این پست مشترک نوشته شده توسط لایدوس و AWS. Leidos یکی از رهبران راهحلهای علم و فناوری FORTUNE 500 است که برای رسیدگی به برخی از سختترین چالشهای جهان در بازارهای دفاع، اطلاعات، امنیت داخلی، عمران و مراقبتهای بهداشتی تلاش میکند.
Leidos با AWS همکاری کرده است تا رویکردی برای حفظ حریم خصوصی و مدلسازی یادگیری ماشین محرمانه (ML) ایجاد کند که در آن خطوط لوله رمزگذاری شده با قابلیت ابر ایجاد میشود.
رمزگذاری همومورفیک رویکرد جدیدی برای رمزگذاری است که به منظور حفظ حریم خصوصی در مواردی که سیاستی دارید که بیان میکند دادهها هرگز نباید رمزگشایی شوند، اجازه میدهد محاسبات و توابع تحلیلی بر روی دادههای رمزگذاریشده بدون نیاز به رمزگشایی اجرا شوند. رمزگذاری کاملا هممورفیک (FHE) قویترین مفهوم این نوع رویکرد است و به شما امکان میدهد ارزش دادههای خود را در جایی که اعتماد صفر کلید است، باز کنید. نیاز اصلی این است که داده ها باید بتوانند با اعداد از طریق یک تکنیک رمزگذاری نمایش داده شوند، که می تواند در مجموعه داده های عددی، متنی و تصویری اعمال شود. دادههایی که از FHE استفاده میکنند از نظر اندازه بزرگتر هستند، بنابراین برای برنامههایی که نیاز به استنتاج در زمان واقعی یا با محدودیتهای اندازه دارند، باید آزمایش انجام شود. همچنین مهم است که تمام محاسبات را به صورت معادلات خطی بیان کنیم.
در این پست، نحوه فعالسازی پیشبینیهای ML حفظ حریم خصوصی را برای محیطهای بسیار تنظیمشده نشان میدهیم. پیش بینی ها (استنتاج) از داده های رمزگذاری شده استفاده می کنند و نتایج فقط توسط مصرف کننده نهایی (سمت مشتری) رمزگشایی می شوند.
برای نشان دادن این موضوع، نمونه ای از سفارشی سازی an را نشان می دهیم آمازون SageMaker Scikit-Learn، منبع باز، ظرف یادگیری عمیق برای فعال کردن یک نقطه پایانی مستقر برای پذیرش درخواستهای استنتاج رمزگذاریشده سمت مشتری. اگرچه این مثال نحوه انجام این کار را برای عملیات استنتاج نشان می دهد، می توانید راه حل را به آموزش و سایر مراحل ML گسترش دهید.
نقاط پایانی با چند کلیک یا خط کد با استفاده از SageMaker مستقر می شوند، که فرآیند ساخت و آموزش ML و مدل های یادگیری عمیق در ابر را برای توسعه دهندگان و کارشناسان ML ساده می کند. مدلهایی که با استفاده از SageMaker ساخته شدهاند، میتوانند به عنوان مستقر شوند نقاط پایانی بلادرنگ، که برای بارهای کاری استنتاج که در آن نیازهای زمان واقعی، حالت پایدار و تاخیر کم دارید بسیار مهم است. برنامه ها و خدمات می توانند به طور مستقیم یا از طریق یک سرور بدون سرور مستقر شده، نقطه پایانی مستقر شده را فراخوانی کنند دروازه API آمازون معماری. برای کسب اطلاعات بیشتر در مورد بهترین شیوه های معماری نقطه پایانی بلادرنگ، به ایجاد یک REST API مبتنی بر یادگیری ماشینی با الگوهای نقشه برداری Amazon API Gateway و Amazon SageMaker. شکل زیر هر دو نسخه از این الگوها را نشان می دهد.
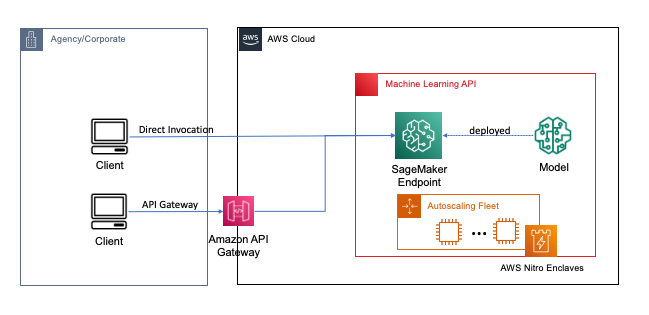
در هر دوی این الگوها، رمزگذاری در حین انتقال، محرمانه بودن را فراهم میکند، زیرا دادهها از طریق سرویسها برای انجام عملیات استنتاج جریان مییابند. هنگامی که توسط نقطه پایانی SageMaker دریافت می شود، داده ها به طور کلی برای انجام عملیات استنتاج در زمان اجرا رمزگشایی می شوند و برای هیچ کد و فرآیند خارجی غیرقابل دسترسی هستند. برای دستیابی به سطوح بیشتر حفاظت، FHE عملیات استنتاج را قادر می سازد تا نتایج رمزگذاری شده ای تولید کند که نتایج را می توان توسط یک برنامه کاربردی یا مشتری قابل اعتماد رمزگشایی کرد.
اطلاعات بیشتر در مورد رمزگذاری کاملا هممورفیک
FHE سیستم ها را قادر می سازد تا محاسبات را روی داده های رمزگذاری شده انجام دهند. محاسبات حاصل، وقتی رمزگشایی می شوند، به طور قابل کنترلی نزدیک به محاسباتی هستند که بدون فرآیند رمزگذاری تولید می شوند. FHE می تواند منجر به یک عدم دقت ریاضی کوچک، شبیه به یک خطای ممیز شناور، به دلیل نویز تزریق شده به محاسبات شود. با انتخاب پارامترهای رمزگذاری مناسب FHE، که یک پارامتر تنظیم شده خاص مشکل است، کنترل می شود. برای اطلاعات بیشتر، ویدیو را بررسی کنید رمزگذاری هممورفیک را چگونه توضیح می دهید؟
نمودار زیر نمونه ای از پیاده سازی یک سیستم FHE را ارائه می دهد.
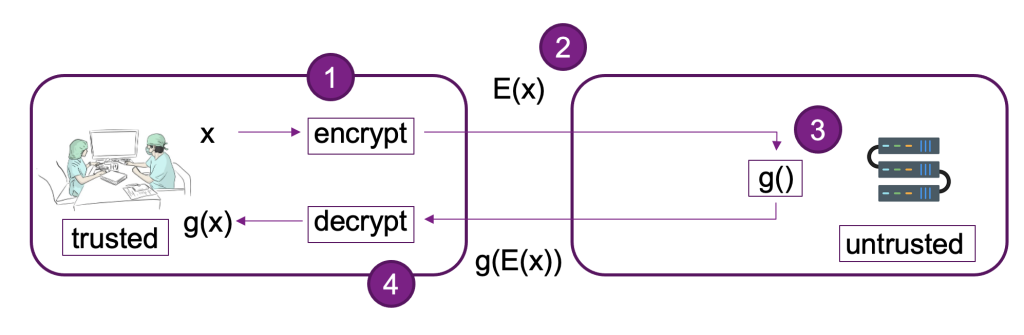
در این سیستم شما یا مشتری مورد اعتمادتان می توانید کارهای زیر را انجام دهید:
- داده ها را با استفاده از یک طرح کلید عمومی FHE رمزگذاری کنید. چند طرح مختلف قابل قبول وجود دارد. در این مثال، ما از طرح CKKS استفاده می کنیم. برای کسب اطلاعات بیشتر در مورد فرآیند رمزگذاری کلید عمومی FHE که انتخاب کردیم، به ادامه مطلب مراجعه کنید CKKS توضیح داد.
- داده های رمزگذاری شده سمت سرویس گیرنده را برای پردازش به یک ارائه دهنده یا سرور ارسال کنید.
- انجام استنتاج مدل بر روی داده های رمزگذاری شده؛ با FHE، نیازی به رمزگشایی نیست.
- نتایج رمزگذاریشده به تماسگیرنده برگردانده میشود و سپس رمزگشایی میشود تا نتیجه شما با استفاده از کلید خصوصی که فقط در اختیار شما یا کاربران مورد اعتماد شما در مشتری است، آشکار شود.
ما از معماری قبلی برای تنظیم نمونه ای با استفاده از نقاط پایانی SageMaker استفاده کرده ایم. Pyfhel به عنوان یک بسته بندی API FHE که ادغام با برنامه های ML را ساده می کند و SEAL به عنوان جعبه ابزار رمزگذاری FHE اساسی ما.
بررسی اجمالی راه حل
ما نمونه ای از خط لوله FHE مقیاس پذیر در AWS با استفاده از یک ساخته شده است رگرسیون لجستیک SKLearn ظرف یادگیری عمیق با مجموعه داده عنبیه. ما کاوش داده ها و مهندسی ویژگی ها را با استفاده از یک نوت بوک SageMaker انجام می دهیم و سپس آموزش مدل را با استفاده از شغل آموزش SageMaker. مدل به دست آمده است مستقر به یک نقطه پایانی بلادرنگ SageMaker برای استفاده توسط خدمات مشتری، همانطور که در نمودار زیر نشان داده شده است.
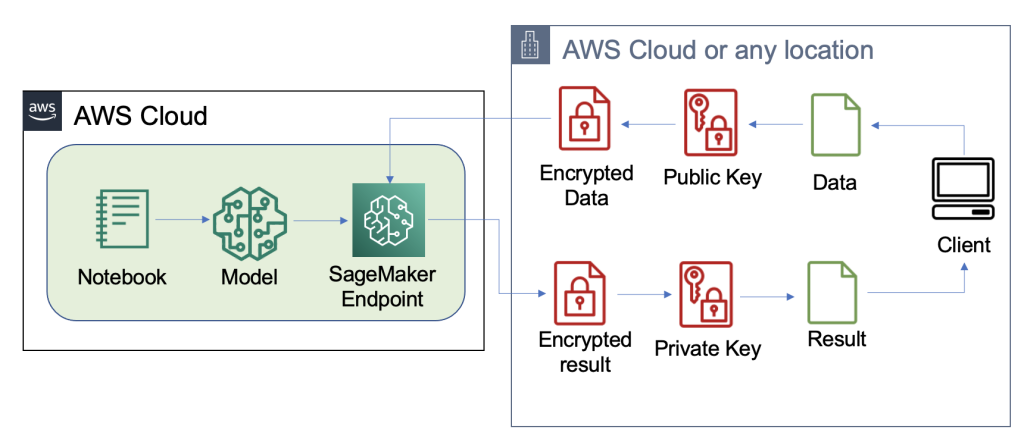
در این معماری، فقط اپلیکیشن کلاینت داده های رمزگذاری نشده را می بیند. داده های پردازش شده از طریق مدل برای استنباط در طول چرخه عمر خود رمزگذاری می شوند، حتی در زمان اجرا در پردازنده در ایزوله. AWS Nitro Enclave. در بخشهای بعدی، کد ساخت این خط لوله را مرور میکنیم.
پیش نیازها
برای پیگیری، فرض می کنیم که شما یک را راه اندازی کرده اید نوت بوک SageMaker با هویت AWS و مدیریت دسترسی (IAM) نقش با AmazonSageMakerFullAccess سیاست مدیریت شده
مدل را آموزش دهید
نمودار زیر روند کار آموزش مدل را نشان می دهد.
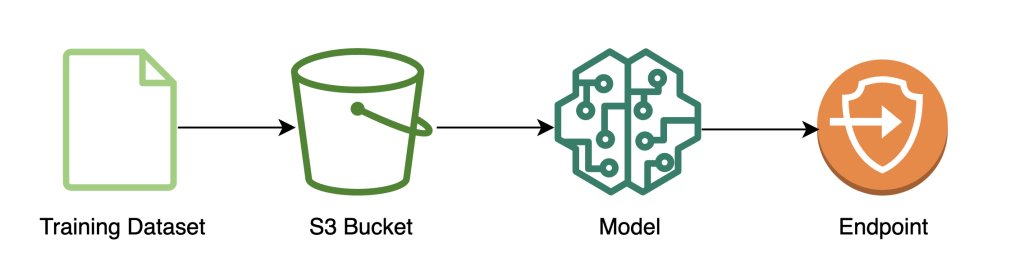
کد زیر نشان می دهد که چگونه ابتدا داده ها را برای آموزش با استفاده از نوت بوک های SageMaker با کشیدن مجموعه داده های آموزشی خود، انجام عملیات تمیز کردن لازم و سپس آپلود داده ها در یک دفترچه یادداشت آماده می کنیم. سرویس ذخیره سازی ساده آمازون سطل (Amazon S3). در این مرحله، ممکن است لازم باشد مهندسی ویژگی های اضافی مجموعه داده خود را انجام دهید یا با فروشگاه های ویژگی آفلاین مختلف ادغام کنید.
در این مثال، ما از حالت اسکریپت در یک چارچوب بومی پشتیبانی شده در SageMaker (یادگیری)، جایی که برآوردگر پیشفرض SageMaker SKLearn را با یک اسکریپت آموزشی سفارشی برای مدیریت دادههای رمزگذاریشده در حین استنتاج نمونهسازی میکنیم. برای مشاهده اطلاعات بیشتر در مورد چارچوب های پشتیبانی شده بومی و حالت اسکریپت، مراجعه کنید از Framework های یادگیری ماشینی، پایتون و R با Amazon SageMaker استفاده کنید.
در نهایت، مدل خود را روی مجموعه داده آموزش میدهیم و مدل آموزشدیده خود را در نوع نمونه انتخابی خود مستقر میکنیم.
در این مرحله، ما یک مدل سفارشی SKLearn FHE را آموزش دادهایم و آن را در یک نقطه پایانی استنتاج بلادرنگ SageMaker که آماده پذیرش دادههای رمزگذاریشده است، مستقر کردهایم.
رمزگذاری و ارسال داده های مشتری
نمودار زیر روند کار رمزگذاری و ارسال داده های مشتری به مدل را نشان می دهد.
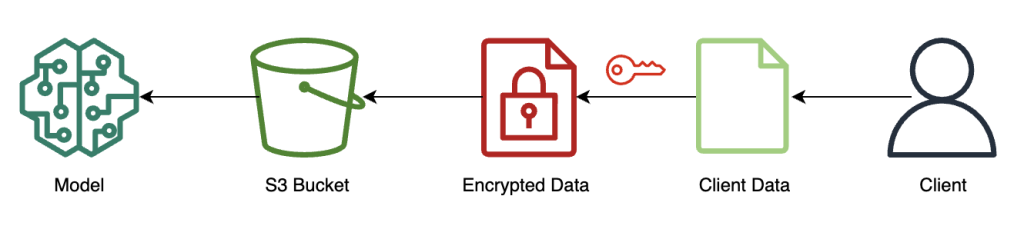
در بیشتر موارد، محموله تماس با نقطه پایانی استنتاج، حاوی داده های رمزگذاری شده است نه اینکه ابتدا آن را در آمازون S3 ذخیره کند. ما این کار را در این مثال انجام میدهیم زیرا تعداد زیادی رکورد را در فراخوانی استنتاج با هم جمع کردهایم. در عمل، این اندازه دسته کوچکتر خواهد بود یا به جای آن از تبدیل دسته ای استفاده می شود. استفاده از Amazon S3 به عنوان یک واسطه برای FHE لازم نیست.
اکنون که نقطه پایانی استنتاج تنظیم شده است، می توانیم ارسال داده ها را شروع کنیم. ما معمولاً از مجموعه دادههای آزمایشی و آموزشی مختلفی استفاده میکنیم، اما برای این مثال از مجموعه دادههای آموزشی مشابهی استفاده میکنیم.
ابتدا مجموعه داده Iris را در سمت کلاینت بارگذاری می کنیم. در مرحله بعد، زمینه FHE را با استفاده از Pyfhel تنظیم می کنیم. ما Pyfhel را برای این فرآیند انتخاب کردیم زیرا نصب و کار با آن ساده است، شامل طرحوارههای محبوب FHE میشود، و بر پیادهسازی رمزگذاری منبع باز زیربنای قابل اعتماد متکی است. SEAL. در این مثال، ما دادههای رمزگذاری شده را به همراه اطلاعات کلیدهای عمومی برای این طرح FHE به سرور ارسال میکنیم، که نقطه پایانی را قادر میسازد تا نتیجه را رمزگذاری کند تا با پارامترهای لازم FHE ارسال شود، اما به آن اجازه نمیدهد. توانایی رمزگشایی داده های دریافتی کلید خصوصی فقط نزد مشتری می ماند که قابلیت رمزگشایی نتایج را دارد.
پس از اینکه دادههای خود را رمزگذاری کردیم، یک فرهنگ لغت کامل داده را - شامل کلیدهای مربوطه و دادههای رمزگذاریشده - برای ذخیره در آمازون S3 گرد هم میآوریم. پس از آن، مدل پیشبینیهای خود را بر روی دادههای رمزگذاریشده از مشتری انجام میدهد، همانطور که در کد زیر نشان داده شده است. توجه داشته باشید که ما کلید خصوصی را ارسال نمی کنیم، بنابراین میزبان مدل قادر به رمزگشایی داده ها نیست. در این مثال، ما داده ها را به عنوان یک شی S3 ارسال می کنیم. متناوبا، آن داده ها ممکن است مستقیماً به نقطه پایانی Sagemaker ارسال شوند. به عنوان یک نقطه پایانی بلادرنگ، payload حاوی پارامتر داده در بدنه درخواست است که در مستندات SageMaker.
تصویر زیر پیش بینی مرکزی را نشان می دهد fhe_train.py (پیوست کل اسکریپت آموزشی را نشان می دهد).
ما در حال محاسبه نتایج رگرسیون لجستیک رمزگذاری شده خود هستیم. این کد یک محصول اسکالر رمزگذاری شده را برای هر کلاس ممکن محاسبه می کند و نتایج را به مشتری برمی گرداند. نتایج، لاجیت های پیش بینی شده برای هر کلاس در تمام مثال ها هستند.
مشتری نتایج رمزگشایی شده را برمی گرداند
نمودار زیر روند کار مشتری را نشان می دهد که نتیجه رمزگذاری شده خود را بازیابی می کند و آن را رمزگشایی می کند (با کلید خصوصی که فقط آنها به آن دسترسی دارند) تا نتیجه استنتاج را آشکار کند.
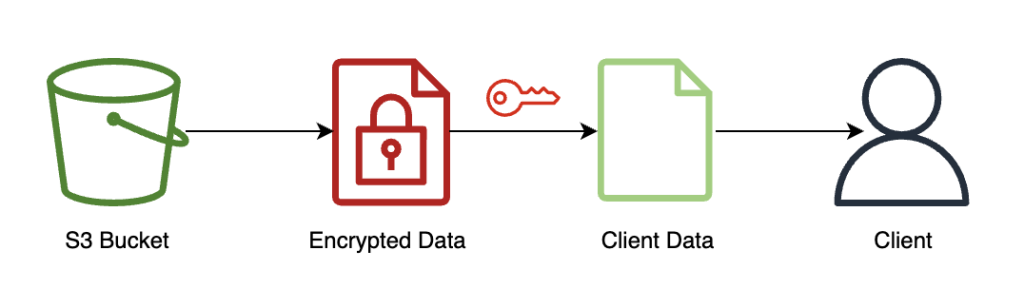
در این مثال، نتایج در آمازون S3 ذخیره میشوند، اما به طور کلی از طریق بارگذاری نقطه پایانی بلادرنگ بازگردانده میشوند. استفاده از Amazon S3 به عنوان یک واسطه برای FHE لازم نیست.
نتیجه استنتاج به طور قابل کنترلی نزدیک به نتایج خواهد بود، گویی که خودشان آن را محاسبه کرده اند، بدون استفاده از FHE.
پاک کردن
ما این فرآیند را با حذف نقطه پایانی که ایجاد کردهایم پایان میدهیم تا مطمئن شویم پس از این فرآیند هیچ محاسبهای استفاده نشده وجود ندارد.
نتایج و ملاحظات
یکی از اشکالات رایج استفاده از FHE در بالای مدلها این است که سربار محاسباتی را اضافه میکند، که در عمل مدل حاصل را برای موارد استفاده تعاملی بسیار کند میکند. اما، در مواردی که داده ها بسیار حساس هستند، ممکن است ارزش این مبادله تاخیر را داشته باشیم. با این حال، برای رگرسیون لجستیک ساده ما، میتوانیم 140 نمونه داده ورودی را در 60 ثانیه پردازش کنیم و عملکرد خطی را ببینیم. نمودار زیر کل زمان پایان به انتها، از جمله زمان انجام شده توسط مشتری برای رمزگذاری ورودی و رمزگشایی نتایج را شامل می شود. همچنین از Amazon S3 استفاده میکند که تأخیر را اضافه میکند و برای این موارد لازم نیست.
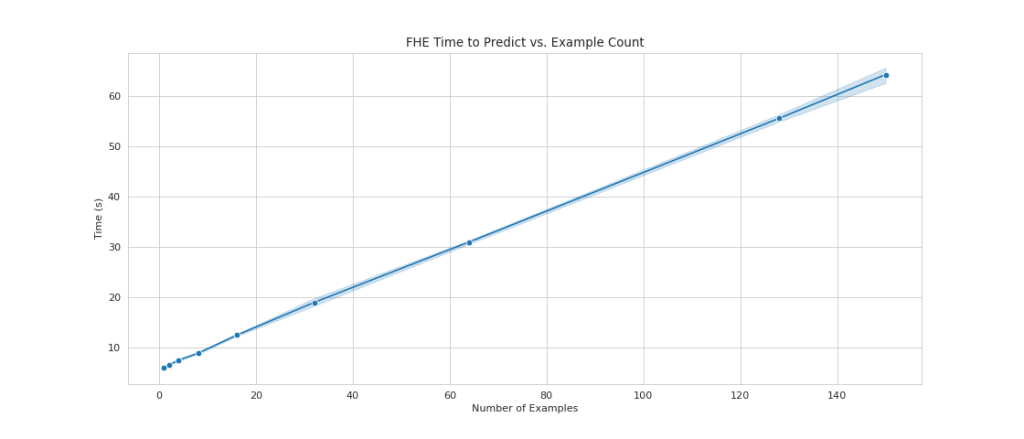
هنگامی که تعداد نمونه ها را از 1 به 150 افزایش می دهیم، مقیاس خطی را مشاهده می کنیم. این مورد انتظار است زیرا هر نمونه به طور مستقل از یکدیگر رمزگذاری شده است، بنابراین ما انتظار افزایش خطی در محاسبات را داریم، با هزینه راه اندازی ثابت.
این همچنین به این معنی است که می توانید ناوگان استنتاج خود را به صورت افقی برای خروجی درخواست بیشتر در پشت نقطه پایانی SageMaker خود مقیاس کنید. شما می توانید استفاده کنید توصیه کننده استنباط آمازون SageMaker برای بهینه سازی هزینه ناوگان خود بسته به نیازهای تجاری شما.
نتیجه
و شما آن را دارید: ML رمزگذاری کاملاً هموار برای یک مدل رگرسیون لجستیک SKLearn که می توانید با چند خط کد تنظیم کنید. با مقداری سفارشیسازی، میتوانید این فرآیند رمزگذاری یکسان را برای انواع مدلها و چارچوبهای مختلف، مستقل از دادههای آموزشی پیادهسازی کنید.
اگر میخواهید درباره ساخت راهحل ML که از رمزگذاری همومورفیک استفاده میکند بیشتر بدانید، با تیم حساب AWS یا شریک خود، Leidos، تماس بگیرید تا بیشتر بدانید. همچنین می توانید برای مثال های بیشتر به منابع زیر مراجعه کنید:
مطالب و نظرات این پست حاوی نظرات نویسندگان شخص ثالث است و AWS مسئولیتی در قبال محتوا یا صحت این پست ندارد.
ضمیمه
متن کامل آموزش به شرح زیر است:
درباره نویسنده
لیو دی آلیبرتی محققی در شتاب دهنده AI/ML Leidos تحت دفتر فناوری است. تحقیقات آنها بر یادگیری ماشینی حفظ حریم خصوصی متمرکز است.
منبیر گولاتی محققی در شتاب دهنده AI/ML Leidos تحت دفتر فناوری است. تحقیقات او بر تقاطع امنیت سایبری و تهدیدهای نوظهور هوش مصنوعی متمرکز است.
جو کوبا مرکز Cloud Excellence Practice Lead در شتاب دهنده مدرنیزاسیون دیجیتال Leidos تحت دفتر فناوری است. در اوقات فراغت از داوری بازی های فوتبال و بازی سافت بال لذت می برد.
بن اسنیولی معمار راه حل های متخصص بخش عمومی است. او با مشتریان دولتی، غیرانتفاعی و آموزشی در پروژه های کلان داده و تحلیلی کار می کند و به آنها کمک می کند تا راه حل هایی با استفاده از AWS بسازند. او در اوقات فراغت خود، حسگرهای اینترنت اشیا را در سرتاسر خانه خود اضافه می کند و تجزیه و تحلیل را روی آنها اجرا می کند.
سامی هدی یک معمار ارشد راه حل در بخش مشاوره همکاران است که بخش عمومی جهانی را پوشش می دهد. سامی مشتاق پروژههایی است که در آنها میتوان از تفکر، نوآوری و هوش هیجانی برای حل مشکلات و تاثیرگذاری بر افراد نیازمند استفاده کرد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/enable-fully-homomorphic-encryption-with-amazon-sagemaker-endpoints-for-secure-real-time-inferencing/

