Estudio Amazon SageMaker proporciona una solución totalmente administrada para que los científicos de datos creen, entrenen e implementen de forma interactiva modelos de aprendizaje automático (ML). En el proceso de trabajar en sus tareas de aprendizaje automático, los científicos de datos suelen comenzar su flujo de trabajo descubriendo fuentes de datos relevantes y conectándose a ellas. Luego usan SQL para explorar, analizar, visualizar e integrar datos de varias fuentes antes de usarlos en su entrenamiento e inferencia de ML. Anteriormente, los científicos de datos a menudo se encontraban haciendo malabarismos con múltiples herramientas para admitir SQL en su flujo de trabajo, lo que obstaculizaba la productividad.
Nos complace anunciar que los cuadernos JupyterLab en SageMaker Studio ahora vienen con soporte integrado para SQL. Los científicos de datos ahora pueden:
- Conéctese a servicios de datos populares, incluidos Atenea amazónica, Desplazamiento al rojo de Amazon, Zona de datos de Amazony Snowflake directamente dentro de los cuadernos
- Explore y busque bases de datos, esquemas, tablas y vistas, y obtenga una vista previa de los datos dentro de la interfaz del cuaderno.
- Mezcle código SQL y Python en el mismo cuaderno para una exploración y transformación eficiente de datos para su uso en proyectos de aprendizaje automático.
- Utilice funciones de productividad del desarrollador, como finalización de comandos SQL, asistencia para formatear el código y resaltado de sintaxis para ayudar a acelerar el desarrollo del código y mejorar la productividad general del desarrollador.
Además, los administradores pueden gestionar de forma segura las conexiones a estos servicios de datos, lo que permite a los científicos de datos acceder a datos autorizados sin la necesidad de gestionar las credenciales manualmente.
En esta publicación, lo guiamos a través de la configuración de esta función en SageMaker Studio y le explicamos varias capacidades de esta función. Luego, mostramos cómo puede mejorar la experiencia SQL en el portátil utilizando capacidades de texto a SQL proporcionadas por modelos de lenguaje grande (LLM) avanzados para escribir consultas SQL complejas utilizando texto en lenguaje natural como entrada. Finalmente, para permitir que una audiencia más amplia de usuarios genere consultas SQL a partir de entradas de lenguaje natural en sus cuadernos, le mostramos cómo implementar estos modelos de texto a SQL usando Amazon SageMaker puntos finales.
Resumen de la solución
Con la integración SQL del portátil SageMaker Studio JupyterLab, ahora puede conectarse a fuentes de datos populares como Snowflake, Athena, Amazon Redshift y Amazon DataZone. Esta nueva característica le permite realizar varias funciones.
Por ejemplo, puede explorar visualmente fuentes de datos como bases de datos, tablas y esquemas directamente desde su ecosistema JupyterLab. Si los entornos de su computadora portátil se ejecutan en SageMaker Distribution 1.6 o superior, busque un nuevo widget en el lado izquierdo de su interfaz JupyterLab. Esta adición mejora la accesibilidad y la gestión de datos dentro de su entorno de desarrollo.
Si actualmente no está en la distribución sugerida de SageMaker (1.5 o inferior) o en un entorno personalizado, consulte el apéndice para obtener más información.

Una vez que haya configurado las conexiones (ilustradas en la siguiente sección), puede enumerar las conexiones de datos, explorar bases de datos y tablas e inspeccionar esquemas.

La extensión SQL incorporada de SageMaker Studio JupyterLab también le permite ejecutar consultas SQL directamente desde una computadora portátil. Los cuadernos Jupyter pueden diferenciar entre código SQL y Python utilizando el %%sm_sql comando mágico, que debe colocarse en la parte superior de cualquier celda que contenga código SQL. Este comando le indica a JupyterLab que las siguientes instrucciones son comandos SQL en lugar de código Python. El resultado de una consulta se puede mostrar directamente en el cuaderno, lo que facilita la integración perfecta de los flujos de trabajo de SQL y Python en su análisis de datos.
El resultado de una consulta se puede mostrar visualmente como tablas HTML, como se muestra en la siguiente captura de pantalla.

También se pueden escribir en un Marco de datos de pandas.

Requisitos previos
Asegúrese de haber cumplido los siguientes requisitos previos para poder utilizar la experiencia SQL del cuaderno de SageMaker Studio:
- SageMaker Estudio V2 – Asegúrese de estar ejecutando la versión más actualizada de su Perfiles de usuario y dominio de SageMaker Studio. Si actualmente estás en SageMaker Studio Classic, consulta Migración desde Amazon SageMaker Studio Classic.
- Rol de IAM – SageMaker requiere un Gestión de identidades y accesos de AWS (IAM) que se asignará a un dominio o perfil de usuario de SageMaker Studio para administrar los permisos de manera efectiva. Es posible que se requiera una actualización del rol de ejecución para incorporar la exploración de datos y la función de ejecución de SQL. La siguiente política de ejemplo permite a los usuarios otorgar, enumerar y ejecutar Pegamento AWS, Atenea, Servicio de almacenamiento simple de Amazon (Amazon S3), Director de secretos de AWSy recursos de Amazon Redshift:
- Espacio JupyterLab – Necesita acceso a SageMaker Studio y JupyterLab Space actualizados con Distribución de SageMaker v1.6 o versiones de imagen posteriores. Si está utilizando imágenes personalizadas para JupyterLab Spaces o versiones anteriores de SageMaker Distribution (v1.5 o inferior), consulte el apéndice para obtener instrucciones para instalar los paquetes y módulos necesarios para habilitar esta función en sus entornos. Para obtener más información sobre SageMaker Studio JupyterLab Spaces, consulte Aumente la productividad en Amazon SageMaker Studio: presentamos JupyterLab Spaces y herramientas de IA generativa.
- Credenciales de acceso a la fuente de datos – Esta función del cuaderno de SageMaker Studio requiere acceso con nombre de usuario y contraseña a fuentes de datos como Snowflake y Amazon Redshift. Cree acceso basado en nombre de usuario y contraseña a estas fuentes de datos si aún no tiene uno. El acceso basado en OAuth a Snowflake no es una característica compatible al momento de escribir este artículo.
- Cargar magia SQL – Antes de ejecutar consultas SQL desde una celda del cuaderno Jupyter, es esencial cargar la extensión SQL magics. usa el comando
%load_ext amazon_sagemaker_sql_magicpara habilitar esta característica. Además, puede ejecutar el%sm_sql?comando para ver una lista completa de opciones admitidas para realizar consultas desde una celda SQL. Estas opciones incluyen establecer un límite de consultas predeterminado de 1,000, ejecutar una extracción completa e inyectar parámetros de consulta, entre otras. Esta configuración permite una manipulación de datos SQL flexible y eficiente directamente dentro del entorno de su portátil.
Crear conexiones de base de datos
Las capacidades integradas de exploración y ejecución de SQL de SageMaker Studio se ven mejoradas por las conexiones de AWS Glue. Una conexión de AWS Glue es un objeto del catálogo de datos de AWS Glue que almacena datos esenciales, como credenciales de inicio de sesión, cadenas URI e información de la nube privada virtual (VPC) para almacenes de datos específicos. Estas conexiones son utilizadas por los rastreadores, los trabajos y los puntos finales de desarrollo de AWS Glue para acceder a varios tipos de almacenes de datos. Puede utilizar estas conexiones para datos de origen y de destino, e incluso reutilizar la misma conexión en varios rastreadores o trabajos de extracción, transformación y carga (ETL).
Para explorar fuentes de datos SQL en el panel izquierdo de SageMaker Studio, primero debe crear objetos de conexión de AWS Glue. Estas conexiones facilitan el acceso a diferentes fuentes de datos y le permiten explorar sus elementos de datos esquemáticos.
En las siguientes secciones, analizamos el proceso de creación de conectores AWS Glue específicos de SQL. Esto le permitirá acceder, ver y explorar conjuntos de datos en una variedad de almacenes de datos. Para obtener información más detallada sobre las conexiones de AWS Glue, consulte Conexión a datos.
Crear una conexión de AWS Glue
La única forma de incorporar fuentes de datos a SageMaker Studio es mediante conexiones de AWS Glue. Debe crear conexiones de AWS Glue con tipos de conexión específicos. Al momento de escribir este artículo, el único mecanismo admitido para crear estas conexiones es usar el Interfaz de línea de comandos de AWS (CLI de AWS).
Archivo JSON de definición de conexión
Al conectarse a diferentes orígenes de datos en AWS Glue, primero debe crear un archivo JSON que defina las propiedades de conexión, denominado archivo JSON. archivo de definición de conexión. Este archivo es crucial para establecer una conexión de AWS Glue y debe detallar todas las configuraciones necesarias para acceder a la fuente de datos. Para conocer las mejores prácticas de seguridad, se recomienda utilizar Secrets Manager para almacenar de forma segura información confidencial, como contraseñas. Mientras tanto, otras propiedades de conexión se pueden administrar directamente a través de conexiones de AWS Glue. Este enfoque garantiza que las credenciales confidenciales estén protegidas y al mismo tiempo hace que la configuración de la conexión sea accesible y manejable.
El siguiente es un ejemplo de una definición de conexión JSON:
Al configurar conexiones de AWS Glue para sus fuentes de datos, existen algunas pautas importantes a seguir para proporcionar funcionalidad y seguridad:
- Stringificación de propiedades - Dentro de
PythonPropertiesclave, asegúrese de que todas las propiedades estén pares clave-valor encadenados. Es fundamental evitar correctamente las comillas dobles utilizando el carácter de barra invertida () cuando sea necesario. Esto ayuda a mantener el formato correcto y evitar errores de sintaxis en su JSON. - Manejo de información sensible – Aunque es posible incluir todas las propiedades de conexión dentro
PythonProperties, es recomendable no incluir detalles confidenciales como contraseñas directamente en estas propiedades. En su lugar, utilice Secrets Manager para manejar información confidencial. Este enfoque protege sus datos confidenciales almacenándolos en un entorno controlado y cifrado, lejos de los archivos de configuración principales.
Cree una conexión de AWS Glue mediante la AWS CLI
Después de incluir todos los campos necesarios en su archivo JSON de definición de conexión, estará listo para establecer una conexión de AWS Glue para su fuente de datos mediante la AWS CLI y el siguiente comando:
Este comando inicia una nueva conexión de AWS Glue según las especificaciones detalladas en su archivo JSON. El siguiente es un desglose rápido de los componentes del comando:
- -región – Esto especifica la región de AWS donde se creará su conexión de AWS Glue. Es fundamental seleccionar la región donde se encuentran sus fuentes de datos y otros servicios para minimizar la latencia y cumplir con los requisitos de residencia de datos.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Este parámetro indica a AWS CLI que lea la configuración de entrada de un archivo local que contiene su definición de conexión en formato JSON.
Debería poder crear conexiones de AWS Glue con el comando AWS CLI anterior desde su terminal Studio JupyterLab. Sobre el Archive menú, seleccione Nuevo y terminal.

Si create-connection El comando se ejecuta correctamente, debería ver su fuente de datos en el panel del navegador SQL. Si no ve su fuente de datos en la lista, elija Refrescar para actualizar el caché.
Crear una conexión de copo de nieve
En esta sección, nos centramos en la integración de una fuente de datos Snowflake con SageMaker Studio. La creación de cuentas, bases de datos y almacenes de Snowflake queda fuera del alcance de esta publicación. Para comenzar con Snowflake, consulte la guía del usuario del copo de nieve. En esta publicación, nos concentramos en crear un archivo JSON de definición de Snowflake y establecer una conexión de origen de datos de Snowflake mediante AWS Glue.
Crear un secreto de Secrets Manager
Puede conectarse a su cuenta de Snowflake utilizando una identificación de usuario y una contraseña o utilizando claves privadas. Para conectarse con una identificación de usuario y una contraseña, debe almacenar de forma segura sus credenciales en Secrets Manager. Como se mencionó anteriormente, aunque es posible incrustar esta información en PythonProperties, no se recomienda almacenar información confidencial en formato de texto sin formato. Asegúrese siempre de que los datos confidenciales se manejen de forma segura para evitar posibles riesgos de seguridad.
Para almacenar información en Secrets Manager, complete los siguientes pasos:
- En la consola de Secrets Manager, elija Almacenar un nuevo secreto.
- tipo secreto, escoger Otro tipo de secreto.
- Para el par clave-valor, elija Texto sin formato e ingresa lo siguiente:
- Ingrese un nombre para su secreto, como
sm-sql-snowflake-secret. - Deje las otras configuraciones como predeterminadas o personalícelas si es necesario.
- Crea el secreto.
Cree una conexión de AWS Glue para Snowflake
Como se mencionó anteriormente, las conexiones de AWS Glue son esenciales para acceder a cualquier conexión desde SageMaker Studio. Puedes encontrar una lista de todas las propiedades de conexión admitidas para Snowflake. A continuación se muestra un ejemplo de definición de conexión JSON para Snowflake. Reemplace los valores del marcador de posición con los valores apropiados antes de guardarlos en el disco:
Para crear un objeto de conexión de AWS Glue para la fuente de datos de Snowflake, utilice el siguiente comando:
Este comando crea una nueva conexión de fuente de datos Snowflake en el panel de su navegador SQL que es navegable y puede ejecutar consultas SQL en ella desde la celda de su cuaderno JupyterLab.

Crear una conexión de Amazon Redshift
Amazon Redshift es un servicio de almacenamiento de datos a escala de petabytes totalmente administrado que simplifica y reduce el costo de analizar todos sus datos mediante SQL estándar. El procedimiento para crear una conexión de Amazon Redshift es muy similar al de una conexión Snowflake.
Crear un secreto de Secrets Manager
De manera similar a la configuración de Snowflake, para conectarse a Amazon Redshift mediante un ID de usuario y una contraseña, debe almacenar de forma segura la información secreta en Secrets Manager. Complete los siguientes pasos:
- En la consola de Secrets Manager, elija Almacenar un nuevo secreto.
- tipo secreto, escoger Credenciales para el clúster de Amazon Redshift.
- Ingrese las credenciales utilizadas para iniciar sesión y acceder a Amazon Redshift como fuente de datos.
- Elija el clúster Redshift asociado con los secretos.
- Introduzca un nombre para el secreto, como por ejemplo
sm-sql-redshift-secret. - Deje las otras configuraciones como predeterminadas o personalícelas si es necesario.
- Crea el secreto.
Si sigue estos pasos, se asegurará de que sus credenciales de conexión se manejen de forma segura, utilizando las sólidas funciones de seguridad de AWS para administrar datos confidenciales de manera efectiva.
Cree una conexión de AWS Glue para Amazon Redshift
Para configurar una conexión con Amazon Redshift mediante una definición JSON, complete los campos necesarios y guarde la siguiente configuración JSON en el disco:
Para crear un objeto de conexión de AWS Glue para la fuente de datos de Redshift, utilice el siguiente comando de AWS CLI:
Este comando crea una conexión en AWS Glue vinculada a su fuente de datos de Redshift. Si el comando se ejecuta correctamente, podrá ver su fuente de datos Redshift dentro del cuaderno SageMaker Studio JupyterLab, listo para ejecutar consultas SQL y realizar análisis de datos.

Crea una conexión con Atenas
Athena es un servicio de consultas SQL totalmente administrado de AWS que permite el análisis de datos almacenados en Amazon S3 utilizando SQL estándar. Para configurar una conexión de Athena como fuente de datos en el navegador SQL del cuaderno JupyterLab, debe crear un JSON de definición de conexión de muestra de Athena. La siguiente estructura JSON configura los detalles necesarios para conectarse a Athena, especificando el catálogo de datos, el directorio provisional de S3 y la región:
Para crear un objeto de conexión de AWS Glue para la fuente de datos de Athena, utilice el siguiente comando de AWS CLI:
Si el comando se ejecuta correctamente, podrá acceder al catálogo de datos y a las tablas de Athena directamente desde el navegador SQL dentro de su cuaderno SageMaker Studio JupyterLab.

Consultar datos de múltiples fuentes
Si tiene varias fuentes de datos integradas en SageMaker Studio a través del navegador SQL integrado y la función SQL del cuaderno, puede ejecutar consultas rápidamente y cambiar sin esfuerzo entre servidores de fuentes de datos en celdas posteriores dentro de un cuaderno. Esta capacidad permite transiciones fluidas entre diferentes bases de datos o fuentes de datos durante su flujo de trabajo de análisis.
Puede ejecutar consultas en una colección diversa de backends de fuentes de datos y llevar los resultados directamente al espacio de Python para su posterior análisis o visualización. Esto es facilitado por el %%sm_sql Comando mágico disponible en los cuadernos de SageMaker Studio. Para generar los resultados de su consulta SQL en un DataFrame de pandas, hay dos opciones:
- Desde la barra de herramientas de la celda de su cuaderno, elija el tipo de salida Marco de datos y nombra tu variable DataFrame
- Agregue el siguiente parámetro a su
%%sm_sqlmando:
El siguiente diagrama ilustra este flujo de trabajo y muestra cómo puede ejecutar consultas sin esfuerzo en varias fuentes en celdas posteriores del cuaderno, así como entrenar un modelo de SageMaker mediante trabajos de entrenamiento o directamente dentro del cuaderno mediante computación local. Además, el diagrama destaca cómo la integración SQL incorporada de SageMaker Studio simplifica los procesos de extracción y construcción directamente dentro del entorno familiar de una celda de notebook JupyterLab.

Texto a SQL: uso del lenguaje natural para mejorar la creación de consultas
SQL es un lenguaje complejo que requiere comprensión de bases de datos, tablas, sintaxis y metadatos. Hoy en día, la inteligencia artificial generativa (IA) puede permitirle escribir consultas SQL complejas sin necesidad de una experiencia profunda en SQL. El avance de los LLM ha tenido un impacto significativo en la generación de SQL basada en el procesamiento del lenguaje natural (NLP), lo que permite la creación de consultas SQL precisas a partir de descripciones en lenguaje natural, una técnica conocida como Texto a SQL. Sin embargo, es esencial reconocer las diferencias inherentes entre el lenguaje humano y SQL. El lenguaje humano a veces puede ser ambiguo o impreciso, mientras que SQL es estructurado, explícito e inequívoco. Cerrar esta brecha y convertir con precisión el lenguaje natural en consultas SQL puede presentar un desafío formidable. Cuando se les brindan las indicaciones adecuadas, los LLM pueden ayudar a cerrar esta brecha al comprender la intención detrás del lenguaje humano y generar consultas SQL precisas en consecuencia.
Con el lanzamiento de la función de consulta SQL en el portátil de SageMaker Studio, SageMaker Studio simplifica la inspección de bases de datos y esquemas, y la creación, ejecución y depuración de consultas SQL sin tener que salir del IDE del portátil de Jupyter. Esta sección explora cómo las capacidades de texto a SQL de los LLM avanzados pueden facilitar la generación de consultas SQL utilizando lenguaje natural dentro de los cuadernos de Jupyter. Empleamos el modelo de última generación Text-to-SQL defog/sqlcoder-7b-2 junto con Jupyter AI, un asistente de IA generativa diseñado específicamente para portátiles Jupyter, para crear consultas SQL complejas a partir de lenguaje natural. Al utilizar este modelo avanzado, podemos crear consultas SQL complejas sin esfuerzo y de manera eficiente utilizando lenguaje natural, mejorando así nuestra experiencia SQL en los cuadernos.
Creación de prototipos de portátiles utilizando Hugging Face Hub
Para comenzar a crear prototipos, necesita lo siguiente:
- Código de GitHub – El código presentado en esta sección está disponible en el siguiente Repositorio GitHub y haciendo referencia a la cuaderno de ejemplo.
- Espacio JupyterLab – El acceso a un espacio JupyterLab de SageMaker Studio respaldado por instancias basadas en GPU es esencial. Para el
defog/sqlcoder-7b-2Para el modelo, se recomienda un modelo de parámetros 7B, utilizando una instancia ml.g5.2xlarge. Alternativas comodefog/sqlcoder-70b-alphuna odefog/sqlcoder-34b-alphaTambién son viables para la conversión de lenguaje natural a SQL, pero es posible que se requieran tipos de instancias más grandes para la creación de prototipos. Asegúrese de tener la cuota para iniciar una instancia respaldada por GPU navegando a la consola de Cuotas de servicio, buscando SageMaker y buscandoStudio JupyterLab Apps running on <instance type>.
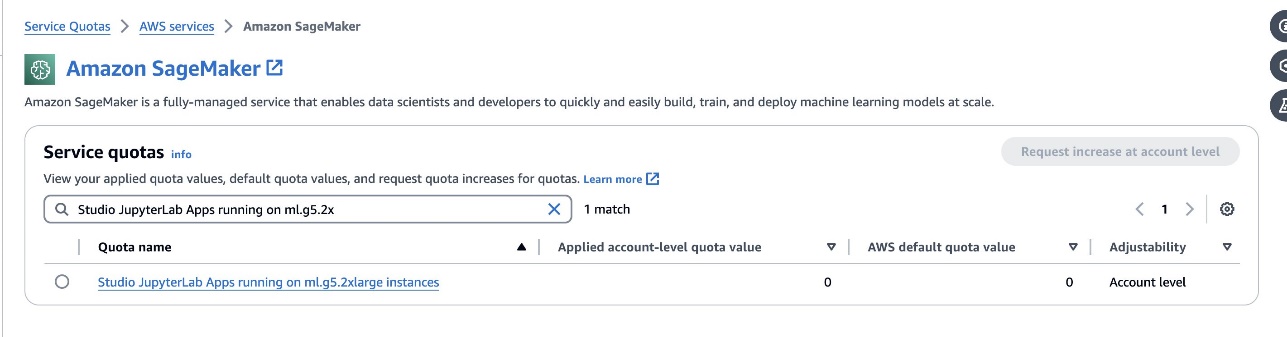
Inicie un nuevo JupyterLab Space respaldado por GPU desde su SageMaker Studio. Se recomienda crear un nuevo JupyterLab Space con al menos 75 GB de Tienda de bloques elásticos de Amazon (Amazon EBS) almacenamiento para un modelo de parámetros 7B.


- abrazando la cara hub – Si su dominio de SageMaker Studio tiene acceso para descargar modelos desde el abrazando la cara hub, puedes usar el
AutoModelForCausalLMclase de abrazando cara/transformers para descargar modelos automáticamente y fijarlos a sus GPU locales. Los pesos del modelo se almacenarán en la memoria caché de su máquina local. Vea el siguiente código:
Una vez que el modelo se haya descargado y cargado por completo en la memoria, debería observar un aumento en la utilización de la GPU en su máquina local. Esto indica que el modelo está utilizando activamente los recursos de la GPU para tareas computacionales. Puede verificar esto en su propio espacio JupyterLab ejecutando nvidia-smi (para una visualización única) o nvidia-smi —loop=1 (para repetir cada segundo) desde su terminal JupyterLab.

Los modelos de texto a SQL destacan por comprender la intención y el contexto de la solicitud de un usuario, incluso cuando el lenguaje utilizado es conversacional o ambiguo. El proceso implica traducir las entradas del lenguaje natural a los elementos correctos del esquema de la base de datos, como nombres de tablas, nombres de columnas y condiciones. Sin embargo, un modelo de texto a SQL disponible en el mercado no conocerá inherentemente la estructura de su almacén de datos, los esquemas de bases de datos específicos ni podrá interpretar con precisión el contenido de una tabla basándose únicamente en los nombres de las columnas. Para utilizar eficazmente estos modelos para generar consultas SQL prácticas y eficientes a partir de lenguaje natural, es necesario adaptar el modelo de generación de texto SQL al esquema de base de datos de su almacén específico. Esta adaptación se facilita mediante el uso de Indicaciones de Maestría en Derecho. La siguiente es una plantilla de aviso recomendada para el modelo de texto a SQL defog/sqlcoder-7b-2, dividida en cuatro partes:
- Tarea – Esta sección debe especificar una tarea de alto nivel que debe realizar el modelo. Debe incluir el tipo de backend de base de datos (como Amazon RDS, PostgreSQL o Amazon Redshift) para que el modelo tenga en cuenta cualquier diferencia sintáctica matizada que pueda afectar la generación de la consulta SQL final.
- Instrucciones – Esta sección debe definir los límites de las tareas y el conocimiento del dominio para el modelo, y puede incluir algunos ejemplos breves para guiar al modelo en la generación de consultas SQL ajustadas.
- Base de datos de esquemas – Esta sección debe detallar los esquemas de la base de datos de su almacén, describiendo las relaciones entre tablas y columnas para ayudar al modelo a comprender la estructura de la base de datos.
- Respuesta – Esta sección está reservada para que el modelo genere la respuesta de la consulta SQL a la entrada de lenguaje natural.
Un ejemplo del esquema de base de datos y el mensaje utilizado en esta sección está disponible en la Repositorio de GitHub.
La ingeniería rápida no se trata sólo de formular preguntas o afirmaciones; es un arte y una ciencia llenos de matices que impactan significativamente la calidad de las interacciones con un modelo de IA. La forma en que se elabora un mensaje puede influir profundamente en la naturaleza y utilidad de la respuesta de la IA. Esta habilidad es fundamental para maximizar el potencial de las interacciones de la IA, especialmente en tareas complejas que requieren comprensión especializada y respuestas detalladas.
Es importante tener la opción de crear y probar rápidamente la respuesta de un modelo para un mensaje determinado y optimizar el mensaje en función de la respuesta. Los cuadernos de JupyterLab brindan la capacidad de recibir comentarios instantáneos de un modelo que se ejecuta en computación local y optimizar el mensaje y ajustar aún más la respuesta de un modelo o cambiar un modelo por completo. En esta publicación, utilizamos una computadora portátil SageMaker Studio JupyterLab respaldada por la GPU NVIDIA A5.2G de 10 GB de ml.g24xlarge para ejecutar la inferencia del modelo de texto a SQL en la computadora portátil y crear interactivamente nuestro indicador de modelo hasta que la respuesta del modelo esté lo suficientemente ajustada para proporcionar respuestas que son directamente ejecutables en las celdas SQL de JupyterLab. Para ejecutar la inferencia del modelo y transmitir simultáneamente las respuestas del modelo, utilizamos una combinación de model.generate y TextIteratorStreamer como se define en el siguiente código:
La salida del modelo se puede decorar con la magia de SageMaker SQL. %%sm_sql ..., que permite que el cuaderno JupyterLab identifique la celda como una celda SQL.
Aloje modelos de texto a SQL como puntos finales de SageMaker
Al final de la etapa de creación de prototipos, hemos seleccionado nuestro LLM de texto a SQL preferido, un formato de solicitud efectivo y un tipo de instancia apropiado para alojar el modelo (ya sea de una sola GPU o de varias GPU). SageMaker facilita el alojamiento escalable de modelos personalizados mediante el uso de puntos finales de SageMaker. Estos puntos finales se pueden definir según criterios específicos, lo que permite la implementación de LLM como puntos finales. Esta capacidad le permite escalar la solución a una audiencia más amplia, lo que permite a los usuarios generar consultas SQL a partir de entradas de lenguaje natural utilizando LLM alojados personalizados. El siguiente diagrama ilustra esta arquitectura.
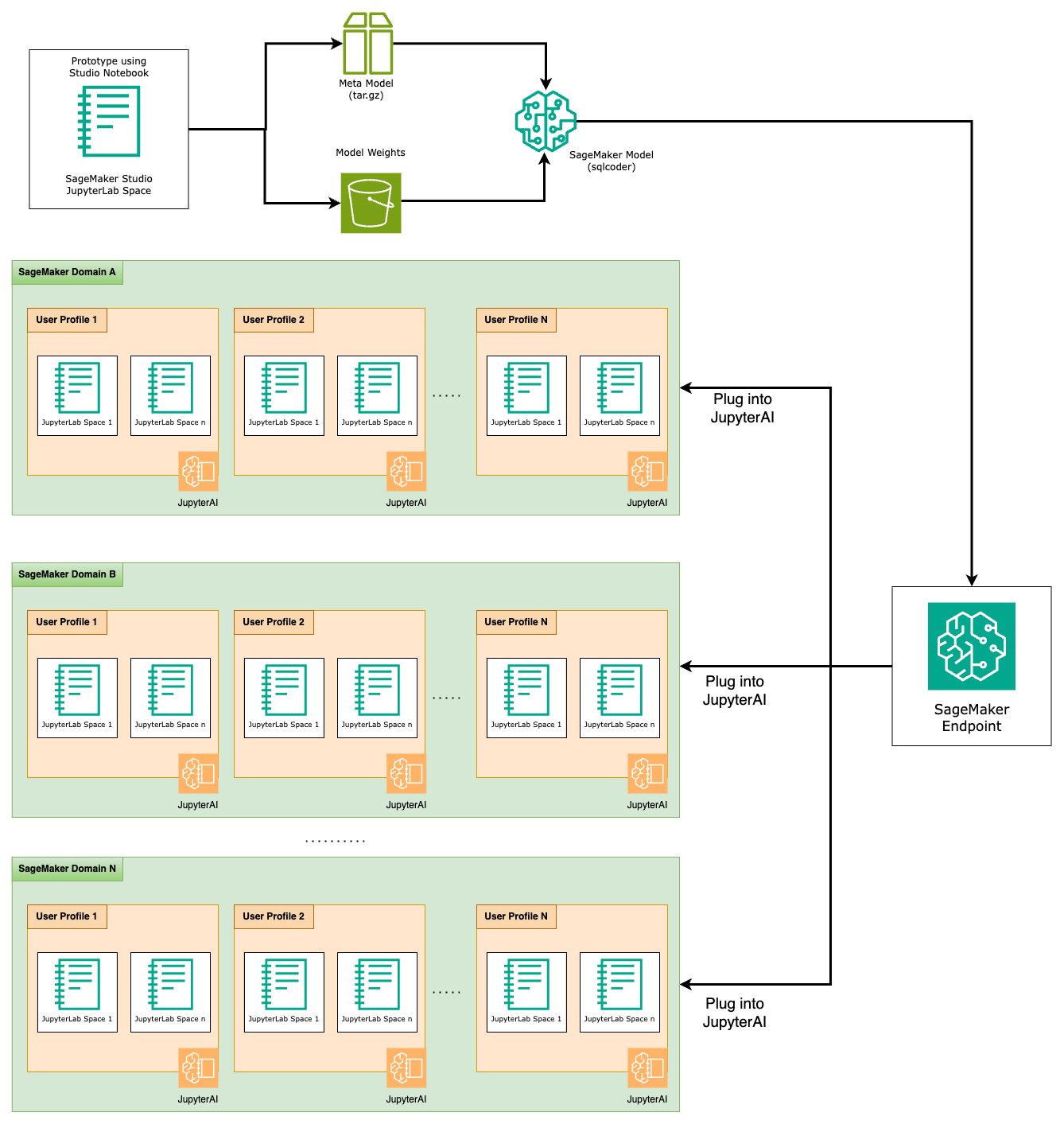
Para alojar su LLM como un punto final de SageMaker, genera varios artefactos.
El primer artefacto son los pesos del modelo. Servicio de biblioteca SageMaker Deep Java (DJL) Los contenedores le permiten configurar configuraciones a través de un meta sirviendo.propiedades archivo, que le permite controlar cómo se obtienen los modelos, ya sea directamente desde Hugging Face Hub o descargando artefactos de modelo desde Amazon S3. Si especifica model_id=defog/sqlcoder-7b-2, DJL Serving intentará descargar este modelo directamente desde Hugging Face Hub. Sin embargo, puede incurrir en cargos de entrada/salida de red cada vez que se implementa o escala elásticamente el punto final. Para evitar estos cargos y potencialmente acelerar la descarga de artefactos del modelo, se recomienda omitir el uso model_id in serving.properties y guarde los pesos del modelo como artefactos S3 y especifíquelos solo con s3url=s3://path/to/model/bin.
Se puede guardar un modelo (con su tokenizador) en el disco y cargarlo en Amazon S3 con solo unas pocas líneas de código:
También utiliza un archivo de solicitud de base de datos. En esta configuración, el mensaje de la base de datos se compone de Task, Instructions, Database Schemay Answer sections. Para la arquitectura actual, asignamos un archivo de solicitud independiente para cada esquema de base de datos. Sin embargo, existe flexibilidad para expandir esta configuración para incluir múltiples bases de datos por archivo de solicitud, lo que permite que el modelo ejecute uniones compuestas entre bases de datos en el mismo servidor. Durante nuestra etapa de creación de prototipos, guardamos el mensaje de la base de datos como un archivo de texto llamado <Database-Glue-Connection-Name>.prompt, Donde Database-Glue-Connection-Name corresponde al nombre de la conexión visible en su entorno JupyterLab. Por ejemplo, esta publicación se refiere a una conexión de Snowflake llamada Airlines_Dataset, por lo que el archivo de solicitud de la base de datos se llama Airlines_Dataset.prompt. Luego, este archivo se almacena en Amazon S3 y, posteriormente, nuestra lógica de servicio de modelos lo lee y lo almacena en caché.
Además, esta arquitectura permite a cualquier usuario autorizado de este punto final definir, almacenar y generar lenguaje natural para consultas SQL sin la necesidad de realizar múltiples implementaciones del modelo. Usamos lo siguiente ejemplo de un mensaje de base de datos para demostrar la funcionalidad de texto a SQL.
A continuación, genera una lógica de servicio de modelo personalizada. En esta sección, describirá una lógica de inferencia personalizada denominada modelo.py. Este script está diseñado para optimizar el rendimiento y la integración de nuestros servicios de Texto a SQL:
- Definir la lógica de almacenamiento en caché del archivo de solicitud de la base de datos – Para minimizar la latencia, implementamos una lógica personalizada para descargar y almacenar en caché los archivos de solicitud de la base de datos. Este mecanismo garantiza que las indicaciones estén disponibles, lo que reduce la sobrecarga asociada con las descargas frecuentes.
- Definir lógica de inferencia de modelo personalizada – Para mejorar la velocidad de inferencia, nuestro modelo de texto a SQL se carga en el formato de precisión float16 y luego se convierte en un modelo DeepSpeed. Este paso permite un cálculo más eficiente. Además, dentro de esta lógica, usted especifica qué parámetros pueden ajustar los usuarios durante las llamadas de inferencia para adaptar la funcionalidad según sus necesidades.
- Definir lógica de entrada y salida personalizada – Establecer formatos de entrada/salida claros y personalizados es esencial para una integración fluida con las aplicaciones posteriores. Una de esas aplicaciones es JupyterAI, que analizamos en la sección siguiente.
Además, incluimos un serving.properties , que actúa como un archivo de configuración global para modelos alojados mediante el servicio DJL. Para obtener más información, consulte Configuraciones y ajustes.
Por último, también puedes incluir un requirements.txt archivo para definir módulos adicionales necesarios para la inferencia y empaquetar todo en un archivo tar para su implementación.
Ver el siguiente código:
Integre su punto final con el asistente de IA Jupyter de SageMaker Studio
IA de Jupyter es una herramienta de código abierto que lleva la IA generativa a los portátiles Jupyter, ofreciendo una plataforma sólida y fácil de usar para explorar modelos de IA generativa. Mejora la productividad en JupyterLab y los portátiles Jupyter al proporcionar funciones como %%ai magic para crear un área de juegos de IA generativa dentro de los portátiles, una interfaz de usuario de chat nativa en JupyterLab para interactuar con la IA como asistente de conversación y compatibilidad con una amplia gama de LLM de proveedores como Titán Amazonas, AI21, Anthropic, Cohere y Hugging Face o servicios gestionados como lecho rocoso del amazonas y puntos finales de SageMaker. Para esta publicación, utilizamos la integración lista para usar de Jupyter AI con los puntos finales de SageMaker para llevar la capacidad de texto a SQL a los cuadernos de JupyterLab. La herramienta Jupyter AI viene preinstalada en todos los espacios JupyterLab de SageMaker Studio respaldados por Imágenes de distribución de SageMaker; Los usuarios finales no necesitan realizar ninguna configuración adicional para comenzar a usar la extensión Jupyter AI para integrarla con un punto final alojado en SageMaker. En esta sección, analizamos las dos formas de utilizar la herramienta integrada Jupyter AI.
Jupyter AI dentro de un cuaderno usando magia
IA de Jupyter %%ai El comando mágico le permite transformar sus cuadernos SageMaker Studio JupyterLab en un entorno de IA generativo reproducible. Para comenzar a usar magias de IA, asegúrese de haber cargado la extensión jupyter_ai_magics para usar %%ai magia, y además cargar amazon_sagemaker_sql_magic que se utilizará %%sm_sql magia:
Para ejecutar una llamada a su punto final de SageMaker desde su computadora portátil usando el %%ai comando mágico, proporcione los siguientes parámetros y estructure el comando de la siguiente manera:
- –nombre-región – Especifique la región donde está implementado su punto final. Esto garantiza que la solicitud se envíe a la ubicación geográfica correcta.
- –esquema-solicitud – Incluir el esquema de los datos de entrada. Este esquema describe el formato esperado y los tipos de datos de entrada que su modelo necesita para procesar la solicitud.
- –ruta-respuesta – Defina la ruta dentro del objeto de respuesta donde se encuentra la salida de su modelo. Esta ruta se utiliza para extraer los datos relevantes de la respuesta devuelta por su modelo.
- -f (opcional) - Esto es un formateador de salida bandera que indica el tipo de salida devuelta por el modelo. En el contexto de un cuaderno de Jupyter, si la salida es código, este indicador debe configurarse en consecuencia para formatear la salida como código ejecutable en la parte superior de una celda del cuaderno de Jupyter, seguido de un área de entrada de texto libre para la interacción del usuario.
Por ejemplo, el comando en una celda del cuaderno de Jupyter podría parecerse al siguiente código:
Ventana de chat de Jupyter AI
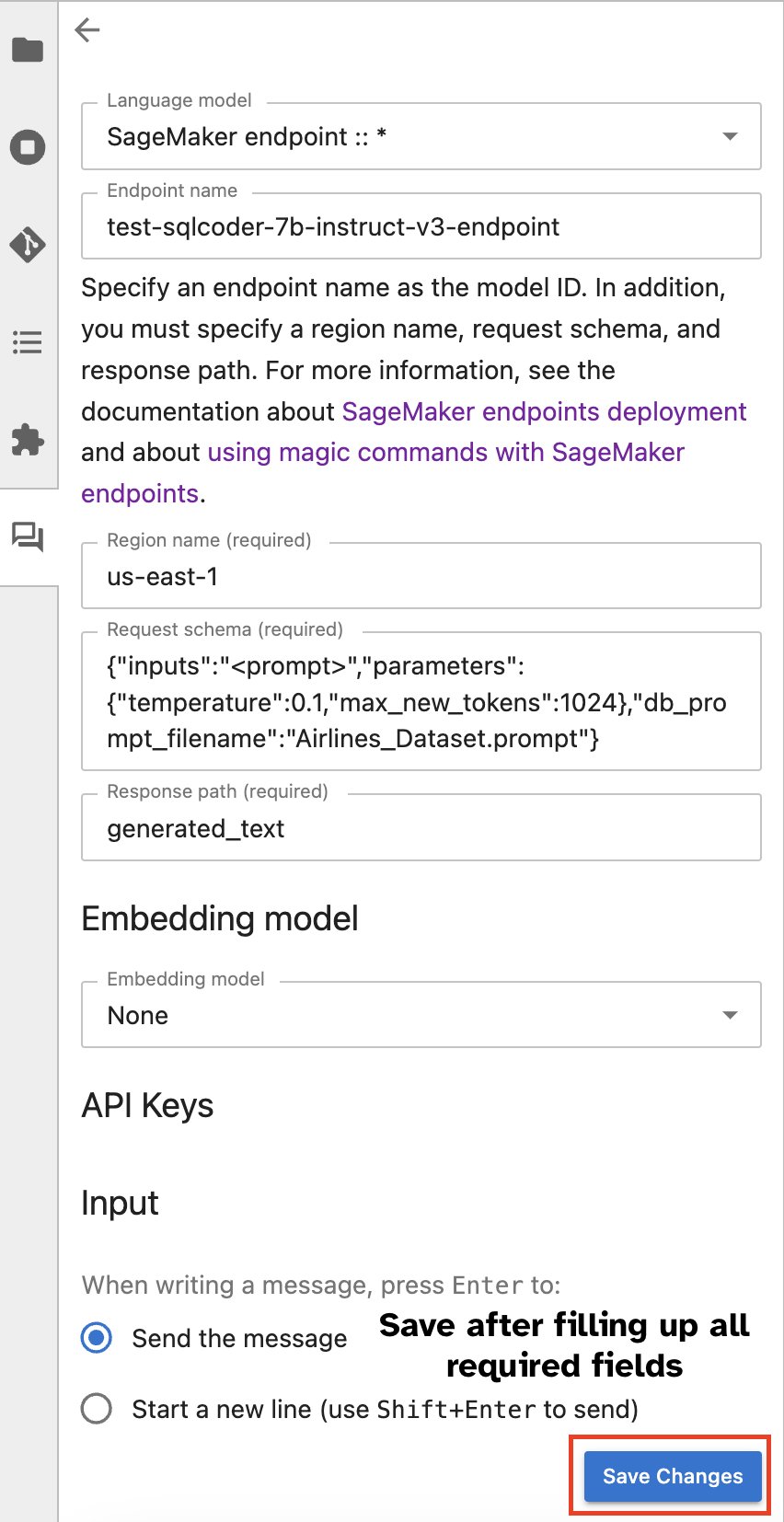
Alternativamente, puede interactuar con los puntos finales de SageMaker a través de una interfaz de usuario integrada, simplificando el proceso de generar consultas o entablar un diálogo. Antes de comenzar a chatear con su punto final de SageMaker, configure los ajustes relevantes en Jupyter AI para el punto final de SageMaker, como se muestra en la siguiente captura de pantalla.
 |
 |
Conclusión
SageMaker Studio ahora simplifica y agiliza el flujo de trabajo de los científicos de datos al integrar la compatibilidad con SQL en los cuadernos de JupyterLab. Esto permite a los científicos de datos concentrarse en sus tareas sin la necesidad de administrar múltiples herramientas. Además, la nueva integración SQL incorporada en SageMaker Studio permite a los usuarios de datos generar consultas SQL sin esfuerzo utilizando texto en lenguaje natural como entrada, acelerando así su flujo de trabajo.
Le recomendamos que explore estas funciones en SageMaker Studio. Para obtener más información, consulte Preparar datos con SQL en Studio.
Apéndice
Habilite el navegador SQL y la celda SQL del cuaderno en entornos personalizados
Si no está utilizando una imagen de distribución de SageMaker o está utilizando imágenes de distribución 1.5 o inferiores, ejecute los siguientes comandos para habilitar la función de exploración de SQL dentro de su entorno de JupyterLab:
Reubicar el widget del navegador SQL
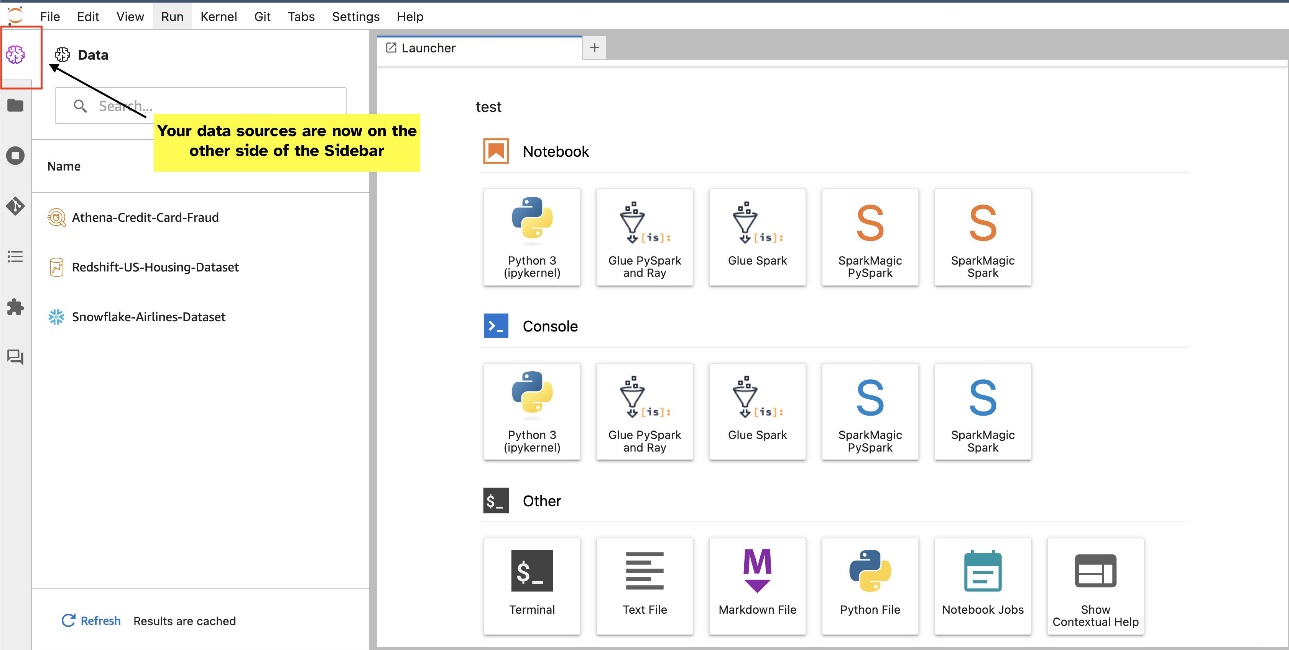
Los widgets de JupyterLab permiten la reubicación. Según sus preferencias, puede mover los widgets a cualquier lado del panel de widgets de JupyterLab. Si lo prefiere, puede mover la dirección del widget SQL al lado opuesto (de derecha a izquierda) de la barra lateral con un simple clic derecho en el icono del widget y eligiendo Cambiar lado de la barra lateral.
 |
 |
Sobre los autores
 Pranav Murthy es un arquitecto de soluciones especializado en IA/ML en AWS. Se centra en ayudar a los clientes a crear, entrenar, implementar y migrar cargas de trabajo de aprendizaje automático (ML) a SageMaker. Anteriormente trabajó en la industria de semiconductores desarrollando grandes modelos de visión por computadora (CV) y procesamiento de lenguaje natural (NLP) para mejorar los procesos de semiconductores utilizando técnicas de aprendizaje automático de última generación. En su tiempo libre le gusta jugar al ajedrez y viajar. Puedes encontrar Pranav en Etiqueta LinkedIn.
Pranav Murthy es un arquitecto de soluciones especializado en IA/ML en AWS. Se centra en ayudar a los clientes a crear, entrenar, implementar y migrar cargas de trabajo de aprendizaje automático (ML) a SageMaker. Anteriormente trabajó en la industria de semiconductores desarrollando grandes modelos de visión por computadora (CV) y procesamiento de lenguaje natural (NLP) para mejorar los procesos de semiconductores utilizando técnicas de aprendizaje automático de última generación. En su tiempo libre le gusta jugar al ajedrez y viajar. Puedes encontrar Pranav en Etiqueta LinkedIn.
 Varun Shah es un ingeniero de software que trabaja en Amazon SageMaker Studio en Amazon Web Services. Se centra en la creación de soluciones de aprendizaje automático interactivas que simplifiquen el procesamiento y la preparación de datos. En su tiempo libre, Varun disfruta de actividades al aire libre, como senderismo y esquí, y siempre está dispuesto a descubrir lugares nuevos y emocionantes.
Varun Shah es un ingeniero de software que trabaja en Amazon SageMaker Studio en Amazon Web Services. Se centra en la creación de soluciones de aprendizaje automático interactivas que simplifiquen el procesamiento y la preparación de datos. En su tiempo libre, Varun disfruta de actividades al aire libre, como senderismo y esquí, y siempre está dispuesto a descubrir lugares nuevos y emocionantes.
 Sumedha Swamy es gerente principal de productos en Amazon Web Services, donde lidera el equipo de SageMaker Studio en su misión de desarrollar el IDE preferido para la ciencia de datos y el aprendizaje automático. Ha dedicado los últimos 15 años a crear productos empresariales y de consumo basados en el aprendizaje automático.
Sumedha Swamy es gerente principal de productos en Amazon Web Services, donde lidera el equipo de SageMaker Studio en su misión de desarrollar el IDE preferido para la ciencia de datos y el aprendizaje automático. Ha dedicado los últimos 15 años a crear productos empresariales y de consumo basados en el aprendizaje automático.
 Bosco Alburquerque es Arquitecto sénior de soluciones de socios en AWS y tiene más de 20 años de experiencia trabajando con productos de análisis y bases de datos de proveedores de bases de datos empresariales y proveedores de la nube. Ha ayudado a empresas de tecnología a diseñar e implementar soluciones y productos de análisis de datos.
Bosco Alburquerque es Arquitecto sénior de soluciones de socios en AWS y tiene más de 20 años de experiencia trabajando con productos de análisis y bases de datos de proveedores de bases de datos empresariales y proveedores de la nube. Ha ayudado a empresas de tecnología a diseñar e implementar soluciones y productos de análisis de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

