آمازون SageMaker Canvas یک فضای کاری بدون کد است که به تحلیلگران و دانشمندان داده شهروندی امکان می دهد پیش بینی های یادگیری ماشینی دقیق (ML) را برای نیازهای تجاری خود ایجاد کنند. از امروز، SageMaker Canvas از پیکربندیهای ساخت مدل پیشرفته مانند انتخاب روش آموزشی (بهینهسازی مجموعه یا فراپارامتر) و الگوریتمها، سفارشیسازی نسبت تقسیم دادههای آموزشی و اعتبارسنجی، و تعیین محدودیتهایی در تکرار خودکار و زمان اجرای کار پشتیبانی میکند، بنابراین به کاربران اجازه میدهد سفارشیسازی کنند. بدون نیاز به نوشتن یک خط کد، پیکربندی های ساختمان را مدل کنید. این انعطافپذیری میتواند توسعه مدل قویتر و روشنتری را ارائه دهد. ذینفعان غیرفنی میتوانند از ویژگیهای بدون کد با تنظیمات پیشفرض استفاده کنند، در حالی که دانشمندان داده شهروندی میتوانند با الگوریتمها و تکنیکهای مختلف ML آزمایش کنند و به آنها کمک کنند تا بفهمند کدام روش برای دادههایشان بهتر است و برای اطمینان از کیفیت و عملکرد مدل، بهینهسازی میشوند.
علاوه بر پیکربندی های ساختمان مدل، SageMaker Canvas اکنون یک تابلوی برتر مدل نیز ارائه می دهد. تابلوی امتیازات به شما امکان می دهد معیارهای عملکرد کلیدی (به عنوان مثال، دقت، دقت، یادآوری و امتیاز F1) را برای پیکربندی مدل های مختلف مقایسه کنید تا بهترین مدل برای داده های خود را شناسایی کنید، در نتیجه شفافیت را در ساخت مدل بهبود بخشیده و به شما در تصمیم گیری آگاهانه کمک می کند. انتخاب های مدل همچنین میتوانید کل گردش کار ساختمان مدل، از جمله مراحل پیشپردازش پیشنهادی، الگوریتمها و محدودههای فراپارامتر را در یک نوت بوک مشاهده کنید. برای دسترسی به این قابلیتها، از سیستم خارج شده و دوباره به SageMaker Canvas وارد شوید و انتخاب کنید پیکربندی مدل هنگام ساخت مدل ها
در این پست، شما را از طریق فرآیند استفاده از پیکربندیهای ساخت مدل پیشرفته SageMaker Canvas برای شروع آموزش بهینهسازی مجموعه و فراپارامتر (HPO) راهنمایی میکنیم.
بررسی اجمالی راه حل
در این بخش، دستورالعملهای گام به گام پیکربندیهای ساخت مدل پیشرفته SageMaker Canvas را به شما نشان میدهیم تا آموزش بهینهسازی مجموعه و فراپارامتر (HPO) را برای تجزیه و تحلیل مجموعه دادههایمان، ساخت مدلهای ML با کیفیت بالا و مشاهده تابلوی امتیازات مدل آغاز کنیم. تصمیم بگیرید که کدام مدل را برای استنتاج منتشر کنید. SageMaker Canvas می تواند به طور خودکار روش آموزشی را بر اساس اندازه مجموعه داده انتخاب کند، یا می توانید آن را به صورت دستی انتخاب کنید. انتخاب ها عبارتند از:
- با یکدیگر: استفاده می کند AutoGluon کتابخانه برای آموزش چندین مدل پایه. برای یافتن بهترین ترکیب برای مجموعه داده خود، حالت گروهی 10 آزمایش را با تنظیمات مدل و متا پارامترهای مختلف اجرا می کند. سپس این مدل ها را با استفاده از روش مجموعه انباشته برای ایجاد یک مدل پیش بینی بهینه ترکیب می کند. در حالت گروهی، SageMaker Canvas از انواع زیر الگوریتم های یادگیری ماشین پشتیبانی می کند:
- GBM سبک: یک چارچوب بهینه که از الگوریتمهای مبتنی بر درخت با تقویت گرادیان استفاده میکند. این الگوریتم از درختانی استفاده می کند که به جای عمق رشد می کنند و برای سرعت بسیار بهینه شده است.
- CatBoost: چارچوبی که از الگوریتم های مبتنی بر درخت با تقویت گرادیان استفاده می کند. برای مدیریت متغیرهای طبقه بندی شده بهینه شده است.
- XGBoost: چارچوبی که از الگوریتم های مبتنی بر درخت با تقویت گرادیان استفاده می کند که به جای وسعت، در عمق رشد می کند.
- جنگل تصادفی: یک الگوریتم مبتنی بر درخت که از چندین درخت تصمیم بر روی نمونههای فرعی تصادفی دادهها با جایگزینی استفاده میکند. درختان در هر سطح به گره های بهینه تقسیم می شوند. تصمیمات هر درخت با هم به طور میانگین برای جلوگیری از برازش بیش از حد و بهبود پیش بینی ها محاسبه می شود.
- درختان اضافی: یک الگوریتم مبتنی بر درخت که از چندین درخت تصمیم در کل مجموعه داده استفاده می کند. درختان به طور تصادفی در هر سطح تقسیم می شوند. تصمیمات هر درخت برای جلوگیری از برازش بیش از حد و بهبود پیش بینی ها متوسط است. درختان اضافی درجه ای از تصادفی سازی را در مقایسه با الگوریتم جنگل تصادفی اضافه می کنند.
- مدل های خطی: چارچوبی که از یک معادله خطی برای مدل سازی رابطه بین دو متغیر در داده های مشاهده شده استفاده می کند.
- مشعل شبکه عصبی: یک مدل شبکه عصبی که با استفاده از Pytorch پیاده سازی شده است.
- شبکه عصبی fast.ai: یک مدل شبکه عصبی که با استفاده از fast.ai پیاده سازی شده است.
- بهینه سازی هایپرپارامتر (HPO): SageMaker Canvas بهترین نسخه یک مدل را با تنظیم هایپرپارامترها با استفاده از بهینهسازی بیزی یا بهینهسازی چند وفاداری در حین اجرای کارهای آموزشی روی مجموعه داده شما پیدا میکند. حالت HPO الگوریتم هایی را انتخاب می کند که بیشترین ارتباط را با مجموعه داده شما دارند و بهترین محدوده ابرپارامترها را برای تنظیم مدل های شما انتخاب می کند. برای تنظیم مدلهای خود، حالت HPO تا 100 آزمایش (پیشفرض) اجرا میشود تا تنظیمات فراپارامترهای بهینه را در محدوده انتخابشده پیدا کند. اگر اندازه مجموعه داده شما کمتر از 100 مگابایت است، SageMaker Canvas از بهینه سازی بیزی استفاده می کند. SageMaker Canvas در صورتی که مجموعه داده شما بزرگتر از 100 مگابایت باشد، بهینه سازی چند وفاداری را انتخاب می کند. در بهینه سازی چند وفاداری، معیارها به طور مداوم از ظروف آموزشی منتشر می شوند. آزمایشی که در برابر معیار هدف انتخابی ضعیف عمل می کند، زود متوقف می شود. آزمایشی که عملکرد خوبی داشته باشد، منابع بیشتری تخصیص می یابد. در حالت HPO، SageMaker Canvas از انواع زیر الگوریتم های یادگیری ماشین پشتیبانی می کند:
- یادگیرنده خطی: یک الگوریتم یادگیری نظارت شده که می تواند مسائل طبقه بندی یا رگرسیون را حل کند.
- XGBoost: یک الگوریتم یادگیری نظارت شده که سعی می کند با ترکیب مجموعه ای از تخمین ها از مجموعه ای از مدل های ساده تر و ضعیف تر، یک متغیر هدف را به طور دقیق پیش بینی کند.
- الگوریتم یادگیری عمیق: یک پرسپترون چند لایه (MLP) و شبکه عصبی مصنوعی پیشخور. این الگوریتم می تواند داده هایی را که به صورت خطی قابل تفکیک نیستند، مدیریت کند.
- خودکار: SageMaker Canvas به طور خودکار یا حالت گروه یا حالت HPO را بر اساس اندازه مجموعه داده شما انتخاب می کند. اگر مجموعه داده شما بزرگتر از 100 مگابایت است، SageMaker Canvas HPO را انتخاب می کند. در غیر این صورت، حالت گروهی را انتخاب می کند.
پیش نیازها
برای این پست باید پیش نیازهای زیر را تکمیل کنید:
- یک حساب AWS.
- SageMaker Canvas را راه اندازی کنید. دیدن پیش نیازهای راه اندازی آمازون SageMaker Canvas.
- کلاسیک را دانلود کنید مجموعه داده تایتانیک به رایانه محلی شما
یک مدل ایجاد کنید
ما شما را با استفاده از مجموعه داده تایتانیک و بوم SageMaker برای ایجاد مدلی راهنمایی می کنیم که پیش بینی می کند کدام مسافران از غرق شدن کشتی تایتانیک جان سالم به در برده اند. این یک مشکل طبقه بندی باینری است. ما روی ایجاد یک آزمایش Canvas با استفاده از حالت آموزش گروهی تمرکز میکنیم و نتایج امتیاز F1 و زمان اجرا کلی را با آزمایش SageMaker Canvas با استفاده از حالت آموزش HPO (100 آزمایش) مقایسه میکنیم.
| نام ستون | توضیحات: |
| مسافر | شماره شناسایی |
| زنده ماند | بقاء |
| پی کلاس | کلاس بلیط |
| نام | نام مسافر |
| ارتباط جنسی | ارتباط جنسی |
| سن | سن در سال |
| Sibsp | تعداد خواهر و برادر یا همسران در کشتی تایتانیک |
| پارچ | تعداد والدین یا فرزندان در کشتی تایتانیک |
| بلیط | شماره بلیط |
| کرایه | نمایشگاه مسافر |
| کابین | شماره کابین |
| مشخص شده است | بندر سوار شدن |
La مجموعه داده تایتانیک دارای 890 سطر و 12 ستون. این شامل اطلاعات جمعیت شناختی مسافران (سن، جنس، کلاس بلیط و غیره) و ستون هدف Survived (بله/خیر) است.
- با وارد کردن مجموعه داده به SageMaker Canvas شروع کنید. مجموعه داده را نام ببرید غول اسا.

- مجموعه داده تایتانیک را انتخاب کرده و انتخاب کنید مدل جدید ایجاد کنید. یک نام برای مدل وارد کنید، انتخاب کنید تجزیه و تحلیل پیش بینی به عنوان نوع مشکل، و انتخاب کنید ساختن.

- تحت یک ستون را برای پیش بینی انتخاب کنید، استفاده از ستون هدف برای انتخاب کشویی کنید زنده ماند. ستون هدف Survived یک نوع داده باینری با مقادیر 0 (زنده نشد) و 1 (بقا) است.
مدل را پیکربندی و اجرا کنید
در آزمایش اول، SageMaker Canvas را پیکربندی میکنید تا یک مجموعه آموزشی را روی مجموعه داده با دقت به عنوان معیار هدف خود اجرا کند. نمره دقت بالاتر نشان می دهد که مدل پیش بینی های صحیح تری انجام می دهد، در حالی که نمره دقت پایین تر نشان می دهد که مدل خطاهای بیشتری دارد. دقت برای مجموعه داده های متعادل به خوبی کار می کند. برای آموزش گروه، XGBoost، Random Forest، CatBoost و Linear Models را به عنوان الگوریتم های خود انتخاب کنید. تقسیم داده ها را در 80/20 پیش فرض برای آموزش و اعتبار سنجی بگذارید. و در نهایت، کار آموزشی را طوری پیکربندی کنید که حداکثر زمان اجرای کار 1 ساعت اجرا شود.
- با انتخاب شروع کنید پیکربندی مدل.

- این یک پنجره مودال را برای پیکربندی مدل. انتخاب فناوری از صفحه ناوبری

- پیکربندی مدل خود را با انتخاب شروع کنید متریک عینی. برای این آزمایش، را انتخاب کنید دقت. امتیاز دقت به شما می گوید که چقدر پیش بینی های مدل به طور کلی درست است.

- انتخاب کنید روش و الگوریتم های آموزشی را انتخاب کنید و با هم. روشهای گروهی در یادگیری ماشینی شامل ایجاد چندین مدل و سپس ترکیب آنها برای تولید نتایج بهبودیافته است. این تکنیک برای افزایش دقت پیش بینی با بهره گیری از نقاط قوت الگوریتم های مختلف استفاده می شود. همانطور که در مسابقات مختلف یادگیری ماشین و برنامه های کاربردی در دنیای واقعی نشان داده شده است، روش های مجموعه برای تولید راه حل های دقیق تری نسبت به یک مدل واحد شناخته شده اند.

- الگوریتم های مختلف را برای استفاده برای مجموعه انتخاب کنید. برای این آزمایش، را انتخاب کنید XGBoost, خطی, CatBoostو جنگل تصادفی. تمام الگوریتم های دیگر را پاک کنید.

- انتخاب کنید تقسیم داده ها از صفحه ناوبری برای این آزمایش، تقسیم آموزش و اعتبار سنجی پیش فرض را 80/20 بگذارید. تکرار بعدی آزمایش از یک تقسیم متفاوت استفاده میکند تا ببیند آیا منجر به عملکرد بهتر مدل میشود یا خیر.

- انتخاب کنید حداکثر نامزدها و زمان اجرا از پنجره ناوبری و تنظیم کنید حداکثر زمان اجرای کار تا 1 ساعت و انتخاب کنید ذخیره.

- را انتخاب کنید ساخت استاندارد برای شروع ساخت

در این مرحله، SageMaker Canvas در حال فراخوانی آموزش مدل بر اساس پیکربندی شما است. از آنجایی که حداکثر زمان اجرا را برای کار آموزشی 1 ساعت تعیین کرده اید، SageMaker Canvas تا یک ساعت طول می کشد تا کار آموزشی را انجام دهد.

نتایج را مرور کنید
پس از اتمام کار آموزشی، SageMaker Canvas به طور خودکار شما را به نمای Analyze بازمی گرداند و نتایج معیارهای هدفی را که برای آزمایش آموزش مدل پیکربندی کرده بودید، نشان می دهد. در این حالت می بینید که دقت مدل 86.034 درصد است.
- دکمه فلش جمع کردن کنار را انتخاب کنید تابلوی امتیازات مدل برای بررسی داده های عملکرد مدل
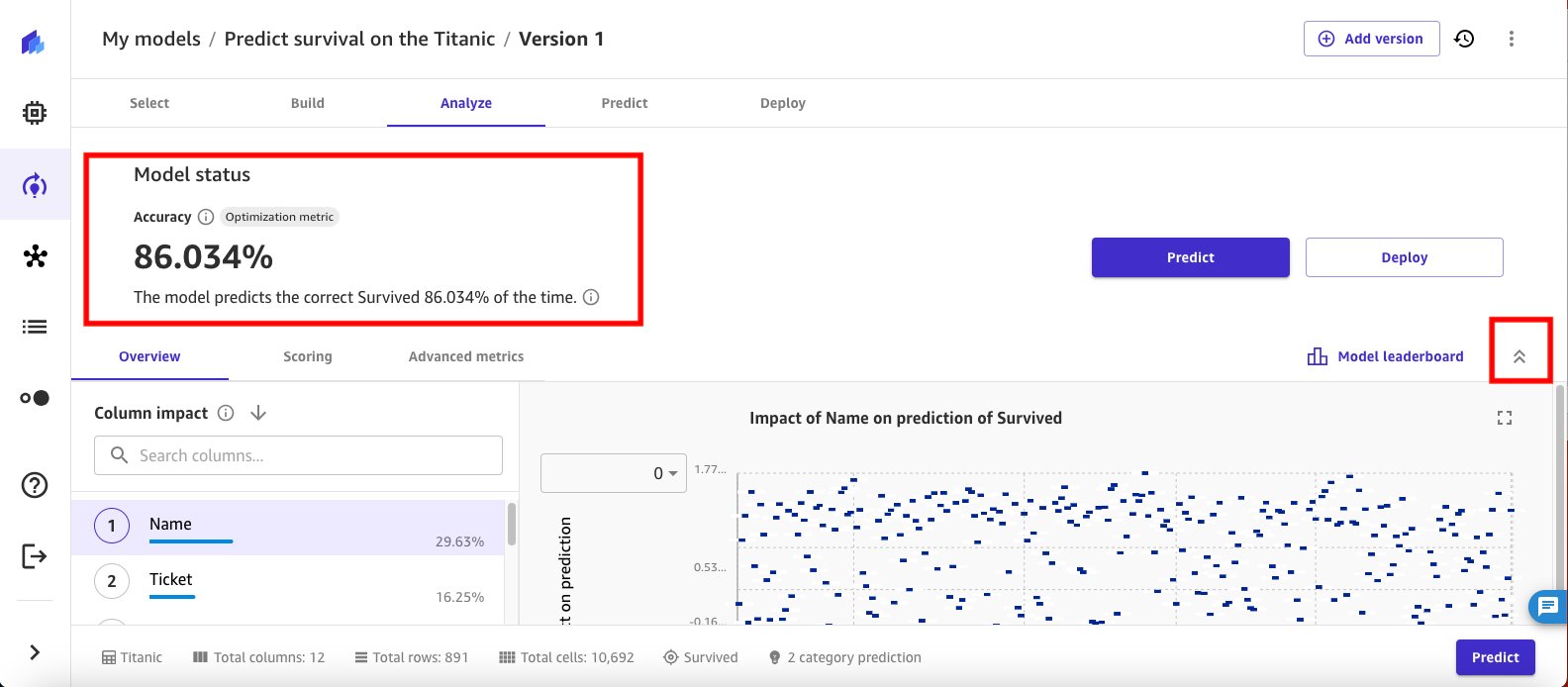
- را انتخاب کنید نمره دهی برای فرو رفتن عمیقتر در بینشهای دقت مدل. مدل آموزش دیده گزارش می دهد که می تواند در 89.72 درصد مواقع مسافرانی که جان سالم به در نبرده اند را به درستی پیش بینی کند.

- را انتخاب کنید معیارهای پیشرفته برای ارزیابی جزئیات عملکرد مدل اضافی. با انتخاب شروع کنید جدول متریک برای بررسی جزئیات معیارها مانند F1, دقت, به یاد بیاوریدو AUC.

- SageMaker Canvas همچنین به تجسم آن کمک می کند ماتریس سردرگمی برای مدل آموزش دیده

- و تجسم می کند منحنی فراخوان دقیق. AUPRC 0.86 دقت طبقه بندی بالایی را نشان می دهد که خوب است.

- را انتخاب کنید تابلوی امتیازات مدل برای مقایسه معیارهای کلیدی عملکرد (مانند دقت، دقت، یادآوری و امتیاز F1) برای مدلهای مختلف ارزیابیشده توسط SageMaker Canvas برای تعیین بهترین مدل برای دادهها، بر اساس پیکربندی که برای این آزمایش تنظیم کردهاید. مدل پیشفرض با بهترین عملکرد با علامت مشخص میشود مدل پیش فرض برچسب روی تابلوی امتیازات مدل

- میتوانید از منوی زمینه در کنار استفاده کنید تا در جزئیات هر یک از مدلها عمیقتر شوید یا یک مدل را به مدل پیشفرض تبدیل کنید. انتخاب کنید مشاهده جزئیات مدل در مدل دوم در تابلوی امتیازات برای دیدن جزئیات.

- SageMaker Canvas نما را تغییر می دهد تا جزئیات نامزد مدل انتخاب شده را نشان دهد. در حالی که جزئیات مدل پیشفرض از قبل در دسترس است، نمای جزییات مدل جایگزین 10 تا 15 دقیقه طول میکشد تا جزئیات را ترسیم کند.

یک مدل دوم ایجاد کنید
اکنون که مدلی را ساخته، اجرا و بررسی کرده اید، بیایید مدل دومی را برای مقایسه بسازیم.
- با انتخاب به نمای مدل پیش فرض برگردید X در گوشه بالا حالا، انتخاب کن اضافه کردن نسخه برای ایجاد یک نسخه جدید از مدل.

- مجموعه داده تایتانیک را که در ابتدا ایجاد کردید انتخاب کنید و سپس انتخاب کنید مجموعه داده را انتخاب کنید.

SageMaker Canvas به طور خودکار مدل را با ستون هدف که قبلاً انتخاب شده است بارگذاری می کند. در این آزمایش دوم، به آموزش HPO می روید تا ببینید آیا نتایج بهتری برای مجموعه داده به همراه دارد یا خیر. برای این مدل، شما همان معیارهای هدف (دقت) را برای مقایسه با آزمایش اول نگه دارید و از الگوریتم XGBoost برای آموزش HPO استفاده کنید. شما تقسیم داده برای آموزش و اعتبار سنجی را به 70/30 تغییر می دهید و حداکثر نامزدها و مقادیر زمان اجرا را برای کار HPO به 20 نامزد و حداکثر زمان اجرای کار را 1 ساعت پیکربندی می کنید.
مدل را پیکربندی و اجرا کنید
- آزمایش دوم را با انتخاب شروع کنید پیکربندی مدل برای پیکربندی جزئیات آموزش مدل خود.
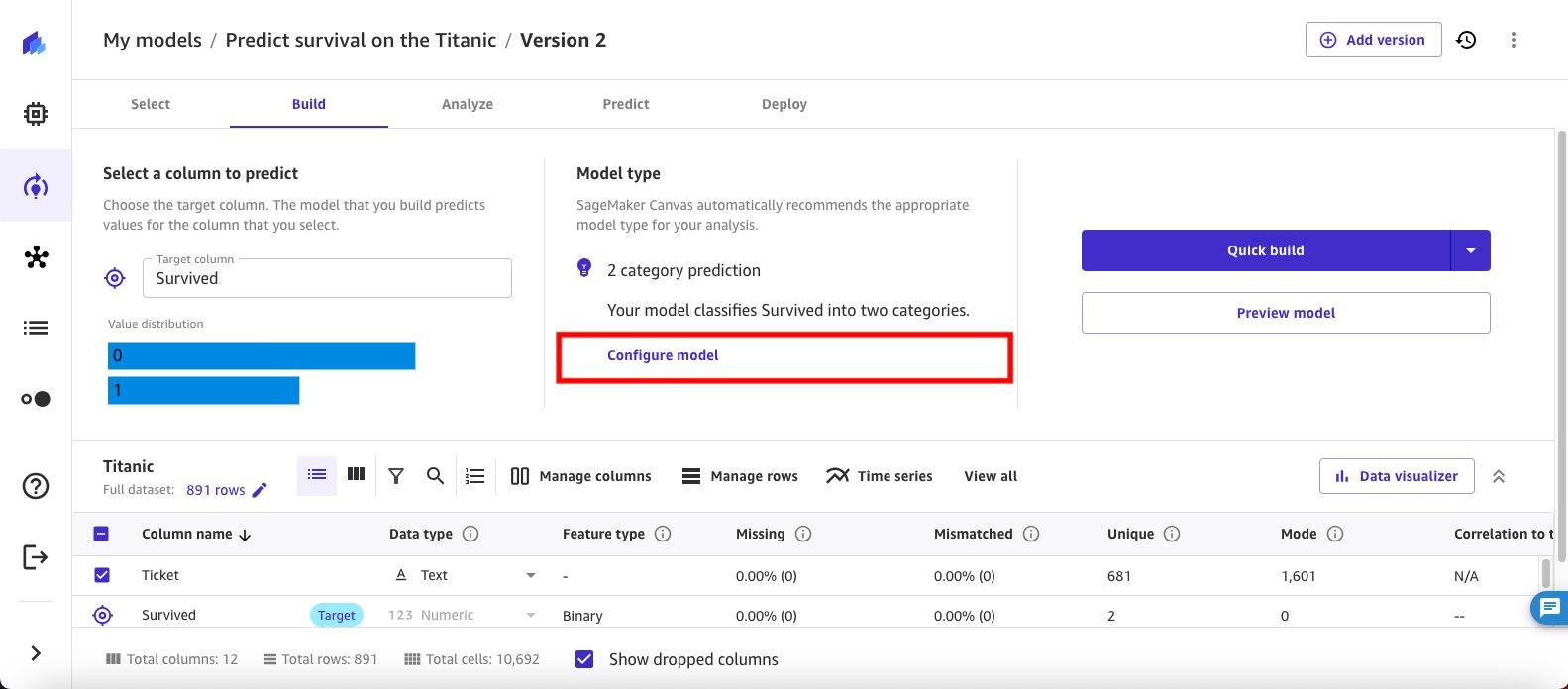
- در پیکربندی مدل پنجره را انتخاب کنید متریک عینی از صفحه ناوبری برای متریک عینی، از منوی کشویی برای انتخاب استفاده کنید دقت، این به شما امکان می دهد تمام خروجی های نسخه را در کنار هم ببینید و مقایسه کنید.
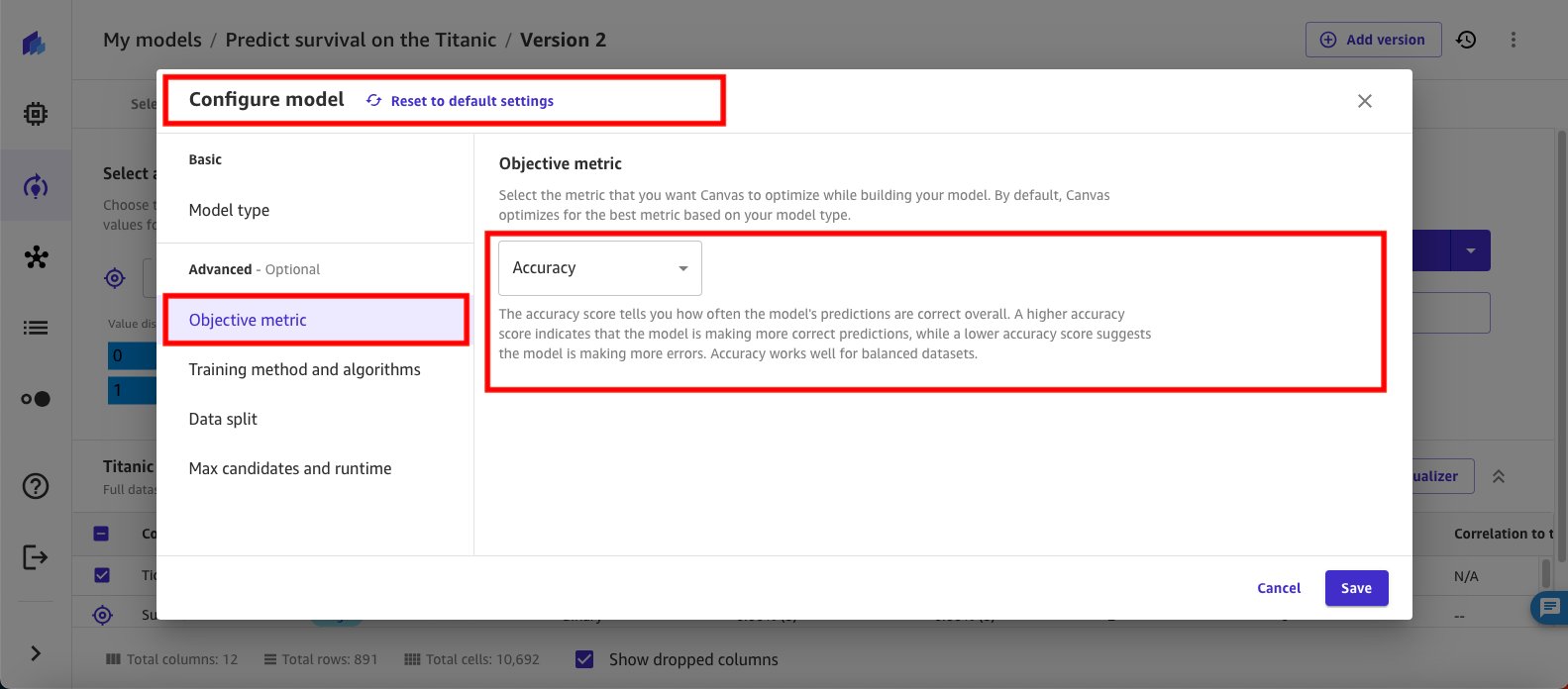
- انتخاب کنید روش و الگوریتم های آموزشی. انتخاب بهینه سازی هایپرپارامتر برای روش آموزش سپس برای انتخاب الگوریتم ها به پایین اسکرول کنید.

- انتخاب کنید XGBoost برای الگوریتم XGBoost تقویت درخت موازی را فراهم می کند که بسیاری از مسائل علم داده را به سرعت و با دقت حل می کند و طیف وسیعی از فراپارامترها را ارائه می دهد که می توانند برای بهبود و استفاده کامل از مدل XGBoost تنظیم شوند.

- انتخاب کنید تقسیم داده ها. برای این مدل، تقسیم داده های آموزشی و اعتبارسنجی را روی 70/30 تنظیم کنید.

- انتخاب کنید حداکثر نامزدها و زمان اجرا و مقادیر کار HPO را روی 20 برای the قرار دهید حداکثر نامزدها و 1 ساعت برای حداکثر زمان اجرای کار. انتخاب کنید ذخیره برای تکمیل پیکربندی مدل دوم.

- اکنون که مدل دوم را پیکربندی کردید، انتخاب کنید ساخت استاندارد برای شروع آموزش

SageMaker Canvas از این پیکربندی برای شروع کار HPO استفاده می کند. این کار آموزشی نیز مانند کار اول تا یک ساعت طول خواهد کشید.

نتایج را مرور کنید
وقتی کار آموزش HPO کامل شد (یا حداکثر زمان اجرا منقضی شد)، SageMaker Canvas خروجی کار آموزشی را بر اساس مدل پیشفرض نمایش میدهد و امتیاز دقت مدل را نشان میدهد.
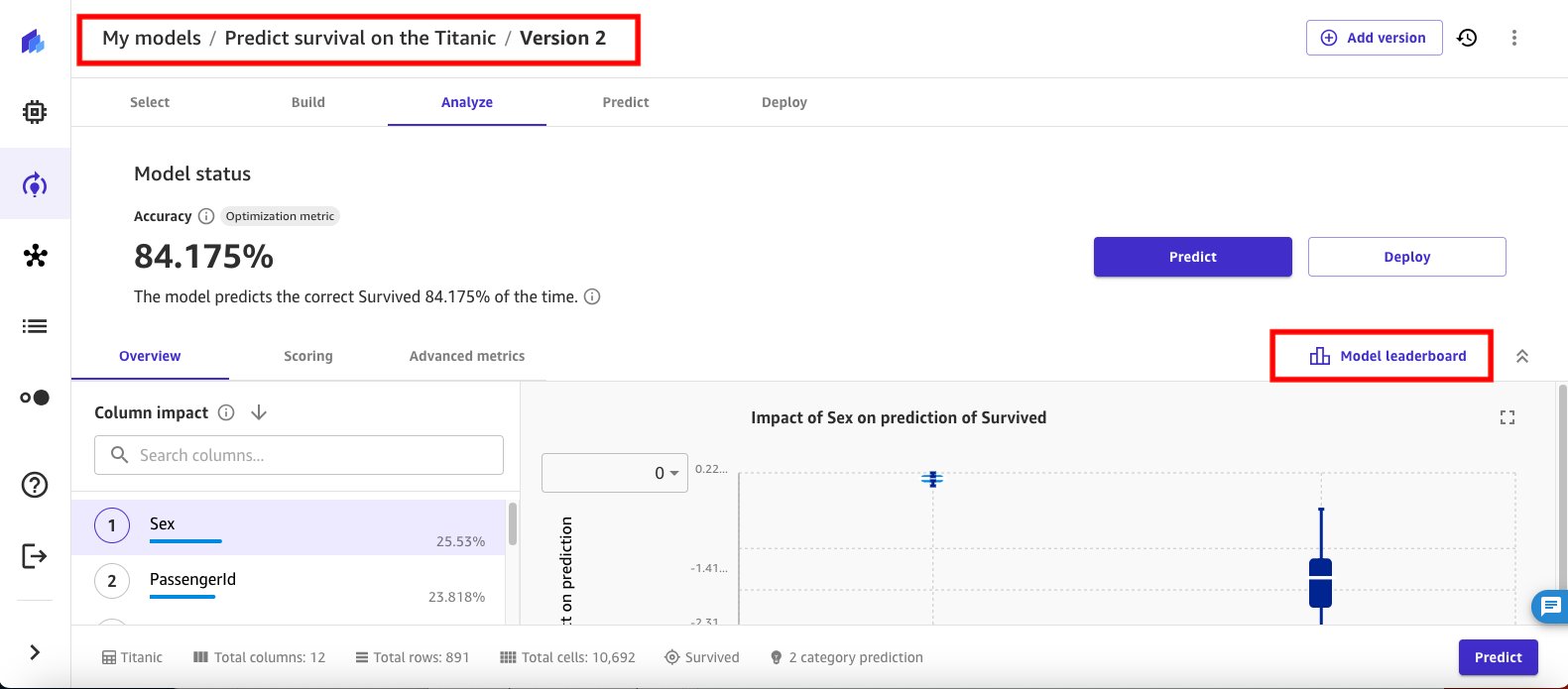
- را انتخاب کنید تابلوی امتیازات مدل برای مشاهده لیست تمام 20 مدل کاندید از دوره آموزشی HPO. بهترین مدل، بر اساس هدف برای یافتن بهترین دقت، به عنوان پیش فرض مشخص می شود.

در حالی که دقت از به طور پیش فرض مدل بهترین است، مدل دیگری از اجرای کار HPO دارای سطح بالاتری در زیر امتیاز منحنی ROC (AUC) است. امتیاز AUC برای ارزیابی عملکرد یک مدل طبقه بندی باینری استفاده می شود. AUC بالاتر نشان می دهد که مدل در تشخیص بهتر بین دو کلاس است، با 1 نمره کامل و 0.5 نشان دهنده حدس تصادفی است.
- از منوی زمینه استفاده کنید تا مدلی با AUC بالاتر به مدل پیش فرض تبدیل شود. منوی زمینه را برای آن مدل انتخاب کرده و انتخاب کنید تغییر به مدل پیش فرض گزینه ای در منوی خط همانطور که در شکل 31 نشان داده شده است.

SageMaker Canvas چند دقیقه طول می کشد تا مدل انتخاب شده را به مدل پیش فرض جدید برای نسخه 2 آزمایش تغییر دهد و آن را به بالای لیست مدل منتقل کند.

مدل ها را مقایسه کنید
در این مرحله، شما دو نسخه از مدل خود دارید و می توانید با رفتن به آن ها را در کنار هم مشاهده کنید مدل های من در بوم SageMaker.
- انتخاب کنید پیش بینی بقا در تایتانیک برای دیدن نسخه های مدل موجود

- دو نسخه وجود دارد و عملکرد آنها به صورت جدولی برای مقایسه کنار هم نمایش داده می شود.

- می بینید که نسخه 1 مدل (که با استفاده از الگوریتم های گروهی آموزش داده شده است) دقت بهتری دارد. اکنون می توانید از SageMaker Canvas برای ایجاد یک نوت بوک SageMaker - با کد، نظرات و دستورالعمل ها - برای سفارشی کردن AutoGluon آزمایش کنید و گردش کار SageMaker Canvas را بدون نوشتن یک خط کد اجرا کنید. با انتخاب منوی زمینه و انتخاب می توانید نوت بوک SageMaker را ایجاد کنید مشاهده نوت بوک.

- نوت بوک SageMaker در یک پنجره پاپ آپ ظاهر می شود. این نوت بوک به شما کمک می کند تا پارامترهای پیشنهادی SageMaker Canvas را بررسی و اصلاح کنید. میتوانید به صورت تعاملی یکی از پیکربندیهای پیشنهادی SageMaker Canvas را انتخاب کنید، آن را تغییر دهید و یک کار پردازشی برای آموزش مدلها بر اساس پیکربندی انتخابشده در محیط SageMaker Studio اجرا کنید.

استنباط
اکنون که بهترین مدل را شناسایی کرده اید، می توانید از منوی زمینه استفاده کنید آن را به یک نقطه پایانی برای استنتاج بلادرنگ مستقر کنید.

یا از منوی زمینه برای عملیاتی کردن مدل ML خود در تولید استفاده کنید ثبت مدل یادگیری ماشین (ML) در رجیستری مدل SageMaker.

پاک کردن
برای جلوگیری از تحمیل هزینههای بعدی، منابعی را که هنگام دنبال کردن این پست ایجاد کردهاید حذف کنید. SageMaker Canvas برای مدت جلسه صورتحساب شما را دریافت می کند، و توصیه می کنیم زمانی که از SageMaker Canvas استفاده نمی کنید از سیستم خارج شوید.
دیدن خروج از Amazon SageMaker Canvas برای جزئیات بیشتر.
نتیجه
SageMaker Canvas ابزار قدرتمندی است که یادگیری ماشین را دموکراتیزه میکند و به ذینفعان غیر فنی و دانشمندان داده شهروندی ارائه میدهد. ویژگیهای جدید معرفیشده، از جمله پیکربندیهای پیشرفته ساخت مدل و تابلوی امتیازات مدل، انعطافپذیری و شفافیت پلتفرم را افزایش میدهد. این به شما امکان میدهد تا مدلهای یادگیری ماشینی خود را با نیازهای خاص کسبوکار بدون جستجو در کد تنظیم کنید. توانایی سفارشیسازی روشهای آموزشی، الگوریتمها، تقسیمبندی دادهها و سایر پارامترها به شما این امکان را میدهد تا تکنیکهای مختلف ML را آزمایش کنید و درک عمیقتری از عملکرد مدل را تقویت کنید.
معرفی تابلوی امتیازات مدل یک پیشرفت قابل توجه است که نمای کلی روشنی از معیارهای عملکرد کلیدی برای پیکربندیهای مختلف ارائه میدهد. این شفافیت به کاربران اجازه می دهد تا تصمیمات آگاهانه ای در مورد انتخاب مدل و بهینه سازی بگیرند. SageMaker Canvas با نمایش کل گردش کار ساخت مدل، از جمله مراحل پیشپردازش پیشنهادی، الگوریتمها و محدودههای فراپارامتر در یک نوت بوک، درک جامعی از فرآیند توسعه مدل را تسهیل میکند.
برای شروع سفر ML کمکد/بدون کد، ببینید آمازون SageMaker Canvas.
تشکر ویژه از همه کسانی که در راه اندازی شرکت کردند:
Esha Dutta، Ed Cheung، Max Kondrashov، Allan Johnson، Ridhim Rastogi، Ranga Reddy Palelra، Ruochen Wen، Ruinong Tian، Sandipan Manna، Renu Rozera، Vikash Garg، Ramesh Sekaran و Gunjan Garg
درباره نویسنده
 جانیشا آناند یک مدیر ارشد محصول در تیم SageMaker Low/No Code ML است که شامل SageMaker Canvas و SageMaker Autopilot است. او از قهوه، فعال ماندن و گذراندن وقت با خانواده اش لذت می برد.
جانیشا آناند یک مدیر ارشد محصول در تیم SageMaker Low/No Code ML است که شامل SageMaker Canvas و SageMaker Autopilot است. او از قهوه، فعال ماندن و گذراندن وقت با خانواده اش لذت می برد.
 ایندی ساونی یک رهبر ارشد راه حل های مشتری با خدمات وب آمازون است. ایندی که همیشه از مشکلات مشتری برعکس کار می کند، به مدیران مشتریان سازمانی AWS در سفر منحصر به فرد خود در تحول ابری توصیه می کند. او بیش از 25 سال تجربه در کمک به سازمان های سازمانی دارد تا فناوری های نوظهور و راه حل های تجاری را اتخاذ کنند. ایندی یک متخصص عمیق در انجمن حوزه فنی AWS برای هوش مصنوعی و یادگیری ماشین (AI/ML) است که در زمینه هوش مصنوعی مولد و راهحلهای SageMaker با کد/بدون کد (LCNC) تخصص دارد.
ایندی ساونی یک رهبر ارشد راه حل های مشتری با خدمات وب آمازون است. ایندی که همیشه از مشکلات مشتری برعکس کار می کند، به مدیران مشتریان سازمانی AWS در سفر منحصر به فرد خود در تحول ابری توصیه می کند. او بیش از 25 سال تجربه در کمک به سازمان های سازمانی دارد تا فناوری های نوظهور و راه حل های تجاری را اتخاذ کنند. ایندی یک متخصص عمیق در انجمن حوزه فنی AWS برای هوش مصنوعی و یادگیری ماشین (AI/ML) است که در زمینه هوش مصنوعی مولد و راهحلهای SageMaker با کد/بدون کد (LCNC) تخصص دارد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/build-and-evaluate-machine-learning-models-with-advanced-configurations-using-the-sagemaker-canvas-model-leaderboard/

