Los avances recientes en el aprendizaje automático (ML) han dado lugar a modelos cada vez más grandes, algunos de los cuales requieren cientos de miles de millones de parámetros. Aunque son más potentes, el entrenamiento y la inferencia sobre esos modelos requieren importantes recursos computacionales. A pesar de la disponibilidad de bibliotecas de capacitación distribuidas avanzadas, es común que los trabajos de capacitación e inferencia necesiten cientos de aceleradores (GPU o chips de aprendizaje automático especialmente diseñados, como tren de AWS y Inferencia de AWS), y por lo tanto decenas o cientos de instancias.
En dichos entornos distribuidos, la observabilidad tanto de las instancias como de los chips ML se vuelve clave para ajustar el rendimiento del modelo y optimizar los costos. Las métricas permiten a los equipos comprender el comportamiento de las cargas de trabajo y optimizar la asignación y utilización de recursos, diagnosticar anomalías y aumentar la eficiencia general de la infraestructura. Para los científicos de datos, la utilización y saturación de los chips ML también son relevantes para la planificación de la capacidad.
Esta publicación lo guía a través del Patrón de observabilidad de código abierto para AWS Inferentia, que le muestra cómo monitorear el rendimiento de los chips ML, utilizados en un Servicio Amazon Elastic Kubernetes (Amazon EKS), con nodos de plano de datos basados en Nube informática elástica de Amazon (Amazon EC2) instancias de tipo Inf1 y Inf2.
El patrón es parte del Acelerador de observabilidad de AWS CDK, un conjunto de módulos obstinados que le ayudarán a establecer la observabilidad de los clústeres de Amazon EKS. El Acelerador de observabilidad de AWS CDK está organizado en torno a patrones, que son unidades reutilizables para implementar múltiples recursos. El conjunto de patrones de observabilidad de código abierto instrumenta la observabilidad con Grafana gestionado por Amazon tableros de instrumentos, un Distribución de AWS para OpenTelemetry recopilador para recopilar métricas, y Servicio administrado de Amazon para Prometheus para almacenarlos
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución.

Esta solución implementa un clúster de Amazon EKS con un grupo de nodos que incluye instancias Inf1.
El tipo de AMI del grupo de nodos es AL2_x86_64_GPU, que usa el AMI de Amazon Linux acelerada optimizada para Amazon EKS. Además de la configuración de AMI estándar optimizada para Amazon EKS, la AMI acelerada incluye la Tiempo de ejecución de NeuronX.
Para acceder a los chips ML de Kubernetes, el patrón implementa el AWS neurona complemento del dispositivo.
Las métricas están expuestas a Amazon Managed Service for Prometheus mediante el neuron-monitor DaemonSet, que implementa un contenedor mínimo, con el Herramientas neuronales instalado. Específicamente, el neuron-monitor DaemonSet ejecuta el neuron-monitor comando canalizado al neuron-monitor-prometheus.py script complementario (ambos comandos son parte del contenedor):
El comando utiliza los siguientes componentes:
neuron-monitorrecopila métricas y estadísticas de las aplicaciones Neuron que se ejecutan en el sistema y transmite los datos recopilados a la salida estándar en Formato JSONneuron-monitor-prometheus.pyMapea y expone los datos de telemetría del formato JSON al formato compatible con Prometheus.
Los datos se visualizan en Amazon Managed Grafana mediante el panel correspondiente.
El resto de la configuración para recopilar y visualizar métricas con Amazon Managed Service for Prometheus y Amazon Managed Grafana es similar a la utilizada en otros patrones basados en código abierto, que se incluyen en el AWS Observability Accelerator for CDK Repositorio de GitHub.
Requisitos previos
Necesita lo siguiente para completar los pasos de esta publicación:
Configurar el entorno
Complete los siguientes pasos para configurar su entorno:
- Abra una ventana de terminal y ejecute los siguientes comandos:
- Recupere los ID del espacio de trabajo de cualquier espacio de trabajo de Amazon Managed Grafana existente:
El siguiente es nuestro resultado de muestra:
- Asigne los valores de
idyendpointa las siguientes variables de entorno:
COA_AMG_ENDPOINT_URL necesita incluir https://.
- Cree una clave API de Grafana desde el espacio de trabajo de Amazon Managed Grafana:
- Establecer un secreto en Gerente de sistemas de AWS:
El complemento Secretos externos accederá al secreto y estará disponible como un secreto nativo de Kubernetes en el clúster EKS.
Arranque el entorno AWS CDK
El primer paso para cualquier implementación de AWS CDK es iniciar el entorno. tu usas el cdk bootstrap en la CLI de AWS CDK para preparar el entorno (una combinación de cuenta de AWS y región de AWS) con los recursos requeridos por AWS CDK para realizar implementaciones en ese entorno. El arranque de AWS CDK es necesario para cada combinación de cuenta y región, por lo que si ya inició AWS CDK en una región, no necesita repetir el proceso de arranque.
Implementar la solución
Complete los siguientes pasos para implementar la solución:
- Clona el Acelerador de observabilidad cdk-aws repositorio e instalar los paquetes de dependencia. Este repositorio contiene código AWS CDK v2 escrito en TypeScript.
Se espera que la configuración real de los archivos JSON del panel de Grafana se especifique en el contexto de AWS CDK. Necesitas actualizar context existentes cdk.json archivo, ubicado en el directorio actual. La ubicación del tablero está especificada por el fluxRepository.values.GRAFANA_NEURON_DASH_URL parámetro, y neuronNodeGroup se utiliza para establecer el tipo de instancia, el número y Tienda de bloques elásticos de Amazon (Amazon EBS) tamaño utilizado para los nodos.
- Ingrese el siguiente fragmento en
cdk.json, reemplazandocontext:
Puede reemplazar el tipo de instancia Inf1 con Inf2 y cambiar el tamaño según sea necesario. Para verificar la disponibilidad en su región seleccionada, ejecute el siguiente comando (modificar Values como veas conveniente):
- Instale las dependencias del proyecto:
- Ejecute los siguientes comandos para implementar el patrón de observabilidad de código abierto:
Validar la solución
Complete los siguientes pasos para validar la solución:
- Ejecute el
update-kubeconfigdominio. Debería poder obtener el comando del mensaje de salida del comando anterior:
- Verifique los recursos que creó:
La siguiente captura de pantalla muestra nuestro resultado de muestra.

- Asegúrese de que el
neuron-device-plugin-daemonsetDaemonSet se está ejecutando:
El siguiente es nuestro resultado esperado:
- Confirma que el
neuron-monitorDaemonSet se está ejecutando:
El siguiente es nuestro resultado esperado:
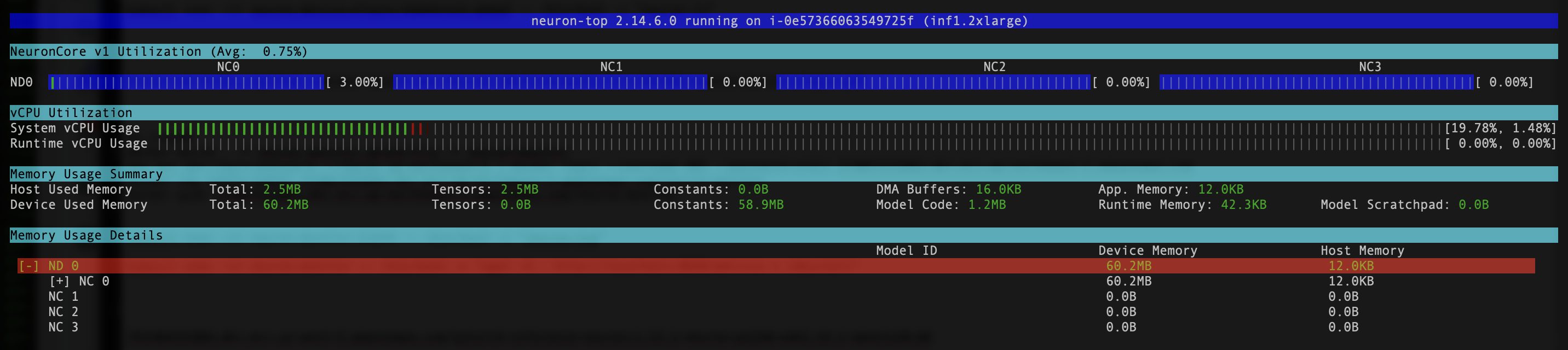
- Para verificar que los dispositivos y núcleos de Neuron estén visibles, ejecute el
neuron-lsyneuron-topcomandos de, por ejemplo, su módulo de monitoreo de neuronas (puede obtener el nombre del módulo de la salida dekubectl get pods -A):
La siguiente captura de pantalla muestra nuestro resultado esperado.

La siguiente captura de pantalla muestra nuestro resultado esperado.
Visualice datos utilizando el panel de Grafana Neuron
Inicie sesión en su espacio de trabajo de Amazon Managed Grafana y navegue hasta Cuadros de mando panel. Deberías ver un panel llamado Neurona / Monitor.
Para ver algunas métricas interesantes en el panel de Grafana, aplicamos el siguiente manifiesto:
Esta es una carga de trabajo de muestra que compila el modelo torchvision ResNet50 y ejecuta inferencias repetitivas en un bucle para generar datos de telemetría.
Para verificar que el pod se implementó correctamente, ejecute el siguiente código:
Deberías ver un pod llamado pytorch-inference-resnet50.
Después de unos minutos, mirando hacia el Neurona / Monitor panel, debería ver las métricas recopiladas similares a las siguientes capturas de pantalla.




Grafana Operador y Flux siempre trabajan juntos para sincronizar sus paneles con Git. Si elimina sus paneles por accidente, se reaprovisionarán automáticamente.
Limpiar
Puede eliminar toda la pila de AWS CDK con el siguiente comando:
Conclusión
En esta publicación, le mostramos cómo introducir la observabilidad, con herramientas de código abierto, en un clúster EKS que presenta un plano de datos que ejecuta instancias EC2 Inf1. Comenzamos seleccionando la AMI acelerada optimizada para Amazon EKS para los nodos del plano de datos, que incluye el tiempo de ejecución del contenedor Neuron y proporciona acceso a los dispositivos AWS Inferentia y Trainium Neuron. Luego, para exponer los núcleos y dispositivos de Neuron a Kubernetes, implementamos el complemento del dispositivo Neuron. La recopilación y el mapeo reales de datos de telemetría en un formato compatible con Prometheus se lograron a través de neuron-monitor y neuron-monitor-prometheus.py. Las métricas se obtuvieron de Amazon Managed Service for Prometheus y se muestran en el panel de Neuron de Amazon Managed Grafana.
Le recomendamos que explore patrones de observabilidad adicionales en el Acelerador de observabilidad de AWS para CDK Repositorio de GitHub. Para obtener más información sobre Neuron, consulte la Documentación de AWS Neuron.
Sobre la autora
 Ricardo Freschi es arquitecto sénior de soluciones en AWS y se centra en la modernización de aplicaciones. Trabaja en estrecha colaboración con socios y clientes para ayudarlos a transformar sus entornos de TI en su viaje hacia la nube de AWS mediante la refactorización de aplicaciones existentes y la creación de otras nuevas.
Ricardo Freschi es arquitecto sénior de soluciones en AWS y se centra en la modernización de aplicaciones. Trabaja en estrecha colaboración con socios y clientes para ayudarlos a transformar sus entornos de TI en su viaje hacia la nube de AWS mediante la refactorización de aplicaciones existentes y la creación de otras nuevas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/open-source-observability-for-aws-inferentia-nodes-within-amazon-eks-clusters/

