ناشران دیجیتال به طور مداوم به دنبال راههایی برای سادهسازی و خودکارسازی گردشهای کاری رسانههای خود هستند تا محتوای جدید را با بیشترین سرعت تولید و منتشر کنند.
ناشران می توانند مخازنی حاوی میلیون ها تصویر داشته باشند و برای صرفه جویی در هزینه، باید بتوانند از این تصاویر در مقالات استفاده مجدد کنند. یافتن تصویری که به بهترین وجه با یک مقاله مطابقت دارد در مخازن با این مقیاس میتواند کاری زمانبر، تکراری و دستی باشد که میتواند خودکار شود. همچنین متکی بر تصاویر موجود در مخزن است که به درستی برچسب گذاری شده اند، که می تواند خودکار نیز باشد (برای یک داستان موفقیت مشتری، به Aller Media با KeyCore و AWS موفق می شود).
در این پست نحوه استفاده را نشان می دهیم شناسایی آمازون, Amazon SageMaker JumpStartو سرویس جستجوی باز آمازون برای حل این مشکل تجاری آمازون Rekognition اضافه کردن قابلیت تجزیه و تحلیل تصویر به برنامه های خود را بدون هیچ گونه تخصص یادگیری ماشینی (ML) آسان می کند و با API های مختلفی برای انجام موارد استفاده مانند تشخیص اشیا، تعدیل محتوا، تشخیص و تجزیه و تحلیل چهره، و تشخیص متن و افراد مشهور ارائه می شود. ما در این مثال استفاده می کنیم. SageMaker JumpStart یک سرویس کمکد است که راهحلهای از پیش ساخته شده، نوتبوکهای نمونه، و بسیاری از مدلهای پیشرفته و از پیش آموزشدیدهشده از منابع عمومی را ارائه میکند که به راحتی با یک کلیک در حساب AWS شما مستقر میشوند. . این مدلها به گونهای بستهبندی شدهاند که بهطور ایمن و آسان قابل استقرار باشند آمازون SageMaker API ها SageMaker JumpStart Foundation Hub جدید به شما امکان می دهد به راحتی مدل های زبان بزرگ (LLM) را مستقر کرده و آنها را با برنامه های خود ادغام کنید. OpenSearch Service یک سرویس کاملاً مدیریت شده است که استقرار، مقیاسبندی و اجرای OpenSearch را ساده میکند. سرویس OpenSearch به شما امکان می دهد بردارها و سایر انواع داده ها را در یک فهرست ذخیره کنید و عملکرد غنی را ارائه می دهد که به شما امکان می دهد اسناد را با استفاده از بردارها و اندازه گیری ارتباط معنایی جستجو کنید، که در این پست از آنها استفاده می کنیم.
هدف نهایی این پست نشان دادن این است که چگونه میتوانیم مجموعهای از تصاویر را که از نظر معنایی شبیه به برخی از متنها هستند، چه یک مقاله یا یک خلاصه تلویزیونی، نشان دهیم.
اسکرین شات زیر نمونه ای از گرفتن یک مقاله کوچک به عنوان ورودی جستجو را نشان می دهد، به جای استفاده از کلمات کلیدی، و قادر به نمایش تصاویر مشابه از نظر معنایی.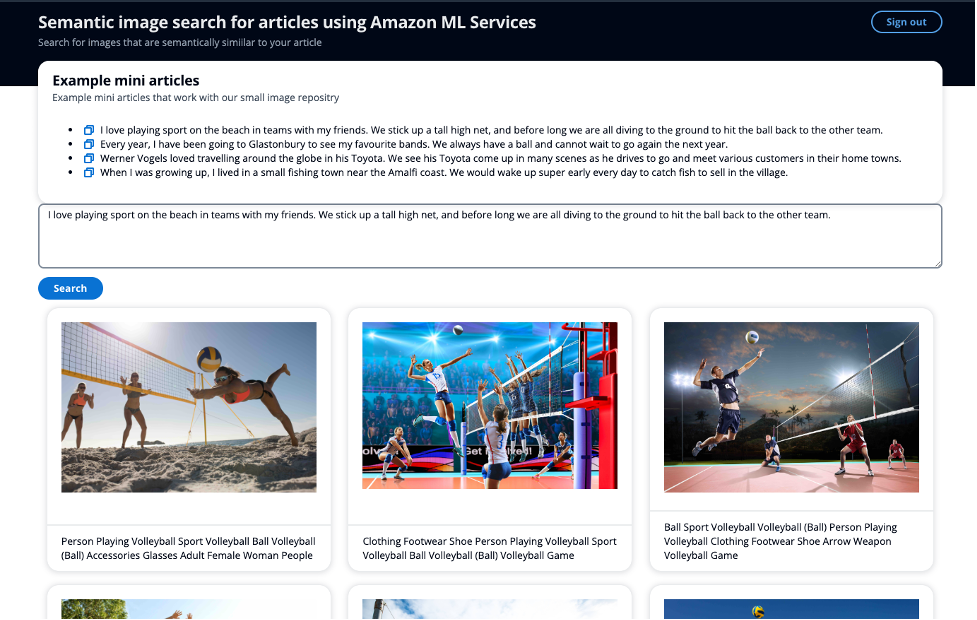
بررسی اجمالی راه حل
راه حل به دو بخش اصلی تقسیم می شود. ابتدا، با استفاده از آمازون Rekognition، متادیتای برچسب و افراد مشهور را از تصاویر استخراج می کنید. سپس با استفاده از یک LLM یک جاسازی ابرداده ایجاد می کنید. شما نام افراد مشهور و جاسازی ابرداده ها را در سرویس OpenSearch ذخیره می کنید. در دومین بخش اصلی، شما یک API دارید تا نمایه سرویس OpenSearch خود را برای تصاویر با استفاده از قابلیت جستجوی هوشمند OpenSearch جستجو کنید تا تصاویری را پیدا کنید که از نظر معنایی مشابه متن شما هستند.
این راه حل از خدمات رویداد محور ما استفاده می کند پل رویداد آمازون, توابع مرحله AWSو AWS لامبدا برای هماهنگ کردن فرآیند استخراج ابرداده از تصاویر با استفاده از آمازون Rekognition. آمازون Rekognition دو فراخوانی API را برای استخراج برچسب ها و افراد مشهور از تصویر انجام خواهد داد.
API تشخیص سلبریتی آمازون Rekognition، تعدادی از عناصر را در پاسخ برمی گرداند. برای این پست از موارد زیر استفاده می کنید:
- نام، شناسه و آدرس اینترنتی – نام افراد مشهور، شناسه شناسایی منحصربهفرد آمازون، و فهرستی از نشانیهای اینترنتی مانند پیوند IMDb یا ویکیپدیای افراد مشهور برای اطلاعات بیشتر.
- MatchConfidence - امتیاز اطمینان مطابقت که می تواند برای کنترل رفتار API استفاده شود. توصیه می کنیم برای انتخاب نقطه عملیاتی مورد نظر خود، یک آستانه مناسب برای این امتیاز در برنامه خود اعمال کنید. به عنوان مثال، با تعیین آستانه 99٪، می توانید موارد مثبت کاذب بیشتری را حذف کنید، اما ممکن است برخی از مسابقات احتمالی را از دست بدهید.
در دومین تماس API خود، API تشخیص برچسب آمازون Rekognition، تعدادی از عناصر را در پاسخ برمی گرداند. شما از موارد زیر استفاده می کنید:
یک مفهوم کلیدی در جستجوی معنایی، تعبیهها است. تعبیه کلمه یک نمایش عددی از یک کلمه یا گروهی از کلمات، به شکل یک برداری است. هنگامی که بردارهای زیادی دارید، می توانید فاصله بین آنها را اندازه گیری کنید و بردارهایی که از نظر فاصله نزدیک هستند از نظر معنایی مشابه هستند. بنابراین، اگر یک جاسازی از تمام ابردادههای تصاویر خود ایجاد کنید، و سپس متن خود را جاسازی کنید، مثلاً یک مقاله یا خلاصه تلویزیونی، با استفاده از همان مدل، میتوانید تصاویری را پیدا کنید که از نظر معنایی مشابه شما هستند. متن داده شده
مدلهای زیادی در SageMaker JumpStart برای ایجاد جاسازیها وجود دارد. برای این راه حل، از GPT-J 6B Embedding استفاده می کنید در آغوش کشیدن صورت. تعبیههای باکیفیت تولید میکند و یکی از معیارهای عملکرد برتر را طبق Hugging Face دارد. نتایج ارزیابی. بستر آمازون گزینه دیگری است که هنوز در پیش نمایش است، که در آن می توانید مدل آمازون Titan Text Embeddings را برای تولید جاسازی ها انتخاب کنید.
شما از مدل از پیش آموزش دیده GPT-J از SageMaker JumpStart برای ایجاد یک جاسازی ابرداده تصویر و ذخیره آن به عنوان بردار k-NN در فهرست سرویس OpenSearch شما، همراه با نام افراد مشهور در یک فیلد دیگر.
بخش دوم راه حل این است که 10 تصویر برتر را به کاربر برگردانید که از نظر معنایی مشابه متن آنها باشد، خواه این یک مقاله باشد یا خلاصه تلویزیون، از جمله افراد مشهور در صورت وجود. هنگام انتخاب تصویری برای همراهی با مقاله، میخواهید تصویر با نکات مرتبط مقاله همخوانی داشته باشد. SageMaker JumpStart مدلهای خلاصهسازی بسیاری را میزبانی میکند که میتواند متن طولانی را بگیرد و آن را به نکات اصلی از متن اصلی کاهش دهد. برای مدل خلاصه سازی، از آزمایشگاه های AI21 مدل خلاصه کردن این مدل خلاصههایی از مقالات خبری را با کیفیت بالا ارائه میکند و متن منبع میتواند تقریباً شامل 10,000 کلمه باشد که به کاربر امکان میدهد کل مقاله را در یک حرکت خلاصه کند.
برای تشخیص اینکه آیا متن حاوی نامهایی است یا خیر، از افراد مشهور بالقوه، استفاده میکنید درک آمازون که می تواند استخراج کند نهادهای کلیدی از یک رشته متن سپس بر اساس نهاد Person که از آن به عنوان پارامتر جستجوی ورودی استفاده می کنید، فیلتر می کنید.
سپس مقاله خلاصه شده را می گیرید و یک جاسازی برای استفاده به عنوان پارامتر جستجوی ورودی دیگر ایجاد می کنید. توجه به این نکته مهم است که شما از همان مدلی استفاده میکنید که در زیرساخت مشابهی برای ایجاد جاسازی مقاله استفاده میکنید که برای تصاویر انجام دادید. شما سپس استفاده کنید k-NN دقیق با اسکریپت امتیازدهی به طوری که می توانید بر اساس دو فیلد جستجو کنید: نام افراد مشهور و برداری که اطلاعات معنایی مقاله را ثبت کرده است. به این پست مراجعه کنید قابلیت های پایگاه داده برداری وکتور سرویس جستجوی باز آمازون توضیح داده شده است، در مورد مقیاس پذیری اسکریپت Score و اینکه چگونه این رویکرد در نمایه های بزرگ ممکن است منجر به تاخیر زیاد شود.
خرید
نمودار زیر معماری راه حل را نشان می دهد.

پیروی از برچسب های شماره گذاری شده:
- شما یک تصویر را در یک آپلود می کنید آمازون S3 سطل
- پل رویداد آمازون به این رویداد گوش می دهد و سپس یک را فعال می کند تابع AWS Step اعدام
- تابع Step ورودی تصویر را می گیرد، برچسب و ابرداده افراد مشهور را استخراج می کند
- La AWS لامبدا تابع فراداده تصویر را می گیرد و یک جاسازی ایجاد می کند
- La یازدهمین حرف الفبای یونانی سپس تابع نام افراد مشهور (در صورت وجود) و جاسازی به عنوان یک بردار k-NN را در فهرست خدمات جستجوی باز درج می کند.
- آمازون S3 میزبان یک وب سایت ثابت ساده است که توسط an آمازون CloudFront توزیع رابط کاربری جلویی (UI) به شما امکان می دهد با استفاده از برنامه احراز هویت کنید Cognito آمازون برای جستجوی تصاویر
- شما یک مقاله یا متنی را از طریق UI ارسال می کنید
- دیگر یازدهمین حرف الفبای یونانی تماس های عملکردی درک آمازون برای شناسایی هر نامی در متن
- سپس تابع متن را خلاصه می کند تا نکات مربوطه را از مقاله بدست آورد
- تابع یک جاسازی از مقاله خلاصه شده ایجاد می کند
- سپس تابع جستجو می کند سرویس OpenSearch نمایه تصویر برای هر تصویری که با نام افراد مشهور و k-نزدیک ترین همسایه های بردار مطابقت دارد با استفاده از شباهت کسینوس
- CloudWatch آمازون و AWS X-Ray به شما قابلیت مشاهده را در پایان تا پایان گردش کار می دهد تا شما را از هرگونه مشکل آگاه کند.
استخراج و ذخیره متادیتای کلیدی تصویر
آمازون Rekognition DetectLabels و RecognizeCelebrities APIهای متادیتا را از تصاویرتان در اختیار شما میگذارند—برچسبهای متنی که میتوانید از آنها برای تشکیل جمله برای ایجاد یک جاسازی استفاده کنید. این مقاله یک ورودی متنی به شما می دهد که می توانید از آن برای ایجاد یک جاسازی استفاده کنید.
جاسازی های کلمه را ایجاد و ذخیره کنید
شکل زیر رسم بردارهای تصاویر ما را در یک فضای 2 بعدی نشان می دهد، جایی که برای کمک بصری، جاسازی ها را بر اساس دسته اصلی آنها طبقه بندی کرده ایم.

شما همچنین یک جاسازی از این مقاله جدید نوشته شده را ایجاد می کنید، به طوری که می توانید سرویس OpenSearch را برای نزدیکترین تصاویر به مقاله در این فضای برداری جستجو کنید. با استفاده از الگوریتم k-nearest همسایه (k-NN)، شما تعیین می کنید که چه تعداد تصویر در نتایج خود بازگردانده شود.
با بزرگنمایی به شکل قبل، بردارها بر اساس فاصله آنها از مقاله رتبه بندی می شوند و سپس K-نزدیک ترین تصاویر را که در این مثال K برابر با 10 است، برمی گرداند.

سرویس OpenSearch قابلیت ذخیره بردارهای بزرگ را در یک نمایه ارائه می دهد، و همچنین عملکردی را برای اجرای پرس و جوها در برابر شاخص با استفاده از k-NN ارائه می دهد، به طوری که می توانید با یک بردار پرس و جو کنید تا k-نزدیک ترین اسنادی را که بردارهایی در فاصله نزدیک دارند، بازگردانید. با استفاده از اندازه گیری های مختلف برای این مثال استفاده می کنیم شباهت کسینوس.
اسامی را در مقاله تشخیص دهید
شما از Amazon Comprehend، یک سرویس پردازش زبان طبیعی (NLP) هوش مصنوعی برای استخراج موجودیت های کلیدی از مقاله استفاده می کنید. در این مثال، شما از Amazon Comprehend برای استخراج موجودیتها و فیلتر کردن توسط نهاد Person استفاده میکنید، که هر نامی را که Amazon Comprehend میتواند در داستان روزنامهنگار پیدا کند، تنها با چند خط کد برمیگرداند:
در این مثال، شما یک تصویر را آپلود می کنید سرویس ذخیره سازی ساده آمازون (Amazon S3)، که جریان کاری را ایجاد می کند که در آن شما ابرداده ها را از تصویر از جمله برچسب ها و افراد مشهور استخراج می کنید. سپس آن ابرداده استخراج شده را به یک جاسازی تبدیل کرده و همه این داده ها را در سرویس OpenSearch ذخیره می کنید.
مقاله را خلاصه کنید و یک جاسازی ایجاد کنید
خلاصه کردن مقاله گام مهمی برای اطمینان از اینکه کلمه جاسازی نکات مرتبط مقاله را به تصویر میکشد و در نتیجه تصاویری را که با موضوع مقاله همخوانی دارند را برمیگرداند.
AI21 Labs Summarize مدل بسیار ساده برای استفاده بدون هیچ گونه درخواست و فقط چند خط کد است:
سپس از مدل GPT-J برای ایجاد تعبیه استفاده می کنید
سپس در سرویس OpenSearch تصاویر خود را جستجو کنید
نمونه زیر نمونه ای از این پرس و جو است:
این معماری شامل یک برنامه وب ساده برای نمایش یک سیستم مدیریت محتوا (CMS) است.
برای یک مقاله نمونه، از ورودی زیر استفاده کردیم:
ورنر فوگلز عاشق سفر در سراسر جهان با تویوتای خود بود. تویوتای او را در صحنههای زیادی میبینیم که در حال رانندگی برای رفتن و ملاقات با مشتریان مختلف در شهرشان است.»

هیچ یک از تصاویر دارای ابرداده با کلمه "Toyota" نیستند، اما معنای کلمه "Toyota" مترادف با اتومبیل و رانندگی است. بنابراین، با این مثال، میتوانیم نشان دهیم که چگونه میتوانیم فراتر از جستجوی کلمات کلیدی برویم و تصاویری را که از نظر معنایی مشابه هستند، برگردانیم. در اسکرین شات بالا از رابط کاربری، عنوان زیر تصویر متادیتای استخراج شده Amazon Rekognition را نشان می دهد.
شما می توانید این راه حل را در یک گردش کار بزرگتر جایی که از فراداده ای که قبلاً از تصاویر خود استخراج کرده اید برای شروع استفاده از جستجوی برداری به همراه سایر عبارات کلیدی مانند نام افراد مشهور استفاده می کنید تا بهترین تصاویر و اسناد طنین انداز را برای درخواست جستجوی خود بازگردانید.
نتیجه
در این پست، ما نشان دادیم که چگونه می توانید از Amazon Rekognition، Amazon Comprehend، SageMaker و OpenSearch Service برای استخراج ابرداده از تصاویر خود استفاده کنید و سپس از تکنیک های ML برای کشف خودکار آنها با استفاده از سلبریتی و جستجوی معنایی استفاده کنید. این امر به ویژه در صنعت انتشارات مهم است، جایی که سرعت در انتشار سریع محتوای تازه و به پلتفرمهای متعدد اهمیت دارد.
برای کسب اطلاعات بیشتر در مورد کار با دارایی های رسانه ای مراجعه کنید هوش رسانه ای با Media2Cloud 3.0 هوشمندتر شده است.
درباره نویسنده
 مارک واتکینز یک معمار راه حل در تیم رسانه و سرگرمی است که از مشتریان خود برای حل بسیاری از مشکلات داده و ML پشتیبانی می کند. او به دور از زندگی حرفه ای، عاشق گذراندن وقت با خانواده و تماشای بزرگ شدن دو فرزند کوچکش است.
مارک واتکینز یک معمار راه حل در تیم رسانه و سرگرمی است که از مشتریان خود برای حل بسیاری از مشکلات داده و ML پشتیبانی می کند. او به دور از زندگی حرفه ای، عاشق گذراندن وقت با خانواده و تماشای بزرگ شدن دو فرزند کوچکش است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. خودرو / خودروهای الکتریکی، کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- ChartPrime. بازی معاملاتی خود را با ChartPrime ارتقا دهید. دسترسی به اینجا.
- BlockOffsets. نوسازی مالکیت افست زیست محیطی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/semantic-image-search-for-articles-using-amazon-rekognition-amazon-sagemaker-foundation-models-and-amazon-opensearch-service/

