See on külaliste ajaveebi postitus, mille on kirjutanud ettevõtte T and T Consulting Services, Inc. juhtiv andmeteadlane Nitin Kumar.
Selles postituses käsitleme liitõppe väärtust ja võimalikku mõju tervishoiuvaldkonnas. See lähenemisviis võib aidata südameinfarktiga patsientidel, arstidel ja teadlastel kiiremini diagnoosida, rikastada otsuseid ning teha teadlikumat ja kaasavat uurimistööd insuldiga seotud terviseprobleemide alal, kasutades pilvepõhist lähenemist AWS-i teenustega kergeks tõstmiseks ja lihtsaks kasutuselevõtuks. .
Südameinfarkti diagnoosimise väljakutsed
Statistika Centers for Disease Control ja ennetamine (CDC) näitavad, et igal aastal kannatab USA-s üle 795,000 25 inimese oma esimese insuldi ja umbes XNUMX% neist kogevad korduvaid haigushooge. See on surmapõhjus number viis Ameerika Insuldi Assotsiatsioon ja peamine puude põhjus USA-s. Seetõttu on ägeda insuldihaigete ajukahjustuse ja muude tüsistuste vähendamiseks ülioluline diagnoosida ja ravida kiiresti.
CT-d ja MRI-d on pildistamistehnoloogiate kuldstandardid erinevate insultide alatüüpide klassifitseerimisel ning on üliolulised patsientide esialgsel hindamisel, algpõhjuse määramisel ja ravimisel. Üheks kriitiliseks väljakutseks, eriti ägeda insuldi korral, on pildidiagnoosimise aeg, mis on keskmiselt vahemikus 30 minutit kuni tund ja see võib olla palju pikem, olenevalt erakorralise meditsiini osakonna rahvarohkest.
Arstid ja meditsiinitöötajad vajavad kiiret ja täpset pildidiagnoosi, et hinnata patsiendi seisundit ja pakkuda välja ravivõimalusi. Dr Werner Vogelsi enda sõnadega kl AWS re:Invent 2023, "Iga sekund, mil inimesel on insult, loeb." Insuldi ohvrid võivad kaotada ligikaudu 1.9 miljardit neuronit iga sekundiga, kui neid ei ravita.
Meditsiiniliste andmete piirangud
Saate kasutada masinõpet (ML), et aidata arste ja teadlasi diagnoosimisülesannete tegemisel, kiirendades sellega protsessi. ML-mudelite koostamiseks ja usaldusväärsete tulemuste saamiseks vajalikud andmekogumid asuvad aga erinevates tervishoiusüsteemides ja organisatsioonides silohoidlates. Need eraldatud pärandandmed võivad kumuleerimisel avaldada tohutut mõju. Miks seda siis veel kasutatud ei ole?
Meditsiinivaldkonna andmekogumitega töötamisel ja ML-lahenduste loomisel on mitmeid väljakutseid, sealhulgas patsientide privaatsus, isikuandmete turvalisus ning teatud bürokraatlikud ja poliitikapiirangud. Lisaks on teadusasutused karmistanud andmete jagamise tavasid. Need takistused takistavad ka rahvusvahelistel uurimisrühmadel töötamast koos mitmekülgsete ja rikkalike andmekogumite kallal, mis võib muuhulgas päästa elusid ja ennetada südameinfarktidest tulenevaid puudeid.
Eeskirjad ja eeskirjad nagu Andmekaitse üldmäärus (GDPR), Tervisekindlustuse ülekantavuse ja vastutuse seadus (HIPPA) ja California tarbija privaatsuse seadus (CCPA) seab kaitsepiirded meditsiinivaldkonna andmete, eriti patsientide andmete jagamisele. Lisaks on üksikute instituutide, organisatsioonide ja haiglate andmestikud sageli liiga väikesed, tasakaalustamata või kallutatud jaotustega, mis põhjustab mudeli üldistamise piiranguid.
Liitõpe: sissejuhatus
Födereeritud õpe (FL) on ML-i detsentraliseeritud vorm – dünaamiline insenerilähenemine. Selle detsentraliseeritud ML-lähenemise korral jagatakse ML-mudelit organisatsioonide vahel patenteeritud andmete alamhulkade koolituseks, erinevalt traditsioonilisest tsentraliseeritud ML-koolitusest, kus mudelit treenitakse üldiselt koondatud andmekogumitel. Andmed jäävad kaitstuks organisatsiooni tulemüüride või VPC taga, samal ajal kui mudelit koos selle metaandmetega jagatakse.
Koolitusfaasis levitatakse ja sünkroonitakse globaalset FL-mudelit üksuste organisatsioonide vahel individuaalsete andmekogumite koolituseks ning tagastatakse kohalik koolitatud mudel. Lõplik globaalne mudel on saadaval ennustuste tegemiseks kõigi osalejate jaoks ja seda saab kasutada ka täiendkoolituse alusena, et luua osalevate organisatsioonide jaoks kohalikke kohandatud mudeleid. Seda saab veelgi laiendada, et saada kasu teistele instituutidele. Selline lähenemine võib oluliselt vähendada edastatavate andmete küberturvalisuse nõudeid, kuna kaob vajadus andmete edastamiseks väljaspool organisatsiooni piire.
Järgmine diagramm illustreerib arhitektuuri näidet.
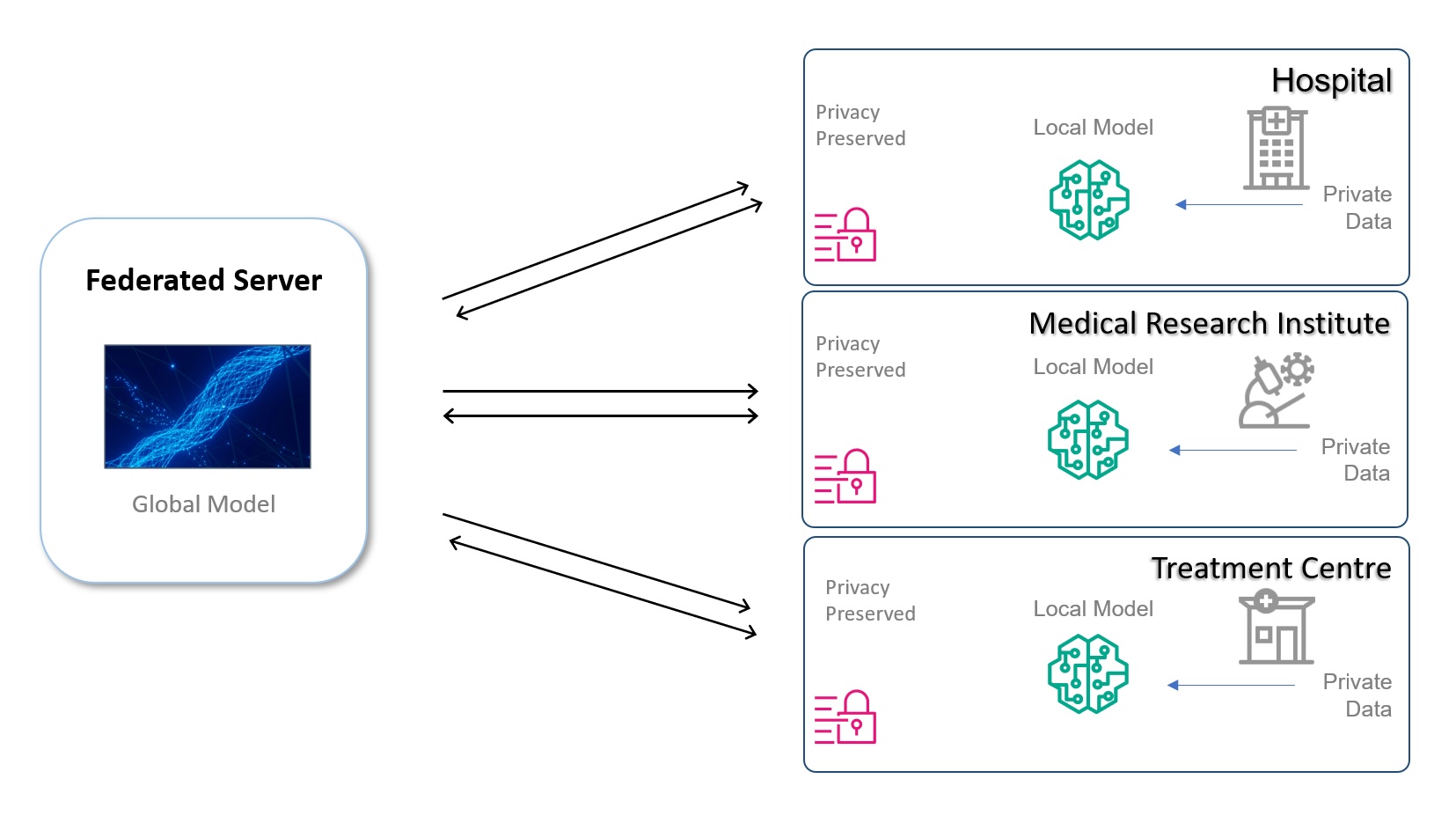
Järgmistes osades arutame, kuidas liitõpe võib aidata.
Föderatsioon õpib päästma päeva (ja päästma elusid)
Hea tehisintellekti (AI) jaoks on vaja häid andmeid.
Pärandsüsteemid, mida sageli leidub föderaalses domeenis, tekitavad olulisi andmetöötlusprobleeme, enne kui saate luureandmeid hankida või liita need uuemate andmekogumitega. See on takistuseks juhtidele väärtusliku luureandmete pakkumisel. See võib viia ebatäpsete otsuste tegemiseni, kuna pärandandmete osakaal on mõnikord palju väärtuslikum võrreldes uuema väikese andmestikuga. Soovite selle kitsaskoha tõhusalt lahendada ilma haiglates ja instituutides asuvate pärand- ja uuemate andmekogumite käsitsi konsolideerimise ja integreerimise töökoormuseta (sealhulgas tülikate kaardistamisprotsessideta), mis võib paljudel juhtudel võtta mitu kuud, kui mitte aastaid. Pärandandmed on üsna väärtuslikud, kuna need sisaldavad olulist kontekstuaalset teavet, mis on vajalik täpsete otsuste tegemiseks ja hästi informeeritud mudelikoolituseks, mis toob kaasa usaldusväärse tehisintellekti reaalses maailmas. Andmete kestus annab teavet andmekogumi pikaajaliste variatsioonide ja mustrite kohta, mis muidu jääksid avastamata ja viiksid kallutatud ja halvasti informeeritud prognoosideni.
Nende andmehoidlate jagamine, et ühendada hajutatud andmete kasutamata potentsiaal, võib päästa ja muuta paljusid elusid. Samuti võib see kiirendada südameinfarktidest tulenevate teiseste terviseprobleemidega seotud uuringuid. See lahendus aitab teil jagada teadmisi andmetest, mis on eraldatud instituutide vahel poliitika või muude põhjuste tõttu, olenemata sellest, kas olete haigla, uurimisinstituut või mõni muu terviseandmetele keskenduv organisatsioon. See võib võimaldada teadlikke otsuseid uurimissuuna ja diagnoosimise kohta. Lisaks annab see turvalise, privaatse ja globaalse teadmistebaasi kaudu luureandmete tsentraliseeritud hoidla.

Liitõppel on palju eeliseid üldiselt ja konkreetselt meditsiiniandmete seadete jaoks.
Turva- ja privaatsusfunktsioonid:
- Hoiab tundlikud andmed Internetist eemal ja kasutab neid endiselt ML-i jaoks ning kasutab oma luureandmeid erineva privaatsusega
- Võimaldab luua, koolitada ja juurutada erapooletuid ja töökindlaid mudeleid mitte ainult masinates, vaid ka võrkudes ilma andmeturbe ohtudeta
- Ületab tõkked, kui andmeid haldab mitu tarnijat
- Kõrvaldab vajaduse saidiülese andmete jagamise ja globaalse juhtimise järele
- Säilitab privaatsuse erineva privaatsusega ja pakub turvalist mitme osapoole arvutust koos kohaliku koolitusega
Toimivuse täiustused:
- Lahendab väikese valimi suuruse probleemi meditsiinilise pildistamise ruumis ja kulukaid märgistamisprotsesse
- Tasakaalustab andmete jaotust
- Võimaldab kasutada enamikke traditsioonilisi ML ja süvaõppe (DL) meetodeid
- Kasutab koondatud pildikomplekte, et aidata parandada statistilist võimsust, ületades üksikute asutuste valimi suuruse piirangu
Vastupidavuse eelised:
- Kui mõni osapool otsustab lahkuda, ei takista see koolitust
- Uus haigla või instituut võib liituda igal ajal; see ei sõltu ühegi sõlmeorganisatsiooni konkreetsest andmekogumist
- Laialt levinud geograafilistesse asukohtadesse hajutatud pärandandmete jaoks pole vaja ulatuslikke andmetöötluse torujuhtmeid
Need funktsioonid võivad aidata langetada seinu sarnastel domeenidel eraldatud andmekogumeid hostivate asutuste vahel. Lahendus võib muutuda jõu kordajaks, rakendades hajutatud andmekogumite ühtseid jõude ja parandades tõhusust, muutes mastaapsuse aspekti radikaalselt ilma raske infrastruktuuri tõstmiseta. See lähenemine aitab ML-l saavutada oma täieliku potentsiaali, saades oskuslikuks kliinilisel tasemel, mitte ainult teadustöös.
Liitõppe jõudlus on võrreldav tavalise ML-ga, nagu on näidatud järgmises eksperiment autor NVidia Clara (Medical Modal ARchive'is (MMAR), kasutades BRATS2018 andmestikku). Siin saavutas FL võrreldava segmenteerimistulemuse võrreldes tsentraliseeritud andmetega treenimisega: üle 80% ligikaudu 600 epohhiga, treenides mitmeliigilise ja mitme klassi ajukasvaja segmenteerimise ülesannet.
Liitõpet on hiljuti testitud mõnes meditsiini alamvaldkonnas kasutusjuhtumite jaoks, sealhulgas patsientide sarnasuse õppimine, patsiendi esitusõpe, fenotüüpimine ja ennustav modelleerimine.
Rakenduse plaan: liitõpe teeb selle võimalikuks ja lihtsaks
FL-iga alustamiseks saate valida paljude kvaliteetsete andmekogumite hulgast. Näiteks ajupiltidega andmekogumid hõlmavad PIDEGE (Autism Brain Imaging Data Exchange algatus), ADNI (Alzheimeri tõve neuroimaging algatus), RSNA (Põhja-Ameerika Radioloogiaühing) Aju CT, BraTS (multimodaalse ajukasvaja kujutise segmenteerimise võrdlusnäitaja), mida värskendatakse regulaarselt ajukasvaja segmenteerimise väljakutse raames. UPenn (Pennsylvania Ülikool), Ühendkuningriigi BioBank (kaetud järgmises NIH-s). paber), Ja XI. Sarnaselt südamepiltide puhul saate valida mitme avalikult kättesaadava valiku hulgast, sealhulgas ACDC (Automatic Cardiac Diagnosis Challenge), mis on südame MRI hindamise andmestik koos täieliku annotatsiooniga, mida mainib National Library of Medicine allpool. paberja M&M (mitmekeskuseline, mitme tarnija ja mitme haigusega) südame segmenteerimise väljakutse, mida on mainitud järgmises IEEE paberile.
Järgmised pildid näitavad a ATLAS R1.1 andmestiku primaarsete kahjustuste tõenäosuslik kahjustuste kattumise kaart. (Insult on üks levinumaid ajukahjustuste põhjuseid Cleveland Clinic.)

Elektrooniliste tervisekaartide (EHR) andmete jaoks on saadaval mõned andmestikud, mis järgivad Kiire tervishoiu koostalitlusvõime ressursid (FHIR) standard. See standard aitab teil luua lihtsaid pilootprojekte, kõrvaldades teatud väljakutsed heterogeensete, normaliseerimata andmekogumitega, võimaldades andmekogude sujuvat ja turvalist vahetamist, jagamist ja integreerimist. FHIR võimaldab maksimaalset koostalitlusvõimet. Andmekogumi näited hõlmavad MIMIK-IV (Meditsiinilise teabe Mart intensiivravi jaoks). Muud kvaliteetsed andmestikud, mis ei ole praegu FHIR, kuid mida saab hõlpsasti teisendada, hõlmavad Medicare'i ja Medicaidi teenuste keskused (CMS) avaliku kasutusega failid (PUF) ja eICU koostööuuringute andmebaas MIT-st (Massachusettsi Tehnoloogiainstituut). Saadaval on ka muid ressursse, mis pakuvad FHIR-põhiseid andmekogumeid.
FL-i juurutamise elutsükkel võib hõlmata järgmist samme: ülesannete lähtestamine, valik, konfigureerimine, mudeli koolitus, kliendi/serveri suhtlus, ajakava ja optimeerimine, versioonide loomine, testimine, juurutamine ja lõpetamine. Traditsioonilise ML-i jaoks meditsiinilise kujutise andmete ettevalmistamiseks on palju aeganõudvaid samme, nagu on kirjeldatud allpool paber. Teatud stsenaariumide puhul võib patsiendi töötlemata andmete eeltöötlemiseks vaja minna valdkonnateadmisi, eriti nende tundliku ja privaatse olemuse tõttu. Neid saab FL-i jaoks koondada ja mõnikord ka kõrvaldada, säästes olulist treeninguaega ja andes kiiremaid tulemusi.
Täitmine
FL-i tööriistad ja raamatukogud on laialdase toega kasvanud, muutes FL-i kasutamise lihtsaks ilma raske tõstukita. Alustamiseks on saadaval palju häid ressursse ja raamistiku valikuid. Võite viidata järgmisele ulatuslik nimekiri FL domeeni kõige populaarsematest raamistikest ja tööriistadest, sealhulgas PySyft, FedML, Lill, OpenFL, FATE, TensorFlow Federatedja NVFlare. See pakub algajatele mõeldud projektide loendit, mida saab kiiresti alustada ja millele edasi arendada.
Saate rakendada pilvepõhist lähenemisviisi Amazon SageMaker mis töötab sujuvalt AWS VPC peering, hoides iga sõlme koolitust vastava VPC privaatses alamvõrgus ja võimaldades sidet privaatsete IPv4-aadresside kaudu. Lisaks on mudelimajutus sisse lülitatud Amazon SageMaker JumpStart võib aidata, paljastades lõpp-punkti API ilma mudelikaalu jagamata.
Samuti eemaldab see kohapealse riistvaraga seotud võimalikud kõrgetasemelised arvutusprobleemid Amazon Elastic Compute Cloud (Amazon EC2) ressursse. Saate rakendada FL-klienti ja servereid AWS-is koos SageMakeri märkmikud ja Amazoni lihtne salvestusteenus (Amazon S3), säilitage reguleeritud juurdepääs andmetele ja mudeliga AWS-i identiteedi- ja juurdepääsuhaldus (IAM) rollid ja kasutamine AWS-i turvamärgi teenus (AWS STS) kliendipoolse turvalisuse tagamiseks. Samuti saate Amazon EC2 abil luua oma kohandatud süsteemi FL-i jaoks.
Üksikasjaliku ülevaate saamiseks FL-i rakendamisest koos Lill SageMakeri raamistik ja arutelu selle erinevusest hajutatud koolitusest, vaadake Masinõpe detsentraliseeritud koolitusandmetega, kasutades Amazon SageMakeri liitõpet.
Järgmised joonised illustreerivad siirdeõppe arhitektuuri FL-is.

FL-andmete väljakutsetega tegelemine
Liitõppega kaasnevad oma andmeprobleemid, sealhulgas privaatsus ja turvalisus, kuid nendega on lihtne tegeleda. Esiteks peate tegelema andmete heterogeensuse probleemiga meditsiiniliste kujutiste andmetega, mis tulenevad erinevatest saitidest ja osalevatest organisatsioonidest salvestatud andmetest. domeeni nihe probleem (nimetatakse ka kui kliendivahetus FL-süsteemis), nagu Guan ja Liu on järgnevalt esile tõstnud paber. See võib kaasa tuua erinevuse globaalse mudeli lähenemises.
Muude kaalumistega komponentide hulka kuuluvad andmete kvaliteedi ja ühtsuse tagamine allika juures, ekspertteadmiste kaasamine õppeprotsessi, et tekitada meditsiinitöötajate seas usaldust süsteemi vastu, ja mudeli täpsuse saavutamine. Lisateavet mõnede võimalike väljakutsete kohta, millega võite rakendamisel kokku puutuda, vaadake järgmist paber.
AWS aitab teil neid probleeme lahendada selliste funktsioonidega nagu Amazon EC2 paindlik ja eelehitatud arvutus Dockeri pildid SageMakeris lihtsaks juurutamiseks. Saate lahendada iga sõlme organisatsiooni kliendipoolsed probleemid, nagu tasakaalustamata andmed ja arvutusressursid. Saate lahendada serveripoolseid õppeprobleeme, näiteks pahatahtlike osapoolte mürgistusrünnakuid Amazoni virtuaalne privaatpilv (Amazon VPC), turvarühmadja muud turbestandardid, mis takistavad klientide korruptsiooni ja rakendavad AWS-i anomaaliate tuvastamise teenuseid.
AWS aitab lahendada ka reaalseid rakendusprobleeme, mis võivad hõlmata integratsiooniprobleeme, ühilduvusprobleeme praeguste või vanade haiglasüsteemidega ja kasutajate kasutuselevõtu tõkkeid, pakkudes paindlikke, hõlpsasti kasutatavaid ja lihtsaid tõstetehnoloogia lahendusi.
AWS-i teenustega saate lubada suuremahulisi FL-põhiseid uuringuid ning kliinilist juurutamist ja juurutamist, mis võib koosneda erinevatest saitidest üle kogu maailma.
Hiljutised koostalitlusvõime poliitikad rõhutavad liitõppe vajadust
Paljud valitsuse hiljuti vastu võetud seadused keskenduvad andmete koostalitlusvõimele, suurendades vajadust andmete organisatsioonidevahelise koostalitlusvõime järele luureks. Seda saab täita kasutades FL-i, sealhulgas raamistikke nagu TEFCA (Usaldusväärse börsi raamistik ja ühine kokkulepe) ja laiendatud USCDI (Ameerika Ühendriikide koostalitlusvõime põhiandmed).
Väljapakutud idee aitab kaasa ka CDC püüdmise ja levitamise algatusele CDC liigub edasi. Järgmine tsitaat GovCIO artiklist Andmete jagamine ja tehisintellekt on föderaalse tervishoiuagentuuri peamised prioriteedid 2024. aastal kordab ka sarnast teemat: „Need võimalused võivad ka avalikkust õiglasel viisil toetada, kohtudes patsientidega seal, kus nad on ja avades neile teenustele kriitilise juurdepääsu. Suur osa sellest tööst taandub andmetele.
See võib andmehoidlate abil aidata meditsiiniinstituute ja agentuure üle kogu riigi (ja kogu maailmas). Nad saavad kasu sujuvast ja turvalisest integreerimisest ja andmete koostalitlusvõimest, muutes meditsiinilised andmed kasutatavaks mõjusate ML-põhiste prognooside ja mustrite tuvastamise jaoks. Alustada võib piltidest, kuid lähenemine on rakendatav ka kõikidele EHR-ile. Eesmärk on leida andmete sidusrühmade jaoks parim lähenemisviis, kasutades pilvepõhist konveieri andmete normaliseerimiseks ja standardiseerimiseks või otse FL-i kasutamiseks.
Uurime näidet kasutusjuhtumist. Südameinfarkti pildiandmed ja skaneeringud on üle riigi ja maailma laiali, isoleeritud silohoidlates instituutides, ülikoolides ja haiglates ning eraldatud bürokraatlike, geograafiliste ja poliitiliste piiridega. Puudub ühtne koondatud allikas ja meditsiinitöötajatel (mitteprogrammeerijatel) pole lihtsat viisi sellest ülevaate saamiseks. Samal ajal ei ole otstarbekas koolitada nende andmete põhjal ML- ja DL-mudeleid, mis võiksid aidata meditsiinitöötajatel teha kiiremaid ja täpsemaid otsuseid kriitilistel aegadel, mil südameskaneeringud võivad võtta tunde, samal ajal kui patsiendi elu võib rippuda. tasakaalu.
Muud teadaolevad kasutusjuhtumid hõlmavad POTSID (Online jälgimissüsteemi ostmine) aadressil NIH (National Institutes of Health) ja küberturvalisus hajutatud ja mitmetasandiliste luurelahenduste vajaduste jaoks COMCOMide/MAJCOMide asukohtades üle maailma.
Järeldus
Liitõppel on palju lubadusi tervishoiu pärandandmete analüütika ja luureandmete jaoks. Pilvepõhise lahenduse juurutamine AWS-i teenustega on lihtne ning FL on eriti kasulik meditsiiniorganisatsioonidele, kellel on pärandandmed ja tehnilised väljakutsed. FL võib avaldada potentsiaalset mõju kogu ravitsüklile ja nüüd veelgi enam, keskendudes suurte föderaalorganisatsioonide ja valitsusjuhtide andmete koostalitlusvõimele.
See lahendus aitab teil vältida ratta taasleiutamist ja kasutada uusimat tehnoloogiat, et astuda hüppeliselt pärandsüsteemidest ja olla selles pidevalt arenevas tehisintellekti maailmas esirinnas. Samuti võite saada liidriks parimate tavade ja tõhusa lähenemisviisi osas andmete koostalitlusvõimele tervishoiuvaldkonnas ja väljaspool asutusi ja instituute ning nende vahel. Kui olete instituut või agentuur, mille andmehoidlad on üle riigi laiali, saate sellest sujuvast ja turvalisest integreerimisest kasu.
Selle postituse sisu ja arvamused on kolmandast osapoolest autori omad ja AWS ei vastuta selle postituse sisu ega täpsuse eest. Iga klient vastutab selle eest, kas neile kehtib HIPAA ja kui jah, siis kuidas HIPAA-d ja selle rakendusmäärusi kõige paremini järgida. Enne AWS-i kasutamist koos kaitstud terviseteabega peavad kliendid sisestama AWS-i äripartneri lisa (BAA) ja järgima selle konfiguratsiooninõudeid.
Teave Autor

Nitin Kumar (MS, CMU) on T and T Consulting Services, Inc. juhtiv andmeteadlane. Tal on laialdased kogemused teadus- ja arendustegevuse prototüüpide loomise, terviseinformaatika, avaliku sektori andmete ja andmete koostalitlusvõime alal. Ta rakendab oma teadmisi tipptasemel uurimismeetoditest föderaalsektoris, et pakkuda uuenduslikke tehnilisi dokumente, POC-sid ja MVP-sid. Ta on teinud koostööd mitme föderaalametiga, et edendada nende andmeid ja tehisintellekti eesmärke. Nitini teised fookusvaldkonnad hõlmavad loomuliku keele töötlemist (NLP), andmejuhtmeid ja generatiivset AI-d.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/enable-data-sharing-through-federated-learning-a-policy-approach-for-chief-digital-officers/

