این پست با جاناتان جونگ، مایک بند، مایکل چی و تامپسون بلیس در لیگ ملی فوتبال نوشته شده است.
A طرح پوشش به قوانین و مسئولیت های هر مدافع فوتبال که وظیفه توقف یک پاس تهاجمی را دارد، اشاره دارد. این هسته اصلی درک و تجزیه و تحلیل هر استراتژی دفاعی فوتبال است. طبقه بندی طرح پوشش برای هر بازی پاس، بینشی از بازی فوتبال را برای تیم ها، پخش کنندگان و هواداران به طور یکسان ارائه می دهد. به عنوان مثال، میتواند ترجیحات دعوتکنندگان بازی را آشکار کند، به درک عمیقتر این امکان را میدهد که چگونه مربیان و تیمهای مربوطه به طور مداوم استراتژیهای خود را بر اساس نقاط قوت حریف تنظیم میکنند، و امکان توسعه تجزیه و تحلیلهای دفاعی جدید مانند منحصر به فرد بودن پوششها را فراهم میکند.ست و همکاران). با این حال، شناسایی دستی این پوششها بر اساس هر بازی، هم پرزحمت و هم دشوار است، زیرا به متخصصان فوتبال نیاز دارد که فیلم بازی را به دقت بررسی کنند. نیاز به یک مدل طبقهبندی پوشش خودکار وجود دارد که بتواند به طور مؤثر و کارآمد برای کاهش هزینه و زمان چرخش، مقیاسبندی شود.
NFL آمار بعدی ژنرال موقعیت مکانی، سرعت و موارد دیگر را در زمان واقعی برای هر بازیکن و بازی فوتبال NFL ثبت می کند و آمارهای پیشرفته مختلفی را که جنبه های مختلف بازی را پوشش می دهد استخراج می کند. از طریق همکاری بین تیم Next Gen Stats و آزمایشگاه راه حل های آمازون ام ال، ما آمار طبقه بندی پوشش مبتنی بر یادگیری ماشین (ML) را توسعه داده ایم که به طور دقیق طرح پوشش دفاعی را بر اساس داده های ردیابی بازیکن شناسایی می کند. مدل طبقه بندی پوشش با استفاده از آموزش داده شده است آمازون SageMaker، و آمار بوده است برای فصل NFL 2022 راه اندازی شد.
در این پست، به جزئیات فنی این مدل ML می پردازیم. ما توضیح میدهیم که چگونه یک مدل ML دقیق و قابل توضیح برای طبقهبندی پوشش از دادههای ردیابی بازیکن طراحی کردهایم، و سپس ارزیابی کمی و نتایج توضیح مدل را دنبال میکنیم.
فرمول بندی مسئله و چالش ها
ما طبقه بندی پوشش دفاعی را به عنوان یک کار طبقه بندی چند کلاسه تعریف می کنیم، با سه نوع پوشش مرد (که در آن هر بازیکن دفاعی یک بازیکن تهاجمی خاصی را پوشش می دهد) و پنج نوع پوشش منطقه (هر بازیکن دفاعی منطقه خاصی را در زمین پوشش می دهد). این هشت کلاس به صورت بصری در شکل زیر نشان داده شده اند: Cover 0 Man، Cover 1 Man، Cover 2 Man، Cover 2 Zone، Cover 3 Zone، Cover 4 Zone، Cover 6 Zone، و Prevent (همچنین پوشش منطقه). دایره های آبی رنگ بازیکنان دفاعی هستند که در نوع خاصی از پوشش قرار گرفته اند. دایره های قرمز رنگ بازیکنان تهاجمی هستند. لیست کامل حروف اختصاری بازیکنان در ضمیمه انتهای این پست ارائه شده است.

تجسم زیر یک بازی نمونه را نشان می دهد که محل قرارگیری همه بازیکنان تهاجمی و تدافعی در شروع بازی (چپ) و وسط همان بازی (راست) است. برای شناسایی صحیح پوشش، اطلاعات زیادی در طول زمان باید در نظر گرفته شود، از جمله نحوه قرار گرفتن مدافعان قبل از ضربه محکم و تنظیمات حرکت بازیکن تهاجمی پس از ضربه زدن به توپ. این چالشی را برای مدل ایجاد می کند تا حرکت و تعامل مکانی-زمانی و اغلب ظریف بین بازیکنان را به تصویر بکشد.

چالش کلیدی دیگری که مشارکت ما با آن مواجه است، ابهام ذاتی در مورد طرح های پوشش مستقر شده است. فراتر از هشت طرح پوشش رایج شناخته شده، ما تنظیماتی را در فراخوانی های پوشش خاص تر شناسایی کردیم که منجر به ابهام در بین هشت کلاس عمومی برای نمودار دستی و طبقه بندی مدل می شود. ما با استفاده از استراتژیهای آموزشی بهبودیافته و توضیح مدل، با این چالشها مقابله میکنیم. ما رویکردهای خود را به طور مفصل در بخش زیر شرح می دهیم.
چارچوب طبقه بندی پوشش قابل توضیح
ما چارچوب کلی خود را در شکل زیر نشان می دهیم، با ورودی داده های ردیابی پخش کننده و برچسب های پوشش که از بالای شکل شروع می شود.

مهندسی ویژگی
داده های ردیابی بازی با سرعت 10 فریم در ثانیه از جمله مکان پخش کننده، سرعت، شتاب و جهت گیری ضبط می شود. مهندسی ویژگی ما دنباله هایی از ویژگی های بازی را به عنوان ورودی برای هضم مدل می سازد. برای یک قاب مشخص، ویژگیهای ما از راهحل Big Data Bowl Kaggle Zoo 2020 الهام گرفته شده است.گوردیف و همکاران): ما یک تصویر برای هر مرحله زمانی با بازیکنان دفاعی در ردیف ها و بازیکنان مهاجم در ستون ها می سازیم. بنابراین، پیکسل تصویر، ویژگیهایی را برای جفت بازیکنان متقاطع نشان میدهد. متفاوت از گوردیف و همکارانما دنبالهای از نمایشهای فریم را استخراج میکنیم که به طور موثر یک ویدیوی کوچک برای مشخص کردن نمایشنامه تولید میکند.
شکل زیر چگونگی تکامل ویژگی ها را در طول زمان و مطابق با دو عکس فوری از یک بازی مثال نشان می دهد. برای وضوح بصری، ما فقط چهار ویژگی از همه مواردی را که استخراج کردیم نشان میدهیم. "LOS" در شکل نشان دهنده خط درگیری است و محور x به جهت افقی سمت راست زمین فوتبال اشاره دارد. توجه داشته باشید که چگونه مقادیر ویژگی، که با نوار رنگ نشان داده شده است، در طول زمان و مطابق با حرکت بازیکن تکامل مییابند. در مجموع، ما دو مجموعه از ویژگی ها را به شرح زیر می سازیم:
- ویژگی های مدافع متشکل از موقعیت مدافع، سرعت، شتاب و جهت گیری، در محور x (جهت افقی سمت راست زمین فوتبال) و محور y (جهت عمودی به بالای زمین فوتبال)
- ویژگی های نسبی مدافع-حمله شامل ویژگی های یکسان، اما به عنوان تفاوت بین بازیکنان دفاعی و تهاجمی محاسبه می شود.

ماژول CNN
ما از یک شبکه عصبی کانولوشنال (CNN) برای مدلسازی تعاملات پیچیده بازیکن مشابه فوتبال منبع باز استفاده میکنیم.بالدوین و همکاران) و راه حل Big Data Bowl Kaggle Zoo (گوردیف و همکاران). تصویر بهدستآمده از مهندسی ویژگی، مدلسازی هر فریم بازی را از طریق CNN تسهیل کرد. ما بلوک کانولوشنال (Conv) استفاده شده توسط راه حل Zoo را اصلاح کردیم (گوردیف و همکاران) با ساختاری انشعاب که از یک CNN یک لایه کم عمق و یک CNN سه لایه عمیق تشکیل شده است. لایه کانولوشن از یک هسته 1×1 در داخل استفاده می کند: نگاه کردن به کرنل به هر جفت بازیکن به صورت جداگانه تضمین می کند که مدل نسبت به بازیکن سفارش دهنده تغییر نمی کند. برای سادگی، ما بازیکنان را بر اساس شناسه NFL آنها برای همه نمونه های بازی سفارش می دهیم. ما تعبیههای فریم را به عنوان خروجی ماژول CNN به دست میآوریم.
مدل سازی زمانی
در مدت بازی کوتاه که فقط چند ثانیه طول می کشد، دارای پویایی های زمانی غنی به عنوان شاخص های کلیدی برای شناسایی پوشش است. مدل سازی CNN مبتنی بر قاب، همانطور که در راه حل باغ وحش استفاده می شود (گوردیف و همکاران، پیشرفت زمانی را در نظر نگرفته است. برای مقابله با این چالش، ما یک ماژول توجه به خود (واسوانی و همکاران)، در بالای CNN، برای مدل سازی زمانی روی هم چیده شده است. در طول آموزش، یاد می گیرد که فریم های فردی را با وزن کردن متفاوت آنها جمع کند (علممار و همکاران). ما آن را با رویکرد LSTM معمولی و دو طرفه در ارزیابی کمی مقایسه خواهیم کرد. جاسازیهای توجه آموختهشده بهعنوان خروجی، پس از آن میانگینگیری میشوند تا جاسازی کل نمایشنامه به دست آید. در نهایت یک لایه کاملا متصل برای تعیین کلاس پوشش نمایشنامه متصل می شود.
صاف کردن مجموعه و لیبل مدل
ابهام در بین هشت طرح پوشش و توزیع نامتعادل آنها، جداسازی واضح بین پوشش ها را چالش برانگیز می کند. ما از مجموعه مدل برای مقابله با این چالش ها در طول آموزش مدل استفاده می کنیم. مطالعه ما نشان میدهد که یک گروه مبتنی بر رأی، یکی از سادهترین روشهای مجموعه، در واقع از رویکردهای پیچیدهتر بهتر عمل میکند. در این روش، هر مدل پایه همان معماری توجه CNN را دارد و به طور مستقل از دانههای تصادفی مختلف آموزش داده میشود. طبقه بندی نهایی میانگین را از خروجی های همه مدل های پایه می گیرد.
ما بیشتر از صاف کردن برچسب استفاده می کنیم (مولر و همکاران) در تلفات آنتروپی متقابل برای کنترل نویز احتمالی در برچسب های نمودار دستی. هموارسازی برچسب، کلاس پوشش مشروح را اندکی به سمت طبقات باقیمانده هدایت میکند. ایده این است که مدل را به انطباق با ابهام پوشش ذاتی به جای تطبیق بیش از حد با هرگونه حاشیه نویسی مغرضانه تشویق کنیم.
ارزیابی کمی
ما از داده های فصل 2018-2020 برای آموزش و اعتبارسنجی مدل و از داده های فصل 2021 برای ارزیابی مدل استفاده می کنیم. هر فصل شامل حدود 17,000 نمایش است. ما یک اعتبارسنجی متقابل پنج برابری را برای انتخاب بهترین مدل در طول آموزش انجام میدهیم و بهینهسازی هایپرپارامتر را برای انتخاب بهترین تنظیمات در معماری چند مدل و پارامترهای آموزشی انجام میدهیم.
برای ارزیابی عملکرد مدل، دقت پوشش، امتیاز F1، دقت بالای 2، و دقت کار سادهتر مرد در مقابل منطقه را محاسبه میکنیم. مدل باغ وحش مبتنی بر CNN که در بالدوین و همکاران برای طبقه بندی پوشش مناسب ترین است و ما از آن به عنوان خط پایه استفاده می کنیم. علاوه بر این، ما نسخههای بهبود یافته خط پایه را در نظر میگیریم که مؤلفههای مدلسازی زمانی را برای مطالعه تطبیقی ترکیب میکنند: یک مدل CNN-LSTM که از یک LSTM دو طرفه برای انجام مدلسازی زمانی استفاده میکند، و یک مدل توجه CNN بدون مجموعه و برچسب. اجزای صاف کننده نتایج در جدول زیر نشان داده شده است.
| مدل | دقت تست 8 پوشش (%) | بالا-2 دقت 8 پوشش (%) | امتیاز F1 8 پوشش | دقت تست مرد در مقابل منطقه (%) |
| خط پایه: مدل باغ وحش | 68.8 0.4 ± | 87.7 0.1 ± | 65.8 0.4 ± | 88.4 0.4 ± |
| CNN-LSTM | 86.5 0.1 ± | 93.9 0.1 ± | 84.9 0.2 ± | 94.6 0.2 ± |
| CNN-توجه | 87.7 0.2 ± | 94.7 0.2 ± | 85.9 0.2 ± | 94.6 0.2 ± |
| مال ما: مجموعه ای از 5 مدل مورد توجه CNN | 88.9 0.1 ± | 97.6 0.1 ± | 87.4 0.2 ± | 95.4 0.1 ± |
مشاهده میکنیم که ادغام ماژول مدلسازی زمانی به طور قابلتوجهی مدل پایه باغوحش را که بر اساس یک قاب بود، بهبود میبخشد. در مقایسه با خط پایه قوی مدل CNN-LSTM، اجزای مدلسازی پیشنهادی ما از جمله ماژول توجه به خود، مجموعه مدل و هموارسازی برچسبگذاری ترکیبی بهبود عملکرد قابل توجهی را ارائه میدهند. مدل نهایی همانطور که با اقدامات ارزیابی نشان داده شده است، عملکرد خوبی دارد. علاوه بر این، ما دقت بسیار بالایی در بالای 2 و فاصله قابل توجهی با دقت بالای 1 را شناسایی می کنیم. این را می توان به ابهام پوشش نسبت داد: وقتی طبقه بندی برتر نادرست است، حدس دوم اغلب با حاشیه نویسی انسانی مطابقت دارد.
توضیحات و نتایج مدل
برای روشن کردن ابهام پوشش و درک اینکه مدل از چه چیزی برای رسیدن به یک نتیجه معین استفاده کرده است، ما تجزیه و تحلیل را با استفاده از توضیحات مدل انجام می دهیم. این شامل دو بخش است: توضیحات کلی که همه جاسازی های آموخته شده را به طور مشترک تجزیه و تحلیل می کند، و توضیحات محلی که در نمایشنامه های فردی بزرگنمایی می کنند تا مهم ترین سیگنال های گرفته شده توسط مدل را تجزیه و تحلیل کنند.
توضیحات جهانی
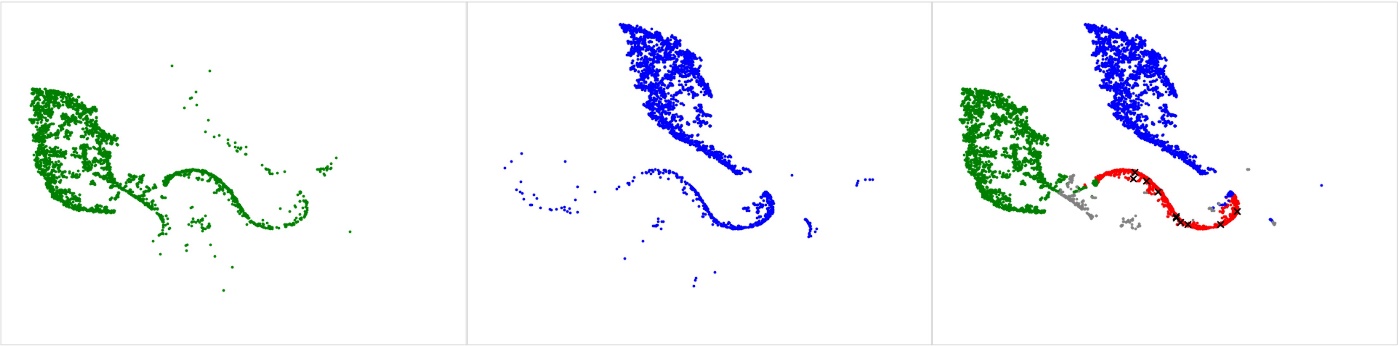
در این مرحله، تعبیههای بازی آموختهشده از مدل طبقهبندی پوشش را در سطح جهانی تجزیه و تحلیل میکنیم تا هر الگوی را که نیاز به بررسی دستی دارد، کشف کنیم. ما از جاسازی همسایه تصادفی توزیع شده t (t-SNE) استفاده می کنیم (Maaten و همکاران) که تعبیههای بازی را در فضای دوبعدی پخش میکند، مانند یک جفت جاسازی مشابه، احتمال توزیع آنها زیاد است. ما با پارامترهای داخلی آزمایش می کنیم تا پیش بینی های دو بعدی پایدار را استخراج کنیم. تعبیههای نمونههای طبقهبندی شده از 2 نمایشنامه در شکل زیر (سمت چپ) نشان داده شدهاند که هر نقطه نشاندهنده یک نمایشنامه خاص است. ما متوجه شدیم که اکثریت هر طرح پوشش به خوبی از هم جدا شدهاند و قابلیت طبقهبندی بهدستآمده توسط مدل را نشان میدهد. ما دو الگوی مهم را مشاهده می کنیم و آنها را بیشتر بررسی می کنیم.
همانطور که در شکل زیر نشان داده شده است، برخی از نمایشنامه ها با انواع پوشش های دیگر ترکیب شده اند. این نمایشنامه ها به طور بالقوه ممکن است به اشتباه برچسب زده شوند و مستحق بازرسی دستی هستند. ما یک طبقهبندیکننده K-Nearest Neighbors (KNN) طراحی میکنیم تا بهطور خودکار این نمایشها را شناسایی کرده و برای بررسی تخصصی ارسال کنیم. نتایج نشان می دهد که اکثر آنها در واقع به اشتباه برچسب گذاری شده اند.

در مرحله بعد، چندین منطقه همپوشانی را در میان انواع پوشش مشاهده میکنیم که ابهام پوشش را در سناریوهای خاص نشان میدهد. به عنوان مثال در شکل زیر Cover 3 Zone (خوشه سبز در سمت چپ) و Cover 1 Man (خوشه آبی در وسط) را از هم جدا می کنیم. اینها دو مفهوم مختلف پوشش تک-بالا هستند که وجه تمایز اصلی پوشش مرد در مقابل منطقه است. ما الگوریتمی طراحی می کنیم که به طور خودکار ابهام بین این دو کلاس را به عنوان منطقه همپوشانی خوشه ها شناسایی می کند. نتیجه به صورت نقاط قرمز در شکل سمت راست زیر، با 10 نمایش نمونه برداری تصادفی با علامت "x" سیاه برای بررسی دستی نشان داده شده است. تحلیل ما نشان میدهد که بیشتر نمونههای بازی در این منطقه شامل نوعی تطبیق الگو هستند. در این نمایشنامهها، مسئولیتهای پوشش به نحوه توزیع مسیرهای گیرندههای تهاجمی بستگی دارد، و تنظیمات میتوانند نمایشنامه را ترکیبی از پوششهای منطقه و مرد جلوه دهند. یکی از این تنظیمات که ما شناسایی کردیم در مورد Cover 3 Zone اعمال میشود، زمانی که گوشه پشتی (CB) به یک طرف در پوشش مرد قفل شده است ("Man Everywhere He Goes" یا MEG) و دیگری دارای یک افت منطقه سنتی است.
توضیحات نمونه
در مرحله دوم، توضیحات نمونه در بازی فردی مورد علاقه بزرگنمایی میکنند و نکات برجسته تعامل بازیکن فریم به فریم را استخراج میکنند که بیشترین کمک را به طرح پوشش شناساییشده دارد. این از طریق الگوریتم Guided GradCAM (رامپراسات و همکاران). ما از توضیحات نمونه در مورد پیشبینیهای مدل با اعتماد پایین استفاده میکنیم.
برای نمایشی که در ابتدای پست نشان دادیم، مدل Cover 3 Zone را با احتمال 44.5٪ و Cover 1 Man را با احتمال 31.3٪ پیش بینی کرد. ما نتایج توضیحی را برای هر دو کلاس همانطور که در شکل زیر نشان داده شده است ایجاد می کنیم. ضخامت خط بیانگر قدرت تعامل است که به شناسایی مدل کمک می کند.
طرح بالای توضیح Cover 3 Zone درست بعد از ضربه زدن به توپ می آید. CB در سمت راست حمله دارای قوی ترین خطوط تعامل است، زیرا او در مقابل QB قرار دارد و در جای خود باقی می ماند. او در نهایت با گیرنده طرف خود که او را تهدید می کند به میدان می رود و مطابقت می دهد.
داستان پایین برای توضیح Cover 1 Man یک لحظه بعد می آید، زیرا بازی اکشن جعلی در حال وقوع است. یکی از قوی ترین تعاملات با CB در سمت چپ حمله است که با WR در حال سقوط است. فیلم پخش نشان میدهد که او قبل از اینکه دور بزند و با WR که عمیقاً او را تهدید میکند بدود، چشمانش به QB است. اس اس در سمت راست حمله همچنین تعامل قوی با TE در سمت خود دارد، زیرا با شکستن TE در داخل شروع به زدن می کند. او در نهایت او را در سراسر آرایش دنبال می کند، اما TE شروع به مسدود کردن او می کند، که نشان می دهد بازی احتمالاً یک گزینه run-pass است. این امر عدم قطعیت طبقهبندی مدل را توضیح میدهد: TE با طراحی به SS چسبیده است و باعث ایجاد سوگیری در دادهها میشود.


نتیجه
آمازون ML Solutions Lab و تیم NFL's Next Gen Stats به طور مشترک آمار طبقه بندی پوشش دفاعی را که اخیرا برای فصل فوتبال NFL 2022 راه اندازی شد. این پست جزئیات فنی ML این آمار را ارائه میکند، از جمله مدلسازی پیشرفت سریع زمانی، استراتژیهای آموزشی برای رسیدگی به ابهام کلاس پوشش، و توضیحات مدل جامع برای سرعت بخشیدن به بررسی کارشناسان در هر دو سطح جهانی و نمونه.
این راه حل، تمایلات و تقسیمات پوشش دفاعی زنده را برای اولین بار در دسترس پخش کنندگان درون بازی قرار می دهد. به همین ترتیب، این مدل NFL را قادر میسازد تا تجزیه و تحلیل خود را از نتایج پس از بازی بهبود بخشد و تطابقهای کلیدی را که منجر به بازیها میشوند، بهتر شناسایی کند.
اگر برای تسریع استفاده از ML کمک میخواهید، لطفاً با آن تماس بگیرید آزمایشگاه راه حل های آمازون ام ال برنامه است.
ضمیمه
| مخفف موقعیت بازیکن | |
| موقعیت های دفاعی | |
| W | "ویل" Linebacker یا طرف ضعیف LB |
| M | "Mike" Linebacker یا LB وسط |
| S | "Sam" Linebacker یا طرف قوی LB |
| CB | گوشه سمت راست |
| DE | پایان دفاعی |
| DT | تکل دفاعی |
| NT | تکل بینی |
| FS | ایمنی رایگان |
| SS | ایمنی قوی |
| S | ایمنی |
| LB | خط مقدم |
| HE B | داخل لاینبکر |
| OLB | پشتیبان خط بیرونی |
| MLB | مدافع خط میانی |
| موقعیت های تهاجمی | |
| X | معمولاً گیرنده عریض شماره 1 در یک تخلف، آنها در LOS تراز می شوند. در سازندهای سفر، این گیرنده اغلب به صورت ایزوله در قسمت پشتی قرار می گیرد. |
| Y | معمولاً نقطه شروع، این بازیکن اغلب در خط و در طرف مقابل به عنوان X قرار می گیرد. |
| Z | این بازیکن معمولاً بیشتر یک گیرنده اسلات است، این بازیکن اغلب از خط درگیری و در همان سمت زمین با انتهای تنگ قرار می گیرد. |
| H | این بازیکن به طور سنتی یک مدافع کناری، اغلب در لیگ مدرن سومین دریافت کننده پهن یا دومین بازیکن ضعیف است. آنها می توانند در سرتاسر سازند همسو شوند، اما تقریباً همیشه خارج از خط کشمکش هستند. بسته به تیم، این بازیکن می تواند به عنوان F نیز انتخاب شود. |
| T | برجسته دویدن به عقب. به غیر از ترکیبهای خالی، این بازیکن در خط عقب قرار میگیرد و تهدیدی برای دریافت دستدف خواهد بود. |
| QB | قهرمان |
| C | مرکز |
| G | گارد |
| RB | در حال اجرا پشت |
| FB | بازپرداخت |
| WR | گیرنده ای |
| TE | پایان محکم |
| LG | گارد چپ |
| RG | نگهبان درست |
| T | برخورد با |
| LT | تکل چپ |
| RT | تکل درست |
منابع
- تج ست، رایان وایزمن، "مطالعه داده های PFF: منحصر به فرد بودن طرح پوشش برای هر تیم و معنای آن برای تغییرات مربیگری" https://www.pff.com/news/nfl-pff-data-study-coverage-scheme-uniqueness-for-each-team-and-what-that-means-for-coaching-changes
- بن بالدوین. "Computer Vision با داده های ردیابی پخش کننده NFL با استفاده از مشعل برای R: طبقه بندی پوشش با استفاده از CNN." https://www.opensourcefootball.com/posts/2021-05-31-computer-vision-in-r-using-torch/
- دیمیتری گوردیف، فیلیپ سینگر. "راه حل رتبه اول باغ وحش." https://www.kaggle.com/c/nfl-big-data-bowl-2020/discussion/119400
- واسوانی، آشیش، نوام شزیر، نیکی پارمار، یاکوب اوسکوریت، لیون جونز، آیدان ان. گومز، لوکاس قیصر، و ایلیا پولوسوکین. "توجه تنها چیزی است که نیاز دارید." پیشرفت در سیستم های پردازش اطلاعات عصبی 30 (2017).
- جی علممار. "ترانسفورماتور مصور." https://jalammar.github.io/illustrated-transformer/
- مولر، رافائل، سیمون کورنبلیت و جفری ای. هینتون. "چه زمانی صاف کردن برچسب کمک می کند؟" پیشرفتها در سیستمهای پردازش اطلاعات عصبی 32 (2019).
- ون در ماتن، لورن و جفری هینتون. "تجسم داده ها با استفاده از t-SNE." مجله تحقیقات یادگیری ماشین 9، شماره 11 (2008).
- Selvaraju، Ramprasaath R.، Michael Cogswell، Abhishek Das، Ramakrishna Vedantam، Devi Parikh و Dhruv Batra. Grad-cam: توضیحات بصری از شبکه های عمیق از طریق محلی سازی مبتنی بر گرادیان. که در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، صص 618-626. 2017.
درباره نویسنده
 آهنگ هوان یک دانشمند کاربردی در آزمایشگاه راهحلهای یادگیری ماشین آمازون است، جایی که او بر روی ارائه راهحلهای سفارشی ML برای موارد استفاده پرتأثیر مشتری از انواع مختلف صنعت کار میکند. زمینه های تحقیقاتی او شبکه های عصبی گراف، بینایی کامپیوتری، تحلیل سری های زمانی و کاربردهای صنعتی آنهاست.
آهنگ هوان یک دانشمند کاربردی در آزمایشگاه راهحلهای یادگیری ماشین آمازون است، جایی که او بر روی ارائه راهحلهای سفارشی ML برای موارد استفاده پرتأثیر مشتری از انواع مختلف صنعت کار میکند. زمینه های تحقیقاتی او شبکه های عصبی گراف، بینایی کامپیوتری، تحلیل سری های زمانی و کاربردهای صنعتی آنهاست.
 محمد الجزایری یک دانشمند کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او به مشتریان AWS کمک می کند تا راه حل های ML را برای رفع چالش های تجاری خود در زمینه هایی مانند تدارکات، شخصی سازی و توصیه ها، دید کامپیوتر، پیشگیری از تقلب، پیش بینی و بهینه سازی زنجیره تامین بسازند. قبل از AWS، او MCS خود را از دانشگاه ویرجینیای غربی دریافت کرد و به عنوان محقق بینایی کامپیوتر در Midea کار کرد. خارج از محل کار، او از فوتبال و بازی های ویدیویی لذت می برد.
محمد الجزایری یک دانشمند کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او به مشتریان AWS کمک می کند تا راه حل های ML را برای رفع چالش های تجاری خود در زمینه هایی مانند تدارکات، شخصی سازی و توصیه ها، دید کامپیوتر، پیشگیری از تقلب، پیش بینی و بهینه سازی زنجیره تامین بسازند. قبل از AWS، او MCS خود را از دانشگاه ویرجینیای غربی دریافت کرد و به عنوان محقق بینایی کامپیوتر در Midea کار کرد. خارج از محل کار، او از فوتبال و بازی های ویدیویی لذت می برد.
 هایبو دینگ یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او به طور گسترده به یادگیری عمیق و پردازش زبان طبیعی علاقه دارد. تحقیقات او بر توسعه مدلهای یادگیری ماشینی قابل توضیح جدید با هدف کارآمدتر و قابل اعتمادتر کردن آنها برای مشکلات دنیای واقعی متمرکز است. دکترای خود را گرفت. از دانشگاه یوتا و قبل از پیوستن به آمازون به عنوان یک دانشمند تحقیقاتی ارشد در Bosch Research آمریکای شمالی کار می کرد. او جدای از کار، از پیاده روی، دویدن و گذراندن وقت با خانواده لذت می برد.
هایبو دینگ یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او به طور گسترده به یادگیری عمیق و پردازش زبان طبیعی علاقه دارد. تحقیقات او بر توسعه مدلهای یادگیری ماشینی قابل توضیح جدید با هدف کارآمدتر و قابل اعتمادتر کردن آنها برای مشکلات دنیای واقعی متمرکز است. دکترای خود را گرفت. از دانشگاه یوتا و قبل از پیوستن به آمازون به عنوان یک دانشمند تحقیقاتی ارشد در Bosch Research آمریکای شمالی کار می کرد. او جدای از کار، از پیاده روی، دویدن و گذراندن وقت با خانواده لذت می برد.
 لین لی چئونگ یک مدیر علمی کاربردی با تیم آمازون ML Solutions Lab در AWS است. او با مشتریان استراتژیک AWS کار می کند تا هوش مصنوعی و یادگیری ماشینی را برای کشف بینش های جدید و حل مشکلات پیچیده کاوش و استفاده کند. او دکترای خود را دریافت کرد. از موسسه فناوری ماساچوست در خارج از محل کار، او از مطالعه و پیاده روی لذت می برد.
لین لی چئونگ یک مدیر علمی کاربردی با تیم آمازون ML Solutions Lab در AWS است. او با مشتریان استراتژیک AWS کار می کند تا هوش مصنوعی و یادگیری ماشینی را برای کشف بینش های جدید و حل مشکلات پیچیده کاوش و استفاده کند. او دکترای خود را دریافت کرد. از موسسه فناوری ماساچوست در خارج از محل کار، او از مطالعه و پیاده روی لذت می برد.
 جاناتان یونگ مهندس نرم افزار ارشد در لیگ ملی فوتبال است. او در هفت سال گذشته با تیم Next Gen Stats همکاری داشته است و به ایجاد پلتفرم از جریان دادههای خام، ساخت میکروسرویسها برای پردازش دادهها تا ساخت APIهایی که دادههای پردازش شده را در معرض نمایش میگذارد، کمک کرده است. او با آزمایشگاه راه حلهای یادگیری ماشین آمازون در ارائه دادههای تمیز برای کار با آنها و همچنین ارائه دانش دامنه در مورد خود دادهها همکاری کرده است. خارج از محل کار، او از دوچرخه سواری در لس آنجلس و پیاده روی در سیرا لذت می برد.
جاناتان یونگ مهندس نرم افزار ارشد در لیگ ملی فوتبال است. او در هفت سال گذشته با تیم Next Gen Stats همکاری داشته است و به ایجاد پلتفرم از جریان دادههای خام، ساخت میکروسرویسها برای پردازش دادهها تا ساخت APIهایی که دادههای پردازش شده را در معرض نمایش میگذارد، کمک کرده است. او با آزمایشگاه راه حلهای یادگیری ماشین آمازون در ارائه دادههای تمیز برای کار با آنها و همچنین ارائه دانش دامنه در مورد خود دادهها همکاری کرده است. خارج از محل کار، او از دوچرخه سواری در لس آنجلس و پیاده روی در سیرا لذت می برد.
 مایک باند مدیر ارشد تحقیقات و تجزیه و تحلیل برای آمار نسل بعدی در لیگ ملی فوتبال است. از زمان پیوستن به تیم در سال 2018، او مسئول ایدهپردازی، توسعه، و ارتباط آمار و بینشهای کلیدی است که از دادههای ردیابی بازیکن برای هواداران، شرکای پخش NFL و 32 باشگاه به طور یکسان به دست آمده است. مایک با مدرک کارشناسی ارشد در تحلیل از دانشگاه شیکاگو، مدرک لیسانس مدیریت ورزشی از دانشگاه فلوریدا، و تجربه در بخش پیشاهنگی وایکینگ های مینه سوتا و بخش استخدام، دانش و تجربه زیادی را برای تیم به ارمغان می آورد. فوتبال فلوریدا گیتور
مایک باند مدیر ارشد تحقیقات و تجزیه و تحلیل برای آمار نسل بعدی در لیگ ملی فوتبال است. از زمان پیوستن به تیم در سال 2018، او مسئول ایدهپردازی، توسعه، و ارتباط آمار و بینشهای کلیدی است که از دادههای ردیابی بازیکن برای هواداران، شرکای پخش NFL و 32 باشگاه به طور یکسان به دست آمده است. مایک با مدرک کارشناسی ارشد در تحلیل از دانشگاه شیکاگو، مدرک لیسانس مدیریت ورزشی از دانشگاه فلوریدا، و تجربه در بخش پیشاهنگی وایکینگ های مینه سوتا و بخش استخدام، دانش و تجربه زیادی را برای تیم به ارمغان می آورد. فوتبال فلوریدا گیتور
 مایکل چی مدیر ارشد فناوری است که بر آمار و مهندسی داده نسل بعدی در لیگ ملی فوتبال نظارت می کند. او دارای مدرک ریاضیات و علوم کامپیوتر از دانشگاه ایلینوی در Urbana Champaign است. مایکل برای اولین بار در سال 2007 به NFL ملحق شد و در درجه اول بر فناوری و پلتفرم های آمار فوتبال تمرکز کرده است. در اوقات فراغت خود از گذراندن اوقات فراغت با خانواده اش در خارج از منزل لذت می برد.
مایکل چی مدیر ارشد فناوری است که بر آمار و مهندسی داده نسل بعدی در لیگ ملی فوتبال نظارت می کند. او دارای مدرک ریاضیات و علوم کامپیوتر از دانشگاه ایلینوی در Urbana Champaign است. مایکل برای اولین بار در سال 2007 به NFL ملحق شد و در درجه اول بر فناوری و پلتفرم های آمار فوتبال تمرکز کرده است. در اوقات فراغت خود از گذراندن اوقات فراغت با خانواده اش در خارج از منزل لذت می برد.
 تامپسون بلیس مدیر، عملیات فوتبال، دانشمند داده در لیگ ملی فوتبال است. او در فوریه 2020 در NFL به عنوان دانشمند داده شروع کرد و در دسامبر 2021 به سمت فعلی خود ارتقا یافت. او مدرک کارشناسی ارشد خود را در علوم داده در دانشگاه کلمبیا در شهر نیویورک در دسامبر 2019 به پایان رساند. او مدرک لیسانس علوم را دریافت کرد. در فیزیک و ستاره شناسی با خردسالان در ریاضیات و علوم کامپیوتر در دانشگاه ویسکانسین - مدیسون در سال 2018.
تامپسون بلیس مدیر، عملیات فوتبال، دانشمند داده در لیگ ملی فوتبال است. او در فوریه 2020 در NFL به عنوان دانشمند داده شروع کرد و در دسامبر 2021 به سمت فعلی خود ارتقا یافت. او مدرک کارشناسی ارشد خود را در علوم داده در دانشگاه کلمبیا در شهر نیویورک در دسامبر 2019 به پایان رساند. او مدرک لیسانس علوم را دریافت کرد. در فیزیک و ستاره شناسی با خردسالان در ریاضیات و علوم کامپیوتر در دانشگاه ویسکانسین - مدیسون در سال 2018.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/identifying-defense-coverage-schemes-in-nfls-next-gen-stats/

