مشتریان مراقبت های بهداشتی و علوم زیستی (HCLS) هوش مصنوعی مولد را به عنوان ابزاری برای دریافت بیشتر از داده های خود استفاده می کنند. موارد استفاده شامل خلاصهسازی اسناد برای کمک به خوانندگان برای تمرکز بر نکات کلیدی یک سند و تبدیل متن بدون ساختار به قالبهای استاندارد شده برای برجسته کردن ویژگیهای مهم است. با فرمتهای داده منحصربفرد و الزامات نظارتی دقیق، مشتریان به دنبال انتخابهایی برای انتخاب کارآمدترین و مقرونبهصرفهترین مدل، و همچنین توانایی انجام سفارشیسازی (تنظیم دقیق) برای مناسبترین کاربرد تجاری خود هستند. در این پست، شما را با استفاده از یک مدل زبان بزرگ فالکون (LLM) آشنا میکنیم Amazon SageMaker JumpStart و با استفاده از مدل برای خلاصه کردن اسناد طولانی با LangChain و Python.
بررسی اجمالی راه حل
آمازون SageMaker بر اساس دو دهه تجربه آمازون در توسعه برنامه های کاربردی ML در دنیای واقعی، از جمله توصیه های محصول، شخصی سازی، خرید هوشمند، روباتیک و دستگاه های صوتی ساخته شده است. SageMaker یک سرویس مدیریت شده واجد شرایط HIPAA است که ابزارهایی را ارائه می دهد که دانشمندان داده، مهندسان ML و تحلیلگران تجاری را قادر می سازد تا با ML نوآوری کنند. در SageMaker است Amazon SageMaker Studioیک محیط توسعه یکپارچه (IDE) که به طور هدفمند برای گردش های کاری ML مشترک ساخته شده است، که به نوبه خود شامل طیف گسترده ای از راه حل های شروع سریع و مدل های ML از پیش آموزش دیده در یک هاب یکپارچه به نام SageMaker JumpStart است. با SageMaker JumpStart، میتوانید از مدلهای از پیش آموزشدیدهشده، مانند Falcon LLM، با نمونههای نوتبوک از پیش ساخته شده و پشتیبانی از SDK برای آزمایش و استقرار این مدلهای ترانسفورماتور قدرتمند استفاده کنید. میتوانید از SageMaker Studio و SageMaker JumpStart برای استقرار و جستجوی مدل تولیدی خود در حساب AWS خود استفاده کنید.
همچنین می توانید اطمینان حاصل کنید که داده های بار استنتاج VPC شما را ترک نمی کند. میتوانید مدلها را بهعنوان نقاط پایانی تک مستاجر ارائه کنید و آنها را با جداسازی شبکه مستقر کنید. علاوه بر این، میتوانید با استفاده از قابلیت هاب مدل خصوصی در SageMaker JumpStart و ذخیره مدلهای تأییدشده در آنجا، مجموعهای از مدلهای انتخابشده را که نیازهای امنیتی شما را برآورده میکنند، مدیریت و مدیریت کنید. SageMaker در اختیار است HIPAA BAA, SOC123و HITRUST CSF.
La فالکون LLM یک مدل زبان بزرگ است که توسط محققان موسسه نوآوری فناوری (TII) بر روی بیش از 1 تریلیون توکن با استفاده از AWS آموزش دیده است. فالکون دارای تغییرات مختلفی است، با دو جزء اصلی آن Falcon 40B و Falcon 7B که به ترتیب از 40 میلیارد و 7 میلیارد پارامتر تشکیل شده است و نسخههای دقیقی که برای کارهای خاص مانند دستورالعملهای زیر آموزش داده شدهاند. فالکون در انواع وظایف، از جمله خلاصه سازی متن، تجزیه و تحلیل احساسات، پاسخ به سؤال و مکالمه به خوبی عمل می کند. این پست یک راهنما ارائه می دهد که می توانید برای استقرار Falcon LLM در حساب AWS خود، با استفاده از یک نمونه نوت بوک مدیریت شده از طریق SageMaker JumpStart برای آزمایش خلاصه سازی متن دنبال کنید.
مرکز مدل SageMaker JumpStart شامل نوت بوک های کاملی برای استقرار و پرس و جوی هر مدل است. تا زمان نگارش این مقاله، شش نسخه از Falcon در هاب مدل SageMaker JumpStart موجود است: Falcon 40B Instruct BF16، Falcon 40B BF16، Falcon 180B BF16، Falcon 180B Chat BF16، Falcon 7B Instruct BF16، و Falcon 7B Instruct BF16. در این پست از مدل Falcon 7B Instruct استفاده شده است.
در بخشهای بعدی، نحوه شروع خلاصهسازی اسناد را با استقرار Falcon 7B در SageMaker Jumpstart نشان میدهیم.
پیش نیازها
برای این آموزش، به یک حساب AWS با دامنه SageMaker نیاز دارید. اگر از قبل دامنه SageMaker ندارید، به آن مراجعه کنید ورود به دامنه Amazon SageMaker برای ایجاد یک
Falcon 7B را با استفاده از SageMaker JumpStart مستقر کنید
برای استقرار مدل خود، مراحل زیر را انجام دهید:
- از کنسول SageMaker به محیط SageMaker Studio خود بروید.
- در داخل IDE، در زیر SageMaker JumpStart در قسمت ناوبری، را انتخاب کنید مدل ها، نوت بوک ها، راه حل ها.
- برای استنتاج، مدل Falcon 7B Instruct را در نقطه پایانی مستقر کنید.

با این کار کارت مدل برای مدل Falcon 7B Instruct BF16 باز می شود. در این صفحه، شما می توانید پیدا کنید گسترش or قطار گزینه ها و همچنین پیوندهایی برای باز کردن نوت بوک های نمونه در SageMaker Studio. این پست از نمونه نوت بوک SageMaker JumpStart برای استقرار مدل استفاده می کند.
- را انتخاب کنید نوت بوک را باز کنید.
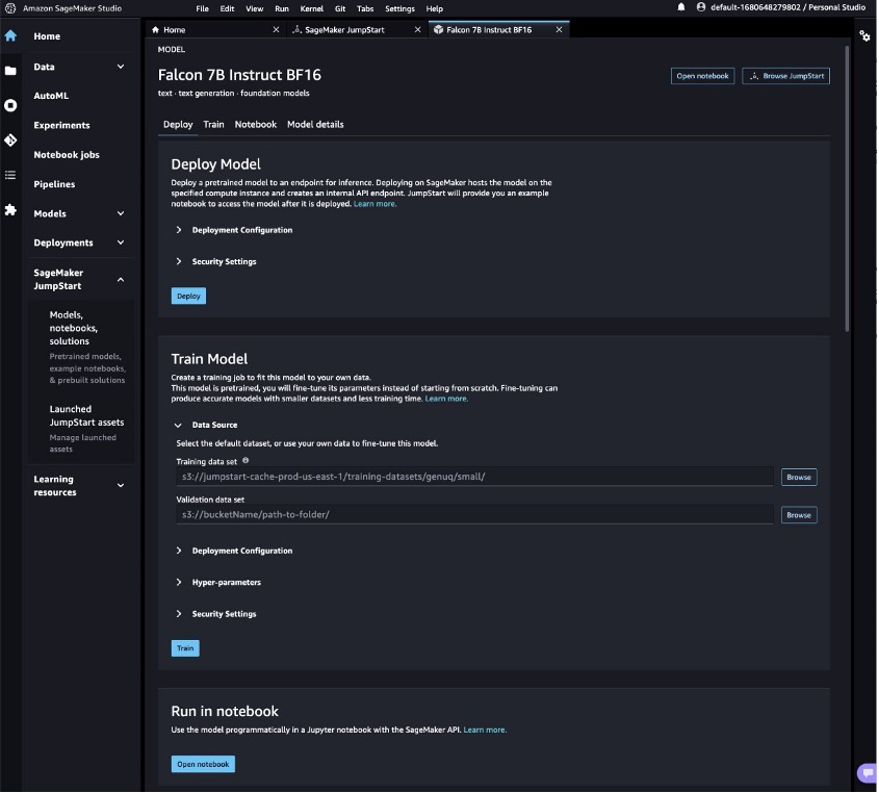
- چهار سلول اول نوت بوک را برای استقرار نقطه پایانی Falcon 7B Instruct اجرا کنید.
میتوانید مدلهای JumpStart مستقر شده خود را در صفحه مشاهده کنید دارایی های JumpStart را راه اندازی کرد احتمال برد مراجعه کنید.
- در قسمت ناوبری، در زیر SageMaker Jumpstart، انتخاب کنید دارایی های JumpStart را راه اندازی کرد.
- انتخاب نقاط پایانی مدل برای مشاهده وضعیت نقطه پایانی خود را انتخاب کنید.

با استقرار نقطه پایانی Falcon LLM، شما آماده پرس و جو از مدل هستید.
اولین پرس و جو خود را اجرا کنید
برای اجرای پرس و جو، مراحل زیر را انجام دهید:
- بر پرونده منو ، انتخاب کنید جدید و دفتر یادداشت برای باز کردن یک نوت بوک جدید
همچنین می توانید دفترچه یادداشت تکمیل شده را دانلود کنید اینجا کلیک نمایید.

- وقتی از شما خواسته شد، تصویر، هسته و نوع نمونه را انتخاب کنید. برای این پست، تصویر Data Science 3.0، هسته Python 3 و نمونه ml.t3.medium را انتخاب می کنیم.

- ماژول های Boto3 و JSON را با وارد کردن دو خط زیر در سلول اول وارد کنید:
- رسانه ها و مطبوعات Shift + Enter برای اجرای سلول
- در مرحله بعد، می توانید تابعی را تعریف کنید که نقطه پایانی شما را فراخوانی کند. این تابع یک بار دیکشنری را می گیرد و از آن برای فراخوانی کلاینت زمان اجرا SageMaker استفاده می کند. سپس پاسخ را از حالت سریال خارج می کند و ورودی و متن تولید شده را چاپ می کند.
محموله شامل اعلان به عنوان ورودی، همراه با پارامترهای استنتاج است که به مدل ارسال می شود.
- می توانید از این پارامترها با اعلان برای تنظیم خروجی مدل برای مورد استفاده خود استفاده کنید:
پرس و جو با یک اعلان خلاصه
این پست از یک مقاله پژوهشی نمونه برای نشان دادن خلاصه سازی استفاده می کند. فایل متنی مثال مربوط به خلاصه سازی خودکار متن در ادبیات زیست پزشکی است. مراحل زیر را کامل کنید:
- دانلود PDF و متن را در فایلی به نام کپی کنید
document.txt. - در SageMaker Studio، نماد آپلود را انتخاب کنید و فایل را در نمونه SageMaker Studio خود آپلود کنید.

خارج از جعبه، Falcon LLM از خلاصه سازی متن پشتیبانی می کند.
- بیایید تابعی ایجاد کنیم که از تکنیک های مهندسی سریع برای خلاصه کردن استفاده کند
document.txt:
متوجه خواهید شد که برای اسناد طولانی تر، یک خطا ظاهر می شود - Falcon، در کنار همه LLM های دیگر، محدودیتی در تعداد توکن های ارسال شده به عنوان ورودی دارد. ما میتوانیم با استفاده از قابلیتهای خلاصهسازی پیشرفته LangChain، که اجازه میدهد ورودی بسیار بزرگتری به LLM داده شود، این محدودیت را دور بزنیم.
وارد کردن و اجرای یک زنجیره خلاصه
LangChain یک کتابخانه نرمافزاری منبع باز است که به توسعهدهندگان و دانشمندان داده اجازه میدهد تا به سرعت برنامههای مولد سفارشی را بدون مدیریت تعاملات پیچیده ML بسازند، تنظیم و اجرا کنند، که معمولاً برای انتزاع بسیاری از موارد استفاده رایج برای مدلهای زبان هوش مصنوعی مولد تنها در چند مورد استفاده میشود. خطوط کد پشتیبانی LangChain از خدمات AWS شامل پشتیبانی از نقاط پایانی SageMaker است.
LangChain یک رابط قابل دسترسی برای LLM ها فراهم می کند. از ویژگیهای آن میتوان به ابزارهایی برای قالببندی سریع و زنجیرهسازی سریع اشاره کرد. این زنجیرهها را میتوان برای خلاصه کردن اسناد متنی که طولانیتر از آنچه مدل زبان پشتیبانی میکند در یک تماس استفاده کرد. میتوانید از استراتژی کاهش نقشه برای خلاصه کردن اسناد طولانی با تقسیم کردن آن به بخشهای قابل مدیریت، خلاصه کردن و ترکیب آنها (و در صورت نیاز دوباره خلاصهسازی) استفاده کنید.
- بیایید LangChain را برای شروع نصب کنیم:
- ماژول های مربوطه را وارد کنید و سند طولانی را به قطعات تقسیم کنید:
- برای اینکه LangChain به طور موثر با Falcon کار کند، باید کلاس های پیش فرض کنترل کننده محتوا را برای ورودی و خروجی معتبر تعریف کنید:
- شما می توانید درخواست های سفارشی را به عنوان تعریف کنید
PromptTemplateاشیاء، ابزار اصلی برای تحریک با LangChain، برای رویکرد خلاصه سازی کاهش نقشه. این یک مرحله اختیاری است زیرا اگر پارامترهای درون فراخوانی برای بارگیری زنجیره خلاصهسازی، اعلانهای نگاشت و ترکیب بهطور پیشفرض ارائه میشوند.load_summarize_chain) تعریف نشده اند.
- LangChain از LLM های میزبانی شده در نقاط پایانی استنتاج SageMaker پشتیبانی می کند، بنابراین به جای استفاده از AWS Python SDK، می توانید برای دسترسی بیشتر، اتصال را از طریق LangChain راه اندازی کنید:
- در نهایت، میتوانید در یک زنجیره خلاصهسازی بارگیری کنید و با استفاده از کد زیر خلاصهای را روی اسناد ورودی اجرا کنید:
از آنجا که verbose پارامتر روی تنظیم شده است True، تمام خروجی های میانی رویکرد کاهش نقشه را خواهید دید. این برای دنبال کردن توالی رویدادها برای رسیدن به خلاصه نهایی مفید است. با این رویکرد کاهش نقشه، می توانید به طور موثر اسناد را بسیار طولانی تر از حد مجاز حداکثر نشانه ورودی مدل خلاصه کنید.
پاک کردن
پس از پایان استفاده از نقطه پایانی استنتاج، مهم است که آن را حذف کنید تا از تحمیل هزینه های غیر ضروری از طریق خطوط کد زیر جلوگیری کنید:
استفاده از مدل های دیگر فونداسیون در SageMaker JumpStart
استفاده از سایر مدلهای پایه موجود در SageMaker JumpStart برای خلاصهسازی اسناد به حداقل هزینه برای راهاندازی و استقرار نیاز دارد. LLM ها گاهی با ساختار فرمت های ورودی و خروجی تغییر می کنند، و با اضافه شدن مدل های جدید و راه حل های از پیش ساخته شده به SageMaker JumpStart، بسته به اجرای کار، ممکن است مجبور شوید کدهای زیر را تغییر دهید:
- اگر در حال انجام خلاصه سازی از طریق
summarize()روش (روش بدون استفاده از LangChain)، ممکن است مجبور شوید ساختار JSON را تغییر دهیدpayloadپارامتر، و همچنین مدیریت متغیر پاسخ درquery_endpoint()تابع - اگر خلاصهسازی را از طریق LangChain انجام میدهید
load_summarize_chain()روش، ممکن است مجبور شوید آن را تغییر دهیدContentHandlerTextSummarizationکلاس، به طور خاصtransform_input()وtransform_output()توابع، برای مدیریت صحیح باری که LLM انتظار دارد و خروجی ای که LLM برمی گرداند.
مدل های پایه نه تنها در عواملی مانند سرعت و کیفیت استنتاج، بلکه در قالب های ورودی و خروجی نیز متفاوت هستند. به صفحه اطلاعات مربوطه LLM در مورد ورودی و خروجی مورد انتظار مراجعه کنید.
نتیجه
مدل Falcon 7B Instruct در مرکز مدل SageMaker JumpStart موجود است و در تعدادی از موارد استفاده کار می کند. این پست نشان میدهد که چگونه میتوانید با استفاده از SageMaker JumpStart، نقطه پایانی Falcon LLM خود را در محیط خود مستقر کنید و اولین آزمایشهای خود را از SageMaker Studio انجام دهید، به شما این امکان را میدهد که به سرعت مدلهای خود را نمونهسازی کنید و به طور یکپارچه به محیط تولید انتقال دهید. با Falcon و LangChain، می توانید به طور موثر اسناد طولانی مراقبت های بهداشتی و علوم زندگی را در مقیاس خلاصه کنید.
برای اطلاعات بیشتر در مورد کار با هوش مصنوعی مولد در AWS، مراجعه کنید معرفی ابزارهای جدید برای ساخت با هوش مصنوعی در AWS. شما می توانید با استفاده از روشی که در این پست توضیح داده شده است، آزمایش و ساختن مستندات خلاصه مفهومی را برای برنامه های کاربردی GenAI مبتنی بر مراقبت های بهداشتی و زندگی خود آغاز کنید. چه زمانی بستر آمازون به طور کلی در دسترس است، ما یک پست بعدی منتشر خواهیم کرد که نشان می دهد چگونه می توانید خلاصه سازی اسناد را با استفاده از Amazon Bedrock و LangChain پیاده سازی کنید.
درباره نویسنده
 جان کیتائوکا یک معمار راه حل در خدمات وب آمازون است. جان به مشتریان کمک می کند تا بارهای کاری AI/ML را در AWS طراحی و بهینه کنند تا به آنها در دستیابی به اهداف تجاری خود کمک کند.
جان کیتائوکا یک معمار راه حل در خدمات وب آمازون است. جان به مشتریان کمک می کند تا بارهای کاری AI/ML را در AWS طراحی و بهینه کنند تا به آنها در دستیابی به اهداف تجاری خود کمک کند.
 جاش فامستاد یک معمار راه حل در خدمات وب آمازون است. جاش با مشتریان بخش عمومی برای ایجاد و اجرای رویکردهای مبتنی بر ابر برای ارائه اولویت های تجاری کار می کند.
جاش فامستاد یک معمار راه حل در خدمات وب آمازون است. جاش با مشتریان بخش عمومی برای ایجاد و اجرای رویکردهای مبتنی بر ابر برای ارائه اولویت های تجاری کار می کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/create-an-hcls-document-summarization-application-with-falcon-using-amazon-sagemaker-jumpstart/

