دیاریزاسیون بلندگو، یک فرآیند ضروری در تجزیه و تحلیل صدا، یک فایل صوتی را بر اساس هویت گوینده تقسیم می کند. این پست به ادغام PyAnnote Hugging Face برای دیاریشن بلندگو می پردازد آمازون SageMaker نقاط انتهایی ناهمزمان
ما یک راهنمای جامع در مورد نحوه استقرار راه حل های تقسیم بندی بلندگو و خوشه بندی با استفاده از SageMaker در AWS Cloud ارائه می دهیم. میتوانید از این راهحل برای برنامههایی که با ضبطهای صوتی با چند بلندگو (بیش از 100) سروکار دارند، استفاده کنید.
بررسی اجمالی راه حل
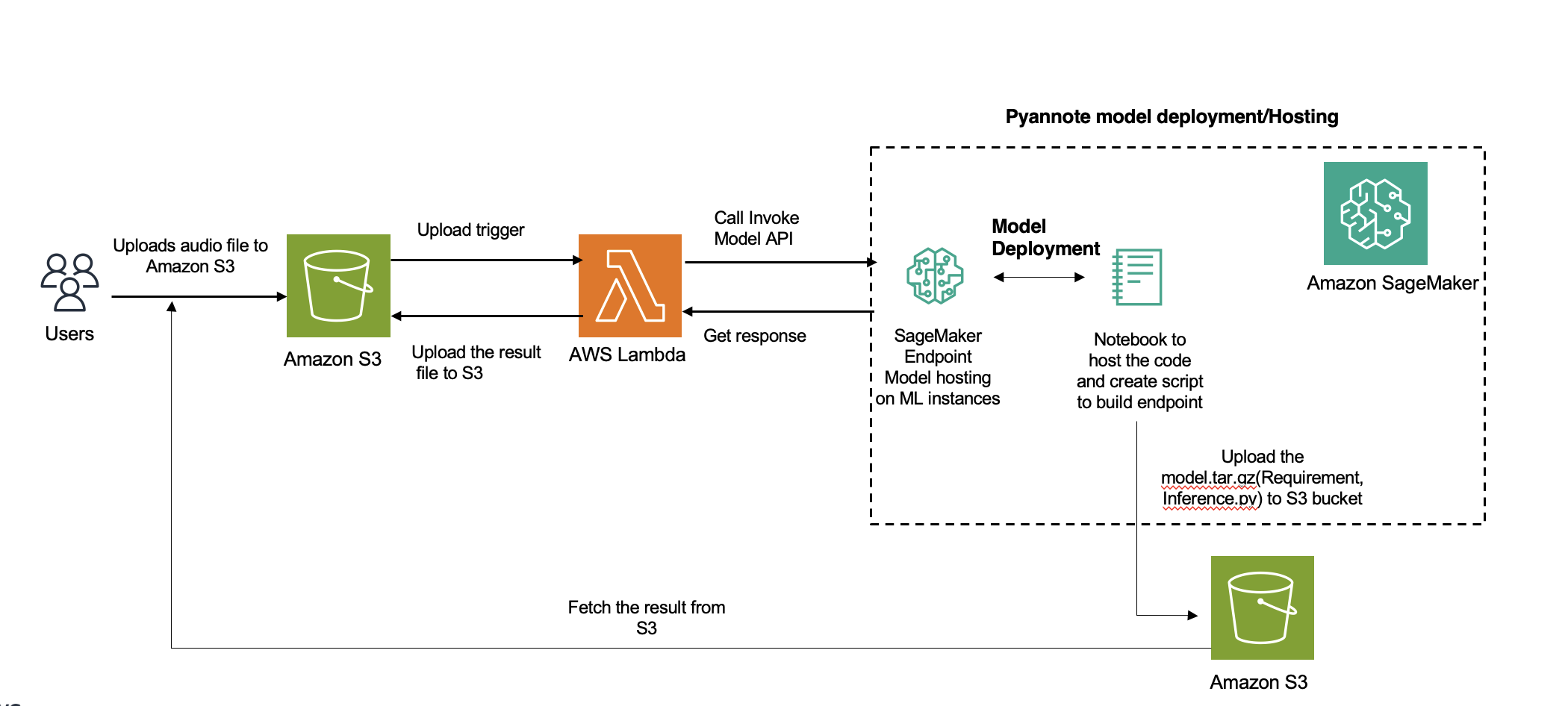
آمازون رونوشت سرویس پیشرو برای دیاریزاسیون بلندگو در AWS است. با این حال، برای زبانهایی که پشتیبانی نمیشوند، میتوانید از مدلهای دیگری (در مورد ما، PyAnnote) استفاده کنید که برای استنباط در SageMaker مستقر میشوند. برای فایلهای صوتی کوتاه که استنتاج تا 60 ثانیه طول میکشد، میتوانید استفاده کنید استنتاج بلادرنگ. به مدت بیش از 60 ثانیه، ناهمگام استنتاج باید استفاده شود مزیت اضافه استنتاج ناهمزمان، صرفه جویی در هزینه با مقیاس خودکار تعداد نمونه ها تا صفر زمانی است که هیچ درخواستی برای پردازش وجود ندارد.
در آغوش کشیدن صورت یک هاب منبع باز محبوب برای مدل های یادگیری ماشین (ML) است. AWS و Hugging Face دارای یک مشارکت که امکان ادغام یکپارچه را از طریق SageMaker با مجموعه ای از ظروف یادگیری عمیق (DLC) AWS برای آموزش و استنباط در PyTorch یا TensorFlow و برآوردگرها و پیش بینی کننده های Hugging Face برای SageMaker Python SDK فراهم می کند. ویژگیها و قابلیتهای SageMaker به توسعهدهندگان و دانشمندان داده کمک میکند تا به راحتی با پردازش زبان طبیعی (NLP) در AWS شروع کنند.
ادغام برای این راه حل شامل استفاده از مدل از پیش آموزش داده شده بیانگر Hugging Face با استفاده از کتابخانه PyAnnote. PyAnnote یک جعبه ابزار متن باز است که در پایتون برای دیاریشن بلندگو نوشته شده است. این مدل که بر روی مجموعه داده های صوتی نمونه آموزش داده شده است، پارتیشن بندی موثر بلندگو را در فایل های صوتی امکان پذیر می کند. این مدل در SageMaker به عنوان یک راهاندازی نقطه پایانی ناهمزمان مستقر شده است که پردازش کارآمد و مقیاسپذیر وظایف دیاریزاسیون را ارائه میکند.
نمودار زیر معماری راه حل را نشان می دهد.
برای این پست از فایل صوتی زیر استفاده می کنیم.
فایل های صوتی استریو یا چند کاناله به طور خودکار با میانگین کانال ها به مونو میکس می شوند. فایلهای صوتی نمونهبرداری شده با سرعت متفاوت، پس از بارگذاری، بهطور خودکار به ۱۶ کیلوهرتز نمونهگیری میشوند.
مطمئن شوید که حساب AWS دارای سهمیه خدماتی برای میزبانی نقطه پایانی SageMaker برای نمونه ml.g5.2xlarge است.
یک تابع مدل برای دسترسی به diarization بلندگو PyAnnote از Hugging Face ایجاد کنید
شما می توانید از Hugging Face Hub برای دسترسی به آموزش های قبلی مورد نظر استفاده کنید مدل دیاریزاسیون بلندگو PyAnnote. هنگام ایجاد نقطه پایانی SageMaker از همان اسکریپت برای دانلود فایل مدل استفاده می کنید.
کد زیر را ببینید:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
کد مدل را بسته بندی کنید
فایل های ضروری مانند inference.py را که حاوی کد استنتاج است آماده کنید:
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data[turn] = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=["start", "end", "speaker"])
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
آماده کن یک requirements.txt فایلی که حاوی کتابخانه های پایتون لازم برای اجرای استنتاج است:
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
در نهایت، را فشرده کنید inference.py و فایل های requirement.txt و ذخیره کنید model.tar.gz:
!tar zcvf model.tar.gz *
یک مدل SageMaker را پیکربندی کنید
یک منبع مدل SageMaker را با مشخص کردن URI تصویر، مکان داده مدل در آن تعریف کنید سرویس ذخیره سازی ساده آمازون (S3) و نقش SageMaker:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client("iam")
role = iam.get_role(RoleName="sagemaker_execution_role")["Role"]["Arn"]
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
مدل را در آمازون S3 آپلود کنید
فایل زیپ شده PyAnnote Hugging Face را در یک سطل S3 آپلود کنید:
یک نقطه پایانی ناهمزمان را برای استقرار مدل در SageMaker با استفاده از پیکربندی استنتاج ناهمزمان ارائه شده پیکربندی کنید:
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
نقطه پایانی را تست کنید
عملکرد نقطه پایانی را با ارسال یک فایل صوتی برای diarization و بازیابی خروجی JSON ذخیره شده در مسیر خروجی S3 مشخص شده ارزیابی کنید:
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
برای استقرار این راه حل در مقیاس، پیشنهاد می کنیم از آن استفاده کنید AWS لامبدا, سرویس اطلاع رسانی ساده آمازون (Amazon SNS)، یا سرویس صف ساده آمازون (Amazon SQS). این سرویس ها برای مقیاس پذیری، معماری های رویداد محور و استفاده کارآمد از منابع طراحی شده اند. آنها می توانند به جدا کردن فرآیند استنتاج ناهمزمان از پردازش نتیجه کمک کنند و به شما این امکان را می دهند که هر جزء را به طور مستقل مقیاس بندی کنید و انبوه درخواست های استنتاج را به طور موثرتری مدیریت کنید.
نتایج
خروجی مدل در ذخیره می شود s3://sagemaker-xxxx /async_inference/output/. خروجی نشان می دهد که ضبط صدا به سه ستون تقسیم شده است:
می توانید با تنظیم MinCapacity روی 0، یک خط مشی مقیاس بندی را صفر کنید. استنتاج ناهمزمان به شما امکان می دهد بدون هیچ درخواستی مقیاس خودکار را به صفر برسانید. شما نیازی به حذف نقطه پایانی ندارید، آن را مقیاس ها از صفر در صورت نیاز مجدد، کاهش هزینه ها در صورت عدم استفاده. کد زیر را ببینید:
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
اگر می خواهید نقطه پایانی را حذف کنید، از کد زیر استفاده کنید:
این راه حل می تواند به طور موثر فایل های صوتی متعدد یا بزرگ را مدیریت کند.
این مثال از یک نمونه برای نمایش استفاده می کند. اگر می خواهید از این راه حل برای صدها یا هزاران ویدیو استفاده کنید و از یک نقطه پایانی ناهمزمان برای پردازش در چندین نمونه استفاده کنید، می توانید از یک سیاست مقیاس بندی خودکار، که برای تعداد زیادی از اسناد منبع طراحی شده است. مقیاس خودکار به صورت پویا تعداد نمونه های ارائه شده برای یک مدل را در پاسخ به تغییرات در حجم کاری شما تنظیم می کند.
این راه حل با جدا کردن وظایف طولانی مدت از استنتاج بلادرنگ، منابع را بهینه می کند و بار سیستم را کاهش می دهد.
نتیجه
در این پست، ما یک رویکرد ساده برای استقرار مدل diarization بلندگوی Hugging Face در SageMaker با استفاده از اسکریپتهای Python ارائه کردیم. استفاده از نقطه پایانی ناهمزمان ابزاری کارآمد و مقیاسپذیر برای ارائه پیشبینیهای دیاریزاسیون به عنوان یک سرویس فراهم میکند و درخواستهای همزمان را بهطور یکپارچه برآورده میکند.
همین امروز با دیاریزاسیون اسپیکرهای ناهمزمان برای پروژه های صوتی خود شروع کنید. اگر در مورد راهاندازی و راهاندازی نقطه پایانی دیاریزاسیون ناهمزمان خود سؤالی دارید در نظرات با ما در میان بگذارید.
درباره نویسنده
سانجی تیواری معمار راه حل های تخصصی AI/ML است که وقت خود را صرف کار با مشتریان استراتژیک برای تعریف الزامات کسب و کار، ارائه جلسات L300 پیرامون موارد استفاده خاص، و طراحی برنامه ها و خدمات AI/ML می کند که مقیاس پذیر، قابل اعتماد و کارآمد هستند. او به راهاندازی و مقیاسبندی سرویس آمازون SageMaker مبتنی بر AI/ML کمک کرده است و چندین اثبات مفهومی را با استفاده از خدمات هوش مصنوعی آمازون پیادهسازی کرده است. او همچنین پلتفرم تجزیه و تحلیل پیشرفته را به عنوان بخشی از سفر تحول دیجیتال توسعه داده است.
کیران چالاپالی یک توسعه دهنده کسب و کار با فناوری عمیق با بخش عمومی AWS است. او بیش از 8 سال تجربه در AI/ML و 23 سال تجربه کلی توسعه و فروش نرم افزار دارد. Kiran به کسبوکارهای بخش عمومی در سراسر هند کمک میکند راهحلهای مبتنی بر ابر را که از فناوریهای هوش مصنوعی، ML، و هوش مصنوعی مولد - از جمله مدلهای زبان بزرگ - استفاده میکنند، کاوش کرده و ایجاد کنند.
 سانجی تیواری معمار راه حل های تخصصی AI/ML است که وقت خود را صرف کار با مشتریان استراتژیک برای تعریف الزامات کسب و کار، ارائه جلسات L300 پیرامون موارد استفاده خاص، و طراحی برنامه ها و خدمات AI/ML می کند که مقیاس پذیر، قابل اعتماد و کارآمد هستند. او به راهاندازی و مقیاسبندی سرویس آمازون SageMaker مبتنی بر AI/ML کمک کرده است و چندین اثبات مفهومی را با استفاده از خدمات هوش مصنوعی آمازون پیادهسازی کرده است. او همچنین پلتفرم تجزیه و تحلیل پیشرفته را به عنوان بخشی از سفر تحول دیجیتال توسعه داده است.
سانجی تیواری معمار راه حل های تخصصی AI/ML است که وقت خود را صرف کار با مشتریان استراتژیک برای تعریف الزامات کسب و کار، ارائه جلسات L300 پیرامون موارد استفاده خاص، و طراحی برنامه ها و خدمات AI/ML می کند که مقیاس پذیر، قابل اعتماد و کارآمد هستند. او به راهاندازی و مقیاسبندی سرویس آمازون SageMaker مبتنی بر AI/ML کمک کرده است و چندین اثبات مفهومی را با استفاده از خدمات هوش مصنوعی آمازون پیادهسازی کرده است. او همچنین پلتفرم تجزیه و تحلیل پیشرفته را به عنوان بخشی از سفر تحول دیجیتال توسعه داده است. کیران چالاپالی یک توسعه دهنده کسب و کار با فناوری عمیق با بخش عمومی AWS است. او بیش از 8 سال تجربه در AI/ML و 23 سال تجربه کلی توسعه و فروش نرم افزار دارد. Kiran به کسبوکارهای بخش عمومی در سراسر هند کمک میکند راهحلهای مبتنی بر ابر را که از فناوریهای هوش مصنوعی، ML، و هوش مصنوعی مولد - از جمله مدلهای زبان بزرگ - استفاده میکنند، کاوش کرده و ایجاد کنند.
کیران چالاپالی یک توسعه دهنده کسب و کار با فناوری عمیق با بخش عمومی AWS است. او بیش از 8 سال تجربه در AI/ML و 23 سال تجربه کلی توسعه و فروش نرم افزار دارد. Kiran به کسبوکارهای بخش عمومی در سراسر هند کمک میکند راهحلهای مبتنی بر ابر را که از فناوریهای هوش مصنوعی، ML، و هوش مصنوعی مولد - از جمله مدلهای زبان بزرگ - استفاده میکنند، کاوش کرده و ایجاد کنند.
