Στο εξελισσόμενο τοπίο της κατασκευής, η μεταμορφωτική δύναμη της τεχνητής νοημοσύνης και της μηχανικής μάθησης (ML) είναι εμφανής, οδηγώντας μια ψηφιακή επανάσταση που εξορθολογίζει τις λειτουργίες και ενισχύει την παραγωγικότητα. Ωστόσο, αυτή η πρόοδος εισάγει μοναδικές προκλήσεις για τις επιχειρήσεις που πλοηγούνται σε λύσεις που βασίζονται σε δεδομένα. Οι βιομηχανικές εγκαταστάσεις παλεύουν με τεράστιους όγκους μη δομημένων δεδομένων, που προέρχονται από αισθητήρες, συστήματα τηλεμετρίας και εξοπλισμό διασκορπισμένο στις γραμμές παραγωγής. Τα δεδομένα σε πραγματικό χρόνο είναι κρίσιμα για εφαρμογές όπως η προγνωστική συντήρηση και η ανίχνευση ανωμαλιών, ωστόσο η ανάπτυξη προσαρμοσμένων μοντέλων ML για κάθε περίπτωση βιομηχανικής χρήσης με τέτοια δεδομένα χρονοσειρών απαιτεί σημαντικό χρόνο και πόρους από τους επιστήμονες δεδομένων, εμποδίζοντας την ευρεία υιοθέτηση.
Παραγωγική τεχνητή νοημοσύνη χρησιμοποιώντας μεγάλα προεκπαιδευμένα μοντέλα θεμελίωσης (FM) όπως π.χ Claude μπορεί να δημιουργήσει γρήγορα μια ποικιλία περιεχομένου από κείμενο συνομιλίας έως κώδικα υπολογιστή με βάση απλές προτροπές κειμένου, γνωστές ως προτροπή μηδενικής βολής. Αυτό εξαλείφει την ανάγκη για τους επιστήμονες δεδομένων να αναπτύσσουν με μη αυτόματο τρόπο συγκεκριμένα μοντέλα ML για κάθε περίπτωση χρήσης και επομένως εκδημοκρατίζει την πρόσβαση σε τεχνητή νοημοσύνη, προς όφελος ακόμη και των μικρών κατασκευαστών. Οι εργαζόμενοι αποκτούν παραγωγικότητα μέσω γνώσεων που δημιουργούνται από την τεχνητή νοημοσύνη, οι μηχανικοί μπορούν να ανιχνεύουν προληπτικά ανωμαλίες, οι διαχειριστές της εφοδιαστικής αλυσίδας βελτιστοποιούν τα αποθέματα και η ηγεσία του εργοστασίου λαμβάνει ενημερωμένες αποφάσεις που βασίζονται σε δεδομένα.
Ωστόσο, τα αυτόνομα FM αντιμετωπίζουν περιορισμούς στο χειρισμό σύνθετων βιομηχανικών δεδομένων με περιορισμούς μεγέθους περιβάλλοντος (συνήθως λιγότερο από 200,000 μάρκες), το οποίο θέτει προκλήσεις. Για να το αντιμετωπίσετε, μπορείτε να χρησιμοποιήσετε την ικανότητα του FM να δημιουργεί κώδικα ως απάντηση σε ερωτήματα φυσικής γλώσσας (NLQ). Πράκτορες όπως pandasAI μπαίνουν στο παιχνίδι, εκτελώντας αυτόν τον κώδικα σε δεδομένα χρονοσειρών υψηλής ανάλυσης και χειρίζονται σφάλματα χρησιμοποιώντας FM. Το PandasAI είναι μια βιβλιοθήκη Python που προσθέτει δυνατότητες παραγωγής τεχνητής νοημοσύνης στα panda, το δημοφιλές εργαλείο ανάλυσης και χειρισμού δεδομένων.
Ωστόσο, πολύπλοκα NLQ, όπως η επεξεργασία δεδομένων χρονοσειρών, η συνάθροιση πολλών επιπέδων και οι λειτουργίες συγκεντρωτικού ή κοινού πίνακα, μπορεί να αποδώσουν ασυνεπή ακρίβεια σεναρίου Python με μια προτροπή μηδενικής λήψης.
Για να βελτιώσουμε την ακρίβεια δημιουργίας κώδικα, προτείνουμε τη δυναμική κατασκευή προτροπές πολλαπλών λήψεων για NLQ. Η προτροπή πολλαπλών λήψεων παρέχει πρόσθετο πλαίσιο στο FM δείχνοντάς του πολλά παραδείγματα επιθυμητών εξόδων για παρόμοια μηνύματα, ενισχύοντας την ακρίβεια και τη συνέπεια. Σε αυτήν την ανάρτηση, οι προτροπές πολλαπλών λήψεων ανακτώνται από μια ενσωμάτωση που περιέχει επιτυχημένο κώδικα Python που εκτελείται σε παρόμοιο τύπο δεδομένων (για παράδειγμα, δεδομένα χρονοσειρών υψηλής ανάλυσης από συσκευές Internet of Things). Η δυναμικά κατασκευασμένη προτροπή πολλαπλών λήψεων παρέχει το πιο σχετικό πλαίσιο για το FM και ενισχύει την ικανότητα του FM για προηγμένους μαθηματικούς υπολογισμούς, επεξεργασία δεδομένων χρονοσειρών και κατανόηση ακρωνύμιων δεδομένων. Αυτή η βελτιωμένη απόκριση διευκολύνει τους εργαζόμενους στις επιχειρήσεις και τις επιχειρησιακές ομάδες να εμπλακούν με δεδομένα, αντλώντας πληροφορίες χωρίς να απαιτούνται εκτενείς δεξιότητες επιστήμης δεδομένων.
Πέρα από την ανάλυση δεδομένων χρονοσειρών, τα FM αποδεικνύονται πολύτιμα σε διάφορες βιομηχανικές εφαρμογές. Οι ομάδες συντήρησης αξιολογούν την υγεία των περιουσιακών στοιχείων, καταγράφουν εικόνες για Αναγνώριση Amazon-βασισμένες περιλήψεις λειτουργικότητας και ανάλυση βασικών αιτιών ανωμαλιών χρησιμοποιώντας έξυπνες αναζητήσεις με Ανάκτηση επαυξημένης γενιάς (ΚΟΥΡΕΛΙ). Για να απλοποιήσει αυτές τις ροές εργασίας, το AWS εισήγαγε Θεμέλιο του Αμαζονίου, επιτρέποντάς σας να δημιουργείτε και να κλιμακώνετε παραγωγικές εφαρμογές AI με προηγμένα προεκπαιδευμένα FM όπως Claude v2. Με Βάσεις γνώσεων για το Amazon Bedrock, μπορείτε να απλοποιήσετε τη διαδικασία ανάπτυξης RAG για να παρέχετε πιο ακριβή ανάλυση της βασικής αιτίας ανωμαλιών για τους εργαζόμενους στα εργοστάσια. Η ανάρτησή μας παρουσιάζει έναν έξυπνο βοηθό για περιπτώσεις βιομηχανικής χρήσης που υποστηρίζεται από το Amazon Bedrock, αντιμετωπίζοντας προκλήσεις NLQ, δημιουργώντας περιλήψεις μερών από εικόνες και βελτιώνοντας τις απαντήσεις FM για τη διάγνωση εξοπλισμού μέσω της προσέγγισης RAG.
Επισκόπηση λύσεων
Το παρακάτω διάγραμμα απεικονίζει την αρχιτεκτονική λύσεων.
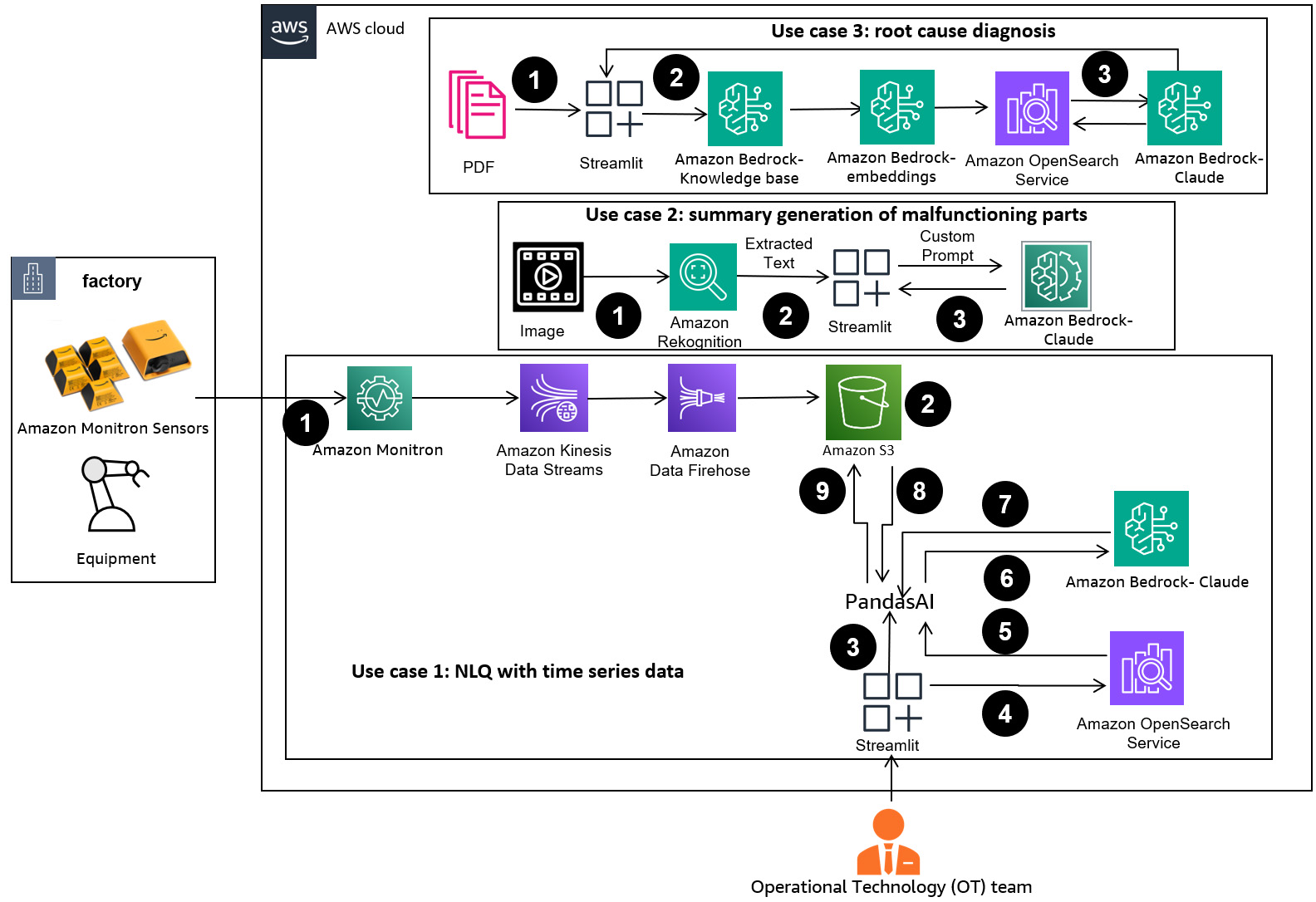
Η ροή εργασίας περιλαμβάνει τρεις διακριτές περιπτώσεις χρήσης:
Περίπτωση χρήσης 1: NLQ με δεδομένα χρονοσειρών
Η ροή εργασίας για το NLQ με δεδομένα χρονοσειρών αποτελείται από τα ακόλουθα βήματα:
- Χρησιμοποιούμε σύστημα παρακολούθησης καταστάσεων με δυνατότητες ML για ανίχνευση ανωμαλιών, όπως π.χ Amazon Monitron, για την παρακολούθηση της υγείας του βιομηχανικού εξοπλισμού. Η Amazon Monitron είναι σε θέση να ανιχνεύσει πιθανές αστοχίες εξοπλισμού από τις μετρήσεις κραδασμών και θερμοκρασίας του εξοπλισμού.
- Συλλέγουμε δεδομένα χρονοσειρών με επεξεργασία Amazon Monitron δεδομένα μέσω Ροές δεδομένων Amazon Kinesis και Amazon Data Firehose, μετατρέποντάς το σε μορφή πίνακα CSV και αποθηκεύοντάς το σε ένα Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) κάδος.
- Ο τελικός χρήστης μπορεί να αρχίσει να συνομιλεί με τα δεδομένα χρονοσειρών του στο Amazon S3 στέλνοντας ένα ερώτημα φυσικής γλώσσας στην εφαρμογή Streamlit.
- Η εφαρμογή Streamlit προωθεί τα ερωτήματα των χρηστών στο Μοντέλο ενσωμάτωσης κειμένου Amazon Bedrock Titan για να ενσωματώσει αυτό το ερώτημα και εκτελεί μια αναζήτηση ομοιότητας μέσα σε ένα Amazon OpenSearch Service ευρετήριο, το οποίο περιέχει προηγούμενα NLQ και παραδείγματα κωδικών.
- Μετά την αναζήτηση ομοιότητας, τα κορυφαία παρόμοια παραδείγματα, συμπεριλαμβανομένων των ερωτήσεων NLQ, του σχήματος δεδομένων και των κωδικών Python, εισάγονται σε μια προσαρμοσμένη προτροπή.
- Η PandasAI στέλνει αυτήν την προσαρμοσμένη προτροπή στο μοντέλο Amazon Bedrock Claude v2.
- Η εφαρμογή χρησιμοποιεί τον πράκτορα PandasAI για να αλληλεπιδράσει με το μοντέλο Amazon Bedrock Claude v2, δημιουργώντας κώδικα Python για ανάλυση δεδομένων Amazon Monitron και απαντήσεις NLQ.
- Αφού το μοντέλο Amazon Bedrock Claude v2 επιστρέψει τον κώδικα Python, το PandasAI εκτελεί το ερώτημα Python στα δεδομένα του Amazon Monitron που ανεβαίνουν από την εφαρμογή, συλλέγοντας εξόδους κώδικα και αντιμετωπίζοντας τυχόν απαραίτητες επαναλήψεις για αποτυχημένες εκτελέσεις.
- Η εφαρμογή Streamlit συλλέγει την απάντηση μέσω του PandasAI και παρέχει την έξοδο στους χρήστες. Εάν η έξοδος είναι ικανοποιητική, ο χρήστης μπορεί να την επισημάνει ως χρήσιμη, αποθηκεύοντας τον κώδικα Python που δημιουργήθηκε από το NLQ και τον Claude στην Υπηρεσία OpenSearch.
Περίπτωση χρήσης 2: Συνοπτική δημιουργία εξαρτημάτων που δυσλειτουργούν
Η περίληψη χρήσης της παραγωγής μας αποτελείται από τα ακόλουθα βήματα:
- Αφού ο χρήστης γνωρίζει ποιο βιομηχανικό στοιχείο παρουσιάζει ανώμαλη συμπεριφορά, μπορεί να ανεβάσει εικόνες του εξαρτήματος που δυσλειτουργεί για να εντοπίσει εάν υπάρχει κάποιο πρόβλημα σωματικά με αυτό το εξάρτημα σύμφωνα με τις τεχνικές προδιαγραφές και την κατάσταση λειτουργίας του.
- Ο χρήστης μπορεί να χρησιμοποιήσει το Amazon Recognition DetectText API για εξαγωγή δεδομένων κειμένου από αυτές τις εικόνες.
- Τα εξαγόμενα δεδομένα κειμένου περιλαμβάνονται στην προτροπή για το μοντέλο Amazon Bedrock Claude v2, επιτρέποντας στο μοντέλο να δημιουργήσει μια περίληψη 200 λέξεων του τμήματος που δυσλειτουργεί. Ο χρήστης μπορεί να χρησιμοποιήσει αυτές τις πληροφορίες για να πραγματοποιήσει περαιτέρω έλεγχο του εξαρτήματος.
Περίπτωση χρήσης 3: Διάγνωση ριζικής αιτίας
Η περίπτωση χρήσης της διάγνωσης της βασικής αιτίας αποτελείται από τα ακόλουθα βήματα:
- Ο χρήστης λαμβάνει εταιρικά δεδομένα σε διάφορες μορφές εγγράφων (PDF, TXT κ.λπ.) που σχετίζονται με δυσλειτουργικά στοιχεία και τα ανεβάζει σε έναν κάδο S3.
- Μια βάση γνώσεων αυτών των αρχείων δημιουργείται στο Amazon Bedrock με ένα μοντέλο ενσωματώσεων κειμένου Titan και ένα προεπιλεγμένο διανυσματικό κατάστημα OpenSearch Service.
- Ο χρήστης θέτει ερωτήσεις σχετικά με τη διάγνωση της βασικής αιτίας για δυσλειτουργία του εξοπλισμού. Οι απαντήσεις παράγονται μέσω της βάσης γνώσεων Amazon Bedrock με μια προσέγγιση RAG.
Προϋποθέσεις
Για να ακολουθήσετε αυτήν την ανάρτηση, θα πρέπει να πληροίτε τις ακόλουθες προϋποθέσεις:
Αναπτύξτε την υποδομή λύσης
Για να ρυθμίσετε τους πόρους λύσης, ολοκληρώστε τα παρακάτω βήματα:
- Αναπτύξτε το AWS CloudFormation πρότυπο opensearchsagemaker.yml, το οποίο δημιουργεί μια συλλογή και ευρετήριο OpenSearch Service, Amazon Sage Maker παράδειγμα φορητού υπολογιστή και κάδος S3. Μπορείτε να ονομάσετε αυτήν τη στοίβα AWS CloudFormation ως:
genai-sagemaker. - Ανοίξτε την παρουσία του σημειωματάριου SageMaker στο JupyterLab. Θα βρείτε τα παρακάτω GitHub repo έχει ήδη ληφθεί σε αυτήν την περίπτωση: ξεκλείδωμα-το-δυναμικό-παραγωγικών-ai-στη-βιομηχανική-λειτουργία.
- Εκτελέστε το σημειωματάριο από τον ακόλουθο κατάλογο σε αυτό το αποθετήριο: unlocking-the-potential-of-generative-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Αυτό το σημειωματάριο θα φορτώσει το ευρετήριο της υπηρεσίας OpenSearch χρησιμοποιώντας το σημειωματάριο SageMaker για την αποθήκευση ζευγών κλειδιών-τιμών από το υπάρχοντα 23 παραδείγματα NLQ.
- Μεταφορτώστε έγγραφα από το φάκελο δεδομένων assetpartdoc στο αποθετήριο GitHub στον κάδο S3 που αναφέρεται στις εξόδους της στοίβας CloudFormation.

Στη συνέχεια, δημιουργείτε τη βάση γνώσεων για τα έγγραφα στο Amazon S3.
- Στην κονσόλα Amazon Bedrock, επιλέξτε Βάση γνώσεων στο παράθυρο πλοήγησης.
- Επιλέξτε Δημιουργήστε βάση γνώσεων.
- Για Όνομα βάσης γνώσεων, πληκτρολογήστε ένα όνομα.
- Για Ρόλος χρόνου εκτέλεσης, Επιλέξτε Δημιουργήστε και χρησιμοποιήστε έναν νέο ρόλο υπηρεσίας.

- Για Όνομα πηγής δεδομένων, εισαγάγετε το όνομα της πηγής δεδομένων σας.
- Για S3 URI, εισαγάγετε τη διαδρομή S3 του κάδου όπου ανεβάσατε τα έγγραφα της βασικής αιτίας.
- Επιλέξτε Επόμενο.
 Το μοντέλο ενσωματώσεων Titan επιλέγεται αυτόματα.
Το μοντέλο ενσωματώσεων Titan επιλέγεται αυτόματα. - Αγορά Γρήγορη δημιουργία ενός νέου διανυσματικού καταστήματος.

- Ελέγξτε τις ρυθμίσεις σας και δημιουργήστε τη βάση γνώσεων επιλέγοντας Δημιουργήστε βάση γνώσεων.
- Αφού δημιουργηθεί με επιτυχία η βάση γνώσεων, επιλέξτε Συγχρονισμός για να συγχρονίσετε τον κάδο S3 με τη βάση γνώσεων.

- Αφού δημιουργήσετε τη βάση γνώσεων, μπορείτε να δοκιμάσετε την προσέγγιση RAG για τη διάγνωση της βασικής αιτίας θέτοντας ερωτήσεις όπως "Ο ενεργοποιητής μου ταξιδεύει αργά, ποιο μπορεί να είναι το πρόβλημα;"

Το επόμενο βήμα είναι να αναπτύξετε την εφαρμογή με τα απαιτούμενα πακέτα βιβλιοθήκης είτε στον υπολογιστή σας είτε σε μια παρουσία EC2 (Ubuntu Server 22.04 LTS).
- Ρυθμίστε τα διαπιστευτήριά σας AWS με το AWS CLI στον τοπικό σας υπολογιστή. Για απλότητα, μπορείτε να χρησιμοποιήσετε τον ίδιο ρόλο διαχειριστή που χρησιμοποιήσατε για την ανάπτυξη της στοίβας CloudFormation. Εάν χρησιμοποιείτε το Amazon EC2, επισυνάψτε έναν κατάλληλο ρόλο IAM στο στιγμιότυπο.
- Κλώνος GitHub repo:
- Αλλάξτε τον κατάλογο σε
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcκαι εκτελέστε τοsetup.shδέσμη ενεργειών σε αυτόν τον φάκελο για να εγκαταστήσετε τα απαιτούμενα πακέτα, συμπεριλαμβανομένων των LangChain και PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Εκτελέστε την εφαρμογή Streamlit με την ακόλουθη εντολή:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Παρέχετε τη συλλογή ARN της υπηρεσίας OpenSearch που δημιουργήσατε στο Amazon Bedrock από το προηγούμενο βήμα.
Συνομιλήστε με τον βοηθό υγείας περιουσιακών στοιχείων σας
Αφού ολοκληρώσετε την ανάπτυξη από άκρο σε άκρο, μπορείτε να αποκτήσετε πρόσβαση στην εφαρμογή μέσω του localhost στη θύρα 8501, η οποία ανοίγει ένα παράθυρο του προγράμματος περιήγησης με τη διεπαφή ιστού. Εάν αναπτύξατε την εφαρμογή σε μια παρουσία EC2, επιτρέψτε την πρόσβαση στη θύρα 8501 μέσω του κανόνα εισερχόμενης ομάδας ασφαλείας. Μπορείτε να πλοηγηθείτε σε διαφορετικές καρτέλες για διάφορες περιπτώσεις χρήσης.
Εξερευνήστε την περίπτωση χρήσης 1
Για να εξερευνήσετε την πρώτη περίπτωση χρήσης, επιλέξτε Δεδομένα Insight και Διάγραμμα. Ξεκινήστε ανεβάζοντας τα δεδομένα χρονοσειρών σας. Εάν δεν έχετε ένα υπάρχον αρχείο δεδομένων χρονικής σειράς για χρήση, μπορείτε να ανεβάσετε τα ακόλουθα δείγμα αρχείου CSV με ανώνυμα δεδομένα έργου Amazon Monitron. Εάν έχετε ήδη ένα έργο Amazon Monitron, ανατρέξτε στο Δημιουργήστε χρήσιμες πληροφορίες για προγνωστική διαχείριση συντήρησης με τα Amazon Monitron και Amazon Kinesis για να μεταδώσετε τα δεδομένα σας Amazon Monitron στο Amazon S3 και να χρησιμοποιήσετε τα δεδομένα σας με αυτήν την εφαρμογή.
Όταν ολοκληρωθεί η μεταφόρτωση, εισαγάγετε ένα ερώτημα για να ξεκινήσει μια συνομιλία με τα δεδομένα σας. Η αριστερή πλαϊνή γραμμή προσφέρει μια σειρά παραδειγμάτων ερωτήσεων για τη διευκόλυνσή σας. Τα ακόλουθα στιγμιότυπα οθόνης απεικονίζουν την απόκριση και τον κώδικα Python που δημιουργείται από το FM κατά την εισαγωγή μιας ερώτησης όπως "Πείτε μου τον μοναδικό αριθμό αισθητήρων για κάθε τοποθεσία που εμφανίζεται ως Προειδοποίηση ή Συναγερμός αντίστοιχα;" (μια ερώτηση σκληρού επιπέδου) ή "Για τους αισθητήρες που εμφανίζουν το σήμα θερμοκρασίας ως ΜΗ υγιές, μπορείτε να υπολογίσετε τη χρονική διάρκεια σε ημέρες για κάθε αισθητήρα που εμφανίζεται μη φυσιολογικό σήμα δόνησης;" (μια ερώτηση σε επίπεδο πρόκλησης). Η εφαρμογή θα απαντήσει στην ερώτησή σας και θα εμφανίσει επίσης το σενάριο Python ανάλυσης δεδομένων που πραγματοποίησε για τη δημιουργία τέτοιων αποτελεσμάτων.
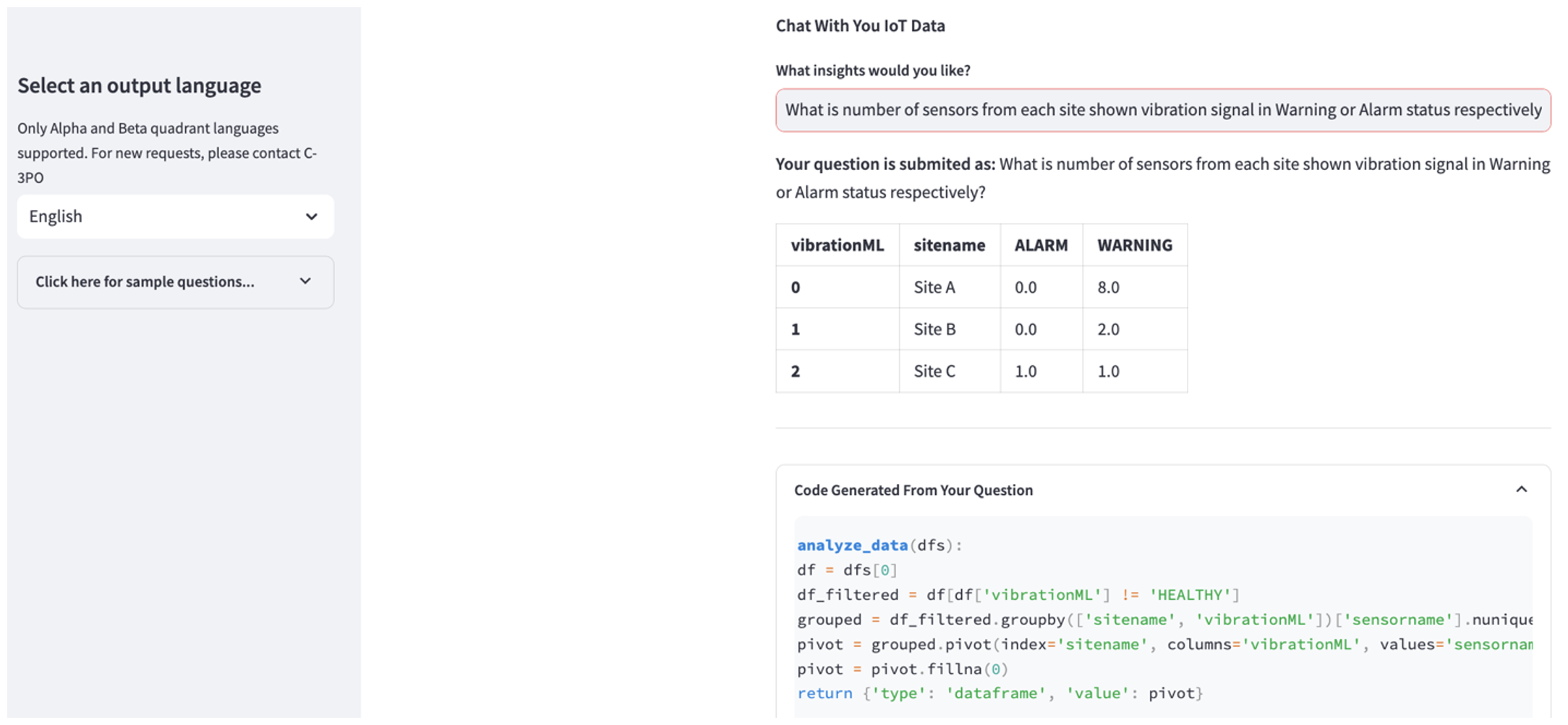

Εάν είστε ικανοποιημένοι με την απάντηση, μπορείτε να την επισημάνετε ως Βοηθητικός, αποθηκεύοντας τον NLQ και τον κώδικα Python που δημιουργήθηκε από τον Claude σε ένα ευρετήριο της υπηρεσίας OpenSearch.

Εξερευνήστε την περίπτωση χρήσης 2
Για να εξερευνήσετε τη δεύτερη περίπτωση χρήσης, επιλέξτε το Σύνοψη λήψης εικόνας καρτέλα στην εφαρμογή Streamlit. Μπορείτε να ανεβάσετε μια εικόνα του βιομηχανικού σας περιουσιακού στοιχείου και η εφαρμογή θα δημιουργήσει μια περίληψη 200 λέξεων των τεχνικών προδιαγραφών και της κατάστασης λειτουργίας του με βάση τις πληροφορίες εικόνας. Το ακόλουθο στιγμιότυπο οθόνης δείχνει τη σύνοψη που δημιουργείται από μια εικόνα μιας κίνησης κινητήρα με ιμάντα. Για να δοκιμάσετε αυτήν τη δυνατότητα, εάν δεν έχετε κατάλληλη εικόνα, μπορείτε να χρησιμοποιήσετε τα παρακάτω παράδειγμα εικόνας.

Ετικέτα κινητήρα υδραυλικού ανελκυστήρα» από τον Clarence Risher έχει άδεια σύμφωνα με CC BY-SA 2.0.

Εξερευνήστε την περίπτωση χρήσης 3
Για να εξερευνήσετε την τρίτη περίπτωση χρήσης, επιλέξτε το Διάγνωση ριζικής αιτίας αυτί. Πληκτρολογήστε ένα ερώτημα σχετικά με το κατεστραμμένο βιομηχανικό σας περιουσιακό στοιχείο, όπως "Ο ενεργοποιητής μου ταξιδεύει αργά, ποιο μπορεί να είναι το πρόβλημα;" Όπως απεικονίζεται στο ακόλουθο στιγμιότυπο οθόνης, η εφαρμογή παρέχει μια απάντηση με το απόσπασμα του εγγράφου προέλευσης που χρησιμοποιείται για τη δημιουργία της απάντησης.

Περίπτωση χρήσης 1: Λεπτομέρειες σχεδίασης
Σε αυτήν την ενότητα, συζητάμε τις λεπτομέρειες σχεδίασης της ροής εργασίας της εφαρμογής για την πρώτη περίπτωση χρήσης.
Προσαρμοσμένη άμεση κατασκευή
Το ερώτημα φυσικής γλώσσας του χρήστη συνοδεύεται από διαφορετικά δύσκολα επίπεδα: εύκολο, δύσκολο και πρόκληση.
Οι απλές ερωτήσεις μπορεί να περιλαμβάνουν τα ακόλουθα αιτήματα:
- Επιλέξτε μοναδικές τιμές
- Μετρήστε τους συνολικούς αριθμούς
- Ταξινόμηση τιμών
Για αυτές τις ερωτήσεις, το PandasAI μπορεί να αλληλεπιδράσει απευθείας με το FM για να δημιουργήσει σενάρια Python για επεξεργασία.
Οι δύσκολες ερωτήσεις απαιτούν βασική λειτουργία συνάθροισης ή ανάλυση χρονοσειρών, όπως τα ακόλουθα:
- Επιλέξτε πρώτα τιμή και ομαδοποιήστε τα αποτελέσματα ιεραρχικά
- Εκτέλεση στατιστικών μετά την αρχική επιλογή εγγραφής
- Πλήθος χρονικών σφραγίδων (για παράδειγμα, ελάχ. και μέγ.)
Για δύσκολες ερωτήσεις, ένα πρότυπο προτροπής με λεπτομερείς οδηγίες βήμα προς βήμα βοηθά τους FM να παρέχουν ακριβείς απαντήσεις.
Οι ερωτήσεις σε επίπεδο πρόκλησης απαιτούν προηγμένους μαθηματικούς υπολογισμούς και επεξεργασία χρονοσειρών, όπως τα ακόλουθα:
- Υπολογίστε τη διάρκεια ανωμαλίας για κάθε αισθητήρα
- Υπολογίστε τους αισθητήρες ανωμαλιών για την τοποθεσία σε μηνιαία βάση
- Συγκρίνετε τις ενδείξεις του αισθητήρα υπό κανονική λειτουργία και μη κανονικές συνθήκες
Για αυτές τις ερωτήσεις, μπορείτε να χρησιμοποιήσετε πολλαπλές λήψεις σε μια προσαρμοσμένη προτροπή για να βελτιώσετε την ακρίβεια απόκρισης. Τέτοιες πολλαπλές λήψεις δείχνουν παραδείγματα προηγμένης επεξεργασίας χρονοσειρών και μαθηματικών υπολογισμών και θα παρέχουν το πλαίσιο για το FM να πραγματοποιήσει σχετικό συμπέρασμα σε παρόμοια ανάλυση. Η δυναμική εισαγωγή των πιο συναφών παραδειγμάτων από μια τράπεζα ερωτήσεων NLQ στην προτροπή μπορεί να είναι μια πρόκληση. Μια λύση είναι να δημιουργήσετε ενσωματώσεις από υπάρχοντα δείγματα ερωτήσεων NLQ και να αποθηκεύσετε αυτές τις ενσωματώσεις σε ένα διανυσματικό κατάστημα όπως το OpenSearch Service. Όταν μια ερώτηση αποστέλλεται στην εφαρμογή Streamlit, η ερώτηση θα διανυσματοποιείται από Bedrock Embeddings. Οι κορυφαίες N πιο σχετικές ενσωματώσεις σε αυτήν την ερώτηση ανακτώνται χρησιμοποιώντας opensearch_vector_search.similarity_search και εισάγεται στο πρότυπο προτροπής ως προτροπή πολλαπλών λήψεων.
Το παρακάτω διάγραμμα απεικονίζει αυτήν τη ροή εργασίας.
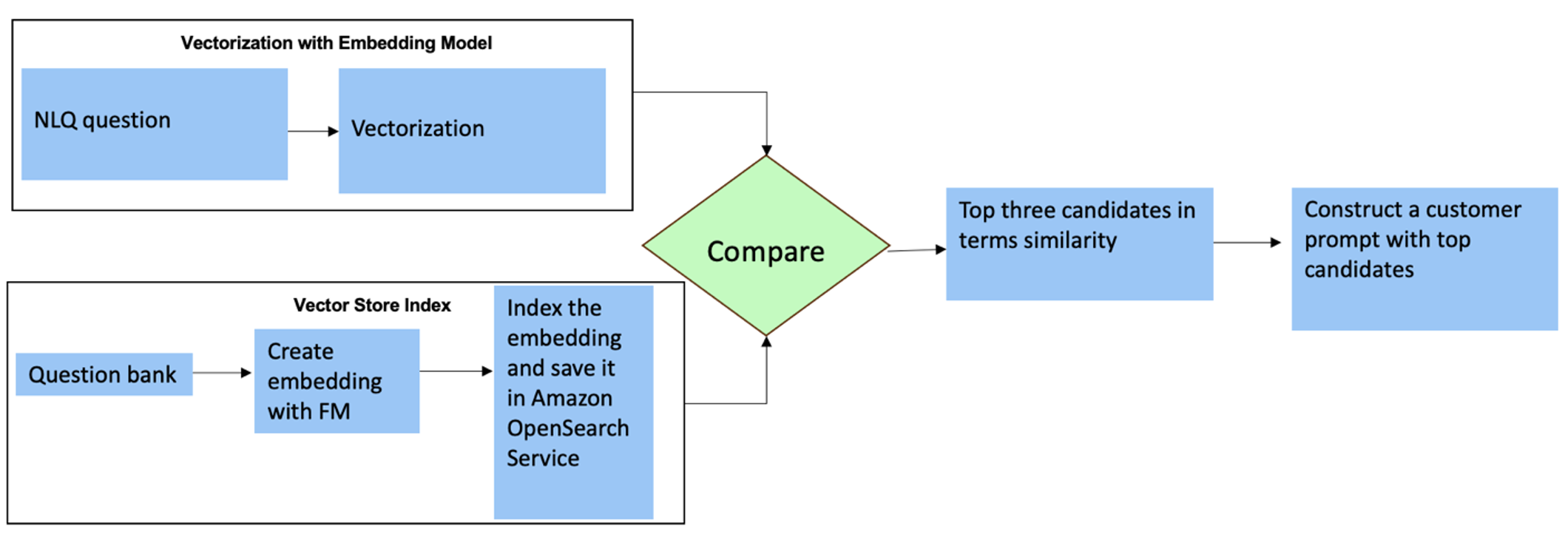
Το στρώμα ενσωμάτωσης κατασκευάζεται χρησιμοποιώντας τρία βασικά εργαλεία:
- Μοντέλο ενσωματώσεων – Χρησιμοποιούμε το Amazon Titan Embeddings που διατίθεται μέσω του Amazon Bedrock (amazon.titan-embed-text-v1) για τη δημιουργία αριθμητικών αναπαραστάσεων εγγράφων κειμένου.
- Διάνυσμα κατάστημα – Για το διανυσματικό μας κατάστημα, χρησιμοποιούμε την Υπηρεσία OpenSearch μέσω του πλαισίου LangChain, βελτιστοποιώντας την αποθήκευση των ενσωματώσεων που δημιουργούνται από παραδείγματα NLQ σε αυτό το σημειωματάριο.
- Περιεχόμενα – Το ευρετήριο της υπηρεσίας OpenSearch παίζει καθοριστικό ρόλο στη σύγκριση των ενσωματώσεων εισόδου με τις ενσωματώσεις εγγράφων και στη διευκόλυνση της ανάκτησης σχετικών εγγράφων. Επειδή οι κώδικες παραδειγμάτων Python αποθηκεύτηκαν ως αρχείο JSON, καταχωρήθηκαν στην υπηρεσία OpenSearch ως διανύσματα μέσω ενός OpenSearchVevtorSearch.fromtexts Κλήση API.
Συνεχής συλλογή παραδειγμάτων που έχουν ελεγχθεί από ανθρώπους μέσω του Streamlit
Στην αρχή της ανάπτυξης εφαρμογών, ξεκινήσαμε με μόνο 23 αποθηκευμένα παραδείγματα στο ευρετήριο της υπηρεσίας OpenSearch ως ενσωματώσεις. Καθώς η εφαρμογή γίνεται ζωντανή στο πεδίο, οι χρήστες αρχίζουν να εισάγουν τα NLQ τους μέσω της εφαρμογής. Ωστόσο, λόγω των περιορισμένων παραδειγμάτων που είναι διαθέσιμα στο πρότυπο, ορισμένα NLQ ενδέχεται να μην βρουν παρόμοια μηνύματα. Για να εμπλουτίζετε συνεχώς αυτές τις ενσωματώσεις και να προσφέρετε πιο σχετικές προτροπές χρήστη, μπορείτε να χρησιμοποιήσετε την εφαρμογή Streamlit για τη συλλογή παραδειγμάτων που έχουν ελεγχθεί από ανθρώπους.
Μέσα στην εφαρμογή, η ακόλουθη λειτουργία εξυπηρετεί αυτόν τον σκοπό. Όταν οι τελικοί χρήστες βρίσκουν χρήσιμο το αποτέλεσμα και επιλέγουν Βοηθητικός, η εφαρμογή ακολουθεί τα εξής βήματα:
- Χρησιμοποιήστε τη μέθοδο επανάκλησης από το PandasAI για να συλλέξετε το σενάριο Python.
- Διαμορφώστε ξανά το σενάριο Python, την ερώτηση εισόδου και τα μεταδεδομένα CSV σε μια συμβολοσειρά.
- Ελέγξτε εάν αυτό το παράδειγμα NLQ υπάρχει ήδη στο τρέχον ευρετήριο της Υπηρεσίας OpenSearch χρησιμοποιώντας opensearch_vector_search.similarity_search_with_score.
- Εάν δεν υπάρχει παρόμοιο παράδειγμα, αυτό το NLQ προστίθεται στο ευρετήριο της υπηρεσίας OpenSearch χρησιμοποιώντας opensearch_vector_search.add_texts.
Σε περίπτωση που κάποιος χρήστης επιλέξει Δεν είναι χρήσιμο, δεν γίνεται καμία ενέργεια. Αυτή η επαναληπτική διαδικασία διασφαλίζει ότι το σύστημα βελτιώνεται συνεχώς ενσωματώνοντας παραδείγματα που συνεισφέρουν οι χρήστες.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Με την ενσωμάτωση του ανθρώπινου ελέγχου, ο αριθμός των παραδειγμάτων στην Υπηρεσία OpenSearch που είναι διαθέσιμα για άμεση ενσωμάτωση αυξάνεται καθώς η εφαρμογή κερδίζει τη χρήση. Αυτό το διευρυμένο σύνολο δεδομένων ενσωμάτωσης έχει ως αποτέλεσμα βελτιωμένη ακρίβεια αναζήτησης με την πάροδο του χρόνου. Συγκεκριμένα, για προκλήσεις NLQ, η ακρίβεια απόκρισης του FM φτάνει περίπου το 90% όταν εισάγονται δυναμικά παρόμοια παραδείγματα για τη δημιουργία προσαρμοσμένων προτροπών για κάθε ερώτηση NLQ. Αυτό αντιπροσωπεύει μια αξιοσημείωτη αύξηση 28% σε σύγκριση με σενάρια χωρίς προτροπές πολλαπλών λήψεων.
Περίπτωση χρήσης 2: Λεπτομέρειες σχεδίασης
Στις εφαρμογές Streamlit Σύνοψη λήψης εικόνας καρτέλα, μπορείτε να ανεβάσετε απευθείας ένα αρχείο εικόνας. Αυτό εκκινεί το Amazon Rekognition API (detect_text API), εξάγοντας κείμενο από την ετικέτα εικόνας που περιγράφει τις προδιαγραφές του μηχανήματος. Στη συνέχεια, τα εξαγόμενα δεδομένα κειμένου αποστέλλονται στο μοντέλο Amazon Bedrock Claude ως πλαίσιο μιας προτροπής, με αποτέλεσμα μια περίληψη 200 λέξεων.
Από την άποψη της εμπειρίας χρήστη, η ενεργοποίηση της λειτουργικότητας ροής για μια εργασία σύνοψης κειμένου είναι πρωταρχικής σημασίας, επιτρέποντας στους χρήστες να διαβάζουν τη σύνοψη που δημιουργείται από FM σε μικρότερα κομμάτια αντί να περιμένουν ολόκληρη την έξοδο. Το Amazon Bedrock διευκολύνει τη ροή μέσω του API του (bedrock_runtime.invoke_model_with_response_stream).
Περίπτωση χρήσης 3: Λεπτομέρειες σχεδίασης
Σε αυτό το σενάριο, έχουμε αναπτύξει μια εφαρμογή chatbot που επικεντρώνεται στην ανάλυση της βασικής αιτίας, χρησιμοποιώντας την προσέγγιση RAG. Αυτό το chatbot αντλεί από πολλά έγγραφα που σχετίζονται με εξοπλισμό ρουλεμάν για να διευκολύνει την ανάλυση της βασικής αιτίας. Αυτό το chatbot ανάλυσης βασικής αιτίας που βασίζεται σε RAG χρησιμοποιεί βάσεις γνώσεων για τη δημιουργία διανυσματικών αναπαραστάσεων κειμένου ή ενσωματώσεων. Το Knowledge Bases for Amazon Bedrock είναι μια πλήρως διαχειριζόμενη δυνατότητα που σας βοηθά να εφαρμόσετε ολόκληρη τη ροή εργασιών RAG, από την απορρόφηση έως την ανάκτηση και την άμεση αύξηση, χωρίς να χρειάζεται να δημιουργήσετε προσαρμοσμένες ενσωματώσεις σε πηγές δεδομένων ή να διαχειριστείτε ροές δεδομένων και λεπτομέρειες εφαρμογής RAG.
Όταν είστε ικανοποιημένοι με την απόκριση της βάσης γνώσεων από το Amazon Bedrock, μπορείτε να ενσωματώσετε την απόκριση της βασικής αιτίας από τη βάση γνώσεων στην εφαρμογή Streamlit.
εκκαθάριση
Για να εξοικονομήσετε κόστος, διαγράψτε τους πόρους που δημιουργήσατε σε αυτήν την ανάρτηση:
- Διαγράψτε τη βάση γνώσεων από το Amazon Bedrock.
- Διαγράψτε το ευρετήριο της υπηρεσίας OpenSearch.
- Διαγράψτε τη στοίβα του genai-sagemaker CloudFormation.
- Διακόψτε την παρουσία EC2 εάν χρησιμοποιήσατε μια παρουσία EC2 για να εκτελέσετε την εφαρμογή Streamlit.
Συμπέρασμα
Οι γενετικές εφαρμογές τεχνητής νοημοσύνης έχουν ήδη μεταμορφώσει διάφορες επιχειρηματικές διαδικασίες, ενισχύοντας την παραγωγικότητα και τα σύνολα δεξιοτήτων των εργαζομένων. Ωστόσο, οι περιορισμοί των FM στον χειρισμό της ανάλυσης δεδομένων χρονοσειρών έχουν εμποδίσει την πλήρη χρήση τους από βιομηχανικούς πελάτες. Αυτός ο περιορισμός έχει εμποδίσει την εφαρμογή της γενετικής τεχνητής νοημοσύνης στον κυρίαρχο τύπο δεδομένων που επεξεργάζεται καθημερινά.
Σε αυτήν την ανάρτηση, παρουσιάσαμε μια γενετική λύση Εφαρμογής AI που έχει σχεδιαστεί για να μετριάσει αυτήν την πρόκληση για τους βιομηχανικούς χρήστες. Αυτή η εφαρμογή χρησιμοποιεί έναν πράκτορα ανοιχτού κώδικα, το PandasAI, για να ενισχύσει την ικανότητα ανάλυσης χρονοσειρών ενός FM. Αντί να στέλνει δεδομένα χρονοσειρών απευθείας σε FM, η εφαρμογή χρησιμοποιεί το PandasAI για τη δημιουργία κώδικα Python για την ανάλυση δεδομένων αδόμητων χρονοσειρών. Για να βελτιωθεί η ακρίβεια της δημιουργίας κώδικα Python, έχει εφαρμοστεί μια προσαρμοσμένη ροή εργασίας δημιουργίας εντολών με ανθρώπινο έλεγχο.
Εξουσιοδοτημένοι με γνώσεις σχετικά με την υγεία των περιουσιακών τους στοιχείων, οι βιομηχανικοί εργαζόμενοι μπορούν να εκμεταλλευτούν πλήρως τις δυνατότητες της γενετικής τεχνητής νοημοσύνης σε διάφορες περιπτώσεις χρήσης, συμπεριλαμβανομένης της διάγνωσης της βασικής αιτίας και του σχεδιασμού αντικατάστασης ανταλλακτικών. Με τις Γνωσιακές Βάσεις για το Amazon Bedrock, η λύση RAG είναι απλή για τους προγραμματιστές να δημιουργήσουν και να διαχειριστούν.
Η τροχιά της διαχείρισης και των λειτουργιών εταιρικών δεδομένων κινείται αναμφισβήτητα προς τη βαθύτερη ενοποίηση με τη γενετική τεχνητή νοημοσύνη για ολοκληρωμένες γνώσεις σχετικά με την επιχειρησιακή υγεία. Αυτή η αλλαγή, με αιχμή του δόρατος από την Amazon Bedrock, ενισχύεται σημαντικά από την αυξανόμενη ευρωστία και τις δυνατότητες των LLM όπως Amazon Bedrock Claude 3 για την περαιτέρω εξύψωση των λύσεων. Για να μάθετε περισσότερα, επισκεφθείτε τη συμβουλευτική Τεκμηρίωση του Amazon Bedrock, και ξεκινήστε με το Εργαστήριο Amazon Bedrock.
Σχετικά με τους συγγραφείς
 Τζούλια Χου είναι Sr. AI/ML Solutions Architect στο Amazon Web Services. Είναι ειδικευμένη στην Generative AI, στην Applied Data Science και στην αρχιτεκτονική IoT. Αυτήν τη στιγμή είναι μέλος της ομάδας Amazon Q και ενεργό μέλος/μέντορας στην Κοινότητα Τεχνικού Πεδίου Μηχανικής Μάθησης. Συνεργάζεται με πελάτες, από νεοσύστατες επιχειρήσεις έως επιχειρήσεις, για την ανάπτυξη AWSome παραγωγικών λύσεων τεχνητής νοημοσύνης. Είναι ιδιαίτερα παθιασμένη με την αξιοποίηση μοντέλων μεγάλων γλωσσών για προηγμένες αναλύσεις δεδομένων και την εξερεύνηση πρακτικών εφαρμογών που αντιμετωπίζουν τις προκλήσεις του πραγματικού κόσμου.
Τζούλια Χου είναι Sr. AI/ML Solutions Architect στο Amazon Web Services. Είναι ειδικευμένη στην Generative AI, στην Applied Data Science και στην αρχιτεκτονική IoT. Αυτήν τη στιγμή είναι μέλος της ομάδας Amazon Q και ενεργό μέλος/μέντορας στην Κοινότητα Τεχνικού Πεδίου Μηχανικής Μάθησης. Συνεργάζεται με πελάτες, από νεοσύστατες επιχειρήσεις έως επιχειρήσεις, για την ανάπτυξη AWSome παραγωγικών λύσεων τεχνητής νοημοσύνης. Είναι ιδιαίτερα παθιασμένη με την αξιοποίηση μοντέλων μεγάλων γλωσσών για προηγμένες αναλύσεις δεδομένων και την εξερεύνηση πρακτικών εφαρμογών που αντιμετωπίζουν τις προκλήσεις του πραγματικού κόσμου.
 Sudeesh Sasidharan είναι Senior Solutions Architect στην AWS, στην ομάδα Energy. Η Sudeesh λατρεύει να πειραματίζεται με νέες τεχνολογίες και να δημιουργεί καινοτόμες λύσεις που επιλύουν πολύπλοκες επιχειρηματικές προκλήσεις. Όταν δεν σχεδιάζει λύσεις ή δεν ασχολείται με τις πιο πρόσφατες τεχνολογίες, μπορείτε να τον βρείτε στο γήπεδο του τένις να δουλεύει στο backhand του.
Sudeesh Sasidharan είναι Senior Solutions Architect στην AWS, στην ομάδα Energy. Η Sudeesh λατρεύει να πειραματίζεται με νέες τεχνολογίες και να δημιουργεί καινοτόμες λύσεις που επιλύουν πολύπλοκες επιχειρηματικές προκλήσεις. Όταν δεν σχεδιάζει λύσεις ή δεν ασχολείται με τις πιο πρόσφατες τεχνολογίες, μπορείτε να τον βρείτε στο γήπεδο του τένις να δουλεύει στο backhand του.
 Νιλ Ντεσάι είναι στέλεχος τεχνολογίας με πάνω από 20 χρόνια εμπειρίας στην τεχνητή νοημοσύνη (AI), την επιστήμη δεδομένων, τη μηχανική λογισμικού και την αρχιτεκτονική επιχειρήσεων. Στην AWS, ηγείται μιας ομάδας αρχιτεκτόνων εξειδικευμένων λύσεων σε υπηρεσίες τεχνητής νοημοσύνης σε όλο τον κόσμο που βοηθούν τους πελάτες να δημιουργήσουν καινοτόμες λύσεις που βασίζονται σε Generative AI, να μοιράζονται βέλτιστες πρακτικές με τους πελάτες και να κατευθύνουν τον οδικό χάρτη προϊόντων. Στους προηγούμενους ρόλους του στις Vestas, Honeywell και Quest Diagnostics, ο Neil είχε ηγετικούς ρόλους στην ανάπτυξη και την κυκλοφορία καινοτόμων προϊόντων και υπηρεσιών που βοήθησαν τις εταιρείες να βελτιώσουν τις δραστηριότητές τους, να μειώσουν το κόστος και να αυξήσουν τα έσοδα. Είναι παθιασμένος με τη χρήση της τεχνολογίας για την επίλυση προβλημάτων του πραγματικού κόσμου και είναι στρατηγικός στοχαστής με αποδεδειγμένο ιστορικό επιτυχίας.
Νιλ Ντεσάι είναι στέλεχος τεχνολογίας με πάνω από 20 χρόνια εμπειρίας στην τεχνητή νοημοσύνη (AI), την επιστήμη δεδομένων, τη μηχανική λογισμικού και την αρχιτεκτονική επιχειρήσεων. Στην AWS, ηγείται μιας ομάδας αρχιτεκτόνων εξειδικευμένων λύσεων σε υπηρεσίες τεχνητής νοημοσύνης σε όλο τον κόσμο που βοηθούν τους πελάτες να δημιουργήσουν καινοτόμες λύσεις που βασίζονται σε Generative AI, να μοιράζονται βέλτιστες πρακτικές με τους πελάτες και να κατευθύνουν τον οδικό χάρτη προϊόντων. Στους προηγούμενους ρόλους του στις Vestas, Honeywell και Quest Diagnostics, ο Neil είχε ηγετικούς ρόλους στην ανάπτυξη και την κυκλοφορία καινοτόμων προϊόντων και υπηρεσιών που βοήθησαν τις εταιρείες να βελτιώσουν τις δραστηριότητές τους, να μειώσουν το κόστος και να αυξήσουν τα έσοδα. Είναι παθιασμένος με τη χρήση της τεχνολογίας για την επίλυση προβλημάτων του πραγματικού κόσμου και είναι στρατηγικός στοχαστής με αποδεδειγμένο ιστορικό επιτυχίας.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

