Amazon EU Design and Construction (Amazon D&C) meeskond on Amazoni ladusid projekteeriv ja ehitav insenerimeeskond. Meeskond navigeerib suures mahus dokumentides ja leiab õige teabe, et tagada laokujunduse vastavus kõrgeimatele standarditele. Postituses Generatiivne AI-toega lahendus rakenduses Amazon SageMaker, mis aitab Amazoni ELi projekteerimisel ja ehitamisel, esitasime küsimusele vastamise robotlahendusele, kasutades a Täiustatud põlvkonna otsimine (RAG) torujuhe peenhäälestusega suur keelemudel (LLM), et Amazon D&C saaks tõhusalt hankida täpset teavet suurest hulgast korrastamata dokumentidest ning pakkuda oma ehitusprojektides õigeaegseid ja kvaliteetseid teenuseid. Amazon D&C meeskond rakendas lahenduse Amazoni inseneride pilootprojektina ja kogus kasutajate tagasisidet.
Selles postituses jagame, kuidas analüüsisime tagasisideandmeid ja tuvastasime RAG-i pakutud täpsuse ja hallutsinatsioonide piirangud ning kasutasime inimese hindamise skoori mudeli koolitamiseks. tugevdamise õppimine. Parema õppimise jaoks koolitusnäidiste suurendamiseks kasutasime tagasiside skooride loomiseks ka teist LLM-i. See meetod käsitles RAG-i piirangut ja parandas veelgi robotite vastuse kvaliteeti. Tutvustame tugevdamise õppeprotsessi ja võrdlusuuringu tulemusi, et näidata LLM-i jõudluse paranemist. Lahendus kasutab Amazon SageMaker JumpStart kui mudeli juurutamise, peenhäälestuse ja tugevdamise õppimise põhiteenus.
Koguge pilootprojekti raames tagasisidet Amazoni inseneridelt
Pärast punktis kirjeldatud lahenduse väljatöötamist Generatiivne AI-toega lahendus rakenduses Amazon SageMaker, mis aitab Amazoni ELi projekteerimisel ja ehitamisel, võttis Amazoni D&C meeskond lahenduse kasutusele ja viis koos Amazoni inseneridega pilootprojekti. Insenerid pääsesid pilootsüsteemi juurde veebirakenduse kaudu, mille on välja töötanud Vooluvalgus, mis on ühendatud RAG torujuhtmega. Valmistamisel kasutasime Amazon OpenSearchi teenus vektori andmebaasi jaoks ja juurutas Amazon SageMakeris peenhäälestatud Mistral-7B-Instruct mudeli.
Üks pilootprojekti põhieesmärke on koguda Amazoni inseneridelt tagasisidet ja kasutada tagasisidet LLM-i hallutsinatsioonide edasiseks vähendamiseks. Selle saavutamiseks töötasime kasutajaliideses välja tagasiside kogumise mooduli, nagu on näidatud järgmisel joonisel, ning salvestasime veebiseansi teabe ja kasutajate tagasiside Amazon DynamoDB. Tagasiside kogumise kasutajaliidese kaudu saavad Amazoni insenerid valida viie rahulolu taseme vahel: täiesti ei nõustu, ei nõustu, neutraalne, nõustun ja täielikult nõus, mis vastavad tagasiside skooridele vahemikus 1–5. Samuti saavad nad anda parema vastuse küsimusele või kommenteerida, miks LLM-i vastus ei ole rahuldav.
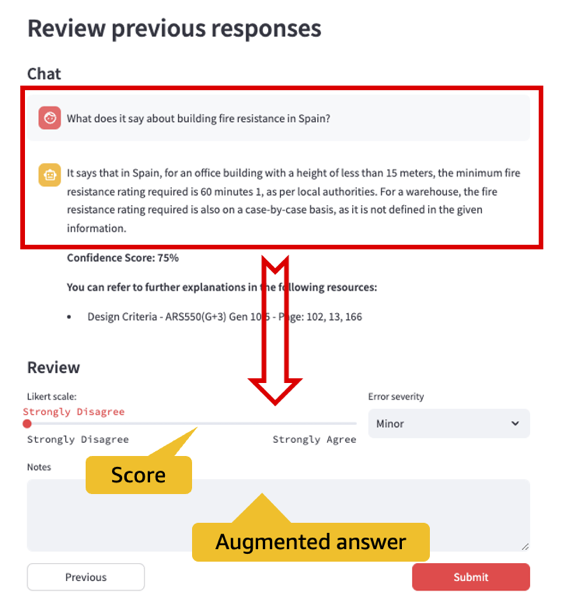
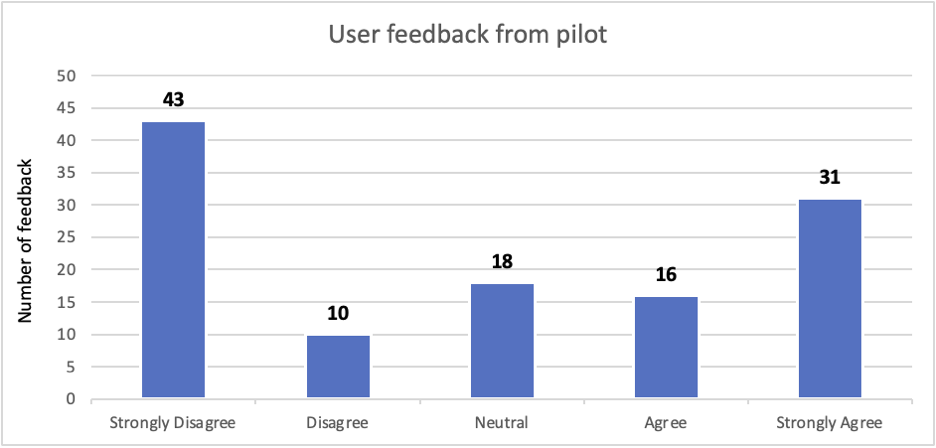
Pilootprojekti ajal andsid kasutajad 118 tagasisidevastust. Järgmine diagramm näitab jaotust negatiivsest positiivseks. Märkasime, et negatiivse tagasisidega tähistatud valesid vastuseid (ei nõustu ja ei nõustu) on kogu tagasisidest 45% (53 vastust 118-st). Mõningaid vigu (umbes 10% negatiivsest tagasisidest ja 7.5% üldistest vastustest) saab lahendada kasutajahariduse ja kiire inseneritööga. Lisaks saame probleemi lahendada järgmises jaotises kirjeldatud LLM-i peenhäälestus- ja tugevdamisõppe lahendusega.
Mõned kasutajad jätsid lihtsalt märkuse, näiteks "Suurepärane!" täielikult nõus olevate vastuste jaoks või "Ei vasta küsimusele" täiesti mittenõusolevate vastuste jaoks. Teised kasutajad andsid hinded ja selgitasid, kuidas nad oma märkustes LLM-i vastuseid põhjendavad. Järgmises näites esitas kasutaja konkreetselt LLM-i hallutsinatsiooni parandamiseks piisava dokumendi ja sisu.
| Küsimus | Kui palju meil parkimiskohti on? |
| Boti vastus |
Antud kontekstist lähtudes pole meil piisavalt infot parkimiskohtade arvu määramiseks. Kontekstis käsitletakse parkimiskohtade miinimumsuurust ja nõudeid välisvalgustuse tasemetele, kuid konkreetset parkimiskohtade arvu pole ette nähtud. ** Täiendavaid selgitusi leiate järgmistest allikatest:** * ARS GEN 10.0/05.01.02. Kujunduskriteeriumid ja lisad/jõudluspakett AR Sorteeritavad disainikriteeriumid v20.1.1.pdf – lehekülg: 10 * ARS GEN 10.0/05.01.02. Kujunduskriteeriumid ja lisad/jõudluspakett AR Sorteeritavad disainikriteeriumid v20.1.1.pdf – lehekülg: 79 |
| Kasutaja skoor | Üldse ei nõustu |
| Kasutaja märkused | See on täpsustatud projekteerimiskriteeriumide jaotise 21 01 13 leheküljel 10 |
Parandage robotite reageerimist juhendatud peenhäälestuse ja tugevdamise õppimisega
Lahendus koosneb kolmest peenhäälestuse etapist:
- Viige läbi kontrollitud peenhäälestus, kasutades märgistatud andmeid. Seda meetodit kirjeldati aastal Generatiivne AI-toega lahendus rakenduses Amazon SageMaker, mis aitab Amazoni ELi projekteerimisel ja ehitamisel.
- Koguge kasutajate tagasisidet, et märgistada küsimuste ja vastuste paarid edasiseks LLM-i häälestamiseks.
- Kui treeningandmed on valmis, häälestage mudelit edasi kasutades õppimine inimeste tagasisidest (RLHF).
RLHF-i kasutatakse laialdaselt generatiivse tehisintellekti (AI) ja LLM rakendustes. See hõlmab preemiafunktsiooni inimeste tagasisidet ja treenib mudelit tugevdava õppimisalgoritmiga, et maksimeerida tasusid, mis paneb mudeli täitma ülesandeid, mis on inimeste eesmärkidega paremini kooskõlas. Järgmine diagramm näitab sammude torustikku.
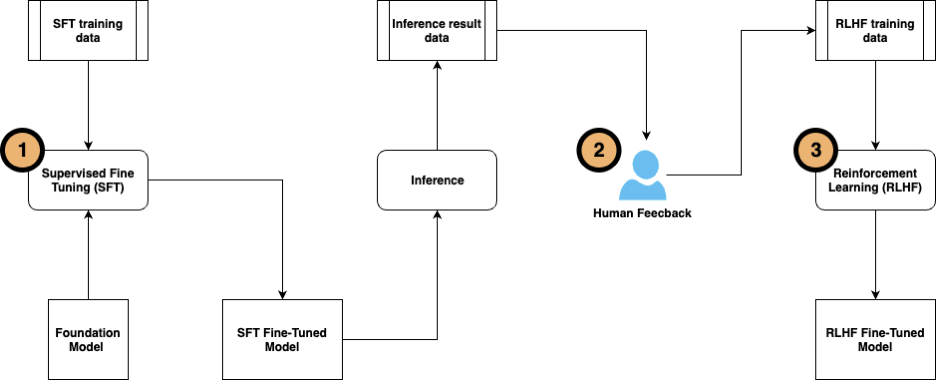
Testisime metoodikat Amazon D&C dokumentide abil Mistral-7B mudeliga SageMaker JumpStartis.
Kontrollitud peenhäälestus
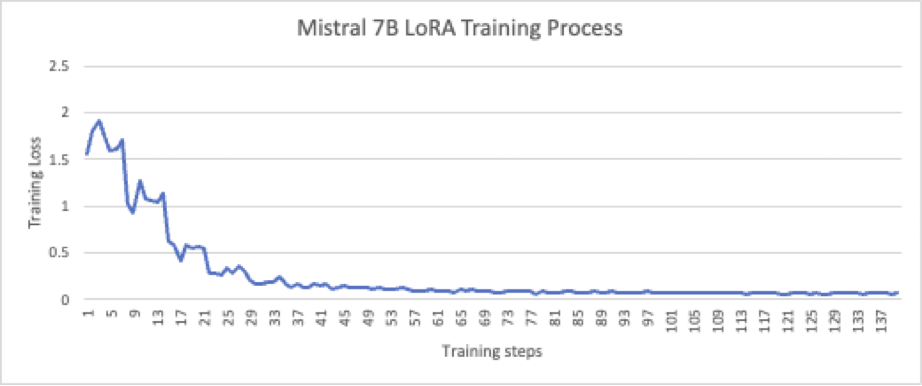
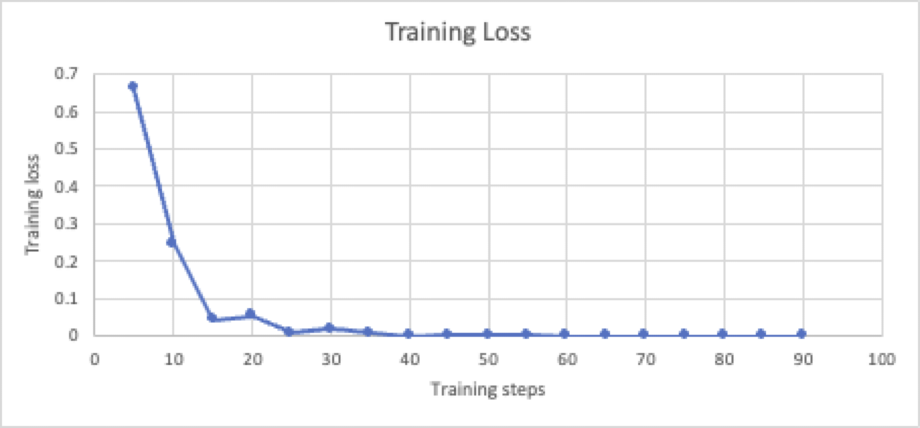
Eelmises postituses näitasime, kuidas täppishäälestatud Falcon-7B mudel ületab RAG torujuhtme ja parandab QA roboti vastuse kvaliteeti ja täpsust. Selle postituse jaoks teostasime Mistral-7B mudeli järelevalve all peenhäälestuse. Järelevalvega peenhäälestamisel kasutati PEFT/LoRA tehnikat (LoRA_r = 512, LoRA_alpha = 1024) 436,207,616 5.68 7,677,964,288 parameetril (3.8% 137 20 XNUMX XNUMX parameetrist). Koolitus viidi läbi pXNUMXx sõlmel XNUMX prooviga, mis olid sünteetiliselt genereeritud LLM-i poolt ja kinnitatud inimeste poolt; protsess on XNUMX epohhi järel hästi ühtlustunud, nagu on näidatud järgmisel joonisel.
Täppishäälestatud mudelit kinnitati 274 valimiga ja järeldustulemusi võrreldi semantilise sarnasuse skoori abil võrdlusvastustega. Skoor on 0.8100, mis on kõrgem kui traditsioonilise RAGi hind 0.6419.
Koguge inimeste ja tehisintellekti tagasisidet õppimise tugevdamiseks
RLHF jaoks on oluline piisav kogus kvaliteetseid koolitusnäidiseid, mille on märgistanud valdkonnaeksperdid (VKEd). Kuid halva kvaliteediga inimmärgised põhjustavad pärast RLHF-i koolitust tõenäoliselt mudeli halvemat jõudlust kui algne mudel. VKEde aeg on käes mis tahes organisatsioonis napp ressurss; sadade või tuhandete LLM-i vastuste läbivaatamine ja tagasiside andmine nõuab VKEdelt märkimisväärset ajainvesteeringut, millel ei pruugi olla selget investeeringutasuvust.
Selle väljakutse lahendamiseks võtsime vastu õppimine tehisintellekti tagasiside põhjal (RLAIF) meetod. RLAIF kasutab hindamistulemuste andmiseks tehisintellekti abilist (teine LLM), mitte inimestelt. Selle hübriidõppe lähenemisviisi puhul täpsustab õppeagent tegevusi mitte ainult inimesega suhtlemise, vaid ka mõne teise AI mudeli tagasiside põhjal. Piisavate koolitusandmete esitamine tugevdava õppe jaoks on palju skaleeritum ja palju vähem subjektiivne, kuna koolitus ei sõltu väikese VKEde rühma konkreetsetest eelistustest. VKEd võivad siiski olla kaasatud, kuid ainult selleks, et jälgida protsessi ja uurida tehisintellekti tagasiside kvaliteeti. See vähendab tohutult VKEde töökoormust, sest tehisintellekti loodud hindeid ja silte on VKEde jaoks palju lihtsam analüüsida, filtreerida ja sorteerida.
Sel kasutusjuhul pakume Anthropic Claude 2 mudelile järgmise viipa, et genereerida hindamisskoorid tugevdava õppeetapi koolitusnäidistena:
Claude 2 mudel genereerib hindamisskoori ja kommentaari selle kohta, miks hinde antakse, nagu on näidatud järgmises näites.
| Küsimus | Mida tähendab „Fit Out Works” selles kontekstis? |
| Viide Vastus | Korraldustööd viitavad ehituslepingu alusel Amazoni poolt või tema nimel arendaja kaudu tehtud töödele kuni esimese saamise kuupäevani mõttelisest arendaja kesta ja põhibaasi ehitamise positsioonist. Nende tööde hulka kuuluvad Amazoni nõutavad ruumilahendused, suure kasti installatsioonid ja kohandatud |
| QA Boti vastus | Korraldustööd viitavad ehituslepingu alusel Amazoni poolt või tema nimel arendaja kaudu tehtud töödele kuni esimese saamise kuupäevani mõttelisest arendaja kesta ja põhibaasi ehitamise positsioonist. |
| AI skoor | 4.5 |
| AI kommentaar | Masinavastus sisaldab põhiteavet standardvast vastusest – et Fit Out Works viitab ehituslepingu alusel tehtud töödele Amazoni poolt või Amazoni nimel arendaja kaudu kuni esimese saamise kuupäevani mõttelisest arendaja kesta ja põhibaasi ehitamise positsioonist. . Täiendavad üksikasjad Amazoni nõutavate Fit-Outide, suure kasti installimiste ja kohandamiste lisamise kohta on asjakohased ja aitavad luua täiendavat konteksti, seega sain masina vastuse hindeks 4.5/5. See kajastab standardvastuse olemust ja annab mõningaid kasulikud lisadetailid. |
274 valideerimisküsimusest genereeris järelevalve all peenhäälestatud mudel 159 vastust, mille AI skoor oli suurem kui 4. Vaatlesime 60 vastust, mille skoor oli alla 3; on ruumi üldise reageerimise kvaliteedi parandamiseks.
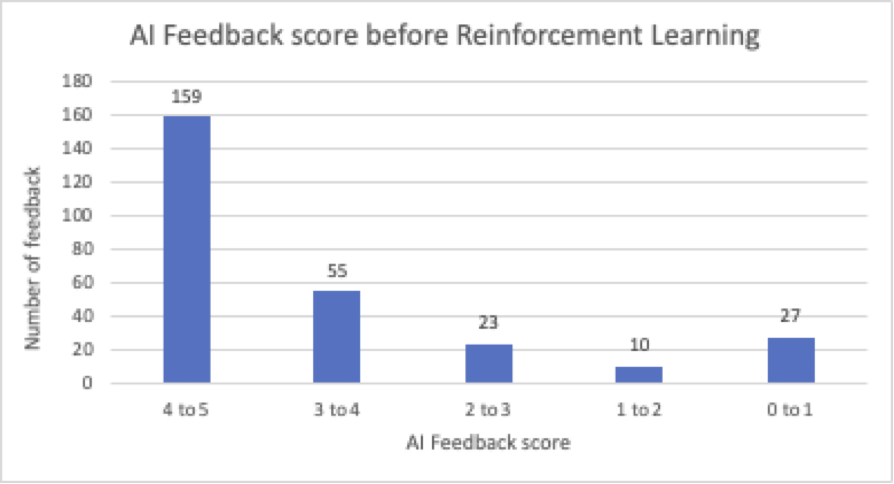
Amazon Engineering VKEd kinnitasid selle AI tagasiside ja tunnistasid tehisintellekti skooride kasutamise eeliseid. Ilma tehisintellekti tagasisideta vajaksid VKEd veidi aega iga LLM-i vastuse ülevaatamiseks ja analüüsimiseks, et tuvastada piirvastused ja hallutsinatsioonid ning hinnata, kas LLM tagastab õige sisu ja põhikontseptsioonid. Tehisintellekti tagasiside annab automaatselt tehisintellekti hinded ja võimaldab VKEdel kasutada filtreerimist, sortimist ja rühmitamist, et kontrollida skoore ja tuvastada vastuste suundumusi. See vähendab keskmise VKE läbivaatamise aega 80%.
Inimese ja tehisintellekti tagasiside põhjal õppimise tugevdamine
Kui koolitusnäidised on valmis, kasutame proksimaalse poliitika optimeerimise (PPO) algoritm tugevdusõppe läbiviimiseks. PPO kasutab poliitika gradiendi meetodit, mis ajakohastab poliitikat õppeprotsessis väikeste sammudega, et õppeagendid jõuaksid usaldusväärselt optimaalse poliitikavõrgustikuni. See muudab treeningprotsessi stabiilsemaks ja vähendab lahknemise võimalust.
Koolitusel kasutame esmalt inimese ja tehisintellektiga märgistatud andmeid, et koostada preemiamudel, mida kasutatakse õppeprotsessis raskuste uuendamisel. Selle kasutusjuhtumi jaoks valime distilroberta baasipõhise preemiamudeli ja treenime seda näidiste järgi järgmises vormingus:
[Instruction, Chosen_response, Rejected_response]
Järgnevalt on toodud treeningrekordi näide.
| Juhendamine | Mida on kontekstist lähtuvalt ette nähtud kaasava ja ligipääsetava disaini jaoks? |
| Valitud_vastus | BREEAM Credit HEA06 – kaasav ja ligipääsetav disain – Hoone on projekteeritud nii, et see vastaks otstarbele, sobiks ja oleks kõigile potentsiaalsetele kasutajatele ligipääsetav. Juurdepääsustrateegia töötatakse välja kooskõlas BREEAM kontrollnimekirjaga A3 |
| Tagasilükatud_vastus | Kontekst ütleb seda |
Preemiamudelit treenitakse õpimääraga 1e-5. Nagu on näidatud järgmisel graafikul, läheneb treening 10 perioodi pärast hästi.
Seejärel kasutatakse preemiamudelit tugevdava õppe jaoks. Sel juhul kasutame õppimise kiirendamiseks PEFT/LoRA-d. LoRA_r on 32 ja LoRA_alpha on 64. PPO-põhine õpe on kolmel perioodil 1.41e-5. Tugevduskoolitus on väga muutlik ja väga tundlik märgistuse andmete ja tagasiside andmete suhtes. Õppeprotsessi jälgimiseks kasutame mõõdikut reward_mean ehk keskmine tasu, mis saadakse keskkonnast spetsiaalselt tasumudeli jälgimisega.
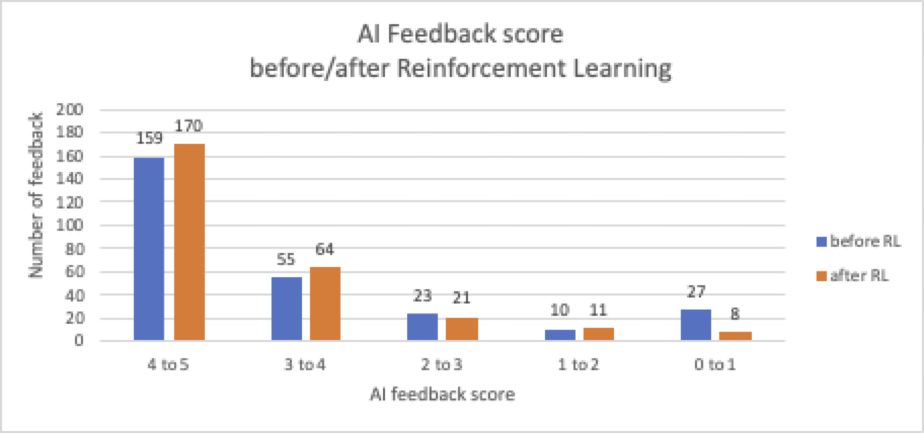
Pärast RLAIF-i võime näha positiivsete skooridega (üle 3) robotite vastuste arvu suurenemist 78.1%-lt 85.5%-le ja negatiivsete skooridega (alla 3) arvu vähenemist 21.9%-lt 14.5%-le. Kokku tõuseb tehisintellekti tagasiside keskmine skoor kuni 8%, 3.9-lt 4.2-le.
Parandust näete järgmises näites.
| Küsimus | Millist tasanduskihti on vaja plaaditavate põrandapindade jaoks? |
| Viide | Betoonist tasanduspõrandat saab kasutada ainult plaaditud põrandatel. Põrandaplaatide kasutamise kohta vaadake jooniste seeriat A-32. |
| Boti vastus enne RLAIF-i | Betoonist tasanduspõrandat saab kasutada ainult siseruumides |
| AI skoor enne RLAIF-i | 3 |
| Boti vastus pärast RLAIF-i | Betoonist tasanduspõrandat saab kasutada ainult plaaditud aladel. Vaadake jooniste seeriat A-32, et näha, kus plaatpõrandat saab kasutada. |
| AI skoor pärast RLAIF-i | 4.5 |
Järeldus
See postitus on jätk meie tööle Amazoni ELi projekteerimis- ja ehitusmeeskonnaga, nagu arutati artiklis Generatiivne AI-toega lahendus rakenduses Amazon SageMaker, mis aitab Amazoni ELi projekteerimisel ja ehitamisel. Selles postituses näitasime, kuidas genereerisime inimeste ja tehisintellekti tagasisideandmeid, et täpsustada Mistral-7B mudelit tugevdava õppe abil. RLAIF-i järgne mudel andis Amazon Engineeringi küsimustele vastamise robotile parema jõudluse, parandas tehisintellekti tagasiside skoori 8%. Amazon D&C meeskonna pilootprojektis vähendas RLAIF-i kasutamine VKEde valideerimise töökoormust hinnanguliselt 80%. Järgmise sammuna laiendame seda lahendust, luues ühenduse Amazon Engineeringi andmetaristuga, ja kavandame raamistiku pideva õppeprotsessi automatiseerimiseks koos inimesega. Samuti parandame AI tagasiside kvaliteeti veelgi, häälestades viipa malli.
Selle protsessi käigus õppisime, kuidas RLHF-i ja RLAIF-i kaudu küsimustele vastamise ülesannete kvaliteeti ja toimivust veelgi parandada.
- Inimlik valideerimine ja suurendamine on LLM-i täpsete ja vastutustundlike tulemuste saamiseks hädavajalikud. Inimeste tagasisidet saab RLHF-is kasutada mudeli reageerimise edasiseks parandamiseks.
- RLAIF automatiseerib hindamise ja õppimise tsükli. Tehisintellekti loodud tagasiside on vähem subjektiivne, kuna see ei sõltu väikese VKEde kogumi konkreetsest eelistusest.
- RLAIF on rohkem skaleeritav, et parandada robotite kvaliteeti pideva tugevdamisõppe kaudu, minimeerides samal ajal VKEdelt nõutavaid jõupingutusi. See on eriti kasulik domeenispetsiifiliste generatiivsete AI-lahenduste arendamiseks suurtes organisatsioonides.
- Seda protsessi tuleks teha regulaarselt, eriti kui on saadaval uued domeeniandmed, mida lahendus katab.
Sel juhul kasutasime mitme LLM-i testimiseks ja mitme LLM-i koolitusmeetodiga katsetamiseks SageMaker JumpStarti. See kiirendab oluliselt tehisintellekti tagasisidet ja õppimistsüklit maksimaalse tõhususe ja kvaliteediga. Oma projekti jaoks saate oma kasutajate tagasiside kogumiseks kasutusele võtta inimahelas lähenemisviisi või luua AI tagasisidet mõne muu LLM-i abil. Seejärel saate oma mudelite RLHF-i ja RLAIF-i abil viimistlemiseks järgida selles postituses määratletud kolmeastmelist protsessi. Protsessi kiirendamiseks soovitame katsetada meetodeid, kasutades SageMaker JumpStart.
Teave Autor
 Yunfei Bai on AWSi vanemlahenduste arhitekt. AI/ML-i, andmeteaduse ja analüütika taustaga Yunfei aitab klientidel äritulemuste saavutamiseks AWS-teenuseid kasutusele võtta. Ta kavandab AI/ML-i ja andmeanalüütilisi lahendusi, mis saavad üle keerulistest tehnilistest väljakutsetest ja juhivad strateegilisi eesmärke. Yunfeil on doktorikraad elektroonika- ja elektrotehnika alal. Väljaspool tööd naudib Yunfei lugemist ja muusikat.
Yunfei Bai on AWSi vanemlahenduste arhitekt. AI/ML-i, andmeteaduse ja analüütika taustaga Yunfei aitab klientidel äritulemuste saavutamiseks AWS-teenuseid kasutusele võtta. Ta kavandab AI/ML-i ja andmeanalüütilisi lahendusi, mis saavad üle keerulistest tehnilistest väljakutsetest ja juhivad strateegilisi eesmärke. Yunfeil on doktorikraad elektroonika- ja elektrotehnika alal. Väljaspool tööd naudib Yunfei lugemist ja muusikat.
 Elad Dwek on Amazoni ehitustehnoloogia juht. Ehituse ja projektijuhtimise taustaga Elad aitab meeskondadel ehitusprojektide elluviimiseks kasutusele võtta uusi tehnoloogiaid ja andmepõhiseid protsesse. Ta tuvastab vajadused ja lahendused ning hõlbustab kohandatud atribuutide väljatöötamist. Eladil on MBA ja BSc kraad ehitustehnikas. Väljaspool tööd naudib Elad joogat, puidutööd ja perega reisimist.
Elad Dwek on Amazoni ehitustehnoloogia juht. Ehituse ja projektijuhtimise taustaga Elad aitab meeskondadel ehitusprojektide elluviimiseks kasutusele võtta uusi tehnoloogiaid ja andmepõhiseid protsesse. Ta tuvastab vajadused ja lahendused ning hõlbustab kohandatud atribuutide väljatöötamist. Eladil on MBA ja BSc kraad ehitustehnikas. Väljaspool tööd naudib Elad joogat, puidutööd ja perega reisimist.
 Luca Cerabone on Amazoni äriteabe insener. Andmeteaduse ja -analüütika taustast lähtuvalt koostab Luca tehnilisi lahendusi, mis vastavad oma klientide ainulaadsetele vajadustele, suunates neid jätkusuutlikumate ja mastaapsemate protsesside poole. Andmeteaduse magistrikraadiga relvastatud Luca naudib isetegemisprojektidega tegelemist, aiatööd ja vaba aja hetkedel kulinaarsete naudingutega katsetamist.
Luca Cerabone on Amazoni äriteabe insener. Andmeteaduse ja -analüütika taustast lähtuvalt koostab Luca tehnilisi lahendusi, mis vastavad oma klientide ainulaadsetele vajadustele, suunates neid jätkusuutlikumate ja mastaapsemate protsesside poole. Andmeteaduse magistrikraadiga relvastatud Luca naudib isetegemisprojektidega tegelemist, aiatööd ja vaba aja hetkedel kulinaarsete naudingutega katsetamist.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/improve-llm-performance-with-human-and-ai-feedback-on-amazon-sagemaker-for-amazon-engineering/

