این پست مهمان توسط Vihan Lakshman، Tharun Medini و Anshumali Shrivastava از ThirdAI نوشته شده است.
یادگیری عمیق در مقیاس بزرگ اخیراً پیشرفت های انقلابی در زمینه های گسترده ای ایجاد کرده است. اگرچه این پیشرفت خیره کننده در هوش مصنوعی قابل توجه است، اما هزینه های مالی و مصرف انرژی مورد نیاز برای آموزش این مدل ها به دلیل نیاز به سخت افزارهای تخصصی مانند GPU ها به عنوان یک گلوگاه مهم ظاهر شده است. بهطور سنتی، حتی مدلهای عصبی با اندازه متوسط، برای آموزش به شتابدهندههای سختافزاری پرهزینه نیاز دارند، که تعداد سازمانهایی را که دارای امکانات مالی برای استفاده کامل از این فناوری هستند، محدود میکند.
ThirdAI Corp. که در سال 2021 تأسیس شد، یک استارت آپ است که به مأموریت دموکراتیک کردن فناوری های هوش مصنوعی از طریق نوآوری های الگوریتمی و نرم افزاری اختصاص یافته است که اقتصاد یادگیری عمیق را به طور اساسی تغییر می دهد. ما یک موتور یادگیری عمیق پراکنده، به نام پیچ، که به طور خاص برای آموزش و استقرار مدلها بر روی سختافزار استاندارد CPU طراحی شده است، برخلاف شتابدهندههای پرهزینه و پر انرژی مانند GPU. بسیاری از مشتریان ما دارند رضایت شدید را گزارش کرد با توانایی ThirdAI برای آموزش و استقرار مدل های یادگیری عمیق برای مشکلات مهم تجاری در زیرساخت مقرون به صرفه CPU.
در این پست، پتانسیل پردازنده AWS Graviton3 را برای تسریع آموزش شبکه عصبی برای موتور یادگیری عمیق مبتنی بر CPU ThirdAI بررسی میکنیم.
مزایای پردازنده های با کارایی بالا
در ThirdAI، ما از طریق الگوریتمهای پراکنده پویا اختصاصی که تنها زیر مجموعهای از نورونها را برای یک ورودی مشخص فعال میکنند، به این پیشرفتها در آموزش شبکههای عصبی کارآمد بر روی CPUها دست مییابیم (شکل زیر را ببینید)، در نتیجه نیاز به محاسبات متراکم کامل را کنار میگذاریم. برخلاف سایر رویکردها برای آموزش شبکه عصبی پراکنده، ThirdAI از آن استفاده می کند هش کردن حساس به محلی برای انتخاب پویا نورون ها برای ورودی داده شده همانطور که در خطوط پررنگ زیر نشان داده شده است. در برخی موارد، ما حتی مشاهده کرده ایم که ما مدل های پراکنده مبتنی بر CPU آموزش سریعتر از معماری متراکم قابل مقایسه در GPUها.
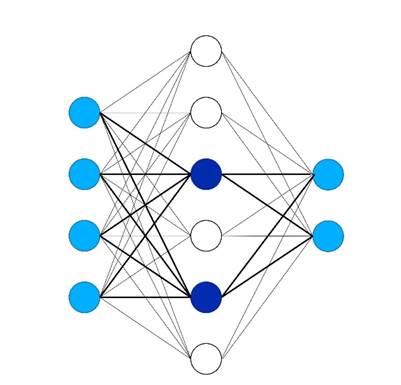
با توجه به اینکه بسیاری از مشتریان هدف ما در فضای ابری کار میکنند – و در میان آنها، اکثریت از AWS استفاده میکنند – ما هیجانزده بودیم که پردازنده AWS Graviton3 را امتحان کنیم تا ببینیم آیا پیشرفتهای چشمگیر قیمت و عملکرد نوآوری سیلیکونی آمازون به حجم کاری منحصربهفرد ما تبدیل میشود یا خیر. آموزش شبکه عصبی پراکنده و در نتیجه صرفه جویی بیشتر برای مشتریان فراهم می کند. اگرچه هم جامعه تحقیقاتی و هم تیم AWS Graviton پیشرفت های هیجان انگیزی در شتاب دهی ارائه کرده اند استنتاج شبکه عصبی در مورد نمونههای CPU، ما در ThirdAI، طبق دانش خود، اولین کسی هستیم که به طور جدی نحوه آموزش کارآمد مدلهای عصبی بر روی CPU را مطالعه میکنیم.
همانطور که در نتایج ما نشان داده شده است، ما افزایش سرعت آموزشی قابل توجهی را با AWS Graviton3 نسبت به نمونه های مشابه Intel و NVIDIA در چندین بار کار مدل سازی نماینده مشاهده کردیم.
انواع نمونه
برای ارزیابی خود، دو نمونه CPU AWS قابل مقایسه را در نظر گرفتیم: یک دستگاه c6i.8xlarge با پردازنده Ice Lake اینتل و یک دستگاه c7g.8xlarge با AWS Graviton3. جدول زیر جزئیات هر نمونه را خلاصه می کند.
| نمونه، مثال | vCPU | RAM (GB) | پردازنده | قیمت درخواستی (US-East-1) |
| c7g.8xlarge | 32 | 64 | AWS Graviton3 | $ 1.1562 / ساعت |
| c6i.8xlarge | 32 | 64 | دریاچه یخ اینتل | $ 1.36 / ساعت |
| g5g.8xlarge (GPU) | 32 | 64 با 16 گیگابایت حافظه گرافیکی | پردازنده های AWS Graviton2 با 1 GPU NVIDIA T4G | $ 1.3720 / ساعت |
ارزیابی 1: طبقه بندی افراطی
برای اولین ارزیابی خود، ما بر روی مشکل طبقهبندی چند برچسبی شدید (XMC)، یک الگوی یادگیری ماشینی (ML) که به طور فزایندهای محبوب است با تعدادی کاربرد عملی در جستجو و توصیهها (از جمله در آمازون). برای ارزیابی خود، ما بر عموم تمرکز می کنیم وظیفه توصیه محصول Amazon-670K، که با توجه به یک محصول ورودی، محصولات مشابه را از مجموعه ای از بیش از 670,000 مورد شناسایی می کند.
در این آزمایش، موتور BOLT ThirdAI را در مقابل TensorFlow 2.11 و PyTorch 2.0 بر روی گزینههای سختافزاری فوقالذکر محک میزنیم: Intel Ice Lake، AWS Graviton3 و GPU NVIDIA T4G. برای آزمایشهای خود بر روی Intel و AWS Graviton، از AWS Deep Learning AMI (Ubuntu 18.04) نسخه 59.0 استفاده میکنیم. برای ارزیابی GPU خود، از NVIDIA-GPU- Optimized Arm64 AMI، از طریق AWS Marketplace در دسترس است. برای این ارزیابی، از معماری مدل SLIDE، که هم عملکرد رقابتی در این وظیفه طبقه بندی شدید و هم عملکرد آموزشی قوی در CPU ها را به دست می آورد. برای مقایسه TensorFlow و PyTorch، ما نسخه مشابه معماری پرسپترون چند لایه SLIDE (MLP) را با ضرب ماتریس متراکم پیادهسازی میکنیم. ما هر مدل را برای پنج دوره (گذرهای کامل از مجموعه داده آموزشی) با اندازه دسته ای ثابت 256 و نرخ یادگیری 0.001 آموزش می دهیم. ما مشاهده کردیم که تمام مدلها به دقت آزمایش یکسان 33.6٪ دست یافتند.
نمودار زیر زمان آموزش BOLT ThirdAI را با TensorFlow 2.11 و PyTorch 2.0 در معیار طبقه بندی شدید Amazon670k مقایسه می کند. تمام مدل ها به دقت تست یکسانی دست می یابند. ما مشاهده میکنیم که AWS Graviton3 به طور قابلتوجهی عملکرد BOLT را بدون نیاز به سفارشیسازی سرعت میبخشد - تقریباً 40٪. ThirdAI's BOLT در AWS Graviton3 همچنین نسبت به مدلهای TensorFlow یا PyTorch که روی GPU آموزش داده شدهاند، به آموزش سریعتری دست مییابد. توجه داشته باشید که هیچ نتیجه ThirdAI در معیار GPU NVIDIA وجود ندارد زیرا BOLT برای اجرا بر روی CPU طراحی شده است. ما معیارهای TensorFlow و PyTorch CPU را به دلیل زمان بسیار طولانی آموزش در نظر نمی گیریم.
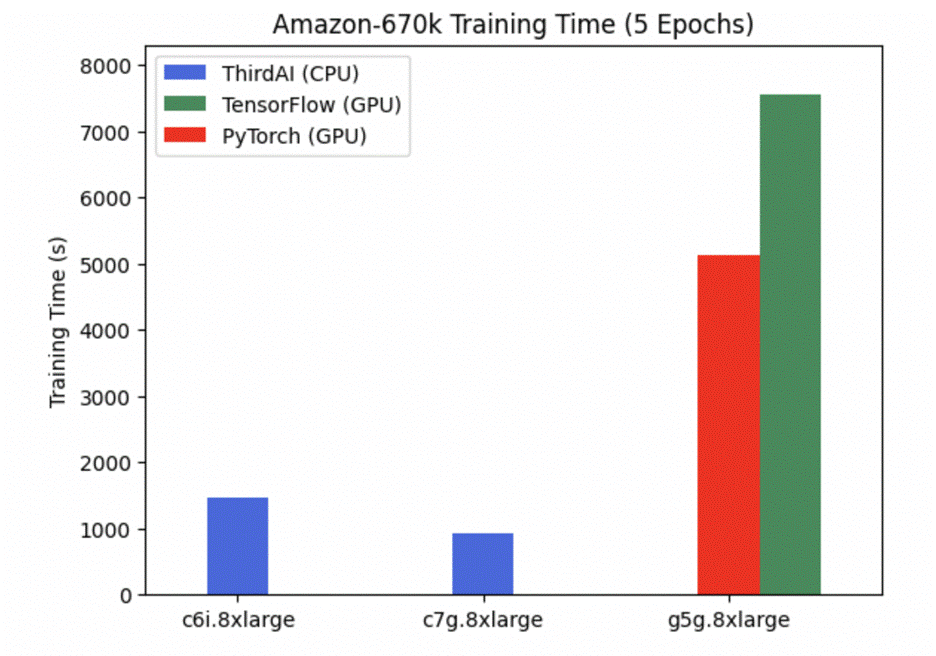
جدول زیر زمان آموزش و دقت تست را برای هر پردازنده/پردازنده تخصصی (GPU) خلاصه می کند.
| پردازنده | موتور | زمان (ها) آموزش | دقت تست |
| Intel Ice Lake (c6i.8xlarge) | پیچ | 1470 | 33.6 |
| AWS Graviton3 (c7g.8xlarge) | پیچ | 935 | 33.6 |
| NVIDIA T4G (g5g.8xlarge) | TensorFlow | 7550 | 33.6 |
| NVIDIA T4G (g5g.8xlarge) | PyTorch | 5130 | 33.6 |
ارزیابی 2: تجزیه و تحلیل احساسات قطبیت Yelp
برای ارزیابی دوم، ما بر روی محبوب تمرکز می کنیم قطبیت Yelp معیار تحلیل احساسات، که شامل طبقه بندی یک بررسی به عنوان مثبت یا منفی است. برای این ارزیابی، ThirdAI را با هم مقایسه می کنیم ترانسفورماتورهای عمیق جهانی (UDT) مدل در برابر تنظیم دقیق DistilBERT شبکه، یک مدل زبان از پیش آموزشدیده فشرده که عملکردی تقریباً پیشرفته را با کاهش تأخیر استنتاج به دست میآورد. از آنجایی که تنظیم دقیق مدلهای DistilBERT بر روی یک CPU به زمان زیادی نیاز دارد (حداقل چند روز)، ما مدلهای مبتنی بر CPU ThirdAI را در مقابل DistilBERT تنظیمشده بر روی یک GPU محک میزنیم. ما همه مدل ها را با اندازه دسته ای 256 برای یک بار عبور از داده ها (یک دوره) آموزش می دهیم. توجه داشته باشیم که میتوانیم با استفاده از BOLT با پاسهای اضافی از دادهها، به دقت کمی بالاتر برسیم، اما برای ثبات، خود را به یک پاس در این ارزیابی محدود میکنیم.
همانطور که در شکل زیر نشان داده شده است، AWS Graviton3 دوباره آموزش مدل UDT ThirdAI را به میزان قابل توجهی تسریع می کند. علاوه بر این، UDT قادر است با کسری از زمان آموزش و بدون نیاز به GPU به دقت تست قابل مقایسه با DistilBERT دست یابد. متذکر می شویم که اخیراً کارهایی نیز انجام شده است بهینه سازی تنظیم دقیق قطبیت Yelp در CPU. با این حال، مدلهای ما همچنان به بهرهوری بیشتری دست مییابند و از هزینههای پیشآموزشی اجتناب میکنند، که قابل توجه است و نیاز به استفاده از شتابدهندههای سختافزاری مانند پردازندههای گرافیکی دارد.
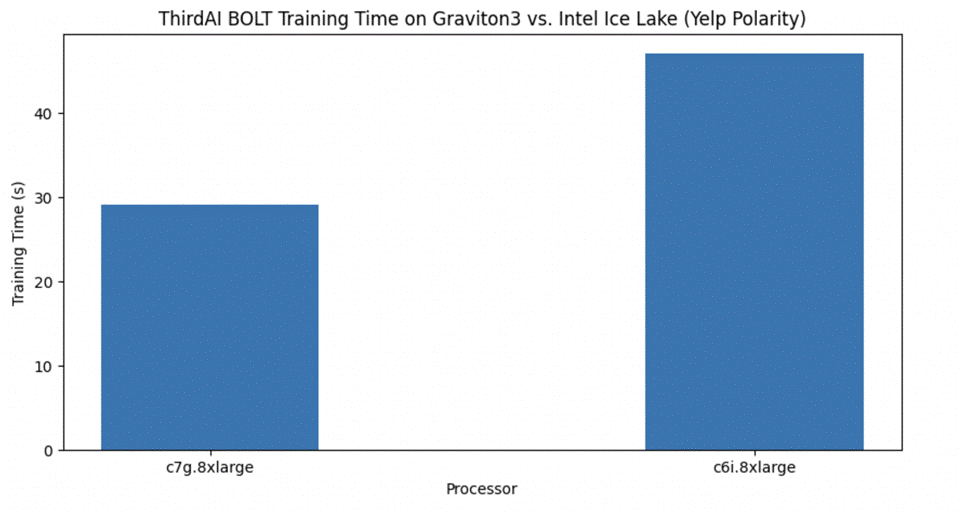
جدول زیر زمان آموزش، دقت تست و تأخیر استنتاج را خلاصه می کند.
| پردازنده | موتور | مدل | زمان (ها) آموزش | دقت تست | تأخیر استنتاج (ms) |
| Intel Icelake (c6i.8xlarge) | پیچ | UDT | 47 | 93.2 | <1 |
| Graviton3 (c7g.8xlarge) | پیچ | UDT | 29 | 92.9 | <1 |
| GPU T4G (g5g.8xlarge) | TensorFlow | DistilBERT | 4200 | 93.3 | 8.7 |
| GPU T4G (g5g.8xlarge) | PyTorch | DistilBERT | 3780 | 93.4 | 8.3 |
ارزیابی 3: طبقه بندی متن چند کلاسه (DBPedia)
برای ارزیابی نهایی، ما بر مشکل طبقهبندی متن چند کلاسه تمرکز میکنیم، که شامل تخصیص یک برچسب به یک متن ورودی معین از مجموعهای از بیش از دو کلاس خروجی است. ما روی DBPedia معیار، که از 14 کلاس خروجی ممکن تشکیل شده است. باز هم می بینیم که AWS Graviton3 عملکرد UDT را نسبت به نمونه مشابه اینتل تقریباً 40 درصد تسریع می کند. همچنین می بینیم که BOLT به نتایج قابل مقایسه با مدل مبتنی بر ترانسفورماتور DistilBERT که روی یک GPU تنظیم شده است، می رسد و در عین حال به تأخیر زیر میلی ثانیه ای می رسد.
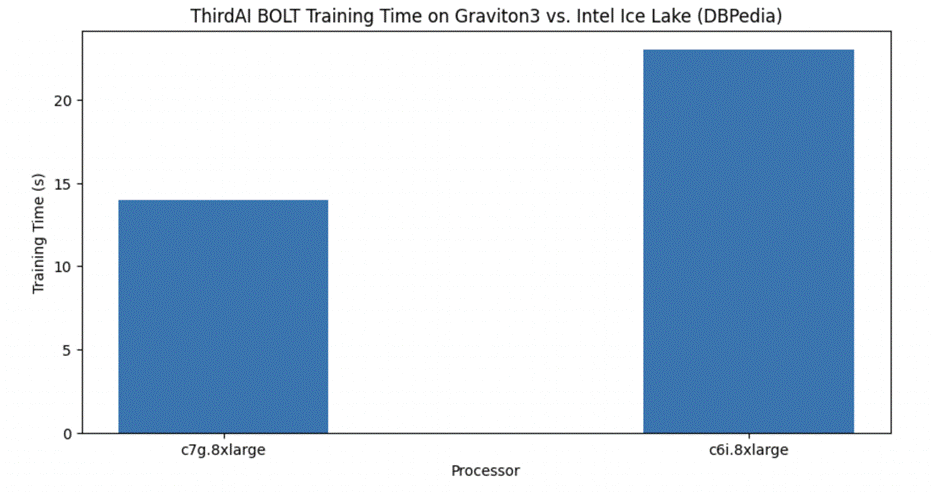
جدول زیر زمان آموزش، دقت تست و تأخیر استنتاج را خلاصه می کند.
| پردازنده | موتور | مدل | زمان (ها) آموزش | دقت تست | تأخیر استنتاج (ms) |
| Intel Icelake (c6i.8xlarge) | پیچ | UDT | 23 | 98.23 | <1 |
| Graviton3 (c7g.8xlarge) | پیچ | UDT | 14 | 98.10 | <1 |
| GPU T4G (g5g.8xlarge) | TensorFlow | DistilBERT | 4320 | 99.23 | 8.6 |
| GPU T4G (g5g.8xlarge) | PyTorch | DistilBERT | 3480 | 99.29 | 8 |
با ThirdAI در AWS Graviton شروع کنید
ما نرم افزار BOLT خود را برای سازگاری با تمام معماری های اصلی CPU از جمله AWS Graviton3 طراحی کرده ایم. در واقع، برای اجرا در AWS Graviton3 نیازی به سفارشی سازی کد خود نداشتیم. بنابراین، می توانید از ThirdAI برای آموزش مدل و استقرار در AWS Graviton3 بدون هیچ تلاش اضافی استفاده کنید. علاوه بر این، همانطور که در اخیر ما شرح داده شده است وایت پیپر تحقیقما مجموعهای از تکنیکهای ریاضی جدید را برای تنظیم خودکار فراپارامترهای تخصصی مرتبط با مدلهای پراکنده خود ایجاد کردهایم، که به مدلهای ما اجازه میدهد تا فوراً به خوبی کار کنند.
همچنین توجه میکنیم که مدلهای ما در درجه اول برای جستجو، توصیهها و وظایف پردازش زبان طبیعی که معمولاً دارای فضاهای خروجی بزرگ و با ابعاد بالا و نیاز به تأخیر استنتاج بسیار کم هستند، به خوبی کار میکنند. ما فعالانه در حال کار بر روی گسترش روشهای خود به دامنههای اضافی، مانند بینایی رایانهای هستیم، اما توجه داشته باشید که بهبود کارایی ما در حال حاضر به همه دامنههای ML ترجمه نمیشود.
نتیجه
در این پست، پتانسیل پردازنده AWS Graviton3 را برای تسریع آموزش شبکه عصبی برای موتور یادگیری عمیق مبتنی بر CPU ThirdAI بررسی کردیم. معیارهای ما در مورد جستجو، طبقهبندی متن، و معیارهای توصیهها نشان میدهند که AWS Graviton3 میتواند بارهای آموزشی مدل ThirdAI را 30 تا 40 درصد در مقایسه با نمونههای x86 با بهبود عملکرد قیمت نزدیک به 50 درصد تسریع کند. علاوه بر این، از آنجایی که نمونههای AWS Graviton3 با هزینه کمتری نسبت به ماشینهای مشابه اینتل و NVIDIA در دسترس هستند و زمان آموزش و استنتاج کوتاهتری را امکانپذیر میکنند، میتوانید با استفاده از هزینه کمتر، ارزش مدل استفاده از AWS را باز کنید. ماشین ها برای مدت زمان کوتاه تر
ما از صرفهجویی در قیمت و عملکرد AWS Graviton3 بسیار هیجانزده هستیم و به دنبال انتقال این پیشرفتها به مشتریان خود هستیم تا بتوانند از آموزش سریعتر ML و استنتاج با عملکرد بهبودیافته در CPUهای ارزانقیمت لذت ببرند. ما به عنوان مشتریان AWS، از سرعتی که AWS Graviton3 به ما اجازه می دهد تا با مدل های خود آزمایش کنیم، خوشحالیم و مشتاقانه منتظر استفاده از نوآوری های سیلیکونی پیشرفته تر از AWS در آینده هستیم. راهنمای فنی گراویتون منبع خوبی است که هنگام ارزیابی حجم کاری ML خود برای اجرا در Graviton باید در نظر بگیرید. همچنین می توانید نمونه های Graviton t4g را امتحان کنید امتحان رایگان.
مطالب و نظرات این پست متعلق به نویسنده شخص ثالث است و AWS مسئولیتی در قبال محتوا یا صحت این پست ندارد. در زمان نوشتن وبلاگ، جدیدترین نمونه c6i بود و از این رو مقایسه با نمونه های c6i انجام شد.
درباره نویسنده
ویهان لاکشمن – ویهان لاکشمن یک دانشمند محقق در شرکت ThirdAI است که بر توسعه سیستم هایی برای یادگیری عمیق کارآمد از نظر منابع متمرکز است. قبل از ThirdAI، او به عنوان یک دانشمند کاربردی در آمازون کار می کرد و مدرک کارشناسی و کارشناسی ارشد را از دانشگاه استنفورد دریافت کرد. ویهان همچنین دریافت کننده بورسیه تحقیقاتی بنیاد ملی علوم است.
ثارون مدینی – تارون مدینی یکی از بنیانگذاران و مدیر ارشد فناوری ThirdAI Corp است. او دکترای خود را در «الگوریتم های هش برای جستجو و بازیابی اطلاعات» در دانشگاه رایس گذرانده است. تارون قبل از ThirdAI در آمازون و تارگت کار می کرد. تارون جوایز متعددی را برای تحقیقات خود دریافت کرده است، از جمله بورسیه BP موسسه کن کندی، بورس تحصیلی انجمن آمریکایی مهندسان هندی، و بورسیه تحصیلات تکمیلی دانشگاه رایس.
آنشومالی شریواستاوا – آنشومالی شریواستاوا دانشیار گروه علوم کامپیوتر در دانشگاه رایس است. او همچنین بنیانگذار و مدیر عامل ThirdAI Corp است، شرکتی که هوش مصنوعی را به سخت افزار کالا از طریق نوآوری های نرم افزاری دموکراتیک می کند. علایق تحقیقاتی گسترده او شامل الگوریتم های احتمالی برای یادگیری عمیق با صرفه منابع است. در سال 2018، ساینس نیوز او را یکی از 10 دانشمند برتر زیر 40 سال برای تماشا معرفی کرد. او برنده جایزه شغلی بنیاد ملی علوم، جایزه محقق جوان از دفتر تحقیقات علمی نیروی هوایی، جایزه تحقیقات یادگیری ماشین از آمازون و جایزه تحقیقات علم داده از Adobe است. او برنده جوایز کاغذی متعددی از جمله جوایز بهترین کاغذ در NIPS 2014 و MLSys 2022، و همچنین جایزه قابل تکرارترین کاغذ در SIGMOD 2019 شده است. کارهای او در زمینه فناوری های یادگیری ماشین کارآمد در CPU توسط مطبوعات معروف از جمله وال استریت ژورنال پوشش داده شده است. نیویورک تایمز، TechCrunch، NDTV و غیره
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/accelerating-large-scale-neural-network-training-on-cpus-with-thirdai-and-aws-graviton/

