In قسمت 1 از این سری راه حلی ارائه کردیم که از آمازون Titan Multimodal Embeddings مدلی برای تبدیل اسلایدهای جداگانه از یک عرشه اسلاید به جاسازی. ما جاسازیها را در یک پایگاه داده برداری ذخیره کردیم و سپس از آن استفاده کردیم Large Language-and-Vision Assistant (LLaVA 1.5-7b) مدلی برای تولید پاسخ های متنی به سؤالات کاربر بر اساس مشابه ترین اسلاید بازیابی شده از پایگاه داده برداری. ما از خدمات AWS از جمله استفاده کردیم بستر آمازون, آمازون SageMakerو بدون سرور جستجوی باز آمازون در این راه حل
در این پست، ما یک رویکرد متفاوت را نشان می دهیم. ما استفاده می کنیم غزل آنتروپیک کلود 3 مدلی برای تولید توضیحات متنی برای هر اسلاید در عرشه اسلاید. سپس با استفاده از این توضیحات به جاسازی متن تبدیل می شوند جاسازی متن آمازون تایتان مدل و در یک پایگاه داده برداری ذخیره می شود. سپس از مدل غزل کلود 3 برای ایجاد پاسخ به سوالات کاربر بر اساس مرتبط ترین توضیحات متنی بازیابی شده از پایگاه داده برداری استفاده می کنیم.
می توانید هر دو رویکرد را برای مجموعه داده خود آزمایش کنید و نتایج را ارزیابی کنید تا ببینید کدام رویکرد بهترین نتایج را به شما می دهد. در قسمت سوم این مجموعه، نتایج هر دو روش را ارزیابی می کنیم.
بررسی اجمالی راه حل
این راه حل یک پیاده سازی برای پاسخ به سوالات با استفاده از اطلاعات موجود در متن و عناصر بصری یک عرشه اسلاید ارائه می دهد. طراحی بر مفهوم نسل افزوده بازیابی (RAG) متکی است. به طور سنتی، RAG با داده های متنی مرتبط است که می تواند توسط مدل های زبان بزرگ (LLM) پردازش شود. در این مجموعه، RAG را گسترش می دهیم تا تصاویر را نیز شامل شود. این یک قابلیت جستجوی قدرتمند برای استخراج محتوای مرتبط با زمینه از عناصر بصری مانند جداول و نمودارها همراه با متن فراهم می کند.
این راه حل شامل اجزای زیر است:
- آمازون Titan Text Embeddings یک مدل جاسازی متنی است که متن زبان طبیعی، از جمله تک کلمات، عبارات، یا حتی اسناد بزرگ را به نمایشهای عددی تبدیل میکند که میتواند در موارد استفاده از جمله جستجو، شخصیسازی و خوشهبندی بر اساس شباهت معنایی استفاده شود.
- Claude 3 Sonnet نسل بعدی مدل های پیشرفته آنتروپیک است. Sonnet یک ابزار همه کاره است که می تواند طیف گسترده ای از وظایف را از عهده دارد، از استدلال و تجزیه و تحلیل پیچیده گرفته تا خروجی های سریع، و همچنین جستجو و بازیابی کارآمد در میان حجم وسیعی از اطلاعات.
- OpenSearch Serverless یک پیکربندی بدون سرور درخواستی برای سرویس جستجوی باز آمازون است. ما از OpenSearch Serverless به عنوان یک پایگاه داده برداری برای ذخیره جاسازی های تولید شده توسط مدل آمازون Titan Text Embeddings استفاده می کنیم. ایندکس ایجاد شده در مجموعه OpenSearch Serverless به عنوان ذخیره بردار برای راه حل RAG ما عمل می کند.
- جذب جستجوی باز آمازون (OSI) یک گردآورنده داده کاملاً مدیریت شده و بدون سرور است که داده ها را به دامنه های سرویس OpenSearch و مجموعه های OpenSearch Serverless تحویل می دهد. در این پست، ما از یک OSI Pipeline API برای تحویل داده ها به فروشگاه برداری بدون سرور OpenSearch استفاده می کنیم.
طراحی راه حل شامل دو بخش است: جذب و تعامل کاربر. در حین دریافت، ما عرشه اسلاید ورودی را با تبدیل هر اسلاید به یک تصویر، ایجاد توضیحات و جاسازی متن برای هر تصویر، پردازش میکنیم. سپس ذخیره داده های برداری را با جاسازی ها و توضیحات متنی برای هر اسلاید پر می کنیم. این مراحل قبل از مراحل تعامل کاربر تکمیل می شوند.
در مرحله تعامل با کاربر، یک سوال از کاربر به تعبیه متن تبدیل می شود. یک جستجوی شباهت در پایگاه داده برداری انجام می شود تا یک توضیح متنی مربوط به یک اسلاید پیدا شود که به طور بالقوه می تواند حاوی پاسخ هایی برای سؤال کاربر باشد. سپس شرح اسلاید و سؤال کاربر را به مدل غزل کلود 3 ارائه می کنیم تا پاسخی برای سؤال ایجاد کنیم. تمام کدهای این پست در آدرس موجود است GitHub مخزن.
نمودار زیر معماری جذب را نشان می دهد.

گردش کار شامل مراحل زیر است:
- اسلایدها به فایل های تصویری (یکی در هر اسلاید) با فرمت JPG تبدیل می شوند و برای تولید توضیحات متنی به مدل غزل کلود 3 منتقل می شوند.
- داده ها به مدل آمازون Titan Text Embeddings ارسال می شود تا جاسازی ها ایجاد شود. در این سری از عرشه اسلاید استفاده می کنیم با استفاده از AWS Trainium & AWS Inferentia، Stable Diffusion را آموزش و اجرا کنید از نشست AWS در تورنتو، ژوئن 2023 برای نشان دادن راه حل. عرشه نمونه دارای 31 اسلاید است، بنابراین ما 31 مجموعه از جاسازی های برداری را تولید می کنیم که هر کدام با 1536 ابعاد هستند. ما فیلدهای فراداده اضافی را برای انجام پرس و جوهای جستجوی غنی با استفاده از قابلیت های جستجوی قدرتمند OpenSearch اضافه می کنیم.
- جاسازی ها با استفاده از یک فراخوانی API وارد خط لوله OSI می شوند.
- خط لوله OSI داده ها را به عنوان اسناد در یک فهرست بدون سرور OpenSearch وارد می کند. ایندکس به عنوان سینک برای این خط لوله پیکربندی شده و به عنوان بخشی از مجموعه OpenSearch Serverless ایجاد شده است.
نمودار زیر معماری تعامل کاربر را نشان می دهد.

گردش کار شامل مراحل زیر است:
- یک کاربر سؤالی مربوط به عرشه اسلایدی که بلعیده شده است ارسال می کند.
- ورودی کاربر با استفاده از مدل آمازون Titan Text Embeddings که با استفاده از Amazon Bedrock قابل دسترسی است، به جاسازی ها تبدیل می شود. جستجوی برداری سرویس OpenSearch با استفاده از این جاسازی ها انجام می شود. ما یک جستوجوی k-نزدیکترین همسایه (k-NN) را برای بازیابی مرتبطترین جاسازیهای مطابق با درخواست کاربر انجام میدهیم.
- فراداده پاسخ از OpenSearch Serverless شامل مسیری به تصویر و توضیحات مربوط به مرتبط ترین اسلاید است.
- یک اعلان با ترکیب سوال کاربر و توضیحات تصویر ایجاد می شود. این درخواست به کلود 3 غزل ارائه شده است که در Amazon Bedrock میزبانی شده است.
- نتیجه این استنتاج به کاربر بازگردانده می شود.
ما مراحل هر دو مرحله را در بخشهای بعدی مورد بحث قرار میدهیم و جزئیات مربوط به خروجی را درج میکنیم.
پیش نیازها
برای پیاده سازی راه حل ارائه شده در این پست، باید یک حساب AWS و آشنایی با FMs، Amazon Bedrock، SageMaker و OpenSearch Service.
این راه حل از مدل های Claude 3 Sonnet و Amazon Titan Text Embeddings استفاده می کند که در Amazon Bedrock میزبانی می شوند. اطمینان حاصل کنید که این مدل ها برای استفاده با پیمایش به آن فعال هستند دسترسی مدل صفحه در کنسول آمازون بستر.
اگر مدلها فعال باشند، وضعیت دسترسی بیان خواهد کرد دسترسی به داده.

اگر مدل ها در دسترس نیستند، با انتخاب، دسترسی را فعال کنید دسترسی مدل را مدیریت کنید، انتخاب مدل ها و انتخاب درخواست دسترسی مدل. مدل ها بلافاصله برای استفاده فعال می شوند.
از AWS CloudFormation برای ایجاد پشته راه حل استفاده کنید
می توانید از AWS CloudFormation برای ایجاد پشته راه حل استفاده کنید. اگر راه حل قسمت 1 را در همان حساب AWS ایجاد کرده اید، حتماً قبل از ایجاد این پشته آن را حذف کنید.
| منطقه AWS | ارتباط دادن |
|---|---|
us-east-1 |
|
us-west-2 |
پس از اینکه پشته با موفقیت ایجاد شد، به برگه خروجی های پشته در کنسول AWS CloudFormation بروید و مقادیر مربوط به آن را یادداشت کنید. MultimodalCollectionEndpoint و OpenSearchPipelineEndpoint. شما از اینها در مراحل بعدی استفاده می کنید.
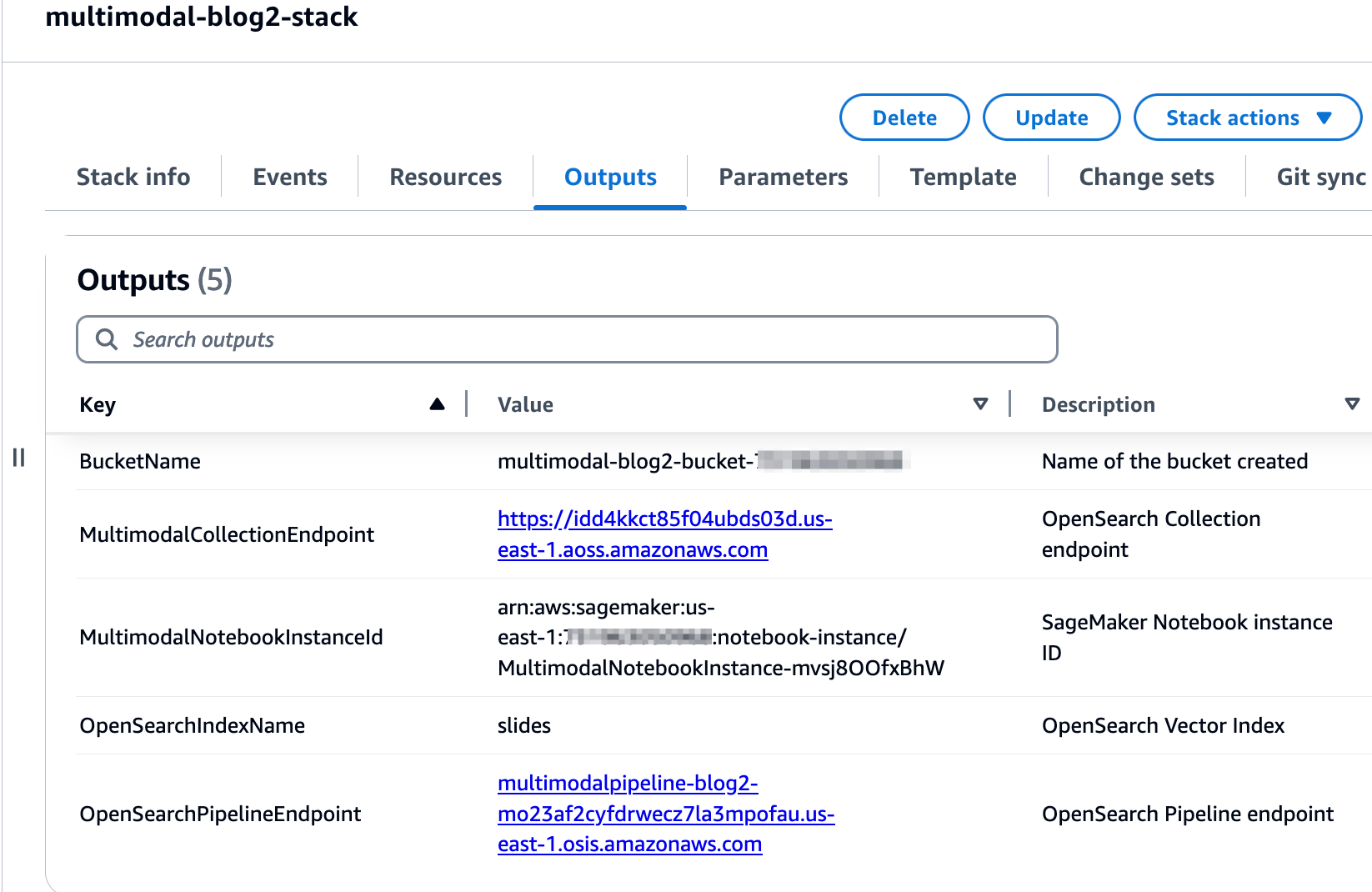
قالب CloudFormation منابع زیر را ایجاد می کند:
- نقش های IAM - به شرح زیر هویت AWS و مدیریت دسترسی نقش های (IAM) ایجاد می شود. این نقشها را بهروزرسانی کنید تا مجوزهای کمترین امتیاز را اعمال کنید، همانطور که در مورد بحث قرار گرفت بهترین شیوه های امنیتی.
SMExecutionRoleبا سرویس ذخیره سازی ساده آمازون (Amazon S3)، SageMaker، OpenSearch Service و Amazon Bedrock دسترسی کامل.OSPipelineExecutionRoleبا دسترسی به سطل S3 و اقدامات OSI.
- نوت بوک SageMaker - تمام کدهای این پست با استفاده از این نوت بوک اجرا می شوند.
- مجموعه بدون سرور OpenSearch – این پایگاه داده برداری برای ذخیره و بازیابی موارد تعبیه شده است.
- خط لوله OSI - این خط لوله برای دریافت داده ها در OpenSearch Serverless است.
- سطل S3 - تمام داده های این پست در این سطل ذخیره می شود.
الگوی CloudFormation پیکربندی خط لوله مورد نیاز برای پیکربندی خط لوله OSI با HTTP به عنوان منبع و نمایه OpenSearch Serverless به عنوان سینک را تنظیم می کند. نوت بوک SageMaker 2_data_ingestion.ipynb نحوه وارد کردن داده ها را با استفاده از خط لوله نشان می دهد درخواست ها کتابخانه HTTP
قالب CloudFormation نیز ایجاد می کند شبکه, رمزگذاری و دسترسی به داده ها خط مشی های مورد نیاز برای مجموعه OpenSearch Serverless شما. این خطمشیها را بهروزرسانی کنید تا مجوزهای کمترین امتیاز را اعمال کنید.
نام الگوی CloudFormation و نام فهرست سرویس OpenSearch در نوت بوک SageMaker ارجاع داده شده است. 3_rag_inference.ipynb. اگر نامهای پیشفرض را تغییر میدهید، مطمئن شوید که آنها را در نوت بوک بهروزرسانی کردهاید.
محلول را تست کنید
پس از ایجاد پشته CloudFormation، می توانید راه حل را آزمایش کنید. مراحل زیر را کامل کنید:
- در کنسول SageMaker، را انتخاب کنید نوت بوک در صفحه ناوبری
- انتخاب کنید
MultimodalNotebookInstanceو انتخاب کنید JupyterLab را باز کنید.
- In مرورگر پرونده، از پوشه notebooks عبور کنید تا نوت بوک ها و فایل های پشتیبانی را ببینید.
نوت بوک ها به ترتیبی که در آن اجرا می شوند شماره گذاری می شوند. دستورالعمل ها و نظرات در هر نوت بوک اقدامات انجام شده توسط آن دفتر را توصیف می کند. ما این نوت بوک ها را یکی یکی اجرا می کنیم.
- را انتخاب کنید
1_data_prep.ipynbبرای باز کردن آن در JupyterLab. - بر دویدن منو ، انتخاب کنید اجرای همه سلول ها برای اجرای کد در این نوت بوک.
این نوت بوک یک نسخه در دسترس عموم را دانلود می کند عرشه اسلاید، هر اسلاید را به فرمت فایل JPG تبدیل کنید و آنها را در سطل S3 آپلود کنید.
- را انتخاب کنید
2_data_ingestion.ipynbبرای باز کردن آن در JupyterLab. - بر دویدن منو ، انتخاب کنید اجرای همه سلول ها برای اجرای کد در این نوت بوک.
در این نوت بوک، شما یک نمایه در مجموعه OpenSearch Serverless ایجاد می کنید. این شاخص داده های جاسازی را برای عرشه اسلاید ذخیره می کند. کد زیر را ببینید:
شما از مدل های Claude 3 Sonnet و Amazon Titan Text Embeddings برای تبدیل تصاویر JPG ایجاد شده در نوت بوک قبلی به جاسازی های برداری استفاده می کنید. این تعبیهها و ابردادههای اضافی (مانند مسیر S3 و توضیحات فایل تصویر) همراه با جاسازیها در فهرست ذخیره میشوند. قطعه کد زیر نشان می دهد که چگونه Claude 3 Sonnet توضیحات تصویر را تولید می کند:
توضیحات تصویر به مدل آمازون Titan Text Embeddings منتقل می شود تا جاسازی های برداری ایجاد شود. این تعبیهها و ابردادههای اضافی (مانند مسیر S3 و توضیحات فایل تصویر) همراه با جاسازیها در فهرست ذخیره میشوند. قطعه کد زیر تماس با مدل آمازون Titan Text Embeddings را نشان می دهد:
داده ها با برقراری یک فراخوانی API به خط لوله OSI وارد فهرست OpenSearch Serverless می شوند. قطعه کد زیر تماس برقرار شده با استفاده از کتابخانه Requests HTTP را نشان می دهد:
- را انتخاب کنید
3_rag_inference.ipynbبرای باز کردن آن در JupyterLab. - بر دویدن منو ، انتخاب کنید اجرای همه سلول ها برای اجرای کد در این نوت بوک.
این نوت بوک راه حل RAG را پیاده سازی می کند: شما سوال کاربر را به جاسازی تبدیل می کنید، یک توضیح تصویر مشابه را از پایگاه داده برداری پیدا می کنید و توضیحات بازیابی شده را در اختیار Claude 3 Sonnet قرار می دهید تا پاسخی برای سوال کاربر ایجاد کند. شما از الگوی سریع زیر استفاده می کنید:
قطعه کد زیر گردش کار RAG را ارائه می دهد:
نتایج
جدول زیر حاوی برخی از سوالات و پاسخ های کاربر است که توسط پیاده سازی ما ایجاد شده است. را سوال ستون سوال کاربر و پاسخ ستون پاسخ متنی تولید شده توسط کلود 3 غزل است. را تصویر ستون تطابق اسلاید k-NN را نشان می دهد که توسط جستجوی برداری بدون سرور OpenSearch برگردانده شده است.
نتایج RAG چند وجهی
| سوال | پاسخ | تصویر |
|---|---|---|
| عملکرد Inf2 چگونه با نمونه های EC2 قابل مقایسه است؟ من به اعداد نیاز دارم | بر اساس اطلاعات ارائه شده در خلاصه، اعداد اصلی مقایسه عملکرد ارائه شده برای نمونه های Amazon EC2 Inf2 در مقایسه با سایر نمونه ها عبارتند از: 1. تا 4 برابر توان عملیاتی بالاتر. 2. تا 10 برابر تاخیر کمتر. خلاصه اعداد خاصی برای مقایسه نمونه های Inf2 با سایر انواع نمونه EC2 ارائه نمی کند. با این حال، بهبود توان عملیاتی و تأخیر را به عنوان مزایای اصلی عملکرد نمونههای Inf2 نسبت به نمونههای قابل مقایسه برای اجرای مدلهای هوش مصنوعی مولد برجسته میکند. |  |
| با توجه به چرخ لنگر AI/ML، خدمات AWS AI/ML چه چیزی را ارائه می دهند؟ | بر اساس خلاصه، خدمات AWS AI/ML طیف وسیعی از قابلیتها را ارائه میکنند که به چرخ طیار AI/ML کمک میکند. این چرخ لنگر شامل نوآوری در توسعه الگوریتمهای جدید و بهتر، امکان استفاده بیشتر و کاربردهای بیشتر، افزایش پذیرش و تقاضا است، که به نوبه خود منجر به سرمایهگذاری بیشتر در تحقیق و بهینهسازی برای هدایت نوآوری بیشتر میشود. به نظر می رسد سرویس های AWS AI/ML ابزارها، منابع و زیرساخت ها را برای پشتیبانی از این چرخه مداوم نوآوری، توسعه اپلیکیشن، پذیرش و سرمایه گذاری مجدد در زمینه هوش مصنوعی و یادگیری ماشین ارائه می دهند. |  |
| در مقایسه با GPT-2، GPT-3 چند پارامتر بیشتر دارد؟ تفاوت عددی بین اندازه پارامتر GPT-2 و GPT-3 چیست؟ | بر اساس اطلاعات ارائه شده در خلاصه، GPT-3 از سال 2020 دارای 175B (175 میلیارد) پارامتر بود، در حالی که GPT-2 از سال 2019 دارای 1.5B (1.5 میلیارد) پارامتر بود. بنابراین، تفاوت عددی بین اندازه پارامتر GPT-2 و GPT-3 173.5 میلیارد پارامتر است. پارامترهای GPT-3 تقریباً 115 برابر بیشتر از GPT-2 است. |  |
| کوارک ها در فیزیک ذرات چیست؟ | متأسفانه، خلاصه ارائه شده حاوی هیچ اطلاعاتی در مورد کوارک ها در فیزیک ذرات نیست. خلاصه تصویری مربوط به پیشرفت پردازش زبان طبیعی و فناوریهای هوش مصنوعی مولد را توصیف میکند، اما چیزی در مورد فیزیک ذرات یا مفهوم کوارکها ذکر نمیکند. |  |
فهرست خود را پرس و جو کنید
میتوانید از داشبوردهای OpenSearch برای تعامل با OpenSearch API برای اجرای آزمایشهای سریع روی فهرست و دادههای دریافتی خود استفاده کنید.

پاک کردن
برای جلوگیری از تحمیل هزینه در آینده، منابع را حذف کنید. می توانید این کار را با حذف پشته با استفاده از کنسول AWS CloudFormation انجام دهید.

نتیجه
شرکتها دائماً محتوای جدید تولید میکنند و اسلایدها روشی متداول برای اشتراکگذاری و انتشار اطلاعات در داخل سازمان و بیرون با مشتریان یا در کنفرانسها هستند. با گذشت زمان، اطلاعات غنی می تواند در حالت های غیر متنی مانند نمودارها و جداول در این عرشه های اسلاید مدفون و پنهان بماند.
شما می توانید از این راه حل و قدرت FM های چندوجهی مانند آمازون Titan Text Embeddings و Claude 3 Sonnet برای کشف اطلاعات جدید یا کشف دیدگاه های جدید در مورد محتوا در عرشه اسلاید استفاده کنید. میتوانید با بهروزرسانی مدلهای مختلف Claude موجود در Amazon Bedrock را امتحان کنید CLAUDE_MODEL_ID در globals.py فایل.
این قسمت 2 از یک مجموعه سه قسمتی است. ما از آمازون Titan Multimodal Embeddings و مدل LLaVA در قسمت 1 استفاده کردیم. در قسمت 3، رویکردهای قسمت 1 و قسمت 2 را با هم مقایسه خواهیم کرد.
بخش هایی از این کد تحت عنوان منتشر شده است مجوز آپاچی 2.0
درباره نویسندگان
 آمیت آرورا یک معمار متخصص هوش مصنوعی و ML در خدمات وب آمازون است که به مشتریان سازمانی کمک می کند تا از خدمات یادگیری ماشینی مبتنی بر ابر استفاده کنند تا نوآوری های خود را به سرعت گسترش دهند. او همچنین یک مدرس کمکی در برنامه علوم داده و تجزیه و تحلیل MS در دانشگاه جورج تاون در واشنگتن دی سی است.
آمیت آرورا یک معمار متخصص هوش مصنوعی و ML در خدمات وب آمازون است که به مشتریان سازمانی کمک می کند تا از خدمات یادگیری ماشینی مبتنی بر ابر استفاده کنند تا نوآوری های خود را به سرعت گسترش دهند. او همچنین یک مدرس کمکی در برنامه علوم داده و تجزیه و تحلیل MS در دانشگاه جورج تاون در واشنگتن دی سی است.
 مانجو پراساد یک معمار ارشد راه حل در خدمات وب آمازون است. او بر ارائه راهنمایی های فنی در حوزه های مختلف فنی، از جمله AI/ML تمرکز دارد. او قبل از پیوستن به AWS، راهحلهایی را برای شرکتهای بخش خدمات مالی و همچنین برای یک استارتآپ طراحی و ساخته بود. او مشتاق به اشتراک گذاری دانش و پرورش علاقه به استعدادهای در حال ظهور است.
مانجو پراساد یک معمار ارشد راه حل در خدمات وب آمازون است. او بر ارائه راهنمایی های فنی در حوزه های مختلف فنی، از جمله AI/ML تمرکز دارد. او قبل از پیوستن به AWS، راهحلهایی را برای شرکتهای بخش خدمات مالی و همچنین برای یک استارتآپ طراحی و ساخته بود. او مشتاق به اشتراک گذاری دانش و پرورش علاقه به استعدادهای در حال ظهور است.
 آرچانا ایناپودی یک معمار ارشد راه حل در AWS است که از یک مشتری استراتژیک پشتیبانی می کند. او بیش از یک دهه تخصص بین صنعتی دارد که در ابتکارات فنی استراتژیک پیشرو است. Archana یکی از اعضای مشتاق جامعه حوزه فنی AI/ML در AWS است. قبل از پیوستن به AWS، Archana مهاجرت از منابع داده سنتی به Hadoop در یک شرکت مراقبتهای بهداشتی را رهبری کرد. او مشتاق استفاده از فناوری برای تسریع رشد، ارائه ارزش به مشتریان و دستیابی به نتایج تجاری است.
آرچانا ایناپودی یک معمار ارشد راه حل در AWS است که از یک مشتری استراتژیک پشتیبانی می کند. او بیش از یک دهه تخصص بین صنعتی دارد که در ابتکارات فنی استراتژیک پیشرو است. Archana یکی از اعضای مشتاق جامعه حوزه فنی AI/ML در AWS است. قبل از پیوستن به AWS، Archana مهاجرت از منابع داده سنتی به Hadoop در یک شرکت مراقبتهای بهداشتی را رهبری کرد. او مشتاق استفاده از فناوری برای تسریع رشد، ارائه ارزش به مشتریان و دستیابی به نتایج تجاری است.
 آنتارا رایسا یک معمار راه حل های هوش مصنوعی و ML در خدمات وب آمازون است که از مشتریان استراتژیک مستقر در دالاس، تگزاس پشتیبانی می کند. او همچنین تجربه قبلی کار با شرکای بزرگ سازمانی در AWS را دارد، جایی که او به عنوان معمار راه حل های موفقیت شریک برای مشتریان دیجیتال محور کار می کرد.
آنتارا رایسا یک معمار راه حل های هوش مصنوعی و ML در خدمات وب آمازون است که از مشتریان استراتژیک مستقر در دالاس، تگزاس پشتیبانی می کند. او همچنین تجربه قبلی کار با شرکای بزرگ سازمانی در AWS را دارد، جایی که او به عنوان معمار راه حل های موفقیت شریک برای مشتریان دیجیتال محور کار می کرد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-2/

