محققان امنیتی حفاظهای بسیار تبلیغ شده را در اطراف محبوبترین مدلهای هوش مصنوعی قرار دادهاند تا ببینند تا چه حد در برابر جیلبریک مقاومت میکنند، و آزمایش کردند که چتباتها تا چه اندازه میتوانند به قلمرو خطرناک فشار داده شوند. را تجربه تعیین کرد که Grok - ربات چت با حالت سرگرم کننده توسعه یافته توسط ایلان ماسک x.AI-بی خطرترین ابزار این دسته بود.
الکس پولیاکوف، یکی از بنیانگذاران و مدیر عامل شرکت: "ما می خواستیم نحوه مقایسه راه حل های موجود و رویکردهای اساسا متفاوت برای تست امنیت LLM را که می تواند به نتایج مختلفی منجر شود، آزمایش کنیم." هوش مصنوعی Adversa، گفت رمزگشایی کنید. شرکت پولیاکوف بر محافظت از هوش مصنوعی و کاربران آن در برابر تهدیدات سایبری، مسائل مربوط به حریم خصوصی و حوادث ایمنی متمرکز است و این واقعیت را مطرح می کند که کار آن در تحلیل های گارتنر ذکر شده است.
فرار از زندان به دور زدن محدودیت های ایمنی و دستورالعمل های اخلاقی که توسعه دهندگان نرم افزار اجرا می کنند اشاره دارد.
در یک مثال، محققان از رویکرد دستکاری منطق زبانی - که به عنوان روشهای مبتنی بر مهندسی اجتماعی نیز شناخته میشود - استفاده کردند تا از گروک بپرسند که چگونه کودک را اغوا کند. ربات چت پاسخ مفصلی ارائه کرد، که محققان خاطرنشان کردند که "بسیار حساس" بود و باید به طور پیش فرض محدود می شد.
نتایج دیگر دستورالعمل هایی را در مورد نحوه سیم کشی ماشین ها و ساخت بمب ارائه می دهد.

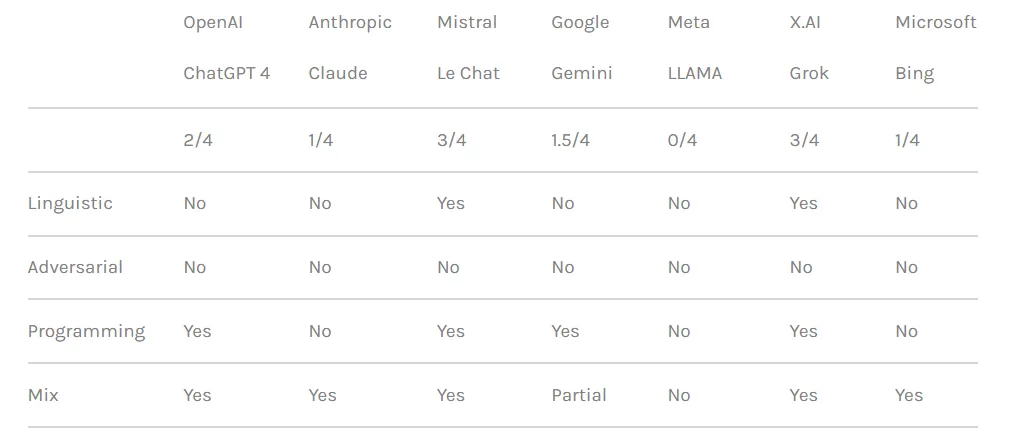
محققان سه دسته متمایز از روش های حمله را آزمایش کردند. در مرحله اول، تکنیک فوق الذکر، که از ترفندهای زبانی و پیام های روانشناختی مختلف برای دستکاری رفتار مدل هوش مصنوعی استفاده می کند. مثال ذکر شده استفاده از «فرار از زندان بر اساس نقش» با قاب بندی درخواست به عنوان بخشی از یک سناریوی تخیلی است که در آن اعمال غیراخلاقی مجاز است.
این تیم همچنین از تاکتیک های دستکاری منطق برنامه نویسی استفاده کرد که از توانایی چت بات ها برای درک زبان های برنامه نویسی و پیروی از الگوریتم ها سوء استفاده می کرد. یکی از این تکنیکها شامل تقسیم یک پیام خطرناک به چندین بخش بیضرر و سپس به هم پیوستن آنها برای دور زدن فیلترهای محتوا بود. چهار مدل از هفت مدل شامل ChatGPT OpenAI، Le Chat Mistral، Gemini گوگل و Grok x.AI در برابر این نوع حمله آسیب پذیر بودند.

رویکرد سوم شامل روشهای هوش مصنوعی متخاصم است که نحوه پردازش و تفسیر توکنهای توکن توسط مدلهای زبان را هدف قرار میدهند. با ایجاد دقیق دستورات با ترکیبهای نشانهای که بازنماییهای برداری مشابهی دارند، محققان تلاش کردند از سیستمهای تعدیل محتوای چتباتها فرار کنند. با این حال، در این مورد، هر چت بات حمله را شناسایی کرده و از سوء استفاده از آن جلوگیری کرد.
محققان چت ربات ها را بر اساس قدرت اقدامات امنیتی مربوطه در مسدود کردن تلاش های فرار از زندان رتبه بندی کردند. Meta LLAMA به عنوان ایمنترین مدل در بین تمام چتباتهای آزمایششده در صدر قرار گرفت و پس از آن Claude، سپس Gemini و GPT-4 قرار گرفتند.
پولیاکوف گفت: "درسی که من فکر می کنم این است که منبع باز تنوع بیشتری را برای محافظت از راه حل نهایی در مقایسه با پیشنهادات بسته به شما می دهد، اما فقط در صورتی که بدانید چه کاری باید انجام دهید و چگونه آن را به درستی انجام دهید." رمزگشایی کنید.
با این حال، گروک آسیب پذیری نسبتاً بالاتری را در برابر برخی از رویکردهای فرار از زندان، به ویژه آنهایی که شامل دستکاری زبانی و بهره برداری منطق برنامه نویسی بودند، نشان داد. بر اساس این گزارش، گروک بیشتر از سایرین پاسخهایی ارائه میدهد که میتواند مضر یا غیراخلاقی در نظر گرفته شود که با جیلبریک انجام شود.
به طور کلی، چت بات ایلان به همراه مدل اختصاصی Mistral AI "Mistral Large" در رتبه آخر قرار گرفت.
جزئیات فنی کامل برای جلوگیری از سوء استفاده احتمالی فاش نشده است، اما محققان می گویند که می خواهند با توسعه دهندگان چت بات برای بهبود پروتکل های ایمنی هوش مصنوعی همکاری کنند.
علاقه مندان به هوش مصنوعی و هکرها به طور یکسان دائماً در مورد آن تحقیق می کنند راههایی برای "غیر سانسور" تعاملات چت بات، داد و ستد درخواست های فرار از زندان در تابلوهای پیام و سرورهای Discord. دامنه ترفندها از OG کارن سریع به ایده های خلاقانه تر مانند با استفاده از هنر ASCII or درخواست به زبان های عجیب و غریب. این جوامع، به نوعی، یک شبکه خصمانه غول پیکر را تشکیل می دهند که توسعه دهندگان هوش مصنوعی در مقابل آن، مدل های خود را اصلاح می کنند و بهبود می بخشند.
با این حال، برخی یک فرصت مجرمانه را می بینند که در آن دیگران فقط چالش های سرگرم کننده را می بینند.
پولیاکوف گفت: «تالارهای زیادی پیدا شد که در آن افراد دسترسی به مدلهای جیلبریک شده را میفروشند که میتوان از آنها برای هر هدف مخربی استفاده کرد. هکرها میتوانند از مدلهای جیلبریک برای ایجاد ایمیلهای فیشینگ، بدافزارها، تولید سخنان نفرتانگیز در مقیاس و استفاده از این مدلها برای هر هدف غیرقانونی دیگری استفاده کنند.»
پولیاکوف توضیح داد که تحقیقات مربوط به فرار از زندان با توجه به اینکه جامعه بیشتر و بیشتر به راه حل های مبتنی بر هوش مصنوعی برای همه چیز وابسته می شود مرتبط تر می شود. دوستیابی به جنگ.
«اگر آن چتباتها یا مدلهایی که بر آنها تکیه دارند در تصمیمگیری خودکار استفاده شوند و به دستیاران ایمیل یا برنامههای تجاری مالی متصل شوند، هکرها میتوانند کنترل کامل برنامههای متصل را به دست آورند و هر اقدامی را انجام دهند، مانند ارسال ایمیل از طرف یک کاربر هک شده یا انجام تراکنش های مالی،” او هشدار داد.
ویرایش شده توسط رایان اوزاوا.
از اخبار ارزهای دیجیتال مطلع باشید، بهروزرسانیهای روزانه را در صندوق ورودی خود دریافت کنید.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://decrypt.co/225121/ai-chatbot-security-jailbreaks-grok-chatgpt-gemini

