این پست توسط Anatoly Khomenko، مهندس یادگیری ماشین، و Abdenour Bezzouh، مدیر ارشد فناوری Talent.com نوشته شده است.
تاسیس در 2011، Talent.com لیست های شغلی پولی را از مشتریان خود و لیست های مشاغل عمومی جمع آوری می کند و یک پلت فرم یکپارچه و به راحتی قابل جستجو ایجاد کرده است. Talent.com با پوشش بیش از 30 میلیون لیست شغلی در بیش از 75 کشور و به زبانها، صنایع و کانالهای توزیع مختلف، نیازهای متنوع جویندگان کار را برآورده میکند و به طور مؤثر میلیونها کارجو را با فرصتهای شغلی مرتبط میکند.
ماموریت Talent.com تسهیل ارتباطات جهانی نیروی کار است. برای دستیابی به این هدف، Talent.com فهرستهای شغلی را از منابع مختلف در وب جمعآوری میکند و به جویندگان کار دسترسی به مجموعه وسیعی از بیش از 30 میلیون فرصت شغلی متناسب با مهارتها و تجربیات آنها را ارائه میدهد. در راستای این ماموریت، Talent.com با AWS همکاری کرد تا یک موتور توصیه شغلی پیشرفته را با هدف کمک به کاربران در پیشبرد شغل خود هدایت کند.
برای اطمینان از عملکرد مؤثر این موتور توصیه شغلی، اجرای یک خط لوله پردازش داده در مقیاس بزرگ که مسئول استخراج و پالایش ویژگیها از فهرستهای مشاغل انبوه Talent.com است، بسیار مهم است. این خط لوله قادر است 5 میلیون رکورد روزانه را در کمتر از 1 ساعت پردازش کند و امکان پردازش چندین روز رکورد را به صورت موازی فراهم می کند. علاوه بر این، این راه حل امکان استقرار سریع در تولید را فراهم می کند. منبع اصلی داده برای این خط لوله قالب JSON Lines است که در آن ذخیره شده است سرویس ذخیره سازی ساده آمازون (Amazon S3) و بر اساس تاریخ پارتیشن بندی شده است. هر روز، این منجر به تولید دهها هزار فایل JSON Lines میشود که روزانه بهروزرسانیهای افزایشی انجام میشود.
هدف اصلی این خط لوله پردازش داده، تسهیل ایجاد ویژگی های لازم برای آموزش و استقرار موتور توصیه کار در Talent.com است. شایان ذکر است که این خط لوله باید از بهروزرسانیهای افزایشی پشتیبانی کند و نیازمندیهای استخراج ویژگی پیچیده لازم برای ماژولهای آموزشی و استقرار ضروری برای سیستم توصیه شغلی را برآورده کند. خط لوله ما متعلق به خانواده فرآیندهای عمومی ETL (استخراج، تبدیل و بارگذاری) است که داده ها را از چندین منبع در یک مخزن بزرگ و مرکزی ترکیب می کند.
برای بینش بیشتر در مورد اینکه Talent.com و AWS چگونه با همکاری یکدیگر تکنیک های آموزش مدل پردازش زبان طبیعی و یادگیری عمیق را ایجاد کردند، با استفاده از آمازون SageMaker برای ایجاد یک سیستم توصیه شغلی به از متن تا شغل رویایی: ایجاد یک توصیهکننده شغلی مبتنی بر NLP در Talent.com با Amazon SageMaker. این سیستم شامل مهندسی ویژگی، طراحی معماری مدل یادگیری عمیق، بهینه سازی هایپرپارامتر و ارزیابی مدل است که در آن همه ماژول ها با استفاده از پایتون اجرا می شوند.
این پست نشان میدهد که چگونه از SageMaker برای ایجاد یک خط لوله پردازش داده در مقیاس بزرگ برای آمادهسازی ویژگیهای موتور توصیه شغلی در Talent.com استفاده کردیم. راه حل به دست آمده به دانشمند داده امکان می دهد تا استخراج ویژگی را در یک نوت بوک SageMaker با استفاده از کتابخانه های پایتون، مانند Scikit یاد بگیرید or PyTorchو سپس به سرعت همان کد را در خط لوله پردازش داده مستقر کرده و استخراج ویژگی را در مقیاس انجام می دهد. راه حل نیازی به انتقال کد استخراج ویژگی برای استفاده از PySpark ندارد، همانطور که در هنگام استفاده لازم است چسب AWS به عنوان راه حل ETL. راهحل ما را میتوان صرفاً توسط یک Data Scientist با استفاده از SageMaker توسعه داده و به کار برد، و نیازی به دانش سایر راهحلهای ETL ندارد، مانند دسته AWS. این می تواند زمان مورد نیاز برای استقرار خط لوله یادگیری ماشین (ML) را به طور قابل توجهی کوتاه کند. خط لوله از طریق پایتون کار میکند و به طور یکپارچه با جریانهای کاری استخراج ویژگی ادغام میشود و آن را با طیف گستردهای از برنامههای تحلیل داده سازگار میکند.
بررسی اجمالی راه حل
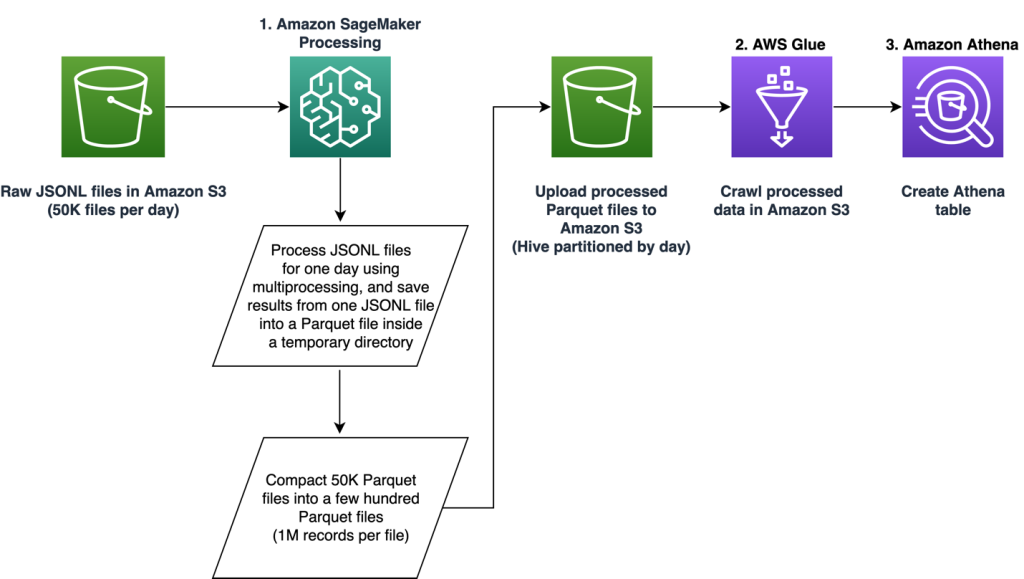
خط لوله از سه فاز اصلی تشکیل شده است:
- از یک استفاده کنید پردازش آمازون SageMaker کار برای رسیدگی به فایل های خام JSONL مرتبط با یک روز مشخص. دادههای چند روزه را میتوان با کارهای پردازش جداگانه به طور همزمان پردازش کرد.
- استخدام کنید چسب AWS برای خزیدن داده ها پس از پردازش چندین روز داده.
- بارگیری ویژگی های پردازش شده برای یک محدوده تاریخی مشخص با استفاده از SQL از یک آمازون آتنا جدول، سپس مدل پیشنهاد دهنده کار را آموزش و اجرا کنید.
فایل های خام JSONL را پردازش کنید
ما فایل های خام JSONL را برای یک روز مشخص با استفاده از یک کار پردازش SageMaker پردازش می کنیم. این کار استخراج ویژگی و فشرده سازی داده ها را پیاده سازی می کند و ویژگی های پردازش شده را در فایل های پارکت با 1 میلیون رکورد در هر فایل ذخیره می کند. ما از موازی سازی CPU برای انجام استخراج ویژگی برای هر فایل خام JSONL به صورت موازی استفاده می کنیم. نتایج پردازش هر فایل JSONL در یک فایل پارکت جداگانه در یک فهرست موقت ذخیره می شود. پس از پردازش همه فایلهای JSONL، هزاران فایل پارکت کوچک را به چندین فایل با 1 میلیون رکورد در هر فایل فشرده میکنیم. سپس فایل های پارکت فشرده به عنوان خروجی کار پردازش در آمازون S3 آپلود می شوند. فشرده سازی داده ها خزیدن کارآمد و پرس و جوهای SQL را در مراحل بعدی خط لوله تضمین می کند.
کد زیر نمونهای برای برنامهریزی یک کار SageMaker Processing برای یک روز مشخص، برای مثال 2020-01-01، با استفاده از SageMaker SDK است. این کار فایل های خام JSONL را از Amazon S3 می خواند (به عنوان مثال از s3://bucket/raw-data/2020/01/01) و فایل های پارکت فشرده را در آمازون S3 ذخیره می کند (مثلاً به s3://bucket/processed/table-name/day_partition=2020-01-01/).
### install dependencies %pip install sagemaker pyarrow s3fs awswrangler import sagemaker
import boto3 from sagemaker.processing import FrameworkProcessor
from sagemaker.sklearn.estimator import SKLearn
from sagemaker import get_execution_role
from sagemaker.processing import ProcessingInput, ProcessingOutput region = boto3.session.Session().region_name
role = get_execution_role()
bucket = sagemaker.Session().default_bucket() ### we use instance with 16 CPUs and 128 GiB memory
### note that the script will NOT load the entire data into memory during compaction
### depending on the size of individual jsonl files, larger instance may be needed
instance = "ml.r5.4xlarge"
n_jobs = 8 ### we use 8 process workers
date = "2020-01-01" ### process data for one day est_cls = SKLearn
framework_version_str = "0.20.0" ### schedule processing job
script_processor = FrameworkProcessor( role=role, instance_count=1, instance_type=instance, estimator_cls=est_cls, framework_version=framework_version_str, volume_size_in_gb=500,
) script_processor.run( code="processing_script.py", ### name of the main processing script source_dir="../src/etl/", ### location of source code directory ### our processing script loads raw jsonl files directly from S3 ### this avoids long start-up times of the processing jobs, ### since raw data does not need to be copied into instance inputs=[], ### processing job input is empty outputs=[ ProcessingOutput(destination="s3://bucket/processed/table-name/", source="/opt/ml/processing/output"), ], arguments=[ ### directory with job's output "--output", "/opt/ml/processing/output", ### temporary directory inside instance "--tmp_output", "/opt/ml/tmp_output", "--n_jobs", str(n_jobs), ### number of process workers "--date", date, ### date to process ### location with raw jsonl files in S3 "--path", "s3://bucket/raw-data/", ], wait=False
)
طرح کلی کد زیر برای اسکریپت اصلی (processing_script.py) که کار پردازش SageMaker را اجرا می کند به شرح زیر است:
import concurrent
import pyarrow.dataset as ds
import os
import s3fs
from pathlib import Path ### function to process raw jsonl file and save extracted features into parquet file from process_data import process_jsonl ### parse command line arguments
args = parse_args() ### we use s3fs to crawl S3 input path for raw jsonl files
fs = s3fs.S3FileSystem()
### we assume raw jsonl files are stored in S3 directories partitioned by date
### for example: s3://bucket/raw-data/2020/01/01/
jsons = fs.find(os.path.join(args.path, *args.date.split('-'))) ### temporary directory location inside the Processing job instance
tmp_out = os.path.join(args.tmp_output, f"day_partition={args.date}") ### directory location with job's output
out_dir = os.path.join(args.output, f"day_partition={args.date}") ### process individual jsonl files in parallel using n_jobs process workers
futures=[]
with concurrent.futures.ProcessPoolExecutor(max_workers=args.n_jobs) as executor: for file in jsons: inp_file = Path(file) out_file = os.path.join(tmp_out, inp_file.stem + ".snappy.parquet") ### process_jsonl function reads raw jsonl file from S3 location (inp_file) ### and saves result into parquet file (out_file) inside temporary directory futures.append(executor.submit(process_jsonl, file, out_file)) ### wait until all jsonl files are processed for future in concurrent.futures.as_completed(futures): result = future.result() ### compact parquet files
dataset = ds.dataset(tmp_out) if len(dataset.schema) > 0: ### save compacted parquet files with 1MM records per file ds.write_dataset(dataset, out_dir, format="parquet", max_rows_per_file=1024 * 1024)
مقیاس پذیری یکی از ویژگی های کلیدی خط لوله ما است. اول، چندین کار پردازش SageMaker را می توان برای پردازش داده ها برای چند روز به طور همزمان استفاده کرد. دوم، ما از بارگیری کل داده های پردازش شده یا خام به یکباره در حافظه خودداری می کنیم، در حالی که هر روز مشخص داده را پردازش می کنیم. این امکان پردازش دادهها را با استفاده از انواع نمونهای که نمیتوانند یک روز کامل داده را در حافظه اولیه جای دهند، میسازد. تنها شرط این است که نوع نمونه باید بتواند N فایل JSONL خام یا پارکت پردازش شده را به طور همزمان در حافظه بارگذاری کند و N تعداد کارگران پردازشی در حال استفاده است.
داده های پردازش شده را با استفاده از چسب AWS خزیدن کنید
پس از پردازش تمام دادههای خام چند روزه، میتوانیم با استفاده از یک خزنده چسب AWS، یک جدول Athena از کل مجموعه داده ایجاد کنیم. ما استفاده می کنیم AWS SDK برای پانداها (awswrangler) کتابخانه برای ایجاد جدول با استفاده از قطعه زیر:
import awswrangler as wr ### crawl processed data in S3
res = wr.s3.store_parquet_metadata( path='s3://bucket/processed/table-name/', database="database_name", table="table_name", dataset=True, mode="overwrite", sampling=1.0, path_suffix='.parquet',
) ### print table schema
print(res[0])
بارگذاری ویژگی های پردازش شده برای آموزش
ویژگیهای پردازششده برای یک محدوده تاریخ مشخص، اکنون میتوانند با استفاده از SQL از جدول Athena بارگیری شوند و سپس میتوان از این ویژگیها برای آموزش مدل توصیهکننده شغل استفاده کرد. به عنوان مثال، قطعه زیر یک ماه از ویژگی های پردازش شده را در یک DataFrame با استفاده از بارگیری می کند awswrangler کتابخانه:
import awswrangler as wr query = """ SELECT * FROM table_name WHERE day_partition BETWEN '2020-01-01' AND '2020-02-01' """ ### load 1 month of data from database_name.table_name into a DataFrame
df = wr.athena.read_sql_query(query, database='database_name')
علاوه بر این، استفاده از SQL برای بارگیری ویژگی های پردازش شده برای آموزش می تواند برای تطبیق موارد استفاده مختلف دیگر گسترش یابد. به عنوان مثال، ما میتوانیم خط لوله مشابهی را برای نگهداری دو جدول Athena جداگانه اعمال کنیم: یکی برای ذخیره نمایشهای کاربر و دیگری برای ذخیره کلیکهای کاربر بر روی این نمایشها. با استفاده از دستورات اتصال SQL، میتوانیم برداشتهایی را که کاربران یا روی آنها کلیک کردهاند یا روی آنها کلیک نکردهاند، بازیابی کنیم و سپس این نمایشها را به یک کار آموزشی مدل منتقل کنیم.
مزایای راه حل
پیاده سازی راه حل پیشنهادی چندین مزیت برای گردش کار موجود ما به همراه دارد، از جمله:
- پیاده سازی ساده شده – این راه حل استخراج ویژگی را با استفاده از کتابخانه های محبوب ML در پایتون امکان می دهد. و نیازی به انتقال کد به PySpark ندارد. این خطوط ساده استخراج ویژگی را دارد زیرا همان کدی که توسط یک دانشمند داده در یک نوت بوک ایجاد شده است توسط این خط لوله اجرا می شود.
- مسیر تولید سریع - این راه حل را می توان توسط یک دانشمند داده توسعه داد و به کار گرفت تا استخراج ویژگی را در مقیاس انجام دهد و آنها را قادر می سازد تا یک مدل توصیه گر ML در برابر این داده ها ایجاد کنند. در همان زمان، همان راه حل را می توان برای تولید توسط یک مهندس ML با تغییرات کمی مورد نیاز به کار برد.
- قابل استفاده مجدد - این راه حل یک الگوی قابل استفاده مجدد برای استخراج ویژگی در مقیاس ارائه می دهد و می تواند به راحتی برای موارد استفاده دیگر فراتر از ساخت مدل های توصیه کننده سازگار شود.
- بهره وری - راه حل عملکرد خوبی ارائه می دهد: پردازش یک روز از آن Talent.comدادههای آن کمتر از ۱ ساعت طول کشید.
- به روز رسانی های افزایشی - این راه حل همچنین از به روز رسانی های افزایشی پشتیبانی می کند. دادههای روزانه جدید را میتوان با یک کار پردازش SageMaker پردازش کرد و مکان S3 حاوی دادههای پردازششده را میتوان برای بهروزرسانی جدول Athena دوباره خزیده کرد. همچنین میتوانیم از cron job برای بهروزرسانی دادههای امروزی چندین بار در روز (مثلاً هر 3 ساعت) استفاده کنیم.
ما از این خط لوله ETL برای کمک به Talent.com برای پردازش 50,000 فایل در روز حاوی 5 میلیون رکورد استفاده کردیم و داده های آموزشی را با استفاده از ویژگی های استخراج شده از 90 روز داده خام Talent.com ایجاد کردیم - در مجموع 450 میلیون رکورد در 900,000 فایل. خط لوله ما به Talent.com کمک کرد تا سیستم توصیه را تنها در عرض 2 هفته بسازد و به تولید برساند. این راه حل تمام فرآیندهای ML از جمله ETL را در Amazon SageMaker بدون استفاده از سایر خدمات AWS انجام داد. سیستم توصیه شغلی باعث افزایش 8.6 درصدی نرخ کلیک در تست آنلاین A/B در مقایسه با راه حل قبلی مبتنی بر XGBoost شد و به اتصال میلیونها کاربر Talent.com به مشاغل بهتر کمک کرد.
نتیجه
این پست خط لوله ETL را که برای پردازش ویژگی برای آموزش و استقرار یک مدل توصیهکننده شغل در Talent.com ایجاد کردهایم، تشریح میکند. خط لوله ما از کارهای پردازش SageMaker برای پردازش کارآمد داده و استخراج ویژگی در مقیاس بزرگ استفاده می کند. کد استخراج ویژگی در پایتون پیادهسازی میشود و امکان استفاده از کتابخانههای محبوب ML را برای انجام استخراج ویژگی در مقیاس، بدون نیاز به پورت کد برای استفاده از PySpark میدهد.
ما خوانندگان را تشویق می کنیم تا امکان استفاده از خط لوله ارائه شده در این وبلاگ را به عنوان الگویی برای موارد استفاده خود که در آن استخراج ویژگی در مقیاس مورد نیاز است، بررسی کنند. این خط لوله می تواند توسط یک دانشمند داده برای ساخت یک مدل ML مورد استفاده قرار گیرد و همان خط لوله می تواند توسط مهندس ML برای اجرا در تولید استفاده شود. این می تواند زمان مورد نیاز برای تولید راه حل ML را به طور قابل توجهی کاهش دهد، همانطور که در مورد Talent.com اتفاق افتاد. خوانندگان می توانند به آموزش راه اندازی و اجرای کارهای پردازش SageMaker. همچنین خوانندگان را برای مشاهده پست معرفی می کنیم از متن تا شغل رویایی: ایجاد یک توصیهکننده شغلی مبتنی بر NLP در Talent.com با Amazon SageMaker، جایی که ما در مورد تکنیک های آموزش مدل یادگیری عمیق استفاده می کنیم آمازون SageMaker برای ساختن سیستم توصیه شغلی Talent.com.
درباره نویسندگان
 دیمیتری بسپالوف یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
دیمیتری بسپالوف یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
 یی شیانگ دانشمند کاربردی II در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابری خود را سرعت بخشند.
یی شیانگ دانشمند کاربردی II در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابری خود را سرعت بخشند.
 تانگ وانگ یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
تانگ وانگ یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
 آناتولی خومنکو مهندس ارشد یادگیری ماشین در Talent.com با اشتیاق به پردازش زبان طبیعی که افراد خوب را با مشاغل خوب تطبیق می دهد.
آناتولی خومنکو مهندس ارشد یادگیری ماشین در Talent.com با اشتیاق به پردازش زبان طبیعی که افراد خوب را با مشاغل خوب تطبیق می دهد.
 عبدالنور بزوح یک مدیر اجرایی با بیش از 25 سال تجربه در ساخت و ارائه راه حل های فناوری که به میلیون ها مشتری می رسد. عبدنور سمت مدیر ارشد فناوری (CTO) را در اختیار داشت Talent.com زمانی که تیم AWS این راه حل خاص را برای آن طراحی و اجرا کرد Talent.com.
عبدالنور بزوح یک مدیر اجرایی با بیش از 25 سال تجربه در ساخت و ارائه راه حل های فناوری که به میلیون ها مشتری می رسد. عبدنور سمت مدیر ارشد فناوری (CTO) را در اختیار داشت Talent.com زمانی که تیم AWS این راه حل خاص را برای آن طراحی و اجرا کرد Talent.com.
 یانجون چی مدیر ارشد علوم کاربردی در آزمایشگاه راه حل یادگیری ماشین آمازون است. او برای کمک به مشتریان AWS برای سرعت بخشیدن به هوش مصنوعی و پذیرش ابری خود، نوآوری می کند و از یادگیری ماشینی استفاده می کند.
یانجون چی مدیر ارشد علوم کاربردی در آزمایشگاه راه حل یادگیری ماشین آمازون است. او برای کمک به مشتریان AWS برای سرعت بخشیدن به هوش مصنوعی و پذیرش ابری خود، نوآوری می کند و از یادگیری ماشینی استفاده می کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/streamlining-etl-data-processing-at-talent-com-with-amazon-sagemaker/

