این پست توسط Anatoly Khomenko، مهندس یادگیری ماشین، و Abdenour Bezzouh، مدیر ارشد فناوری Talent.com نوشته شده است.
در 2011 تاسیس شد، Talent.com یکی از بزرگترین منابع اشتغال در جهان است. این شرکت فهرست های شغلی پولی از مشتریان خود را با لیست مشاغل عمومی در یک پلتفرم قابل جستجو ترکیب می کند. Talent.com با بیش از 30 میلیون شغل در بیش از 75 کشور فهرست شده است. نتیجه پلتفرمی است که میلیونها جوینده کار را با مشاغل موجود مطابقت میدهد.
ماموریت Talent.com متمرکز کردن تمام مشاغل موجود در وب است تا به جویندگان کار کمک کند بهترین تطابق خود را پیدا کنند و در عین حال بهترین تجربه جستجو را برای آنها فراهم کند. تمرکز آن بر ارتباط است، زیرا ترتیب مشاغل توصیه شده برای نشان دادن مشاغل مرتبط با علایق کاربران بسیار مهم است. عملکرد الگوریتم تطبیق Talent.com برای موفقیت کسب و کار بسیار مهم است و یکی از عوامل کلیدی در تجربه کاربران آن است. پیشبینی اینکه کدام مشاغل برای یک جوینده کار مرتبط هستند، بر اساس مقدار محدود اطلاعات ارائه شده، که معمولاً شامل چند کلمه کلیدی و یک مکان است، چالش برانگیز است.
با توجه به این ماموریت، Talent.com و AWS برای ایجاد یک موتور توصیه شغلی با استفاده از پیشرفته ترین روش های پردازش زبان طبیعی (NLP) و تکنیک های آموزش مدل یادگیری عمیق با یکدیگر متحد شدند. آمازون SageMaker ارائه تجربه ای بی نظیر برای جویندگان کار. این پست رویکرد مشترک ما را برای طراحی یک سیستم توصیه شغلی، از جمله مهندسی ویژگی، طراحی معماری مدل یادگیری عمیق، بهینهسازی فراپارامتر، و ارزیابی مدل نشان میدهد که قابلیت اطمینان و اثربخشی راهحل ما را هم برای جویندگان کار و هم برای کارفرمایان تضمین میکند. این سیستم توسط تیمی از دانشمندان اختصاصی یادگیری ماشین کاربردی (ML)، مهندسان ML و متخصصان موضوع با همکاری AWS و Talent.com توسعه یافته است.
سیستم توصیه باعث افزایش 8.6 درصدی نرخ کلیک (CTR) در تست آنلاین A/B در برابر راه حل قبلی مبتنی بر XGBoost شده است و به اتصال میلیون ها کاربر Talent.com به مشاغل بهتر کمک می کند.
بررسی اجمالی راه حل
نمای کلی سیستم در شکل زیر نشان داده شده است. این سیستم درخواست جستجوی کاربر را به عنوان ورودی دریافت می کند و یک لیست رتبه بندی شده از مشاغل را به ترتیب مناسب بودن خروجی می دهد. تناسب شغلی با احتمال کلیک (احتمال کلیک یک جوینده کار برای اطلاعات بیشتر) اندازه گیری می شود.

این سیستم شامل چهار جزء اصلی است:
- معماری مدل - هسته اصلی این موتور توصیه شغلی یک مدل برج سهگانه مبتنی بر یادگیری عمیق است که شامل یک رمزگذار پرس و جو است که درخواستهای جستجوی کاربر را رمزگذاری میکند، یک رمزگذار سند که شرح شغل را رمزگذاری میکند و یک رمزگذار تعاملی که کار کاربر گذشته را پردازش میکند. ویژگی های تعامل خروجی های سه برج به هم متصل شده و از یک سر طبقه بندی عبور می کنند تا احتمال کلیک کار را پیش بینی کنند. این سیستم با آموزش این مدل در مورد جستوجوها، مشخصات شغلی و دادههای تعامل با کاربر تاریخی از Talent.com، توصیههای شغلی شخصی و بسیار مرتبط را به جویندگان کار ارائه میکند.
- مهندسی ویژگی - ما دو مجموعه مهندسی ویژگی را برای استخراج اطلاعات ارزشمند از داده های ورودی و تغذیه آن به برج های مربوطه در مدل انجام می دهیم. این دو مجموعه مهندسی ویژگی استاندارد و تعبیههای Sentence-BERT (SBERT) با تنظیم دقیق هستند. ما از ویژگی های استاندارد مهندسی شده به عنوان ورودی به رمزگذار تعامل استفاده می کنیم و جاسازی مشتق شده SBERT را در رمزگذار پرس و جو و رمزگذار سند تغذیه می کنیم.
- بهینه سازی و تنظیم مدل - ما از متدولوژی های آموزشی پیشرفته برای آموزش، آزمایش و استقرار سیستم با SageMaker استفاده می کنیم. این شامل آموزش SageMaker Distributed Data Parallel (DDP)، تنظیم خودکار مدل SageMaker (AMT)، زمانبندی نرخ یادگیری، و توقف زودهنگام برای بهبود عملکرد مدل و سرعت آموزش است. استفاده از چارچوب آموزشی DDP به سرعت آموزش مدل ما تقریباً هشت برابر سریعتر کمک کرد.
- ارزیابی مدل - ما ارزیابی آفلاین و آنلاین را انجام می دهیم. ما عملکرد مدل را با منطقه زیر منحنی (AUC) و میانگین دقت در K (mAP@K) در ارزیابی آفلاین ارزیابی میکنیم. در طول تست آنلاین A/B، ما پیشرفتهای CTR را ارزیابی میکنیم.
در بخش های بعدی جزئیات این چهار جزء را ارائه می دهیم.
طراحی معماری مدل یادگیری عمیق
ما یک مدل برج سهگانه عمیق نقطهای (TTDP) با استفاده از معماری یادگیری عمیق سهگانه برج و رویکرد مدلسازی جفت نقطهای طراحی میکنیم. معماری برج سه گانه سه شبکه عصبی عمیق موازی را فراهم می کند که هر برج به طور مستقل مجموعه ای از ویژگی ها را پردازش می کند. این الگوی طراحی به مدل اجازه می دهد تا بازنمایی های متمایز را از منابع مختلف اطلاعات بیاموزد. پس از اینکه نمایشهای هر سه برج بهدست آمد، آنها به هم متصل میشوند و از یک سر طبقهبندی عبور میکنند تا پیشبینی نهایی (0-1) روی احتمال کلیک (یک تنظیم مدلسازی نقطهای) انجام شود.
این سه برج بر اساس اطلاعاتی که پردازش میکنند نامگذاری میشوند: رمزگذار پرس و جو درخواست جستجوی کاربر را پردازش میکند، رمزگذار سند محتوای اسنادی شغل نامزد شامل عنوان شغل و نام شرکت را پردازش میکند، و رمزگذار تعامل از ویژگیهای مرتبط استخراج شده از تعاملات قبلی کاربر استفاده میکند. و تاریخ (در بخش بعدی بیشتر مورد بحث قرار خواهد گرفت).
هر یک از این برج ها نقش مهمی در یادگیری نحوه توصیه مشاغل ایفا می کنند:
- رمزگذار پرس و جو - رمزگذار پرس و جو، جاسازی های SBERT را که از جستار جستجوی کار کاربر مشتق شده است، می گیرد. ما تعبیهها را از طریق یک مدل SBERT که بهخوبی تنظیم کردهایم، تقویت میکنیم. این رمزگذار هدف جستجوی کار کاربر را پردازش کرده و درک میکند، از جمله جزئیات و تفاوتهای ظریف ثبتشده توسط جاسازیهای دامنه خاص ما.
- رمزگذار سند - رمزگذار سند اطلاعات هر فهرست شغل را پردازش می کند. به طور خاص، جاسازی های SBERT متن پیوسته را از عنوان شغل و شرکت می گیرد. شهود این است که کاربران به مشاغل نامزدی که بیشتر مرتبط با پرس و جو هستند علاقه بیشتری خواهند داشت. با نگاشت مشاغل و پرس و جوهای جستجو در همان فضای برداری (تعریف شده توسط SBERT)، مدل می تواند یاد بگیرد که احتمال مشاغل بالقوه ای که یک جوینده کار روی آن کلیک می کند را پیش بینی کند.
- رمزگذار تعامل – رمزگذار تعامل با تعاملات گذشته کاربر با لیست مشاغل سروکار دارد. ویژگیها از طریق یک مرحله مهندسی ویژگی استاندارد تولید میشوند که شامل محاسبه معیارهای محبوبیت برای نقشهای شغلی و شرکتها، ایجاد امتیاز شباهت زمینه، و استخراج پارامترهای تعامل از تعاملات قبلی کاربر است. همچنین موجودیتهای نامگذاریشده شناساییشده در عنوان شغل و عبارتهای جستجو را با یک مدل تشخیص نهاد نامگذاری شده (NER) از پیش آموزشدیده پردازش میکند.
هر برج یک خروجی مستقل به صورت موازی تولید می کند که همه آنها به هم متصل می شوند. سپس این بردار ویژگی ترکیبی برای پیشبینی احتمال کلیک فهرست کار برای یک درخواست کاربر ارسال میشود. معماری برج سهگانه انعطافپذیری را در ثبت روابط پیچیده بین ورودیها یا ویژگیهای مختلف فراهم میکند، و به مدل اجازه میدهد تا از نقاط قوت هر برج در حالی که بازنماییهای گویاتری برای کار دادهشده یاد میگیرد، استفاده کند.
احتمال کلیک پیشبینیشده مشاغل کاندیدا از بالا به پایین رتبهبندی میشوند و توصیههای شغلی شخصیسازی شده را ایجاد میکنند. از طریق این فرآیند، ما اطمینان میدهیم که هر بخش از اطلاعات - خواه هدف جستجوی کاربر، جزئیات فهرست شغل یا تعاملات گذشته باشد - به طور کامل توسط یک برج خاص که به آن اختصاص داده شده است ثبت شود. روابط پیچیده بین آنها نیز از طریق ترکیب خروجی های برج گرفته می شود.
مهندسی ویژگی
ما دو مجموعه از فرآیندهای مهندسی ویژگی را برای استخراج اطلاعات ارزشمند از دادههای خام و وارد کردن آن به برجهای مربوطه در مدل انجام میدهیم: مهندسی ویژگی استاندارد و تعبیههای SBERT با تنظیم دقیق.
مهندسی ویژگی استاندارد
فرآیند آماده سازی داده های ما با مهندسی ویژگی استاندارد آغاز می شود. به طور کلی، ما چهار نوع ویژگی را تعریف می کنیم:
- محبوبیت - ما امتیازات محبوبیت را در سطح شغلی فردی، سطح شغلی و سطح شرکت محاسبه می کنیم. این معیاری از جذابیت یک شغل یا شرکت خاص را ارائه می دهد.
- شباهت متنی - برای درک رابطه متنی بین عناصر متنی مختلف، نمرات شباهت، از جمله شباهت رشتهای بین عبارت جستجو و عنوان شغل را محاسبه میکنیم. این به ما کمک می کند تا ارتباط یک فرصت شغلی را با سابقه جستجو یا درخواست کارجو بسنجیم.
- اثر متقابل - علاوه بر این، ما ویژگیهای تعامل را از تعاملات قبلی کاربران با فهرستهای شغلی استخراج میکنیم. نمونه بارز این موضوع شباهت جاسازی شده بین عناوین شغلی کلیک شده قبلی و عناوین شغلی نامزدها است. این معیار به ما کمک می کند شباهت بین مشاغل قبلی را که کاربر نسبت به فرصت های شغلی آینده نشان داده است، درک کنیم. این دقت موتور توصیه کار ما را افزایش می دهد.
- مشخصات – در نهایت، اطلاعات علاقه شغلی تعریف شده توسط کاربر را از نمایه کاربر استخراج می کنیم و آن را با نامزدهای شغلی جدید مقایسه می کنیم. این به ما کمک می کند بفهمیم که آیا یک نامزد شغل با علاقه کاربر مطابقت دارد یا خیر.
یک گام مهم در آماده سازی داده های ما، استفاده از یک مدل NER از پیش آموزش دیده است. با پیادهسازی مدل NER، میتوانیم موجودیتهای نامگذاریشده را در عناوین شغلی و عبارتهای جستجو شناسایی و برچسبگذاری کنیم. در نتیجه، این به ما امکان میدهد نمرات شباهت را بین این موجودیتهای شناساییشده محاسبه کنیم، و معیاری متمرکزتر و آگاهتر از ارتباط را ارائه کنیم. این روش نویز در دادههای ما را کاهش میدهد و روشی دقیقتر و حساس به زمینه برای مقایسه مشاغل به ما میدهد.
تعبیههای SBERT با تنظیم دقیق
برای افزایش ارتباط و دقت سیستم توصیه شغلی خود، از قدرت SBERT استفاده می کنیم، یک مدل قدرتمند مبتنی بر ترانسفورماتور، که به دلیل مهارتش در گرفتن معانی و زمینه های معنایی از متن شناخته شده است. با این حال، تعبیههای عمومی مانند SBERT، اگرچه مؤثر هستند، اما ممکن است به طور کامل تفاوتهای ظریف و اصطلاحات منحصربهفرد ذاتی در یک حوزه خاص مانند حوزه ما را که حول اشتغال و جستجوی شغل متمرکز است، دربر نگیرند. برای غلبه بر این موضوع، جاسازیهای SBERT را با استفاده از دادههای دامنه خاص خود تنظیم میکنیم. این فرآیند تنظیم دقیق، مدل را برای درک بهتر و پردازش زبان، اصطلاحات و زمینه خاص صنعت بهینه میکند و تعبیهها را بیشتر منعکسکننده حوزه خاص ما میکند. در نتیجه، جاسازیهای اصلاحشده عملکرد بهبود یافتهای را در گرفتن اطلاعات معنایی و متنی در حوزه ما ارائه میدهند که منجر به توصیههای شغلی دقیقتر و معنادارتر برای کاربران میشود.
شکل زیر مرحله تنظیم دقیق SBERT را نشان می دهد.
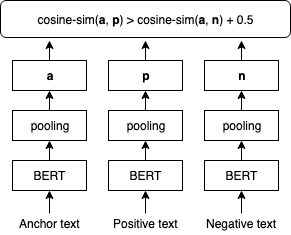
ما تعبیههای SBERT را با استفاده از تنظیم دقیق انجام میدهیم TripletLoss با متریک فاصله کسینوس که جاسازی متن را می آموزد که در آن متن های لنگر و مثبت شباهت کسینوس بالاتری نسبت به متن های لنگر و منفی دارند. ما از عبارت های جستجوی کاربران به عنوان متن لنگر استفاده می کنیم. ما عناوین شغلی و نام کارفرمایان را به عنوان ورودی به متون مثبت و منفی ترکیب می کنیم. متون مثبت از آگهی های کاری که کاربر مربوطه روی آنها کلیک کرده است، نمونه برداری می شود، در حالی که متون منفی از آگهی های کاری که کاربر روی آنها کلیک نکرده است، نمونه برداری می شود. در زیر نمونه اجرای روش تنظیم دقیق است:
آموزش مدل با SageMaker Distributed Data Parallel
ما از SageMaker Distributed Data Parallel (SMDDP) استفاده می کنیم، یکی از ویژگی های پلتفرم SageMaker ML که بر روی PyTorch DDP ساخته شده است. این یک محیط بهینه برای اجرای مشاغل آموزشی PyTorch DDP در پلتفرم SageMaker فراهم می کند. این برای سرعت بخشیدن به آموزش مدل یادگیری عمیق طراحی شده است. این کار را با تقسیم یک مجموعه داده بزرگ به قطعات کوچکتر و توزیع آنها در چندین GPU انجام می دهد. این مدل در هر پردازنده گرافیکی تکرار می شود. هر GPU داده های اختصاص داده شده خود را به طور مستقل پردازش می کند و نتایج در همه GPU ها جمع آوری و همگام می شوند. DDP از ارتباطات گرادیان مراقبت می کند تا کپی های مدل را هماهنگ نگه دارد و برای سرعت بخشیدن به آموزش، آنها را با محاسبات گرادیان همپوشانی می کند. SMDDP از یک الگوریتم AllReduce بهینه برای به حداقل رساندن ارتباط بین GPUها، کاهش زمان همگام سازی و بهبود سرعت کلی استفاده می کند. این الگوریتم با شرایط مختلف شبکه تطبیق مییابد و آن را هم برای محیطهای داخلی و هم برای محیطهای مبتنی بر ابر کارآمد میکند. در معماری SMDDP (همانطور که در شکل زیر نشان داده شده است)، آموزش توزیع شده نیز با استفاده از خوشهای از گرههای متعدد مقیاسبندی میشود. این بدان معناست که نه تنها چندین GPU در یک نمونه محاسباتی، بلکه بسیاری از نمونهها با چندین GPU، که سرعت آموزش را بیشتر میکند.

برای آشنایی بیشتر با این معماری به ادامه مطلب مراجعه نمایید مقدمه ای بر کتابخانه موازی داده های توزیع شده SageMaker.
با SMDDP، ما توانسته ایم زمان آموزش مدل TTDP خود را به میزان قابل توجهی کاهش دهیم و آن را هشت برابر سریعتر کنیم. زمانهای آموزش سریعتر به این معنی است که میتوانیم مدلهای خود را سریعتر تکرار و بهبود دهیم، که منجر به توصیههای شغلی بهتر برای کاربران در مدت زمان کوتاهتری میشود. این افزایش بهره وری در حفظ رقابت پذیری موتور توصیه شغلی ما در بازار کار به سرعت در حال تحول است.
همانطور که در بلوک کد زیر نشان داده شده است، می توانید اسکریپت آموزشی خود را با SMDDP تنها با سه خط کد تطبیق دهید. با استفاده از PyTorch به عنوان مثال، تنها کاری که باید انجام دهید این است که کلاینت PyTorch کتابخانه SMDDP را وارد کنید (smdistributed.dataparallel.torch.torch_smddp). مشتری ثبت نام می کند smddp به عنوان یک Backend برای PyTorch.
پس از اینکه یک اسکریپت PyTorch در حال کار دارید که برای استفاده از کتابخانه موازی داده های توزیع شده سازگار شده است، می توانید یک کار آموزشی توزیع شده را با استفاده از SageMaker Python SDK راه اندازی کنید.
ارزیابی عملکرد مدل
هنگام ارزیابی عملکرد یک سیستم توصیه، بسیار مهم است که معیارهایی را انتخاب کنید که نزدیک به اهداف تجاری باشد و درک روشنی از اثربخشی مدل ارائه دهد. در مورد ما، ما از AUC برای ارزیابی عملکرد پیشبینی کلیک شغلی مدل TTDP خود و از mAP@K برای ارزیابی کیفیت فهرست مشاغل رتبهبندی نهایی استفاده میکنیم.
AUC به ناحیه زیر منحنی مشخصه عملکرد گیرنده (ROC) اشاره دارد. این احتمال را نشان می دهد که یک مثال مثبت انتخاب شده به طور تصادفی بالاتر از یک مثال منفی انتخاب شده به طور تصادفی رتبه بندی می شود. از 0 تا 1 متغیر است که 1 نشان دهنده یک طبقه بندی ایده آل و 0.5 نشان دهنده یک حدس تصادفی است. mAP@K معیاری است که معمولاً برای ارزیابی کیفیت سیستمهای بازیابی اطلاعات، مانند موتور پیشنهاد کار ما، استفاده میشود. دقت متوسط بازیابی K آیتم های مرتبط را برای یک پرس و جو یا کاربر معین اندازه گیری می کند. از 0 تا 1 متغیر است که 1 نشان دهنده رتبه بندی بهینه و 0 نشان دهنده کمترین دقت ممکن در مقدار K داده شده است. ما AUC، mAP@1 و mAP@3 را ارزیابی می کنیم. در مجموع، این معیارها به ما امکان میدهد توانایی مدل را برای تمایز بین کلاسهای مثبت و منفی (AUC) و موفقیت آن در رتبهبندی مرتبطترین موارد در بالا (mAP@K) اندازهگیری کنیم.
بر اساس ارزیابی آفلاین ما، مدل TTDP نسبت به مدل پایه - مدل تولید مبتنی بر XGBoost موجود - 16.65٪ برای AUC، 20٪ برای mAP@1 و 11.82٪ برای mAP@3 بهتر عمل کرد.

علاوه بر این، ما یک تست آنلاین A/B برای ارزیابی سیستم پیشنهادی طراحی کردیم و آزمایش را روی درصدی از جمعیت ایمیل ایالات متحده به مدت 6 هفته انجام دادیم. در مجموع، تقریباً 22 میلیون ایمیل با استفاده از شغل توصیه شده توسط سیستم جدید ارسال شد. افزایش کلیک در مقایسه با مدل قبلی 8.6٪ بود. Talent.com به تدریج درصد را افزایش می دهد تا سیستم جدید را به جمعیت و کانال های کامل خود عرضه کند.
نتیجه
ایجاد یک سیستم توصیه شغلی یک تلاش پیچیده است. هر جوینده کار نیازها، ترجیحات و تجربیات حرفه ای منحصر به فردی دارد که نمی توان از یک جستجوی کوتاه استنباط کرد. در این پست، Talent.com با AWS همکاری کرد تا یک راهحل توصیهکننده شغلی مبتنی بر یادگیری عمیق را ایجاد کند که لیست مشاغلی را که باید به کاربران توصیه شود رتبهبندی میکند. تیم Talent.com واقعاً از همکاری با تیم AWS در طول فرآیند حل این مشکل لذت برد. این یک نقطه عطف مهم در سفر تحول آفرین Talent.com است، زیرا این تیم از قدرت یادگیری عمیق برای توانمندسازی کسب و کار خود استفاده می کند.
این پروژه با استفاده از SBERT برای ایجاد تعبیههای متنی تنظیم شده است. در زمان نگارش، AWS معرفی شد آمازون تایتان Embeddings به عنوان بخشی از مدل های بنیادی آنها (FM) ارائه شده از طریق بستر آمازون، که یک سرویس کاملاً مدیریت شده است که مجموعهای از مدلهای پایه با کارایی بالا را از شرکتهای پیشرو هوش مصنوعی ارائه میدهد. ما خوانندگان را تشویق میکنیم تا تکنیکهای یادگیری ماشین ارائهشده در این پست وبلاگ را بررسی کنند و از قابلیتهای ارائهشده توسط AWS، مانند SMDDP، استفاده کنند، در حالی که از مدلهای اساسی AWS Bedrock برای ایجاد قابلیتهای جستجوی خود استفاده میکنند.
منابع
درباره نویسندگان
 یی شیانگ دانشمند کاربردی II در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابری خود را سرعت بخشند.
یی شیانگ دانشمند کاربردی II در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابری خود را سرعت بخشند.
 تانگ وانگ یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
تانگ وانگ یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
 دیمیتری بسپالوف یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
دیمیتری بسپالوف یک دانشمند ارشد کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به مشتریان AWS در صنایع مختلف کمک می کند تا پذیرش هوش مصنوعی و ابر خود را تسریع کنند.
 آناتولی خومنکو یک مهندس ارشد یادگیری ماشین در Talent.com با علاقه به پردازش زبان طبیعی است که افراد خوب را با مشاغل خوب مطابقت می دهد.
آناتولی خومنکو یک مهندس ارشد یادگیری ماشین در Talent.com با علاقه به پردازش زبان طبیعی است که افراد خوب را با مشاغل خوب مطابقت می دهد.
 عبدالنور بزوح یک مدیر اجرایی با بیش از 25 سال تجربه در ساخت و ارائه راه حل های فناوری که به میلیون ها مشتری می رسد. عبدنور سمت مدیر ارشد فناوری (CTO) را در اختیار داشت Talent.com زمانی که تیم AWS این راه حل خاص را برای آن طراحی و اجرا کرد Talent.com.
عبدالنور بزوح یک مدیر اجرایی با بیش از 25 سال تجربه در ساخت و ارائه راه حل های فناوری که به میلیون ها مشتری می رسد. عبدنور سمت مدیر ارشد فناوری (CTO) را در اختیار داشت Talent.com زمانی که تیم AWS این راه حل خاص را برای آن طراحی و اجرا کرد Talent.com.
 دیل ژاک یک استراتژیست ارشد هوش مصنوعی در مرکز نوآوری هوش مصنوعی مولد است که در آن به مشتریان AWS کمک می کند تا مشکلات تجاری را به راه حل های هوش مصنوعی ترجمه کنند.
دیل ژاک یک استراتژیست ارشد هوش مصنوعی در مرکز نوآوری هوش مصنوعی مولد است که در آن به مشتریان AWS کمک می کند تا مشکلات تجاری را به راه حل های هوش مصنوعی ترجمه کنند.
 یانجون چی مدیر ارشد علوم کاربردی در آزمایشگاه راه حل یادگیری ماشین آمازون است. او برای کمک به مشتریان AWS برای سرعت بخشیدن به هوش مصنوعی و پذیرش ابری خود، نوآوری می کند و از یادگیری ماشینی استفاده می کند.
یانجون چی مدیر ارشد علوم کاربردی در آزمایشگاه راه حل یادگیری ماشین آمازون است. او برای کمک به مشتریان AWS برای سرعت بخشیدن به هوش مصنوعی و پذیرش ابری خود، نوآوری می کند و از یادگیری ماشینی استفاده می کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/from-text-to-dream-job-building-an-nlp-based-job-recommender-at-talent-com-with-amazon-sagemaker/

