Amazon SageMaker Studio pakub andmeteadlastele täielikult hallatavat lahendust masinõppe (ML) mudelite interaktiivseks koostamiseks, koolitamiseks ja juurutamiseks. ML-ülesannete täitmisel alustavad andmeteadlased tavaliselt oma töövoogu asjakohaste andmeallikate avastamisest ja nendega ühenduse loomisest. Seejärel kasutavad nad SQL-i, et uurida, analüüsida, visualiseerida ja integreerida erinevatest allikatest pärit andmeid, enne kui kasutavad seda oma ML-koolituses ja järeldustes. Varem leidsid andmeteadlased sageli, et kasutasid oma töövoos SQL-i toetamiseks mitut tööriista, mis takistas tootlikkust.
Meil on hea meel teatada, et SageMaker Studio JupyterLabi sülearvutid on nüüd varustatud SQL-i sisseehitatud toega. Andmeteadlased saavad nüüd:
- Ühendage populaarsete andmeteenustega, sealhulgas Amazonase Athena, Amazoni punane nihe, Amazon DataZoneja Snowflake otse märkmikus
- Sirvige ja otsige andmebaase, skeeme, tabeleid ja vaateid ning vaadake andmeid sülearvuti liideses
- Segage SQL-i ja Pythoni koodid samas sülearvutis, et ML-projektides kasutada andmeid tõhusalt uurida ja teisendada
- Kasutage arendaja tootlikkuse funktsioone, nagu SQL-käskude lõpetamine, koodi vormindamise abi ja süntaksi esiletõstmine, et kiirendada koodi arendamist ja parandada arendaja üldist tootlikkust
Lisaks saavad administraatorid turvaliselt hallata ühendusi nende andmeteenustega, võimaldades andmeteadlastel pääseda juurde volitatud andmetele, ilma et oleks vaja mandaate käsitsi hallata.
Selles postituses juhendame teid selle funktsiooni seadistamisel SageMaker Studios ja tutvustame teile selle funktsiooni erinevaid võimalusi. Seejärel näitame, kuidas saate täiustada sülearvutisisest SQL-i kogemust, kasutades täiustatud suurte keelemudelite (LLM) pakutavaid tekst-SQL-i võimalusi, et kirjutada keerulisi SQL-päringuid, kasutades sisendina loomuliku keele teksti. Lõpuks, et võimaldada laiemal kasutajaskonnal genereerida SQL-päringuid oma märkmikus loomuliku keele sisendist, näitame teile, kuidas neid tekst-SQL-i mudeleid juurutada, kasutades Amazon SageMaker lõpp-punktid.
Lahenduse ülevaade
SageMaker Studio JupyterLabi sülearvuti SQL-integratsiooniga saate nüüd ühenduse luua populaarsete andmeallikatega, nagu Snowflake, Athena, Amazon Redshift ja Amazon DataZone. See uus funktsioon võimaldab teil täita erinevaid funktsioone.
Näiteks saate visuaalselt uurida andmeallikaid, nagu andmebaasid, tabelid ja skeemid otse oma JupyterLabi ökosüsteemist. Kui teie sülearvuti keskkonnas töötab SageMaker Distribution 1.6 või uuem, otsige oma JupyterLabi liidese vasakult küljelt uut vidinat. See lisamine parandab teie arenduskeskkonnas andmetele juurdepääsu ja haldamist.
Kui te ei kasuta praegu soovitatud SageMakeri levitamist (1.5 või vanem) või kohandatud keskkonda, vaadake lisateavet lisast.

Pärast ühenduste seadistamist (illustreeritud järgmises jaotises) saate andmeühendusi loetleda, andmebaase ja tabeleid sirvida ning skeeme kontrollida.

SageMaker Studio JupyterLabi sisseehitatud SQL-laiendus võimaldab teil ka otse sülearvutist SQL-päringuid käivitada. Jupyteri sülearvutid suudavad SQL-i ja Pythoni koodide vahel vahet teha %%sm_sql magic käsk, mis tuleb paigutada iga SQL-koodi sisaldava lahtri ülaossa. See käsk annab JupyterLabile märku, et järgmised juhised on SQL-käsud, mitte Pythoni kood. Päringu väljundit saab kuvada otse sülearvutis, mis hõlbustab SQL-i ja Pythoni töövoogude sujuvat integreerimist teie andmeanalüüsi.
Päringu väljundit saab kuvada visuaalselt HTML-tabelitena, nagu on näidatud järgmisel ekraanipildil.

Neid saab kirjutada ka a panda DataFrame.

Eeldused
Veenduge, et olete SageMaker Studio sülearvuti SQL-kogemuse kasutamiseks täitnud järgmised eeltingimused.
- SageMaker Studio V2 – Veenduge, et kasutate oma kõige värskemat versiooni SageMaker Studio domeen ja kasutajaprofiilid. Kui kasutate praegu SageMaker Studio Classicut, vaadake Üleminek Amazon SageMaker Studio Classicust.
- IAM roll - SageMaker nõuab AWS-i identiteedi- ja juurdepääsuhaldus (IAM) roll, mis määratakse SageMaker Studio domeenile või kasutajaprofiilile, et õigusi tõhusalt hallata. Andmete sirvimise ja SQL-i käitamise funktsiooni toomiseks võib olla vajalik täitmisrolli värskendus. Järgmine näide poliitika võimaldab kasutajatel anda, loetleda ja käivitada AWS liim, Ateena, Amazoni lihtne salvestusteenus (Amazon S3), AWS-i saladuste haldurja Amazon Redshifti ressursid:
- JupyterLab ruum – Teil on vaja juurdepääsu värskendatud SageMaker Studiole ja JupyterLab Space'ile SageMakeri levitamine v1.6 või uuemad pildiversioonid. Kui kasutate JupyterLab Spacesi või SageMaker Distributioni vanemate versioonide jaoks (v1.5 või vanem) kohandatud kujutisi, vaadake lisast juhiseid selle funktsiooni lubamiseks oma keskkondades vajalike pakettide ja moodulite installimiseks. SageMaker Studio JupyterLab Spacesi kohta lisateabe saamiseks vaadake Suurendage Amazon SageMaker Studio tootlikkust: JupyterLab Spacesi ja generatiivsete AI tööriistade tutvustamine.
- Andmeallika juurdepääsu mandaadid – See SageMaker Studio sülearvuti funktsioon nõuab kasutajanime ja parooli juurdepääsu andmeallikatele, nagu Snowflake ja Amazon Redshift. Looge nendele andmeallikatele kasutajanimi ja paroolipõhine juurdepääs, kui teil seda veel pole. OAuth-põhine juurdepääs Snowflake'ile ei ole selle kirjutamise seisuga toetatud.
- Laadige SQL-i maagia – Enne SQL-päringute käivitamist Jupyteri sülearvuti lahtrist on oluline laadida SQL magics laiendus. Kasutage käsku
%load_ext amazon_sagemaker_sql_magicselle funktsiooni lubamiseks. Lisaks saate käivitada%sm_sql?käsk, et vaadata SQL-lahtrist pärimise toetatud valikute põhjalikku loendit. Nende valikute hulka kuuluvad muu hulgas päringu vaikelimiidi seadmine 1,000, täieliku ekstraktsiooni käivitamine ja päringuparameetrite sisestamine. See seadistus võimaldab paindlikku ja tõhusat SQL-andmete töötlemist otse teie sülearvuti keskkonnas.
Loo andmebaasiühendused
SageMaker Studio sisseehitatud SQL-i sirvimis- ja täitmisvõimalusi täiustavad AWS Glue ühendused. AWS-liimi ühendus on AWS-i liimiandmete kataloogi objekt, mis salvestab konkreetsete andmehoidlate jaoks olulisi andmeid, nagu sisselogimismandaadid, URI-stringid ja virtuaalse privaatpilve (VPC) teave. Neid ühendusi kasutavad AWS Glue indeksoijad, tööd ja arenduse lõpp-punktid, et pääseda juurde erinevat tüüpi andmesalvedele. Saate neid ühendusi kasutada nii lähte- kui ka sihtandmete jaoks ning isegi sama ühendust mitme roomaja vahel kasutada või ETL-i töid ekstraktida, teisendada ja laadida.
SQL-i andmeallikate uurimiseks SageMaker Studio vasakpoolsel paanil peate esmalt looma AWS Glue'i ühendusobjektid. Need ühendused hõlbustavad juurdepääsu erinevatele andmeallikatele ja võimaldavad teil uurida nende skemaatilisi andmeelemente.
Järgmistes jaotistes käsitleme SQL-spetsiifiliste AWS-liimipistikute loomise protsessi. See võimaldab teil pääseda juurde, vaadata ja uurida mitmesuguste andmesalvede andmekogumeid. Üksikasjalikuma teabe saamiseks AWS-liimi ühenduste kohta vt Andmetega ühenduse loomine.
Looge AWS-liimi ühendus
Ainus viis andmeallikate SageMaker Studiosse toomiseks on AWS Glue ühendustega. Peate looma AWS-liimi ühendused kindlate ühendustüüpidega. Selle kirjutamise seisuga on ainus toetatud mehhanism nende ühenduste loomiseks AWS-i käsurea liides (AWS CLI).
Ühenduse määratluse JSON-fail
AWS Glue'is erinevate andmeallikatega ühenduse loomisel peate esmalt looma JSON-faili, mis määrab ühenduse atribuudid, mida nimetatakse ühenduse määratlusfail. See fail on AWS-liimi ühenduse loomiseks ülioluline ja peaks üksikasjalikult kirjeldama kõiki andmeallikale juurdepääsuks vajalikke konfiguratsioone. Parimate turvatavade huvides on soovitatav kasutada tundliku teabe (nt paroolid) turvaliseks salvestamiseks Secrets Manageri. Samal ajal saab muid ühenduse omadusi hallata otse AWS Glue ühenduste kaudu. See lähenemine tagab, et tundlikud mandaadid on kaitstud, muutes samal ajal ühenduse konfiguratsiooni juurdepääsetavaks ja hallatavaks.
Järgmine on ühenduse määratluse JSON-i näide:
Andmeallikate jaoks AWS-liimi ühenduste seadistamisel tuleb järgida mõnda olulist juhist, et tagada nii funktsionaalsus kui ka turvalisus.
- Omaduste stringifitseerimine – Sees
PythonPropertiesklahvi, veenduge, et kõik omadused on olemas stringitud võtme-väärtuse paarid. Väga oluline on topeltjutumärkidest õigesti pääseda, kasutades vajadusel kaldkriipsu (). See aitab säilitada õiget vormingut ja vältida süntaksivigu teie JSON-is. - Tundliku teabe käsitlemine – Kuigi on võimalik kaasata kõik ühenduse omadused
PythonProperties, on soovitatav mitte lisada nendesse atribuutidesse tundlikke üksikasju, nagu paroolid. Selle asemel kasutage tundliku teabe haldamiseks saladuste haldurit. See lähenemine kaitseb teie tundlikke andmeid, salvestades need kontrollitud ja krüptitud keskkonda, eemal peamistest konfiguratsioonifailidest.
Looge AWS-liimi ühendus, kasutades AWS-i CLI-d
Kui olete oma ühenduse määratluse JSON-faili kõik vajalikud väljad lisanud, olete valmis looma oma andmeallika jaoks AWS-liimi ühenduse, kasutades AWS-i CLI-d ja järgmist käsku:
See käsk käivitab teie JSON-failis üksikasjalike spetsifikatsioonide alusel uue AWS-liimi ühenduse. Järgmine on käsukomponentide kiire jaotus:
- – piirkond – See määrab AWS-i piirkonna, kus teie AWS-liimi ühendus luuakse. Latentsuse minimeerimiseks ja andmete asukohanõuete järgimiseks on ülioluline valida piirkond, kus teie andmeallikad ja muud teenused asuvad.
- –cli-input-json file:///path/to/file/connection/definition/file.json – See parameeter suunab AWS-i CLI-d lugema sisendkonfiguratsiooni kohalikust failist, mis sisaldab teie ühenduse määratlust JSON-vormingus.
Teil peaks olema võimalik luua AWS Glue ühendusi eelmise AWS CLI käsuga oma Studio JupyterLabi terminalist. peal fail menüüst valige Uus ja terminal.

Kui create-connection käsk töötab edukalt, peaksite nägema oma andmeallikat SQL-i brauseri paanil. Kui te oma andmeallikat loendis ei näe, valige värskendama vahemälu värskendamiseks.
Looge lumehelbe ühendus
Selles jaotises keskendume lumehelbe andmeallika integreerimisele SageMaker Studioga. Snowflake'i kontode, andmebaaside ja ladude loomine ei kuulu selle postituse ulatusse. Lumehelbega alustamiseks vaadake jaotist Lumehelbe kasutusjuhend. Selles postituses keskendume Snowflake'i definitsiooni JSON-faili loomisele ja Snowflake'i andmeallika ühenduse loomisele, kasutades AWS-liimi.
Looge saladuste halduri saladus
Saate luua ühenduse oma Snowflake'i kontoga kas kasutajatunnuse ja parooli või privaatvõtmete abil. Kasutajatunnuse ja parooliga ühenduse loomiseks peate oma mandaadid turvaliselt saladuste haldurisse salvestama. Nagu varem mainitud, pole seda teavet võimalik manustada PythonPropertiesi alla, kuid tundlikku teavet lihtteksti vormingus ei soovitata talletada. Võimalike turvariskide vältimiseks veenduge alati, et tundlikke andmeid käsitletaks turvaliselt.
Teabe salvestamiseks saladuste haldurisse toimige järgmiselt.
- Valige konsoolil Secrets Manager Salvestage uus saladus.
- eest Salajane tüüp, vali Muud tüüpi saladused.
- Valige võtme-väärtuse paari jaoks Lihttekst ja sisestage järgmine:
- Sisestage oma saladusele nimi, näiteks
sm-sql-snowflake-secret. - Jätke muud sätted vaikeseadeteks või kohandage neid vajadusel.
- Loo saladus.
Looge Snowflake'i jaoks AWS-liimi ühendus
Nagu varem mainitud, on AWS Glue ühendused olulised, et pääseda juurde mis tahes ühendusele SageMaker Studio kaudu. Võite leida nimekirja kõik Snowflake'i toetatud ühenduse omadused. Järgmine on Snowflake'i JSON-i ühenduse määratluse näidis. Enne kettale salvestamist asendage kohahoidja väärtused sobivate väärtustega:
Lumehelbe andmeallika jaoks AWS Glue ühendusobjekti loomiseks kasutage järgmist käsku:
See käsk loob teie SQL-i brauseri paanil uue andmeallika ühenduse Snowflake, mida saab sirvida ja saate selle vastu käitada SQL-päringuid oma JupyterLabi märkmiku lahtrist.

Looge Amazon Redshift ühendus
Amazon Redshift on täielikult hallatav, petabaitide ulatusega andmelaoteenus, mis lihtsustab kõigi teie andmete analüüsimist standardse SQL-i abil ja vähendab selle kulusid. Amazon Redshift ühenduse loomise protseduur peegeldab täpselt Snowflake ühenduse loomist.
Looge saladuste halduri saladus
Sarnaselt Snowflake'i seadistusega peate Amazon Redshiftiga kasutaja ID ja parooli abil ühenduse loomiseks salvestama saladusteabe turvaliselt saladuste haldurisse. Tehke järgmised sammud.
- Valige konsoolil Secrets Manager Salvestage uus saladus.
- eest Salajane tüüp, vali Amazon Redshift klastri mandaadid.
- Sisestage mandaadid, mida kasutati sisselogimiseks, et pääseda juurde Amazon Redshiftile andmeallikana.
- Valige saladustega seotud punanihke klaster.
- Sisestage saladusele nimi, näiteks
sm-sql-redshift-secret. - Jätke muud sätted vaikeseadeteks või kohandage neid vajadusel.
- Loo saladus.
Järgides neid samme, veendute, et teie ühenduse mandaate käsitletakse turvaliselt, kasutades tundlike andmete tõhusaks haldamiseks AWS-i tugevaid turvafunktsioone.
Looge Amazon Redshifti jaoks AWS-liimi ühendus
Amazon Redshiftiga ühenduse loomiseks JSON-definitsiooni abil täitke vajalikud väljad ja salvestage kettale järgmine JSON-i konfiguratsioon:
Redshift andmeallika jaoks AWS Glue ühendusobjekti loomiseks kasutage järgmist AWS CLI käsku:
See käsk loob AWS Glue'is ühenduse, mis on lingitud teie Redshifti andmeallikaga. Kui käsk töötab edukalt, näete oma Redshifti andmeallikat SageMaker Studio JupyterLabi märkmikus, mis on valmis SQL-päringute käitamiseks ja andmeanalüüsi tegemiseks.

Looge Athena ühendus
Athena on AWS-i täielikult hallatav SQL-päringuteenus, mis võimaldab standardset SQL-i kasutades analüüsida Amazon S3-sse salvestatud andmeid. Athena ühenduse seadistamiseks JupyterLabi märkmiku SQL-brauseris andmeallikana, peate looma Athena näidisühenduse määratluse JSON. Järgmine JSON-struktuur konfigureerib Athenaga ühenduse loomiseks vajalikud üksikasjad, täpsustades andmekataloogi, S3 etapikataloogi ja piirkonna:
Athena andmeallika jaoks AWS Glue ühendusobjekti loomiseks kasutage järgmist AWS CLI käsku:
Kui käsk õnnestub, pääsete SageMaker Studio JupyterLabi märkmikus otse SQL-brauserist juurde Athena andmekataloogile ja tabelitele.

Andmete päring mitmest allikast
Kui teil on sisseehitatud SQL-brauseri ja sülearvuti SQL-funktsiooni kaudu SageMaker Studiosse integreeritud mitu andmeallikat, saate kiiresti käivitada päringuid ja hõlpsalt vahetada andmeallika taustaprogrammide vahel märkmiku järgmistes lahtrites. See võimalus võimaldab analüüsi töövoo ajal sujuvaid üleminekuid erinevate andmebaaside või andmeallikate vahel.
Saate käitada päringuid mitmesuguse andmeallika taustaprogrammide kogumi vastu ja tuua tulemused edasiseks analüüsiks või visualiseerimiseks otse Pythoni ruumi. Seda soodustavad %%sm_sql maagiline käsk on saadaval SageMaker Studio sülearvutites. SQL-päringu tulemuste väljastamiseks panda DataFrame'i on kaks võimalust.
- Valige sülearvuti lahtri tööriistaribalt väljundi tüüp DataFrame ja nimetage oma DataFrame'i muutuja
- Lisage omale järgmine parameeter
%%sm_sqlkäsk:
Järgmine diagramm illustreerib seda töövoogu ja näitab, kuidas saate hõlpsalt käivitada päringuid erinevatest allikatest järgmistes märkmiku lahtrites, samuti treenida SageMakeri mudelit koolitustööde abil või otse sülearvutis, kasutades kohalikku arvutust. Lisaks näitab diagramm, kuidas SageMaker Studio sisseehitatud SQL-i integreerimine lihtsustab ekstraktimise ja ehitamise protsesse otse JupyterLabi sülearvuti lahtri tuttavas keskkonnas.

Tekst SQL-i: loomuliku keele kasutamine päringu loomise täiustamiseks
SQL on keeruline keel, mis nõuab andmebaaside, tabelite, süntaksite ja metaandmete mõistmist. Tänapäeval võib generatiivne tehisintellekt (AI) võimaldada teil kirjutada keerulisi SQL-päringuid ilma põhjalikku SQL-i kogemust nõudmata. LLM-ide areng on oluliselt mõjutanud loomuliku keele töötlemisel (NLP) põhinevat SQL-i genereerimist, võimaldades luua täpseid SQL-päringuid loomuliku keele kirjeldustest – seda tehnikat nimetatakse tekstist SQL-iks. Siiski on oluline tunnistada inimkeele ja SQL-i olemuslikke erinevusi. Inimkeel võib mõnikord olla mitmetähenduslik või ebatäpne, samas kui SQL on struktureeritud, selgesõnaline ja ühemõtteline. Selle lünga ületamine ja loomuliku keele täpne teisendamine SQL-päringuteks võib olla tohutu väljakutse. Asjakohaste viipade korral saavad LLM-id aidata seda lünka ületada, mõistes inimkeele taga olevaid eesmärke ja genereerides vastavalt täpseid SQL-päringuid.
SageMaker Studio sülearvutisisese SQL-päringu funktsiooni väljalaskmisega muudab SageMaker Studio andmebaaside ja skeemide kontrollimise ning SQL-päringute koostamise, käivitamise ja silumise lihtsaks, ilma et peaksite kunagi Jupyteri sülearvuti IDE-st lahkuma. Selles jaotises uuritakse, kuidas täiustatud LLM-ide teksti-SQL-i võimalused võivad hõlbustada SQL-päringute genereerimist, kasutades Jupyteri sülearvutites loomulikku keelt. Kasutame tipptasemel Text-to-SQL mudelit defog/sqlcoder-7b-2 koos Jupyteri AI-ga, generatiivse AI-assistentiga, mis on spetsiaalselt loodud Jupyteri sülearvutite jaoks, et luua loomulikust keelest keerukaid SQL-päringuid. Seda täiustatud mudelit kasutades saame hõlpsalt ja tõhusalt luua keerulisi SQL-päringuid, kasutades loomulikku keelt, parandades seeläbi meie SQL-i kasutuskogemust sülearvutites.
Sülearvuti prototüüpimine Hugging Face Hubi abil
Prototüüpimise alustamiseks vajate järgmist.
- GitHubi kood – Selles jaotises esitatud kood on saadaval allpool GitHub repo ja viidates näidismärkmik.
- JupyterLab ruum – Juurdepääs SageMaker Studio JupyterLab Space'ile, mida toetavad GPU-põhised eksemplarid, on hädavajalik. Jaoks
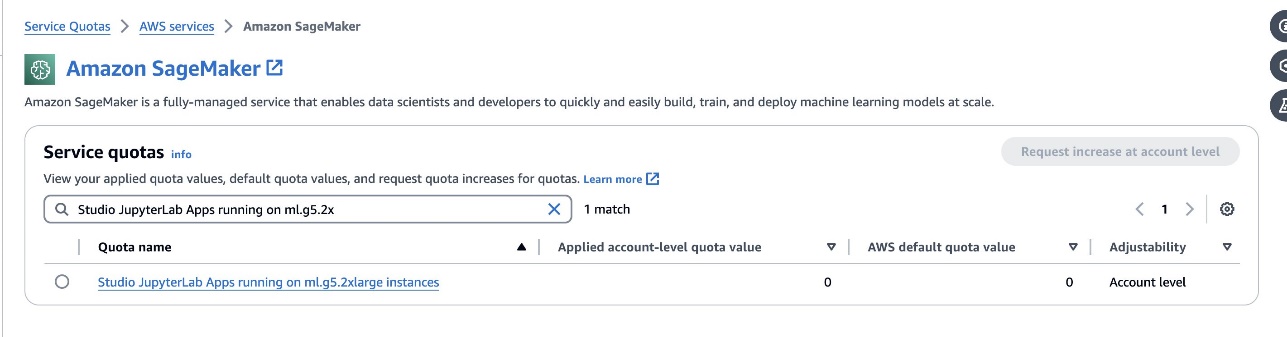
defog/sqlcoder-7b-2mudelil on soovitatav kasutada 7B parameetrimudelit, kasutades ml.g5.2xlarge eksemplari. Alternatiivid nagudefog/sqlcoder-70b-alpha võidefog/sqlcoder-34b-alphaon elujõulised ka loomuliku keele teisendamiseks SQL-iks, kuid prototüüpimiseks võib vaja minna suuremaid eksemplaritüüpe. Veenduge, et teil oleks kvoot GPU-ga toetatud eksemplari käivitamiseks, navigeerides teenusekvootide konsooli, otsides SageMakerit ja otsidesStudio JupyterLab Apps running on <instance type>.
Käivitage oma SageMaker Studios uus GPU-ga toetatud JupyterLab Space. Soovitatav on luua uus JupyterLabi ruum, mille maht on vähemalt 75 GB Amazoni elastsete plokkide pood (Amazon EBS) salvestusruum 7B parameetriga mudeli jaoks.


- Kallistamine Face Hub – Kui teie SageMaker Studio domeenil on juurdepääs mudelite allalaadimiseks saidilt Kallistamine Face Hub, võite kasutada
AutoModelForCausalLMklassist alates kallistav nägu/transformerid mudelite automaatseks allalaadimiseks ja nende kinnitamiseks kohalikele GPU-dele. Mudeli kaalud salvestatakse teie kohaliku masina vahemällu. Vaadake järgmist koodi:
Kui mudel on täielikult alla laaditud ja mällu laaditud, peaksite oma kohalikus masinas jälgima GPU kasutuse kasvu. See näitab, et mudel kasutab arvutusülesannete jaoks aktiivselt GPU ressursse. Saate seda kontrollida oma JupyterLabi ruumis, käivitades nvidia-smi (ühekordse kuvamise jaoks) või nvidia-smi —loop=1 (kordamiseks iga sekundi järel) oma JupyterLabi terminalist.

Tekst-SQL-i mudelid mõistavad suurepäraselt kasutaja päringu eesmärki ja konteksti, isegi kui kasutatav keel on kõnekas või mitmetähenduslik. Protsess hõlmab loomuliku keele sisendite tõlkimist õigeteks andmebaasiskeemi elementideks, nagu tabelinimed, veergude nimed ja tingimused. Kuid valmis tekstist SQL-i muutev mudel ei tunne oma olemuselt teie andmelao struktuuri, konkreetseid andmebaasiskeeme ega suuda ainult veergude nimede põhjal tabeli sisu täpselt tõlgendada. Nende mudelite tõhusaks kasutamiseks loomulikust keelest praktiliste ja tõhusate SQL-päringute genereerimiseks on vaja kohandada SQL-i teksti genereerimise mudel teie konkreetse laoandmebaasi skeemiga. Seda kohanemist hõlbustab kasutamine LLM küsib. Järgmine on defog/sqlcoder-7b-2 Text-to-SQL mudeli soovitatav viipamall, mis on jagatud neljaks osaks.
- Ülesanne – Selles jaotises tuleks täpsustada kõrgetasemeline ülesanne, mille mudel peab täitma. See peaks sisaldama andmebaasi taustaprogrammi tüüpi (nt Amazon RDS, PostgreSQL või Amazon Redshift), et mudel oleks teadlik kõigist nüansilistest süntaktilistest erinevustest, mis võivad mõjutada lõpliku SQL-päringu genereerimist.
- Juhised – See jaotis peaks määratlema mudeli ülesannete piirid ja domeeniteadlikkuse ning võib sisaldada väheseid näiteid, mis juhivad mudelit peenhäälestatud SQL-päringute genereerimisel.
- Andmebaasiskeem – Selles jaotises tuleks kirjeldada üksikasjalikult teie lao andmebaasi skeeme, kirjeldades tabelite ja veergude vahelisi seoseid, et aidata mudelil andmebaasi struktuurist aru saada.
- Vastus – See jaotis on reserveeritud mudeli jaoks, mis väljastab SQL-päringu vastuse loomuliku keele sisendisse.
Selles jaotises kasutatud andmebaasi skeemi ja viipa näide on saadaval aadressil GitHubi Repo.
Kiire projekteerimine ei tähenda ainult küsimuste või väidete koostamist; see on nüansirikas kunst ja teadus, mis mõjutab oluliselt tehisintellekti mudeliga suhtlemise kvaliteeti. Viipe koostamise viis võib oluliselt mõjutada tehisintellekti vastuse olemust ja kasulikkust. See oskus on ülimalt oluline tehisintellekti interaktsioonide potentsiaali maksimeerimiseks, eriti keeruliste ülesannete puhul, mis nõuavad erilist mõistmist ja üksikasjalikke vastuseid.
On oluline, et oleks võimalik kiiresti luua ja testida mudeli vastust antud viipa jaoks ning optimeerida viipa vastuse põhjal. JupyterLabi sülearvutid pakuvad võimalust saada kohest mudeli tagasisidet kohalikul arvutusel töötavalt mudelilt ning optimeerida viipa ja häälestada mudeli vastust veelgi või muuta mudelit täielikult. Selles postituses kasutame SageMaker Studio JupyterLabi sülearvutit, mida toetab ml.g5.2xlarge'i NVIDIA A10G 24 GB GPU, et käivitada sülearvuti tekstist SQL-i mudeli järeldusi ja koostada interaktiivselt oma mudeliviipa, kuni mudeli vastus on piisavalt häälestatud. vastused, mis on otse käivitatavad JupyterLabi SQL-i lahtrites. Mudeli järelduse käitamiseks ja mudeli vastuste samaaegseks voogesitamiseks kasutame kombinatsiooni model.generate ja TextIteratorStreamer nagu on määratletud järgmises koodis:
Mudeli väljundit saab kaunistada SageMaker SQL maagiaga %%sm_sql ..., mis võimaldab JupyterLabi märkmikul tuvastada lahtri SQL-i lahtrina.
Tekst-SQL-mudelite hostimine SageMakeri lõpp-punktidena
Prototüüpimise etapi lõpus oleme valinud eelistatud teksti-SQL-i LLM-i, tõhusa viipavormingu ja mudeli hostimiseks sobiva eksemplari tüübi (kas ühe GPU või mitme GPU-ga). SageMaker hõlbustab kohandatud mudelite skaleeritavat hostimist SageMakeri lõpp-punktide kasutamise kaudu. Neid lõpp-punkte saab määratleda vastavalt konkreetsetele kriteeriumidele, mis võimaldab lõpp-punktidena juurutada LLM-e. See võimalus võimaldab teil skaleerida lahendust laiemale vaatajaskonnale, võimaldades kasutajatel luua SQL-päringuid loomuliku keele sisenditest, kasutades kohandatud hostitud LLM-e. Järgmine diagramm illustreerib seda arhitektuuri.
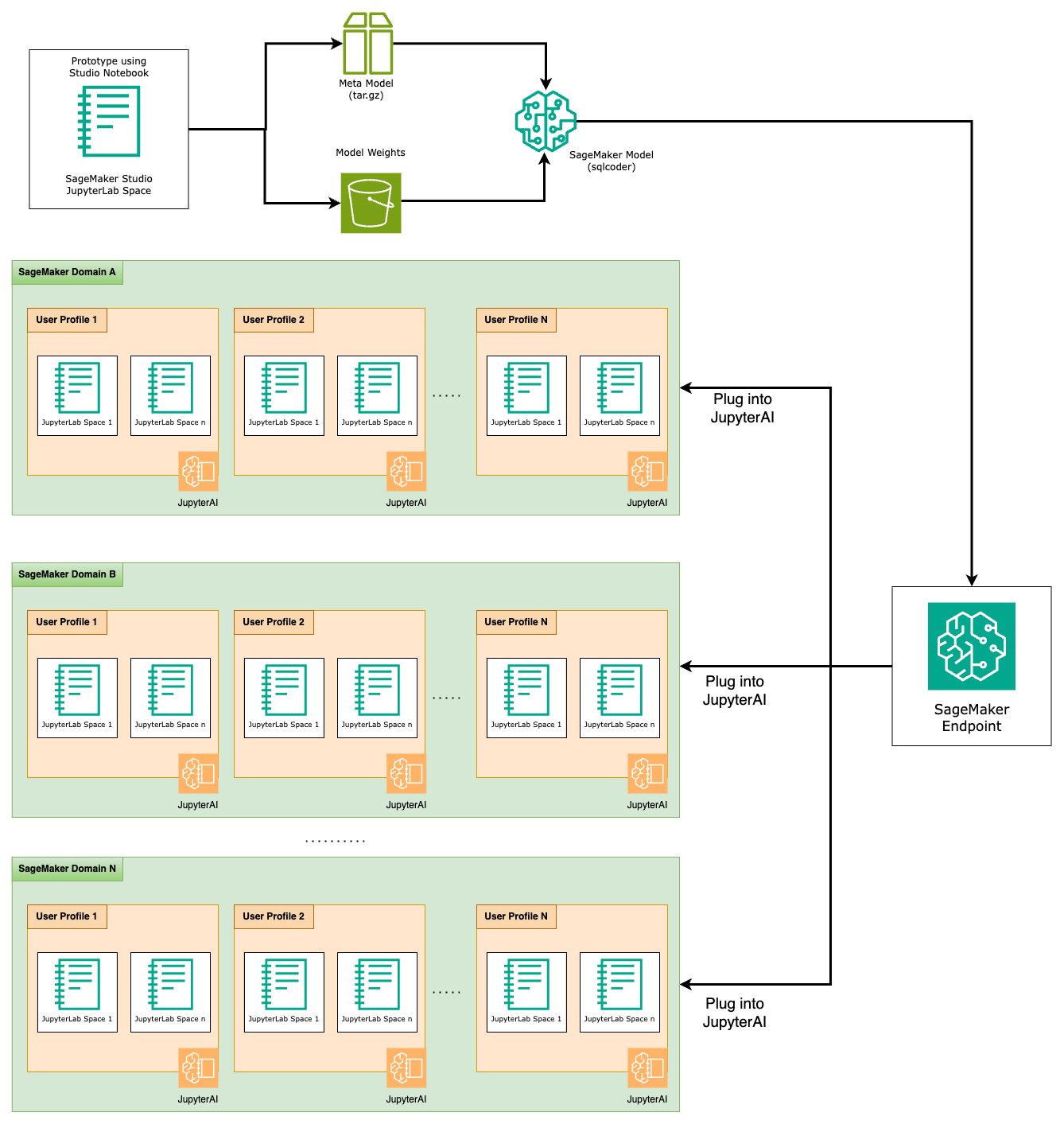
LLM-i hostimiseks SageMakeri lõpp-punktina loote mitu artefakti.
Esimene artefakt on mudeli kaalud. SageMakeri sügava Java raamatukogu (DJL) teenindamine konteinerid võimaldavad seadistada konfiguratsioone meta kaudu serveerimine.omadused faili, mis võimaldab teil suunata mudelite hankimist – kas otse Hugging Face Hubist või laadides alla mudeliartefakte Amazon S3-st. Kui täpsustate model_id=defog/sqlcoder-7b-2, proovib DJL Serving seda mudelit Hugging Face Hubist otse alla laadida. Siiski võivad teil tekkida võrgu sisse-/väljapääsutasud iga kord, kui lõpp-punkt juurutatakse või elastselt skaleeritakse. Nende tasude vältimiseks ja mudeli artefaktide allalaadimise võimalikuks kiirendamiseks on soovitatav kasutamine vahele jätta model_id in serving.properties ja salvestage mudeli kaalud S3 artefaktidena ja määrake need ainult koos s3url=s3://path/to/model/bin.
Mudeli (koos tokenisaatoriga) kettale salvestamiseks ja Amazon S3-sse üleslaadimiseks saab teha vaid mõne koodirea:
Kasutate ka andmebaasi viipafaili. Selles seadistuses koosneb andmebaasi viip Task, Instructions, Database Schemaja Answer sections. Praeguse arhitektuuri jaoks eraldame iga andmebaasi skeemi jaoks eraldi viipafaili. Siiski on võimalik seda seadistust paindlikult laiendada, et hõlmata mitu andmebaasi ühe viipafaili kohta, võimaldades mudelil käivitada sama serveri andmebaaside liitühendusi. Prototüüpimise etapis salvestame andmebaasiviipa tekstifailina nimega <Database-Glue-Connection-Name>.prompt, Kus Database-Glue-Connection-Name vastab teie JupyterLabi keskkonnas nähtavale ühenduse nimele. Näiteks viitab see postitus lumehelbe ühendusele nimega Airlines_Dataset, nii et andmebaasi viipafailile antakse nimi Airlines_Dataset.prompt. See fail salvestatakse seejärel Amazon S3-sse ning seejärel loetakse ja salvestatakse vahemällu meie mudeli teenindamise loogika abil.
Lisaks võimaldab see arhitektuur selle lõpp-punkti kõigil volitatud kasutajatel määratleda, salvestada ja genereerida SQL-päringute jaoks loomulikku keelt, ilma et oleks vaja mudelit korduvalt ümber paigutada. Kasutame järgmist andmebaasi viipa näide teksti-SQL-i funktsiooni demonstreerimiseks.
Järgmisena loote kohandatud mudeli teenuseloogika. Selles jaotises kirjeldate kohandatud järeldusloogikat nimega mudel.py. See skript on loodud meie tekst-SQL-i teenuste toimivuse ja integreerimise optimeerimiseks.
- Määratlege andmebaasi viipafailide vahemällu salvestamise loogika – Latentsuse minimeerimiseks rakendame andmebaasi viipade failide allalaadimiseks ja vahemällu salvestamiseks kohandatud loogikat. See mehhanism tagab, et viibad on hõlpsasti kättesaadavad, vähendades sagedase allalaadimisega seotud üldkulusid.
- Määratlege kohandatud mudeli järeldusloogika – Järelduste kiiruse suurendamiseks laaditakse meie tekst-SQL-mudel täppisvormingus float16 ja teisendatakse seejärel DeepSpeed-mudeliks. See samm võimaldab tõhusamalt arvutada. Lisaks saate selle loogika raames määrata, milliseid parameetreid saavad kasutajad järelduskõnede ajal kohandada, et kohandada funktsioone vastavalt oma vajadustele.
- Määratlege kohandatud sisend- ja väljundloogika – Selgete ja kohandatud sisend-/väljundvormingute loomine on oluline sujuvaks integreerimiseks allavoolu rakendustega. Üks selline rakendus on JupyterAI, mida käsitleme järgmises jaotises.
Lisaks lisame a serving.properties fail, mis toimib globaalse konfiguratsioonifailina mudelite jaoks, mida hostitakse DJL-i serveerimist kasutades. Lisateabe saamiseks vaadake Konfiguratsioonid ja seaded.
Lõpuks võite lisada ka a requirements.txt faili, et määratleda järelduste tegemiseks vajalikud lisamoodulid ja pakkida kõik juurutamiseks tarballi.
Vaadake järgmist koodi:
Integreerige oma lõpp-punkt SageMaker Studio Jupyter AI assistendiga
Jupyter AI on avatud lähtekoodiga tööriist, mis toob generatiivse AI Jupyteri sülearvutitesse, pakkudes tugevat ja kasutajasõbralikku platvormi generatiivsete AI mudelite uurimiseks. See suurendab JupyterLabi ja Jupyteri sülearvutite tootlikkust, pakkudes selliseid funktsioone nagu %%ai maagia generatiivse tehisintellekti mänguväljaku loomiseks sülearvutites, JupyterLabi natiivne vestlusliides AI-ga suhtlemiseks vestlusabilisena ja tugi paljudele LLM-idele alates pakkujatele meeldib Amazoni titaan, AI21, Anthropic, Cohere ja Hugging Face või hallatavad teenused nagu Amazonase aluspõhi ja SageMakeri lõpp-punktid. Selle postituse jaoks kasutame Jupyter AI valmisintegratsiooni SageMakeri lõpp-punktidega, et tuua tekstist SQL-i võime JupyterLabi sülearvutitesse. Jupyteri AI tööriist on eelinstallitud kõigisse SageMaker Studio JupyterLab Spaces, mida toetab SageMakeri levitamise pildid; lõppkasutajad ei pea tegema täiendavaid konfiguratsioone, et alustada Jupyteri AI laienduse kasutamist, et integreerida SageMakeri hostitud lõpp-punktiga. Selles jaotises käsitleme kahte võimalust integreeritud Jupyteri AI tööriista kasutamiseks.
Jupyter AI sülearvuti sees, kasutades maagiat
Jupyteri AI-d %%ai magic käsk võimaldab teil muuta oma SageMaker Studio JupyterLabi sülearvutid reprodutseeritavaks generatiivseks AI keskkonnaks. AI-maagia kasutamise alustamiseks veenduge, et oleksite laadinud kasutamiseks laienduse jupyter_ai_magics %%ai maagia ja lisaks laadige amazon_sagemaker_sql_magic kasutada %%sm_sql maagia:
SageMakeri lõpp-punktile helistamiseks sülearvutist kasutades %%ai magic käsk, esitage järgmised parameetrid ja struktureerige käsk järgmiselt:
- – piirkonna nimi – Määrake piirkond, kus teie lõpp-punkt on juurutatud. See tagab, et päring suunatakse õigesse geograafilisse asukohta.
- -taotlus-skeem – Kaasake sisendandmete skeem. See skeem kirjeldab eeldatavat vormingut ja sisendandmete tüüpe, mida teie mudel vajab päringu töötlemiseks.
- -vastus-tee – Määrake tee vastuseobjektis, kus asub teie mudeli väljund. Seda teed kasutatakse asjakohaste andmete eraldamiseks teie mudeli tagastatud vastusest.
- -f (valikuline) - See on väljundi vormindaja lipp, mis näitab mudeli tagastatud väljundi tüüpi. Jupyteri sülearvuti kontekstis, kui väljund on kood, tuleks see lipp vastavalt määrata, et vormindada väljund käivitatava koodina Jupyteri märkmiku lahtri ülaosas, millele järgneb kasutaja interaktsiooniks vaba tekstisisestusala.
Näiteks võib Jupyteri märkmiku lahtris olev käsk välja näha järgmise koodina:
Jupyter AI vestlusaken
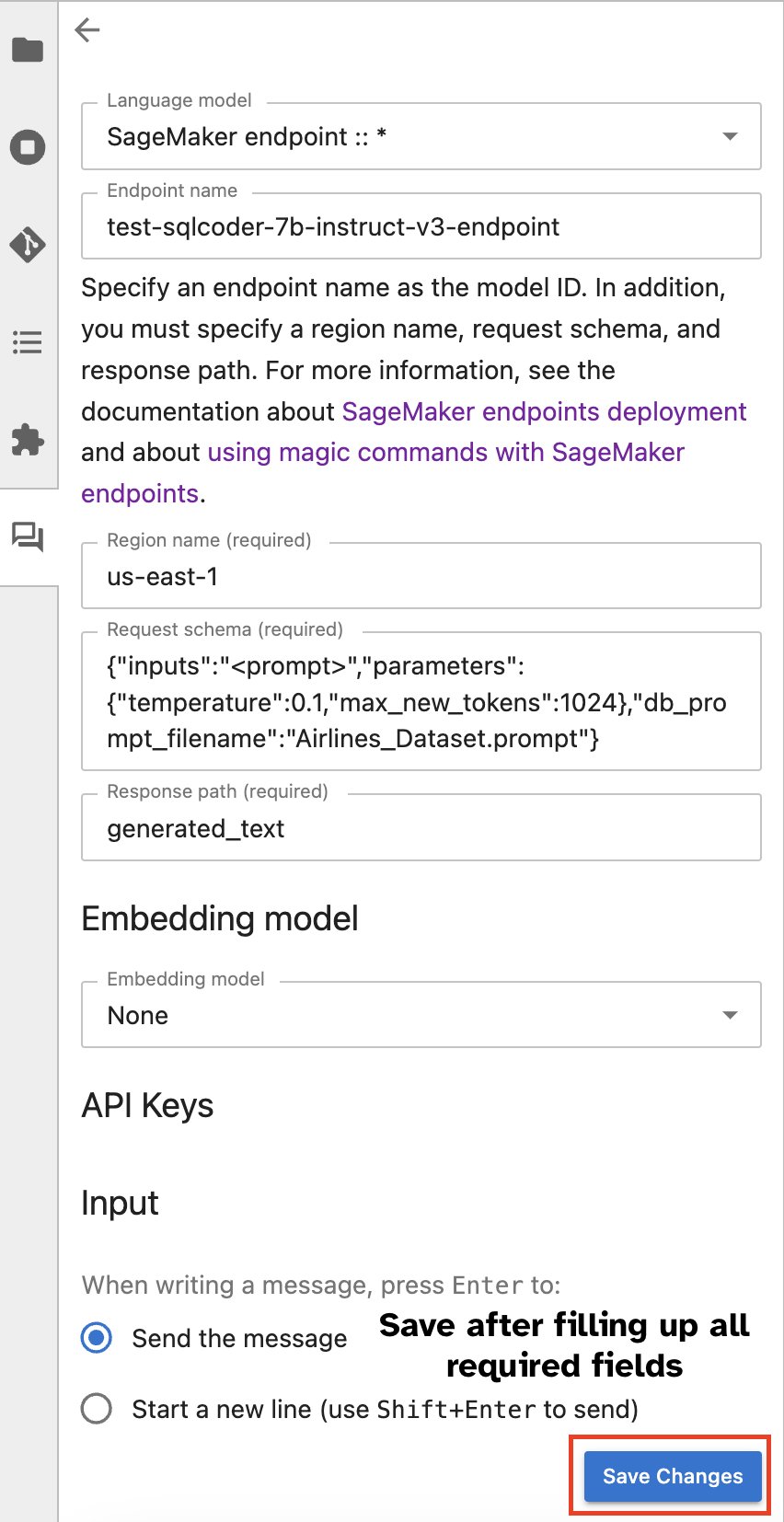
Teise võimalusena saate SageMakeri lõpp-punktidega suhelda sisseehitatud kasutajaliidese kaudu, lihtsustades päringute genereerimise või dialoogis osalemise protsessi. Enne SageMakeri lõpp-punktiga vestluse alustamist konfigureerige Jupyter AI-s SageMakeri lõpp-punkti jaoks asjakohased sätted, nagu on näidatud järgmisel ekraanipildil.
 |
 |
Järeldus
SageMaker Studio lihtsustab ja ühtlustab nüüd andmeteadlase töövoogu, integreerides SQL-i toe JupyterLabi sülearvutitesse. See võimaldab andmeteadlastel keskenduda oma ülesannetele, ilma et oleks vaja hallata mitut tööriista. Lisaks võimaldab SageMaker Studio uus sisseehitatud SQL-i integratsioon andmeisikutel hõlpsalt genereerida SQL-päringuid, kasutades sisendiks loomulikku keelt, kiirendades seeläbi nende töövoogu.
Soovitame teil neid funktsioone SageMaker Studios uurida. Lisateabe saamiseks vaadake Valmistage Studios ette andmed SQL-iga.
Lisa
Lubage kohandatud keskkondades SQL-brauser ja sülearvuti SQL-lahter
Kui te ei kasuta SageMaker Distributioni kujutist või Distributioni kujutisi 1.5 või vanemat versiooni, käivitage järgmised käsud, et lubada SQL-i sirvimisfunktsioon oma JupyterLabi keskkonnas:
Viige SQL-brauseri vidin ümber
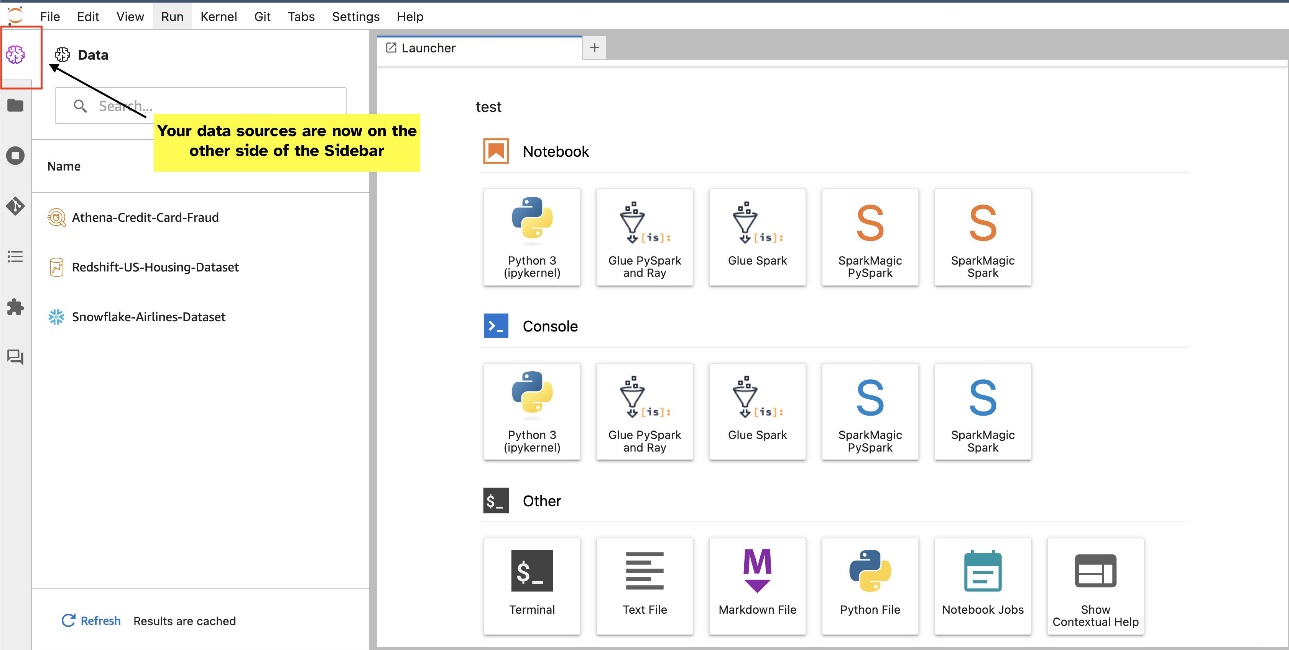
JupyterLabi vidinad võimaldavad ümberpaigutamist. Sõltuvalt teie eelistusest saate vidinaid teisaldada JupyterLabi vidinate paani mõlemale küljele. Soovi korral saate liigutada SQL-i vidina suuna külgriba vastasküljele (paremalt vasakule), tehes lihtsa paremklõpsuga vidina ikoonil ja valides Lülitage külgriba külg.
 |
 |
Autoritest
 Pranav Murthy on AWS-i AI/ML-i spetsialistilahenduste arhitekt. Ta keskendub sellele, et aidata klientidel masinõppe (ML) töökoormust SageMakerisse luua, koolitada, juurutada ja üle viia. Varem töötas ta pooljuhttööstuses, töötades välja suuri arvutinägemise (CV) ja loomuliku keele töötlemise (NLP) mudeleid, et täiustada pooljuhtprotsesse, kasutades nüüdisaegseid ML-tehnikaid. Vabal ajal meeldib talle malet mängida ja reisida. Pranavi leiate aadressilt LinkedIn.
Pranav Murthy on AWS-i AI/ML-i spetsialistilahenduste arhitekt. Ta keskendub sellele, et aidata klientidel masinõppe (ML) töökoormust SageMakerisse luua, koolitada, juurutada ja üle viia. Varem töötas ta pooljuhttööstuses, töötades välja suuri arvutinägemise (CV) ja loomuliku keele töötlemise (NLP) mudeleid, et täiustada pooljuhtprotsesse, kasutades nüüdisaegseid ML-tehnikaid. Vabal ajal meeldib talle malet mängida ja reisida. Pranavi leiate aadressilt LinkedIn.
 Varun Shah on tarkvarainsener, kes töötab Amazon SageMaker Studios Amazon Web Servicesis. Ta on keskendunud interaktiivsete ML-lahenduste loomisele, mis lihtsustavad andmetöötlust ja andmete ettevalmistamise teekondi. Vabal ajal naudib Varun väljas tegevusi, sealhulgas matkamist ja suusatamist, ning on alati valmis avastama uusi põnevaid kohti.
Varun Shah on tarkvarainsener, kes töötab Amazon SageMaker Studios Amazon Web Servicesis. Ta on keskendunud interaktiivsete ML-lahenduste loomisele, mis lihtsustavad andmetöötlust ja andmete ettevalmistamise teekondi. Vabal ajal naudib Varun väljas tegevusi, sealhulgas matkamist ja suusatamist, ning on alati valmis avastama uusi põnevaid kohti.
 Sumedha Swamy on Amazon Web Servicesi peamine tootejuht, kus ta juhib SageMaker Studio meeskonda selle missioonil andmeteaduse ja masinõppe jaoks valitud IDE väljatöötamisel. Ta on viimased 15 aastat pühendanud masinõppepõhiste tarbija- ja ettevõttetoodete loomisele.
Sumedha Swamy on Amazon Web Servicesi peamine tootejuht, kus ta juhib SageMaker Studio meeskonda selle missioonil andmeteaduse ja masinõppe jaoks valitud IDE väljatöötamisel. Ta on viimased 15 aastat pühendanud masinõppepõhiste tarbija- ja ettevõttetoodete loomisele.
 Bosco Albuquerque on AWS-i vanempartnerlahenduste arhitekt ning tal on üle 20-aastane kogemus ettevõtete andmebaasimüüjate ja pilveteenuste pakkujate andmebaasi- ja analüüsitoodetega. Ta on aidanud tehnoloogiaettevõtetel kavandada ja juurutada andmeanalüütika lahendusi ja tooteid.
Bosco Albuquerque on AWS-i vanempartnerlahenduste arhitekt ning tal on üle 20-aastane kogemus ettevõtete andmebaasimüüjate ja pilveteenuste pakkujate andmebaasi- ja analüüsitoodetega. Ta on aidanud tehnoloogiaettevõtetel kavandada ja juurutada andmeanalüütika lahendusi ja tooteid.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

