See on külalispostitus kasutajalt Skaalautuv kapital, Euroopa juhtiv FinTech, mis pakub digitaalset varahaldust ja maaklerplatvormi kindla intressimääraga kauplemisel.
Kiiresti kasvava ettevõttena on Scalable Capitali eesmärk mitte ainult ehitada uuenduslikku, tugevat ja usaldusväärset infrastruktuuri, vaid pakkuda ka klientidele parimaid kogemusi, eriti kui tegemist on klienditeenustega.
Scalable saab meie klientidelt igapäevaselt sadu meilipäringuid. Kaasaegse loomuliku keeletöötluse (NLP) mudeli juurutamisel on reageerimisprotsess palju tõhusamalt kujundatud ja klientide ooteaeg on tohutult vähenenud. Masinõppe (ML) mudel klassifitseerib uued sissetulevad kliendipäringud kohe, kui need saabuvad, ja suunab need ümber etteantud järjekordadesse, mis võimaldab meie pühendunud kliendi eduagentidel keskenduda meilide sisule vastavalt oma oskustele ja anda asjakohaseid vastuseid.
Selles postituses demonstreerime Hugging Face trafode kasutamise tehnilisi eeliseid Amazon SageMaker, nagu koolitus ja mastaapsed katsed ning suurenenud tootlikkus ja kulutõhusus.
Probleemipüstituses
Scalable Capital on üks kiiremini kasvavaid finantstehnoloogiaid Euroopas. Investeeringute demokratiseerimise eesmärgil pakub ettevõte oma klientidele lihtsat juurdepääsu finantsturgudele. Scalable kliendid saavad aktiivselt turul osaleda ettevõtte vahenduskauplemisplatvormi kaudu või kasutada Scalable Wealth Managementit, et investeerida intelligentselt ja automatiseeritud viisil. 2021. aastal koges Scalable Capitali kliendibaas kümnekordselt, kümnetelt tuhandetelt sadade tuhandeteni.
Et pakkuda oma klientidele tipptasemel (ja järjepidevat) kasutuskogemust toodete ja klienditeeninduse lõikes, otsis ettevõte automatiseeritud lahendusi skaleeritava lahenduse tõhususe suurendamiseks, säilitades samal ajal töökvaliteedi. Scalable Capitali andmeteaduse ja klienditeeninduse meeskonnad tuvastasid, et üks suurimaid kitsaskohti meie klientide teenindamisel oli meilipäringutele vastamine. Täpsemalt oli kitsaskohaks klassifitseerimise samm, kus töötajad pidid igapäevaselt taotlustekste lugema ja sildistada. Pärast kirjade õigetesse järjekordadesse suunamist tegelesid vastavad spetsialistid juhtumid kiiresti ja lahendasid need.
Selle klassifitseerimisprotsessi sujuvamaks muutmiseks koostas ja juurutas Scalable'i andmeteaduse meeskond multitegumtööga NLP-mudeli, kasutades tipptasemel trafoarhitektuuri, mis põhines eelkoolitatud andmetel. destilbert-alus-saksa korpus mudeli avaldas Hugging Face. destilbert-alus-saksa korpus kasutab teadmiste destilleerimine meetod väiksema üldotstarbelise keeleesitusmudeli eelkoolitamiseks kui algne BERT-i baasmudel. Destilleeritud versioon saavutab originaalversiooniga võrreldava jõudluse, olles samas väiksem ja kiirem. ML elutsükli protsessi hõlbustamiseks otsustasime oma mudelite ehitamiseks, juurutamiseks, teenindamiseks ja jälgimiseks kasutusele võtta SageMakeri. Järgmises osas tutvustame meie projekti arhitektuurilist disaini.
Lahenduse ülevaade
Scalable Capitali ML-i infrastruktuur koosneb kahest AWS-kontost: üks on arendusetapi keskkond ja teine tootmisetapi jaoks.
Järgmine diagramm näitab meie meiliklassifikaatori projekti töövoogu, kuid seda saab üldistada ka teistele andmeteaduse projektidele.
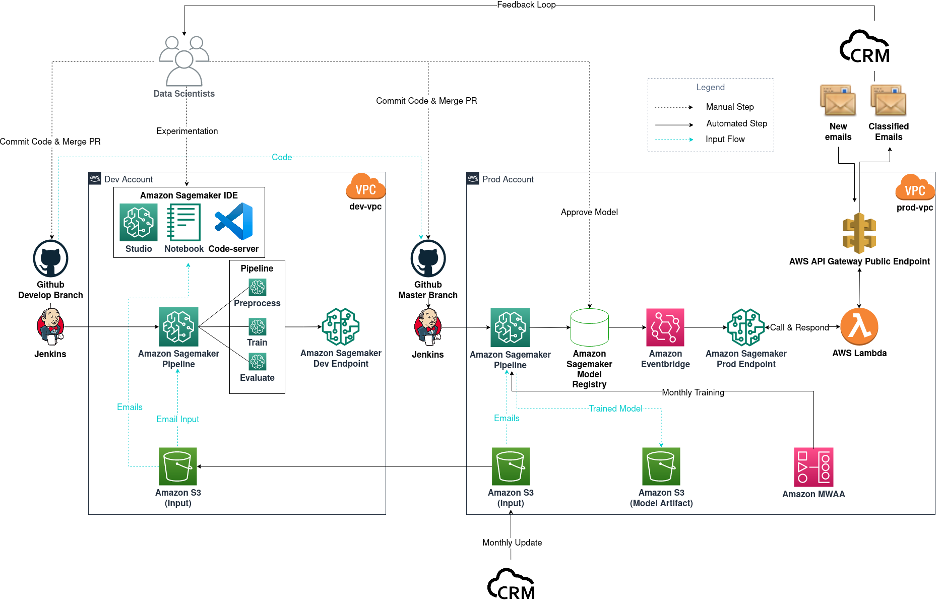
Meilide klassifitseerimise projekti diagramm
Töövoog koosneb järgmistest komponentidest:
- Mudeli katsetamine - Andmeteadlased kasutavad Amazon SageMaker Studio teha esimesed sammud andmeteaduse elutsüklis: uurimuslik andmete analüüs (EDA), andmete puhastamine ja ettevalmistamine ning prototüüpmudelite ehitamine. Kui uurimisetapp on lõppenud, kasutame SageMakeri sülearvutis hostitud VSCode'i kui kaugarendustööriista, et oma koodibaasi moduleerida ja toota. Erinevat tüüpi mudelite ja mudelikonfiguratsioonide uurimiseks ning samal ajal oma katsetuste jälgimiseks kasutame SageMakeri koolitust ja SageMakeri katseid.
- Mudeli ehitamine – Pärast seda, kui oleme otsustanud oma tootmiskasutuse mudeli kasuks, antud juhul mitme ülesande jaoks destilbert-alus-saksa korpus Hugging Face'i eelkoolitatud mudeli järgi peenhäälestatud mudelit rakendame ja edastame oma koodi Githubi arendusharusse. Githubi ühendamise sündmus käivitab meie Jenkinsi CI torujuhtme, mis omakorda käivitab testiandmetega SageMaker Pipelinesi töö. See toimib testina, et veenduda, kas koodid töötavad ootuspäraselt. Testimise eesmärgil kasutatakse testimise lõpp-punkti.
- Mudeli juurutamine – Olles veendunud, et kõik töötab ootuspäraselt, ühendavad andmeteadlased arendusharu esmaseks haruks. See liitmissündmus käivitab nüüd SageMaker Pipelinesi töö, mis kasutab koolituse eesmärgil tootmisandmeid. Seejärel toodetakse mudeli artefaktid ja salvestatakse need väljundisse Amazoni lihtne salvestusteenus (Amazon S3) ämbrisse ja uus mudeliversioon logitakse SageMakeri mudeliregistrisse. Andmeteadlased uurivad uue mudeli toimivust ja kiidavad seejärel heaks, kas see vastab ootustele. Mudeli kinnitamise sündmuse jäädvustab Amazon EventBridge, mis seejärel juurutab mudeli tootmiskeskkonnas SageMakeri lõpp-punkti.
- MLOps – Kuna SageMakeri lõpp-punkt on privaatne ja sellele ei pääse teenused väljaspool VPC-d, an AWS Lambda funktsioon ja Amazon API värav CRM-iga suhtlemiseks on vaja avalikku lõpp-punkti. Iga kord, kui CRM-i postkasti saabuvad uued meilid, kutsub CRM välja API lüüsi avaliku lõpp-punkti, mis omakorda käivitab funktsiooni Lambda, et kutsuda välja privaatne SageMakeri lõpp-punkt. Seejärel edastab funktsioon API lüüsi avaliku lõpp-punkti kaudu klassifikatsiooni tagasi CRM-ile. Meie juurutatud mudeli toimivuse jälgimiseks rakendame CRM-i ja andmeteadlaste vahel tagasisideahela, et jälgida mudeli ennustusmõõdikuid. Igakuiselt värskendab CRM eksperimenteerimiseks ja mudelikoolituseks kasutatud ajaloolisi andmeid. Me kasutame Amazoni hallatavad töövood Apache Airflow jaoks (Amazon MWAA) meie igakuise ümberõppe planeerijaks.
Järgmistes jaotistes jagame üksikasjalikumalt andmete ettevalmistamise, mudeli katsetamise ja mudeli juurutamise etapid.
Andmete ettevalmistamine
Scalable Capital kasutab meiliandmete haldamiseks ja salvestamiseks CRM-i tööriista. Asjakohane meili sisu koosneb teemast, sisust ja kontohalduripankadest. Igale meilile saab määrata kolm silti: millisest ärivaldkonnast meil pärineb, milline järjekord on sobiv ja meili konkreetne teema.
Enne NLP-mudelite treenimise alustamist veendume, et sisendandmed on puhtad ja märgised on määratud vastavalt ootustele.
Skaleeritavatelt klientidelt puhta päringu sisu hankimiseks eemaldame toormeiliandmetest ning lisateksti ja sümbolid, nagu meiliallkirjad, muljed, meiliahelate varasemate kirjade tsitaadid, CSS-sümbolid ja nii edasi. Vastasel juhul võib meie tulevaste koolitatud mudelite jõudlus halveneda.
Meilide sildid arenevad aja jooksul, kuna skaleeritavad klienditeeninduse meeskonnad lisavad uusi ja täiustavad või eemaldavad olemasolevaid, et vastata ärivajadustele. Tagamaks, et koolitusandmete sildid ja eeldatavad prognooside klassifikatsioonid on ajakohased, teeb andmeteaduse meeskond tihedat koostööd klienditeeninduse meeskonnaga, et tagada siltide õigsus.
Mudeli katsetamine
Alustame oma katset kergesti saadaolevate eelkoolitatud materjalidega destilbert-alus-saksa korpus mudeli avaldas Hugging Face. Kuna eelkoolitatud mudel on üldotstarbeline keeleesitusmudel, saame kohandada arhitektuuri konkreetsete allavoolu ülesannete täitmiseks (nt klassifitseerimine ja küsimustele vastamine), kinnitades närvivõrku sobivad pead. Meie kasutusjuhul on meid huvitavaks allavoolu ülesandeks järjestuse klassifitseerimine. Ilma muutmata olemasolevat arhitektuuri, otsustame iga meie nõutava kategooria jaoks viimistleda kolm eraldi eelkoolitatud mudelit. Koos SageMakeri nägu kallistavad sügavõppemahutid (DLC-d), NLP-katsete käivitamine ja haldamine on Hugging Face konteinerite ja SageMaker Experiments API abil lihtsaks tehtud.
Järgmine on koodilõik train.py:
Järgmine kood on kallistava näo hindaja:
Peenhäälestatud mudelite kinnitamiseks kasutame F1-skoor meie e-posti andmestiku tasakaalustamata olemuse tõttu, aga ka muude mõõdikute (nt täpsus, täpsus ja meeldetuletus) arvutamiseks. Selleks, et SageMaker Experiments API registreeriks koolitustöö mõõdikud, peame esmalt logima mõõdikud koolitustöö kohalikku konsooli, mille võtab üles Amazon CloudWatch. Seejärel määrame CloudWatchi logide jäädvustamiseks õige regex-vormingu. Mõõdikute definitsioonid hõlmavad mõõdikute nime ja regex-validimist mõõdikute väljavõtmiseks koolitustööst.
Klassifikaatori mudeli koolituse iteratsiooni osana kasutame tulemuse hindamiseks segaduste maatriksit ja klassifitseerimisaruannet. Järgmisel joonisel on kujutatud ärivaldkonna prognoosimise segaduste maatriks.
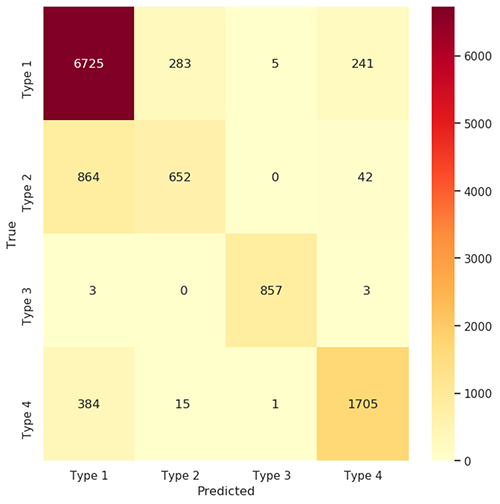
Segadusmaatriks
Järgmisel ekraanipildil on näide ärivaldkonna prognoosi klassifitseerimisaruandest.
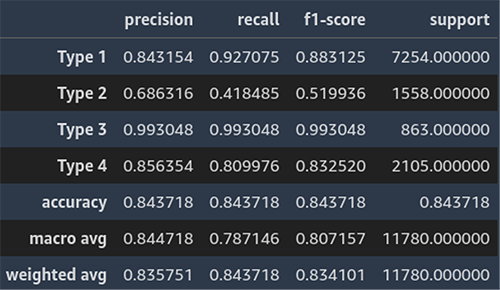
Klassifikatsiooniaruanne
Meie katse järgmise iteratsioonina kasutame ära mitme ülesandega õppimine meie mudeli täiustamiseks. Mitme ülesandega õpe on koolituse vorm, kus mudel õpib lahendama mitut ülesannet korraga, sest ülesannete vahel jagatud teave võib parandada õppimise efektiivsust. Kinnitades algsele distilberti arhitektuurile veel kaks klassifikatsioonipead, saame läbi viia mitme ülesandega peenhäälestuse, mis saavutab meie klienditeenindusmeeskonna jaoks mõistlikud mõõdikud.
Mudeli juurutamine
Meie kasutusjuhul tuleb meiliklassifikaator juurutada lõpp-punkti, kuhu meie CRM-i konveier saab saata hulga klassifitseerimata meile ja saada prognoose. Kuna meil on muid loogikaid (nt sisendandmete puhastamine ja mitme ülesande ennustused) lisaks Kallistava näo mudeli järeldusele, peame kirjutama kohandatud järeldusskripti, mis järgib SageMakeri standard.
Järgmine on koodilõik inference.py:
Kui kõik on valmis ja valmis, kasutame SageMakeri torujuhtmeid oma koolitustoru haldamiseks ja ühendame selle meie infrastruktuuriga, et lõpetada MLOps-i seadistamine.
Juurutatud mudeli toimivuse jälgimiseks loome tagasisideahela, mis võimaldab CRM-il anda meile juhtumite lõpetamisel salastatud meilide olekut. Selle teabe põhjal teeme juurutatud mudeli täiustamiseks muudatusi.
Järeldus
Selles postituses jagasime, kuidas SageMaker aitab Scalable'i andmeteaduse meeskonnal tõhusalt hallata andmeteaduse projekti, nimelt meiliklassifikaatori projekti elutsüklit. Elutsükkel algab andmete analüüsi ja uurimise algfaasiga SageMaker Studio abil; liigub SageMakeri koolituse, järelduste ja Hugging Face DLC-dega mudelikatsetuste ja juurutamise juurde; ja täiendab koolitust koos teiste AWS-teenustega integreeritud SageMakeri torujuhtmetega. Tänu sellele taristule suudame uusi mudeleid tõhusamalt korrata ja juurutada ning seega täiustada olemasolevaid protsesse skaleeritavas ja ka meie klientide kogemusi.
Hugging Face ja SageMakeri kohta lisateabe saamiseks vaadake järgmisi ressursse:
Autoritest
 Dr Sandra Schmid on Scalable GmbH andmeanalüüsi juht. Ta vastutab koos oma meeskondadega andmepõhiste lähenemisviiside ja kasutusjuhtude eest ettevõttes. Tema põhirõhk on masinõppe ja andmeteaduse mudelite ja ärieesmärkide parima kombinatsiooni leidmisel, et saada andmetest võimalikult palju ärilist väärtust ja tõhusust.
Dr Sandra Schmid on Scalable GmbH andmeanalüüsi juht. Ta vastutab koos oma meeskondadega andmepõhiste lähenemisviiside ja kasutusjuhtude eest ettevõttes. Tema põhirõhk on masinõppe ja andmeteaduse mudelite ja ärieesmärkide parima kombinatsiooni leidmisel, et saada andmetest võimalikult palju ärilist väärtust ja tõhusust.
 Huy Dang Scalable GmbH andmeteadlane. Tema kohustuste hulka kuulub andmeanalüütika, masinõppemudelite loomine ja juurutamine, samuti andmeteaduse meeskonna infrastruktuuri arendamine ja hooldamine. Vabal ajal meeldib talle lugeda, matkata, ronida ja olla kursis viimaste masinõppe arengutega.
Huy Dang Scalable GmbH andmeteadlane. Tema kohustuste hulka kuulub andmeanalüütika, masinõppemudelite loomine ja juurutamine, samuti andmeteaduse meeskonna infrastruktuuri arendamine ja hooldamine. Vabal ajal meeldib talle lugeda, matkata, ronida ja olla kursis viimaste masinõppe arengutega.
 Mia Chang on Amazon Web Servicesi ML-i spetsialistilahenduste arhitekt. Ta töötab EMEA-s asuvate klientidega ja jagab parimaid tavasid AI/ML-i töökoormuste käitamiseks pilves, omades rakendusmatemaatikat, arvutiteadust ja AI/ML-i tausta. Ta keskendub NLP-spetsiifilistele töökoormustele ning jagab oma kogemusi konverentsiesineja ja raamatute autorina. Vabal ajal naudib ta joogat, lauamänge ja kohvi keetmist.
Mia Chang on Amazon Web Servicesi ML-i spetsialistilahenduste arhitekt. Ta töötab EMEA-s asuvate klientidega ja jagab parimaid tavasid AI/ML-i töökoormuste käitamiseks pilves, omades rakendusmatemaatikat, arvutiteadust ja AI/ML-i tausta. Ta keskendub NLP-spetsiifilistele töökoormustele ning jagab oma kogemusi konverentsiesineja ja raamatute autorina. Vabal ajal naudib ta joogat, lauamänge ja kohvi keetmist.
 Moritz Guertler on AWS-i digitaalsete ettevõtete segmendi kontojuht. Ta keskendub klientidele FinTechi ruumis ja toetab neid innovatsiooni kiirendamisel turvalise ja skaleeritava pilveinfrastruktuuri kaudu.
Moritz Guertler on AWS-i digitaalsete ettevõtete segmendi kontojuht. Ta keskendub klientidele FinTechi ruumis ja toetab neid innovatsiooni kiirendamisel turvalise ja skaleeritava pilveinfrastruktuuri kaudu.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Autod/elektrisõidukid, Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- ChartPrime. Tõsta oma kauplemismängu ChartPrime'iga kõrgemale. Juurdepääs siia.
- BlockOffsets. Keskkonnakompensatsiooni omandi ajakohastamine. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/accelerate-client-success-management-through-email-classification-with-hugging-face-on-amazon-sagemaker/

