه حل، انرژی، AWS بود. او دکترای خود را در ژئوفیزیک با مدرک دکترای جزئی در رشته آمار از دانشگاه استنفورد دریافت کرد. او متعهد به همکاری با مشتریان است تا به آنها کمک کند بزرگ فکر کنند و نتایج تجاری را ارائه دهند. او متخصص در یادگیری ماشین و کاربرد آن در حل مشکلات تجاری است.
 تیانی مائو یک دانشمند کاربردی در AWS مستقر در منطقه شیکاگو است. او بیش از 5 سال تجربه در ساخت راه حل های یادگیری ماشینی و یادگیری عمیق دارد و بر بینایی کامپیوتر و یادگیری تقویتی با بازخوردهای انسانی تمرکز دارد. او از کار با مشتریان برای درک چالش های آنها و حل آنها با ایجاد راه حل های نوآورانه با استفاده از خدمات AWS لذت می برد.
تیانی مائو یک دانشمند کاربردی در AWS مستقر در منطقه شیکاگو است. او بیش از 5 سال تجربه در ساخت راه حل های یادگیری ماشینی و یادگیری عمیق دارد و بر بینایی کامپیوتر و یادگیری تقویتی با بازخوردهای انسانی تمرکز دارد. او از کار با مشتریان برای درک چالش های آنها و حل آنها با ایجاد راه حل های نوآورانه با استفاده از خدمات AWS لذت می برد.
 یونژی شی یک دانشمند کاربردی در آزمایشگاه راه حلهای آمازون ML است، جایی که با مشتریان در بخشهای مختلف صنعت کار میکند تا به آنها کمک کند تا راهحلهای AI/ML ساخته شده بر روی سرویسهای AWS Cloud را برای حل چالشهای تجاری خود ایدهبندی، توسعه و استقرار دهند. او با مشتریان در خودروسازی، زمین فضایی، حمل و نقل و تولید کار کرده است. یونژی دکترای خود را گرفت. در ژئوفیزیک از دانشگاه تگزاس در آستین.
یونژی شی یک دانشمند کاربردی در آزمایشگاه راه حلهای آمازون ML است، جایی که با مشتریان در بخشهای مختلف صنعت کار میکند تا به آنها کمک کند تا راهحلهای AI/ML ساخته شده بر روی سرویسهای AWS Cloud را برای حل چالشهای تجاری خود ایدهبندی، توسعه و استقرار دهند. او با مشتریان در خودروسازی، زمین فضایی، حمل و نقل و تولید کار کرده است. یونژی دکترای خود را گرفت. در ژئوفیزیک از دانشگاه تگزاس در آستین.
 دیگو سوکولینسکی یک مدیر ارشد علوم کاربردی در مرکز نوآوری هوش مصنوعی AWS است، جایی که او تیم تحویل را برای مناطق شرقی ایالات متحده و آمریکای لاتین رهبری می کند. او بیش از بیست سال تجربه در یادگیری ماشین و بینایی کامپیوتر دارد و دارای مدرک دکترا در ریاضیات از دانشگاه جان هاپکینز است.
دیگو سوکولینسکی یک مدیر ارشد علوم کاربردی در مرکز نوآوری هوش مصنوعی AWS است، جایی که او تیم تحویل را برای مناطق شرقی ایالات متحده و آمریکای لاتین رهبری می کند. او بیش از بیست سال تجربه در یادگیری ماشین و بینایی کامپیوتر دارد و دارای مدرک دکترا در ریاضیات از دانشگاه جان هاپکینز است.
 شین چن در حال حاضر رئیس آزمایشگاه راه حلهای علوم مردمی در Amazon People Experience Technology (PXT، با نام مستعار HR) Central Science است. او تیمی از دانشمندان کاربردی را رهبری می کند تا راه حل های علمی درجه تولید بسازند تا به طور فعال مکانیسم ها و بهبود فرآیند را شناسایی و راه اندازی کنند. پیش از این، او رئیس مرکز ایالات متحده، منطقه بزرگ چین، LATAM و Automotive Vertical در آزمایشگاه راهحلهای یادگیری ماشین AWS بود. او به مشتریان AWS کمک کرد تا راهحلهای یادگیری ماشینی را برای رسیدگی به بالاترین فرصتهای یادگیری ماشینی سرمایهگذاری در سازمانشان شناسایی و بسازند. شین عضو هیئت علمی دانشگاه نورث وسترن و موسسه فناوری ایلینویز است. وی دکترای خود را در رشته علوم و مهندسی کامپیوتر از دانشگاه نوتردام اخذ کرد.
شین چن در حال حاضر رئیس آزمایشگاه راه حلهای علوم مردمی در Amazon People Experience Technology (PXT، با نام مستعار HR) Central Science است. او تیمی از دانشمندان کاربردی را رهبری می کند تا راه حل های علمی درجه تولید بسازند تا به طور فعال مکانیسم ها و بهبود فرآیند را شناسایی و راه اندازی کنند. پیش از این، او رئیس مرکز ایالات متحده، منطقه بزرگ چین، LATAM و Automotive Vertical در آزمایشگاه راهحلهای یادگیری ماشین AWS بود. او به مشتریان AWS کمک کرد تا راهحلهای یادگیری ماشینی را برای رسیدگی به بالاترین فرصتهای یادگیری ماشینی سرمایهگذاری در سازمانشان شناسایی و بسازند. شین عضو هیئت علمی دانشگاه نورث وسترن و موسسه فناوری ایلینویز است. وی دکترای خود را در رشته علوم و مهندسی کامپیوتر از دانشگاه نوتردام اخذ کرد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/how-united-airlines-built-a-cost-efficient-optical-character-recognition-active-learning-pipeline/

