Με την έλευση της γενετικής τεχνητής νοημοσύνης, τα σημερινά βασικά μοντέλα (FM), όπως τα μεγάλα γλωσσικά μοντέλα (LLM) Claude 2 και Llama 2, μπορούν να εκτελέσουν μια σειρά παραγωγικών εργασιών, όπως απάντηση σε ερωτήσεις, σύνοψη και δημιουργία περιεχομένου σε δεδομένα κειμένου. Ωστόσο, τα δεδομένα του πραγματικού κόσμου υπάρχουν σε πολλαπλούς τρόπους, όπως κείμενο, εικόνες, βίντεο και ήχος. Πάρτε για παράδειγμα ένα πάτωμα διαφανειών του PowerPoint. Θα μπορούσε να περιέχει πληροφορίες με τη μορφή κειμένου ή ενσωματωμένες σε γραφήματα, πίνακες και εικόνες.
Σε αυτήν την ανάρτηση, παρουσιάζουμε μια λύση που χρησιμοποιεί πολυτροπικά FM όπως το Amazon Titan Multimodal Embeddings μοντέλο και LLaVA 1.5 και υπηρεσίες AWS συμπεριλαμβανομένων Θεμέλιο του Αμαζονίου και Amazon Sage Maker για την εκτέλεση παρόμοιων εργασιών παραγωγής σε πολυτροπικά δεδομένα.
Επισκόπηση λύσεων
Η λύση παρέχει μια υλοποίηση για την απάντηση σε ερωτήσεις χρησιμοποιώντας πληροφορίες που περιέχονται στο κείμενο και οπτικά στοιχεία ενός καταστρώματος διαφανειών. Ο σχεδιασμός βασίζεται στην ιδέα της Augmented Generation (RAG). Παραδοσιακά, το RAG έχει συσχετιστεί με δεδομένα κειμένου που μπορούν να υποβληθούν σε επεξεργασία από LLM. Σε αυτήν την ανάρτηση, επεκτείνουμε το RAG για να συμπεριλάβει και εικόνες. Αυτό παρέχει μια ισχυρή δυνατότητα αναζήτησης για εξαγωγή σχετικού περιεχομένου από οπτικά στοιχεία όπως πίνακες και γραφήματα μαζί με κείμενο.
Υπάρχουν διάφοροι τρόποι για να σχεδιάσετε μια λύση RAG που περιλαμβάνει εικόνες. Έχουμε παρουσιάσει μια προσέγγιση εδώ και θα ακολουθήσουμε μια εναλλακτική προσέγγιση στη δεύτερη ανάρτηση αυτής της σειράς τριών μερών.
Αυτή η λύση περιλαμβάνει τα ακόλουθα συστατικά:
- Μοντέλο Amazon Titan Multimodal Embeddings – Αυτό το FM χρησιμοποιείται για τη δημιουργία ενσωματώσεων για το περιεχόμενο στο slide deck που χρησιμοποιείται σε αυτήν την ανάρτηση. Ως πολυτροπικό μοντέλο, αυτό το μοντέλο Titan μπορεί να επεξεργαστεί κείμενο, εικόνες ή έναν συνδυασμό ως είσοδο και να δημιουργήσει ενσωματώσεις. Το μοντέλο Titan Multimodal Embeddings δημιουργεί διανύσματα (ενσωματώσεις) 1,024 διαστάσεων και είναι προσβάσιμο μέσω του Amazon Bedrock.
- Large Language and Vision Assistant (LLaVA) – Το LLaVA είναι ένα πολυτροπικό μοντέλο ανοιχτού κώδικα για οπτική και γλωσσική κατανόηση και χρησιμοποιείται για την ερμηνεία των δεδομένων στις διαφάνειες, συμπεριλαμβανομένων οπτικών στοιχείων όπως γραφήματα και πίνακες. Χρησιμοποιούμε την έκδοση παραμέτρων 7 δισεκατομμυρίων LLaVA 1.5-7b σε αυτή τη λύση.
- Amazon Sage Maker – Το μοντέλο LLaVA αναπτύσσεται σε ένα τελικό σημείο SageMaker χρησιμοποιώντας υπηρεσίες φιλοξενίας SageMaker και χρησιμοποιούμε το τελικό σημείο που προκύπτει για να εκτελέσουμε συμπεράσματα σε σχέση με το μοντέλο LLaVA. Χρησιμοποιούμε επίσης σημειωματάρια SageMaker για την ενορχήστρωση και την επίδειξη αυτής της λύσης από άκρη σε άκρη.
- Amazon OpenSearch χωρίς διακομιστή – Το OpenSearch Serverless είναι μια κατ' απαίτηση διαμόρφωση χωρίς διακομιστή Amazon OpenSearch Service. Χρησιμοποιούμε το OpenSearch Serverless ως διανυσματική βάση δεδομένων για την αποθήκευση ενσωματώσεων που δημιουργούνται από το μοντέλο Titan Multimodal Embeddings. Ένα ευρετήριο που δημιουργήθηκε στη συλλογή OpenSearch Serverless χρησιμεύει ως αποθήκευση διανυσμάτων για τη λύση RAG.
- Απορρόφηση OpenSearch Amazon (OSI) – Το OSI είναι ένας πλήρως διαχειριζόμενος συλλέκτης δεδομένων χωρίς διακομιστή που παραδίδει δεδομένα σε τομείς της Υπηρεσίας OpenSearch και συλλογές OpenSearch Serverless. Σε αυτήν την ανάρτηση, χρησιμοποιούμε μια διοχέτευση OSI για την παράδοση δεδομένων στο χώρο αποθήκευσης διανυσμάτων OpenSearch Serverless.
Αρχιτεκτονική λύσεων
Ο σχεδιασμός της λύσης αποτελείται από δύο μέρη: την κατάποση και την αλληλεπίδραση με τον χρήστη. Κατά τη διάρκεια της απορρόφησης, επεξεργαζόμαστε το κατάστρωμα διαφανειών εισόδου μετατρέποντας κάθε διαφάνεια σε εικόνα, δημιουργούμε ενσωματώσεις για αυτές τις εικόνες και, στη συνέχεια, συμπληρώνουμε το χώρο αποθήκευσης διανυσματικών δεδομένων. Αυτά τα βήματα ολοκληρώνονται πριν από τα βήματα αλληλεπίδρασης με τον χρήστη.
Στη φάση αλληλεπίδρασης με τον χρήστη, μια ερώτηση από τον χρήστη μετατρέπεται σε ενσωματώσεις και εκτελείται μια αναζήτηση ομοιότητας στη διανυσματική βάση δεδομένων για να βρεθεί μια διαφάνεια που θα μπορούσε ενδεχομένως να περιέχει απαντήσεις σε ερωτήσεις χρήστη. Στη συνέχεια παρέχουμε αυτήν τη διαφάνεια (με τη μορφή αρχείου εικόνας) στο μοντέλο LLaVA και στην ερώτηση του χρήστη ως προτροπή για να δημιουργήσουμε μια απάντηση στο ερώτημα. Όλος ο κώδικας για αυτήν την ανάρτηση είναι διαθέσιμος στο GitHub ρεπό.
Το παρακάτω διάγραμμα απεικονίζει την αρχιτεκτονική απορρόφησης.
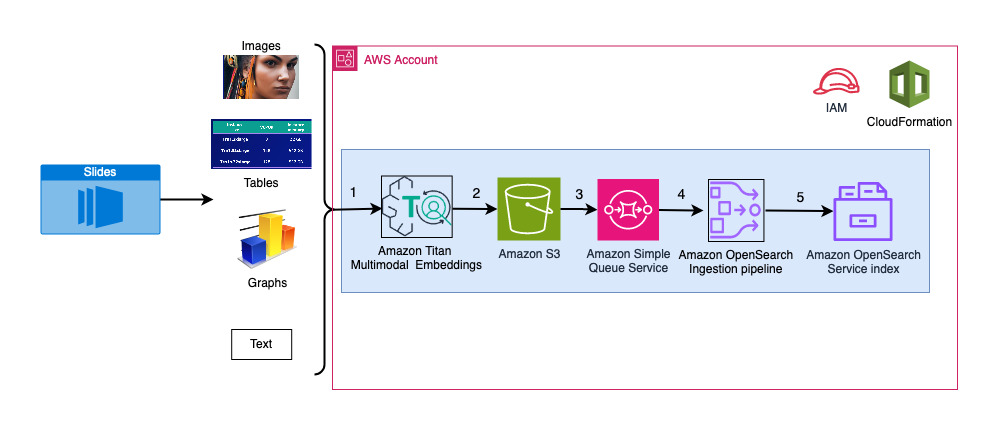
Τα βήματα της ροής εργασιών είναι τα εξής:
- Οι διαφάνειες μετατρέπονται σε αρχεία εικόνας (μία ανά διαφάνεια) σε μορφή JPG και μεταβιβάζονται στο μοντέλο Titan Multimodal Embeddings για τη δημιουργία ενσωματώσεων. Σε αυτήν την ανάρτηση, χρησιμοποιούμε το slide deck με τίτλο Εκπαιδεύστε και αναπτύξτε το Stable Diffusion χρησιμοποιώντας AWS Trainium & AWS Inferentia από τη Σύνοδο Κορυφής AWS στο Τορόντο, Ιούνιος 2023, για να δείξουμε τη λύση. Το δείγμα γέφυρας έχει 31 διαφάνειες, επομένως δημιουργούμε 31 σετ διανυσματικών ενσωματώσεων, το καθένα με 1,024 διαστάσεις. Προσθέτουμε επιπλέον πεδία μεταδεδομένων σε αυτές τις διανυσματικές ενσωματώσεις που δημιουργούνται και δημιουργούμε ένα αρχείο JSON. Αυτά τα πρόσθετα πεδία μεταδεδομένων μπορούν να χρησιμοποιηθούν για την εκτέλεση ερωτημάτων πλούσιας αναζήτησης χρησιμοποιώντας τις ισχυρές δυνατότητες αναζήτησης του OpenSearch.
- Οι δημιουργούμενες ενσωματώσεις συγκεντρώνονται σε ένα μόνο αρχείο JSON που μεταφορτώνεται Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3).
- Μέσω Ειδοποιήσεις συμβάντων Amazon S3, ένα συμβάν τοποθετείται σε ένα Υπηρεσία απλής ουράς Amazon (Amazon SQS) ουρά.
- Αυτό το συμβάν στην ουρά SQS λειτουργεί ως έναυσμα για την εκτέλεση του αγωγού OSI, το οποίο με τη σειρά του απορροφά τα δεδομένα (αρχείο JSON) ως έγγραφα στο ευρετήριο OpenSearch Serverless. Λάβετε υπόψη ότι το ευρετήριο OpenSearch Serverless έχει ρυθμιστεί ως το νεροχύτη για αυτόν τον αγωγό και δημιουργείται ως μέρος της συλλογής OpenSearch Serverless.
Το παρακάτω διάγραμμα απεικονίζει την αρχιτεκτονική αλληλεπίδρασης χρήστη.
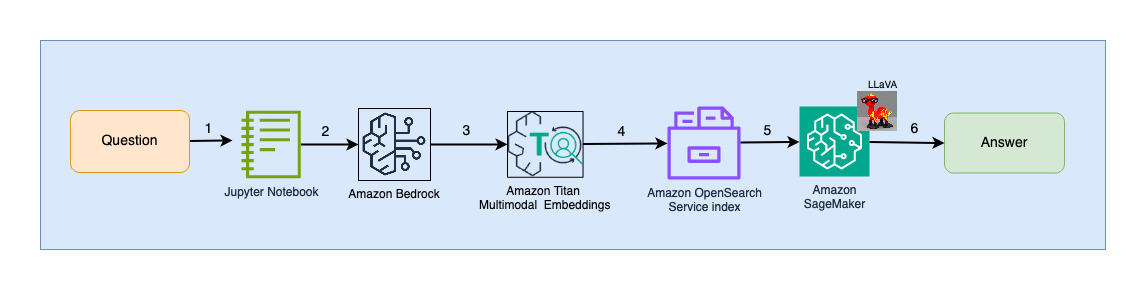
Τα βήματα της ροής εργασιών είναι τα εξής:
- Ένας χρήστης υποβάλλει μια ερώτηση σχετικά με το slide deck που έχει απορροφηθεί.
- Η είσοδος του χρήστη μετατρέπεται σε ενσωματώσεις χρησιμοποιώντας το μοντέλο Titan Multimodal Embeddings στο οποίο έχει πρόσβαση μέσω του Amazon Bedrock. Μια διανυσματική αναζήτηση OpenSearch εκτελείται χρησιμοποιώντας αυτές τις ενσωματώσεις. Εκτελούμε μια αναζήτηση k-πλησιέστερου γείτονα (k=1) για να ανακτήσουμε την πιο σχετική ενσωμάτωση που ταιριάζει με το ερώτημα χρήστη. Η ρύθμιση k=1 ανακτά την πιο σχετική διαφάνεια στην ερώτηση χρήστη.
- Τα μεταδεδομένα της απάντησης από το OpenSearch Serverless περιέχουν μια διαδρομή προς την εικόνα που αντιστοιχεί στην πιο σχετική διαφάνεια.
- Δημιουργείται ένα μήνυμα προτροπής συνδυάζοντας την ερώτηση χρήστη και τη διαδρομή εικόνας και παρέχεται στο LLaVA που φιλοξενείται στο SageMaker. Το μοντέλο LLaVA είναι σε θέση να κατανοήσει την ερώτηση του χρήστη και να απαντήσει σε αυτήν εξετάζοντας τα δεδομένα στην εικόνα.
- Το αποτέλεσμα αυτού του συμπεράσματος επιστρέφεται στον χρήστη.
Αυτά τα βήματα αναλύονται λεπτομερώς στις επόμενες ενότητες. Δείτε το Αποτελέσματα ενότητα για στιγμιότυπα οθόνης και λεπτομέρειες σχετικά με την έξοδο.
Προϋποθέσεις
Για να εφαρμόσετε τη λύση που παρέχεται σε αυτήν την ανάρτηση, θα πρέπει να έχετε ένα Λογαριασμός AWS και εξοικείωση με τα FM, το Amazon Bedrock, το SageMaker και την Υπηρεσία OpenSearch.
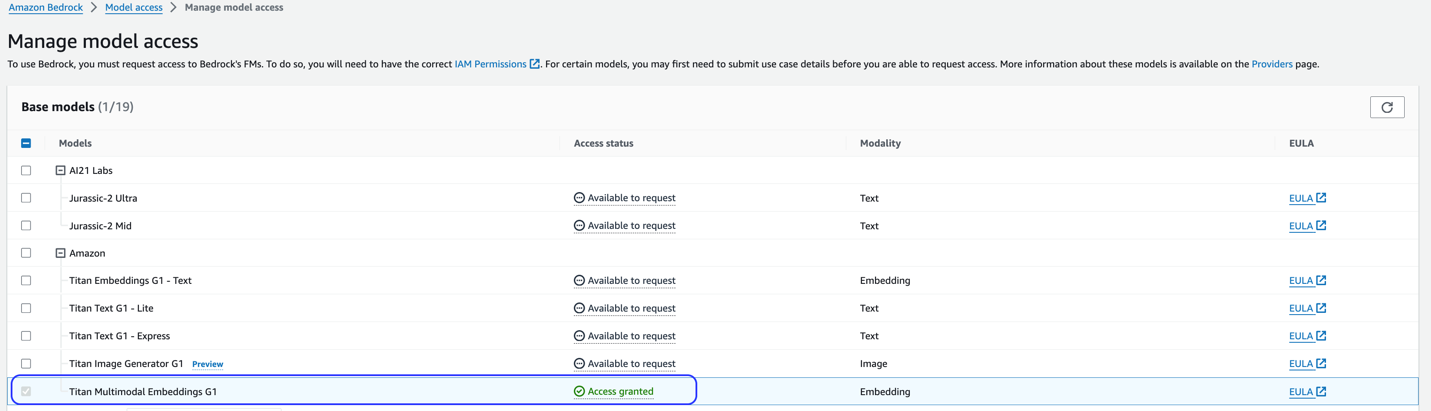
Αυτή η λύση χρησιμοποιεί το μοντέλο Titan Multimodal Embeddings. Βεβαιωθείτε ότι αυτό το μοντέλο είναι ενεργοποιημένο για χρήση στο Amazon Bedrock. Στην κονσόλα Amazon Bedrock, επιλέξτε Πρόσβαση μοντέλου στο παράθυρο πλοήγησης. Εάν το Titan Multimodal Embeddings είναι ενεργοποιημένο, θα δηλωθεί η κατάσταση πρόσβασης Πρόσβαση επετράπη.
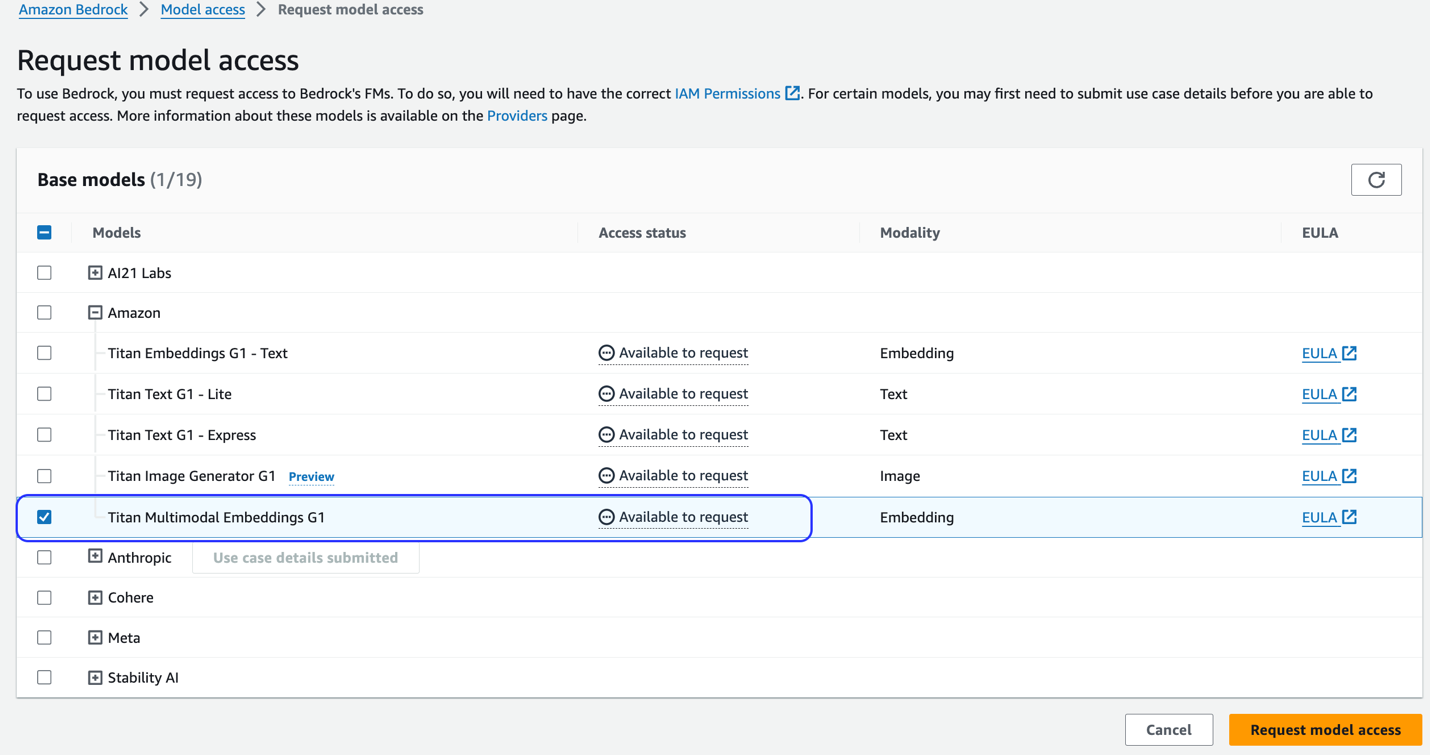
Εάν το μοντέλο δεν είναι διαθέσιμο, ενεργοποιήστε την πρόσβαση στο μοντέλο επιλέγοντας Διαχείριση πρόσβασης μοντέλου, επιλέγοντας Titan Multimodal Embeddings G1, και την επιλογή Ζητήστε πρόσβαση μοντέλου. Το μοντέλο ενεργοποιείται για χρήση αμέσως.
Χρησιμοποιήστε ένα πρότυπο AWS CloudFormation για να δημιουργήσετε τη στοίβα λύσεων
Χρησιμοποιήστε ένα από τα παρακάτω AWS CloudFormation πρότυπα (ανάλογα με την περιοχή σας) για την εκκίνηση των πόρων λύσης.
| Περιοχή AWS | Σύνδεσμος |
|---|---|
us-east-1 |
|
us-west-2 |
Αφού δημιουργηθεί η στοίβα με επιτυχία, μεταβείτε στη στοίβα Έξοδοι καρτέλα στην κονσόλα AWS CloudFormation και σημειώστε την τιμή για MultimodalCollectionEndpoint, το οποίο χρησιμοποιούμε στα επόμενα βήματα.
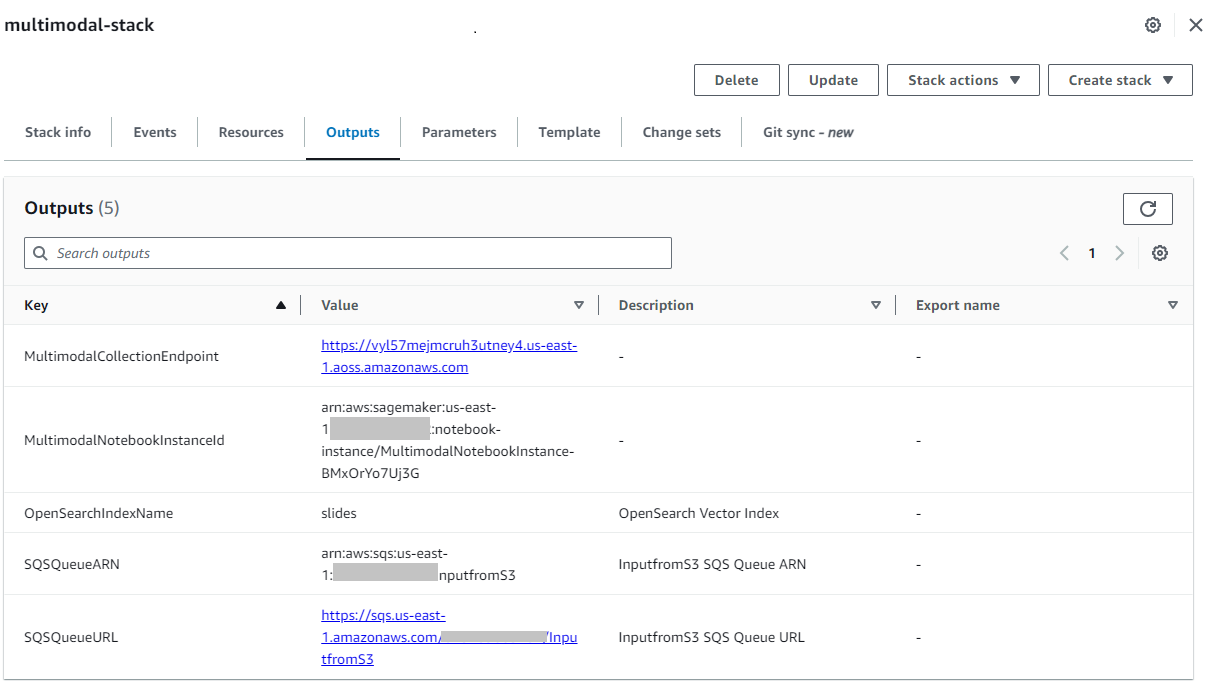
Το πρότυπο CloudFormation δημιουργεί τους ακόλουθους πόρους:
- Ρόλοι IAM - Το ακόλουθο Διαχείριση ταυτότητας και πρόσβασης AWS (IAM) δημιουργούνται ρόλοι. Ενημερώστε αυτούς τους ρόλους για εφαρμογή άδειες ελάχιστων προνομίων.
SMExecutionRoleμε πλήρη πρόσβαση Amazon S3, SageMaker, OpenSearch Service και Bedrock.OSPipelineExecutionRoleμε πρόσβαση σε συγκεκριμένες ενέργειες Amazon SQS και OSI.
- Σημειωματάριο SageMaker – Όλος ο κώδικας για αυτήν την ανάρτηση εκτελείται μέσω αυτού του σημειωματάριου.
- Συλλογή OpenSearch χωρίς διακομιστή – Αυτή είναι η διανυσματική βάση δεδομένων για την αποθήκευση και την ανάκτηση ενσωματώσεων.
- Ο αγωγός OSI – Αυτή είναι η διοχέτευση για την απορρόφηση δεδομένων στο OpenSearch Serverless.
- Κάδος S3 – Όλα τα δεδομένα για αυτήν την ανάρτηση αποθηκεύονται σε αυτόν τον κάδο.
- SQS ουρά – Τα συμβάντα για την ενεργοποίηση της εκτέλεσης του αγωγού OSI τοποθετούνται σε αυτήν την ουρά.
Το πρότυπο CloudFormation διαμορφώνει τη διοχέτευση OSI με επεξεργασία Amazon S3 και Amazon SQS ως πηγή και ευρετήριο OpenSearch Serverless ως καταβόθρα. Οποιαδήποτε αντικείμενα δημιουργήθηκαν στον καθορισμένο κάδο S3 και το πρόθεμα (multimodal/osi-embeddings-json) θα ενεργοποιήσει ειδοποιήσεις SQS, οι οποίες χρησιμοποιούνται από τον αγωγό OSI για την απορρόφηση δεδομένων στο OpenSearch Serverless.
Το πρότυπο CloudFormation δημιουργεί επίσης δίκτυο, κρυπτογράφηση, να πρόσβαση δεδομένων πολιτικές που απαιτούνται για τη συλλογή OpenSearch Serverless. Ενημερώστε αυτές τις πολιτικές για να εφαρμόσετε δικαιώματα ελάχιστων προνομίων.
Σημειώστε ότι το όνομα του προτύπου CloudFormation αναφέρεται στα σημειωματάρια του SageMaker. Εάν αλλάξει το προεπιλεγμένο όνομα προτύπου, βεβαιωθείτε ότι έχετε ενημερώσει το ίδιο globals.py
Δοκιμάστε τη λύση
Αφού ολοκληρωθούν τα προαπαιτούμενα βήματα και η στοίβα CloudFormation έχει δημιουργηθεί με επιτυχία, είστε πλέον έτοιμοι να δοκιμάσετε τη λύση:
- Στην κονσόλα SageMaker, επιλέξτε Φορητοί υπολογιστές στο παράθυρο πλοήγησης.
- Επιλέξτε το
MultimodalNotebookInstanceπαράδειγμα σημειωματάριου και επιλέξτε Ανοίξτε το JupyterLab.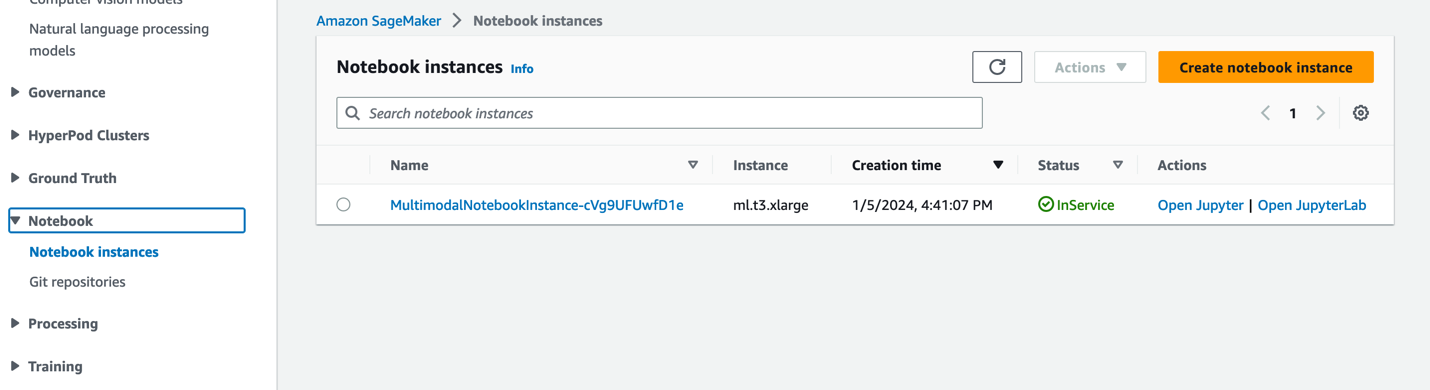
- In Αρχείο περιήγησης αρχείων, περάστε στο φάκελο σημειωματάρια για να δείτε τα σημειωματάρια και τα υποστηρικτικά αρχεία.
Τα σημειωματάρια αριθμούνται με τη σειρά με την οποία εκτελούνται. Οι οδηγίες και τα σχόλια σε κάθε σημειωματάριο περιγράφουν τις ενέργειες που εκτελούνται από αυτό το σημειωματάριο. Τρέχουμε αυτά τα σημειωματάρια ένα προς ένα.
- Επιλέξτε 0_deploy_llava.ipynb για να το ανοίξετε στο JupyterLab.
- Στις τρέξιμο μενού, επιλέξτε Εκτελέστε όλα τα κελιά για να εκτελέσετε τον κώδικα σε αυτό το σημειωματάριο.
Αυτό το σημειωματάριο αναπτύσσει το μοντέλο LLaVA-v1.5-7B σε ένα τελικό σημείο του SageMaker. Σε αυτό το σημειωματάριο, πραγματοποιούμε λήψη του μοντέλου LLaVA-v1.5-7B από το HuggingFace Hub, αντικαθιστούμε το σενάριο inference.py με llava_inference.py, και δημιουργήστε ένα αρχείο model.tar.gz για αυτό το μοντέλο. Το αρχείο model.tar.gz μεταφορτώνεται στο Amazon S3 και χρησιμοποιείται για την ανάπτυξη του μοντέλου στο τελικό σημείο του SageMaker. ο llava_inference.py Το σενάριο έχει πρόσθετο κώδικα που επιτρέπει την ανάγνωση ενός αρχείου εικόνας από το Amazon S3 και την εκτέλεση συμπερασμάτων σε αυτό.
- Επιλέξτε 1_data_prep.ipynb για να το ανοίξετε στο JupyterLab.
- Στις τρέξιμο μενού, επιλέξτε Εκτελέστε όλα τα κελιά για να εκτελέσετε τον κώδικα σε αυτό το σημειωματάριο.
Αυτό το σημειωματάριο κατεβάζει το διαφάνεια, μετατρέπει κάθε διαφάνεια σε μορφή αρχείου JPG και τις ανεβάζει στον κάδο S3 που χρησιμοποιείται για αυτήν την ανάρτηση.
- Επιλέξτε 2_data_ingestion.ipynb για να το ανοίξετε στο JupyterLab.
- Στις τρέξιμο μενού, επιλέξτε Εκτελέστε όλα τα κελιά για να εκτελέσετε τον κώδικα σε αυτό το σημειωματάριο.
Κάνουμε τα εξής σε αυτό το σημειωματάριο:
- Δημιουργούμε ένα ευρετήριο στη συλλογή OpenSearch Serverless. Αυτό το ευρετήριο αποθηκεύει τα δεδομένα ενσωματώσεων για το slide deck. Δείτε τον παρακάτω κώδικα:
- Χρησιμοποιούμε το μοντέλο Titan Multimodal Embeddings για να μετατρέψουμε τις εικόνες JPG που δημιουργήθηκαν στο προηγούμενο σημειωματάριο σε διανυσματικές ενσωματώσεις. Αυτές οι ενσωματώσεις και τα πρόσθετα μεταδεδομένα (όπως η διαδρομή S3 του αρχείου εικόνας) αποθηκεύονται σε ένα αρχείο JSON και αποστέλλονται στο Amazon S3. Σημειώστε ότι δημιουργείται ένα μόνο αρχείο JSON, το οποίο περιέχει έγγραφα για όλες τις διαφάνειες (εικόνες) που έχουν μετατραπεί σε ενσωματώσεις. Το ακόλουθο απόσπασμα κώδικα δείχνει πώς μια εικόνα (με τη μορφή κωδικοποιημένης συμβολοσειράς Base64) μετατρέπεται σε ενσωματώσεις:
- Αυτή η ενέργεια ενεργοποιεί τη διοχέτευση OpenSearch Ingestion, η οποία επεξεργάζεται το αρχείο και το απορροφά στο ευρετήριο OpenSearch Serverless. Το παρακάτω είναι ένα δείγμα του αρχείου JSON που δημιουργήθηκε. (Ένα διάνυσμα με τέσσερις διαστάσεις εμφανίζεται στον κώδικα του παραδείγματος. Το μοντέλο Titan Multimodal Embeddings δημιουργεί 1,024 διαστάσεις.)
- Επιλέξτε 3_rag_inference.ipynb για να το ανοίξετε στο JupyterLab.
- Στις τρέξιμο μενού, επιλέξτε Εκτελέστε όλα τα κελιά για να εκτελέσετε τον κώδικα σε αυτό το σημειωματάριο.
Αυτό το σημειωματάριο υλοποιεί τη λύση RAG: μετατρέπουμε την ερώτηση χρήστη σε ενσωματώσεις, βρίσκουμε μια παρόμοια εικόνα (διαφάνεια) από τη διανυσματική βάση δεδομένων και παρέχουμε την ανακτημένη εικόνα στο LLaVA για να δημιουργήσουμε μια απάντηση στην ερώτηση του χρήστη. Χρησιμοποιούμε το ακόλουθο πρότυπο προτροπής:
Το ακόλουθο απόσπασμα κώδικα παρέχει τη ροή εργασίας RAG:
Αποτελέσματα
Ακολουθεί μια συλλογή ορισμένων ερωτήσεων και απαντήσεων των χρηστών που δημιουργήθηκαν από την υλοποίησή μας. ο Ερώτηση στήλη καταγράφει την ερώτηση χρήστη και το Απάντηση στήλη είναι η απάντηση κειμένου που δημιουργείται από το LLaVA. Εικόνα είναι η k-πλησιέστερη (k=1) αντιστοίχιση διαφανειών που επιστρέφεται από τη διανυσματική αναζήτηση χωρίς διακομιστή OpenSearch. Αυτή η διαφάνεια ερμηνεύεται από το LLaVA για να δώσει την απάντηση.
Πολυτροπικά αποτελέσματα RAG
| Ερώτηση | Απάντηση | Εικόνα |
|---|---|---|
| Πώς συγκρίνεται η απόδοση του Inf2 με συγκρίσιμες περιπτώσεις EC2; Χρειάζομαι αριθμούς. | Σύμφωνα με το slide deck, οι περιπτώσεις Inf2 από το AWS Inferentia2 προσφέρουν έως και 4 φορές υψηλότερη απόδοση και 10 φορές χαμηλότερο λανθάνοντα χρόνο σε σύγκριση με συγκρίσιμες περιπτώσεις EC2. |  |
| Σύμφωνα με τον σφόνδυλο AI/ML, τι παρέχουν οι υπηρεσίες AWS AI/ML; | Οι υπηρεσίες AWS AI/ML παρέχουν καλύτερες δυνατότητες $/perfer, νέες δυνατότητες και επενδύσεις στην καινοτομία. |  |
| Σε σύγκριση με το GPT-2, πόσες περισσότερες παραμέτρους έχει το GPT-3; Ποια είναι η αριθμητική διαφορά μεταξύ του μεγέθους παραμέτρου του GPT-2 και του GPT-3; | Σύμφωνα με τη διαφάνεια, το GPT-3 έχει 175 δισεκατομμύρια παραμέτρους, ενώ το GPT-2 έχει 1.5 δισεκατομμύρια παραμέτρους. Η αριθμητική διαφορά μεταξύ του μεγέθους της παραμέτρου του GPT-2 και του GPT-3 είναι 173.5 δισεκατομμύρια. | 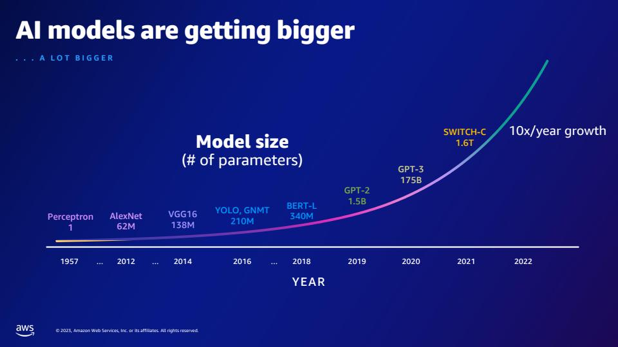 |
| Τι είναι τα κουάρκ στη σωματιδιακή φυσική; | Δεν βρήκα την απάντηση σε αυτή την ερώτηση στο slide deck. |  |
Μη διστάσετε να επεκτείνετε αυτή τη λύση στα slide decks σας. Απλώς ενημερώστε τη μεταβλητή SLIDE_DECK στο globals.py με μια διεύθυνση URL στο slide deck σας και εκτελέστε τα βήματα απορρόφησης που περιγράφονται στην προηγούμενη ενότητα.
Άκρο
Μπορείτε να χρησιμοποιήσετε τους πίνακες ελέγχου OpenSearch για να αλληλεπιδράσετε με το OpenSearch API για να εκτελέσετε γρήγορες δοκιμές στο ευρετήριό σας και στα δεδομένα που έχετε απορροφήσει. Το ακόλουθο στιγμιότυπο οθόνης δείχνει ένα παράδειγμα GET πίνακα ελέγχου OpenSearch.
εκκαθάριση
Για να αποφύγετε μελλοντικές χρεώσεις, διαγράψτε τους πόρους που δημιουργήσατε. Μπορείτε να το κάνετε αυτό διαγράφοντας τη στοίβα μέσω της κονσόλας CloudFormation.

Επιπλέον, διαγράψτε το τελικό σημείο συμπερασμάτων SageMaker που δημιουργήθηκε για εξαγωγή συμπερασμάτων LLaVA. Μπορείτε να το κάνετε αυτό αφαιρώντας το σχολιασμό του βήματος εκκαθάρισης 3_rag_inference.ipynb και εκτέλεση του κελιού ή διαγράφοντας το τελικό σημείο μέσω της κονσόλας SageMaker: επιλέξτε Συμπέρασμα και Τελικά σημεία στο παράθυρο πλοήγησης, επιλέξτε το τελικό σημείο και διαγράψτε το.
Συμπέρασμα
Οι επιχειρήσεις δημιουργούν συνεχώς νέο περιεχόμενο και τα slide decks είναι ένας κοινός μηχανισμός που χρησιμοποιείται για την κοινή χρήση και τη διάδοση πληροφοριών εσωτερικά με τον οργανισμό και εξωτερικά με πελάτες ή σε συνέδρια. Με την πάροδο του χρόνου, οι εμπλουτισμένες πληροφορίες μπορούν να παραμείνουν θαμμένες και κρυμμένες σε τρόπους που δεν αφορούν κείμενο, όπως γραφήματα και πίνακες σε αυτά τα καταστρώματα διαφανειών. Μπορείτε να χρησιμοποιήσετε αυτήν τη λύση και τη δύναμη των πολυτροπικών FM, όπως το μοντέλο Titan Multimodal Embeddings και το LLaVA, για να ανακαλύψετε νέες πληροφορίες ή να ανακαλύψετε νέες προοπτικές για το περιεχόμενο στα slide decks.
Σας ενθαρρύνουμε να μάθετε περισσότερα εξερευνώντας Amazon SageMaker JumpStart, Μοντέλα Amazon Titan, Amazon Bedrock και OpenSearch Service και δημιουργία λύσης χρησιμοποιώντας το δείγμα υλοποίησης που παρέχεται σε αυτήν την ανάρτηση.
Προσέξτε για δύο επιπλέον δημοσιεύσεις ως μέρος αυτής της σειράς. Το Μέρος 2 καλύπτει μια άλλη προσέγγιση που θα μπορούσατε να ακολουθήσετε για να μιλήσετε στο slide deck σας. Αυτή η προσέγγιση δημιουργεί και αποθηκεύει συμπεράσματα LLaVA και χρησιμοποιεί αυτά τα αποθηκευμένα συμπεράσματα για να απαντήσει σε ερωτήματα χρήστη. Το Μέρος 3 συγκρίνει τις δύο προσεγγίσεις.
Σχετικά με τους συγγραφείς
 Amit Arora είναι ειδικός αρχιτέκτονας AI και ML στο Amazon Web Services, βοηθώντας τους εταιρικούς πελάτες να χρησιμοποιούν υπηρεσίες μηχανικής εκμάθησης που βασίζονται σε cloud για να κλιμακώσουν γρήγορα τις καινοτομίες τους. Είναι επίσης επίκουρος λέκτορας στο πρόγραμμα MS data Science and analytics στο Πανεπιστήμιο Georgetown στην Ουάσιγκτον DC
Amit Arora είναι ειδικός αρχιτέκτονας AI και ML στο Amazon Web Services, βοηθώντας τους εταιρικούς πελάτες να χρησιμοποιούν υπηρεσίες μηχανικής εκμάθησης που βασίζονται σε cloud για να κλιμακώσουν γρήγορα τις καινοτομίες τους. Είναι επίσης επίκουρος λέκτορας στο πρόγραμμα MS data Science and analytics στο Πανεπιστήμιο Georgetown στην Ουάσιγκτον DC
 Manju Prasad είναι Senior Solutions Architect στους Strategic Accounts στο Amazon Web Services. Επικεντρώνεται στην παροχή τεχνικής καθοδήγησης σε διάφορους τομείς, συμπεριλαμβανομένου του AI/ML σε έναν μαρκίζ πελάτη M&E. Πριν από την ένταξή της στην AWS, σχεδίασε και κατασκεύασε λύσεις για εταιρείες στον τομέα των χρηματοοικονομικών υπηρεσιών και επίσης για μια startup.
Manju Prasad είναι Senior Solutions Architect στους Strategic Accounts στο Amazon Web Services. Επικεντρώνεται στην παροχή τεχνικής καθοδήγησης σε διάφορους τομείς, συμπεριλαμβανομένου του AI/ML σε έναν μαρκίζ πελάτη M&E. Πριν από την ένταξή της στην AWS, σχεδίασε και κατασκεύασε λύσεις για εταιρείες στον τομέα των χρηματοοικονομικών υπηρεσιών και επίσης για μια startup.
 Archana Inapudi είναι Senior Solutions Architect στην AWS υποστηρίζοντας στρατηγικούς πελάτες. Έχει πάνω από μια δεκαετία εμπειρίας βοηθώντας τους πελάτες να σχεδιάσουν και να δημιουργήσουν λύσεις ανάλυσης δεδομένων και βάσεων δεδομένων. Είναι παθιασμένη με τη χρήση της τεχνολογίας για την παροχή αξίας στους πελάτες και την επίτευξη επιχειρηματικών αποτελεσμάτων.
Archana Inapudi είναι Senior Solutions Architect στην AWS υποστηρίζοντας στρατηγικούς πελάτες. Έχει πάνω από μια δεκαετία εμπειρίας βοηθώντας τους πελάτες να σχεδιάσουν και να δημιουργήσουν λύσεις ανάλυσης δεδομένων και βάσεων δεδομένων. Είναι παθιασμένη με τη χρήση της τεχνολογίας για την παροχή αξίας στους πελάτες και την επίτευξη επιχειρηματικών αποτελεσμάτων.
 Αντάρα Ράισα είναι αρχιτέκτονας λύσεων AI και ML στην Amazon Web Services που υποστηρίζει στρατηγικούς πελάτες με έδρα από το Ντάλας του Τέξας. Έχει επίσης προηγούμενη εμπειρία σε συνεργασία με μεγάλους εταιρικούς εταίρους στην AWS, όπου εργάστηκε ως Αρχιτέκτονας λύσεων επιτυχίας συνεργατών για ψηφιακούς εγγενείς πελάτες.
Αντάρα Ράισα είναι αρχιτέκτονας λύσεων AI και ML στην Amazon Web Services που υποστηρίζει στρατηγικούς πελάτες με έδρα από το Ντάλας του Τέξας. Έχει επίσης προηγούμενη εμπειρία σε συνεργασία με μεγάλους εταιρικούς εταίρους στην AWS, όπου εργάστηκε ως Αρχιτέκτονας λύσεων επιτυχίας συνεργατών για ψηφιακούς εγγενείς πελάτες.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/

