Amazon SageMaker Autopilot، یک سرویس یادگیری ماشینی با کد پایین (ML) که به طور خودکار بهترین مدل های ML را بر اساس داده های جدولی می سازد، آموزش می دهد و تنظیم می کند، اکنون با خطوط لوله آمازون SageMaker، اولین سرویس یکپارچه سازی مداوم و تحویل مداوم (CI/CD) برای ML ساخته شده است. این امکان اتوماسیون یک جریان سرتاسری از ساخت مدلهای ML را با استفاده از Autopilot و ادغام مدلها در مراحل بعدی CI/CD فراهم میکند.
تاکنون، برای راهاندازی یک آزمایش Autopilot در Pipelines، باید با نوشتن کد یکپارچهسازی سفارشی با Pipelines، یک گردش کار ساخت مدل ایجاد کنید. یازدهمین حرف الفبای یونانی or پردازش مراحل برای اطلاعات بیشتر ببین انتقال مدلهای Amazon SageMaker Autopilot ML از آزمایش به تولید با استفاده از خطوط لوله Amazon SageMaker.
با پشتیبانی از Autopilot به عنوان یک مرحله بومی در Pipelines، اکنون می توانید یک مرحله آموزش خودکار اضافه کنید (AutoMLStep) در Pipelines و فراخوانی آزمایش Autopilot با حالت آموزش ترکیبی. برای مثال، اگر در حال ایجاد یک گردش کار آموزشی و ارزیابی ML برای یک مورد استفاده از کشف تقلب با Pipelines هستید، اکنون می توانید یک آزمایش Autopilot را با استفاده از مرحله AutoML راه اندازی کنید، که به طور خودکار چندین آزمایش را برای یافتن بهترین مدل در یک مجموعه داده ورودی داده شده اجرا می کند. . پس از ایجاد بهترین مدل با استفاده از مرحله مدل، عملکرد آن را می توان بر روی داده های تست با استفاده از مرحله تبدیل و یک مرحله پردازش برای یک اسکریپت ارزیابی سفارشی در Pipelines. در نهایت، مدل را می توان با استفاده از رجیستری مدل SageMaker ثبت کرد مرحله مدل در ترکیب با مرحله شرط.
در این پست، نحوه ایجاد یک گردش کار ML سرتاسر برای آموزش و ارزیابی یک مدل ML تولید شده SageMaker با استفاده از مرحله AutoML تازه راه اندازی شده در Pipelines و ثبت آن در رجیستری مدل SageMaker را نشان می دهیم. مدل ML با بهترین عملکرد را می توان در یک نقطه پایانی SageMaker مستقر کرد.
نمای کلی مجموعه داده
ما از در دسترس عموم استفاده می کنیم مجموعه داده درآمد سرشماری بزرگسالان UCI 1994 برای پیش بینی اینکه آیا یک فرد درآمد سالانه بیش از 50,000 دلار در سال دارد یا خیر. این یک مشکل طبقه بندی باینری است. گزینه های متغیر هدف درآمد یا <=50K یا >50K هستند.
مجموعه داده شامل 32,561 ردیف برای آموزش و اعتبار سنجی و 16,281 ردیف برای آزمایش با 15 ستون است. این شامل اطلاعات جمعیت شناختی افراد و class به عنوان ستون هدف که طبقه درآمد را نشان می دهد.
| نام ستون | توضیحات: |
| سن | مداوم |
| کلاس کاری | خصوصی، Self-emp-not-inc، Self-emp-inc، دولت فدرال، دولت محلی، ایالتی، بدون حقوق، هرگز کار نکرده |
| fnlwgt | مداوم |
| تحصیلات | لیسانس، چند کالج، یازدهم، HS-grad، پروفسور مدرسه، Assoc-acdm، Assoc-voc، 11، 9-7، 8، کارشناسی ارشد، 12-1، 4، دکترا، 10-5، پیش دبستانی |
| آموزش و پرورش | مداوم |
| وضعیت تاهل | متاهل-مدنی-همسر، طلاق، هرگز ازدواج نکرده، جدا شده، بیوه، متاهل-همسر-غایب، متاهل-اف-همسر |
| اشغال | پشتیبانی فنی، تعمیرات صنایع دستی، خدمات دیگر، فروش، مدیریت اجرایی، تخصص حرفه ای، گرداننده-پاک کننده، بازرسی ماشین آلات، کارمند اداری، کشاورزی-ماهیگیری، حمل و نقل، خدمات خانه خصوصی، خدمات حفاظتی، نیروهای مسلح |
| ارتباط | همسر، فرزند خود، شوهر، غیر فامیل، دیگر بستگان، مجرد |
| نژاد | سفید، آسیایی-پاک-جزیره، آمر-هند-اسکیمو، دیگر، سیاه |
| ارتباط جنسی | زن، مرد |
| سود سرمایه | مداوم |
| سرمایه-زیان | مداوم |
| ساعت در هفته | مداوم |
| کشور مادری | ایالات متحده، کامبوج، انگلستان، پورتوریکو، کانادا، آلمان، ایالات متحده (گوام-USVI-و غیره)، هند، ژاپن، یونان، جنوب، چین، کوبا، ایران، هندوراس، فیلیپین، ایتالیا، لهستان، جامائیکا ، ویتنام، مکزیک، پرتغال، ایرلند، فرانسه، جمهوری دومینیکن، لائوس، اکوادور، تایوان، هائیتی، کلمبیا، مجارستان، گواتمالا، نیکاراگوئه، اسکاتلند، تایلند، یوگسلاوی، السالوادور، تریناداد و توباگو، پرو، هنگ، هلند-هلند |
| کلاس | طبقه درآمد، یا <=50K یا >50K |
بررسی اجمالی راه حل
ما از Pipelines برای هماهنگی متفاوت استفاده می کنیم مراحل خط لوله برای آموزش مدل اتوپایلوت مورد نیاز است. ما یک را ایجاد و اجرا می کنیم آزمایش خلبان خودکار به عنوان بخشی از مرحله AutoML همانطور که در این آموزش توضیح داده شده است.
مراحل زیر برای این فرآیند آموزش سرپایی Autopilot مورد نیاز است:
- ایجاد و نظارت بر کار آموزش خلبان خودکار با استفاده از
AutoMLStep. - با استفاده از یک مدل SageMaker ایجاد کنید
ModelStep. این مرحله بهترین متادیتا و مصنوعات مدل را که توسط Autopilot در مرحله قبل ارائه شده است، واکشی می کند. - مدل Autopilot آموزش دیده را بر روی مجموعه داده آزمایشی با استفاده از ارزیابی کنید
TransformStep. - خروجی را از اجرای قبلی مقایسه کنید
TransformStepبا استفاده از برچسب های هدف واقعیProcessingStep. - ثبت نام مدل ML به رجیستری مدل SageMaker با استفاده از
ModelStep، اگر متریک ارزیابی قبلی به دست آمده از یک آستانه از پیش تعریف شده فراتر رودConditionStep. - از مدل ML به عنوان نقطه پایانی SageMaker برای اهداف آزمایشی استفاده کنید.
معماری
نمودار معماری زیر مراحل مختلف خط لوله لازم برای بسته بندی تمام مراحل در یک خط لوله آموزشی SageMaker Autopilot قابل تکرار، خودکار و مقیاس پذیر را نشان می دهد. فایل های داده از سطل S3 خوانده می شوند و مراحل خط لوله به ترتیب فراخوانی می شوند.
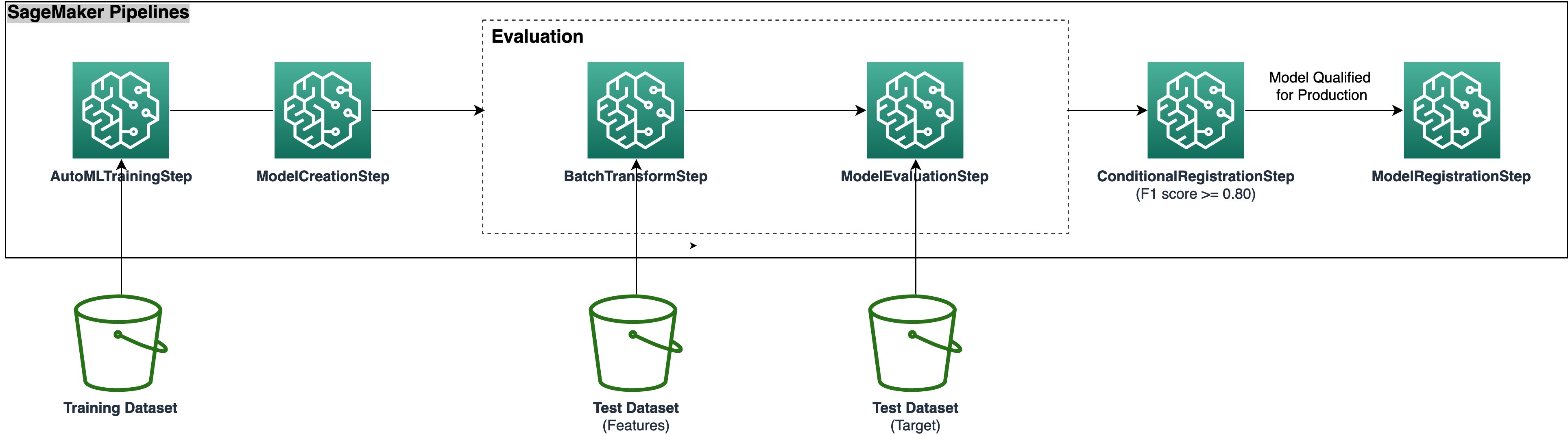
خرید
در این پست توضیحات مفصلی در مورد مراحل خط لوله ارائه شده است. ما کد را بررسی می کنیم و اجزای هر مرحله را مورد بحث قرار می دهیم. برای استقرار راه حل، به نمونه دفترچه یادداشت، که دستورالعمل های گام به گام برای پیاده سازی گردش کار Autopilot MLOps با استفاده از Pipelines را ارائه می دهد.
پیش نیازها
پیش نیازهای زیر را کامل کنید:
هنگامی که مجموعه داده آماده استفاده است، باید Pipelines را راهاندازی کنیم تا فرآیندی تکرارپذیر برای ساخت و آموزش خودکار مدلهای ML با استفاده از Autopilot ایجاد کنیم. ما استفاده می کنیم SageMaker SDK برای تعریف، اجرا و ردیابی برنامهریزی یک خط لوله آموزشی ML سرتاسر.
مراحل خط لوله
در بخشهای بعدی، مراحل مختلف خط لوله SageMaker از جمله آموزش AutoML، ایجاد مدل، استنتاج دستهای، ارزیابی و ثبت شرطی بهترین مدل را مرور میکنیم. نمودار زیر کل جریان خط لوله را نشان می دهد.
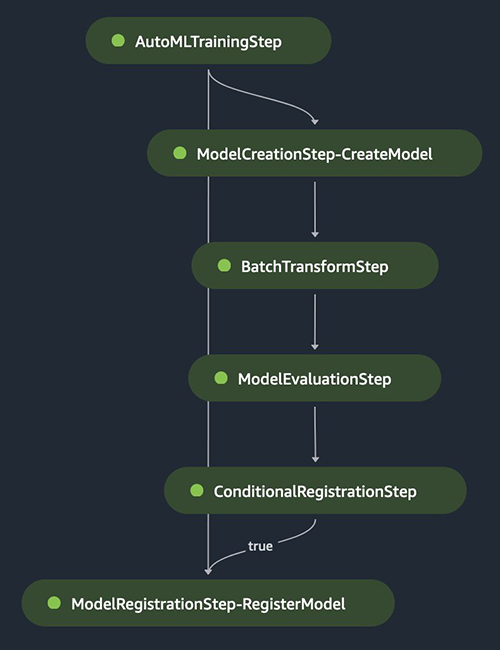
مرحله آموزش AutoML
An شی AutoML برای تعریف اجرای کار آموزشی Autopilot استفاده می شود و می توان با استفاده از آن به خط لوله SageMaker اضافه کرد AutoMLStep کلاس، همانطور که در کد زیر نشان داده شده است. حالت آموزش گروه بندی باید مشخص شود، اما سایر پارامترها را می توان در صورت نیاز تنظیم کرد. به عنوان مثال، به جای اینکه اجازه دهید کار AutoML به طور خودکار ML را استنتاج کند نوع مشکل و متریک هدف، این ها را می توان با مشخص کردن کد هاردکد کرد problem_type و job_objective پارامترها به شی AutoML منتقل می شوند.
مرحله ایجاد مدل
مرحله AutoML به تولید نامزدهای مدل ML مختلف، ترکیب آنها و به دست آوردن بهترین مدل ML می پردازد. مصنوعات و ابردادههای مدل بهطور خودکار ذخیره میشوند و میتوان با فراخوانی آن را دریافت کرد get_best_auto_ml_model() روش در مرحله آموزش AutoML. سپس می توان از آنها برای ایجاد یک مدل SageMaker به عنوان بخشی از مرحله Model استفاده کرد:
مراحل تبدیل دسته ای و ارزیابی
ما با استفاده از شی ترانسفورماتور برای استنتاج دسته ای در مجموعه داده آزمایشی، که سپس می تواند برای اهداف ارزیابی استفاده شود. پیشبینیهای خروجی با برچسبهای حقیقت واقعی یا زمینی با استفاده از تابع متریک Scikit-learn مقایسه میشوند. ما نتایج خود را بر اساس ارزیابی می کنیم امتیاز F1. معیارهای عملکرد در یک فایل JSON ذخیره میشوند که هنگام ثبت مدل در مرحله بعدی به آن ارجاع داده میشود.
مراحل ثبت نام مشروط
در این مرحله، اگر از آستانه ارزیابی از پیش تعریف شده فراتر رود، مدل Autopilot جدید خود را در رجیستری مدل SageMaker ثبت می کنیم.
خط لوله را ایجاد و اجرا کنید
پس از تعریف مراحل، آنها را در یک خط لوله SageMaker ترکیب می کنیم:
مراحل به ترتیب متوالی اجرا می شوند. خط لوله تمام مراحل یک کار AutoML را با استفاده از Autopilot و Pipelines برای آموزش، ارزیابی مدل و ثبت مدل اجرا می کند.
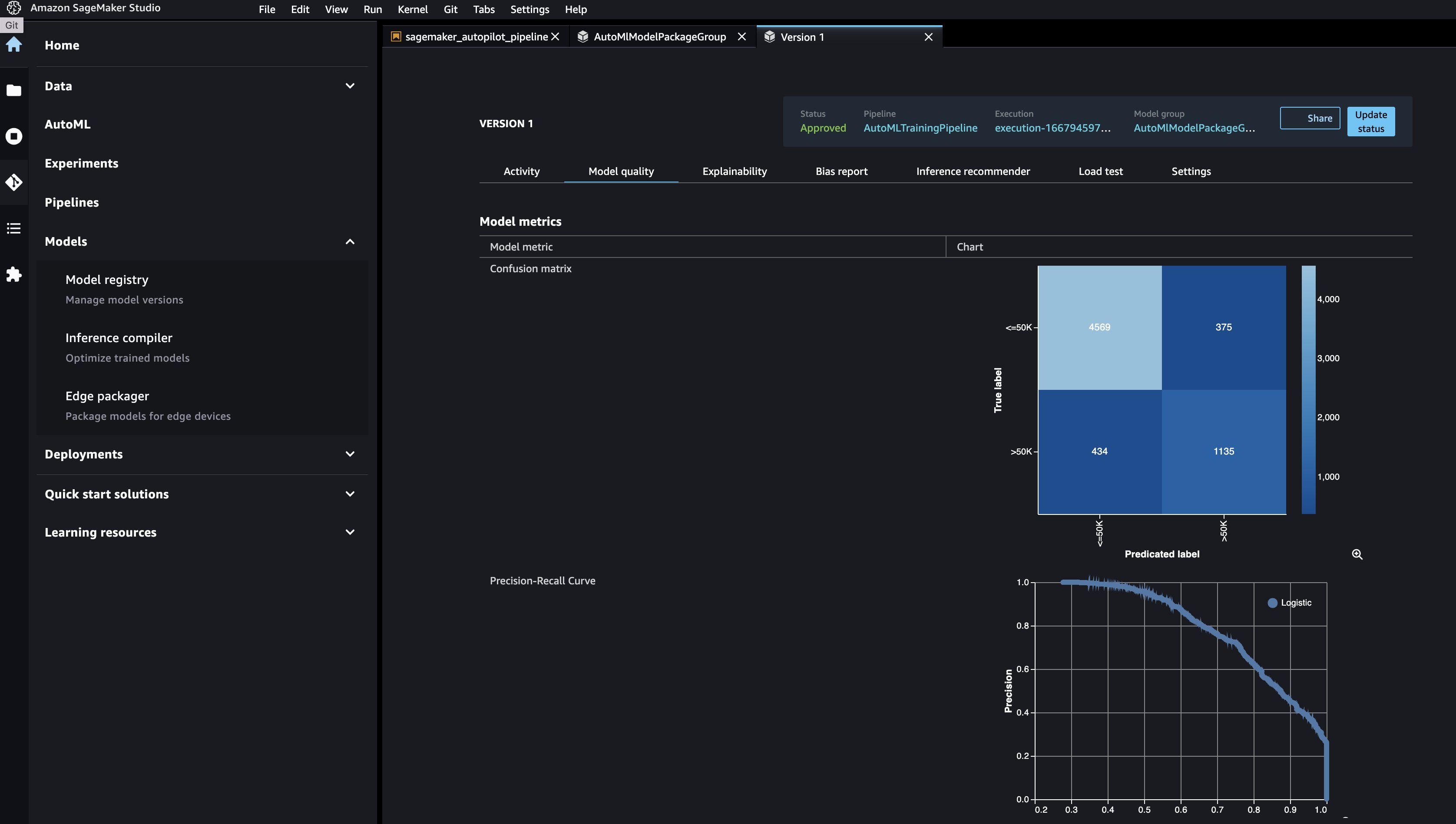
با رفتن به رجیستری مدل در کنسول استودیو و باز کردن آن، می توانید مدل جدید را مشاهده کنید AutoMLModelPackageGroup. هر نسخه از یک کار آموزشی را برای مشاهده معیارهای هدف در آن انتخاب کنید کیفیت مدل تب.
می توانید گزارش توضیح پذیری را در مورد مشاهده کنید قابل توضیح برای درک پیشبینیهای مدل خود، را انتخاب کنید.
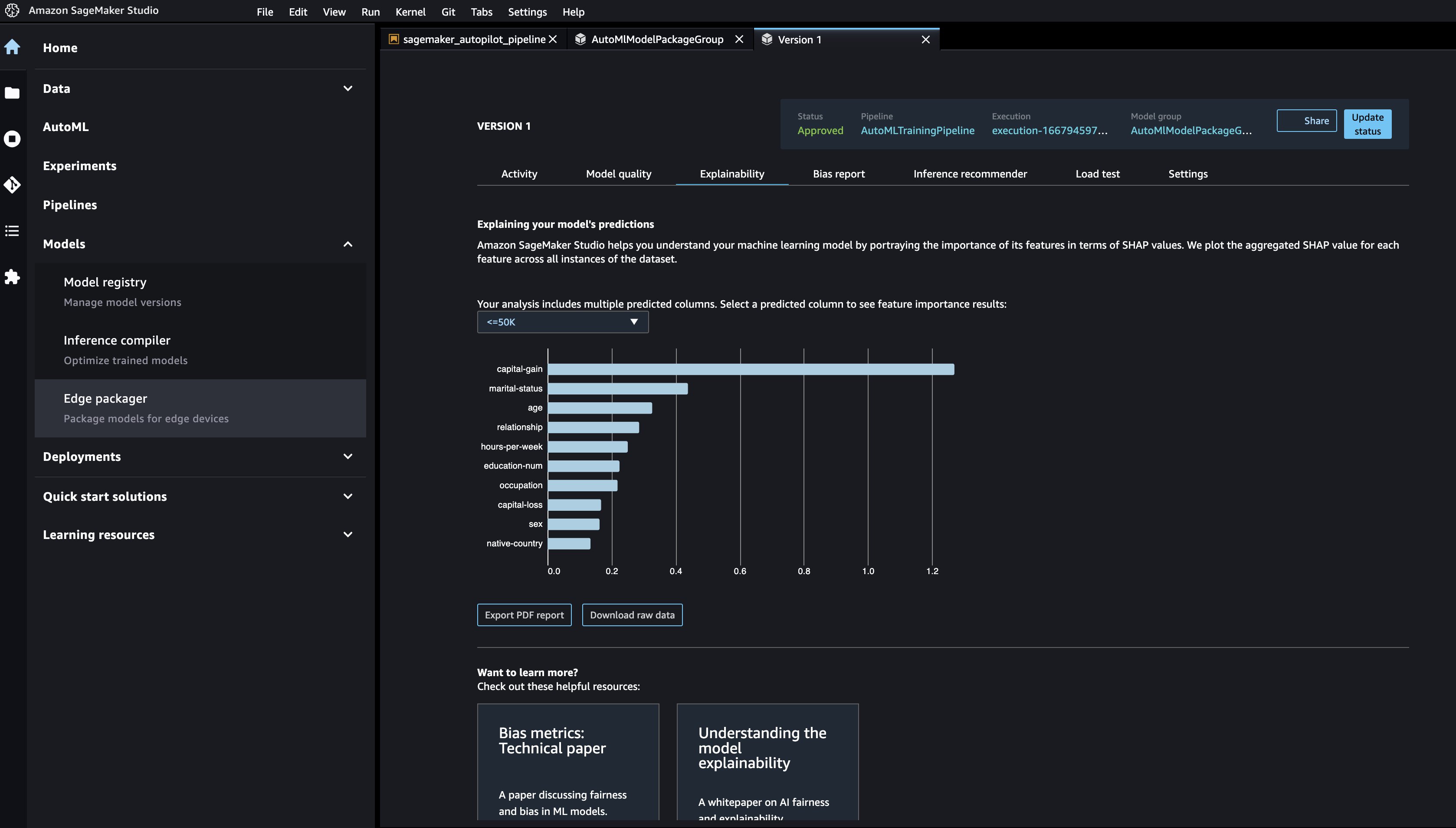
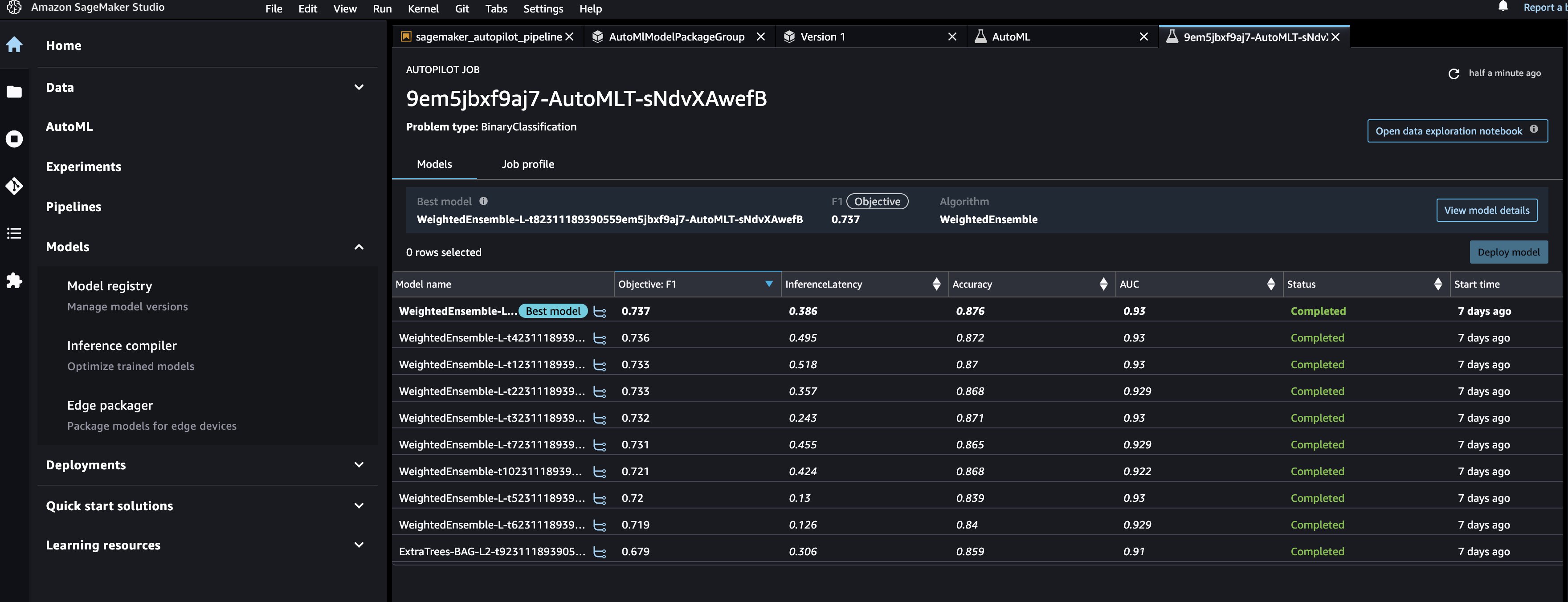
برای مشاهده آزمایش Autopilot زیربنایی برای همه مدلهای ایجاد شده در AutoMLStep، به مسیر خودکار کردن صفحه و نام شغل را انتخاب کنید.
مدل را مستقر کنید
پس از بررسی دستی عملکرد مدل ML، می توانیم مدل جدید ایجاد شده خود را در نقطه پایانی SageMaker مستقر کنیم. برای این کار، میتوانیم سلولهایی را در نوتبوک اجرا کنیم که نقطه پایانی مدل را با استفاده از پیکربندی مدل ذخیرهشده در رجیستری مدل SageMaker ایجاد میکنند.
توجه داشته باشید که این اسکریپت برای اهداف نمایشی به اشتراک گذاشته شده است، اما توصیه می شود برای استقرار تولید برای استنتاج ML از خط لوله CI/CD قوی تری پیروی کنید. برای اطلاعات بیشتر مراجعه کنید ساخت، خودکارسازی، مدیریت و مقیاسبندی گردشهای کاری ML با استفاده از خطوط لوله آمازون SageMaker.
خلاصه
این پست یک رویکرد خط لوله ML با استفاده آسان را برای آموزش خودکار مدلهای ML جدولی (AutoML) با استفاده از Autopilot، Pipelines و Studio شرح میدهد. AutoML کارایی متخصصان ML را بهبود می بخشد و مسیر از آزمایش ML تا تولید را بدون نیاز به تخصص گسترده ML تسریع می بخشد. ما مراحل خط لوله مربوطه مورد نیاز برای ایجاد، ارزیابی و ثبت مدل ML را بیان می کنیم. با امتحان کردن شروع کنید نمونه دفترچه یادداشت برای آموزش و استقرار مدل های AutoML سفارشی خود.
برای کسب اطلاعات بیشتر در مورد Autopilot و Pipelines، مراجعه کنید توسعه مدل را با Amazon SageMaker Autopilot به صورت خودکار انجام دهید و خطوط لوله آمازون SageMaker.
تشکر ویژه از همه کسانی که در راه اندازی شرکت کردند: Shenghua Yue، John He، Ao Guo، Xinlu Tu، Tian Qin، Yanda Hu، Zhankui Lu و Dewen Qi.
درباره نویسنده
 جانیشا آناند یک مدیر محصول ارشد در تیم SageMaker Low/No Code ML است که شامل SageMaker Autopilot است. او از قهوه، فعال ماندن و گذراندن وقت با خانواده اش لذت می برد.
جانیشا آناند یک مدیر محصول ارشد در تیم SageMaker Low/No Code ML است که شامل SageMaker Autopilot است. او از قهوه، فعال ماندن و گذراندن وقت با خانواده اش لذت می برد.
 مارسلو آبرله مهندس ML در AWS AI است. او کمک میکند آزمایشگاه راه حل های آمازون ام ال مشتریان سیستم ها و چارچوب های مقیاس پذیر ML(-Ops) می سازند. او در اوقات فراغت خود از پیاده روی و دوچرخه سواری در منطقه خلیج سانفرانسیسکو لذت می برد.
مارسلو آبرله مهندس ML در AWS AI است. او کمک میکند آزمایشگاه راه حل های آمازون ام ال مشتریان سیستم ها و چارچوب های مقیاس پذیر ML(-Ops) می سازند. او در اوقات فراغت خود از پیاده روی و دوچرخه سواری در منطقه خلیج سانفرانسیسکو لذت می برد.
 گرمی کوهن یک معمار راه حل با AWS است که در آن به مشتریان کمک می کند تا راه حل های پیشرفته و مبتنی بر ابر بسازند. او در اوقات فراغت خود از پیادهروی کوتاه در ساحل، کاوش در منطقه خلیج با خانوادهاش، تعمیر وسایل اطراف خانه، شکستن وسایل اطراف خانه و باربیکیو لذت میبرد.
گرمی کوهن یک معمار راه حل با AWS است که در آن به مشتریان کمک می کند تا راه حل های پیشرفته و مبتنی بر ابر بسازند. او در اوقات فراغت خود از پیادهروی کوتاه در ساحل، کاوش در منطقه خلیج با خانوادهاش، تعمیر وسایل اطراف خانه، شکستن وسایل اطراف خانه و باربیکیو لذت میبرد.
 Shenghua Yue مهندس توسعه نرم افزار در Amazon SageMaker است. او بر ساخت ابزارها و محصولات ML برای مشتریان تمرکز دارد. در خارج از محل کار، او از فضای باز، یوگا و پیاده روی لذت می برد.
Shenghua Yue مهندس توسعه نرم افزار در Amazon SageMaker است. او بر ساخت ابزارها و محصولات ML برای مشتریان تمرکز دارد. در خارج از محل کار، او از فضای باز، یوگا و پیاده روی لذت می برد.
- Coinsmart. بهترین صرافی بیت کوین و کریپتو اروپا.اینجا کلیک کنید
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/launch-amazon-sagemaker-autopilot-experiments-directly-from-within-amazon-sagemaker-pipelines-to-easily-automate-mlops-workflows/

