این پست با همکاری Daniele Chiappalupi، شرکتکننده تیم هکاتون دانشجویی AWS در ETH Zürich نوشته شده است.
همه می توانند به راحتی با استفاده از یادگیری ماشینی (ML) شروع کنند Amazon SageMaker JumpStart. در این پست، ما به شما نشان میدهیم که چگونه یک تیم دانشگاهی Hackathon از SageMaker JumpStart برای ساخت سریع برنامهای استفاده کرد که به کاربران کمک میکند تا تعصبات را شناسایی و حذف کنند.
«Amazon SageMaker در پروژه ما نقش اساسی داشت. این کار استقرار و مدیریت یک نمونه از پیش آموزش دیده Flan را آسان کرد و پایه محکمی برای برنامه ما به ما ارائه داد. ویژگی مقیاسپذیری خودکار آن در دورههای پرترافیک بسیار مهم بود، و اطمینان حاصل کرد که برنامه ما پاسخگو باقی میماند و کاربران یک تجزیه و تحلیل سوگیری ثابت و سریع دریافت میکنند. علاوه بر این، با اجازه دادن به ما برای تخلیه وظیفه سنگین جستجوی مدل Flan به یک سرویس مدیریت شده، ما توانستیم برنامه خود را سبک و سریع نگه داریم و تجربه کاربر را در دستگاه های مختلف افزایش دهیم. ویژگیهای SageMaker به ما این امکان را میدهد که زمان خود را در هکاتون به حداکثر برسانیم و به ما این امکان را میدهد تا به جای مدیریت عملکرد و زیرساخت مدل، روی بهینهسازی درخواستها و برنامههایمان تمرکز کنیم.
– دانیله چیاپالوپی، شرکتکننده تیم هکاتون دانشجویی AWS در ETH زوریخ.
بررسی اجمالی راه حل
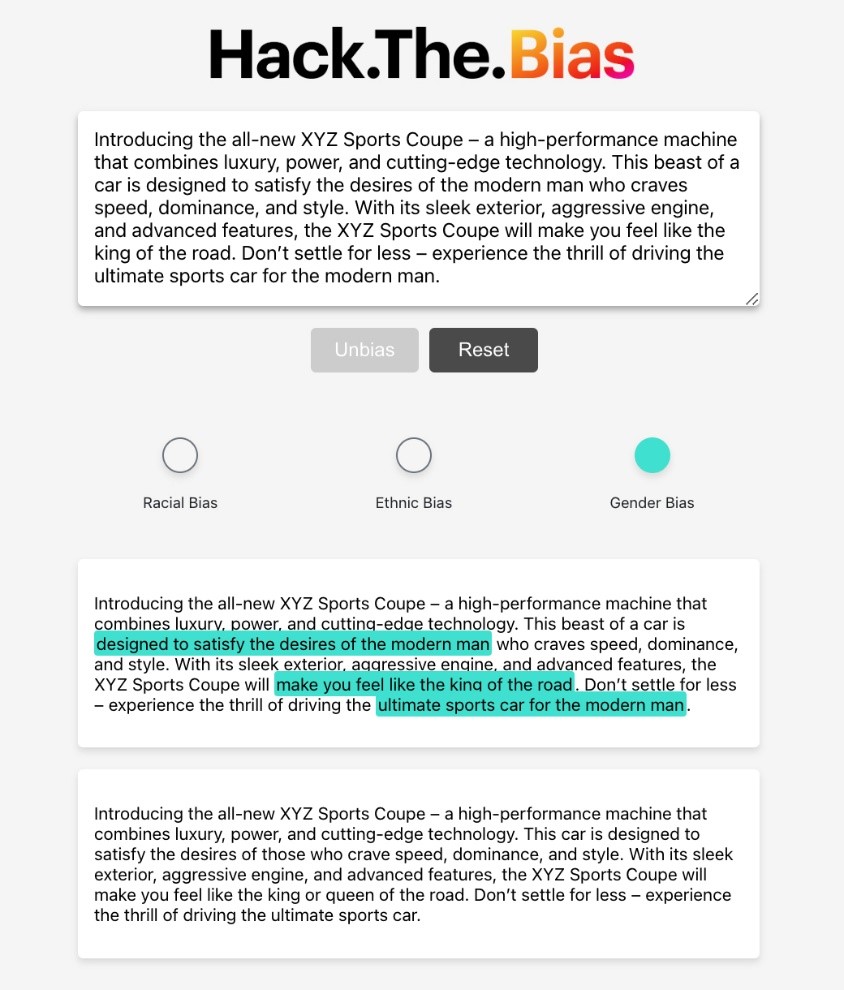
موضوع هکاتون کمک به اهداف پایدار سازمان ملل با فناوری هوش مصنوعی است. همانطور که در شکل زیر نشان داده شده است، اپلیکیشن ساخته شده در هکاتون به سه هدف توسعه پایدار (آموزش با کیفیت، هدف قرار دادن تبعیض مبتنی بر جنسیت و کاهش نابرابری ها) کمک می کند و به کاربران کمک می کند تا سوگیری ها را از متن خود شناسایی و حذف کنند تا عادلانه ترویج شود. و زبان فراگیر.

همانطور که در تصویر زیر نشان داده شده است، پس از ارائه متن، برنامه یک نسخه جدید تولید می کند که عاری از تعصبات نژادی، قومیتی و جنسیتی است. علاوه بر این، بخش های خاصی از متن ورودی شما را که مربوط به هر دسته از سوگیری است، برجسته می کند.
در معماری نشان داده شده در نمودار زیر، کاربران متن را در قسمت وارد می کنند واکنش نشان می دهندبرنامه وب مبتنی بر، که باعث می شود دروازه API آمازون، که به نوبه خود یک را فرا می خواند AWS لامبدا عملکرد بسته به تعصب در متن کاربر. تابع Lambda نقطه پایانی مدل Flan را در SageMaker JumpStart فراخوانی میکند، که نتیجه متن بیطرفانه را از طریق همان مسیر به برنامه front-end برمیگرداند.

فرآیند توسعه اپلیکیشن
روند توسعه این برنامه تکراری بود و بر دو حوزه اصلی متمرکز بود: رابط کاربری و یکپارچه سازی مدل ML.
ما React را به دلیل انعطاف پذیری، مقیاس پذیری و ابزارهای قدرتمند برای ایجاد رابط های کاربری تعاملی برای توسعه front-end انتخاب کردیم. با توجه به ماهیت برنامه ما - پردازش ورودی کاربر و ارائه نتایج اصلاح شده - معماری مبتنی بر مؤلفه React ایده آل بود. با React، میتوانیم یک برنامه کاربردی تک صفحهای بسازیم که به کاربران امکان میدهد متن ارسال کنند و بدون نیاز به بازخوانی دائمی صفحه، نتایج بیطرفانه را ببینند.
متن وارد شده توسط کاربر باید توسط یک مدل زبانی قدرتمند پردازش شود تا تعصبات را بررسی کند. ما Flan را به دلیل استحکام، کارایی و ویژگیهای مقیاسپذیری آن انتخاب کردیم. برای استفاده از Flan، همانطور که در تصویر زیر نشان داده شده است، از SageMaker JumpStart استفاده کردیم. آمازون SageMaker استقرار و مدیریت یک نمونه از پیش آموزشدیدهشده Flan را آسان کرد و به ما این امکان را میدهد که به جای مدیریت عملکرد و زیرساخت مدل، روی بهینهسازی درخواستها و درخواستهایمان تمرکز کنیم.

اتصال مدل Flan به برنامه front-end ما نیاز به یکپارچگی قوی و ایمن داشت که با استفاده از Lambda و API Gateway به دست آمد. با Lambda، ما یک تابع بدون سرور ایجاد کردیم که مستقیماً با مدل SageMaker ما ارتباط برقرار می کند. سپس از API Gateway برای ایجاد یک نقطه پایانی ایمن، مقیاسپذیر و به آسانی برای برنامه React خود برای فراخوانی تابع Lambda استفاده کردیم. هنگامی که کاربر متنی را ارسال میکرد، برنامه یک سری فراخوانی API را به دروازه راهاندازی میکرد - ابتدا برای شناسایی وجود هرگونه سوگیری، سپس در صورت لزوم، درخواستهای اضافی برای شناسایی، مکانیابی و خنثی کردن سوگیری. همه این درخواستها از طریق تابع Lambda و سپس به مدل SageMaker ما هدایت شدند.
وظیفه نهایی ما در فرآیند توسعه، انتخاب اعلان هایی برای پرس و جو از مدل زبان بود. در اینجا، مجموعه دادههای CrowS-Pairs نقش مهمی ایفا کردند، زیرا نمونههای واقعی متن مغرضانه را در اختیار ما قرار میداد، که ما از آنها برای تنظیم دقیق درخواستهای خود استفاده میکردیم. ما دستورات را با یک فرآیند تکراری انتخاب کردیم، با هدف به حداکثر رساندن دقت در تشخیص سوگیری در این مجموعه داده.
با پایان دادن به فرآیند، ما یک جریان عملیاتی یکپارچه را در برنامه نهایی مشاهده کردیم. این فرآیند با ارسال متنی توسط کاربر برای تجزیه و تحلیل آغاز می شود، که سپس از طریق یک درخواست POST به نقطه پایانی امن API Gateway ما ارسال می شود. این تابع Lambda را فعال می کند که با نقطه پایانی SageMaker ارتباط برقرار می کند. در نتیجه، مدل Flan یک سری پرس و جو دریافت می کند. ابتدا وجود هرگونه سوگیری در متن را بررسی می کند. اگر سوگیری ها شناسایی شوند، پرس و جوهای اضافی برای مکان یابی، شناسایی و خنثی کردن این عناصر مغرضانه مستقر می شوند. سپس نتایج از طریق همان مسیر – ابتدا به تابع Lambda، سپس از طریق دروازه API و در نهایت به کاربر بازگردانده میشوند. اگر هر گونه سوگیری در متن اصلی وجود داشته باشد، کاربر یک تحلیل جامع دریافت می کند که انواع سوگیری های شناسایی شده، اعم از نژادی، قومیتی یا جنسیتی را نشان می دهد. بخشهای خاصی از متن که این سوگیریها در آنها یافت میشوند برجسته میشوند و به کاربران دید واضحی از تغییرات ایجاد شده میدهند. در کنار این تحلیل، یک نسخه جدید و بدون تعصب از متن آنها ارائه شده است که به طور موثر ورودی بالقوه مغرضانه را به روایتی فراگیرتر تبدیل می کند.
در بخش های بعدی مراحل اجرای این راه حل را به تفصیل شرح می دهیم.
محیط React را راه اندازی کنید
ما با راه اندازی محیط توسعه خود برای React شروع کردیم. برای بوت استرپ یک برنامه جدید React با حداقل پیکربندی، از Create-react-app استفاده کردیم:
npx create-react-app my-app
رابط کاربری را بسازید
با استفاده از React، ما یک رابط کاربری ساده برای وارد کردن متن توسط کاربران با دکمه ارسال، دکمه بازنشانی و نمایشگرهایی برای نمایش نتایج پردازش شده در زمانی که در دسترس هستند طراحی کردیم.
مدل Flan را در SageMaker راه اندازی کنید
ما از SageMaker برای ایجاد یک نمونه از پیش آموزش دیده از مدل زبان Flan با نقطه پایانی برای استنتاج بلادرنگ استفاده کردیم. این مدل را می توان در برابر هر باری با ساختار JSON مانند موارد زیر استفاده کرد:
یک تابع Lambda ایجاد کنید
ما یک تابع Lambda ایجاد کردیم که مستقیماً با نقطه پایانی SageMaker ما تعامل داشت. این تابع به گونه ای طراحی شده است که درخواستی را با متن کاربر دریافت کند، آن را به نقطه پایانی SageMaker ارسال کند و نتایج اصلاح شده را برگرداند، همانطور که در کد زیر نشان داده شده است (ENDPOINT_NAME به عنوان نقطه پایانی نمونه SageMaker تنظیم شد):
راه اندازی API Gateway
ما یک REST API جدید را در API Gateway پیکربندی کردیم و آن را به تابع Lambda خود پیوند دادیم. این اتصال به برنامه React ما اجازه داد تا درخواستهای HTTP را به دروازه API ارسال کند، که متعاقباً عملکرد Lambda را فعال کرد.
برنامه React را با API ادغام کنید
ما برنامه React را بهروزرسانی کردیم تا با کلیک روی دکمه ارسال، یک درخواست POST به دروازه API ایجاد کند، در حالی که متن درخواست، متن کاربر است. کد جاوا اسکریپتی که برای انجام فراخوانی API استفاده کردیم به شرح زیر است (REACT_APP_AWS_ENDPOINT مربوط به نقطه پایانی API Gateway است که به تماس Lambda محدود شده است):
بهینه سازی انتخاب سریع
برای بهبود دقت تشخیص سوگیری، اعلان های مختلفی را در برابر مجموعه داده CrowS-Pairs آزمایش کردیم. از طریق این فرآیند تکراری، دستوراتی را انتخاب کردیم که بالاترین دقت را به ما میداد.
برنامه React را در Vercel اجرا و آزمایش کنید
پس از ساخت برنامه، آن را در Vercel مستقر کردیم تا در دسترس عموم قرار گیرد. ما آزمایشهای گستردهای انجام دادیم تا اطمینان حاصل کنیم که برنامه مطابق انتظار عمل میکند، از رابط کاربری گرفته تا پاسخهای مدل زبان.
این مراحل زمینه را برای ایجاد برنامه کاربردی ما برای تجزیه و تحلیل و تعصب زدایی متن فراهم کرد. علیرغم پیچیدگی ذاتی این فرآیند، استفاده از ابزارهایی مانند SageMaker، Lambda و API Gateway توسعه را ساده کرد و به ما اجازه داد بر روی هدف اصلی پروژه - شناسایی و حذف تعصبات در متن - تمرکز کنیم.
نتیجه
SageMaker JumpStart یک راه راحت برای کشف ویژگی ها و قابلیت های SageMaker ارائه می دهد. راهحلهای تکمرحلهای، نوتبوکهای نمونه، و مدلهای از پیش آموزشدیده قابل استقرار را ارائه میدهد. این منابع به شما امکان می دهد تا به سرعت SageMaker را یاد بگیرید و درک کنید. علاوه بر این، شما این امکان را دارید که مدل ها را به دقت تنظیم کنید و آنها را بر اساس نیازهای خاص خود به کار بگیرید. دسترسی به JumpStart از طریق در دسترس است Amazon SageMaker Studio یا به صورت برنامه نویسی با استفاده از API های SageMaker.
در این پست، شما یاد گرفتید که چگونه یک تیم دانشجویی Hackathon با استفاده از SageMaker JumpStart راه حلی را در مدت زمان کوتاهی توسعه دادند، که نشان دهنده پتانسیل AWS و SageMaker JumpStart در ایجاد امکان توسعه سریع و استقرار راه حل های پیشرفته هوش مصنوعی، حتی توسط تیم ها یا افراد کوچک است.
برای کسب اطلاعات بیشتر در مورد استفاده از SageMaker JumpStart، مراجعه کنید دستورالعمل تنظیم دقیق FLAN T5 XL با Amazon SageMaker Jumpstart و درخواست صفر شات برای مدل پایه Flan-T5 در آمازون SageMaker JumpStart.
ETH Analytics Club میزبان «ETH Datathon» یک هکاتون AI/ML بود که بیش از 150 شرکتکننده از ETH زوریخ، دانشگاه زوریخ و EPFL را جذب میکند. این رویداد دارای کارگاه های آموزشی به رهبری رهبران صنعت، چالش کدنویسی 24 ساعته و فرصت های شبکه ای ارزشمند با دانشجویان و متخصصان صنعت است. با تشکر فراوان از تیم هکاتون ETH: دانیله چیاپالوپی، آتینا نیسیوتی، و فرانچسکو ایگنازیو ری، و همچنین بقیه تیم سازماندهی AWS: آلیس مورانو، دمیر کاتویک، ایانا پیکس، یان اولیور سیدنفوس، لارس نتمن، و مارکوس وینترهولر.
مطالب و نظرات این پست متعلق به نویسنده شخص ثالث است و AWS مسئولیتی در قبال محتوا یا صحت این پست ندارد.
درباره نویسندگان
 جون ژانگ یک معمار Solutions مستقر در زوریخ است. او به مشتریان سوئیسی کمک می کند تا راه حل های مبتنی بر ابر را برای دستیابی به پتانسیل تجاری خود معمار کنند. او به پایداری علاقه دارد و تلاش می کند تا چالش های پایداری فعلی را با فناوری حل کند. او همچنین یک طرفدار بزرگ تنیس است و از بازی های رومیزی بسیار لذت می برد.
جون ژانگ یک معمار Solutions مستقر در زوریخ است. او به مشتریان سوئیسی کمک می کند تا راه حل های مبتنی بر ابر را برای دستیابی به پتانسیل تجاری خود معمار کنند. او به پایداری علاقه دارد و تلاش می کند تا چالش های پایداری فعلی را با فناوری حل کند. او همچنین یک طرفدار بزرگ تنیس است و از بازی های رومیزی بسیار لذت می برد.
 موهان گودا تیم یادگیری ماشین را در AWS سوئیس رهبری می کند. او در درجه اول با مشتریان Automotive کار می کند تا راه حل ها و پلت فرم های خلاقانه AI/ML را برای وسایل نقلیه نسل بعدی توسعه دهد. موهان قبل از کار با AWS با یک شرکت مشاوره مدیریت جهانی با تمرکز بر استراتژی و تجزیه و تحلیل کار می کرد. اشتیاق او در وسایل نقلیه متصل و رانندگی مستقل نهفته است.
موهان گودا تیم یادگیری ماشین را در AWS سوئیس رهبری می کند. او در درجه اول با مشتریان Automotive کار می کند تا راه حل ها و پلت فرم های خلاقانه AI/ML را برای وسایل نقلیه نسل بعدی توسعه دهد. موهان قبل از کار با AWS با یک شرکت مشاوره مدیریت جهانی با تمرکز بر استراتژی و تجزیه و تحلیل کار می کرد. اشتیاق او در وسایل نقلیه متصل و رانندگی مستقل نهفته است.
 ماتتیاس اگلی رئیس آموزش و پرورش سوئیس است. او یک رهبر تیم مشتاق با تجربه گسترده در توسعه تجارت، فروش و بازاریابی است.
ماتتیاس اگلی رئیس آموزش و پرورش سوئیس است. او یک رهبر تیم مشتاق با تجربه گسترده در توسعه تجارت، فروش و بازاریابی است.
 کمنگ ژانگ یک مهندس ML مستقر در زوریخ است. او به مشتریان جهانی کمک می کند تا برنامه های کاربردی مبتنی بر ML را طراحی، توسعه و مقیاس کنند تا قابلیت های دیجیتالی خود را برای افزایش درآمد کسب و کار و کاهش هزینه تقویت کنند. او همچنین علاقه زیادی به ایجاد برنامه های کاربردی انسان محور با استفاده از دانش علوم رفتاری دارد. او به ورزش های آبی و سگ گردانی علاقه دارد.
کمنگ ژانگ یک مهندس ML مستقر در زوریخ است. او به مشتریان جهانی کمک می کند تا برنامه های کاربردی مبتنی بر ML را طراحی، توسعه و مقیاس کنند تا قابلیت های دیجیتالی خود را برای افزایش درآمد کسب و کار و کاهش هزینه تقویت کنند. او همچنین علاقه زیادی به ایجاد برنامه های کاربردی انسان محور با استفاده از دانش علوم رفتاری دارد. او به ورزش های آبی و سگ گردانی علاقه دارد.
 دانیله چیاپالوپی اخیراً از ETH زوریخ فارغ التحصیل شده است. او از هر جنبه ای از مهندسی نرم افزار، از طراحی تا پیاده سازی، و از استقرار تا تعمیر و نگهداری لذت می برد. او اشتیاق عمیقی به هوش مصنوعی دارد و مشتاقانه منتظر کاوش، استفاده و مشارکت در آخرین پیشرفتها در این زمینه است. در اوقات فراغت، او عاشق اسنوبورد سواری در ماه های سردتر و بازی بسکتبال پیک آپ در هنگام گرم شدن هوا است.
دانیله چیاپالوپی اخیراً از ETH زوریخ فارغ التحصیل شده است. او از هر جنبه ای از مهندسی نرم افزار، از طراحی تا پیاده سازی، و از استقرار تا تعمیر و نگهداری لذت می برد. او اشتیاق عمیقی به هوش مصنوعی دارد و مشتاقانه منتظر کاوش، استفاده و مشارکت در آخرین پیشرفتها در این زمینه است. در اوقات فراغت، او عاشق اسنوبورد سواری در ماه های سردتر و بازی بسکتبال پیک آپ در هنگام گرم شدن هوا است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/innovation-for-inclusion-hack-the-bias-with-amazon-sagemaker/

