Tänapäeval kasutavad kliendid kõikidest tööstusharudest – olgu selleks finantsteenused, tervishoid ja bioteadused, reisimine ja hotellindus, meedia ja meelelahutus, telekommunikatsioon, tarkvara kui teenus (SaaS) ja isegi patenteeritud mudelite pakkujad –, et kasutada suuri keelemudeleid (LLM). luua rakendusi, nagu küsimuste ja vastuste (QnA) vestlusrobotid, otsingumootorid ja teadmistebaasid. Need generatiivne AI rakendusi ei kasutata mitte ainult olemasolevate äriprotsesside automatiseerimiseks, vaid neil on ka võimalus neid rakendusi kasutavate klientide kasutuskogemust muuta. Seoses edusammudega, mida tehakse selliste LLM-idega nagu Mixtral-8x7B Juhend, tuletis sellistest arhitektuuridest nagu ekspertide segu (KKM), otsivad kliendid pidevalt võimalusi generatiivsete AI-rakenduste jõudluse ja täpsuse parandamiseks, võimaldades samal ajal tõhusalt kasutada laiemat valikut suletud ja avatud lähtekoodiga mudeleid.
Tavaliselt kasutatakse LLM-i väljundi täpsuse ja jõudluse parandamiseks mitmeid tehnikaid, näiteks peenhäälestust parameetrite tõhus peenhäälestus (PEFT), tugevdav õppimine inimeste tagasisidest (RLHF), ja esinemine teadmiste destilleerimine. Generatiivsete AI-rakenduste loomisel saate aga kasutada alternatiivset lahendust, mis võimaldab välisteadmiste dünaamilist kaasamist ja võimaldab juhtida genereerimiseks kasutatavat teavet, ilma et peaksite oma olemasolevat alusmudelit viimistlema. See on koht, kus kasutatakse täiustatud genereerimist (Retrieval Augmented Generation, RAG), mis on mõeldud spetsiaalselt generatiivsete AI-rakenduste jaoks, mitte kallimatel ja jõulisematel peenhäälestusalternatiividel, millest oleme arutanud. Kui rakendate oma igapäevastes ülesannetes keerulisi RAG-rakendusi, võite oma RAG-süsteemidega kokku puutuda tavaliste probleemidega, nagu ebatäpne otsimine, dokumentide suurenev suurus ja keerukus ning konteksti ülevool, mis võivad oluliselt mõjutada loodud vastuste kvaliteeti ja usaldusväärsust. .
Selles postituses käsitletakse RAG-mustreid, et parandada vastuse täpsust, kasutades LangChaini ja tööriistu, nagu põhidokumendi retriiver, lisaks sellistele tehnikatele nagu kontekstuaalne tihendamine, et võimaldada arendajatel olemasolevaid generatiivseid AI-rakendusi täiustada.
Lahenduse ülevaade
Selles postituses demonstreerime teksti genereerimise Mixtral-8x7B Instruct kasutamist koos BGE Large En manustamismudeliga, et tõhusalt konstrueerida Amazon SageMakeri sülearvutis RAG QnA süsteem, kasutades algdokumendi otsimise tööriista ja kontekstipõhise tihendamise tehnikat. Selle lahenduse arhitektuuri illustreerib järgmine diagramm.
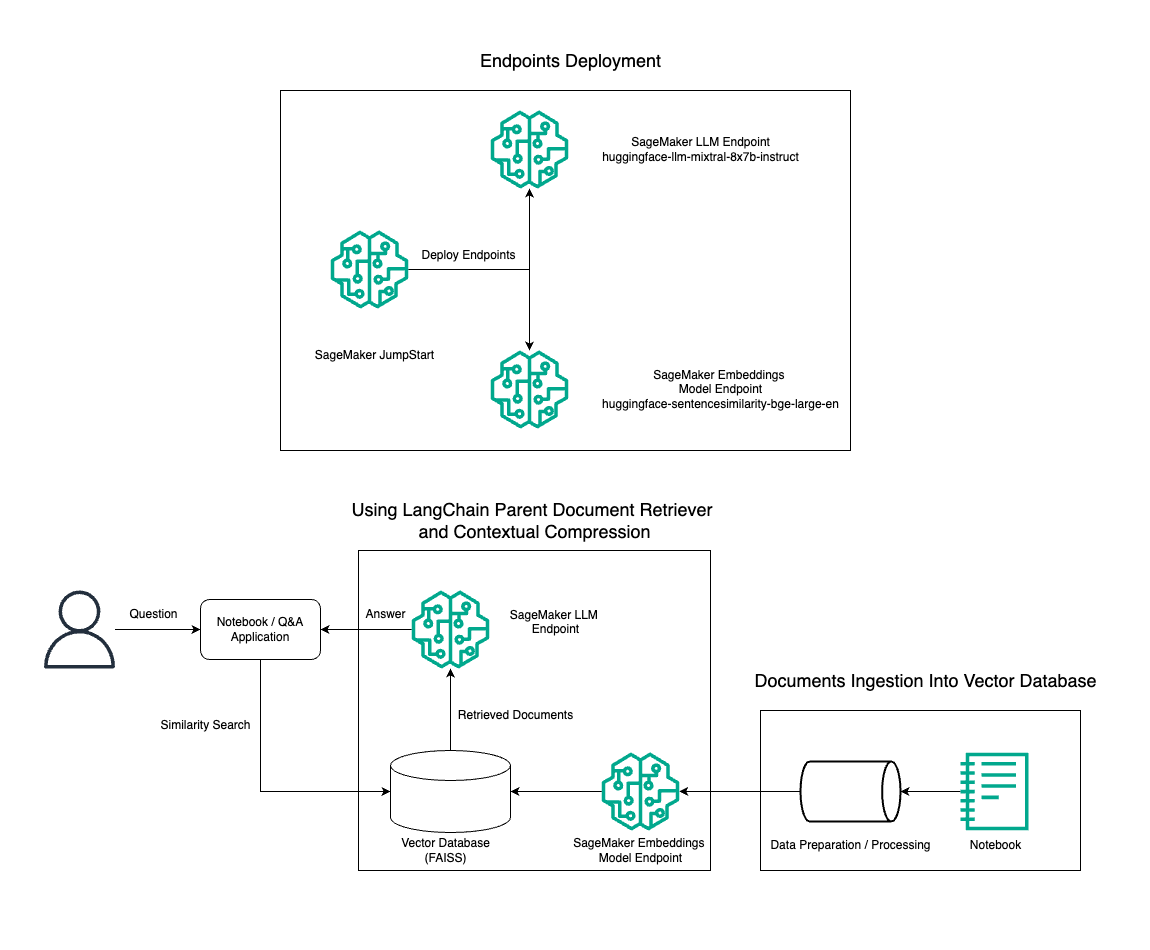
Saate selle lahenduse juurutada vaid mõne klõpsuga Amazon SageMaker JumpStart, täielikult hallatav platvorm, mis pakub tipptasemel alusmudeleid erinevateks kasutusjuhtudeks, nagu sisu kirjutamine, koodi genereerimine, küsimustele vastamine, tekstide kirjutamine, kokkuvõtete tegemine, klassifitseerimine ja teabe otsimine. See pakub komplekti eelkoolitatud mudeleid, mida saate kiiresti ja lihtsalt juurutada, kiirendades masinõppe (ML) rakenduste arendamist ja juurutamist. Üks SageMaker JumpStarti põhikomponente on Model Hub, mis pakub laia valikut eelkoolitatud mudeleid, nagu Mixtral-8x7B, erinevate ülesannete jaoks.
Mixtral-8x7B kasutab MoE arhitektuuri. See arhitektuur võimaldab närvivõrgu eri osadel spetsialiseeruda erinevatele ülesannetele, jagades töökoormuse tõhusalt mitme eksperdi vahel. See lähenemisviis võimaldab traditsiooniliste arhitektuuridega võrreldes tõhusamalt koolitada ja juurutada suuremaid mudeleid.
KKM arhitektuuri üks peamisi eeliseid on selle skaleeritavus. Jaotades töökoormuse mitme eksperdi vahel, saab KKM-mudeleid koolitada suuremate andmekogumite osas ja saavutada parema jõudluse kui sama suurusega traditsioonilised mudelid. Lisaks võivad MoE mudelid olla järelduste tegemisel tõhusamad, kuna antud sisendi jaoks tuleb aktiveerida ainult ekspertide alamhulk.
Lisateavet AWS-i Mixtral-8x7B juhise kohta leiate aadressilt Mixtral-8x7B on nüüd saadaval Amazon SageMaker JumpStartis. Mudel Mixtral-8x7B on piiranguteta kasutamiseks saadaval Apache 2.0 litsentsi alusel.
Selles postituses arutame, kuidas saate seda kasutada LangChain tõhusamate ja tõhusamate RAG-rakenduste loomiseks. LangChain on avatud lähtekoodiga Pythoni teek, mis on loodud rakenduste loomiseks koos LLM-idega. See pakub modulaarset ja paindlikku raamistikku LLM-ide kombineerimiseks teiste komponentidega, nagu teadmistebaasid, otsingusüsteemid ja muud AI-tööriistad, et luua võimsaid ja kohandatavaid rakendusi.
Käime läbi RAG torujuhtme ehitamise SageMakeris koos Mixtral-8x7B-ga. Me kasutame Mixtral-8x7B Instruct teksti genereerimise mudelit koos BGE Large En manustamismudeliga, et luua tõhus QnA süsteem, kasutades SageMakeri sülearvutis RAG-i. Kasutame eksemplari ml.t3.medium, et demonstreerida LLM-ide juurutamist SageMaker JumpStarti kaudu, millele pääseb juurde SageMakeri loodud API lõpp-punkti kaudu. See seadistus võimaldab LangChainiga täiustatud RAG-tehnikaid uurida, katsetada ja optimeerida. Samuti illustreerime FAISS Embeddingi poe integreerimist RAG-i töövoogu, tõstes esile selle rolli manuste salvestamisel ja toomisel, et parandada süsteemi jõudlust.
Teeme SageMakeri märkmiku lühikese ülevaate. Üksikasjalikumate ja samm-sammult juhiste saamiseks vaadake Täiustatud RAG-mustrid koos Mixtraliga SageMakeri Jumpstart GitHubi repos.
Vajadus täiustatud RAG-mustrite järele
Täiustatud RAG-mustrid on olulised, et parandada LLM-ide praegusi võimeid inimsarnase teksti töötlemisel, mõistmisel ja genereerimisel. Kuna dokumentide suurus ja keerukus suurenevad, võib dokumendi mitme tahu ühe manustamisega esindamine viia spetsiifilisuse kadumiseni. Kuigi on oluline tabada dokumendi üldist olemust, on sama oluline ära tunda ja esindada erinevaid alamtekste. See on väljakutse, millega puutute sageli kokku suuremate dokumentidega töötades. Veel üks RAG-i väljakutse on see, et otsingu puhul ei ole te teadlik konkreetsetest päringutest, mida teie dokumendisalvestussüsteem sisestamisel käsitleb. See võib viia selleni, et päringu jaoks kõige asjakohasem teave jääb teksti alla (konteksti ületäitumine). Ebaõnnestumise leevendamiseks ja olemasoleva RAG-arhitektuuri täiustamiseks saate kasutada täiustatud RAG-mustreid (emadokumendi otsija ja kontekstipõhine tihendamine), et vähendada otsinguvigu, parandada vastuste kvaliteeti ja võimaldada keerulist küsimuste käsitlemist.
Selles postituses käsitletud tehnikate abil saate lahendada välisteadmiste otsimise ja integreerimisega seotud peamisi väljakutseid, võimaldades teie rakendusel pakkuda täpsemaid ja kontekstiteadlikumaid vastuseid.
Järgmistes osades uurime, kuidas vanemdokumentide otsijad ja kontekstuaalne tihendamine võib aidata teil lahendada mõningaid meie käsitletud probleeme.
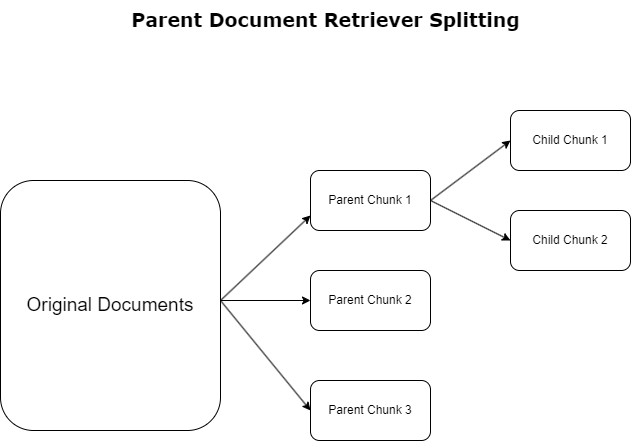
Vanemate dokumendi retriiver
Eelmises osas tõime esile väljakutsed, millega RAG-rakendused ulatuslike dokumentidega tegelemisel kokku puutuvad. Nende väljakutsetega toimetulemiseks vanemdokumentide otsijad kategoriseerida ja määrata sissetulevad dokumendid kui vanema dokumendid. Neid dokumente tunnustatakse nende kõikehõlmavuse tõttu, kuid neid ei kasutata otse manustamiseks algsel kujul. Selle asemel, et tihendada tervet dokumenti üheks manustamiseks, lahutavad põhidokumendi otsijad need põhidokumendid lapse dokumendid. Iga alamdokument hõlmab laiema põhidokumendi erinevaid aspekte või teemasid. Pärast nende alamsegmentide tuvastamist määratakse igaühele individuaalsed manused, mis kajastavad nende spetsiifilist temaatilist olemust (vt järgmist diagrammi). Otsimise ajal käivitatakse põhidokument. See tehnika pakub sihipäraseid, kuid laiaulatuslikke otsinguvõimalusi, pakkudes LLM-ile laiemat perspektiivi. Vanemdokumendi otsijad pakuvad LLM-idele kahekordse eelise: alamdokumentide manustamise spetsiifilisus täpse ja asjakohase teabe otsimiseks koos vanemate dokumentide kutsumisega vastuse genereerimiseks, mis rikastab LLM-i väljundeid kihilise ja põhjaliku kontekstiga.
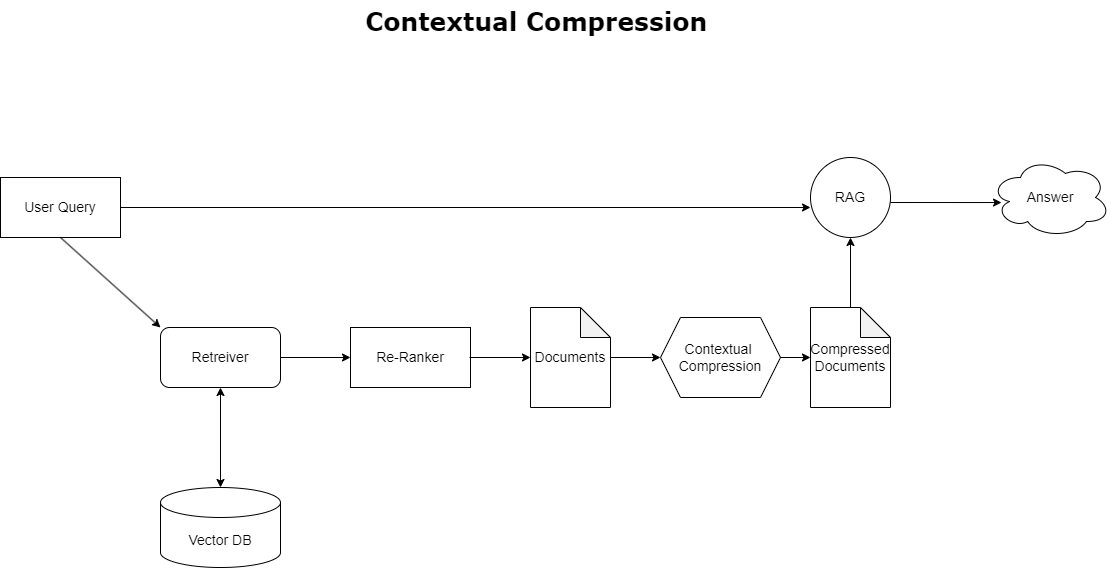
Kontekstuaalne tihendamine
Varem käsitletud konteksti ületäitumise probleemi lahendamiseks võite kasutada kontekstuaalne tihendamine otsitud dokumentide tihendamiseks ja filtreerimiseks päringu kontekstiga vastavuses, nii et säilitatakse ja töödeldakse ainult asjakohast teavet. See saavutatakse algse dokumentide toomise põhiretriiveri ja nende dokumentide täpsustamiseks mõeldud dokumendikompressori kombinatsiooni abil, vähendades nende sisu või välistades need täielikult asjakohasuse alusel, nagu on näidatud järgmisel diagrammil. See lihtsustatud lähenemine, mida hõlbustab kontekstuaalne tihendusretriiver, suurendab oluliselt RAG-i rakenduse tõhusust, pakkudes meetodit teabemassist ainult olulise eraldamiseks ja kasutamiseks. See lahendab teabe ülekülluse ja ebaolulise andmetöötluse probleemi, mis toob kaasa parema vastuse kvaliteedi, kulutõhusamad LLM-toimingud ja sujuvama üldise otsinguprotsessi. Põhimõtteliselt on see filter, mis kohandab teabe vastavalt päringule, muutes selle väga vajalikuks tööriistaks arendajatele, kes soovivad optimeerida oma RAG-rakendusi parema jõudluse ja kasutajate rahulolu saavutamiseks.
Eeldused
Kui olete SageMakeri uus kasutaja, vaadake jaotist Amazon SageMakeri arendusjuhend.
Enne lahendusega alustamist looge AWS-i konto. AWS-i konto loomisel saate ühekordse sisselogimise (SSO) identiteedi, millel on täielik juurdepääs konto kõikidele AWS-i teenustele ja ressurssidele. Seda identiteeti nimetatakse AWS-i kontoks juurkasutaja.
Sisselogimine teenusesse AWS-i juhtimiskonsool konto loomisel kasutatud e-posti aadressi ja parooli kasutamine annab teile täieliku juurdepääsu oma konto kõikidele AWS-i ressurssidele. Soovitame tungivalt mitte kasutada juurkasutajat igapäevaste, isegi haldustoimingute jaoks.
Selle asemel järgige turvalisuse parimad tavad in AWS-i identiteedi- ja juurdepääsuhaldus (IAM) ja luua administraatorikasutaja ja grupp. Seejärel lukustage turvaliselt juurkasutaja mandaadid ja kasutage neid vaid mõne konto- ja teenusehaldustoimingu tegemiseks.
Mudel Mixtral-8x7b nõuab ml.g5.48xsuurt eksemplari. SageMaker JumpStart pakub lihtsustatud viisi juurdepääsuks ja juurutamiseks enam kui 100 erinevale avatud lähtekoodiga ja kolmanda osapoole alusmudelile. Selleks, et käivitage SageMaker JumpStartist Mixtral-8x7B hostimiseks lõpp-punkt, peate võib-olla taotlema teenusekvoodi suurendamist, et pääseda ligi ml.g5.48xlarge eksemplarile lõpp-punkti kasutamise jaoks. Sa saad taotleda teenusekvooti konsooli kaudu, AWS-i käsurea liides (AWS CLI) või API, et võimaldada neile lisaressurssidele juurdepääsu.
Seadistage SageMakeri märkmiku eksemplar ja installige sõltuvused
Alustamiseks looge SageMakeri märkmiku eksemplar ja installige vajalikud sõltuvused. Vaadake GitHub repo eduka seadistamise tagamiseks. Pärast sülearvuti eksemplari seadistamist saate mudeli juurutada.
Samuti saate sülearvutit kohapeal käitada eelistatud integreeritud arenduskeskkonnas (IDE). Veenduge, et teil oleks Jupyteri sülearvutilabor installitud.
Mudeli juurutamine
Juurutage Mixtral-8X7B Instruct LLM mudel SageMaker JumpStartis:
Juurutage BGE Large En manustamismudel saidil SageMaker JumpStart:
Seadistage LangChain
Pärast kõigi vajalike teekide importimist ning mudeli Mixtral-8x7B ja BGE Large En manustamismudeli juurutamist saate nüüd seadistada LangChaini. Üksikasjalikud juhised leiate jaotisest GitHub repo.
Andmete ettevalmistamine
Selles postituses kasutame QnA teostamiseks tekstikorpusena mitu aastat Amazoni kirju aktsionäridele. Andmete ettevalmistamise üksikasjalikumate sammude kohta vaadake jaotist GitHub repo.
Küsimusele vastamine
Kui andmed on ette valmistatud, saate kasutada LangChaini pakutavat ümbrist, mis ümbritseb vektormälu ja võtab sisendi LLM-i jaoks. See ümbris täidab järgmised toimingud:
- Võtke sisendküsimus.
- Looge küsimuse manustamine.
- Hankige asjakohased dokumendid.
- Lisage dokumendid ja küsimus viipasse.
- Käivitage mudel viipaga ja genereerige vastus loetaval viisil.
Nüüd, kui vektorite pood on paigas, võite hakata küsimusi esitama:
Tavaline retriiveri kett
Eelmises stsenaariumis uurisime kiiret ja lihtsat viisi, kuidas saada oma küsimusele kontekstiteadlik vastus. Vaatame nüüd RetrievalQA abil kohandatavamat valikut, kus saate parameetriga chain_type abil kohandada, kuidas tuuakse dokumendid viipale lisada. Samuti, et kontrollida, kui palju asjakohaseid dokumente tuleks alla laadida, saate järgmises koodis muuta parameetrit k, et näha erinevaid väljundeid. Paljude stsenaariumide korral võiksite teada, milliseid lähtedokumente LLM vastuse genereerimiseks kasutas. Saate need dokumendid väljundisse hankida kasutades return_source_documents, mis tagastab dokumendid, mis on lisatud LLM-viiba konteksti. RetrievalQA võimaldab teil pakkuda ka kohandatud viipamalli, mis võib olla mudelile spetsiifiline.
Esitame küsimuse:
Vanemdokumentide retriiveri kett
Vaatame täiustatud RAG-i võimalust abiga ParentDocumentRetriiver. Dokumendi otsimisega töötades võite leida kompromissi täpse manustamise jaoks väikeste dokumentide ja suuremate dokumentide salvestamise vahel, et säilitada rohkem konteksti. Algdokumendi retriiver saavutab selle tasakaalu, jagades ja salvestades väikesed andmetükid.
Kasutame a parent_splitter et jagada originaaldokumendid suuremateks tükkideks, mida nimetatakse põhidokumentideks ja a child_splitter algdokumentidest väiksemate alamdokumentide loomiseks:
Seejärel indekseeritakse alamdokumendid vektormälus, kasutades manuseid. See võimaldab asjakohaste alamdokumentide tõhusat hankimist sarnasuse alusel. Asjakohase teabe hankimiseks hangib ülemdokumendi taastaja esmalt alamdokumendid vektorsalvest. Seejärel otsib see nende alamdokumentide vanemate ID-d ja tagastab vastavad suuremad vanemadokumendid.
Esitame küsimuse:
Kontekstuaalne tihendusahel
Vaatame veel ühte täiustatud RAG-i valikut kontekstuaalne tihendamine. Üks otsinguga seotud väljakutseid on see, et tavaliselt me ei tea konkreetseid päringuid, millega teie dokumendisalvestussüsteem andmete süsteemi sisestamisel kokku puutub. See tähendab, et päringu jaoks kõige olulisem teave võib olla maetud dokumenti, milles on palju ebaolulist teksti. Selle täieliku dokumendi edastamine oma rakenduse kaudu võib põhjustada kulukamaid LLM-kõnesid ja kehvemaid vastuseid.
Kontekstuaalne tihendusretriiver lahendab väljakutse hankida asjakohane teave dokumendisalvestussüsteemist, kus asjakohased andmed võivad olla maetud palju teksti sisaldavatesse dokumentidesse. Väljaotsitud dokumentide tihendamisel ja filtreerimisel antud päringukonteksti alusel tagastatakse ainult kõige olulisem teave.
Kontekstipõhise tihendamise retriiveri kasutamiseks vajate järgmist.
- Põhiline retriiver – See on esialgne retriiver, mis hangib päringu alusel salvestussüsteemist dokumendid
- Dokumendikompressor – See komponent võtab algselt välja otsitud dokumendid ja lühendab neid, vähendades üksikute dokumentide sisu või loobudes ebaolulised dokumendid üldse, kasutades asjakohasuse määramiseks päringu konteksti
Kontekstuaalse tihendamise lisamine LLM-ahela ekstraktoriga
Esmalt mähkige oma põhiretriiver a-ga ContextualCompressionRetriever. Lisate an LLMChainExtractor, mis kordab algselt tagastatud dokumente ja eraldab igaühest ainult päringu jaoks asjakohase sisu.
Käivitage kett, kasutades nuppu ContextualCompressionRetriever koos LLMChainExtractor ja edastage viip chain_type_kwargs argument.
Esitame küsimuse:
Filtreerige dokumente LLM kettfiltriga
. LLMChainFilter on veidi lihtsam, kuid tugevam kompressor, mis kasutab LLM-i ahelat, et otsustada, millised algselt hangitud dokumentidest välja filtreerida ja millised tagastada, ilma dokumendi sisuga manipuleerimata:
Käivitage kett, kasutades nuppu ContextualCompressionRetriever koos LLMChainFilter ja edastage viip chain_type_kwargs argument.
Esitame küsimuse:
Võrrelge tulemusi
Järgmises tabelis võrreldakse erinevate päringute tulemusi vastavalt tehnikale.
| Tehnika | Päring 1 | Päring 2 | võrdlus |
| Kuidas AWS arenes? | Miks Amazon on edukas? | ||
| Regulaarne retriiveri ahela väljund | AWS (Amazon Web Services) arenes algselt kahjumlikust investeeringust 85 miljardi dollari suuruse aastase tulumääraga äriks, millel on suur kasumlikkus, pakkudes laia valikut teenuseid ja funktsioone ning muutudes oluliseks osaks Amazoni portfellist. Vaatamata skeptitsismile ja lühiajalistele vastutuultele jätkas AWS uuenduste tegemist, uute klientide meelitamist ja aktiivsete klientide migreerimist, pakkudes selliseid eeliseid nagu paindlikkus, uuenduslikkus, kuluefektiivsus ja turvalisus. AWS laiendas ka oma pikaajalisi investeeringuid, sealhulgas kiibi arendamist, et pakkuda uusi võimalusi ja muuta oma klientide jaoks võimalikke. | Amazon on edukas tänu oma pidevale innovatsioonile ja laienemisele uutele valdkondadele, nagu tehnoloogilise infrastruktuuri teenused, digitaalsed lugemisseadmed, hääljuhitavad isiklikud assistendid ja uued ärimudelid, nagu kolmandate osapoolte turg. Selle edule aitab kaasa ka selle võime operatsioone kiiresti skaleerida, nagu on näha selle täitmise ja transpordivõrkude kiires laienemises. Lisaks on Amazoni keskendumine oma protsesside optimeerimisele ja tõhususe suurendamisele toonud kaasa tootlikkuse paranemise ja kulude vähenemise. Amazon Businessi näide tõstab esile ettevõtte võimet kasutada oma e-kaubanduse ja logistika tugevaid külgi erinevates sektorites. | Tavalise retriiveriahela vastuste põhjal märkame, et kuigi see annab pikki vastuseid, kannatab see konteksti ületäitumise all ja ei maini korpuse olulisi üksikasju, mis puudutavad esitatud päringule vastamist. Tavaline otsinguahel ei suuda nüansse tabada sügavuse või kontekstipõhise ülevaatega, mis võib puududa dokumendi kriitilistest aspektidest. |
| Vanema dokumendi retriiveri väljund | AWS (Amazon Web Services) sai alguse teenuse Elastic Compute Cloud (EC2) esmasest funktsioonivaesest käivitamisest 2006. aastal, pakkudes ainult ühte eksemplari suurust ühes andmekeskuses, ühes maailma piirkonnas ja ainult Linuxi operatsioonisüsteemi eksemplare. ja ilma paljude põhifunktsioonideta, nagu jälgimine, koormuse tasakaalustamine, automaatne skaleerimine või püsisalvestus. Kuid AWS-i edu võimaldas neil kiiresti itereerida ja lisada puuduvad võimalused, lõpuks laienedes, et pakkuda erinevaid maitseid, suurusi ja arvutus-, salvestus- ja võrgustamisvõimalusi, samuti arendada oma kiipe (Graviton), et tõsta hinda ja jõudlust veelgi. . AWS-i iteratiivne innovatsiooniprotsess nõudis 20 aasta jooksul märkimisväärseid investeeringuid rahalistesse ja inimressurssidesse, sageli enne selle tasumist, et rahuldada klientide vajadusi ning parandada pikaajalisi kliendikogemusi, lojaalsust ja aktsionäride tulu. | Amazon on edukas tänu oma võimele pidevalt uuendusi teha, kohaneda muutuvate turutingimustega ja vastata klientide vajadustele erinevates turusegmentides. See on ilmne Amazon Businessi edus, mille aastane brutomüük on kasvanud ligikaudu 35 miljardi dollarini, pakkudes äriklientidele valikut, väärtust ja mugavust. Amazoni investeeringud e-kaubandusse ja logistikasse on võimaldanud luua ka selliseid teenuseid nagu Buy with Prime, mis aitab otse tarbijale suunatud veebisaitidega kaupmeestel suunata konversioone vaatamistelt ostudele. | Emadokumendi retriiver uurib sügavamalt AWS-i kasvustrateegia eripärasid, sealhulgas klientide tagasiside põhjal uute funktsioonide iteratiivset lisamise protsessi ja üksikasjalikku teekonda funktsioonivaesest esialgsest turuletoomisest turgu valitseva positsioonini, pakkudes samas kontekstirohket vastust. . Vastused hõlmavad paljusid aspekte tehnilistest uuendustest ja turustrateegiast organisatsiooni tõhususe ja kliendikesksuseni, pakkudes koos näidetega terviklikku ülevaadet edu soodustavatest teguritest. Selle põhjuseks võib olla algdokumendi retriiveri sihitud, kuid laiaulatuslikud otsinguvõimalused. |
| LLM-ahela ekstraktor: kontekstipõhine tihendusväljund | AWS arenes, alustades väikese projektina Amazonis, nõudes märkimisväärseid kapitaliinvesteeringuid ja silmitsi skeptitsismiga nii ettevõtte sees kui ka väljaspool. AWS-il oli aga potentsiaalsete konkurentide ees edumaa ja ta uskus väärtusse, mida see võib klientidele ja Amazonile tuua. AWS võttis pikaajalise kohustuse jätkata investeerimist, mille tulemusel toodi 3,300. aastal turule üle 2022 uue funktsiooni ja teenuse. AWS on muutnud seda, kuidas kliendid oma tehnoloogilise infrastruktuuri haldavad, ja sellest on saanud 85 miljardi dollari suurune aastakasum, millel on suur kasumlikkus. AWS on ka oma pakkumisi pidevalt täiustanud, näiteks täiustanud EC2 lisafunktsioonide ja -teenustega pärast selle esmast käivitamist. | Pakutud konteksti põhjal võib Amazoni edu seostada strateegilise laienemisega raamatumüügiplatvormilt ülemaailmsele turule, kus on elav kolmanda osapoole müüjate ökosüsteem, varajasele investeeringule AWS-i, uuendustele Kindle'i ja Alexa kasutuselevõtul ning olulisele kasvule. aasta tuludes aastatel 2019–2022. See kasv tõi kaasa täitmiskeskuste jalajälje laiendamise, viimase miili transpordivõrgu loomise ja uue sorteerimiskeskuste võrgu ehitamise, mis optimeeriti tootlikkuse ja kulude vähendamiseks. | LLM-ketiga ekstraktor säilitab tasakaalu võtmepunktide põhjaliku katmise ja tarbetu sügavuse vältimise vahel. See kohandub dünaamiliselt päringu kontekstiga, nii et väljund on otseselt asjakohane ja kõikehõlmav. |
| LLM-ahela filter: kontekstipõhine tihendusväljund | AWS (Amazon Web Services) arenes välja, käivitades algselt funktsioonivaene, kuid klientide tagasiside põhjal kiiresti itereerides, et lisada vajalikke võimalusi. See lähenemisviis võimaldas AWS-il käivitada 2. aastal piiratud funktsioonidega EC2006 ja lisada seejärel pidevalt uusi funktsioone, nagu täiendavad eksemplari suurused, andmekeskused, piirkonnad, operatsioonisüsteemi valikud, jälgimistööriistad, koormuse tasakaalustamine, automaatne skaleerimine ja püsisalvestus. Aja jooksul muutus AWS funktsioonivaesest teenusest mitme miljardi dollari suuruseks ettevõtteks, keskendudes klientide vajadustele, paindlikkusele, innovatsioonile, kuluefektiivsusele ja turvalisusele. AWS-i aastane tulumäär on nüüd 85 miljardit dollarit ja see pakub igal aastal üle 3,300 uue funktsiooni ja teenuse, mis on mõeldud paljudele klientidele alustavatest ettevõtetest rahvusvaheliste ettevõtete ja avaliku sektori organisatsioonideni. | Amazon on edukas tänu oma uuenduslikele ärimudelitele, pidevatele tehnoloogilistele edusammudele ja strateegilistele organisatsioonilistele muudatustele. Ettevõte on järjekindlalt häirinud traditsioonilisi tööstusharusid, tutvustades uusi ideid, nagu pood erinevate toodete ja teenuste jaoks, kolmanda osapoole turg, pilveinfrastruktuuriteenused (AWS), Kindle e-luger ja Alexa hääljuhitav isiklik assistent. . Lisaks on Amazon teinud oma tõhususe parandamiseks struktuurilisi muudatusi, näiteks reorganiseerinud oma USA täitmisvõrgustiku, et vähendada kulusid ja tarneaegu, aidates sellega veelgi kaasa selle edule. | Sarnaselt LLM-i ketiekstraktoriga tagab LLM-i kettfilter selle, et kuigi põhipunktid on kaetud, on väljund tõhus klientidele, kes otsivad sisutihedaid ja kontekstuaalseid vastuseid. |
Nende erinevate tehnikate võrdlemisel näeme, et sellistes kontekstides nagu AWS-i ülemineku üksikasjad lihtsast teenusest keeruliseks, mitme miljardi dollari suuruseks üksuseks või Amazoni strateegiliste edusammude selgitamine, puudub tavalisel retriiveriahelal täpsus, mida pakuvad keerukamad tehnikad. mis viib vähem sihitud teabeni. Kuigi käsitletud täiustatud tehnikate vahel on väga vähe erinevusi, on need palju informatiivsemad kui tavalised retriiveriketid.
Sellistes tööstusharudes nagu tervishoid, telekommunikatsioon ja finantsteenused klientidele, kes soovivad oma rakendustes rakendada RAG-i, muudavad tavalise retriiveriahela piirangud täpsuse, liiasuse vältimise ja teabe tõhusa tihendamise osas selle nende vajaduste täitmiseks vähem sobivaks. arenenumatele põhidokumentide otsimis- ja kontekstipõhise tihendamise tehnikatele. Need tehnikad suudavad destilleerida tohutul hulgal teavet kontsentreeritud ja mõjusa ülevaate saamiseks, mida vajate, aidates samal ajal parandada hinna ja kvaliteedi suhet.
Koristage
Kui olete märkmiku käitamise lõpetanud, kustutage loodud ressursid, et vältida kasutatavate ressursside eest tasude kogunemist.
Järeldus
Selles postituses tutvustasime lahendust, mis võimaldab teil rakendada põhidokumendi otsimise ja kontekstipõhise tihendusahela tehnikaid, et parandada LLM-ide võimet teavet töödelda ja genereerida. Testisime neid täiustatud RAG-tehnikaid mudelitega Mixtral-8x7B Instruct ja BGE Large En, mis on saadaval SageMaker JumpStartiga. Uurisime ka püsiva salvestusruumi kasutamist manuste ja dokumenditükkide jaoks ning integreerimist ettevõtte andmesalvedega.
Tehnikad, mida me kasutasime, mitte ainult ei täpsusta viisi, kuidas LLM-mudelid pääsevad juurde välistele teadmistele ja kaasavad neid, vaid parandavad oluliselt ka nende väljundite kvaliteeti, asjakohasust ja tõhusust. Kombineerides otsingu suurtest tekstikorpustest keele genereerimise võimalustega, võimaldavad need täiustatud RAG-tehnikad LLM-idel toota faktilisemaid, sidusamaid ja kontekstile vastavaid vastuseid, parandades nende jõudlust mitmesuguste loomuliku keele töötlemise ülesannete puhul.
Selle lahenduse keskmes on SageMaker JumpStart. SageMaker JumpStartiga saate juurdepääsu avatud ja suletud lähtekoodiga mudelite ulatuslikule valikule, lihtsustades ML-iga alustamise protsessi ning võimaldades kiiret katsetamist ja juurutamist. Selle lahenduse juurutamise alustamiseks navigeerige rakenduses sülearvutisse GitHub repo.
Autoritest
 Niithiyn Vijeaswaran on AWS-i lahenduste arhitekt. Tema fookusvaldkond on generatiivsed AI ja AWS AI kiirendid. Tal on bakalaureusekraad arvutiteaduses ja bioinformaatikas. Niithiyn teeb tihedat koostööd Generative AI GTM meeskonnaga, et võimaldada AWS-i klientidel mitmel rindel ja kiirendada nende generatiivse AI kasutuselevõttu. Ta on kirglik Dallas Mavericksi fänn ja talle meeldib tosse koguda.
Niithiyn Vijeaswaran on AWS-i lahenduste arhitekt. Tema fookusvaldkond on generatiivsed AI ja AWS AI kiirendid. Tal on bakalaureusekraad arvutiteaduses ja bioinformaatikas. Niithiyn teeb tihedat koostööd Generative AI GTM meeskonnaga, et võimaldada AWS-i klientidel mitmel rindel ja kiirendada nende generatiivse AI kasutuselevõttu. Ta on kirglik Dallas Mavericksi fänn ja talle meeldib tosse koguda.
 Sebastian Bustillo on AWS-i lahenduste arhitekt. Ta keskendub tehisintellekti/ML-tehnoloogiatele, olles sügavalt kirglik generatiivsete AI ja arvutuskiirendite vastu. AWS-is aitab ta klientidel generatiivse AI abil avada äriväärtust. Kui ta ei ole tööl, naudib ta täiusliku tassi kohvi valmistamist ja oma naisega maailma avastamist.
Sebastian Bustillo on AWS-i lahenduste arhitekt. Ta keskendub tehisintellekti/ML-tehnoloogiatele, olles sügavalt kirglik generatiivsete AI ja arvutuskiirendite vastu. AWS-is aitab ta klientidel generatiivse AI abil avada äriväärtust. Kui ta ei ole tööl, naudib ta täiusliku tassi kohvi valmistamist ja oma naisega maailma avastamist.
 Armando Diaz on AWS-i lahenduste arhitekt. Ta keskendub generatiivsele AI-le, AI/ML-ile ja andmeanalüüsile. AWS-is aitab Armando klientidel integreerida oma süsteemidesse tipptasemel generatiivse AI-võimalusi, edendades innovatsiooni ja konkurentsieelist. Kui ta pole tööl, naudib ta oma naise ja perega aega veetmist, matkamist ja maailmas reisimist.
Armando Diaz on AWS-i lahenduste arhitekt. Ta keskendub generatiivsele AI-le, AI/ML-ile ja andmeanalüüsile. AWS-is aitab Armando klientidel integreerida oma süsteemidesse tipptasemel generatiivse AI-võimalusi, edendades innovatsiooni ja konkurentsieelist. Kui ta pole tööl, naudib ta oma naise ja perega aega veetmist, matkamist ja maailmas reisimist.
 Dr Farooq Sabir on AWS-i tehisintellekti ja masinõppe lahenduste vanemarhitekt. Tal on doktori- ja magistrikraad elektrotehnika alal Texase ülikoolist Austinis ning magistrikraadi arvutiteaduses Georgia Tehnoloogiainstituudist. Tal on üle 15-aastane töökogemus ning talle meeldib õpetada ja juhendada ka kolledži üliõpilasi. AWS-is aitab ta klientidel sõnastada ja lahendada äriprobleeme andmeteaduse, masinõppe, arvutinägemise, tehisintellekti, numbrilise optimeerimise ja sellega seotud valdkondades. Teksases Dallases asuv talle ja ta perele meeldib reisida ja pikki teereise teha.
Dr Farooq Sabir on AWS-i tehisintellekti ja masinõppe lahenduste vanemarhitekt. Tal on doktori- ja magistrikraad elektrotehnika alal Texase ülikoolist Austinis ning magistrikraadi arvutiteaduses Georgia Tehnoloogiainstituudist. Tal on üle 15-aastane töökogemus ning talle meeldib õpetada ja juhendada ka kolledži üliõpilasi. AWS-is aitab ta klientidel sõnastada ja lahendada äriprobleeme andmeteaduse, masinõppe, arvutinägemise, tehisintellekti, numbrilise optimeerimise ja sellega seotud valdkondades. Teksases Dallases asuv talle ja ta perele meeldib reisida ja pikki teereise teha.
 Marco Punio on lahenduste arhitekt, kes keskendub generatiivsele AI-strateegiale, rakenduslikele AI-lahendustele ja uuringute läbiviimisele, et aidata klientidel AWS-i osas hüpermastaabis töötada. Marco on digitaalse natiivse pilvenõustaja, kellel on kogemusi finantstehnoloogia, tervishoiu ja bioteaduste, tarkvara kui teenusena ja hiljuti telekommunikatsioonitööstuses. Ta on kvalifitseeritud tehnoloog, kelle kirg on masinõpe, tehisintellekt ning ühinemised ja omandamised. Marco asub Seattle'is, WA ja talle meeldib vabal ajal kirjutada, lugeda, treenida ja rakendusi koostada.
Marco Punio on lahenduste arhitekt, kes keskendub generatiivsele AI-strateegiale, rakenduslikele AI-lahendustele ja uuringute läbiviimisele, et aidata klientidel AWS-i osas hüpermastaabis töötada. Marco on digitaalse natiivse pilvenõustaja, kellel on kogemusi finantstehnoloogia, tervishoiu ja bioteaduste, tarkvara kui teenusena ja hiljuti telekommunikatsioonitööstuses. Ta on kvalifitseeritud tehnoloog, kelle kirg on masinõpe, tehisintellekt ning ühinemised ja omandamised. Marco asub Seattle'is, WA ja talle meeldib vabal ajal kirjutada, lugeda, treenida ja rakendusi koostada.
 AJ Dhimine on AWS-i lahenduste arhitekt. Ta on spetsialiseerunud generatiivsele AI-le, serverita andmetöötlusele ja andmeanalüütikale. Ta on masinõppe tehnilise valdkonna kogukonna aktiivne liige/mentor ja avaldanud mitmeid teadusartikleid erinevatel AI/ML teemadel. Ta töötab klientidega alates idufirmadest kuni ettevõteteni, et arendada AWSome generatiivseid AI-lahendusi. Ta on eriti kirglik suurte keelemudelite kasutamise vastu täiustatud andmeanalüütika jaoks ja praktiliste rakenduste uurimise vastu, mis lahendavad tegelikke väljakutseid. Väljaspool tööd naudib AJ reisimist ja on praegu 53 riigis eesmärgiga külastada kõiki maailma riike.
AJ Dhimine on AWS-i lahenduste arhitekt. Ta on spetsialiseerunud generatiivsele AI-le, serverita andmetöötlusele ja andmeanalüütikale. Ta on masinõppe tehnilise valdkonna kogukonna aktiivne liige/mentor ja avaldanud mitmeid teadusartikleid erinevatel AI/ML teemadel. Ta töötab klientidega alates idufirmadest kuni ettevõteteni, et arendada AWSome generatiivseid AI-lahendusi. Ta on eriti kirglik suurte keelemudelite kasutamise vastu täiustatud andmeanalüütika jaoks ja praktiliste rakenduste uurimise vastu, mis lahendavad tegelikke väljakutseid. Väljaspool tööd naudib AJ reisimist ja on praegu 53 riigis eesmärgiga külastada kõiki maailma riike.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

