Εισαγωγή
Αυτός ο οδηγός είναι το πρώτο μέρος τριών οδηγών σχετικά με τις μηχανές υποστήριξης διανυσμάτων (SVM). Σε αυτή τη σειρά, θα δουλέψουμε σε μια θήκη χρήσης πλαστών τραπεζογραμματίων, θα μάθουμε για τα απλά SVM, μετά για τις υπερπαράμετρους SVM και, τέλος, θα μάθουμε μια έννοια που ονομάζεται κόλπο πυρήνα και εξερευνήστε άλλους τύπους SVM.
Εάν θέλετε να διαβάσετε όλους τους οδηγούς ή να δείτε ποιοι σας ενδιαφέρουν περισσότερο, παρακάτω είναι ο πίνακας των θεμάτων που καλύπτονται σε κάθε οδηγό:
1. Εφαρμογή SVM και Kernel SVM με το Scikit-Learn της Python
- Περίπτωση χρήσης: ξεχάστε τα χαρτονομίσματα
- Ιστορικό των SVM
- Απλό (γραμμικό) μοντέλο SVM
- Σχετικά με το σύνολο δεδομένων
- Εισαγωγή του συνόλου δεδομένων
- Εξερευνώντας το σύνολο δεδομένων
- Εφαρμογή SVM με το Scikit-Learn
- Διαίρεση δεδομένων σε σύνολα αμαξοστοιχίας/δοκιμών
- Εκπαίδευση του Μοντέλου
- Κάνοντας προβλέψεις
- Αξιολόγηση του Μοντέλου
- Ερμηνεία Αποτελεσμάτων
2. Κατανόηση των Υπερπαραμέτρων SVM (Ερχομαι συντομα!)
- Η υπερπαράμετρος C
- Η υπερπαράμετρος γάμμα
3. Εφαρμογή άλλων γεύσεων SVM με το Scikit-Learn της Python (Ερχομαι συντομα!)
- Η γενική ιδέα των SVM (ανακεφαλαίωση)
- Πυρήνας (κόλπο) SVM
- Εφαρμογή SVM μη γραμμικού πυρήνα με το Scikit-Learn
- Εισαγωγή βιβλιοθηκών
- Εισαγωγή του συνόλου δεδομένων
- Διαίρεση δεδομένων σε χαρακτηριστικά (X) και στόχο (y)
- Διαίρεση δεδομένων σε σύνολα αμαξοστοιχίας/δοκιμών
- Εκπαίδευση του Αλγόριθμου
- Πολυωνυμικός πυρήνας
- Κάνοντας προβλέψεις
- Αξιολόγηση του Αλγορίθμου
- Γκαουσιανός πυρήνας
- Πρόβλεψη και Αξιολόγηση
- Σιγμοειδής πυρήνας
- Πρόβλεψη και Αξιολόγηση
- Σύγκριση μη γραμμικών επιδόσεων πυρήνα
Περίπτωση χρήσης: Πλαστά τραπεζογραμμάτια
Μερικές φορές οι άνθρωποι βρίσκουν έναν τρόπο να πλαστογραφούν τραπεζογραμμάτια. Εάν υπάρχει ένα άτομο που κοιτάζει αυτές τις σημειώσεις και επαληθεύει την εγκυρότητά τους, μπορεί να είναι δύσκολο να εξαπατηθεί από αυτές.
Τι γίνεται όμως όταν δεν υπάρχει άτομο να κοιτάξει κάθε νότα; Υπάρχει τρόπος να γνωρίζουμε αυτόματα αν τα τραπεζογραμμάτια είναι πλαστά ή αληθινά;
Υπάρχουν πολλοί τρόποι για να απαντήσετε σε αυτές τις ερωτήσεις. Μια απάντηση είναι να φωτογραφίσετε κάθε σημείωμα που λάβατε, να συγκρίνετε την εικόνα του με την εικόνα ενός πλαστού χαρτονομίσματος και στη συνέχεια να το ταξινομήσετε ως αληθινό ή πλαστό. Μόλις είναι κουραστικό ή κρίσιμο να περιμένετε την επικύρωση της σημείωσης, θα ήταν επίσης ενδιαφέρον να γίνει αυτή η σύγκριση γρήγορα.
Εφόσον χρησιμοποιούνται εικόνες, μπορούν να συμπιεστούν, να μειωθούν σε κλίμακα του γκρι και να εξαχθούν ή να κβαντιστούν οι μετρήσεις τους. Με αυτόν τον τρόπο, η σύγκριση θα γίνεται μεταξύ των μετρήσεων των εικόνων, αντί του εικονοστοιχείου κάθε εικόνας.
Μέχρι στιγμής, έχουμε βρει έναν τρόπο επεξεργασίας και σύγκρισης τραπεζογραμματίων, αλλά πώς θα ταξινομηθούν σε αληθινά ή πλαστά; Μπορούμε να χρησιμοποιήσουμε τη μηχανική μάθηση για να κάνουμε αυτήν την ταξινόμηση. Υπάρχει ένας αλγόριθμος ταξινόμησης που ονομάζεται Υποστήριξη μηχανής διάνυσμα, κυρίως γνωστό με τη συντομογραφία του: SVM.
Ιστορικό των SVM
Τα SVM εισήχθησαν αρχικά το 1968, από τους Vladmir Vapnik και Alexey Chervonenkis. Εκείνη την εποχή, ο αλγόριθμός τους περιοριζόταν στην ταξινόμηση δεδομένων που μπορούσαν να διαχωριστούν χρησιμοποιώντας μόνο μία ευθεία γραμμή ή δεδομένα που ήταν γραμμικά διαχωρίσιμο. Μπορούμε να δούμε πώς θα μοιάζει αυτός ο διαχωρισμός:

Στην παραπάνω εικόνα έχουμε μια γραμμή στη μέση, προς την οποία κάποια σημεία βρίσκονται στα αριστερά και άλλα είναι στα δεξιά αυτής της γραμμής. Παρατηρήστε ότι και οι δύο ομάδες σημείων είναι τέλεια διαχωρισμένες, δεν υπάρχουν σημεία μεταξύ ή ακόμα και κοντά στη γραμμή. Φαίνεται ότι υπάρχει ένα περιθώριο μεταξύ όμοιων σημείων και της γραμμής που τα χωρίζει, αυτό το περιθώριο ονομάζεται περιθώριο διαχωρισμού. Η λειτουργία του περιθωρίου διαχωρισμού είναι να κάνει μεγαλύτερο το διάστημα μεταξύ των όμοιων σημείων και της γραμμής που τα χωρίζει. Το SVM το κάνει αυτό χρησιμοποιώντας ορισμένα σημεία και υπολογίζει τα κάθετα διανύσματά του για να υποστηρίξει την απόφαση για το περιθώριο της γραμμής. Αυτά είναι τα φορείς υποστήριξης που αποτελούν μέρος του ονόματος του αλγορίθμου. Θα καταλάβουμε περισσότερα για αυτούς αργότερα. Και η ευθεία που βλέπουμε στη μέση βρίσκεται με μεθόδους που μεγιστοποίηση αυτό το διάστημα μεταξύ της γραμμής και των σημείων ή που μεγιστοποιούν το περιθώριο διαχωρισμού. Αυτές οι μέθοδοι προέρχονται από τον τομέα του Θεωρία Βελτιστοποίησης.
Στο παράδειγμα που μόλις είδαμε, και οι δύο ομάδες σημείων μπορούν εύκολα να διαχωριστούν, καθώς κάθε μεμονωμένο σημείο είναι κοντά στα παρόμοια σημεία του και οι δύο ομάδες είναι μακριά η μία από την άλλη.
Τι συμβαίνει όμως εάν δεν υπάρχει τρόπος διαχωρισμού των δεδομένων χρησιμοποιώντας μία ευθεία γραμμή; Εάν υπάρχουν ακατάστατα σημεία εκτός θέσης ή εάν χρειάζεται καμπύλη;
Για την επίλυση αυτού του προβλήματος, το SVM βελτιώθηκε αργότερα στη δεκαετία του 1990 ώστε να μπορεί επίσης να ταξινομεί δεδομένα που είχαν σημεία που απείχαν από την κεντρική του τάση, όπως ακραία σημεία ή πιο σύνθετα προβλήματα που είχαν περισσότερες από δύο διαστάσεις και δεν ήταν γραμμικά διαχωρισμένα. .
Αυτό που είναι περίεργο είναι ότι μόνο τα τελευταία χρόνια οι SVM έχουν υιοθετηθεί ευρέως, κυρίως λόγω της ικανότητάς τους να επιτυγχάνουν μερικές φορές περισσότερο από το 90% των σωστών απαντήσεων ή ακρίβεια, για δύσκολα προβλήματα.
Τα SVM υλοποιούνται με μοναδικό τρόπο σε σύγκριση με άλλους αλγόριθμους μηχανικής μάθησης, εφόσον βασίζονται σε στατιστικές εξηγήσεις για το τι είναι μάθηση ή Στατιστική μάθησης.
Σε αυτό το άρθρο, θα δούμε τι είναι οι αλγόριθμοι Support Vector Machines, τη σύντομη θεωρία πίσω από μια μηχανή διανυσμάτων υποστήριξης και την εφαρμογή τους στη βιβλιοθήκη Scikit-Learn της Python. Στη συνέχεια θα προχωρήσουμε προς μια άλλη έννοια SVM, γνωστή ως Πυρήνας SVM, ή Κόλπο πυρήνα, και θα το εφαρμόσει επίσης με τη βοήθεια του Scikit-Learn.
Απλό (γραμμικό) μοντέλο SVM
Σχετικά με το σύνολο δεδομένων
Ακολουθώντας το παράδειγμα που δίνεται στην εισαγωγή, θα χρησιμοποιήσουμε ένα σύνολο δεδομένων που έχει μετρήσεις πραγματικών και πλαστών εικόνων τραπεζογραμματίων.
Όταν κοιτάμε δύο νότες, τα μάτια μας συνήθως τις σαρώνουν από αριστερά προς τα δεξιά και ελέγχουν πού μπορεί να υπάρχουν ομοιότητες ή ανομοιότητες. Αναζητούμε μια μαύρη κουκκίδα πριν από μια πράσινη κουκκίδα ή ένα γυαλιστερό σημάδι που βρίσκεται πάνω από μια εικόνα. Αυτό σημαίνει ότι υπάρχει μια σειρά με την οποία εξετάζουμε τις σημειώσεις. Αν ξέραμε ότι υπήρχαν πράσινα και μαύρες κουκκίδες, αλλά όχι αν η πράσινη κουκκίδα ερχόταν πριν από τη μαύρη, ή αν η μαύρη ερχόταν πριν από την πράσινη, θα ήταν πιο δύσκολο να κάνουμε διάκριση μεταξύ των νότων.
Υπάρχει μια παρόμοια μέθοδος με αυτή που μόλις περιγράψαμε, η οποία μπορεί να εφαρμοστεί στις εικόνες των τραπεζογραμματίων. Σε γενικές γραμμές, αυτή η μέθοδος συνίσταται στη μετάφραση των εικονοστοιχείων της εικόνας σε σήμα και στη συνέχεια λαμβάνοντας υπόψη τη σειρά με την οποία συμβαίνει κάθε διαφορετικό σήμα στην εικόνα μετατρέποντάς το σε μικρά κύματα ή κυματίδια. Μετά την απόκτηση των κυματιδίων, υπάρχει ένας τρόπος να γνωρίζουμε τη σειρά με την οποία κάποιο σήμα συμβαίνει πριν από ένα άλλο, ή ώρα, αλλά όχι ακριβώς τι σήμα. Για να το γνωρίζουμε αυτό, πρέπει να ληφθούν οι συχνότητες της εικόνας. Λαμβάνονται με μια μέθοδο που κάνει την αποσύνθεση κάθε σήματος, που ονομάζεται Μέθοδος Fourier.
Μόλις ληφθεί η διάσταση του χρόνου μέσω των κυματιδίων και η διάσταση της συχνότητας μέσω της μεθόδου Fourier, γίνεται μια υπέρθεση χρόνου και συχνότητας για να δούμε πότε και τα δύο έχουν ταίριασμα, αυτό είναι το περιελιγμός ανάλυση. Η συνέλιξη αποκτά μια προσαρμογή που ταιριάζει με τα κυματίδια με τις συχνότητες της εικόνας και ανακαλύπτει ποιες συχνότητες είναι πιο εμφανείς.
Αυτή η μέθοδος που περιλαμβάνει την εύρεση των κυμάτων, των συχνοτήτων τους και στη συνέχεια την τοποθέτηση και των δύο, ονομάζεται Μετασχηματισμός κυματιδίων. Ο μετασχηματισμός κυματιδίου έχει συντελεστές και αυτοί οι συντελεστές χρησιμοποιήθηκαν για να ληφθούν οι μετρήσεις που έχουμε στο σύνολο δεδομένων.
Εισαγωγή του συνόλου δεδομένων
Το σύνολο δεδομένων τραπεζογραμματίων που πρόκειται να χρησιμοποιήσουμε σε αυτήν την ενότητα είναι το ίδιο που χρησιμοποιήθηκε στην ενότητα ταξινόμησης του Εκμάθηση δέντρου αποφάσεων.
Σημείωση: Μπορείτε να κατεβάσετε το σύνολο δεδομένων εδώ.
Ας εισάγουμε τα δεδομένα σε ένα panda dataframe δομή και ρίξτε μια ματιά στις πέντε πρώτες σειρές του με το head() μέθοδος.
Σημειώστε ότι τα δεδομένα αποθηκεύονται σε α txt (κείμενο) μορφή αρχείου, χωρισμένη με κόμμα, και είναι χωρίς κεφαλίδα. Μπορούμε να τον ανακατασκευάσουμε ως πίνακα διαβάζοντάς τον ως α csv, διευκρινίζοντας το separator ως κόμμα και προσθέτοντας τα ονόματα των στηλών με το names διαφωνία.
Ας ακολουθήσουμε αυτά τα τρία βήματα ταυτόχρονα και, στη συνέχεια, ας δούμε τις πρώτες πέντε σειρές των δεδομένων:
import pandas as pd data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ["variance", "skewness", "curtosis", "entropy", "class"] bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()
Αυτο εχει ως αποτελεσμα:
variance skewness curtosis entropy class
0 3.62160 8.6661 -2.8073 -0.44699 0
1 4.54590 8.1674 -2.4586 -1.46210 0
2 3.86600 -2.6383 1.9242 0.10645 0
3 3.45660 9.5228 -4.0112 -3.59440 0
4 0.32924 -4.4552 4.5718 -0.98880 0
Σημείωση: Μπορείτε επίσης να αποθηκεύσετε τα δεδομένα τοπικά και να τα αντικαταστήσετε data_link for data_path, και περάστε στη διαδρομή προς το τοπικό σας αρχείο.
Μπορούμε να δούμε ότι υπάρχουν πέντε στήλες στο σύνολο δεδομένων μας, δηλαδή, variance, skewness, curtosis, entropy, να class. Στις πέντε σειρές, οι τέσσερις πρώτες στήλες συμπληρώνονται με αριθμούς όπως 3.62160, 8.6661, -2.8073 ή συνεχής αξίες και το τελευταίο class η στήλη έχει τις πρώτες πέντε σειρές της γεμάτες με 0 ή α διακριτά αξία.
Δεδομένου ότι ο στόχος μας είναι να προβλέψουμε εάν ένα τραπεζογραμμάτιο είναι αυθεντικό ή όχι, μπορούμε να το κάνουμε αυτό με βάση τα τέσσερα χαρακτηριστικά του χαρτονομίσματος:
-
varianceεικόνας μετασχηματισμένης κυματιδίων. Γενικά, η διακύμανση είναι μια συνεχής τιμή που μετρά πόσο τα σημεία δεδομένων είναι κοντά ή μακριά από τη μέση τιμή των δεδομένων. Εάν τα σημεία είναι πιο κοντά στη μέση τιμή των δεδομένων, η κατανομή είναι πιο κοντά σε μια κανονική κατανομή, πράγμα που συνήθως σημαίνει ότι οι τιμές της είναι πιο καλά κατανεμημένες και κάπως πιο εύκολο να προβλεφθούν. Στο τρέχον πλαίσιο εικόνας, αυτή είναι η διακύμανση των συντελεστών που προκύπτουν από τον μετασχηματισμό κυματιδίων. Όσο λιγότερη διακύμανση, τόσο πιο κοντά ήταν οι συντελεστές στη μετάφραση της πραγματικής εικόνας. -
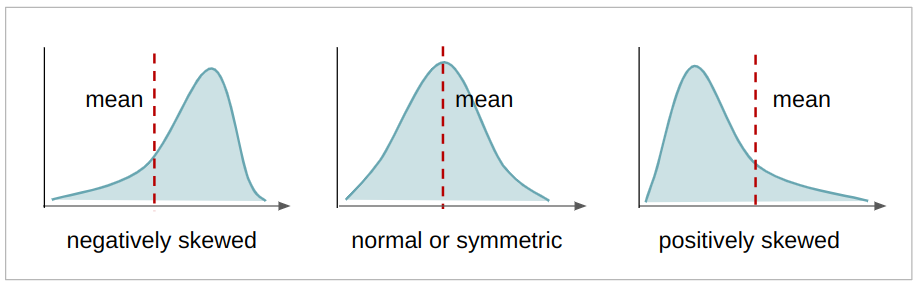
skewnessεικόνας μετασχηματισμένης κυματιδίων. Η λοξότητα είναι μια συνεχής τιμή που δείχνει την ασυμμετρία μιας κατανομής. Εάν υπάρχουν περισσότερες τιμές στα αριστερά του μέσου όρου, η κατανομή είναι λοξά αρνητικά, εάν υπάρχουν περισσότερες τιμές στα δεξιά του μέσου όρου, η κατανομή είναι θετικά λοξά, και αν ο μέσος όρος, ο τρόπος και ο διάμεσος είναι ο ίδιος, η κατανομή είναι συμμετρικός. Όσο πιο συμμετρική είναι μια κατανομή, τόσο πιο κοντά είναι σε μια κανονική κατανομή, έχοντας επίσης τις τιμές της πιο καλά κατανεμημένες. Στο παρόν πλαίσιο, αυτή είναι η λοξότητα των συντελεστών που προκύπτουν από τον μετασχηματισμό κυματιδίων. Όσο πιο συμμετρικοί, τόσο πιο κοντά είμαστε οι συντελεστέςvariance,skewness,curtosis,entropyγια τη μετάφραση της πραγματικής εικόνας.
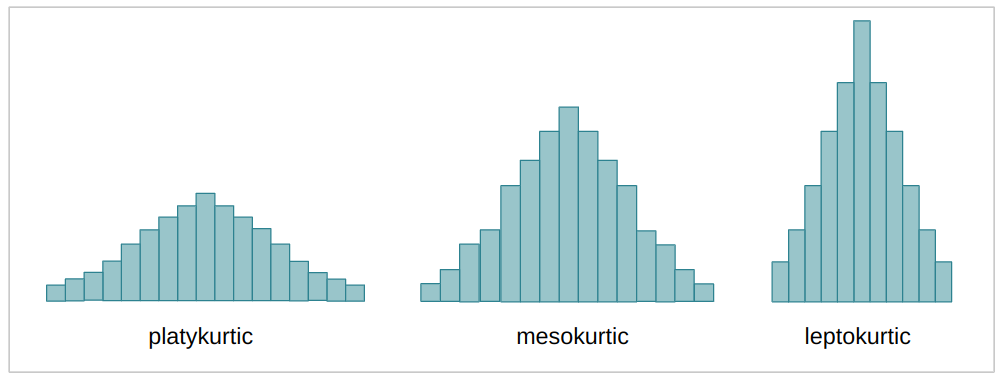
curtosis(ή κύρτωση) της μετασχηματισμένης εικόνας κυματιδίων. Η κύρτωση είναι μια συνεχής τιμή που, όπως η λοξότητα, περιγράφει επίσης το σχήμα μιας κατανομής. Ανάλογα με τον συντελεστή κύρτωσης (k), μια κατανομή – σε σύγκριση με την κανονική κατανομή μπορεί να είναι λίγο πολύ επίπεδη – ή να έχει περισσότερα ή λιγότερα δεδομένα στα άκρα ή τις ουρές της. Όταν η κατανομή είναι πιο απλωμένη και πιο επίπεδη, ονομάζεται πλατύκουρτικος; όταν είναι λιγότερο απλωμένο και πιο συγκεντρωμένο στη μέση, μεσοκουρτικός; και όταν η κατανομή είναι σχεδόν εξ ολοκλήρου συγκεντρωμένη στη μέση, καλείται leptokurtic. Αυτή είναι η ίδια περίπτωση με τις προηγούμενες περιπτώσεις διακύμανσης και λοξότητας, όσο πιο μεσοκουρτική είναι η κατανομή, τόσο πιο κοντά ήταν οι συντελεστές στη μετάφραση της πραγματικής εικόνας.
entropyτης εικόνας. Η εντροπία είναι επίσης μια συνεχής τιμή, συνήθως μετρά την τυχαιότητα ή την αταξία σε ένα σύστημα. Στο πλαίσιο μιας εικόνας, η εντροπία μετρά τη διαφορά μεταξύ ενός εικονοστοιχείου και των γειτονικών του εικονοστοιχείων. Για το περιβάλλον μας, όσο περισσότερη εντροπία έχουν οι συντελεστές, τόσο μεγαλύτερη ήταν η απώλεια κατά τον μετασχηματισμό της εικόνας – και όσο μικρότερη η εντροπία, τόσο μικρότερη η απώλεια πληροφοριών.

Η πέμπτη μεταβλητή ήταν η class μεταβλητή, η οποία πιθανώς έχει τιμές 0 και 1, που λένε αν η σημείωση ήταν πραγματική ή πλαστό.
Μπορούμε να ελέγξουμε αν η πέμπτη στήλη περιέχει μηδενικά και μονάδες με Pandas' unique() μέθοδος:
bankdata['class'].unique()
Η παραπάνω μέθοδος επιστρέφει:
array([0, 1]) Η παραπάνω μέθοδος επιστρέφει έναν πίνακα με τιμές 0 και 1. Αυτό σημαίνει ότι οι μόνες τιμές που περιέχονται στις σειρές της κλάσης μας είναι μηδενικά και μονάδες. Είναι έτοιμο να χρησιμοποιηθεί ως στόχος στην εποπτευόμενη μάθησή μας.
classτης εικόνας. Αυτή είναι μια ακέραια τιμή, είναι 0 όταν η εικόνα είναι πλαστογραφημένη και 1 όταν η εικόνα είναι πραγματική.
Εφόσον έχουμε μια στήλη με τους σχολιασμούς πραγματικών και ξεχασμένων εικόνων, αυτό σημαίνει ότι ο τύπος μάθησής μας είναι εποπτεία.
Συμβουλές: για να μάθετε περισσότερα σχετικά με το σκεπτικό πίσω από το Wavelet Transform στις εικόνες των τραπεζογραμματίων και τη χρήση του SVM, διαβάστε τη δημοσιευμένη εργασία των συγγραφέων.
Μπορούμε επίσης να δούμε πόσες εγγραφές ή εικόνες έχουμε, κοιτάζοντας τον αριθμό των σειρών στα δεδομένα μέσω του shape ιδιοκτησία:
bankdata.shape
Αυτό βγάζει:
(1372, 5)
Η παραπάνω γραμμή σημαίνει ότι υπάρχουν 1,372 σειρές μετασχηματισμένων εικόνων τραπεζογραμματίων και 5 στήλες. Αυτά είναι τα δεδομένα που θα αναλύσουμε.
Εισαγάγαμε το σύνολο δεδομένων μας και κάναμε μερικούς ελέγχους. Τώρα μπορούμε να εξερευνήσουμε τα δεδομένα μας για να τα κατανοήσουμε καλύτερα.
Εξερευνώντας το σύνολο δεδομένων
Μόλις είδαμε ότι υπάρχουν μόνο μηδενικά και ένα στη στήλη της τάξης, αλλά μπορούμε επίσης να γνωρίζουμε σε ποια αναλογία είναι – με άλλα λόγια – αν υπάρχουν περισσότερα μηδενικά από ένα, περισσότερα ένα από μηδενικά ή αν οι αριθμοί των τα μηδενικά είναι ίδια με τον αριθμό των μονάδων, δηλαδή είναι ισόρροπη.
Για να γνωρίζουμε την αναλογία μπορούμε να μετρήσουμε καθεμία από τις τιμές μηδέν και μία στα δεδομένα με value_counts() μέθοδος:
bankdata['class'].value_counts()
Αυτό βγάζει:
0 762
1 610
Name: class, dtype: int64
Στο παραπάνω αποτέλεσμα, μπορούμε να δούμε ότι υπάρχουν 762 μηδενικά και 610 ένα, ή 152 περισσότερα μηδενικά από ένα. Αυτό σημαίνει ότι έχουμε λίγο περισσότερες πλαστογραφημένες από τις πραγματικές εικόνες, και αν αυτή η απόκλιση ήταν μεγαλύτερη, για παράδειγμα, 5500 μηδενικά και 610 μονάδες, θα μπορούσε να επηρεάσει αρνητικά τα αποτελέσματά μας. Μόλις προσπαθούμε να χρησιμοποιήσουμε αυτά τα παραδείγματα στο μοντέλο μας – όσα περισσότερα παραδείγματα υπάρχουν, συνήθως σημαίνει ότι όσες περισσότερες πληροφορίες θα πρέπει το μοντέλο να αποφασίσει μεταξύ πλαστών ή πραγματικών σημειώσεων – εάν υπάρχουν λίγα παραδείγματα πραγματικών σημειώσεων, το μοντέλο είναι επιρρεπές σε κάνει λάθος όταν προσπαθεί να τα αναγνωρίσει.
Γνωρίζουμε ήδη ότι υπάρχουν 152 ακόμη πλαστές σημειώσεις, αλλά μπορούμε να είμαστε σίγουροι ότι είναι αρκετά παραδείγματα για να μάθει το μοντέλο; Το να γνωρίζουμε πόσα παραδείγματα χρειάζονται για τη μάθηση είναι μια πολύ δύσκολη ερώτηση για να απαντήσουμε, αντίθετα, μπορούμε να προσπαθήσουμε να καταλάβουμε, σε ποσοστιαία βάση, πόση είναι αυτή η διαφορά μεταξύ των τάξεων.
Το πρώτο βήμα είναι να χρησιμοποιήσετε πάντα τα πάντα value_counts() μέθοδο πάλι, αλλά τώρα ας δούμε το ποσοστό συμπεριλαμβάνοντας το όρισμα normalize=True:
bankdata['class'].value_counts(normalize=True)
Η normalize=True υπολογίζει το ποσοστό των δεδομένων για κάθε τάξη. Μέχρι στιγμής, το ποσοστό των πλαστών (0) και των πραγματικών δεδομένων (1) είναι:
0 0.555394
1 0.444606
Name: class, dtype: float64
Αυτό σημαίνει ότι περίπου το (~) 56% του συνόλου δεδομένων μας είναι πλαστό και το 44% του είναι πραγματικό. Αυτό μας δίνει μια αναλογία 56%-44%, η οποία είναι ίδια με μια διαφορά 12%. Αυτή στατιστικά θεωρείται μικρή διαφορά, γιατί είναι μόλις λίγο πάνω από το 10%, άρα τα δεδομένα θεωρούνται ισορροπημένα. Εάν αντί για μια αναλογία 56:44, υπήρχε μια αναλογία 80:20 ή 70:30, τότε τα δεδομένα μας θα θεωρούνταν ανισορροπημένα και θα έπρεπε να κάνουμε κάποια αντιμετώπιση ανισορροπίας, αλλά, ευτυχώς, αυτό δεν ισχύει.
Μπορούμε επίσης να δούμε αυτή τη διαφορά οπτικά, ρίχνοντας μια ματιά στην κατανομή της τάξης ή του στόχου με ένα ιστόγραμμα εμποτισμένο με Pandas, χρησιμοποιώντας:
bankdata['class'].plot.hist();
Αυτό σχεδιάζει ένα ιστόγραμμα χρησιμοποιώντας τη δομή του πλαισίου δεδομένων απευθείας, σε συνδυασμό με το matplotlib βιβλιοθήκη που βρίσκεται στα παρασκήνια.

Εξετάζοντας το ιστόγραμμα, μπορούμε να είμαστε σίγουροι ότι οι τιμές στόχου μας είναι είτε 0 είτε 1 και ότι τα δεδομένα είναι ισορροπημένα.
Αυτή ήταν μια ανάλυση της στήλης που προσπαθούσαμε να προβλέψουμε, αλλά τι γίνεται με την ανάλυση των άλλων στηλών των δεδομένων μας;
Μπορούμε να ρίξουμε μια ματιά στις στατιστικές μετρήσεις με το describe() μέθοδος πλαισίου δεδομένων. Μπορούμε επίσης να χρησιμοποιήσουμε .T της μετατόπισης – για την αντιστροφή στηλών και σειρών, καθιστώντας πιο άμεση τη σύγκριση μεταξύ των τιμών:
Ρίξτε μια ματιά στον πρακτικό μας οδηγό για την εκμάθηση του Git, με βέλτιστες πρακτικές, πρότυπα αποδεκτά από τον κλάδο και συμπεριλαμβανόμενο φύλλο εξαπάτησης. Σταματήστε τις εντολές του Git στο Google και πραγματικά μαθαίνουν το!
bankdata.describe().T
Αυτο εχει ως αποτελεσμα:
count mean std min 25% 50% 75% max
variance 1372.0 0.433735 2.842763 -7.0421 -1.773000 0.49618 2.821475 6.8248
skewness 1372.0 1.922353 5.869047 -13.7731 -1.708200 2.31965 6.814625 12.9516
curtosis 1372.0 1.397627 4.310030 -5.2861 -1.574975 0.61663 3.179250 17.9274
entropy 1372.0 -1.191657 2.101013 -8.5482 -2.413450 -0.58665 0.394810 2.4495
class 1372.0 0.444606 0.497103 0.0000 0.000000 0.00000 1.000000 1.0000
Παρατηρήστε ότι οι στήλες λοξότητας και κύρτωσης έχουν μέσες τιμές που απέχουν πολύ από τις τιμές τυπικής απόκλισης, αυτό δείχνει ότι αυτές οι τιμές που απέχουν περισσότερο από την κεντρική τάση των δεδομένων ή έχουν μεγαλύτερη μεταβλητότητα.
Μπορούμε επίσης να ρίξουμε μια ματιά στην κατανομή κάθε χαρακτηριστικού οπτικά, σχεδιάζοντας το ιστόγραμμα κάθε χαρακτηριστικού μέσα σε έναν βρόχο for. Εκτός από την εξέταση της κατανομής, θα ήταν ενδιαφέρον να δούμε πώς διαχωρίζονται τα σημεία κάθε κατηγορίας για κάθε χαρακτηριστικό. Για να γίνει αυτό, μπορούμε να σχεδιάσουμε μια γραφική παράσταση διασποράς κάνοντας έναν συνδυασμό χαρακτηριστικών μεταξύ τους και να αντιστοιχίσουμε διαφορετικά χρώματα σε κάθε σημείο σε σχέση με την κατηγορία του.
Ας ξεκινήσουμε με την κατανομή κάθε χαρακτηριστικού και σχεδιάζουμε το ιστόγραμμα κάθε στήλης δεδομένων εκτός από το class στήλη. ο class Η στήλη δεν θα λαμβάνεται υπόψη από τη θέση της στον πίνακα στηλών τραπεζικών δεδομένων. Θα επιλεγούν όλες οι στήλες εκτός από την τελευταία με columns[:-1]:
import matplotlib.pyplot as plt for col in bankdata.columns[:-1]: plt.title(col) bankdata[col].plot.hist() plt.show();
Αφού εκτελέσουμε τον παραπάνω κώδικα, μπορούμε να δούμε ότι και τα δύο skewness και entropy οι κατανομές δεδομένων είναι αρνητικά λοξές και curtosis είναι θετικά λοξή. Όλες οι κατανομές είναι συμμετρικές και variance είναι η μόνη κατανομή που είναι κοντά στο φυσιολογικό.
Μπορούμε τώρα να προχωρήσουμε στο δεύτερο μέρος και να σχεδιάσουμε το διάγραμμα διασποράς κάθε μεταβλητής. Για να γίνει αυτό, μπορούμε επίσης να επιλέξουμε όλες τις στήλες εκτός από την κλάση, with columns[:-1], χρησιμοποιήστε το Seaborn's scatterplot() και δύο για βρόχους για να λάβετε τις παραλλαγές στο ζευγάρωμα για καθένα από τα χαρακτηριστικά. Μπορούμε επίσης να αποκλείσουμε τη σύζευξη ενός χαρακτηριστικού με τον εαυτό του, δοκιμάζοντας εάν το πρώτο χαρακτηριστικό ισούται με το δεύτερο με ένα if statement.
import seaborn as sns for feature_1 in bankdata.columns[:-1]: for feature_2 in bankdata.columns[:-1]: if feature_1 != feature_2: print(feature_1, feature_2) sns.scatterplot(x=feature_1, y=feature_2, data=bankdata, hue='class') plt.show();
Παρατηρήστε ότι όλα τα γραφήματα έχουν τόσο πραγματικά όσο και πλαστά σημεία δεδομένων που δεν διαχωρίζονται σαφώς μεταξύ τους, αυτό σημαίνει ότι υπάρχει κάποιο είδος υπέρθεσης κλάσεων. Εφόσον ένα μοντέλο SVM χρησιμοποιεί μια γραμμή για διαχωρισμό μεταξύ κλάσεων, θα μπορούσε οποιαδήποτε από αυτές τις ομάδες στα γραφήματα να διαχωριστεί χρησιμοποιώντας μόνο μία γραμμή; Φαίνεται απίθανο. Έτσι μοιάζουν τα περισσότερα πραγματικά δεδομένα. Το πιο κοντινό που μπορούμε να φτάσουμε σε έναν χωρισμό είναι ο συνδυασμός των skewness και variance, ή entropy και variance οικόπεδα. Αυτό μάλλον οφείλεται σε variance δεδομένα που έχουν σχήμα κατανομής πιο κοντά στο κανονικό.
Αλλά η εξέταση όλων αυτών των γραφημάτων στη σειρά μπορεί να είναι λίγο δύσκολη. Έχουμε την εναλλακτική να δούμε όλα τα γραφήματα κατανομής και διασποράς μαζί χρησιμοποιώντας το Seaborn's pairplot().
Και οι δύο προηγούμενοι βρόχοι for που είχαμε κάνει μπορούν να αντικατασταθούν από αυτήν ακριβώς τη γραμμή:
sns.pairplot(bankdata, hue='class');
Κοιτάζοντας το pairplot, φαίνεται ότι, στην πραγματικότητα, curtosis και variance θα ήταν ο ευκολότερος συνδυασμός χαρακτηριστικών, επομένως οι διαφορετικές κατηγορίες θα μπορούσαν να χωριστούν με μια γραμμή ή γραμμικά διαχωρίσιμο.
Εάν τα περισσότερα δεδομένα απέχουν πολύ από το να είναι γραμμικά διαχωριστά, μπορούμε να προσπαθήσουμε να τα επεξεργαστούμε εκ των προτέρων, μειώνοντας τις διαστάσεις τους, και επίσης να κανονικοποιήσουμε τις τιμές τους για να προσπαθήσουμε να κάνουμε την κατανομή πιο κοντά σε ένα κανονικό.
Για αυτήν την περίπτωση, ας χρησιμοποιήσουμε τα δεδομένα ως έχουν, χωρίς περαιτέρω προεπεξεργασία, και αργότερα, μπορούμε να πάμε ένα βήμα πίσω, να προσθέσουμε στην προεπεξεργασία δεδομένων και να συγκρίνουμε τα αποτελέσματα.
Συμβουλές: Κατά την εργασία με δεδομένα, συνήθως χάνονται πληροφορίες κατά τη μετατροπή τους, επειδή κάνουμε προσεγγίσεις, αντί να συλλέγουμε περισσότερα δεδομένα. Η εργασία με τα αρχικά δεδομένα πρώτα όπως είναι, εάν είναι δυνατόν, προσφέρει μια βασική γραμμή πριν δοκιμάσετε άλλες τεχνικές προεπεξεργασίας. Όταν ακολουθείτε αυτή τη διαδρομή, το αρχικό αποτέλεσμα που χρησιμοποιεί ακατέργαστα δεδομένα μπορεί να συγκριθεί με ένα άλλο αποτέλεσμα που χρησιμοποιεί τεχνικές προεπεξεργασίας στα δεδομένα.
Σημείωση: Συνήθως στη Στατιστική, κατά την κατασκευή μοντέλων, είναι σύνηθες να ακολουθούμε μια διαδικασία ανάλογα με το είδος των δεδομένων (διακριτά, συνεχή, κατηγορικά, αριθμητικά), την κατανομή τους και τις υποθέσεις του μοντέλου. Ενώ στην Επιστήμη Υπολογιστών (CS), υπάρχει περισσότερος χώρος για δοκιμή, σφάλματα και νέες επαναλήψεις. Στο CS είναι σύνηθες να υπάρχει μια βασική γραμμή για σύγκριση. Στο Scikit-learn, υπάρχει μια εφαρμογή εικονικών μοντέλων (ή εικονικών εκτιμητών), μερικά δεν είναι καλύτερα από το να πετάς ένα νόμισμα και απλά απαντήστε Ναί (ή 1) 50% του χρόνου. Είναι ενδιαφέρον να χρησιμοποιούμε εικονικά μοντέλα ως βάση για το πραγματικό μοντέλο κατά τη σύγκριση των αποτελεσμάτων. Αναμένεται ότι τα πραγματικά αποτελέσματα του μοντέλου είναι καλύτερα από μια τυχαία εικασία, διαφορετικά η χρήση ενός μοντέλου μηχανικής μάθησης δεν θα ήταν απαραίτητη.
Εφαρμογή SVM με το Scikit-Learn
Πριν ασχοληθούμε περισσότερο με τη θεωρία του πώς λειτουργεί το SVM, μπορούμε να δημιουργήσουμε το πρώτο μας βασικό μοντέλο με τα δεδομένα και το Scikit-Learn's Υποστήριξη Vector Classifier or SVC τάξη.
Το μοντέλο μας θα λάβει τους συντελεστές wavelet και θα προσπαθήσει να τους ταξινομήσει με βάση την κλάση. Το πρώτο βήμα σε αυτή τη διαδικασία είναι ο διαχωρισμός των συντελεστών ή χαρακτηριστικά από την τάξη ή στόχος. Μετά από αυτό το βήμα, το δεύτερο βήμα είναι η περαιτέρω διαίρεση των δεδομένων σε ένα σύνολο που θα χρησιμοποιηθεί για την εκμάθηση του μοντέλου ή σύνολο τρένου και ένα άλλο που θα χρησιμοποιηθεί για την αξιολόγηση του μοντέλου ή σύνολο δοκιμών.
Σημείωση: Η ονοματολογία των δοκιμών και της αξιολόγησης μπορεί να είναι λίγο συγκεχυμένη, επειδή μπορείτε επίσης να χωρίσετε τα δεδομένα σας μεταξύ συνόλων τρένου, αξιολόγησης και δοκιμών. Με αυτόν τον τρόπο, αντί να έχετε δύο σετ, θα έχετε ένα ενδιάμεσο σετ απλώς για να το χρησιμοποιήσετε και να δείτε εάν η απόδοση του μοντέλου σας βελτιώνεται. Αυτό σημαίνει ότι το μοντέλο θα εκπαιδευτεί με το σύνολο αμαξοστοιχίας, θα ενισχυθεί με το σύνολο αξιολόγησης και θα αποκτήσει μια τελική μέτρηση με το σύνολο δοκιμής.
Μερικοί άνθρωποι λένε ότι η αξιολόγηση είναι αυτό το ενδιάμεσο σύνολο, άλλοι θα πουν ότι το σετ δοκιμής είναι το ενδιάμεσο σύνολο και ότι το σύνολο αξιολόγησης είναι το τελικό σύνολο. Αυτός είναι ένας άλλος τρόπος για να προσπαθήσουμε να εγγυηθούμε ότι το μοντέλο δεν βλέπει το ίδιο παράδειγμα με οποιονδήποτε τρόπο ή ότι κάποιο είδος διαρροή δεδομένων δεν συμβαίνει και ότι υπάρχει γενίκευση μοντέλου με τη βελτίωση των μετρήσεων του τελευταίου συνόλου. Εάν θέλετε να ακολουθήσετε αυτήν την προσέγγιση, μπορείτε να διαιρέσετε περαιτέρω τα δεδομένα για άλλη μια φορά όπως περιγράφεται σε αυτό Scikit-Learn's train_test_split() – Σύνολα εκπαίδευσης, δοκιμών και επικύρωσης οδηγός.
Διαίρεση δεδομένων σε σύνολα αμαξοστοιχίας/δοκιμών
Στην προηγούμενη συνεδρία, κατανοήσαμε και διερευνήσαμε τα δεδομένα. Τώρα, μπορούμε να διαιρέσουμε τα δεδομένα μας σε δύο συστοιχίες – έναν για τα τέσσερα χαρακτηριστικά και έναν άλλο για το πέμπτο, ή χαρακτηριστικό στόχο. Εφόσον θέλουμε να προβλέψουμε την κλάση ανάλογα με τους συντελεστές κυματιδίων, μας y θα είναι το class στήλη και μας X θα το variance, skewness, curtosis, να entropy στήλες.
Για να διαχωρίσουμε τον στόχο και τα χαρακτηριστικά, μπορούμε να αποδώσουμε μόνο το class στήλη προς y, αποβάλλοντάς το αργότερα από το πλαίσιο δεδομένων για να αποδοθούν οι υπόλοιπες στήλες X με .drop() μέθοδος:
y = bankdata['class']
X = bankdata.drop('class', axis=1) Μόλις τα δεδομένα χωριστούν σε χαρακτηριστικά και ετικέτες, μπορούμε να τα χωρίσουμε περαιτέρω σε σύνολα τρένων και δοκιμών. Αυτό θα μπορούσε να γίνει με το χέρι, αλλά το model_selection βιβλιοθήκη του Scikit-Learn περιέχει το train_test_split() μέθοδος που μας επιτρέπει να διαιρούμε τυχαία τα δεδομένα σε σύνολα αμαξοστοιχιών και δοκιμών.
Για να το χρησιμοποιήσουμε, μπορούμε να εισάγουμε τη βιβλιοθήκη, να καλέσουμε το train_test_split() μέθοδος, περάστε X και y δεδομένα και ορίστε α test_size να περάσει ως επιχείρημα. Σε αυτή την περίπτωση, θα το ορίσουμε ως 0.20– αυτό σημαίνει ότι το 20% των δεδομένων θα χρησιμοποιηθεί για δοκιμές και το υπόλοιπο 80% για εκπαίδευση.
Αυτή η μέθοδος λαμβάνει τυχαία δείγματα με σεβασμό στο ποσοστό που έχουμε ορίσει, αλλά σέβεται τα ζεύγη Xy, μήπως η δειγματοληψία θα μπερδέψει τελείως τη σχέση.
Δεδομένου ότι η διαδικασία δειγματοληψίας είναι εγγενώς τυχαία, θα έχουμε πάντα διαφορετικά αποτελέσματα κατά την εκτέλεση της μεθόδου. Για να μπορούμε να έχουμε τα ίδια αποτελέσματα, ή αναπαραγώγιμα αποτελέσματα, μπορούμε να ορίσουμε μια σταθερά που ονομάζεται SEED με την τιμή 42.
Μπορείτε να εκτελέσετε το ακόλουθο σενάριο για να το κάνετε:
from sklearn.model_selection import train_test_split SEED = 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
Παρατηρήστε ότι το train_test_split() μέθοδος επιστρέφει ήδη το X_train, X_test, y_train, y_test θέτει με αυτή τη σειρά. Μπορούμε να εκτυπώσουμε τον αριθμό των δειγμάτων που διαχωρίστηκαν για τρένο και δοκιμή παίρνοντας το πρώτο (0) στοιχείο του shape περιουσία που επιστράφηκε πλειάδα:
xtrain_samples = X_train.shape[0]
xtest_samples = X_test.shape[0] print(f'There are {xtrain_samples} samples for training and {xtest_samples} samples for testing.')
Αυτό δείχνει ότι υπάρχουν 1097 δείγματα για εκπαίδευση και 275 για δοκιμή.
Εκπαίδευση του Μοντέλου
Έχουμε χωρίσει τα δεδομένα σε σετ τρένων και δοκιμών. Τώρα είναι ώρα να δημιουργήσετε και να εκπαιδεύσετε ένα μοντέλο SVM στα δεδομένα της αμαξοστοιχίας. Για να γίνει αυτό, μπορούμε να εισάγουμε Scikit-Learn's svm βιβλιοθήκη μαζί με το Υποστήριξη Vector Classifier τάξη, ή SVC τάξη.
Μετά την εισαγωγή της κλάσης, μπορούμε να δημιουργήσουμε ένα στιγμιότυπο της – καθώς δημιουργούμε ένα απλό μοντέλο SVM, προσπαθούμε να διαχωρίσουμε τα δεδομένα μας γραμμικά, ώστε να μπορούμε να σχεδιάσουμε μια γραμμή για να διαιρέσουμε τα δεδομένα μας – που είναι το ίδιο με τη χρήση ενός γραμμική συνάρτηση – ορίζοντας kernel='linear' ως επιχείρημα για τον ταξινομητή:
from sklearn.svm import SVC
svc = SVC(kernel='linear')
Με αυτόν τον τρόπο, ο ταξινομητής θα προσπαθήσει να βρει μια γραμμική συνάρτηση που διαχωρίζει τα δεδομένα μας. Αφού δημιουργήσουμε το μοντέλο, ας το εκπαιδεύσουμε ή ταιριάζουν αυτό, με τα δεδομένα του τρένου, που χρησιμοποιεί το fit() μέθοδο και δίνοντας το X_train χαρακτηριστικά και y_train στόχους ως επιχειρήματα.
Μπορούμε να εκτελέσουμε τον ακόλουθο κώδικα για να εκπαιδεύσουμε το μοντέλο:
svc.fit(X_train, y_train)
Ακριβώς έτσι, το μοντέλο είναι εκπαιδευμένο. Μέχρι στιγμής, κατανοήσαμε τα δεδομένα, τα χωρίσαμε, δημιουργήσαμε ένα απλό μοντέλο SVM και προσαρμόσαμε το μοντέλο στα δεδομένα του τρένου.
Το επόμενο βήμα είναι να κατανοήσουμε πόσο καλά κατάφερε αυτή η εφαρμογή να περιγράψει τα δεδομένα μας. Με άλλα λόγια, να απαντήσουμε εάν ένα γραμμικό SVM ήταν μια επαρκής επιλογή.
Κάνοντας προβλέψεις
Ένας τρόπος για να απαντήσετε εάν το μοντέλο κατάφερε να περιγράψει τα δεδομένα είναι να υπολογίσετε και να εξετάσετε κάποια ταξινόμηση μετρήσεις.
Λαμβάνοντας υπόψη ότι η μάθηση εποπτεύεται, μπορούμε να κάνουμε προβλέψεις με X_test και συγκρίνετε αυτά τα αποτελέσματα πρόβλεψης – τα οποία θα μπορούσαμε να ονομάσουμε y_pred – με το πραγματικό y_test, ή επίγεια αλήθεια.
Για να προβλέψουμε ορισμένα από τα δεδομένα, του μοντέλου predict() μπορεί να χρησιμοποιηθεί μέθοδος. Αυτή η μέθοδος λαμβάνει τα χαρακτηριστικά δοκιμής, X_test, ως όρισμα και επιστρέφει μια πρόβλεψη, είτε 0 είτε 1, για καθένα από αυτά X_testσειρές του.
Μετά την πρόβλεψη των X_test δεδομένα, τα αποτελέσματα αποθηκεύονται σε α y_pred μεταβλητός. Έτσι, κάθε μία από τις κλάσεις που προβλέπονται με το απλό γραμμικό μοντέλο SVM είναι τώρα στο y_pred μεταβλητός.
Αυτός είναι ο κωδικός πρόβλεψης:
y_pred = svc.predict(X_test)
Λαμβάνοντας υπόψη ότι έχουμε τις προβλέψεις, μπορούμε τώρα να τις συγκρίνουμε με τα πραγματικά αποτελέσματα.
Αξιολόγηση του Μοντέλου
Υπάρχουν διάφοροι τρόποι σύγκρισης των προβλέψεων με τα πραγματικά αποτελέσματα και μετρούν διαφορετικές πτυχές μιας ταξινόμησης. Μερικές πιο χρησιμοποιούμενες μετρήσεις ταξινόμησης είναι:
-
Πίνακας σύγχυσης: όταν πρέπει να γνωρίζουμε πόσα δείγματα πήραμε σωστά ή λάθος κάθε τάξη. Καλούνται οι τιμές που ήταν σωστές και σωστά προβλεπόμενες αληθινά θετικά, λέγονται αυτά που είχαν προβλεφθεί ως θετικά αλλά δεν ήταν θετικά ψευδώς θετικά. Η ίδια ονοματολογία του αληθινά αρνητικά και ψευδώς αρνητικά χρησιμοποιείται για αρνητικές τιμές.
-
Ακρίβεια: όταν ο στόχος μας είναι να κατανοήσουμε ποιες σωστές τιμές πρόβλεψης θεωρήθηκαν σωστές από τον ταξινομητή μας. Η ακρίβεια θα διαιρέσει αυτές τις αληθινές θετικές τιμές με τα δείγματα που είχαν προβλεφθεί ως θετικά.
$$
precision = frac{text{true positives}}{text{true positives} + text{false positives}}
$$
- Ανάκληση: συνήθως υπολογίζεται μαζί με ακρίβεια για να κατανοήσουμε πόσα από τα αληθινά θετικά εντοπίστηκαν από τον ταξινομητή μας. Η ανάκληση υπολογίζεται διαιρώντας τα αληθινά θετικά με οτιδήποτε θα έπρεπε να είχε προβλεφθεί ως θετικό.
$$
ανάκληση = frac{text{true positives}}{text{true positives} + text{false negatives}}
$$
- Βαθμολογία F1: είναι η ισορροπημένη ή αρμονική μέση της ακρίβειας και της ανάκλησης. Η χαμηλότερη τιμή είναι 0 και η υψηλότερη είναι 1. Όταν
f1-scoreισούται με 1, σημαίνει ότι όλες οι κατηγορίες είχαν προβλεφθεί σωστά – αυτό είναι πολύ δύσκολο να επιτευχθεί με πραγματικά δεδομένα (εξαιρέσεις υπάρχουν σχεδόν πάντα).
$$
text{f1-score} = 2* frac{text{precision} * text{recal}}{text{precision} + text{recall}}
$$
Έχουμε ήδη εξοικειωθεί με τα μέτρα μήτρας σύγχυσης, ακρίβειας, ανάκλησης και βαθμολογίας F1. Για να τα υπολογίσουμε, μπορούμε να εισάγουμε Scikit-Learn's metrics βιβλιοθήκη. Αυτή η βιβλιοθήκη περιέχει το classification_report και confusion_matrix μεθόδους, η μέθοδος αναφοράς ταξινόμησης επιστρέφει τη βαθμολογία ακρίβειας, ανάκλησης και f1. Και τα δυο classification_report και confusion_matrix μπορεί εύκολα να χρησιμοποιηθεί για να ανακαλύψει τις τιμές για όλες αυτές τις σημαντικές μετρήσεις.
Για τον υπολογισμό των μετρήσεων, εισάγουμε τις μεθόδους, τις καλούμε και μεταβιβάζουμε ως ορίσματα τις προβλεπόμενες ταξινομήσεις, y_test, και τις ετικέτες ταξινόμησης, ή y_true.
Για καλύτερη οπτικοποίηση του πίνακα σύγχυσης, μπορούμε να τον σχεδιάσουμε σε ένα Seaborn's heatmap μαζί με σχολιασμούς ποσότητας και για την αναφορά ταξινόμησης, είναι καλύτερο να εκτυπώσετε το αποτέλεσμά της, ώστε τα αποτελέσματά της να μορφοποιηθούν. Αυτός είναι ο παρακάτω κώδικας:
from sklearn.metrics import classification_report, confusion_matrix cm = confusion_matrix(y_test,y_pred)
sns.heatmap(cm, annot=True, fmt='d').set_title('Confusion matrix of linear SVM') print(classification_report(y_test,y_pred))
Αυτό εμφανίζει:
precision recall f1-score support 0 0.99 0.99 0.99 148 1 0.98 0.98 0.98 127 accuracy 0.99 275 macro avg 0.99 0.99 0.99 275
weighted avg 0.99 0.99 0.99 275

Στην αναφορά ταξινόμησης, γνωρίζουμε ότι υπάρχει ακρίβεια 0.99, ανάκληση 0.99 και βαθμολογία f1 0.99 για τα πλαστά χαρτονομίσματα ή κατηγορία 0. Αυτές οι μετρήσεις ελήφθησαν χρησιμοποιώντας 148 δείγματα όπως φαίνεται στη στήλη υποστήριξης. Εν τω μεταξύ, για την κλάση 1, ή τις πραγματικές νότες, το αποτέλεσμα ήταν μία μονάδα παρακάτω, 0.98 ακρίβειας, 0.98 ανάκλησης και η ίδια βαθμολογία f1. Αυτή τη φορά, χρησιμοποιήθηκαν 127 μετρήσεις εικόνας για τη λήψη αυτών των αποτελεσμάτων.
Αν κοιτάξουμε τον πίνακα σύγχυσης, μπορούμε επίσης να δούμε ότι από 148 δείγματα κατηγορίας 0, τα 146 ταξινομήθηκαν σωστά και υπήρχαν 2 ψευδώς θετικά, ενώ για 127 δείγματα κατηγορίας 1, υπήρχαν 2 ψευδώς αρνητικά και 125 αληθινά θετικά.
Μπορούμε να διαβάσουμε την αναφορά ταξινόμησης και τον πίνακα σύγχυσης, αλλά τι σημαίνουν;
Ερμηνεία Αποτελεσμάτων
Για να μάθετε το νόημα, ας δούμε όλες τις μετρήσεις σε συνδυασμό.
Σχεδόν όλα τα δείγματα για την κατηγορία 1 ταξινομήθηκαν σωστά, υπήρχαν 2 λάθη για το μοντέλο μας κατά τον προσδιορισμό των πραγματικών τραπεζογραμματίων. Αυτό είναι το ίδιο με το 0.98, ή 98%, ανάκληση. Κάτι παρόμοιο μπορούμε να πούμε για την κατηγορία 0, μόνο 2 δείγματα ταξινομήθηκαν λανθασμένα, ενώ 148 είναι αληθινά αρνητικά, με συνολική ακρίβεια 99%.
Εκτός από αυτά τα αποτελέσματα, όλα τα άλλα σημειώνουν 0.99, που είναι σχεδόν 1, μια πολύ υψηλή μέτρηση. Τις περισσότερες φορές, όταν συμβαίνει μια τόσο υψηλή μέτρηση με δεδομένα πραγματικής ζωής, αυτό μπορεί να υποδεικνύει ένα μοντέλο που είναι υπερβολικά προσαρμοσμένο στα δεδομένα, ή υπερπροσαρμοσμένο.
Όταν υπάρχει υπερπροσαρμογή, το μοντέλο μπορεί να λειτουργεί καλά κατά την πρόβλεψη των δεδομένων που είναι ήδη γνωστά, αλλά χάνει την ικανότητα γενίκευσης σε νέα δεδομένα, κάτι που είναι σημαντικό σε σενάρια πραγματικού κόσμου.
Ένα γρήγορο τεστ για να μάθετε αν συμβαίνει υπερπροσάρτηση είναι επίσης με δεδομένα τρένου. Εάν το μοντέλο έχει απομνημονεύσει κάπως τα δεδομένα του τρένου, οι μετρήσεις θα είναι πολύ κοντά στο 1 ή στο 100%. Θυμηθείτε ότι τα δεδομένα του τρένου είναι μεγαλύτερα από τα δεδομένα των δοκιμών – για αυτόν τον λόγο – προσπαθήστε να τα δείτε αναλογικά, περισσότερα δείγματα, περισσότερες πιθανότητες να κάνετε λάθη, εκτός αν υπήρξε κάποια υπερπροσαρμογή.
Για να προβλέψουμε με δεδομένα τρένου, μπορούμε να επαναλάβουμε αυτό που κάναμε για τα δεδομένα δοκιμών, αλλά τώρα με X_train:
y_pred_train = svc.predict(X_train) cm_train = confusion_matrix(y_train,y_pred_train)
sns.heatmap(cm_train, annot=True, fmt='d').set_title('Confusion matrix of linear SVM with train data') print(classification_report(y_train,y_pred_train))
Αυτό βγάζει:
precision recall f1-score support 0 0.99 0.99 0.99 614 1 0.98 0.99 0.99 483 accuracy 0.99 1097 macro avg 0.99 0.99 0.99 1097
weighted avg 0.99 0.99 0.99 1097

Είναι εύκολο να δει κανείς ότι φαίνεται να υπάρχει υπερπροσαρμογή, αφού οι μετρήσεις του τρένου είναι 99% όταν έχουν 4 φορές περισσότερα δεδομένα. Τι μπορεί να γίνει σε αυτό το σενάριο;
Για να επαναφέρουμε την υπερπροσαρμογή, μπορούμε να προσθέσουμε περισσότερες παρατηρήσεις τρένου, να χρησιμοποιήσουμε μια μέθοδο εκπαίδευσης με διαφορετικά μέρη του συνόλου δεδομένων, όπως π.χ. διασταυρωμένη επικύρωση, και επίσης αλλάξτε τις προεπιλεγμένες παραμέτρους που υπάρχουν ήδη πριν από την εκπαίδευση, κατά τη δημιουργία του μοντέλου μας ή υπερπαραμέτρους. Τις περισσότερες φορές, το Scikit-learn ορίζει ορισμένες παραμέτρους ως προεπιλογές και αυτό μπορεί να συμβεί σιωπηλά εάν δεν αφιερωθεί πολύς χρόνος για την ανάγνωση της τεκμηρίωσης.
Μπορείτε να ελέγξετε το δεύτερο μέρος αυτού του οδηγού (έρχεται σύντομα!) για να δείτε πώς μπορείτε να εφαρμόσετε διασταυρούμενη επικύρωση και να εκτελέσετε συντονισμό υπερπαραμέτρων.
Συμπέρασμα
Σε αυτό το άρθρο μελετήσαμε τον απλό γραμμικό πυρήνα SVM. Πήραμε τη διαίσθηση πίσω από τον αλγόριθμο SVM, χρησιμοποιήσαμε ένα πραγματικό σύνολο δεδομένων, εξερευνήσαμε τα δεδομένα και είδαμε πώς αυτά τα δεδομένα μπορούν να χρησιμοποιηθούν μαζί με το SVM, υλοποιώντας τα με τη βιβλιοθήκη Scikit-Learn της Python.
Για να συνεχίσετε την εξάσκηση, μπορείτε να δοκιμάσετε άλλα σύνολα δεδομένων πραγματικού κόσμου διαθέσιμα σε μέρη όπως Kaggle, UCI, Δημόσια σύνολα δεδομένων Big Query, πανεπιστήμια και κυβερνητικούς ιστότοπους.
Θα πρότεινα επίσης να εξερευνήσετε τα πραγματικά μαθηματικά πίσω από το μοντέλο SVM. Αν και δεν θα το χρειαστείτε απαραίτητα για να χρησιμοποιήσετε τον αλγόριθμο SVM, εξακολουθείτε να είναι πολύ βολικό να γνωρίζετε τι πραγματικά συμβαίνει στα παρασκήνια ενώ ο αλγόριθμός σας βρίσκει όρια απόφασης.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- Minting the Future με την Adryenn Ashley. Πρόσβαση εδώ.
- πηγή: https://stackabuse.com/implementing-svm-and-kernel-svm-with-pythons-scikit-learn/

